

-
摘要: 为了有效融合RGB图像颜色信息和Depth图像深度信息, 提出一种基于贝叶斯框架融合的RGB-D图像显著性检测方法.通过分析3D显著性在RGB图像和Depth图像分布的情况, 采用类条件互信息熵(Class-conditional mutual information, CMI)度量由深层卷积神经网络提取的颜色特征和深度特征的相关性, 依据贝叶斯定理得到RGB-D图像显著性后验概率.假设颜色特征和深度特征符合高斯分布, 基于DMNB (Discriminative mixed-membership naive Bayes)生成模型进行显著性检测建模, 其模型参数由变分最大期望算法进行估计.在RGB-D图像显著性检测公开数据集NLPR和NJU-DS2000上测试, 实验结果表明提出的方法具有更高的准确率和召回率.Abstract: In this paper, we propose a saliency detection model for RGB-D images based on the deep features of RGB images and depth images within a Bayesian framework. By analysis of 3D saliency in the case of RGB images and depth images, class-conditional mutual information (CMI) is computed for measuring the dependence of deep features extracted by CNN, then the posterior probability of the RGB-D saliency is formulated by applying the Bayes' theorem. By assuming that color- and depth-based deep features are Gaussian distributions, a discriminative mixed-membership naive Bayes (DMNB) model is used to calculate the final saliency map. The Gaussian distribution parameter can be estimated in the DMNB model by using a variational inference-based expectation maximization algorithm. The experimental results on the RGB-D image NLPR and NJU-DS2000 datasets show that the proposed model performs better than other existing models.
-
Key words:
- Bayesian fusion /
- deep learning /
- generative model /
- saliency detection /
- RGB-D images
-
在现代信号处理和数据分析领域, 从高维输入信号中提取能够反映系统本质属性的信息是一件非常有意义的工作, 通常将能够完成此类工作的方法称为系统特征提取方法, 而主成分分析方法是应用比较广泛的一种系统特征提取方法.主成分分析主要是通过正交变换将高维的数据映射到低维空间, 从而达到数据压缩和系统特征提取的目的[1].在信号处理领域, 通常又将输入信号自相关矩阵最大特征值对应的特征向量称之为信号的主成分, 将由信号的多个主成分张成的子空间称为信号的主子空间, 而将能够实现对输入信号的主成分或主子空间进行提取的方法称为主成分分析方法[2].目前, 主成分分析方法已经广泛应用于图像处理[3]、故障诊断[4]、模式识别[5]等领域.
采用神经网络方法来提取输入信号中的主成分是目前国内外的一个研究热点.因为相比传统的数值算法, 如EVD (Eigenvalue decomposition)和SVD (Singular value decomposition), 神经网络算法可以避免对输入信号自相关矩阵的计算, 而且能够处理非平稳的随机输入信号.自从Oja提出的第一个主成分分析神经网络算法以来[6], 学者们相继提出了很多主成分分析算法, 如NIC (Novel information criterion)算法[7]、ULA (Unified learning algorithm)算法[8]、UIC (Unified information criterion)算法[9]等.虽然这些算法已经在各个领域得到了广泛的应用.但是这些算法在应用范围上仍然存在一定的限制, 如Oja算法和ULA算法只能提取一个主成分; NIC算法和UIC算法只能进行主子空间跟踪, 不能提取多个主成分.而在某些信号处理领域需要对信号的多个主成分进行提取, 因此研究如何提取多个主成分就成为一件非常有意义的工作.
目前为止, 学者们已经提出了一些多个主成分提取算法.根据主成分的获取方式不同, Ouyang等将现行算法分为串行算法和并行算法两类[10].串行算法首先采用单个主成分提取算法提取信号的第一个主成分, 然后采用压缩技术对采样信号进行处理, 消除信号中第一个主成分的影响, 而后依旧采用单个主成分提取算法来提取信号的第二个主成分; 重复上述步骤, 就可以实现多个主成分的提取.串行算法的缺点主要有以下4个方面: 1) 由于串行算法在每次提取过程中都需要用到全部的采样数据, 因此需要大量的存储器件; 2) 由于主成分的提取过程是顺序进行的, 因此会造成很大的提取时延; 3) 由于下一个主成分的提取依赖于当前主成分的提取结果, 因此当前主成分的提取误差会传播到下一次提取过程中, 当提取主成分的维数很大时, 串行算法会造成很大的误差累积; 4) 串行算法必须是信号全部采集完成后才能使用, 因此难以满足实时信号处理的要求.相比串行算法, 并行算法可以在一个算法迭代过程中实现多个主成分的同时提取, 因此可以避免串行算法的上述缺点.此外由于并行算法还具有很好的实时性, 因此引发了大量学者的研究.
在文献[11]中, Oja等采用对神经网络输出进行加权的方式, 提出了第一个多个主成分并行提取算法; Ouyang等则是对NIC算法进行了加权改进, 提出了一种非对称结构的算法---WNIC (Weighted NIC)算法[10]; Tanaka等[12]对加权的Oja算法进行改进, 提出了一类更为一般化的多个主成分提取算法; 通过对正交投影子空间跟踪算法(Orthogonal projection approximation and subspace tracking, OPAST)进行适当改进, Bartelmaos等提出了一种可以并行提取多个主成分的PC-OPAST (Principal component-OPAST)算法[13], 仿真实验表明PC-OPAST算法的估计精度要高于WNIC算法; Li等通过对NIC算法进行了改进, 提出了一种具有对称结构的算法---MNIC (Modified NIC)算法[14];此后基于Givens空间旋转变换法, Thameri等[15-16]采用提出了4种不同类型的多个主成分并行提取算法(MED-GOPAST (Maximum error deviation-generalized OPAST)、IMED-GOPAST (Improved MED-generalized OPAST)、AS-GOPAST (Automatic selection-generalized OPAST)、H-GOPAST (Hybrid-generalized OPAST)).相比上述其他算法, Thameri等所提算法具有较低的计算复杂度.然而, 上述大多数并行提取算法都属于二阶算法, 算法的收敛速度较慢.为了进一步提升算法的收敛速度, 本文提出了一种新型的算法.
本文的章节安排如下:第1节主要介绍本文中符号的命名规则和重要符号说明; 第2节根据现有的算法提出了一种新型的多个主成分提取算法; 第3节主要是对算法进行收敛性分析; 算法的自稳定性证明安排在第4节; 第5节是算法的数值仿真和实际应用; 第6节是本文的结论.
1. 符号说明
为了规范符号使用, 这里对本文中符号的使用规则进行确定.在本文中, 矩阵用斜体大写字母表示(如 ${{R}}$ ); 而加粗的斜体小写字母则代表向量(如 ${{\pmb y}}$ ); 标量一般用不加粗的斜体小写字母表示(如 $\eta $ ).此外, 这里还给出了一些常用符号的含义:
${{R}}$ 向量的自相关矩阵
${{W}}$ 神经网络的权矩阵
${{A}}$ 加权矩阵
$\eta $ 神经网络的学习因子
$\alpha$ 遗忘因子
$n$ 提取主成分的维数
2. 新型的多个主成分提取算法
考虑满足如下多输入多输出关系的线性神经网络模型:
$ \begin{equation} {{\pmb y}}(k)= {{{W}}^{\rm T}}(k){{\pmb x}}(k) \end{equation} $
(1) 其中, ${{\pmb y}}(k)\in\textbf{R}{^{r \times 1}}$ 是神经网络的输出, ${{W}}(k)\in \textbf{R} {^{n \times r}}$ 是神经网络的权矩阵, 输入信号 ${{\pmb x}}(k)\in {\textbf{R}^{n \times 1}}$ 是一个零均值的随机过程, 这里作为神经网络的输入, $n$ 代表输入向量的维数, $r$ 代表所需提取主成分的维数.
