

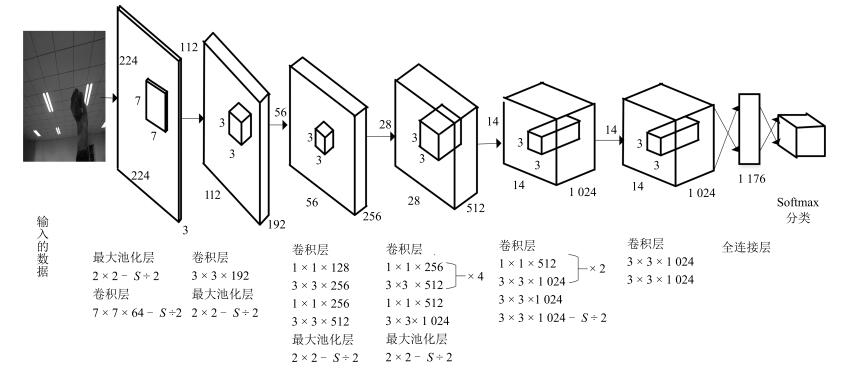
An Improved YOLO Feature Extraction Algorithm and Its Application to Privacy Situation Detection of Social Robots
-
摘要: 为了提高YOLO识别较小目标的能力,解决其在特征提取过程中的信息丢失问题,提出改进的YOLO特征提取算法.将目标检测方法DPM与R-FCN融入到YOLO中,设计一种改进的神经网络结构,包含一个全连接层以及先池化再卷积的特征提取模式以减少特征信息的丢失.然后,设计基于RPN的滑动窗口合并算法,进而形成基于改进YOLO的特征提取算法.搭建服务机器人情境检测平台,给出服务机器人情境检测的总体工作流程.设计家居环境下的六类情境,建立训练数据集、验证数据集和4类测试数据集.测试分析训练步骤与预测概率估计值、学习率与识别准确性之间的关系,找出了适合所提出算法的训练步骤与学习率的经验值.测试结果表明:所提出的算法隐私情境检测准确率为94.48%,有较强的识别鲁棒性.最后,与YOLO算法的比较结果表明,本文算法在识别准确率方面优于YOLO算法.Abstract: To address the limitation of YOLO algorithm in recognizing small objects and information loss during feature extraction, we propose FYOLO, an improved feature extraction algorithm based on YOLO. The algorithm uses a novel neural network structure inspired by the deformable parts model (DPM) and region-based fully convolutional networks (R-FCN). A sliding window merging algorithm based on region proposal networks (RPN) is then combined with the neural network to form the FYOLO algorithm. To evaluate the performance of the proposed algorithm, we develop a social robot platform for privacy situation detection. We consider six types of situations in a smart home and prepare three datasets including training dataset, validation dataset, and test dataset. Experimental parameters such as training step and learning rate are set in terms of their relationships with the prediction accuracy. Extensive privacy situation detection experiments on the social robot show that FYOLO is capable of recognizing privacy situations with an accuracy of 94.48%, indicating the good robustness of our FYOLO algorithm. Finally, the comparison results between FYOLO and YOLO show that the proposed FYOLO outperforms YOLO in recognition accuracy.
