

Adaptive RBF Neural Network Based Backsteppting Control for Supercavitating Vehicles
-
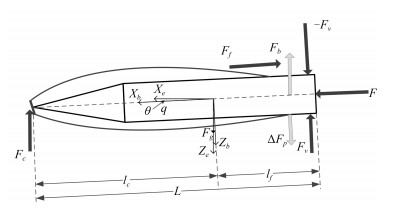
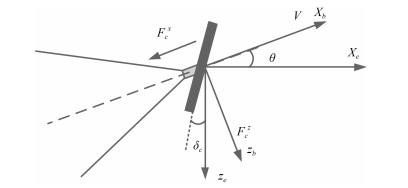
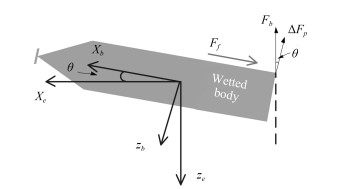
摘要: 针对超空泡航行体姿轨控制普遍存在的模型不确定性问题进行相关研究.为此, 首先对其动力学特性进行分析, 并建立了超空泡航行体的动力学名义模型, 随后将其改写为不确定反馈系统, 然后利用反演控制方法设计超空泡航行体姿轨控制器, 针对模型中的未知函数利用径向基函数(Radial basis function, RBF)神经网络进行逼近并补偿, 由基于Lyapunov稳定理论设计的自适应方法计算神经网络的权重, 并给出稳定性证明.仿真研究验证了控制器设计的有效性.Abstract: This paper is proposed for the problems of model uncertainty such as the control of supercavitating vehicles. Firstly, the nominal model of supercavitating vehicles is built based on the analysis of the vehicle dynamic characteristics. Then we rewrite it as the uncertainty feedback system, and an orbit and attitude controller is designed via the backstepping control theory. The radial basis function (RBF) neural networks are presented to approximate and compensate the unknown functions, otherwise, the weights of the neural networks are designed by the adaptive method based on the Lyapunov theory, and the stability proof is also proposed. Finally, the simulations prove the effectiveness of the above controllers.
-
Key words:
- Adaptive control /
- radial basis function (RBF) neural network /
- supercavitating vehicles /
- backsteppting control
1) 本文责任编委 倪茂林 -
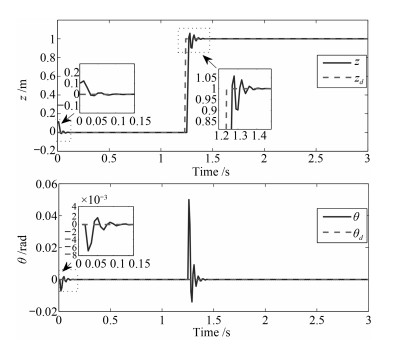
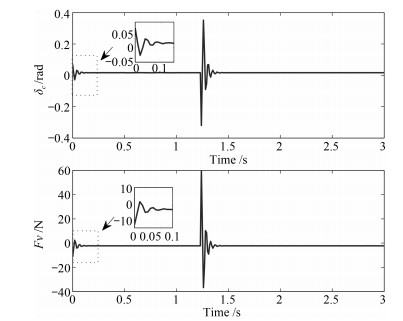
图 7 深度$z$及俯仰角$\theta$设定信号与实际跟踪响应
Fig. 7 Desired trajectory and actual trajectory of $z$ and $\theta$
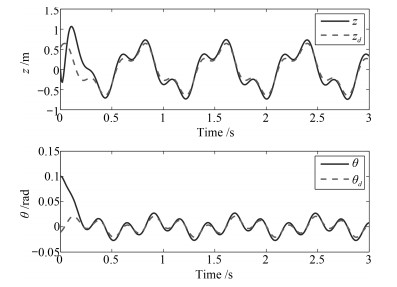
图 10 深度$z$及俯仰角$\theta$设定轨迹与实际跟踪响应
Fig. 10 Desired trajectories and actual trajectories of $z$ and $\theta$
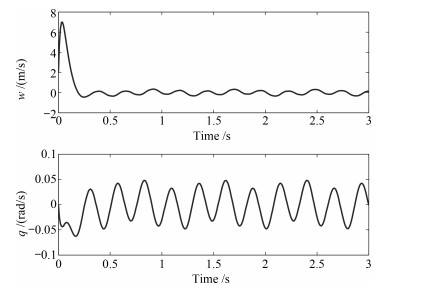
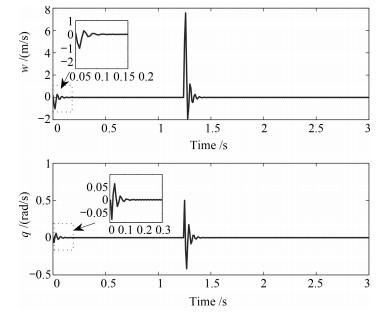
图 11 纵向速度$w$及俯仰角速度$q$状态响应
Fig. 11 Longitudinal velocity $w$ and Pitching angular velocity $q$ responses
-
[1] Kirschner I N, Kring D C, Stokes A W, Fine N E, Uhlman Jr J S. Control strategies for supercavitating vehicles. Journal of Vibration and Control, 2002, 8(2): 219-242 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_f7aa13c4006388f458982fd8c3d1525b [2] Savchenko Y N. Investigation of high speed supercavitating underwater motion of bodies, High-speed motion in water, AGARD Report 827, 20-1-20-12, NASA 19980020552. NASA, USA, 1998. [3] Vanek B, Bokor J, Balas G. High-speed supercavitation vehicle control. In: Proceedings of AIAA Guidance, Navigation, and Control Conference and Exhibit. Keystone, CO, USA: AIAA, 2006. [4] Dzielski J, Kurdila A. A benchmark control problem for supercavitating vehicles and an initial investigation of solutions. Journal of Vibration and Control, 2003, 9(7): 791- 804 doi: 10.1177/1077546303009007004 [5] Mao X F, Wang Q. Nonlinear control design for a supercavitating vehicle. IEEE Transactions on Control Systems Technology, 2009, 17(4): 816-832 doi: 10.1109/TCST.2009.2013338 [6] Mao X F, Wang Q. Adaptive control design for a supercavitating vehicle model based on fin force parameter estimation. Journal of Vibration and Control, 2015, 21(6): 1220-1233 doi: 10.1177/1077546313496263 [7] Li D J, Luo K, Huang C, Dang J J, Zhang Y W. Dynamics model and control of high-speed supercavitating vehicles incorporated with time-delay. International Journal of Nonlinear Sciences and Numerical Simulation, 2014, 15(3-4): 221-230 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ijnsns-2013-0063 [8] Kawakami E, Arndt R E