

-
摘要: 基于最大似然估计(Maximum likelihood estimation,MLE)的语言模型(Language model,LM)数据增强方法由于存在暴露偏差问题而无法生成具有长时语义信息的采样数据.本文提出了一种基于对抗训练策略的语言模型数据增强的方法,通过一个辅助的卷积神经网络判别模型判断生成数据的真伪,从而引导递归神经网络生成模型学习真实数据的分布.语言模型的数据增强问题实质上是离散序列的生成问题.当生成模型的输出为离散值时,来自判别模型的误差无法通过反向传播算法回传到生成模型.为了解决此问题,本文将离散序列生成问题表示为强化学习问题,利用判别模型的输出作为奖励对生成模型进行优化,此外,由于判别模型只能对完整的生成序列进行评价,本文采用蒙特卡洛搜索算法对生成序列的中间状态进行评价.语音识别多候选重估实验表明,在有限文本数据条件下,随着训练数据量的增加,本文提出的方法可以进一步降低识别字错误率(Character error rate,CER),且始终优于基于MLE的数据增强方法.当训练数据达到6M词规模时,本文提出的方法使THCHS30数据集的CER相对基线系统下降5.0%,AISHELL数据集的CER相对下降7.1%.Abstract: The conventional approach to data augmentation for language models based on maximum likelihood estimation (MLE) causes the exposure bias problem, which leads to generated text lacking of long-term semantics. We propose a novel data augmentation approach via adversarial training, which uses a convolutional neural network as a discriminator to guide the training of a recurrent neural network based generative model. The matter of augmentation for language models can be regarded as discrete sequential data generation. When outputs of the generative model are discrete, backforward propagation algorithm fails to update the generative model via the gradient of discriminator errors. To deal with this problem, we treat the generative model as a stochastic policy in reinforcement learning and optimize it by rewards from the discriminator. Since the discriminator can only judge completed sequences, we evaluate intermediate states by Monte Carlo search. Experiments on rescoring the n-best lists of speech recognition outputs show that with the increase of training corpus, the proposed approach achieves a lower character error rate (CER) and always outperforms the MLE-based approach. When training corpus reaches 6 million tokens, the proposed approach provides a relative 5.0% CER reduction on THCHS30 dataset and a relative 7.1% CER reduction on AISHELL dataset compared with the baseline.
-
-
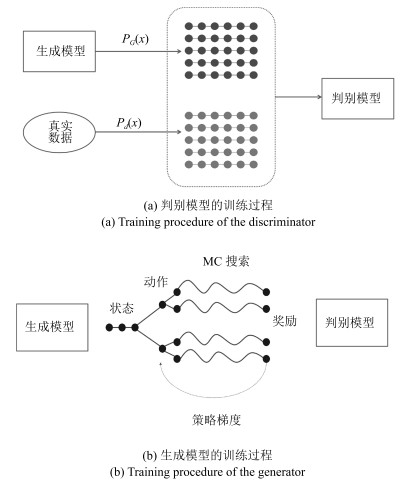
图 1 序列生成对抗网络训练过程
Fig. 1 Training procedure of the sequential generative adversarial network
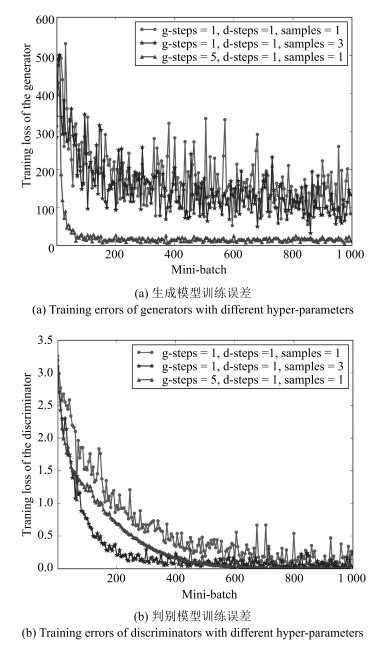
图 2 不同超参数条件下序列对抗生成网络训练误差
Fig. 2 Training errors of sequential generative adversarial networks with different hyper-parameters

图 3 序列生成对抗网络在不同数据集上的性能
Fig. 3 Performance of sequential generative adversarial networks on different datasets

图 4 训练数据规模对两种数据增强技术性能的影响
Fig. 4 The effect of the size of training data on two augmentation approaches
表 1 不同数据增强技术对识别字错误率的影响(%)
Table 1 Character error rates of different methods (%)
THCHS 30 AISHELL 基线系统 42.5 16.9 最大似然估计 40.8 16.0 对抗训练策略 40.4 15.7  下载: 导出CSV
下载: 导出CSV
表 2 相同历史信息条件下不同生成模型生成的文本对比
Table 2 Sentences generated by different models given the same context
序号 模型 采样文本/真实文本 真实数据 华北北部旱情仍未解除的地区, 宁肯让夏玉米种子下地等雨也不要迟播 样例1 MLE 存在一些安全隐患 GAN 为加快稳定粮食生产市场平稳监管 真实数据 至于业已结婚成家的人员可以不考虑农转非, 因为这些人农转非已无实际意义 样例2 MLE 下降7个城市房价将面临顺利明显上涨 GAN 保障房建设力度确实有限 真实数据 1993年台湾茶饮料销售额达5亿美元, 是各类饮料中增幅最快的产品 样例3 MLE 股票分红地价约60亿价加速 GAN 同比增长至31.6 真实数据 工信部就十二五时期的宽带建设, 已进行全面规划 样例4 MLE 重点在科技创新方面 GAN 所以我当时可以做规划
下载: 导出CSV
-