-
Key words:
- YOLO /
- feature extraction algorithm /
- social robot /
- detection of privacy situations /
- smart homes
-
-

图 2 不同网格规模下的目标识别效果对比图
Fig. 2 Comparison diagram of object recognition with different grid scale

图 4 情境检测系统的总体工作流程
Fig. 4 The overall flow chart of the privacy situation detection system
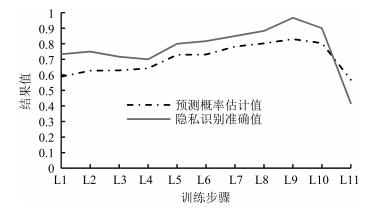
图 6 不同步骤下的模型性能变化趋势
Fig. 6 Variation trends of the proposed model under different steps
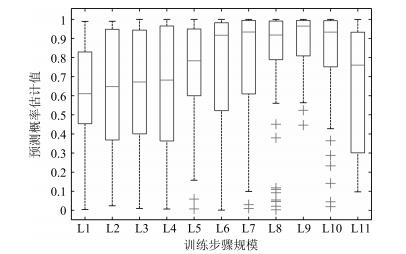
图 7 不同训练步骤下模型的预测概率估计值统计盒图
Fig. 7 Boxplot of prediction accuracy under different training steps
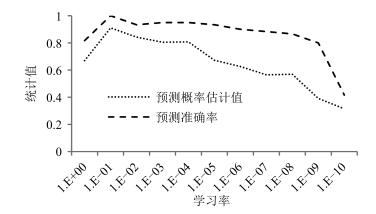
图 8 不同学习率下的模型性能变化趋势
Fig. 8 The trend of model performance under different learning rates
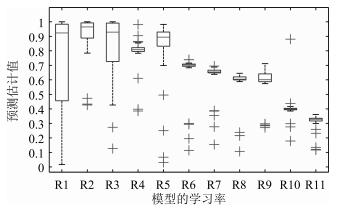
图 9 不同学习率下的预测估计值统计盒图
Fig. 9 Boxplot of prediction accuracy with different learning rates
表 1 不同步骤下的模型性能表现
Table 1 The model performance with different steps
助记符 步骤规模 预测概率估计值均值 识别准确率均值 单图识别时间均值(ms) L1 1 000 0.588 0.733 2.46 L2 2 000 0.627 0.750 2.50 L3 3 000 0.629 0.717 2.51 L4 4 000 0.642 0.700 2.53 L5 5 000 0.729 0.800 2.55 L6 6 000 0.731 0.817 2.52 L7 7 000 0.782 0.850 2.45 L8 8 000 0.803 0.883 2.17 L9 9 000 0.830 0.967 2.16 L10 10 000 0.804 0.900 2.21 L11 20 000 0.569 0.417 2.27  下载: 导出CSV
下载: 导出CSV
表 2 不同学习率下的模型性能统计结果
Table 2 The statistical results of model performance with different learning rates
助记符 学习率 预测概率估计值均值 识别准确率均值 R1 1 0.670 0.817 R2 ${10}^{-1}$ 0.911 1.000 R3 ${10}^{-2}$ 0.843 0.933 R4 ${10}^{-3}$ 0.805 0.950 R5 ${10}^{-4}$ 0.801 0.950 R6 ${10}^{-5}$ 0.672 0.933 R7 ${10}^{-6}$ 0.626 0.900 R8 ${10}^{-7}$ 0.565 0.880 R9 ${10}^{-8}$ 0.569 0.867 R10 ${10}^{-9}$ 0.391 0.800 R11 ${10}^{-10}$ 0.315 0.417
下载: 导出CSV
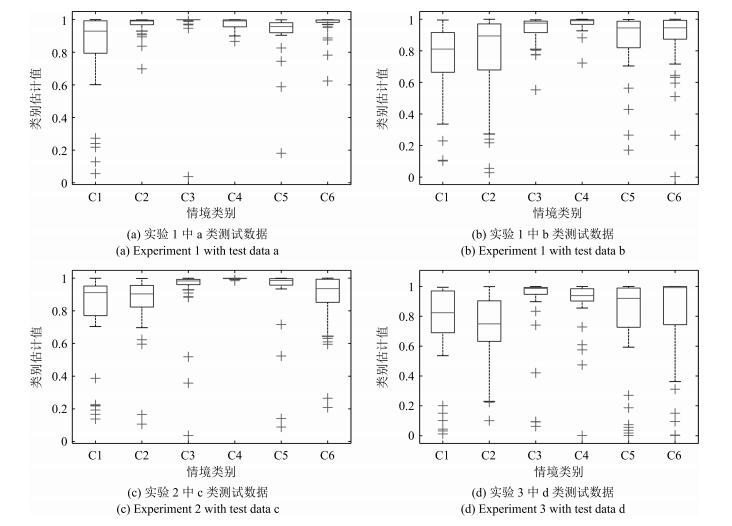
表 3 系统针对不同测试数据集的隐私识别准确率
Table 3 Privacy situation recognition accuracy of the proposed system for different testing data sets
实验 测试数据集 情境识别准确率 C1 C2 C3 C4 C5 C6 实验1 a类测试数据 0.900 0.975 0.975 0.975 1.000 0.975 b类测试数据 0.850 0.950 0.975 0.925 1.000 0.950 实验2 c类测试数据 0.850 0.850 0.950 1.000 1.000 0.925 实验3 d类测试数据 0.850 0.850 0.850 0.900 0.975 0.875
下载: 导出CSV
表 4 系统针对不同测试数据的隐私类别估计值统计表
Table 4 Privacy situation recognition accuracy of the proposed system for different testing data sets
判别估计值 测试数据 C1 C2 C3 C4 C5 C6 均值 方差 均值 方差 均值 方差 均值 方差 均值 方差 均值 方差 a类测试数据 0.820 0.275 0.968 0.006 0.971 0.168 0.972 0.038 0.920 0.141 0.972 0.152 b类测试数据 0.789 0.276 0.849 0.192 0.922 0.096 0.997 0.003 0.918 0.216 0.869 0.191 c类测试数据 0.751 0.359 0.774 0.253 0.937 0.272 0.974 0.047 0.854 0.212 0.864 0.214 d类测试数据 0.742 0.304 0.713 0.274 0.854 0.292 0.890 0.186 0.768 0.332 0.807 0.311 单图识别时间(ms) 3.32 1.62 3.13 2.87 2.69 3.15
下载: 导出CSV
表 5 YOLO算法的隐私识别准确率统计结果
Table 5 Privacy situation recognition accuracy by applying YOLO
实验 测试数据集 情境识别准确率 C1 C2 C3 C4 C5 C6 实验1 a类测试数据 0.750 0.975 0.950 1.000 0.975 0.950 b类测试数据 0.725 0.975 0.875 0.875 0.825 0.750 实验2 c类测试数据 0.625 0.850 0.675 0.675 0.600 0.750 实验3 d类测试数据 0.600 0.600 0.600 0.600 0.600 0.725
下载: 导出CSV
表 6 YOLO算法的隐私类别预测概率估计值统计结果
Table 6 Statistical results of privacy situation estimates by applying YOLO
