

-
摘要: 当前景或背景的灰度分布呈现为非正态分布特征时,比如极值、瑞利、贝塔或均匀分布,将所选阈值与最优阈值之差控制在10个灰度级内并非易事.为了在统一框架内处理不同灰度分布情形下的阈值选择问题,提出了一种归一化互信息量最大化导向的自动阈值选择方法.该方法先采用多尺度梯度乘变换规范化输入图像,获得具有单峰长拖尾灰度分布的规范图像;然后对不同阈值对应的二值图像进行轮廓提取,获得不同的轮廓图像;最后计算规范图像和不同轮廓图像之间的归一化互信息量,并以最大值对应的阈值作为最终阈值.在具有不同灰度分布模式的9幅合成图像和59幅真实世界图像上,将提出的方法和1种人工阈值方法及4种自动阈值方法进行了比较.实验结果表明,提出的方法虽然在计算效率方面不优于4个自动方法,但在分割的适应性和精确度方面优势明显:对前述不同灰度分布情形,其所选阈值与最优阈值之差都在9个灰度级内.Abstract: When the gray level distribution of foreground or background appears a non-normal distribution, such as extreme value, Rayleigh, beta or uniform distribution, it is challenging to keep the difference between the selected threshold and the optimal threshold under control within 10 gray levels. To deal with the issue of threshold selection in different gray level distributions within a unified framework, we propose an automatic method of threshold selection that is guided by maximizing normalized mutual information. Firstly, this method applies a multiscale gradient multiplication to an input image, which produces a normalized image with a single-peaked trailing distribution. Then, the binary images corresponding to different thresholds are subjected to contour extraction to produce different contour images. Finally, normalized mutual information between the normalized image and different contour images is calculated and the threshold corresponding to maximum is taken as the final threshold. The proposed method is compared with a manual thresholding method and 4 automatic ones on 9 synthetic images and 59 real-world ones with different distributions. The results show that the proposed method is not superior to these 4 automatic methods in computational efficiency, but it has a significant advantage in the adaptability and accuracy of segmentation:in the case of the aforementioned different gray level distributions, the differences between its selected thresholds and the optimal ones are all within 9 gray levels.1) 本文责任编委 胡清华
-
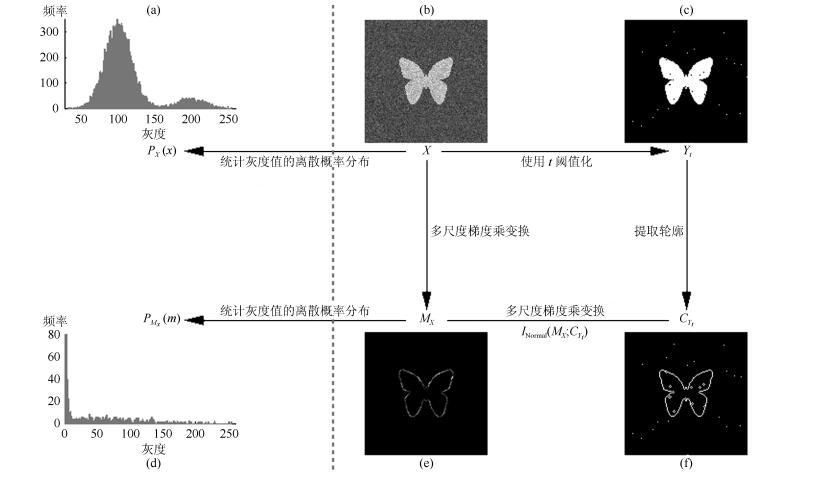
图 1 MNMI方法所涉及的关键概念和步骤的图示((a)原始图像$X$的灰度直方图; (b)原始图像$X$; (c)使用$t$阈值化原始图像$X$所得的二值图像${{Y}_{t}}$; (d)对原始图像$X$进行多尺度梯度乘变换后所得图像${{M}_{X}}$的灰度直方图; (e)图像${{M}_{X}}$; (f)从二值图像${{Y}_{t}}$中提取轮廓后所得轮廓图像${{C}_{{{Y}_{t}}}}$.注意, 为了能更清楚地显示灰度区间[0, 255]内灰度值出现的频率, (d)中灰度直方图在频率为80处进行了截断.)
