

Adaptive RBF Neural Network Based Backsteppting Control for Supercavitating Vehicles
-
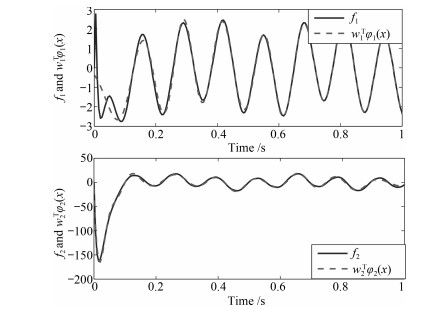
摘要: 针对超空泡航行体姿轨控制普遍存在的模型不确定性问题进行相关研究.为此, 首先对其动力学特性进行分析, 并建立了超空泡航行体的动力学名义模型, 随后将其改写为不确定反馈系统, 然后利用反演控制方法设计超空泡航行体姿轨控制器, 针对模型中的未知函数利用径向基函数(Radial basis function, RBF)神经网络进行逼近并补偿, 由基于Lyapunov稳定理论设计的自适应方法计算神经网络的权重, 并给出稳定性证明.仿真研究验证了控制器设计的有效性.Abstract: This paper is proposed for the problems of model uncertainty such as the control of supercavitating vehicles. Firstly, the nominal model of supercavitating vehicles is built based on the analysis of the vehicle dynamic characteristics. Then we rewrite it as the uncertainty feedback system, and an orbit and attitude controller is designed via the backstepping control theory. The radial basis function (RBF) neural networks are presented to approximate and compensate the unknown functions, otherwise, the weights of the neural networks are designed by the adaptive method based on the Lyapunov theory, and the stability proof is also proposed. Finally, the simulations prove the effectiveness of the above controllers.
-
Key words:
- Adaptive control /
- radial basis function (RBF) neural network /
- supercavitating vehicles /
- backsteppting control
-
-
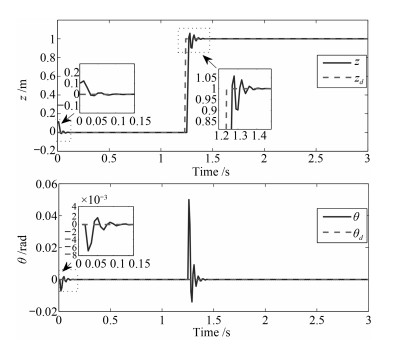
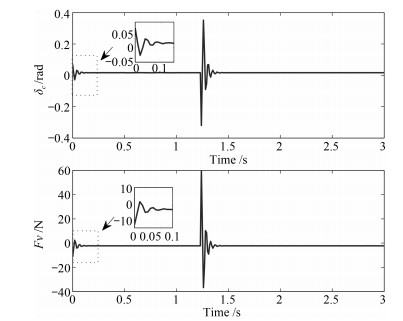
图 7 深度$z$及俯仰角$\theta$设定信号与实际跟踪响应
Fig. 7 Desired trajectory and actual trajectory of $z$ and $\theta$
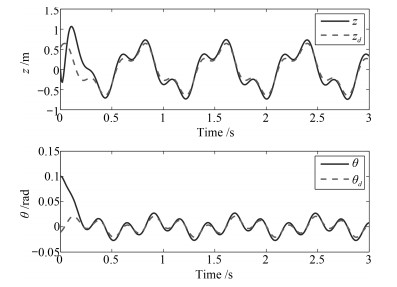
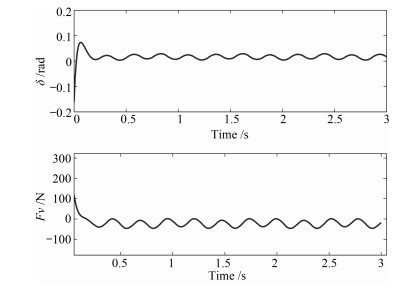
图 10 深度$z$及俯仰角$\theta$设定轨迹与实际跟踪响应
Fig. 10 Desired trajectories and actual trajectories of $z$ and $\theta$
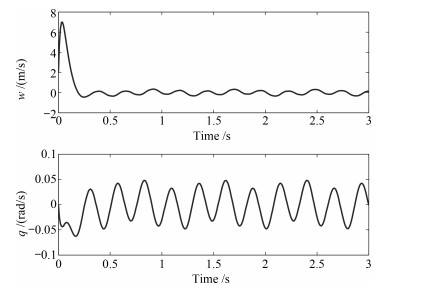
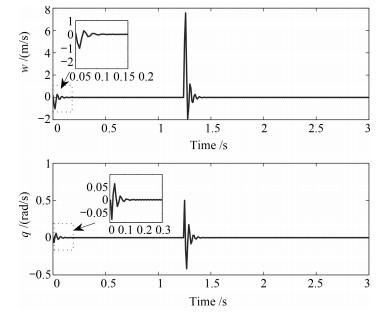
图 11 纵向速度$w$及俯仰角速度$q$状态响应
Fig. 11 Longitudinal velocity $w$ and Pitching angular velocity $q$ responses
-
[1] Kirschner I N, Kring D C, Stokes A W, Fine N E, Uhlman Jr J S. Control strategies for supercavitating vehicles. Journal of Vibration and Control, 2002, 8(2): 219-242 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_f7aa13c4006388f458982fd8c3d1525b [2] Savchenko Y N. Investigation of high speed supercavitating underwater motion of bodies, High-speed motion in water, AGARD Report 827, 20-1-20-12, NASA 19980020552. NASA, USA, 