

-
摘要: 低秩纹理结构是图像处理领域中具有重要几何意义的结构,通过提取低秩纹理可以对受到各种变换干扰的图像进行有效校正.针对受到各种变换干扰的低秩图像校正问题,利用生成式框架来缓解图像中不具明显低秩特性区域的校正结果不理想的问题,提出了一种非监督式的由图像生成图像的低秩纹理生成对抗网络(Low-rank generative adversarial network,LR-GAN)算法.首先,该算法将传统的无监督学习的低秩纹理映射算法(Transform invariant low-rank textures,TILT)作为引导加入到网络中来辅助判别器,使网络整体达到无监督学习的效果,并且使低秩对抗对在生成网络和判别网络上都能够学习到结构化的低秩表示.其次,为了保证生成的图像既有较高的图像质量又有相对较低的秩,同时考虑到低秩约束条件下的优化问题不易解决(NP难问题),在经过一定阶段TILT的引导后,设计并加入了低秩梯度滤波层来逼近网络的低秩最优解.通过在MNIST,SVHN和FG-NET这三个数据集上的实验,并使用分类算法评估生成的低秩图像质量,结果表明,本文提出的LR-GAN算法均取得了较好的生成质量与识别效果.
-
关键词:
- 生成对抗网络 /
- 低秩纹理生成对抗网络 /
- 结构化低秩表示 /
- 低秩约束
Abstract: Low-rank texture structure is an important geometric structure in image processing. By extracting low-rank textures, images with various interferences can be rectified effectively. To solve the problem of low rank image correction with various interferences, this paper proposes to use the generation framework to alleviate poor correction results on the region without obvious low-rank properties. And a low-rank texture generative adversarial network (LR-GAN) is proposed using an unsupervised image-to-image network. Firstly, by using transform invariant low-rank textures (TILT) to guide the discriminator in the LR-GAN, the whole network can not only achieve the effect of unsupervised learning but also learn a structured low rank representation on both generation network and discrimination network. Secondly, considering that the low-rank constraint is difficult to optimize (NP-hard problem) in the loss function, we introduce a layer of the low-rank gradient filters to approach the optimal low-rank solution after many iterations guided by TILT. We evaluate the LR-GAN network on three public datasets: MNIST, SVHN and FG-NET, and verify the quality of generative low-rank images by using a classification network. Experimental results demonstrate that the proposed method is effective in both generative quality and recognition accuracy.1) 本文责任编委 王坤峰 -
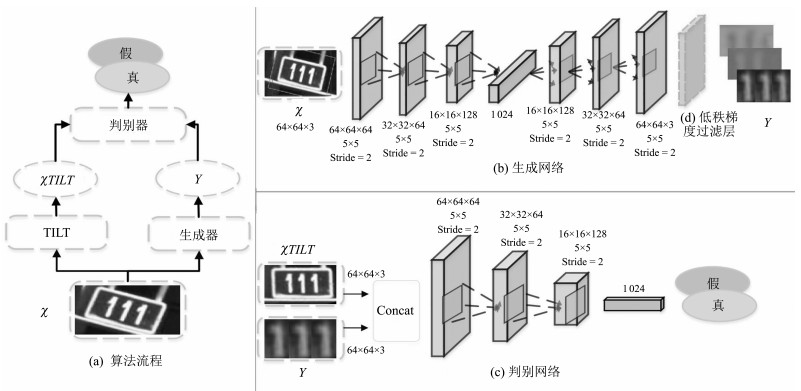
图 2 LR-GAN的网络结构示意图((a) LR-GAN网络的整体算法流程; (b)生成器网络负责生成原始图像的低秩纹理图像; (c)判别器网络将生成器生成的图像和TILT算法转换之后的图像进行对抗学习; (d)为在训练后期加入的低秩梯度过滤层)
Fig. 2 The structure chart of LR-GAN ((a) The general framework of LR-GAN; (b) The Generator generates the low-rank texture image from the original image; (c) The Discriminator distinguishes between the generative image and the TILT image; (d) The layer of the low-rank gradient filter for training.)