Fig. 1 Graphic illustration of crucial concepts and steps in MNMI method ((a) Gray level histogram of original image $X$; (b) original image $X$; (c) binary image ${{Y}_{t}}$ obtained by thresholding original image $X$ with a gray level $t$; (d) gray level histogram of image ${{M}_{X}}$ produced by applying a multiscale gradient multiplication transformation to original image $X$; (e) image ${{M}_{X}}$; (f) contour image ${{C}_{{{Y}_{t}}}}$ extracted from binary image ${{Y}_{t}}$. The gray level histogram in (d) is truncated at the frequency 80 for more clearly showing the frequency of gray level in the range [0, 255].)
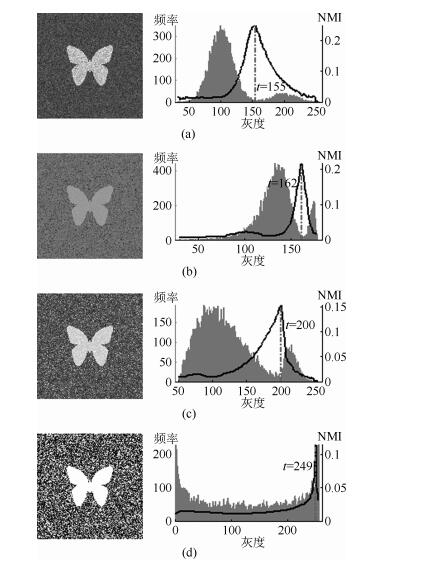
图 2 灰度直方图呈现出双峰特征的4幅合成图像.每幅子图的左边显示了合成图像, 右边显示了对应的灰度直方图, 黑色曲线显示了提出的MNMI方法计算阈值的目标函数曲线, 虚线及旁边的数字标示了MNMI方法计算出的阈值(下同) ((a)正态分布情形; (b)极值分布情形; (c)瑞利分布情形; (d)贝塔分布情形)
Fig. 2 4 synthetic images with bimodal gray level histogram. In each sub-figure, a synthetic image is shown on the left; on the right, the gray level histogram is shown, the objective function of MNMI method is illustrated with a black curve, and the threshold obtained by MNMI method is indicated with a dashed line and a number (the same below) ((a) Normal distribution, (b) Extreme value distribution, (c) Rayleigh distribution, (d) Beta distribution)

图 3 灰度直方图呈现出单峰特征的3幅合成图像((a)正态分布情形; (b)极值分布情形; (c)瑞利分布情形)
Fig. 3 3 synthetic images with unimodal gray level histogram ((a) Normal distribution, (b) extreme value distribution, (c) Rayleigh distribution)

图 4 灰度直方图呈现出无峰特征的合成图像
Fig. 4 A synthetic image with a uniform distribution of gray level

图 5 灰度直方图呈现出多峰特征的合成图像 (灰度直方图的灰度区间[0, 50]由瑞利分布和均匀分布组合而成, 区间[51, 100]为均匀分布,区间[101, 150]由极值分布和均匀分布组合而成, 区间[151, 200]由贝塔分布和正态分布组合而成,区间[201, 255]为正态分布)
Fig. 5 A synthetic image with multimodal gray level histogram (The gray level histogram in the range [0, 50] is combined by a Rayleigh distribution and a uniform distribution, [51, 100] by a uniform distribution, [101, 150] by an extreme value distribution and a uniform distribution, [151, 200] by a beta distribution and a normal distribution, and [201, 255] by a normal distribution.)