令为输入信号的自相关矩阵, ${\lambda _i}$ 和分别为自相关矩阵 ${{R}}$ 的特征值和对应的特征向量.则根据矩阵理论的知识可得:矩阵 ${{R}}$ 是一个对称正定矩阵, 且其特征值均是非负的.对矩阵 ${{R}}$ 进行特征值分解得:
$ \begin{equation} {{R}} = {{U\Lambda }}{{{U}}^{\rm T}} \end{equation} $
(2) 其中, 是由矩阵 ${{R}}$ 的特征向量构成的矩阵, 是由矩阵 ${{R}}$ 的特征值组成的对角矩阵.为了后续使用方便, 这里将特征值按照降序的方式进行排列, 即特征值满足如下方程:
$ \begin{equation} {\lambda _1} > {\lambda _2} > \cdots > {\lambda _r} > \cdots > {\lambda _n} > 0 \end{equation} $
(3) 根据主成分的定义可知, 特征值所对应的特征向量称为矩阵 ${{R}}$ 的前 $r$ 主成分, 而通常将由这些主成分张成的空间称为信号的主子空间.而多个主成分提取算法的任务就是构造合适的神经网络权矩阵迭代更新方程, 使神经网络的权矩阵能够收敛到矩阵 ${{R}}$ 的前 $r$ 主成分.
在文献[11]中, Oja等利用加权子空间法提出了多个主成分并行提取算法, 其算法形式为:
$ \begin{align} {{W}}(k + 1)=& {{W}}(k)+ \eta [{{RW}}(k)- \nonumber\\ &{{W}}(k){{{W}}^{\rm T}}(k){{RW}}(k){{A}}] \end{align} $
(4) 其中, $\eta$ 是神经网络的学习因子且满足关系 $0< \eta <1$ , $A$ 是一个 $r \times r$ 维对角矩阵且其对角线元素为: .在式(4) 所描述的学习算法的约束下, 神经网络算法的权矩阵将收敛到信号自相关矩阵 ${{R}}$ 的前 $r$ 个主成分.然而算法(4) 存在收敛速度慢的问题, 为此本文提出了如下算法, 其算法形式为:
$ \begin{align} {{W}}(k &+ 1) =\nonumber\\ &{{W}}(k)+ \eta {{W}}(k)[{({{{W}}^{\rm T}}(k){{W}}(k))^{-1}}- \nonumber\\ &{{I}}]+\eta ({{RW}}(k){{{W}}^{\rm T}}(k){{W}}(k){{{A}}^2} -\nonumber\\ &{{W}}(k){{A}}{{{W}}^{\rm T}}(k){{RW}}(k){{A}}) \end{align} $
(5) 其中矩阵 ${{A}}$ 同样为一个 $r \times r$ 维对角矩阵且其对角线元素为: ${a_1} > {a_2} > \cdots > {a_r} > 0$ , 这点是与算法(4) 一致的.式(5) 是一种全新的多个主成分提取算法.对比式(4) 和式(5) 可以发现, 式(5) 是一个非二阶的算法.根据文献[9]的结论, 非二阶算法可以在算法迭代过程中引入一个自适应的学习因子, 进而加速算法的收敛速度.因此式(5) 所描述的算法应具有较快的收敛速度, 这点将在稍后的仿真实验部分予以验证.
在主成分分析神经网络算法领域, 通常将与学习因子相乘的项称为算法的学习步长[9].显然, 式(5) 中算法的学习步长由两部分构成.为了简便起见, 这里令矩阵和矩阵.如果令式(5) 中的加权矩阵 ${{A}} = {{I}}$ , 且省去算法的矩阵 $C$ , 则算法退化成为另外一种主成分分析算法---Chen算法[17].然而仅仅由矩阵 ${{B}}$ 构成学习步长时, 算法很容易发生边界不稳定现象.为此, 需要对神经网络的加权矩阵加以限制, 最常用的方法就是增加正交约束[9].这里采用了一个非二阶的权矩阵约束措施(即添加矩阵 $C$ ), 这一操作不仅可以解决算法的不稳定问题, 还可以提升算法的收敛速度.
式(5) 所描述的算法只适用于自相关矩阵已知的情况, 而在实际使用时只能得到信号的观测值, 自相关矩阵通常是未知的且是需要实时估计的.这里给出自相关矩阵的估计公式:
$ \begin{equation} {{\hat R}}(k)= \frac{{(k - 1)}}{k}\alpha {{\hat R}}(k - 1)+ \frac{{{{{\pmb x}}_k}{{\pmb x}}_k^{\rm T}}}{k} \end{equation} $
(6) 其中, $\alpha$ 为遗忘因子, 且满足 $0<\alpha <1$ .显然当时, 矩阵 ${{\hat R}}(k)\to {{R}}$ .因此式(5) 在实际使用时, 应首先使用式(6) 对自相关矩阵进行估计, 然后将估计得到的矩阵代入式(5), 即可以完成对输入信号多个主成分的提取.为方便使用, 这里将式(5) 所描述的算法记为FMPCE (Fast multiple principle components extraction algorithm)算法.
3. 多个主成分提取算法的性能分析
本节将对所提算法在平稳点处的收敛特性进行分析, 相关结论由定理1给出.
定理1. 当且仅当权矩阵 ${{W}} = {{P}}$ 时, 式(5) 所描述的FMPCE算法达到稳定状态, 其中 $P$ 是由矩阵 $R$ 的前 $r$ 个特征值对应的特征向量构成的矩阵, 即有.
证明. 根据文献[18]的描述, 算法的学习步长通常为一个损失函数的梯度.通过对损失函数平稳点的分析就可以完成算法收敛性的分析.这里假设该损失函数为 $JW$ , 则该损失函数对于权矩阵 $W$ 的一阶微分可以表示为:
$ \begin{align} \nabla J({{W}})&=\nonumber \\ &{{RW}}{{{W}}^{\rm T}}{{W}}{A^2} - {{WA}}{{{W}}^{\rm T}}{{RWA}}+ \nonumber\\ & {{W}}{({{{W}}^{\rm T}}{{W}})^{ - 1}} - {{W}} \end{align} $
(7) 如果权矩阵 ${{W}} = {{P}}$ , 则有
$ \begin{align} \nabla J({{W}})&|_{W= P}=\nonumber\\& {{RP}}{{{P}}^{\rm T}}{{P}}{{{A}}^2} - {{PA}}{{{P}}^{\rm T}}{{RPA}}~+ \nonumber\\&{{P}}{({{{P}}^{\rm T}}{{P}})^{ - 1}} - {{P}}=\nonumber\\& {{P}}{{{\Lambda }}_r}{{{A}}^2} - {{PA}}{{{\Lambda }}_r}{{A}}= {{0}} \end{align} $
(8) 其中, 是由矩阵 $R$ 的前 $r$ 个特征值构成的对角矩阵.反之, 根据矩阵分析理论, 在平稳点处有 $\nabla J({{W}})= {{0}}$ , 即
$ \begin{equation} \begin{split} &{{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2} - {{WA}}{{{W}}^{\rm T}}{{RWA}} = \\ &~~~~~~~~~{{W}} - {{W}}{({{{W}}^{\rm T}}{{W}})^{ - 1}} \end{split} \end{equation} $
(9) 对上式两边左乘以 ${{{W}}^{\rm T}}$ , 可得
$ \begin{equation} \begin{split} &{{{W}}^{\rm T}}{{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2} - {{{W}}^{\rm T}}{{WA}}{{{W}}^{\rm T}}{{RWA}}=\\ & \quad\quad\quad\quad {{{W}}^{\rm T}}{{W}} - {{I}} \end{split} \end{equation} $
(10) 定义矩阵 ${{Q}} = {{{W}}^{\rm T}}{{W}} - {{I}}$ , 则矩阵 $Q$ 是一个对称矩阵, 由于权矩阵 $W$ 的任意性, 则有矩阵和分别是两个对称矩阵, 即有
$ \begin{equation} {{{W}}^{\rm T}}{{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2} = {{{A}}^2}{{{W}}^{\rm T}}{{W}}{{{W}}^{\rm T}}{{RW}} \end{equation} $
(11) $ \begin{equation} {{{W}}^{\rm T}}{{WA}}{{{W}}^{\rm T}}{{RWA}} = {{A}}{{{W}}^{\rm T}}{{RWA}}{{{W}}^{\rm T}}{{W}} \end{equation} $
(12) 由于矩阵 ${{{W}}^{\rm T}}{{RW}}$ 和矩阵 $A$ 均是对称矩阵, 则根据上面两式可得 ${{{W}}^{\rm T}}{{W}} = {{I}}$ .也就是说, 在 $J({{W}})$ 的平稳点处权矩阵 $W$ 的各列向量之间是相互正交的.将其代入式(9) 可得, $J({{W}})$ 平稳点有:
$ \begin{equation} {{RW}}{{{A}}^2} = {{WA}}{{{W}}^{\rm T}}{{RWA}} \end{equation} $
(13) 令是矩阵的特征值分解, 其中 $Q$ 是一个正交矩阵.将其代入式(13) 可得: ${{RP'}} = {{P'}}{{{\Lambda '}}_r}$ , 其中, .由于矩阵 ${{{\Lambda '}}_r}$ 是一个对角矩阵且 ${{P'}}$ 是一个列满秩矩阵, 则矩阵 ${{{\Lambda'}}_r}$ 和 ${{P'}}$ 必定等于矩阵 ${{{\Lambda }}_r}$ 和 ${{P}}$ .
