

-
摘要: 随着大量移动设备的出现,准确和高效的轨迹预测有助于提高面向位置的应用和服务的质量和水平.针对现有方法对轨迹不确定性缺乏有效建模的问题,提出了基于非参数密度估计的不确定轨迹终点预测方法.在轨迹建模及模型训练阶段,利用非参数估计对起点与终点相同的轨迹构建基于密度分布的不确定轨迹模型;在轨迹预测阶段,将待预测轨迹视为轨迹数据流,并通过KS(Kolmogorov-Smirnov)检验方法与具有相同起点的不确定轨迹模型进行匹配,其中匹配程度最高的不确定轨迹即为预测轨迹.通过真实轨迹数据集上的实验表明,与现有各类主要轨迹预测方法相比,本方法在不同条件下的预测效率与准确性都有较明显优势.Abstract: With the popularization of a large number of mobile devices, the accurate and efficient trajectory prediction could help to improve the service quality of location-oriented applications. To solve the problem of less effectiveness existing in modeling for uncertain trajectories, we propose a method for predicting the destination of uncertain trajectories using the non-parametric density estimation method. In the modeling stage, the uncertain trajectory model between the same origin and destination is constructed with the method of non-parametric estimation to represent the density distribution feature. In the trajectory prediction stage, the trajectory to be predicted is regarded as a data stream. And it is matched with the uncertain trajectory having the same origin through the KS (Kolmogorov-Smirnov) hypothesis testing. Then the optimal matching uncertain trajectory is the prediction result and its destination is the predictive destination. The Experiments on real trajectory datasets indicate that the proposed method has obvious advantages in prediction efficiency and accuracy under different conditions, as compared to the existing trajectory prediction methods.1) 本文责任编委 曾志刚
-
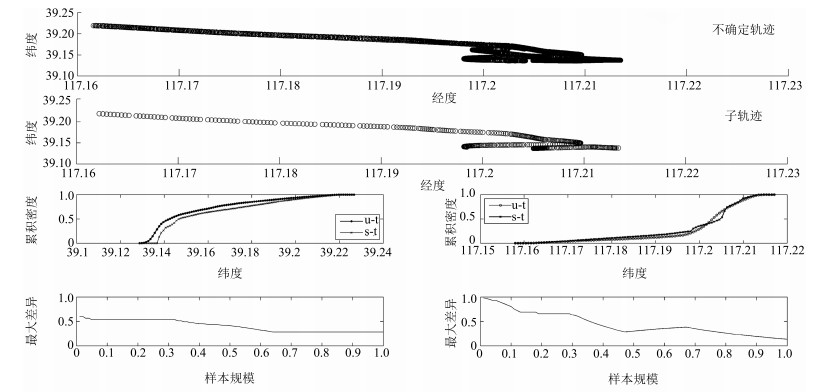
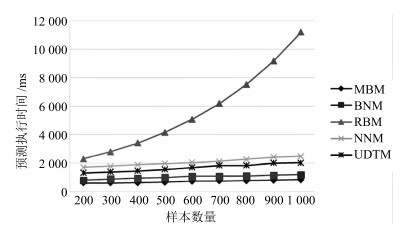
图 5 不确定轨迹预测的累计密度及其误差变化
Fig. 5 Accumulation density and error of uncertain trajectory prediction
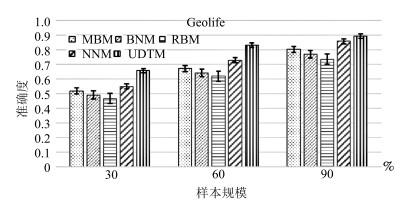
表 1 数据集上各算法的预测准确性对比
Table 1 Prediction accuracy comparison of several methods on Geolife
样本规模 MBM BNM RBM NNM UDTM 30% 0.496 0.51 0.434 0.552 0.671 0.515 0.511 0.491 0.549 0.663 0.506 0.489 0.495 0.548 0.653 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.508 0.524 0.467 0.561 0.660 0.523 0.498 0.426 0.548 0.673 0.502 0.495 0.464 0.547 0.674 60% 0.674 0.630 0.618 0.694 0.860 0.652 0.634 0.633 0.716 0.827 0.654 0.660 0.665 0.749 0.855 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.696 0.643 0.585 0.729 0.847 0.687 0.632 0.627 0.717 0.861 0.650 0.654 0.644 0.732 0.861 90% 0.793 0.749 0.761 0.861 0.916 0.807 0.745 0.729 0.861 0.897 0.794 0.800 0.750 0.861 0.900 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.799 0.784 0.771 0.863 0.890 0.775 0.780 0.706 0.860 0.894 0.802 0.767 0.771 0.839 0.900  下载: 导出CSV
下载: 导出CSV
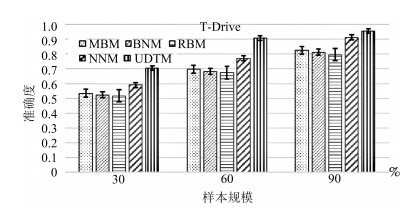
表 2 T-Drive数据集上各算法的预测准确性对比
Table 2 Prediction accuracy comparison of several methods on T-Drive
样本规模 MBM BNM RBM NNM UDTM 30% 0.519 0.495 0.49 0.593 0.705 0.511 0.513 0.444 0.596 0.699 0.477 0.512 0.482 0.579 0.708 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.520 0.510 0.467 0.586 0.719 0.535 0.506 0.488 0.601 0.721 0.521 0.505 0.480 0.594 0.702 60% 0.691 0.659 0.620 0.780 0.898 0.680 0.688 0.683 0.747 0.895 0.673 0.675 0.634 0.767 0.889 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.685 0.675 0.654 0.793 0.897 0.675 0.681 0.660 0.772 0.879 0.680 0.644 0.607 0.761 0.902 90% 0.841 0.798 0.751 0.915 0.969 0.805 0.779 0.761 0.879 0.944 0.857 0.808 0.777 0.910 0.948 $\cdots$ $\cdots$ $\cdots$ $\cdots$ $\cdots$ 0.839 0.823 0.694 0.893 0.963 0.790 0.797 0.721 0.901 0.961 0.804 0.786 0.740 0.888 0.961
下载: 导出CSV
-
