

A Parallel Multiple Minor Components Extraction Algorithm and Its Convergence Analysis
-
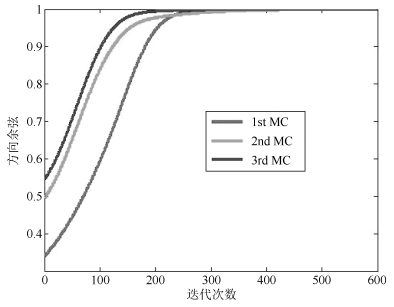
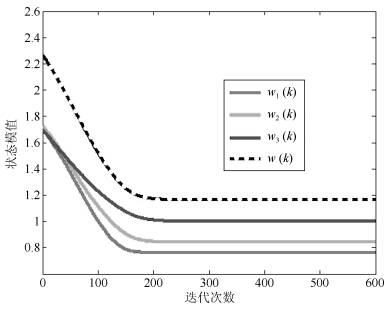
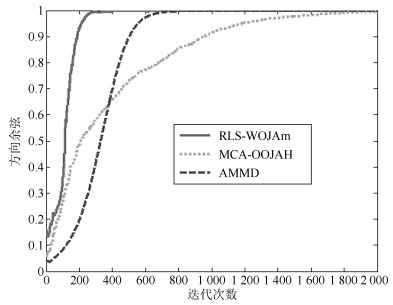
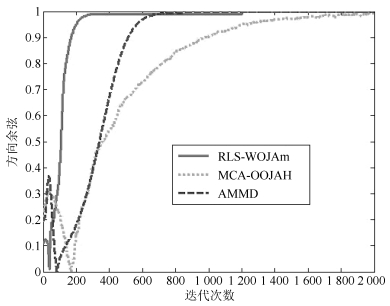
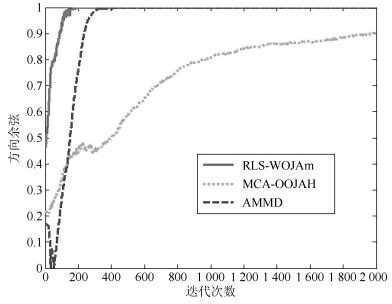
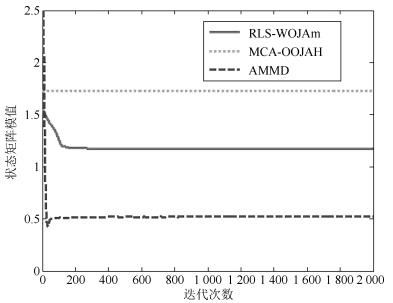
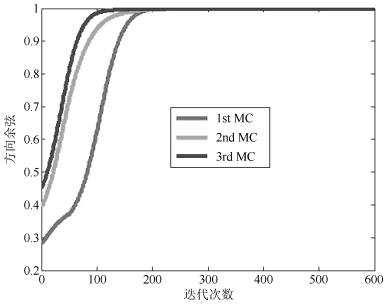
摘要: 次成分分析是信号处理领域内一项重要的分析工具.目前,多维次成分并行提取算法数量稀少,而且现有的算法在应用时还存在很多限制条件.针对上述问题,在分析研究OJAm次子空间跟踪算法的基础上,采用加权矩阵法提出了一种多维次成分提取算法,并采用递归最小二乘法对所提算法进行了简化,最后采用李雅普诺夫函数法确定了所提算法的全局收敛域.相比现有算法,所提算法对信号的特征值大小没有要求,也不需要在迭代过程中进行模值归一化操作,同时算法具有较低的计算复杂度.仿真实验表明:所提算法能够并行提取多维次成分,而且收敛速度要优于现有同类型算法.Abstract: Minor component analysis is a powerful tool in the field of signal processing. Up to now, there are few algorithms that can extract multiple minor components in parallel. Some existing algorithms have some limitations for real applications. In order to solve these problems, a novel multiple minor components extraction algorithm is proposed by introduing the weighted matrix method into the OJAm minor subspace algorithm. A recursive least square (RLS) algorithm is also derived based on the proposed algorithm. The global convergence region of the proposed algorithm is obtained by using the Lyapunov function method. Compared with some existing algorithms, the proposed algorithm has no restriction on the values of eigenvalue and does not need normalization operation during iterations. Its computation complexity is less than those of some counterparts. Simulation results show that the proposed algorithm can adaptively extract multiple minor components from input signals in parallel and has faster convergence speed than some same-type algorithms.1) 本文责任编委 王占山
-
[1] Thameri M, Abed-Meraim K, Belouchrani A. Low complexity adaptive algorithms for Principal and Minor Component Analysis. Digital Signal Processing, 2013, 23(1):19-29 doi: 10.1016/j.dsp.2012.09.007 [2] Arjomandi-Lari M, Karimi M. Generalized YAST algorithm for signal subspace tracking. Signal Processing, 2015, 117:82-95 doi: 10.1016/j.sigpro.2015.04.025 [3] Jou Y D, Sun C M, Chen F K. Eigenfilter design of FIR digital filters using minor component analysis. In:9th International Conference on Information, Communications and Signal Processing. Tainan, China:IEEE, 2013. 1-5 [4] Pattanadech N, Yutthagowith P. Fast curve fitting algorithm for parameter evaluation in lightning impulse test technique. IEEE Transactions on Dielectrics and Electrical Insulation, 2015, 22(5):2931-2936 doi: 10.1109/TDEI.2015.005165 [5] Cirrincione G, Cirrincione M. Neural-Based Orthogonal Data Fitting:The EXIN Neural Networks. New York, USA:John Wiley and Sons, 2011 [6] Kong X Y, Hu C H, Duan Z S. Neural networks for principal component analysis. Principal Component Analysis Networks and Algorithms. Singapore:Springer, 2017. 47-73 [7] 高迎彬, 孔祥玉, 胡昌华, 侯立安.并行提取多个次成分的改进型Möller算法.