下面对加权矩阵 ${{A}}$ 的作用做进一步讨论.令和 ${{{R}}_y} = {{{W}}^{\rm T}}{{RW}}$ , 将其代入式(13) 并进行适当化简可得:
$ \begin{equation} {{W}} = {{{R}}_{xy}}{({{A}}{{{R}}_y}{{{A}}^{ - 1}})^{ - 1}} \end{equation} $
(14) 矩阵的作用就是对矩阵 ${{{R}}_{xy}}$ 的各列向量施加Gram-Schmidt正交化操作[19].由于矩阵是一个非对称矩阵且矩阵的各元素可以写为:
$ \begin{align} \begin{array}{l} {{A}}{{{R}}_y}{{{A}}^{ - 1}}=~~~~~\\ ~~~ \left[{\begin{array}{*{10}{c}} {{\rm E}\{ z_1^2\} }&{\dfrac{{{a_1}}}{{{a_2}}}z}&{\dfrac{{{a_1}}}{{{a_3}}}z}& \cdots &{\dfrac{{{a_1}}}{{{a_r}}}z}\\ {\dfrac{{{a_2}}}{{{a_1}}}z}&{{\rm E}\{ z_2^2\} }&{\dfrac{{{a_2}}}{{{a_3}}}z}& \cdots &{\dfrac{{{a_2}}}{{{a_r}}}z}\\ \vdots&\vdots&\vdots &\ddots&\vdots \\ {\dfrac{{{a_r}}}{{{a_1}}}z}&{\dfrac{{{a_2}}}{{{a_r}}}z}&{\dfrac{{{a_3}}}{{{a_r}}}z}& \cdots &{{\rm E}\{ z_r^2\} } \end{array}} \right] \end{array} \end{align} $
(14) 其中用 $z$ 来代表矩阵 ${{{R}}_y}$ 的元素.根据式(15) 可得矩阵 ${{{R}}_y}$ 的上三角部分的元素均是乘以一个大于1的数, 而下三角部分则是乘以一个小于1的数.通过使用第一列正交化 ${{R}}_{xy}$ 可以获得矩阵 ${{{R}}}$ 的第一个主成分, 通过第二列正交化 ${{R}}_{xy}$ 可以获得矩阵 ${{{R}}}$ 的第二个主成分, 依次类推.值得注意的是第二列中只有一个大于1的系数 ${{a}_{1}}/{{a}_{2}}$ , 而其他所有系数均是小于1.根据文献[20]可得, 系数 ${{a}_{1}}/{{a}_{2}}$ 可以避免后续操作对已经提取的主成分造成影响.上述分析表明, 可以通过合理的选择加权矩阵 ${{A}}$ , 使得算法最终将能够实现对矩阵 $R$ 的多个主成分的提取.
4. 算法的自稳定性分析
自稳定性是指不论神经网络初始权矩阵如何选择, 神经网络权矩阵的模值均能收敛到一个常值, 而与初始权矩阵无关.在文献[21]中Möller指出:所有不具备自稳定性的神经网络算法都具有发散的可能性, 因此自稳定性已经成为了神经网络算法的一个必备特性.本节将对FMPCE算法的自稳定性进行分析证明.
定理2. 如果输入信号是有界的且学习因子 $\eta$ 足够小, 则FMPCE算法的权矩阵模值将收敛到一个常值(该值等于提取主成分维数的均方根, 即 $\sqrt{r}$ ), 而与初始权矩阵的选择无关.
证明. 根据式(5) 可得, 在 $k+1$ 时刻权矩阵的模值为:
$ \begin{align*} \begin{array}{l} \left\| {{{W}}(k + 1)} \right\|_F^2=~~~~\\ ~~~~~~~~ {\rm tr}\left[{{{{W}}^{\rm T}}(k + 1){{W}}(k + 1)} \right]=\\~~~~~~~~ {\rm tr}\left\{ {\left[{{{W}} + \eta {{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2}- \eta {{W}}-} \right.} \right.\\~~~~~~~~ {\left. {\eta {{WA}}{{{W}}^{\rm T}}{{RWA}} + \eta {{W}}{{({{{W}}^{\rm T}}{{W}})}^{-1}}} \right]^{\rm T}}\times\\~~~~~~~~ \left[{{{W}} + \eta {{W}}{{({{{W}}^{\rm T}}{{W}})}^{-1}}-\eta {{W}}} \right. + \\~~~~~~~~ \left. {\left. { \eta {{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2}-\eta {{WA}}{{{W}}^{\rm T}}{{RWA}}} \right]} \right\}=\\~~~~~~~~ {\rm tr}\left\{ {{{{W}}^{\rm T}}{{W}} + 2\eta {{{W}}^{\rm T}}{{RW}}{{{W}}^{\rm T}}{{W}}{{{A}}^2}}- \right.\\~~~~~~~~ 2\eta {{{W}}^{\rm T}}{{WA}}{{{W}}^{\rm T}}{{RWA}} - 2\eta {{{W}}^{\rm T}}{{W}}+ \\~~~~~~~~ 2\eta {{{W}}^{\rm T}}{{W}}{({{{W}}^{\rm T}}{{W}})^{ - 1}} + o(\eta ) \approx\\~~~~~~~~ {\rm tr}\left\{ {{{{W}}^{\rm T}}{{W}}} \right\} + 2\eta {\rm tr}\left\{ {{{I}} - {{{W}}^{\rm T}}{{W}}} \right\} \end{array}\\[-6mm] \end{align*} $
(16) 在上式中为了书写方便, 而省略了第二个等号以后的迭代时刻符号 $k$ .由于学习因子足够小, 因此可以忽略有关学习因子的二阶项.对比前后两个时刻权矩阵模值的大小可得:
$ \begin{equation} \begin{split} &\frac{{\left\| W(k + 1) \right\|_F^2}}{{\left\| {{{W}}(k)} \right\|_F^2}}=~~~~~~~~~~~~\\ &~~~~~~~~~~~~1+\frac{{ 2\eta {\rm tr}\left\{ {{{I}} - {{{W}}^{\rm T}}(k){{W}}(k)} \right\}}}{{{\rm tr}\left\{ {{{{W}}^{\rm T}}(k){{W}}(k)} \right\}}}=\\ &~~~~~~~~~~~~ 1 + 2\eta \frac{{r - \left\| {{{W}}(k)} \right\|_F^2}}{{\left\| {{{W}}(k)} \right\|_F^2}}~~~~~~\\ &~~~~~~~~~~~~ \left\{ {\begin{array}{*{20}{c}} { > 1}, &\mbox{若}&{\left\| {{{W}}(k)} \right\|_F^{} < \sqrt r }\\ { = 1}, &\mbox{若}&{\left\| {{{W}}(k)} \right\|_F^{} = \sqrt r }\\ { < 1}, &\mbox{若}&{\left\| {{{W}}(k)} \right\|_F^{} > \sqrt r } \end{array}} \right. \end{split} \end{equation} $
(17) 通过式(17) 可以发现, 无论 $k$ 时刻的权矩阵模值是否等于 $\sqrt r $ , 下一时刻 $k+1$ 的权矩阵模值都将趋于 $\sqrt r $ , 即在收敛时权矩阵模值将趋于一个常数.这一特性表明, 无论初始时刻的权矩阵模值如何选择, 将不会对算法的收敛结果造成任何影响, 即FMPCE算法具有自稳定性.