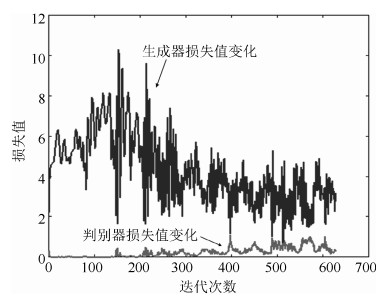
图 5 MNIST数据集迭代过程中生成器与判别器的损失值变化
Fig. 5 The loss of both the generator and the discriminator on MNIST during the iterations
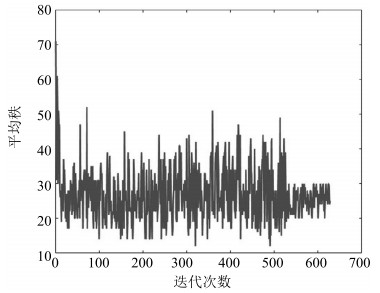
图 6 MNIST数据集上生成器迭代过程中图像秩的变化
Fig. 6 The changes of the rank during the generator iterations on MNIST

图 8 SVHN数据集迭代过程中生成器与判别器的损失值变化
Fig. 8 The loss of both the generator and the discriminator on SVHN during the iterations
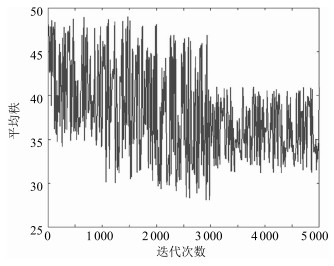
图 9 SVHN数据集上生成器迭代过程中图像秩的变化
Fig. 9 The changes of the rank during the generator iterations on SVHN
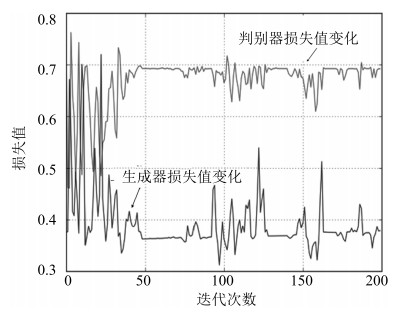
图 11 FG-NET数据集迭代过程中生成器与判别器的损失值变化
Fig. 11 The loss of both the generator and the discriminator on FG-NET during the iterations
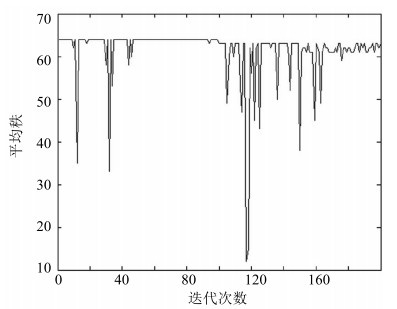
图 12 FG-NET数据集上生成器迭代过程中图像秩的变化
Fig. 12 The changes of the rank during the generator iterations on FG-NET
表 1 MNIST与SVHN上的平均秩结果
Table 1 The average rank on MNIST and SVHN datasets
method MNIST SVHN TILT 31 46 LR-GAN 29 40 LR-GAN + Filter 27 37  下载: 导出CSV
下载: 导出CSV
表 2 在形变的MNIST上的分类识别效果
Table 2 The classification performance on distorted MNIST
database method mAp no 0.5701 MNIST TILT 0.6303 ours 0.6497
下载: 导出CSV
表 3 在SVHN上的分类识别效果
Table 3 The classification performance on SVHN
database method mAp no 0.9609 SVHN TILT 0.9701 ours 0.9756
下载: 导出CSV
-
[1] 李树涛, 魏丹.压缩传感综述.自动化学报, 2009, 35(11):1369-1377 http://www.aas.net.cn/CN/abstract/abstract13592.shtmlLi Shu-Tao, Wei Dan. A survey on compressive sensing. Acta Automatica Sinica, 2009, 35(11):1369-1377 http://www.aas.net.cn/CN/abstract/abstract13592.shtml [2] 彭义刚, 索津莉, 戴琼海, 徐文立.从压缩传感到低秩矩阵恢复:理论与应用.自动化学报, 2013, 39(7):981-994 http://www.aas.net.cn/CN/abstract/abstract18126.shtmlPeng Yi-Gang, Suo Jin-Li, Dai Qiong-Hai, Xu Wen-Li. From compressed sensing to low-rank matrix recovery:theory and applications. Acta Automatica Sinica, 2013, 39(7):981-994 http://www.aas.net.cn/CN/abstract/abstract18126.shtml [3] Yang S, Wei E L, Guan R M, Zhang X F, Qin J, Wang Y Y. Triangle chain codes for image matching. Neurocomputing, 2013, 120:268-276 doi: 10.1016/j.neucom.2012.08.055 [4] Brown M, Lowe D G. Automatic panoramic image stitching using invariant features. International Journal of Computer Vision, 2007, 74(1):59-73 doi: 10.1007/s11263-006-0002-3 [5] Han J G, Farin D, de With P. A mixed-reality system for broadcasting sports video to mobile devices. IEEE MultiMedia, 2011, 18(2):72-84 doi: 10.1109/MMUL.2010.24 [6] Cheng L, Gong J Y, Li M C, Liu Y X. 3D building model reconstruction from multi-view aerial imagery and lidar data. Photogrammetric Engineering and Remote Sensing, 2011, 77(2):125-139 doi: 10.14358/PERS.77.2.125 [7] Zhang Z D, Liang X, Ganesh A, Ma Y. Tilt: transform invariant low-rank textures. In: Proceedings of the 10th Asian Conference on Computer Vision-ACCV 2010. Berlin Heidelberg, Germany: Springer, 2011. 314-328 [8] Zhang Z D, Ganesh A, Liang X, Ma Y. Tilt:transform invariant low-rank textures. International Journal of Computer Vision, 2012, 99(1):1-24 doi: 10.1007/s11263-012-0515-x [9] Zhang Y, Jiang Z L, Davis L S. Learning structured low-rank representations for image classification. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, OR, USA: IEEE, 2013. 676-683 [10] Zhang Z D, Liang X, Ma Y. Unwrapping low-rank textures on generalized cylindrical surfaces. In: Proceedings of the 2001 International Conference on Computer Vision (ICCV). Barcelona, Spain: IEEE, 2011. 1347-1354 [11] Mobahi H, Zhou Z H, Yang A Y, Ma Y. Holistic 3D reconstruction of urban structures from low-rank textures. In: Proceedings of the 2011 International Conference on Computer Vision Workshops (ICCV Workshops). Barcelona, Spain: IEEE, 2011. 