1998. [3] Vanek B, Bokor J, Balas G. High-speed supercavitation vehicle control. In: Proceedings of AIAA Guidance, Navigation, and Control Conference and Exhibit. Keystone, CO, USA: AIAA, 2006. [4] Dzielski J, Kurdila A. A benchmark control problem for supercavitating vehicles and an initial investigation of solutions. Journal of Vibration and Control, 2003, 9(7): 791- 804 doi: 10.1177/1077546303009007004 [5] Mao X F, Wang Q. Nonlinear control design for a supercavitating vehicle. IEEE Transactions on Control Systems Technology, 2009, 17(4): 816-832 doi: 10.1109/TCST.2009.2013338 [6] Mao X F, Wang Q. Adaptive control design for a supercavitating vehicle model based on fin force parameter estimation. Journal of Vibration and Control, 2015, 21(6): 1220-1233 doi: 10.1177/1077546313496263 [7] Li D J, Luo K, Huang C, Dang J J, Zhang Y W. Dynamics model and control of high-speed supercavitating vehicles incorporated with time-delay. International Journal of Nonlinear Sciences and Numerical Simulation, 2014, 15(3-4): 221-230 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ijnsns-2013-0063 [8] Kawakami E, Arndt R E A. Investigation of the behavior of ventilated supercavities. Journal of Fluids Engineering, 2011, 133(9): Article No.091305 [9] Sanabria D E, Balas G, Arndt R. Modeling, control, and experimental validation of a high-speed supercavitating vehicle. IEEE Journal of Oceanic Engineering, 2015, 40(2): 362-373 doi: 10.1109/JOE.2014.2312591 [10] Yuan X L, Xing T. Hydrodynamic characteristics of a supercavitating vehicle's aft body. Ocean Engineering, 2016, 114: 37-46 doi: 10.1016/j.oceaneng.2016.01.012 [11] Kim S, Kim N. Neural network-based adaptive control for a supercavitating vehicle in transition phase. Journal of Marine Science and Technology, 2015, 20(3): 454-466 doi: 10.1007/s00773-014-0298-6 [12] Liu J K. Radial Basis Function (RBF) Neural Network Control for Mechanical Systems: Design, Analysis and Matlab Simulation. Berlin Heidelberg: Springer, 2013. [13] Park B S, Kwon J W, Kim H. Neural network-based output feedback control for reference tracking of underactuated surface vessels. Automatica, 2017, 77: 353-359 doi: 10.1016/j.automatica.2016.11.024 [14] Wang T, Gao H J, Qiu J B. A combined adaptive neural network and nonlinear model predictive control for multirate networked industrial process control. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(2): 416-425 doi: 10.1109/TNNLS.2015.2411671 [15] He W, Chen Y H, Yin Z. Adaptive neural network control of an uncertain robot with full-state constraints. IEEE Transactions on Cybernetics, 2016, 46(3): 620-629 doi: 10.1109/TCYB.2015.2411285 [16] Sun C Y, He W, Ge W L, Chang C. Adaptive neural network control of biped robots. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(2): 315-326 [17] Sun T R, Pei H L, Pan Y P, Zhou H B, Zhang C H. Neural network-based sliding mode adaptive control for robot manipulators. Neurocomputing, 2011, 74(14-15): 2377-2384 doi: 10.1016/j.neucom.2011.03.015 [18] Liu D R, Wang D, Zhao D B, Wei Q L, Jin N. Neural-network-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming. IEEE Transactions on Automation Science and Engineering, 2012, 9(3): 628-634 doi: 10.1109/TASE.2012.2198057 [19] Li Y H, Qiang S, Zhuang X Y, Kaynak O. Robust and adaptive backstepping control for nonlinear systems using RBF neural networks. IEEE Transactions on Neural Networks, 2004, 15(3): 693-701 doi: 10.1109/TNN.2004.826215 [20] Kwan C, Lewis F L. Robust backstepping control of nonlinear systems using neural networks. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2000, 30(6): 753-766 doi: 10.1109/3468.895898 [21] Zhang T, Ge S S, Hang C C. Adaptive neural network control for strict-feedback nonlinear systems using backstepping design. Automatica, 2000, 36(12): 1835-1846 doi: 10.1016/S0005-1098(00)00116-3 [22] Peng X G, Wu Y P. Large-scale cooperative co-evolution using niching-based multi-modal optimization and adaptive fast clustering. Swarm and Evolutionary Computation, 2017, 35: 65-77 doi: 10.1016/j.swevo.2017.03.001 [23] Vanek B, Bokor J, Balas G J, Arndt R E A. Longitudinal motion control of a high-speed supercavitation vehicle. Journal of Vibration and Control, 2007, 13(2): 159-184 doi: 10.1177/1077546307070226 [24] Peng X G, Liu K, Jin Y C. A dynamic optimization approach to the design of cooperative co-evolutionary algorithms. Knowledge-Based Systems, 2016, 109: 174-186 doi: 10.1016/j.knosys.2016.07.001 期刊类型引用(29)