5. 仿真实验
本节将提供4个仿真实验来对所提算法的性能进行验证.第一个实验主要验证FMPCE算法提取信号中多个主成分的能力; 第二实验主要考察FMPCE算法的自稳定性; 第三个实验则是将FMPCE算法与一些现存的多个主成分提取算法进行比较; 第四个实验则是应用FMPCE算法进行图像压缩和重建并与一些现有算法进行比较.在整个实验过程中, 为了定量地对算法性能进行评价, 这里引入如下两个评价函数, 第一个是方向余弦(Direction cosine, DC):
$ \begin{equation} {\rm DC}_i(k)= \frac{{\left| {{{\pmb w}}_i^{\rm T}(k){{{\pmb u}}_i}} \right|}}{{\left\| {{{\pmb w}_i}(k)} \right\| \cdot \left\| {{{{\pmb u}}_i}} \right\|}} \end{equation} $
(18) 其中, $i = 1, 2, \cdots, r$ 且 ${{{\pmb w}}_i}$ 代表权矩阵 $W$ 的第 $i$ 列, ${{{\pmb u}}_i}$ 则代表信号的第 $i$ 个主成分.从式(18) 可以得出:如果方向余弦曲线能够收敛到1, 神经网络算法的权矩阵必定已经收敛到信号主成分的方向.方向余弦衡量的是算法的估计精度, 而权向量模值则能够评价算法的收敛性.
$ \begin{equation} {\rm{Nor}}{{\rm{m}}_i}{\rm{(}}k{\rm{)= }}\left\| {{{{\pmb w}}_i}(k)} \right\|, {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} i = 1, 2, \cdots, r \end{equation} $
(19) 5.1 多个主成分提取能力验证
本实验采用文献[10]中所使用的信号产生方法, 输入信号采用如下一阶滑动回归模型来产生:
$ \begin{equation} x(k)= 0.75x(k - 1)+ e(k) \end{equation} $
(20) 该模型由一个均值为0方差为1的高斯白噪声 $e(k)$ 作为模型驱动输入.取该模型的10个不连续的输出构成神经网络的输入向量, 即 $n=10$ .接下来采用本文所提出的FMPCE算法对该输入信号的前3个主成分进行提取, 即 $r=3$ . FMPCE算法的初始化参数设置为:初始权矩阵为随机的, 学习因子 $\eta=0.1$ , 加权矩阵 ${{A}} ={\rm diag}\{3, 2, 1\}$ .图 1和图 2分别给出了FMPCE算法的仿真结果, 在该图中, 所有学习曲线均是为100次独立实验的平均结果.
从图 1中可以看出:大约经过1500次左右的迭代后, FMPCE算法的3条方向余弦曲线就都收敛到了1, 这就说明FMPCE算法的权矩阵已经收敛到了信号主成分的方向; 对照图 2可以看出, 经过30次迭代运算后, 权矩阵模值均已经收敛到1, 也就是说此时的FMPCE算法已经收敛.该仿真实验表明: FMPCE算法具备提取信号多个主成分的能力.
5.2 FMPCE算法的自稳定性实验
本实验主要对FMPCE算法的自稳定性进行仿真验证.本实验同样采取式(20) 产生的输入信号. FMPCE算法的初始化参数设置为:学习因子 $\eta = 0.01$ , 加权矩阵, 初始化权矩阵为随机产生的且其模值被标准化为模值大于3, 等于3和小于3等情况.然后分别考察在这种不同初始权矩阵情况下, FMPCE算法的权矩阵模值收敛情况.
图 3是经过100次独立仿真获得的FMPCE算法权矩阵模值曲线, 从图 3中可以看出:不论初始权矩阵如何选择, FMPCE算法收敛时权矩阵模值均等于 $\sqrt{3}$ , 这点是与定理2中的分析一致的.通过该实验可得: FMPCE算法具有自稳定性.
5.3 FMPCE算法与其他算法的对比
本节将所提出的FMPCE算法与文献[14]中的MNIC算法和文献[15]中的MED-GOPAST算法进行对比.本实验中的输入信号同样由式(20) 产生, 这里分别采用这三种算法对该输入信号的前2个主成分进行提取, 即 $r=2$ .三种算法的初始化参数设置为:对MNIC算法和FMPCE算法而言, 加权矩阵 ${{A}} ={\rm diag}\{2, 1\}$ , 学习因子 $\eta = 0.15$ ; 对MED-GOPAST算法而言, 遗忘因子 $\alpha = 0.998$ .为了公平比较, 三种算法的初始化权矩阵均是随机产生的.三种算法对于该信号的提取结果如图 4和图 5所示, 该结果是100次独立实验结果的平均值.
从图 4和图 5中可以看出:大约经历了200次左右的迭代运算后, FMPCE算法的方向余弦曲线就已经收敛到了1, 这一收敛速度要优于MED-GOPAST算法和MNIC算法.从上面两图的最后放大结果中还可以看出, 虽然三种算法均收敛到了单位1, 但是三种算法的最终收敛值并不相同:其中MNIC算法与单位1偏差最大, MED-GOPAST算法次之, 三种算法中FMPCE算法偏差最小.由于方向余弦可以表征算法的估计精度, 所以可以说在这三种算法中, FMPCE算法具有最好的估计精度.通过此实验可以得出结论: FMPCE算法不仅具有较快的收敛速度, 而且具有很高的估计精度.
5.4 FMPCE算法在图像压缩中的应用
图像压缩一直是计算机图形图像学领域内的热点问题, 通过图像压缩技术可以减小图像数据中的冗余信息从而实现更加高效的格式存储和数据传输, 而基于主成分分析的压缩方法又是图像压缩领域内的一种常用方法[22].本小节将采用主成分分析方法对著名的Lena图像进行压缩和重构. Lena原始图像如图 6(a)所示, 该图像的分辨率512像素 $\times$ 512像素.这里将Lena图像分解为若干个8像素 $\times$ 8像素的不重叠小块并将这些小块按照从左到右从上到下的顺序排列, 就构成了一个64维的数据向量.将这些数据进行中心化处理后作为主成分分析算法的输入序列.然后分别采用FMPCE算法、MED-GOPAST算法和MNIC算法对Lena图像进行压缩后重建.
三种算法的初始化参数设置方法与第5.3节相同, 这里不再重复.图 6(b) $\sim$ (d)分别给出了在重构维数为1, 4, 7三种不同情况下采用FMPCE算法对于Lena图像的重构结果, 表 1给出了在不同的重构维数下, 三种算法的重构误差.从图 6和表 1中可以得出:利用FMPCE算法对Lena图像进行压缩重构可以获得较清晰的重构图像和较低的重构误差, 即可以利用FMPCE算法解决图像重构问题.对比三种不同算法的重构误差还可以发现, 在相同的重构维数下FMPCE算法具有最小的重构误差, 即FMPCE算法对提取的主成分具有最高的估计精度, 这点是与第5.3节中的结论一致的.
表 1 不同重构维数下三种算法的重构误差Table 1 Reconstitution errors of the three algorithms with different reconstitution dimensions重构维数 1 4 7 FMPCE 0.094 0.0837 0.0813 MED-GOPAST 0.0959 0.0852 0.0846 MNIC 0.1283 0.1015 0.0933 6. 结论
本文首先对一些多个主成分提取并行算法进行了研究, 针对现有算法收敛速度慢的问题, 提出了一种新的具有较快收敛速度的非二阶算法, 该算法可以从输入信号中并行提取多个主成分; 然后采用平稳点分析法对所提算法的收敛性和自稳定性进行了证明; 最后通过仿真实验对所提算法的性能进行了验证.仿真结果表明:相比一些现有算法, 所提算法不仅收敛速度快而且估计精度较高.