图 6 6个阈值方法在59幅真实世界图像上分割精度的量化比较(在每幅子图中, 各条水平虚线标示了对应情形下ME值的平均值)
Fig. 6 Quantification comparisons of segmentation accuracy for 6 thresholding methods on 59 real-world images (In each sub-figure, each horizontal dashed lines indicate the corresponding average ME, respectively)
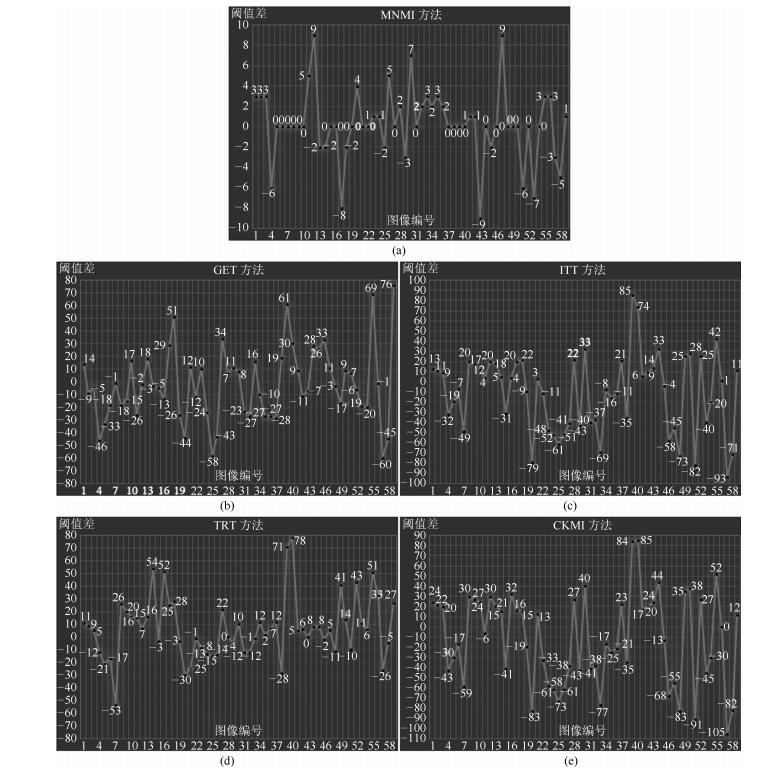
图 7 对59幅真实世界图像, MNMI, GET, ITT, TRT, CKMI方法和IT方法获得的阈值之差(在每幅子图中, 每个黑点旁的数字标示了相应的阈值差)
Fig. 7 The differences between MNMI, GET, ITT, TRT, CKMI and IT methods in segmentation thresholds for 59 real-world images (In each sub-figure, the number beside each black point labels the specific difference of segmentation threshold)
表 1 6个阈值分割方法在灰度直方图呈现出双峰特征的4幅合成图像上的阈值$ t$和ME值
Table 1 Threshold values $t$ and ME values of 6 thresholding methods on 4 synthetic images with bimodal gray level histogram
阈值方法 正态分布$t$, ME (%) 极值分布$t$, ME (%) 瑞利分布$t$, ME (%) 贝塔分布$t$, ME (%) IT 155, 0.18 162, 0.17 201, 1.23 249, 0.20 GET 186, 2.25 144, 16.99 175, 4.17 175, 27.50 ITT 149, 0.33 133, 44.34 142, 16.94 128, 39.16 TRT 150, 0.28 152, 4.33 164, 6.94 174, 27.81 CKMI 139, 1.42 135, 39.36 133, 22.80 124, 40.05 MNMI 155, 0.18 162, 0.17 200, 1.26 249, 0.20  下载: 导出CSV
下载: 导出CSV
表 2 6个阈值分割方法在灰度直方图呈现出单峰特征的3幅合成图像上的阈值$t$和ME值
Table 2 Threshold values $t$ and ME values of 6 thresholding methods on 3 synthetic images with unimodal gray level histogram
阈值方法 正态分布$t$, ME (%) 极值分布$t$, ME (%) 瑞利分布$t$, ME (%) IT 168, 0.03 142, 0.04 120, 0.05 GET 179, 0.14 134, 14.98 93, 14.79 ITT 102, 44.29 122, 63.90 80, 38.00 TRT 146, 0.59 134, 14.98 103, 5.40 CKMI 100, 48.62 126, 48.67 75, 49.70 MNMI 168, 0.03 142, 0.04 120, 0.05
下载: 导出CSV
表 3 6个阈值分割方法在灰度直方图分别呈现出无峰特征和多峰特征的合成图像上的阈值$t$和ME值
Table 3 Threshold values $t$ and ME values of 6 thresholding methods on synthetic images with uniform gray level histogram and multimodal one
阈值方法 均匀分布(无峰)$t$, ME (%) 混合分布(多峰)$t$, ME (%) IT 230, 0.21 204, 0.25 GET 180, 19.71 180, 17.75 ITT 126, 40.61 110, 55.60 TRT 174, 22.24 154, 27.89 CKMI 128, 39.82 108, 55.90 MNMI 230, 0.21 204, 0.25
下载: 导出CSV
表 4 5个自动阈值分割方法的计算效率比较
Table 4 Quantitative comparisons of 5 automatic thresholding methods in computational efficiency
阈值方法 合成图像上耗时(秒) 真实世界图像上耗时(秒) 均值 标准偏差 均值 标准偏差 ITT 0.007 0.002 0.008 0.005 GET 0.039 0.031 0.045 0.028 CKMI 0.081 0.008 0.127 0.073 TRT 0.116 0.061 0.109 0.093 MNMI 0.215 0.068 0.327 0.205
下载: 导出CSV
表 5 不同步长下MNMI方法的计算效率和误分类率
Table 5 Computational efficiency and ME of MNMI method with different steps
步长$\rho $ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 合成图像 平均耗时(秒) 0.215 0.138 0.113 0.103 0.096 0.093 0.090 0.088 0.088 0.087 0.087 0.086 0.088 0.087 0.088 平均ME (%) 0.267 0.267 0.267 0.267 0.267 0.267 0.267 0.319 0.319 0.267 0.267 10.653 0.267 0.267 0.267 真实世界图像 平均耗时(秒) 0.327 0.190 0.147 0.125 0.115 0.108 0.105 0.102 0.104 0.104 0.101 0.101 0.103 0.106 0.108 平均ME (%) 0.371 0.371 0.373 0.371 0.373 0.377 1.038 2.705 0.372 2.001 1.994 3.235 2.113 3.277 3.776
下载: 导出CSV
-