[1] 司玉景, 肖业鸣, 徐及, 潘接林, 颜永红.面向口语统计语言模型建模的自动语料生成算法.自动化学报, 2014, 40(12):2808-2814 http://www.aas.net.cn/CN/abstract/abstract18559.shtmlSi Yu-Jing, Xiao Ye-Ming, Xu Ji, Pan Jie-Lin, Yan Yong-Hong. Automatic text corpus generation algorithm towards oral statistical language modeling. Acta Automatica Sinica, 2014, 40(12):2808-2814 http://www.aas.net.cn/CN/abstract/abstract18559.shtml [2] Allison B, Guthrie D, Guthrie L. Another look at the data sparsity problem. In: Proceedings of the 9th International Conference on Text, Speech, and Dialogue. Brno, Czech Republic: Springer, 2006. 327-334 [3] Janiszek D, De Mori R, Bechet E. Data augmentation and language model adaptation. In: Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Salt Lake City, UT, USA: IEEE, 2001. 549-552 [4] Ng T, Ostendorf M, Hwang M Y, Siu M, Bulyko I, Lei X. Web-data augmented language models for mandarin conversational speech recognition. In: Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Philadelphia, USA: IEEE, 2005. 589-592 [5] Si Y J, Chen M Z, Zhang Q Q, Pan J L, Yan Y H. Block based language model for target domain adaptation towards web corpus. Journal of Computational Information Systems, 2013, 9(22):9139-9146 [6] Sutskever I, Martens J, Hinton G. Generating text with recurrent neural networks. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, Washington, USA: IEEE, 2011. 1017-1024 [7] Bowman S R, Vilnis L, Vinyals O, Dai A M, Jozefowicz R, Bengio S. Generating sentences from a continuous space. arXiv: 1511.06349, 2015. [8] Ranzato M, Chopra S, Auli M, Zaremba W. Sequence level training with recurrent neural networks. arXiv: 1511.06732, 2015. [9] Norouzi M, Bengio S, Chen Z F, Jaitly N, Schuster M, Wu Y H, et al. Reward augmented maximum likelihood for neural structured prediction. In: Proceedings of the 2016 Advances in Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 1723-1731 [10] Lamb A, Goyal A, Zhang Y, Zhang S Z, Courville A, Bengio Y. Professor forcing: a new algorithm for training recurrent networks. In: Proceedings of the 29th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 4601-4609 [11] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2672-2680 [12] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [13] Kaelbling L P, Littman M L, Moore A W. Reinforcement learning:a survey. Journal of Artificial Intelligence Research, 1996, 4(1):237-285 [14] Van Otterlo M, Wiering M. Reinforcement learning and Markov decision processes. Reinforcement Learning: State-of-the-Art. Berlin, Germany: Springer, 2012. 3-42 [15] 陈兴国, 俞扬.强化学习及其在电脑围棋中的应用.自动化学报, 2016, 42(5):685-695 http://www.aas.net.cn/CN/abstract/abstract18858.shtmlChen Xing-Guo, Yu Yang. Reinforcement learning and its application to the game of go. Acta Automatica Sinica, 2016, 42(5):685-695 http://www.aas.net.cn/CN/abstract/abstract18858.shtml [16] Chaslot G M J B, Winands M H M, Uiterwijk J W H M, Van Den Herik H J, Bouzy B. Progressive strategies for Monte-Carlo tree search. New Mathematics and Natural Computation, 2008, 4(3):343-357 doi: 10.1142/S1793005708001094 [17] Silver D, Huang A J, Maddison C J, Guez A, Sifre L, Van Den Driessche G, et al. Mastering the game of go with deep neural networks and tree search. Nature, 2016, 529(7587):484-489 doi: 10.1038/nature16961 [18] Quinlan J R. Bagging, boosting, and C4. 5. In: Proceddings of the 13th National Conference on Artificial Intelligence and the 8th Innovative Applications of Artificial Intelligence Conference. Portland, USA: AAAI, 1996. 