1. 李倩,聂简,黄鸿殿,孔庆宇,奔粤阳. 基于大脑海马认知机理的主从式AUV协同定位方法. 中国惯性技术学报. 2024(01): 27-33 .  百度学术
百度学术2. 游雄,李科,田江鹏,杨剑,余岸竹,贾奋励. 机器地图信息加工模型. 武汉大学学报(信息科学版). 2024(04): 516-526 . 百度学术3. 高昊,王仁茂. 基于类脑仿生的环境感知技术. 舰船电子对抗. 2024(05): 42-46+55 . 百度学术4. 陈荟慧,钟委钊. 基于人机协作的高质量城市图像采集方法. 应用科学学报. 2023(05): 801-814 . 百度学术5. 朱祥维,沈丹,肖凯,马岳鑫,廖祥,古富强,余芳文,高柯夫,刘经南. 类脑导航的机理、算法、实现与展望. 航空学报. 2023(19): 6-38 . 百度学术6. 于乃功,廖诣深. 基于鼠脑内嗅—海马认知机制的移动机器人空间定位模型. 生物医学工程学杂志. 2022(02): 217-227 . 百度学术7. 刘溢,阳加远,张驰. 一种基于RTX的移动机器人实时控制平台. 电子技术与软件工程. 2022(08): 169-172 . 百度学术8. 于子航,王改云. 基于路径积分强化的机器人目标导向运动控制. 计算机仿真. 2022(07): 412-415+516 . 百度学术9. 董卫华,刘毅龙,黑巧松,杨天宇. 泛地图空间认知理论与方法研究框架. 武汉大学学报(信息科学版). 2022(12): 2007-2014 . 百度学术10. 阮晓钢,李鹏,朱晓庆,刘鹏飞. 基于目标导向行为和空间拓扑记忆的视觉导航方法. 计算机学报. 2021(03): 594-608 . 百度学术11. 赵辰豪,吴德伟,韩昆,代传金. 无环境信息下多尺度网格细胞群空间表征模型. 系统工程与电子技术. 2021(03): 814-822 . 百度学术12. 阮晓钢,柴洁,武悦,张晓平,黄静. 基于海马体位置细胞的认知地图构建与导航. 自动化学报. 2021(03): 666-677 . 本站查看13. 冀俊忠,刘金铎,邹爱笑,杨翠翠. 一种融合多源信息的脑效应连接网络蚁群学习算法. 自动化学报. 2021(04): 864-881 . 本站查看14. 万刚,武易天. 地图空间认知的数学基础. 测绘学报. 2021(06): 726-738 . 百度学术15. 洪涛,史涛,任红格. 一种改进型RatSLAM算法构建认知地图的研究. 现代计算机. 2021(21): 47-52 . 百度学术16. 韩昆,吴德伟,来磊. 类脑导航中基于差分Hebbian学习的网格细胞构建模型. 系统工程与电子技术. 2020(03): 674-679 . 百度学术17. 黄宜庆,王正刚,王徽,葛愿. 基于边缘梯度算法的多移动机器人协作地图构建. 信息与控制. 2020(01): 62-68 . 百度学术18. 于乃功,廖诣深,郑相国. 一种基于海马位置细胞选择机制的空间认知模型. 生物医学工程学杂志. 2020(01): 27-37 . 百度学术19. 胡小平,毛军,范晨,张礼廉,何晓峰,韩国良,范颖. 仿生导航技术综述. 导航定位与授时. 2020(04): 1-10 . 百度学术20. 于乃功,冯慧,廖诣深,郑相国. 一种基于感知速度与感知角度的网格野计算模型. 生物医学工程学杂志. 2020(05): 863-874 . 百度学术21. 晁丽君,熊智,杨闯,华冰,王雅婷,刘建业. 无人飞行器三维类脑SLAM自主导航方法. 飞控与探测. 2020(05): 35-43 . 百度学术22. 张孝伍. 图上的概率分布及位置方向信息的表征方法. 青岛理工大学学报. 2019(01): 113-121 . 百度学术23. 方略,何洪军. 基于鼠脑海马位置细胞与Q学习面向目标导航. 生物信息学. 2019(01): 31-38 . 百度学术24. 王均,凌有铸,王静. 基于特征融合的仿生SLAM算法研究. 安徽工程大学学报. 2019(02): 26-33 . 百度学术25. 刘建业,杨闯,熊智,赖际舟,熊骏. 无人机类脑吸引子神经网络导航技术. 导航定位与授时. 2019(05): 52-60 . 百度学术26. 韩昆,吴德伟,来磊,杨林. 自主导航条件下网格细胞放电模型. 电子科技大学学报. 2019(05): 711-716 . 百度学术27. 丛明,邹强,刘冬,杜宇. 定位细胞认知机理启发的机器人导航研究综述. 机械工程学报. 2019(23): 1-12 . 百度学术28. 邹强,丛明,刘冬,杜宇. 仿鼠脑海马的机器人地图构建与路径规划方法. 华中科技大学学报(自然科学版). 2018(12): 83-88 . 百度学术29. 吴德伟,何晶,韩昆,李卉. 无人作战平台认知导航及其类脑实现思想. 空军工程大学学报(自然科学版). 2018(06): 33-38 . 百度学术其他类型引用(29)
-

 下载:
下载:

图(14)
计量
- 文章访问数: 2379
- HTML全文浏览量: 1915
- PDF下载量: 333
- 被引次数: 58