-

图 4 RGB-D图像超像素分割(如RGB图像矩形框区域所显示, 兼顾颜色和深度信息超像素分割得到边缘比只考虑颜色信息要准确.同样情况, Depth图像矩形框区域显示兼顾颜色和深度信息超像素分割得到边缘比只考虑深度信息要准确)
Fig. 4 Visual samples for superpixel segmentation of RGB-D images (Within the rectangle, the boundary between the foreground and the background segmented by the color and depth cues more accurate than color-based segmentation. Similarly, within the rectangle, the boundary between the foreground and the background segmented by the color and depth cues more accurate than depth-based segmentation)

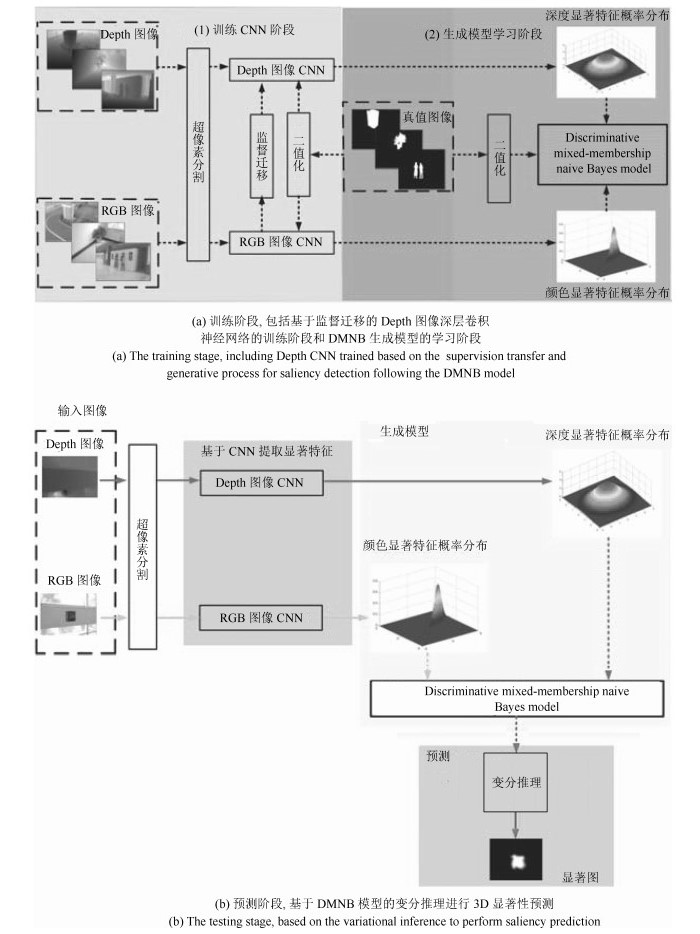
图 5 监督迁移学习过程示意图((a)提取Depth图像显著特征的深层卷积神经网络结构图.其中Relu层使用修正线性函数Relu$(x) = \max(x, 0)$保证输出不为负; Lrn表示局部响应归一化层; Dropout表示Dropout层, 在训练时以0.5比例忽略隐层节点防止过拟合. (b)基于深层卷积神经网络提取RGB图像和Depth图像显著特征流程图.首先图像被裁剪成尺寸为227$\times$227$\times$3作为深层卷积神经网络的输入, 在卷积层1通过96核的尺寸为7$\times$7步长为2滤波器卷积滤波, 得到卷积图像通过Relu函数, 再经过池化层1尺寸为3$\times$3步长为2的最大值池化成96个尺寸为55$\times$55的特征图, 最后对得到的特征图进行局部响应归一化.在卷积层2, 池化层2, 卷积层3, 卷积层4, 卷积层5和池化层5执行相似的处理.其池化层5输出作为全连接层6的输入, 经过全连接层7由输出层输出显著类别, 其中输出层采用softmax函数. (c)本文基于监督迁移学习的方法, 在RGB图像训练完成的Clarifai网络的基础上, 利用与RGB图像配对的Depth图像重新训练提取Depth图像显著特征的深层卷积神经网络)
Fig. 5 Architecture for supervision transfer ((a) The Architecture of Depth CNN, where Relu denotes a rectified linear function Relu$(x) = \max(x, 0)$, which rectify the feature maps thus ensuring the feature maps are always positive, lrn denotes a local response normalization layer, and Dropout is used in the fully connected layers with a rate of 0.5 to prevent CNN from overfitting. (b) The flowchart of image processed based on Depth CNN. A 227 by 227 crop of an image (with 3 planes) is presented as the input. This is convolved with 96 different 1st layer filters, each of size 7 by 7, using a stride of 2 in both $x$ and $y$. The resulting feature maps are then: passed through a rectified linear fuction, pooled (max within 3 by 3 regions, using stride 2), and local response normalized across feature maps to give 96 different 55 by 55 element feature maps. Similar operations are repeated in layers 2, 3, 4, 5. The last two layers are fully connected, taking features from the pooling layer 5 as input in vector form. The final layer is a 2-way softmax function, which indicates the image is salient or not. (c) We train a CNN model for depth images by teaching the network to reproduce the mid-level semantic representation learned from RGB images for which there are paired images)
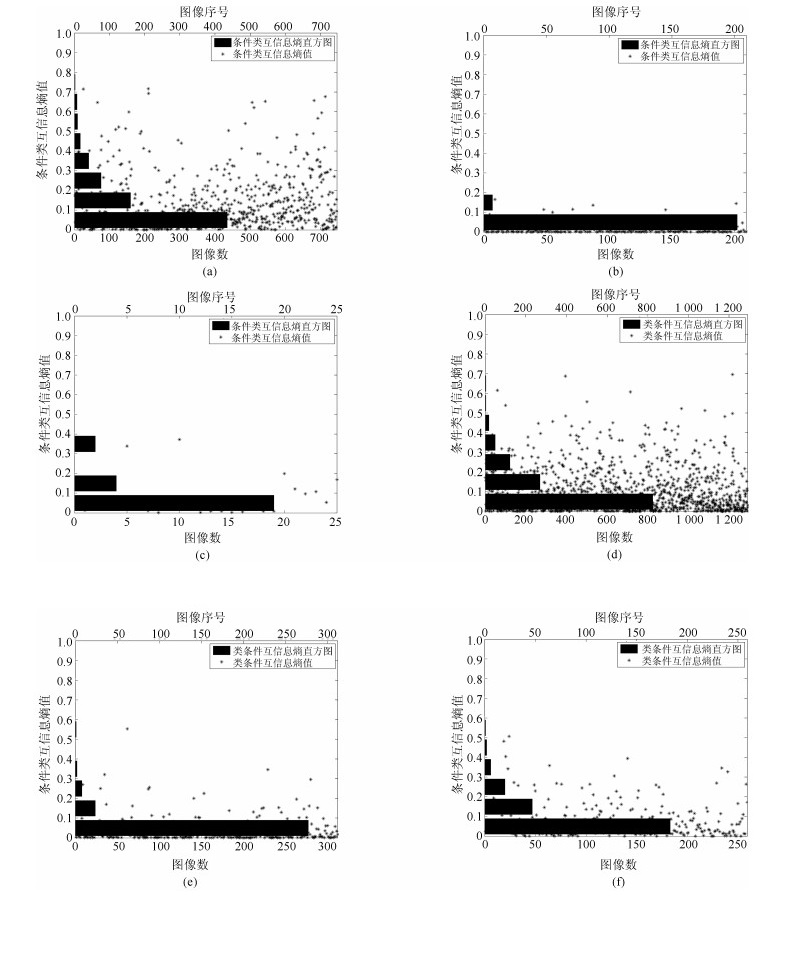
图 6 NLPR数据集和NJU-DS2000数据集RGB图像和Depth图像显著特征的类条件互信息熵分布图((a) NLPR数据集颜色-深度显著情况; (b) NLPR数据集颜色显著情况; (c) NLPR数据集深度显著情况; (d) NJU-DS2000数据集颜色-深度显著情况; (e) NJU-DS2000数据集颜色显著情况; (f) NJU-DS2000数据集深度显著情况)
Fig. 6 Visual result for class-conditional mutual information between color and depth deep features on NLPR and NJU-DS2000 RGB-D image datasets ((a) Color-depth saliency situation in terms of the NLPR dataset, (b) Color saliency situation in terms of the NLPR dataset, (c) Depth saliency situation in terms of the NLPR dataset, (d) Color-depth saliency situation in terms of the NJU-DS2000 dataset, (e) Color saliency situation in terms of the NJU-DS2000 dataset, (f) Depth saliency situation in terms of the NJU-DS2000 dataset.)