[1] Sezgin M, Sankur B. Survey over image thresholding techniques and quantitative performance evaluation. Journal of Electronic Imaging, 2004, 13(1):146-165 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ028531304/ [2] 范九伦, 任静.基于平方距离的对称共生矩阵阈值法.电子学报, 2011, 39(10):2277-2281 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201110011Fan Jiu-Lun, Ren Jing. Symmetric co-occurrence matrix thresholding method based on square distance. Acta Electronica Sinica, 2011, 39(10):2277-2281 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201110011 [3] 龙建武, 申铉京, 臧慧, 陈海鹏.高斯尺度空间下估计背景的自适应阈值分割算法.自动化学报, 2014, 40(8):1773-1782 http://www.aas.net.cn/CN/abstract/abstract18444.shtmlLong Jian-Wu, Shen Xuan-Jing, Zang Hui, Chen Hai-Peng. An adaptive thresholding algorithm by background estimation in Gaussian scale space. Acta Automatica Sinica, 2014, 40(8):1773-1782 http://www.aas.net.cn/CN/abstract/abstract18444.shtml [4] 吴一全, 孟天亮, 吴诗婳.图像阈值分割方法研究进展20年(1994-2014).数据采集与处理, 2015, 30(1):1-23 http://d.old.wanfangdata.com.cn/Periodical/sjcjycl201501001Wu Yi-Quan, Meng Tian-Liang, Wu Shi-Hua. Research progress of image thresholding methods in recent 20 years (1994-2014). Journal of Data Acquisition & Processing, 2015, 30(1):1-23 http://d.old.wanfangdata.com.cn/Periodical/sjcjycl201501001 [5] 陈海鹏, 申铉京, 龙建武.采用高斯拟合的全局阈值算法阈值优化框架.计算机研究与发展, 2016, 53(4):892-903 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201604015Chen Hai-Peng, Shen Xuan-Jing, Long Jian-Wu. Threshold optimization framework of global thresholding algorithms using Gaussian fitting. Journal of Computer Research and Development, 2016, 53(4):892-903 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201604015 [6] 陶文兵, 金海.一种新的基于图谱理论的图像阈值分割方法.计算机学报, 2007, 30(1):110-119 doi: 10.3321/j.issn:0254-4164.2007.01.013Tao Wen-Bing, Jin Hai. A new image thresholding method based on graph spectral theory. Chinese Journal of Computers, 2007, 30(1):110-119 doi: 10.3321/j.issn:0254-4164.2007.01.013 [7] Zou Y B, Liu H, Zhang Q. Image bilevel thresolding based on stable transition region set. Digital Signal Processing, 2013, 23(1):126-141 doi: 10.1016/j.dsp.2012.08.004 [8] Otsu N. A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics, 1979, 9(1):62-66 doi: 10.1109/TSMC.1979.4310076 [9] Kittler J, Illingworth J. Minimum error thresholding. Pattern Recognition, 1991, 19(1):41-47 http://d.old.wanfangdata.com.cn/Periodical/hwyjggc201403055 [10] Kapur J N, Sahoo P K, Wong A K C. A new method for gray-level picture thresholding using the entropy of the histogram. Computer Vision, Graphics, and Image Processing, 1985, 29(3):273-285 doi: 10.1016/0734-189X(85)90125-2 [11] Li C H, Lee C K. Minimum cross entropy thresholding. Pattern Recognition, 1993, 26(4):617-625 doi: 10.1016/0031-3203(93)90115-D [12] Pal N R, Pal S K. Entropic thresholding. Signal Processing, 1989, 16(2):97-108 doi: 10.1016/0165-1684(89)90090-X [13] de Albuquerque M P, Esquef I A, Gesualdi Mello A R, de Albuquerqueb M P. Image thresholding using Tsallis entropy. Pattern Recognition Letters, 2004, 25(9):1059-1065 doi: 10.1016/j.patrec.2004.03.003 [14] Sahoo P, Wilkins C, Yeager J. Threshold selection using Renyi's entropy. Pattern Recognition, 1997, 30(1):71-84 http://d.old.wanfangdata.com.cn/Periodical/xdkjyc201801015 [15] Nie F Y, Zhang P F, Li J Q, Ding D H. A novel generalized entropy and its application in image thresholding. Signal Processing, 2017, 134:23-34 doi: 10.1016/j.sigpro.2016.11.004 [16] 许向阳, 宋恩民, 金良海. Otsu准则的阈值性质分析.