

Image Recognition With Conditional Deep Convolutional Generative Adversarial Networks
-
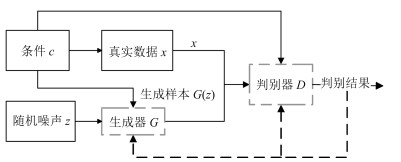
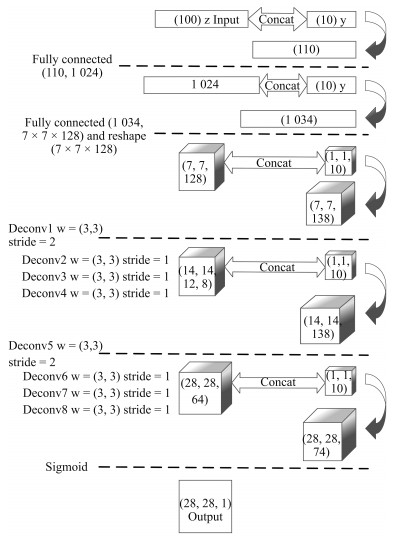
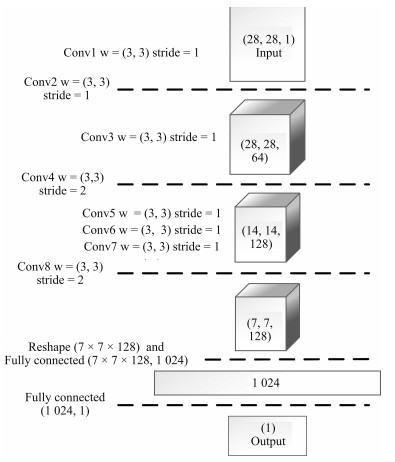
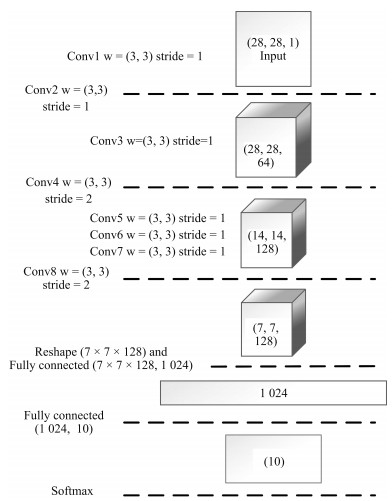
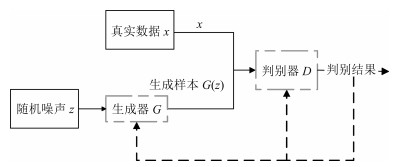
摘要: 生成对抗网络(Generative adversarial networks,GAN)是目前热门的生成式模型.深度卷积生成对抗网络(Deep convolutional GAN,DCGAN)在传统生成对抗网络的基础上,引入卷积神经网络(Convolutional neural networks,CNN)进行无监督训练;条件生成对抗网络(Conditional GAN,CGAN)在GAN的基础上加上条件扩展为条件模型.结合深度卷积生成对抗网络和条件生成对抗网络的优点,建立条件深度卷积生成对抗网络模型(Conditional-DCGAN,C-DCGAN),利用卷积神经网络强大的特征提取能力,在此基础上加以条件辅助生成样本,将此结构再进行优化改进并用于图像识别中,实验结果表明,该方法能有效提高图像的识别准确率.Abstract: Generative adversarial network (GAN) is a prevalent generative model. Deep convolutional generative adversarial network (DCGAN), based on traditional generative adversarial networks, introduces convolutional neural networks (CNN) into the training for unsupervised learning to improve the effect of generative networks. Conditional generative adversarial network (CGAN) is a conditional model which adds condition extension into GAN. The generative model of conditional-DCGAN (C-DCGAN) is a combination of DCGAN and CGAN, which integrates the feature extraction of convolutional networks and condition auxiliary generative sample for image recognition. The result of simulation experiments shows that this model can improve the accuracy of image recognition.1) 本文责任编委 李力
-
表 1 MNIST上各方法准确率对比
Table 1 The recognition accuracy comparison on MNIST
识别方法 预训练 准确率(%) linear classifier (1-layer NN) 去斜 91.60 K-nearest-neighbors, Euclidean (L2) - 95.00 40 PCA+quadratic classifier - 96.70 SVM, Gaussian Kernel - 98.60 Trainable feature extractor+SVMs [no distortions] - 99.17 Convolutional net LeNet-5, [no distortions] - 99.05 Convolutional net LeNet-5, [huge, distortions] huge distortions 99.15 Convolutional net LeNet-5, [distortions] distortions 99.20 CNN 归一化 98.40 C-DCGAN+Softmax - 99.45  下载: 导出CSV
下载: 导出CSV
表 2 CIFAR-10上各方法准确率对比
Table 2 The recognition accuracy comparison on CIFAR-10
识别方法 准确率(%) 1 Layer K-means 80.6 3 Layer K-means Learned RF 82.0 View Invariant K-means 81.9 Cuda-convnet (CNN) 82.0 DCGAN+L2-SVM 82.8 C-DCGAN+Softmax 84
下载: 导出CSV
-
[1] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [2] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM, 2014. 2672-2680 [3] Ratliff L J, Burden S A, Sastry S S. Characterization and computation of local Nash equilibria in continuous games. In: Proceedings of the 51st Communication, Control, and Computing (Allerton). Monticello, IL, USA: IEEE, 2013. 917-924 [4] Goodfellow I. NIPS 2016 tutorial: generative adversarial networks. arXiv preprint arXiv: 1701.00160, 2016. [5] Li J W, Monroe W, Shi T L, Jean S, Ritter A, Jurafsky D. Adversarial learning for neural dialogue generation. arXiv preprint arXiv: 1701.06547, 2017. [6] Yu L T, Zhang W N, Wang J, Yu Y. SeqGAN: sequence generative adversarial nets with policy gradient. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI, 2017. 2852-2858 [7] Hu W W, Tan Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv preprint arXiv: 1702.05983, 2017. [8] Chidambaram M, Qi Y J. Style transfer generative adversarial networks: learning to play chess differently. arXiv preprint arXiv: 1702.06762, 2017. [9] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [10] 常亮, 邓小明, 周明全, 武仲科, 袁野, 杨硕, 王宏安.图像理解中的卷积神经网络.自动化学报, 2016, 42(9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtmlChang Liang, Deng Xiao-Ming, Zhou Ming-Quan, Wu Zhong-Ke, Yuan Ye, Yang Shuo, Wang Hong-An. Convolutional neural networks in image understanding. Acta Automatica Sinica, 2016, 42(9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtml [11] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv: 1511.06434, 2015. [12] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊.深度学习在手写汉字识别中的应用综述.自动化学报, 2016, 42(8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtmlJin Lian-Wen, Zhong Zhuo-Yao, Yang Zhao, Yang Wei-Xin, Xie Ze-Cheng, Sun Jun. Applications of deep learning for handwritten Chinese character recognition:a review. Acta Automatica Sinica, 2016, 42(8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtml [13] 陈荣, 曹永锋, 孙洪.基于主动学习和半监督学习的多类图像分类.自动化学报, 2011, 37(8):954-962 http://www.aas.net.cn/CN/abstract/abstract17514.shtmlChen Rong, Cao Yong-Feng, Sun Hong. Multi-class image classification with active learning and semi-supervised learning. Acta Automatica Sinica, 2011, 37(8):954-962 http://www.aas.net.cn/CN/abstract/abstract17514.shtml [14] Arjovsky M, Bottou L. Towards principled methods for training generative adversarial networks. arXiv preprint arXiv: 1701.04862, 2017. [15] Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout:a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 2014, 15(1):1929-1958 https://www.mendeley.com/research-papers/dropout-simple-way-prevent-neural-networks-overfitting/ [16] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. 448-456 [17] Simon M, Rodner E, Denzler J. ImageNet pre-trained models with batch normalization. arXiv preprint arXiv: 1612.01452, 2016. [18] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: ACM, 2012. 1097-1105 [19] LeCun Y, Cortes C, Burges C J C. The MNIST database of handwritten digits[Online], available: http://yann.lecun.com/exdb/mnist/, July 12, 2016 [20] 许可. 卷积神经网络在图像识别上的应用的研究[硕士学位论文]. 浙江大学, 中国, 2012.Xu Ke. Study of Convolutional Neural Network Applied on Image Recognition[Master thesis], Zhejiang University, China, 2012. [21] Krizhevsky A, Nair V, Hinton G. The CIFAR-10 dataset[Online], available: http://www.cs.toronto.edu/kriz/cifar.html, July 24, 2017 -