控制与决策, 2017, 32 (3):493-497 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201703015Gao Ying-Bin, Kong Xiang-Yu, Hu Chang-Hua, Hou Li-An. Modified Möller algorithm for multiple minor components extraction. Control and Decision, 2017, 32(3):493-497 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201703015 [8] Oja E. Principal components, minor components, and linear neural networks. Neural Networks, 1992, 5(6):927-935 doi: 10.1016/S0893-6080(05)80089-9 [9] Mathew G, Reddy V U. Orthogonal eigensubspace estimation using neural networks. IEEE Transactions on Signal Processing, 1994, 42(7):1803-1811 doi: 10.1109/78.298287 [10] Jankovic M V, Reljin B. A new minor component analysis method based on Douglas-Kung-Amari minor subspace analysis method. IEEE Signal Processing Letters, 2005, 12(12):859-862 doi: 10.1109/LSP.2005.859497 [11] Tan K K, Lv J C, Zhang Y, Huang S N. Adaptive multiple minor directions extraction in parallel using a PCA neural network. Theoretical Computer Science, 2010, 411 48:4200-4215 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=7df63e683cd19c7aad37b172b356a6e9 [12] Bartelmaos S, Abed-Meraim K. Fast adaptive algorithms for minor component analysis using Householder transformation. Digital Signal Processing, 2011, 21(6):667-678 doi: 10.1016/j.dsp.2011.05.001 [13] Feng D Z, Zheng W X, Jia Y. Neural network learning algorithms for tracking minor subspace in high-dimensional data stream. IEEE Transactions on Neural Networks, 2005, 16(3):513-521 doi: 10.1109/TNN.2005.844854 [14] Nguyen T D, Takahashi N, Yamada I. An adaptive extraction of generalized eigensubspace by using exact nested orthogonal complement structure. Multidimensional Systems and Signal Processing, 2013, 24(3):457-483 doi: 10.1007/s11045-012-0172-9 [15] Yang B. Projection approximation subspace tracking. IEEE Transactions on Signal Processing, 1995, 43(1):95-107 doi: 10.1109/78.365290 [16] Gao Y B, Kong X Y, Hu C H, Li H Z, Hou L A. A generalized information criterion for generalized minor component extraction. IEEE Transactions on Signal Processing, 2017, 65(4):947-959 doi: 10.1109/TSP.2016.2631444 [17] Nguyen T D, Yamada I. Adaptive normalized quasi-newton algorithms for extraction of generalized Eigen-Pairs and their convergence analysis. IEEE Transactions on Signal Processing, 2013, 61(6):1404-1418 doi: 10.1109/TSP.2012.2234744 [18] Lewis D W. Matrix Theory. Singapore:World Scientific, 2012 [19] Miao Y, Hua Y. Fast subspace tracking and neural network learning by a novel information criterion. IEEE Transactions on Signal Processing, 1998, 46(7):1967-1979 doi: 10.1109/78.700968 [20] Gao Y B, Kong X Y, Hu C H, Zhang H H, Hou L A. Convergence analysis of Möller algorithm for estimating minor component. Neural Processing Letters, 2014, 42(2):355-368 doi: 10.1007/s11063-014-9360-y [21] Kong X Y, Hu C H, Ma H G, Han C Z. A unified self-stabilizing neural network algorithm for principal and minor components extraction. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(2):185-198 doi: 10.1109/TNNLS.2011.2178564 -

 下载:
下载:


图(8)
计量
- 文章访问数: 1827
- HTML全文浏览量: 226
- PDF下载量: 446
- 被引次数: 0