A. Investigation of the behavior of ventilated supercavities. Journal of Fluids Engineering, 2011, 133(9): Article No.091305 [9] Sanabria D E, Balas G, Arndt R. Modeling, control, and experimental validation of a high-speed supercavitating vehicle. IEEE Journal of Oceanic Engineering, 2015, 40(2): 362-373 doi: 10.1109/JOE.2014.2312591 [10] Yuan X L, Xing T. Hydrodynamic characteristics of a supercavitating vehicle's aft body. Ocean Engineering, 2016, 114: 37-46 doi: 10.1016/j.oceaneng.2016.01.012 [11] Kim S, Kim N. Neural network-based adaptive control for a supercavitating vehicle in transition phase. Journal of Marine Science and Technology, 2015, 20(3): 454-466 doi: 10.1007/s00773-014-0298-6 [12] Liu J K. Radial Basis Function (RBF) Neural Network Control for Mechanical Systems: Design, Analysis and Matlab Simulation. Berlin Heidelberg: Springer, 2013. [13] Park B S, Kwon J W, Kim H. Neural network-based output feedback control for reference tracking of underactuated surface vessels. Automatica, 2017, 77: 353-359 doi: 10.1016/j.automatica.2016.11.024 [14] Wang T, Gao H J, Qiu J B. A combined adaptive neural network and nonlinear model predictive control for multirate networked industrial process control. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(2): 416-425 doi: 10.1109/TNNLS.2015.2411671 [15] He W, Chen Y H, Yin Z. Adaptive neural network control of an uncertain robot with full-state constraints. IEEE Transactions on Cybernetics, 2016, 46(3): 620-629 doi: 10.1109/TCYB.2015.2411285 [16] Sun C Y, He W, Ge W L, Chang C. Adaptive neural network control of biped robots. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(2): 315-326 [17] Sun T R, Pei H L, Pan Y P, Zhou H B, Zhang C H. Neural network-based sliding mode adaptive control for robot manipulators. Neurocomputing, 2011, 74(14-15): 2377-2384 doi: 10.1016/j.neucom.2011.03.015 [18] Liu D R, Wang D, Zhao D B, Wei Q L, Jin N. Neural-network-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming. IEEE Transactions on Automation Science and Engineering, 2012, 9(3): 628-634 doi: 10.1109/TASE.2012.2198057 [19] Li Y H, Qiang S, Zhuang X Y, Kaynak O. Robust and adaptive backstepping control for nonlinear systems using RBF neural networks. IEEE Transactions on Neural Networks, 2004, 15(3): 693-701 doi: 10.1109/TNN.2004.826215 [20] Kwan C, Lewis F L. Robust backstepping control of nonlinear systems using neural networks. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2000, 30(6): 753-766 doi: 10.1109/3468.895898 [21] Zhang T, Ge S S, Hang C C. Adaptive neural network control for strict-feedback nonlinear systems using backstepping design. Automatica, 2000, 36(12): 1835-1846 doi: 10.1016/S0005-1098(00)00116-3 [22] Peng X G, Wu Y P. Large-scale cooperative co-evolution using niching-based multi-modal optimization and adaptive fast clustering. Swarm and Evolutionary Computation, 2017, 35: 65-77 doi: 10.1016/j.swevo.2017.03.001 [23] Vanek B, Bokor J, Balas G J, Arndt R E A. Longitudinal motion control of a high-speed supercavitation vehicle. Journal of Vibration and Control, 2007, 13(2): 159-184 doi: 10.1177/1077546307070226 [24] Peng X G, Liu K, Jin Y C. A dynamic optimization approach to the design of cooperative co-evolutionary algorithms. Knowledge-Based Systems, 2016, 109: 174-186 doi: 10.1016/j.knosys.2016.07.001 -

 下载:
下载:


图(14)
计量
- 文章访问数: 2547
- HTML全文浏览量: 2038
- PDF下载量: 336
- 被引次数: 0