593-600 [12] Zhang Z D, Matsushita Y, Ma Y. Camera calibration with lens distortion from low-rank textures. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado Springs, CO, USA: IEEE, 2011. 2321-2328 [13] Zhang X, Lin Z C, Sun F C, Ma Y. Rectification of optical characters as transform invariant low-rank textures. In: Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR). Washington, DC, USA: IEEE, 2013. 393-397 [14] Lin Z C, Liu R S, Su Z X. Linearized alternating direction method with adaptive penalty for low-rank representation. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Granada, Spain: ACM, 2011. 612-620 [15] Zhang Q, Li Y J, Blum R S, Xiang P. Matching of images with projective distortion using transform invariant low-rank textures. Journal of Visual Communication and Image Representation, 2016, 38:602-613 doi: 10.1016/j.jvcir.2016.04.007 [16] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM, 2014. 2672-2680 [17] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [18] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. In: Proceedings of the 2016 International Conference on Learning Representation (ICLR). San Juan, Puerto Rico: 2016. 3, 5, 6 [19] Nair V, Hinton G E. Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel: ACM, 2010. 807-814 [20] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. 448-456 [21] Fan E G. Extended tanh-function method and its applications to nonlinear equations. Physics Letters A, 2000, 277(4-5):212-218 doi: 10.1016/S0375-9601(00)00725-8 [22] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, Georgia, USA: PMLR, 2013. [23] Mao X D, Li Q, Xie H R, Lau R Y K, Wang Z, Smolley S P. Least squares generative adversarial networks. In: Proceedings of the 2017 International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2813-2821 [24] Zhao S Y, Li W J. Fast asynchronous parallel stochastic gradient descent: a lock-free approach with convergence guarantee. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, Arizona: AAAI, 2016. 2379-2385 [25] LeCun Y, Cortes C, Burges C J C. The MNIST database of handwritten digits[Online], available: http://yann.lecun.com/exdb/mnist/, July 12, 2016 [26] Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K. Spatial transformer networks. In: Proceedings of the 29th Annual Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2015. 2017-2025 [27] Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng A Y. Reading digits in natural images with unsupervised feature learning. In: Proceedings of the 2011 NIPS Workshop on Deep Learning and Unsupervised Feature Learning. Granada, Spain: NIPS, 2011. 2: 5-13 [28] Panis G, Lanitis A, Tsapatsoulis N, Cootes T F. Overview of research on facial ageing using the FG-NET ageing database. IET Biometrics, 2016, 5(2):37-46 doi: 10.1049/iet-bmt.2014.0053 [29] 李力, 林懿伦, 曹东璞, 郑南宁, 王飞跃.平行学习——机器学习的一个新型理论框架.自动化学报, 2017, 43(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtmlLi Li, Lin Yi-Lun, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel learning——a new framework for machine learning. Acta Automatica Sinica, 2017, 43(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtml [30] 王坤峰, 苟超, 王飞跃.平行视觉:基于ACP的智能视觉计算方法.自动化学报, 2016, 42(10):1490-1500 http://www.aas.net.cn/CN/abstract/abstract18936.shtmlWang Kun-Feng, Gou Chao, Wang Fei-Yue. Parallel vision:an ACP-based approach to intelligent vision computing. Acta Automatica Sinica, 2016, 42(10):1490-1500 http://www.aas.net.cn/CN/abstract/abstract18936.shtml -

 下载:
下载:





计量
- 文章访问数: 2836
- HTML全文浏览量: 563
- PDF下载量: 1134
- 被引次数: 0