[1] Song C M, Qu Z H, Blumm N, Barabási A L. Limits of predictability in human mobility. Science, 2010, 327(5968):1018-1021 doi: 10.1126/science.1177170 [2] Mamoulis N, Cao H P, Kollios G, Hadjieleftheriou M, Tao Y F, Cheung D W. Mining, indexing, and querying historical spatiotemporal data. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle, USA: ACM, 2004. 236-245 [3] Morzy M. Mining frequent trajectories of moving objects for location prediction. In: Proceedings of the 5th International Conference on Machine Learning and Data Mining in Pattern Recognition. Leipzig, Germany: Springer, 2007. 667-680 [4] Jeung H, Liu Q, Shen H T, Zhou X F. A hybrid prediction model for moving objects. In: Proceedings of the 24th International Conference on Data Engineering. Cancun, Mexico: IEEE, 2008. 70-79 [5] Ying J J C, Lee W C, Weng T C, Tseng V S. Semantic trajectory mining for location prediction. In: Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. Chicago, USA: ACM, 2011. 34-43 [6] Zheng Y, Zhang L Z, Xie X, Alma W Y. Mining interesting locations and travel sequences from GPS trajectories. In: Proceedings of the 18th International Conference on World Wide Web. Madrid, Spain: ACM, 2009. 791-800 [7] Qiao S J, Shen D Y, Wang X T, Han N, Zhu W. A self-adaptive parameter selection trajectory prediction approach via hidden Markov models. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(1):284-296 doi: 10.1109/TITS.6979 [8] De Brébisson A, Simon É, Auvolat A, Vincent P, Bengio Y. Artificial neural networks applied to taxi destination prediction. In: Proceedings of the 2015 International Conference on ECML PKDD Discovery Challenge. Aachen, Germany: CEUR-WS.org, 2015. 40-51 [9] Krumm J, Horvitz E. Predestination: inferring destinations from partial trajectories. In: Proceedings of the 8th International Conference on Ubiquitous Computing. Orange County, USA: Springer, 2006. 243-260 [10] Ziebart B D, Maas A L, Dey A K, Bagnell J A. Navigate like a cabbie: probabilistic reasoning from observed context-aware behavior. In: Proceedings of the 10th International Conference on Ubiquitous computing. Seoul, Korea: ACM, 2008. 322-331 [11] Patterson D J, Liao L, Fox D, Kautz H. Inferring high-level behavior from low-level sensors. In: Proceedings of the 5th International Conference on Ubiquitous Computing. Seattle, WA, USA: Springer, 2003. 73-89 [12] Monreale A, Pinelli F, Trasarti R, Giannotti F. Wherenext: a location predictor on trajectory pattern mining. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France: ACM, 2009. 637-646 [13] Ashbrook D, Starner T. Using GPS to learn significant locations and predict movement across multiple users. Personal and Ubiquitous Computing, 2003, 7(5):275-286 doi: 10.1007/s00779-003-0240-0 [14] Gambs S, Killijian M O, Del M N, Cortez P. Next place prediction using mobility markov chains. In: Proceedings of the 1st Workshop on Measurement, Privacy, and Mobility. Bern, Switzerland: ACM, 2012. Article No.3 [15] 乔少杰, 金琨, 韩楠, 唐常杰, 格桑多吉, Gutierrez L A.一种基于高斯混合模型的轨迹预测算法.软件学报, 2015, 26(5):1048-1063 http://d.old.wanfangdata.com.cn/Periodical/rjxb201505005Qiao Shao-Jie, Jin Kun, Han Nan, Tang Chang-Jie, Gesangduoji, Gutierrez L A. Trajectory prediction algorithm based on Gaussian mixture model. Journal of Software, 2015, 26(5):1048-1063 http://d.old.wanfangdata.com.cn/Periodical/rjxb201505005 [16] Besse P C, Guillouet B, Loubes J M, Royer F. Destination prediction by trajectory distribution based model. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(8):2470-2481 doi: 10.1109/TITS.2017.2749413 [17] Willard K E, Connelly D P. Nonparametric probability density estimation:improvements to the histogram for laboratory data. Computers and Biomedical Research, 1992, 25(1):17-28 https://linkinghub.elsevier.com/retrieve/pii/0010480992900326 [18] 王星, 褚挺进.非参数统计(第2版).北京:清华大学出版社, 2014. 361.Wang Xing, Chu Ting-Jin. Non-parametric Statistics (2nd Edition). Beijing:Tsinghua press, 2014. 361 [19] Yuan J, Zheng Y, Xie X, Sun G Z. Driving with knowledge from the physical world. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2011. 316-324 [20] Ferrer G, Sanfeliu A. Bayesian human motion intentionality prediction in urban environments. Pattern Recognition Letters, 2014, 44:134-140 doi: 10.1016/j.patrec.2013.08.013 [21] Bui D T, Tuan T A, Klempe H, Pradhan B, Revhaug I. Spatial prediction models for shallow landslide hazards:a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides, 2016, 13(2):361-378 doi: 10.1007/s10346-015-0557-6 -

 下载:
下载:



图(9) / 表(2)
计量
- 文章访问数: 3449
- HTML全文浏览量: 463
- PDF下载量: 494
- 被引次数: 0