电子学报, 2009, 37(12):2716-2719 doi: 10.3321/j.issn:0372-2112.2009.12.020Xu Xiang-Yang, Song En-Min, Jin Liang-Hai. Characteristic analysis of threshold based on Otsu criterion. Acta Electronica Sinica, 2009, 37(12):2716-2719 doi: 10.3321/j.issn:0372-2112.2009.12.020 [17] Xue J H, Titterington D M. t-test, F-tests and Otsu's methods for image thresholding. IEEE Transactions on Image Processing, 2011, 20(8):2392-2396 doi: 10.1109/TIP.2011.2114358 [18] Xue J H, Titterington D M. Median-based image thresholding. Image and Vision Computing, 2011, 29(9):631-637 doi: 10.1016/j.imavis.2011.06.003 [19] Cai H M, Yang Z, Cao X H, Xia W M, Xu X Y. A new iterative triclass thresholding technique in image segmentation. IEEE Transactions on Image Processing, 2014, 23(3):1038-1046 doi: 10.1109/TIP.2014.2298981 [20] Fan J L, Lei B. A modified valley-emphasis method for automatic thresholding. Pattern Recognition Letters, 2012, 33(6):703-708 doi: 10.1016/j.patrec.2011.12.009 [21] Lin Q Q, Ou C J. Tsallis entropy and the long-range correlation in image thresholding. Signal Processing, 2012, 92(12):2931-2939 doi: 10.1016/j.sigpro.2012.05.025 [22] 章毓晋.图像分割中基于过渡区技术的统计调查.计算机辅助设计与图形学学报, 2015, 27(3):379-387 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201503001Zhang Yu-Jin. A survey on transition region-based techniques for image segmentation. Journal of Computer-Aided Design & Computer Graphics, 2015, 27(3):379-387 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201503001 [23] 闫成新, 桑农, 张天序, 曾坤.基于局部复杂度的图像过渡区提取与分割.红外与毫米波学报, 2005, 24(4):312-316 doi: 10.3321/j.issn:1001-9014.2005.04.017Yan Cheng-Xin, Sang Nong, Zhang Tian-Xu, Zeng Kun. Image transition region extraction and segmentation based on local complexity. Journal of Infrared and Millimeter Waves, 2005, 24(4):312-316 doi: 10.3321/j.issn:1001-9014.2005.04.017 [24] 冯涛, 周祖安, 刘其真.基于局部复杂度的图像过渡区处理研究.中国图象图形学报, 2008, 13(10):1894-1897 doi: 10.11834/jig.20081019Feng Tao, Zhou Zu-An, Liu Qi-Zhen. Analysis of the image transition region processing based on local complexity. Journal of Image and Graphics, 2008, 13(10):1894-1897 doi: 10.11834/jig.20081019 [25] 王彦春, 梁德群, 王演.基于图像模糊熵邻域非一致性的过渡区提取与分割.电子学报, 2008, 36(12):2445-2449 doi: 10.3321/j.issn:0372-2112.2008.12.032Wang Yan-Chun, Liang De-Qun, Wang Yan. Transition region extraction and segmentation based on image fuzzy entropy neighborhood unhomogeneity. Acta Electronica Sinica, 2008, 36(12):2445-2449 doi: 10.3321/j.issn:0372-2112.2008.12.032 [26] 刘健庄, 栗文青.灰度图像的二维Otsu自动阈值分割法.自动化学报, 1993, 19(1):101-105 http://www.aas.net.cn/CN/abstract/abstract14268.shtmlLiu Jian-Zhuang, Li Wen-Qing. The automatic thresholding of gray-level pictures via two-dimensional Otsu method. Acta Automatica Sinica, 1993, 19(1):101-105 http://www.aas.net.cn/CN/abstract/abstract14268.shtml [27] 范九伦, 赵凤.