判别估计值 情境类别 a类测试数据 b类测试数据 c类测试数据 d类测试数据 均值 方差 均值 方差 均值 方差 均值 方差 C1 0.644 0.366 0.568 0.465 0.540 0.381 0.501 0.413 C2 0.939 0.182 0.923 0.149 0.693 0.317 0.305 0.433 C3 0.873 0.244 0.867 0.302 0.866 0.290 0.851 0.313 C4 0.999 0.001 0.963 0.017 0.647 0.439 0.513 0.399 C5 0.972 0.133 0.815 0.228 0.570 0.381 0.568 0.465 C6 0.936 0.223 0.725 0.339 0.674 0.386 0.622 0.345
下载: 导出CSV
-
[1] Shankar K, Camp L J, Connelly K, Huber L L. Aging, privacy, and home-based computing:developing a design framework. IEEE Pervasive Computing, 2012, 11(4):46-54 doi: 10.1109/MPRV.2011.19 [2] Fernandes F E, Yang G C, Do H M, Sheng W H. Detection of privacy-sensitive situations for social robots in smart homes. In: Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE). Fort Worth, TX, USA: IEEE, 2016. 727-732 [3] Arabo A, Brown I, El-Moussa F. Privacy in the age of mobility and smart devices in smart homes. In: Proceedings of the 2012 ASE/IEEE International Conference on and 2012 International Conference on Social Computing (SocialCom) Privacy, Security, Risk and Trust. Amsterdam, Netherlands: IEEE, 2012. 819-826 [4] Kozlov D, Veijalainen J, Ali Y. Security and privacy threats in IoT architectures. In: Proceedings of the 7th International Conference on Body Area Networks. Brussels, Belgium: ICST, 2012. 256-262 [5] Denning T, Matuszek C, Koscher K, Smith J R. A spotlight on security and privacy risks with future household robots: attacks and lessons. In: Proceedings of the 11th International Conference on Ubiquitous Computing. Orlando, USA: ACM, 2009. 105-114 [6] Lee A L, Hill C J, McDonald C F, Holland A E. Pulmonary rehabilitation in individuals with non-cystic fibrosis bronchiectasis:a systematic review. Archives of Physical Medicine and Rehabilitation, 2017, 98(4):774-782 doi: 10.1016/j.apmr.2016.05.017 [7] 刘凯, 张立民, 范晓磊.改进卷积玻尔兹曼机的图像特征深度提取.哈尔滨工业大学学报, 2016, 48(5):155-159 http://d.old.wanfangdata.com.cn/Periodical/hebgydxxb201605026Liu Kai, Zhang Li-Min, Fan Xiao-Lei. New image deep feature extraction based on improved CRBM. Journal of Harbin Institute of Technology, 2016, 48(5):155-159 http://d.old.wanfangdata.com.cn/Periodical/hebgydxxb201605026 [8] Lee H, Grosse R, Ranganath R, Ng A Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In: Proceedings of the 26th Annual International Conference on Machine Learning. New York, USA: ACM, 2009. 609-616 [9] 于来行, 冯林, 张晶, 刘胜蓝.自适应融合目标和背景的图像特征提取方法.计算机辅助设计与图形学学报, 2016, 28(8):1250-1259 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201608006Yu Lai-Hang, Feng Lin, Zhang Jing, Liu Sheng-Lan. An image feature extraction method based on adaptive fusion of object and background. Journal of Computer-Aided Design and Computer Graphics, 2016, 28(8):1250-1259 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201608006 [10] Ding Y, Zhao Y, Zhao X Y. Image quality assessment based on multi-feature extraction and synthesis with support vector regression. Signal Processing:Image Communication, 2017, 54:81-92 doi: 10.1016/j.image.2017.03.001 [11] Batool N, Chellappa R. Fast detection of facial wrinkles based on Gabor features using image morphology and geometric constraints. Pattern Recognition, 2015, 48(3):642-658 doi: 10.1016/j.patcog.2014.08.003 [12] Joseph R, Santosh D. YOLO: real-time object detection[Online], available: http://pjreddie.com/darknet, November 3, 2016 [13] Liu Y L, Zhang Y M, Zhang X Y, Liu C L. Adaptive spatial pooling for image classification. Pattern Recognition, 2016, 55:58-67 doi: 10.1016/j.patcog.2016.01.030 [14] 朱煜, 赵江坤, 王逸宁, 郑兵兵.