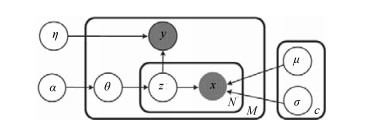
图 7 基于DMNB模型显著性检测的图模型($y$和$\pmb{x}$为可观测变量, $\pmb{z}$为隐藏变量.其中$\pmb{x}_{1:N} = (\pmb{x}_c, \pmb{x}_d)$表示RGB-D图像显著特征, 特征$\pmb{x}_j$服从$C$个均值为$\{\mu_{jk}|j = 1, \cdots, N\}$和方差为$\{\sigma_{jk}^2|j = 1, \cdots, N\}$高斯分布. $y$是标识超像素是否显著的标签, 取值1或者0, 其中1表示显著, 0表示非显著)
Fig. 7 Graphical models of DMNB for saliency estimation ($y$ and $\pmb{x}$ are the corresponding observed states, and $\pmb{z}$ is the hidden variable, where each feature $\pmb{x}_j$ is assumed to have been generated from one of $C$ Gaussian distribution with a mean of $\{\mu_{jk}|j = 1, \cdots, N\}$ and a variance of $\{\sigma_{jk}^2|j = 1, \cdots, N\}$, $y$ is either 1 or 0 that indicates whether the pixel is salient or not.)

图 8 对比基于生成聚类和狄利克雷过程聚类方法确定DMNB模型混合分量参数$C$ ((a)针对NLPR数据集显著特征生成聚类图. (b)针对NLPR数据集基于狄利克雷过程的显著特征聚类图, 其中不同图例的数目代表DMNB模型混合分量参数$C$.对于NLPR数据集, 得到$C = 24$. (c)针对NJU-DS2000数据集显著性特征生成聚类图. (d)针对NJU-DS2000数据集基于狄利克雷过程的显著特征聚类图, 其中不同图例的数目代表DMNB模型混合分量参数$C$.对于NJU-DS2000数据集, 得到$C = 28$)
Fig. 8 Visual result for the number of components $C$ in the DMNB model: generative clusters vs DPMM clustering ((a) Generative clusters for NLPR RGB-D image dataset. (b) DPMM clustering for NLPR RGB-D image dataset, where the number of colors and shapes of the points denote the number of components $C$. We find $C = 24$ using DPMM on the NLPR dataset. (c) Generative clusters for NJU-DS2000 RGB-D image dataset. (d) DPMM clustering for NJU-DS2000 RGB-D image dataset, where the number of colors and shapes of the points denote the number of components $C$. We find $C = 28$ using DPMM on the NJU-DS2000 dataset.)
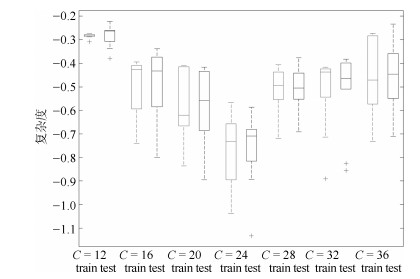
图 9 对于NLPR数据集交叉验证DMNB模型混合分量参数$C$, 给定一个由DPMM模型得到的参数$C$的取值范围, 采用10-fold进行交叉验证
Fig. 9 Cross validation for the parameter $C$ in the DMNB model in terms of NLPR dataset, we use 10-fold cross-validation with the parameter $C$ for DMNB models, the $C$ found using DPMM was adjusted over a wide range in a 10-fold cross-validation

图 10 NLPR数据集颜色-深度显著情况显著图对比. ((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h) LMH方法; (i) GP方法; (j)本文方法)
Fig. 10 Visual comparison of the saliency detection in the color-depth saliency situation in terms of NLPR dataset ((a) RGB image, (b) Depth image, (c) Ground truth, (d) ACSD, (e) GMR, (f) MC, (g) MDF, (h) LMH, (i) GP, (j) BFSD)
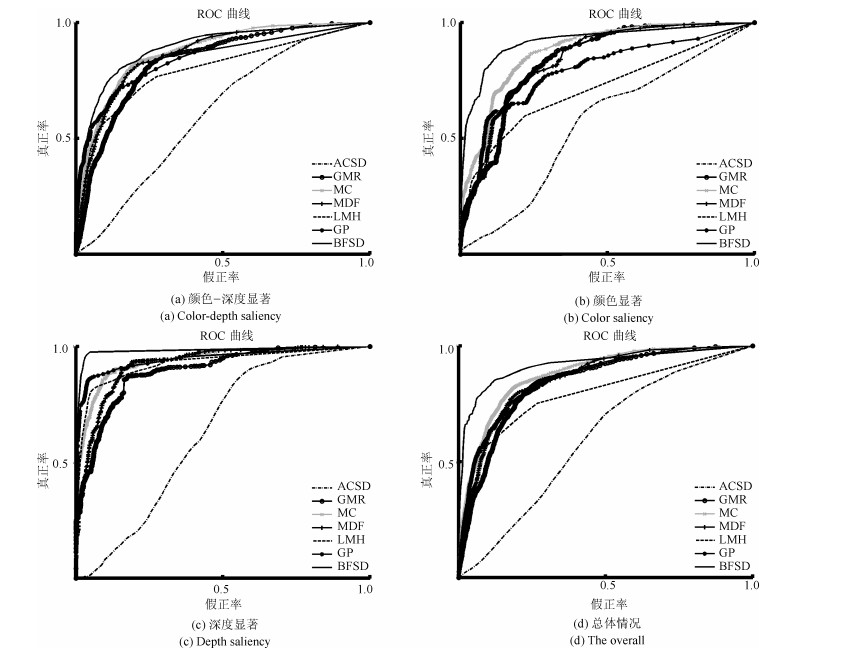
图 11 NLPR数据集ROC曲线对比图
Fig. 11 The ROC curves of different saliency detection models in terms of the NLPR dataset
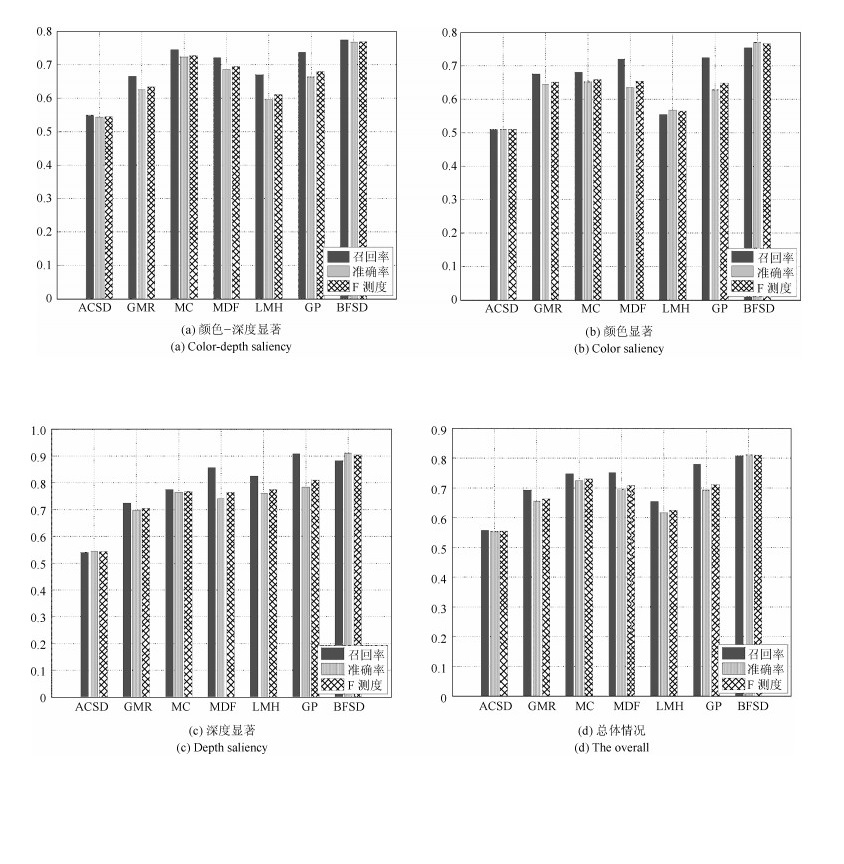
图 12 NLPR数据集F测度结果对比图
Fig. 12 The F-measures of different saliency detection models when used on the NLPR dataset

图 13 NLPR数据集颜色显著情况显著图对比((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h) LMH方法; (i) GP方法; (j)本文方法)
Fig. 13 Visual comparison of the saliency detection in the color saliency situation in terms of NLPR dataset ((a) RGB image, (b) Depth image, (c) Ground truth, (d) ACSD, (e) GMR, (f) MC, (g) MDF, (h) LMH, (i) GP, (j) BFSD)

图 14 NLPR数据集深度显著情况显著图对比((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h) LMH方法; (i) GP方法; (j)本文方法)
Fig. 14 Visual comparison of the saliency detection in the depth saliency situation in terms of NLPR dataset ((a) RGB image, (b) Depth image, (c) Ground truth, (d) ACSD, (e) GMR, (f) MC, (g) MDF, (h)LMH, (i) GP, (j) BFSD)

图 15 NJU-DS2000数据集颜色-深度显著情况显著图对比((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h)本文方法)
Fig. 15 Visual comparison of the saliency detection in the color-depth saliency situation in terms of NJU-DS2000 dataset ((a) RGB image, (b) Depth image, (c) Ground truth, (d) ACSD, (e) GMR, (f) MC, (g) MDF, (h) BFSD)

图 16 NJU-DS2000数据集颜色显著情况显著图对比. ((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h)本文方法)
Fig. 16 Visual comparison of the saliency detection in the color saliency situation in terms of NJU-DS2000 dataset ((a) RGB image, (b) Depth image, (c) Ground truth, (d) ACSD, (e) GMR, (f) MC, (g) MDF, (h) BFSD)