725-730 [19] Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: ACM, 2013. Ⅲ-1310-Ⅲ-1318 [20] Pascanu R, Mikolov T, Bengio Y. Understanding the exploding gradient problem. arXiv: 1211.5063, 2012. [21] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8):1735-1780 doi: 10.1162/neco.1997.9.8.1735 [22] Sundermeyer M, Schlüter R, Ney H. LSTM neural networks for language modeling. In: Proceedings of the 13th Annual Conference of the International Speech Communication Association. Portland, USA: IEEE, 2012. 601-608 [23] Cho K, Van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv: 1406.1078, 2014. [24] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv: 1409.0473, 2014. [25] Veselý K, Ghoshal A, Burget L, Povey D. Sequence-discriminative training of deep neural networks. In: Proceedings of the 14th Annual Conference of the International Speech Communication Association. Lyon, France: IEEE, 2013. 2345-2349 [26] Kim Y. Convolutional neural networks for sentence classification. arXiv: 1408.5882, 2014. [27] Lai S W, Xu L H, Liu K, Zhao J. Recurrent convolutional neural networks for text classification. In: Proceddings of the 29th AAAI Conference on Artificial Intelligence. Austin, USA: AAAI, 2015. 2267-2273 [28] Zhang X, LeCun Y. Text understanding from scratch. arXiv: 1502.01710, 2015. [29] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv: 1301.3781, 2013. [30] Srivastava R K, Greff K, Schmidhuber J. Highway networks. arXiv: 1505.00387, 2015. [31] Wang D, Zhang X W. THCHS-30: a free Chinese speech corpus. arXiv: 1512.01882, 2015. [32] Bu H, Du J Y, Na X Y, Wu B G, Zheng H. AIShell-1: an open-source mandarin speech corpus and a speech recognition baseline. arXiv: 1709.05522, 2017. [33] Povey D, Ghoshal A, Boulianne G, Burget L, Glembek O, Goel N, et al. The Kaldi speech recognition toolkit. In: Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding. Hawaii, USA: IEEE, 2011. 1-4 [34] Stolcke A. SRILM——an extensible language modeling toolkit. In: Proceedings of the 7th International Conference on Spoken Language Processing. Denver, USA: IEEE, 2002. 901-904 [35] Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z F, Citro C, et al. Tensorflow: large-scale machine learning on heterogeneous distributed systems. arXiv: 1603.04467, 2016. [36] Kingma D P, Ba J. Adam: a method for stochastic optimization. arXiv: 1412.6980, 2014. [37] Moore R C, Lewis W. Intelligent selection of language model training data. In: Proceedings of the 2010 ACL Conference Short Papers. Uppsala, Sweden: ACM, 2010. 220-224 [38] Tüske Z, Irie K, Schlüter R, Ney H. Investigation on log-linear interpolation of multi-domain neural network language model. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech, and Signal Processing. Shanghai, China: IEEE, 2016. 6005-6009 [39] Le Q, Mikolov T. Distributed representations of sentences and documents. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: IEEE, 2014. 1017-1024 [40] Van Der Maaten L. Accelerating t-SNE using tree-based algorithms. The Journal of Machine Learning Research, 2014, 15(1):3221-32451 -


计量
- 文章访问数: 2579
- HTML全文浏览量: 589
- PDF下载量: 1213
- 被引次数: 0