基于深度学习的人体行为识别算法综述.自动化学报, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtmlZhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtml [15] Peng Q W, Luo W, Hong G Y, Feng M. Pedestrian detection for transformer substation based on Gaussian mixture model and YOLO. In: Proceedings of the 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC). Hangzhou, China: IEEE, 2016. 562-565 [16] Nguyen V T, Nguyen T B, Chung S T. ConvNets and AGMM based real-time human detection under fisheye camera for embedded surveillance. In: Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC). Jeju, South Korea: IEEE, 2016. 840-845 [17] Erseghe T. Distributed optimal power flow using ADMM. IEEE Transactions on Power Systems, 2014, 29(5):2370-2380 doi: 10.1109/TPWRS.2014.2306495 [18] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2315-2324 [19] Parham J, Stewart C. Detecting plains and grevy's zebras in the realworld. In: Proceedings of the 2016 IEEE Winter Applications of Computer Vision Workshops (WACVW). Lake Placid, USA: IEEE, 2016. 1-9 [20] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN:towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6):1137-1146 doi: 10.1109/TPAMI.2016.2577031 [21] Gall J, Lempitsky V. Class-specific Hough forests for object detection. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2013. 1022-1029 [22] Yeung S, Russakovsky O, Mori G, Li F F. End-to-end learning of action detection from frame glimpses in videos. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2678-2687 [23] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[Online], available: https://arxiv.org/abs/1612.08242, December 30, 2016 [24] Körtner T. Ethical challenges in the use of social service robots for elderly people. Zeitschrift Für Gerontologie Und Geriatrie, 2016, 49(4):303-307 doi: 10.1007/s00391-016-1066-5 [25] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645 doi: 10.1109/TPAMI.2009.167 [26] Girshick R, Donahue J, Darrell T, Malik J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(1):142-158 doi: 10.1109/TPAMI.2015.2437384 [27] Gao W, Zhou Z H. Dropout rademacher complexity of deep neural networks. Science China Information Sciences, 2016, 59: Article No. 072104 [28] Tzutalin. LabelImg[Online], available: https://github.com/tzutalin/labelImg, November 6, 2016 [29] Abadi M, Agarwal A, Barham P, Zheng X Q. TensorFlow: large-scale machine learning on heterogeneous distributed systems[Online], available: http://download.tensorflow.org/paper/whitepaper2015.pdf. November 12, 2015 [30] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2015. 779-788 -



计量
- 文章访问数: 2793
- HTML全文浏览量: 590
- PDF下载量: 764
- 被引次数: 0