图 17 NJU-DS2000数据集深度显著情况显著图对比((a) RGB图像; (b) Depth图像; (c)真值图; (d) ACSD方法; (e) GMR方法; (f) MC方法; (g) MDF方法; (h)本文方法)
Fig. 17 Visual comparison of the saliency detection in the depth saliency situation in terms of NJU-DS2000 dataset ((a) RGB image; (b) Depth image; (c) Ground truth; (d) ACSD; (e) GMR; (f) MC; (g) MDF; (h) BFSD)
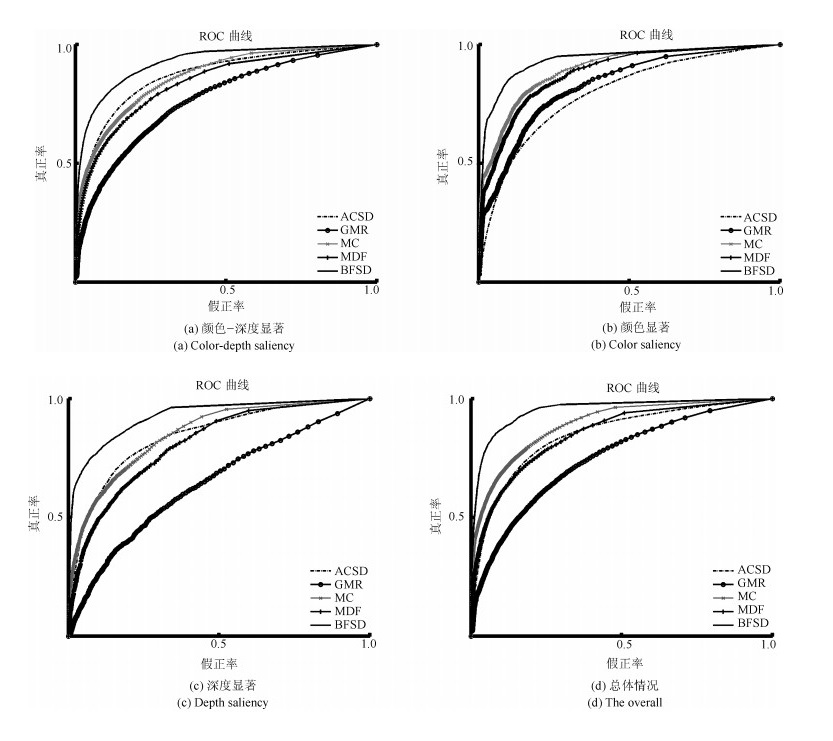
图 18 NJU-DS2000数据集ROC对比图
Fig. 18 The ROC curves of different saliency detection models in terms of the NJU-DS2000 dataset
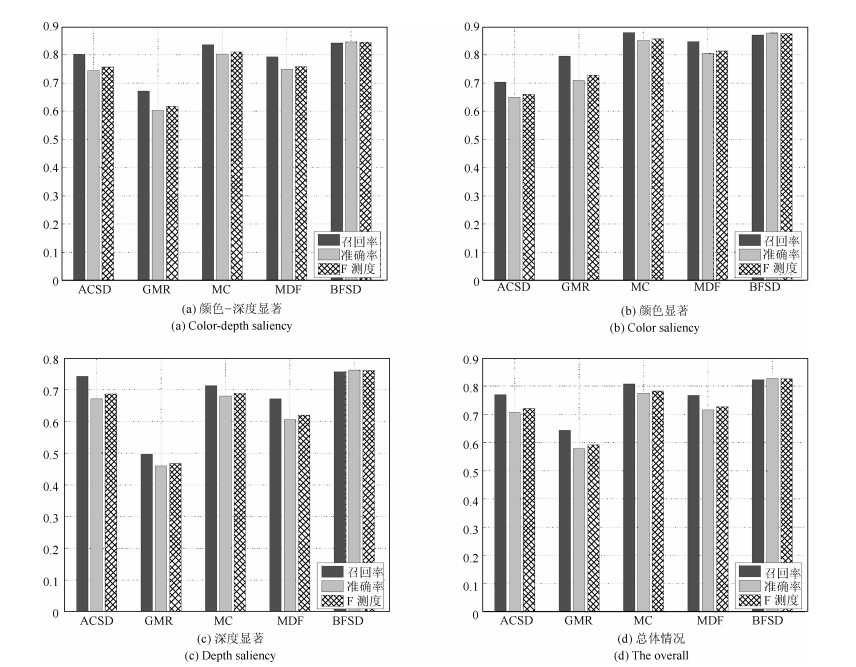
图 19 NJU-DS2000数据集F测度结果对比图
Fig. 19 The F-measures of different saliency detection models when used on the NJU-DS2000 dataset
表 1 RGB-D图像数据集中3D显著性分布比例
Table 1 3D saliency situation on RGB-D image dataset
 下载: 导出CSV
下载: 导出CSV
表 2 参数表
Table 2 Summary of parameters
变量名 取值范围 参数描述 $\tau$ (0, 1) 类条件互信息熵阈值 $\alpha$ (0, 20) 狄利克雷分布参数 $\theta$ (0, 1) 多项式分布参数 $\eta$ (-10.0, 3.0) 伯努利分布参数 $\Omega$ ((0, 1), (0, 0.2)) 高斯分布参数 $N$ $> 2$ 特征维度 $C$ $> 2$ DMNB模型分量参数 $\varepsilon_\mathcal{L}$ (0, 1) EM收敛阈值
下载: 导出CSV
表 3 NLPR数据集和NJU-DS2000数据集分布情况
Table 3 The benchmark and existing 3D saliency detection dataset
数据集 图片数 显著目标数 场景种类 中央偏置 NLPR 1000 (大多数)一个 11 是 NJU-DS2000 2000 (大多数)一个 $>$ 20 是
下载: 导出CSV
表 4 NLPR数据集处理一幅RGB-D图像平均时间比较
Table 4 Comparison of the average running time for per RGB-D image on the NLPR dataset
数据集 GMR MC MDF ACSD LMH GP BFSD NLPR 2.9s 72.7s $942.3$s 0.2s 2.8s 38.9s 80.1s
下载: 导出CSV
表 5 AUC值比较
Table 5 Comparison of the AUC on the NLPR dataset
显著分布情况 ACSD GMR MC MDF LMH GP BFSD 颜色-深度显著 0.61 0.73 0.81 0.82 0.70 0.79 0.83 颜色显著 0.56 0.74 0.84 0.83 0.61 0.65 0.84 深度显著 0.63 0.71 0.76 0.74 0.75 0.81 0.90 总体 0.60 0.73 0.81 0.80 0.69 0.78 0.85
下载: 导出CSV
-
[1] Borji A, Itti L. State-of-the-art in visual attention modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 185-207 doi: 10.1109/TPAMI.2012.89 [2] Wang Wen-Guan, Shen Jian-Bing, Shao Ling, Porikli Fatih. Correspondence driven saliency transfer. IEEE Transaction on Image Processing, 2016, 25(11): 5025-5034 doi: 10.1109/TIP.2016.2601784 [3] 丁正虎, 余映, 王斌, 张立明.选择性视觉注意机制下的多光谱图像舰船检测.计算机辅助设计与图形学学报, 2011, 23(3): 419-425 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201103007Ding Zheng-Hu, Yu Ying, Wang Bin, Zhang Li-Ming. Visual attention-based ship detection in multispectral imagery. Journal of Computer-Aided Design & Computer Graphics, 2011, 23(3): 419-425 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201103007 [4] Gao D S, Han S Y, Vasconcelos N. Discriminant saliency, the detection of suspicious coincidences, and applications to visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(6): 989-1005 doi: 10.1109/TPAMI.2009.27 [5] Jian M W, Dong J Y, Ma J. Image retrieval using wavelet-based salient regions. The Imaging Science Journal, 2011, 59(4): 219-231 doi: 10.1179/136821910X12867873897355 [6] 王向阳, 杨红颖, 郑宏亮, 吴俊峰.基于视觉权值的分块颜色直方图图像检索算法.自动化学报, 2010, 36(10): 1489-1492 doi: 10.3724/SP.J.1004.2010.01489Wang Xiang-Yang, Yang Hong-Ying, Zheng Hong-Liang, Wu Jun-Feng. A color block-histogram image retrieval based on visual weight. Acta Automatica Sinica, 2010, 36(10): 1489-1492 doi: 10.3724/SP.J.1004.2010.01489 [7] 冯欣, 杨丹, 张凌.基于视觉注意力变化的网络丢包视频质量评估.自动化学报, 2011, 37(11): 1322-1331 doi: 10.3724/SP.J.1004.2011.01322Feng Xin, Yang Dan, Zhang Ling. Saliency variation based quality assessment for packet-loss-impaired videos. Acta Automatica Sinica, 2011, 37(11): 1322-1331 doi: 10.3724/SP.J.1004.2011.01322 [8] Gupta R, Chaudhury S. A scheme for attentional video compression. In: Proceedings of the 4th International Conference on Pattern Recognition and Machine Intelligence. Moscow, Russia: IEEE, 2011. 458-465 [9] Guo C L, Zhang L M. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Transactions on Image Processing, 2010, 19(1): 185-198 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=560c7c523a5fae193c072cc702070cd8 [10] Kim W, Kim C. A novel image importance model for content-aware image resizing. In: Proceedings of the 18th IEEE International Conference on Image Processing. Brussels, Belgium: IEEE, 2011. 