灰度图像的二维Otsu曲线阈值分割法.电子学报, 2007, 35(4):751-755 doi: 10.3321/j.issn:0372-2112.2007.04.029Fan Jiu-Lun, Zhao Feng. Two-dimensional Otsu's curve thresholding segmentation method for gray-level images. Acta Electronica Sinica, 2007, 35(4):751-755 doi: 10.3321/j.issn:0372-2112.2007.04.029 [28] 范九伦, 雷博.灰度图像的二维交叉熵直线型阈值分割法.电子学报, 2009, 37(3):476-480 doi: 10.3321/j.issn:0372-2112.2009.03.009Fan Jiu-Lun, Lei Bo. Two-dimensional cross-entropy linear-type threshold segmentation method for gray-level images. Acta Electronica Sinica, 2009, 37(3):476-480 doi: 10.3321/j.issn:0372-2112.2009.03.009 [29] 范九伦, 雷博.灰度图像最小误差阈值分割法的二维推广.自动化学报, 2009, 35(4):386-393 http://www.aas.net.cn/CN/abstract/abstract13382.shtmlFan Jiu-Lun, Lei Bo. Two-dimensional extension of minimum error threshold segmentation method for gray-level images. Acta Automatica Sinica, 2009, 35(4):386-393 http://www.aas.net.cn/CN/abstract/abstract13382.shtml [30] 吴一全, 张晓杰, 吴诗婳. 2维对称交叉熵图像阈值分割.中国图象图形学报, 2011, 16(8):1393-1401 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201108009Wu Yi-Quan, Zhang Xiao-Jie, Wu Shi-Hua. Two-dimensional symmetric cross-entropy image thresholding. Journal of Image and Graphics, 2011, 16(8):1393-1401 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201108009 [31] 范九伦, 赵凤, 张雪峰.三维Otsu阈值分割方法的递推算法.电子学报, 2007, 35(7):1398-1402 doi: 10.3321/j.issn:0372-2112.2007.07.034Fan Jiu-Lun, Zhao Feng, Zhang Xue-Feng. Recursive algorithm for three-dimensional Otsu's thresholding segmentation method. Acta Electronica Sinica, 2007, 35(7):1398-1402 doi: 10.3321/j.issn:0372-2112.2007.07.034 [32] 申铉京, 龙建武, 陈海鹏, 魏巍.三维直方图重建和降维的Otsu阈值分割算法.电子学报, 2011, 39(5):1108-1114 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201105022Shen Xuan-Jing, Long Jian-Wu, Chen Hai-Peng, Wei Wei. Otsu thresholding algorithm based on rebuilding and dimension reduction of the 3-dimensional histogram. Acta Electronica Sinica, 2011, 39(5):1108-1114 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201105022 [33] 刘金, 金炜东. 3维自适应最小误差阈值分割法.中国图象图形学报, 2013, 18(11):1416-1424 doi: 10.11834/jig.20131104Liu Jin, Jin Wei-Dong. Three-dimensional adaptive minimum error thresholding segmentation algorithm. Journal of Image and Graphics, 2013, 18(11):1416-1424 doi: 10.11834/jig.20131104 [34] 卢振泰, 吕庆文, 陈武凡.基于最大互信息量的图像自动优化分割.中国图象图形学报, 2008, 13(4):658-661 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a200804010Lu Zhen-Tai, Lv Qing-Wen, Chen Wu-Fan. Unsupervised segmentation of medical image based on maximizing mutual information. Journal of Image and Graphics, 2008, 13(4):658-661 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a200804010 [35] Strehl A, Ghosh J. Cluster ensembles——a knowledge reuse framework for combining multiple partitions. The Journal of Machine Learning Research, 2002, 3(3):583-617 [36] Bemis R. Thresholding tool[Online], available: http://cn.mathworks.com/matlabcentral/fileexchange/6770-thresholding-tool, September 1, 2017. -

 下载:
下载:

计量
- 文章访问数: 2615
- HTML全文浏览量: 629
- PDF下载量: 420
- 被引次数: 0