 下载:
下载:
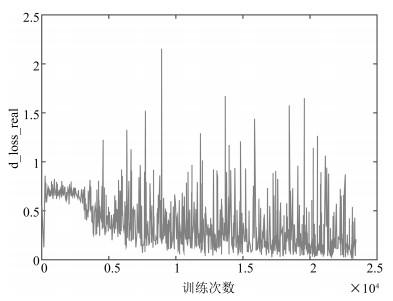
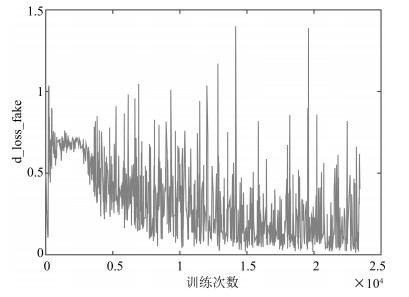
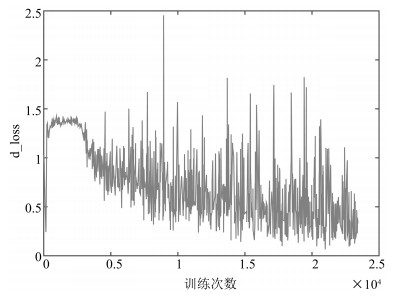
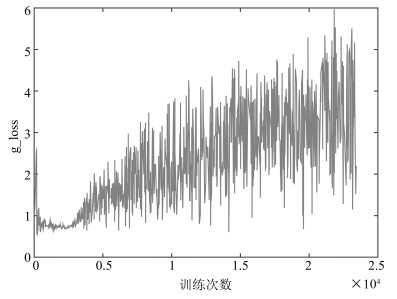






图(18) / 表(2)
计量
- 文章访问数: 5670
- HTML全文浏览量: 2161
- PDF下载量: 2320
- 被引次数: 0