2469-2472 [11] 江晓莲, 李翠华, 李雄宗.基于视觉显著性的两阶段采样突变目标跟踪算法.自动化学报, 2014, 40(6): 1098-1107 doi: 10.3724/SP.J.1004.2014.01098Jiang Xiao-Lian, Li Cui-Hua, Li Xiong-Zong. Saliency based tracking method for abrupt motions via two-stage sampling. Acta Automatica Sinica, 2014, 40(6): 1098-1107 doi: 10.3724/SP.J.1004.2014.01098 [12] 黎万义, 王鹏, 乔红.引入视觉注意机制的目标跟踪方法综述.自动化学报, 2014, 40(4): 561-576 doi: 10.3724/SP.J.1004.2014.00561Li Wan-Yi, Wang Peng, Qiao Hong. A survey of visual attention based methods for object tracking. Acta Automatica Sinica, 2014, 40(4): 561-576 doi: 10.3724/SP.J.1004.2014.00561 [13] Le Callet P, Niebur E. Visual attention and applications in multimedia technologies. Proceedings of the IEEE, 2013, 101(9): 2058-2067 doi: 10.1109/JPROC.2013.2265801 [14] Wang J L, Fang Y M, Narwaria M, Lin W S, Le Callet P. Stereoscopic image retargeting based on 3D saliency detection, In: Proceedings of 2014 International Conference on Acoustics, Speech, and Signal Processing. Florence, Italy: IEEE, 2014. 669-673 [15] Kim H, Lee S, Bovik A C. Saliency prediction on stereoscopic videos. IEEE Transactions on Image Processing, 2014, 23(4): 1476-1490 doi: 10.1109/TIP.2014.2303640 [16] Zhang Y, Jiang G Y, Yu M, Chen K. Stereoscopic visual attention model for 3D video. In: Proceedings of the 16th International Conference on Multimedia Modeling. Chongqing, China: Springer, 2010. 314-324 [17] Uherčík M, Kybic J, Zhao Y, Cachard C, Liebgott H. Line filtering for surgical tool localization in 3D ultrasound images. Computers in Biology and Medicine, 2013, 43(12): 2036-2045 doi: 10.1016/j.compbiomed.2013.09.020 [18] Zhao Y, Cachard C, Liebgott H. Automatic needle detection and tracking in 3D ultrasound using an ROI-based RANSAC and Kalman method. Ultrasonic Imaging, 2013, 35(4): 283-306 doi: 10.1177/0161734613502004 [19] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259 doi: 10.1109/34.730558 [20] 胡正平, 孟鹏权.全局孤立性和局部同质性图表示的随机游走显著目标检测算法.自动化学报, 2011, 37(10): 1279-1284 doi: 10.3724/SP.J.1004.2011.01279Hu Zheng-Ping, Meng Peng-Quan. Graph presentation random walk salient object detection algorithm based on global isolation and local homogeneity. Acta Automatica Sinica, 2011, 37(10): 1279-1284 doi: 10.3724/SP.J.1004.2011.01279 [21] Cheng M M, Mitra N J, Huang X L, Torr P H S, Hu S M. Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 569-582 doi: 10.1109/TPAMI.2014.2345401 [22] 唐勇, 杨林, 段亮亮.基于图像单元对比度与统计特性的显著性检测.自动化学报, 2013, 39(10): 1632-1641 doi: 10.3724/SP.J.1004.2013.01632Tang Yong, Yang Lin, Duan Liang-Liang. Image cell based saliency detection via color contrast and distribution. Acta Automatica Sinica, 2013, 39(10): 1632-1641 doi: 10.3724/SP.J.1004.2013.01632 [23] 郭迎春, 袁浩杰, 吴鹏.基于Local特征和Regional特征的图像显著性检测.自动化学报, 2013, 39(8): 1214-1224 doi: 10.3724/SP.J.1004.2013.01214Guo Ying-Chun, Yuan Hao-Jie, Wu Peng. Image saliency detection based on local and regional features. Acta Automatica Sinica, 2013, 39(8): 1214-1224 doi: 10.3724/SP.J.1004.2013.01214 [24] 徐威, 唐振民.利用层次先验估计的显著性目标检测.自动化学报, 2015, 41(4): 799-812 doi: 10.16383/j.aas.2015.c140281Xu Wei, Tang Zhen-Min. Exploiting hierarchical prior estimation for salient object detection. Acta Automatica Sinica, 2015, 41(4): 799-812 doi: 10.16383/j.aas.2015.c140281 [25] Shi K Y, Wang K Z, Lu J, B Lin L. PISA: pixelwise image saliency by aggregating complementary appearance contrast measures with spatial priors. In: Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 2115-2122 [26] Judd T, Ehinger K, Durand F, Torralba A. Learning to predict where humans look. In: Proceedings of the 12th International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 2106-2113 [27] Liu T, Yuan Z J, Sun J, Wang J D, Zheng N N, Tang X O, et al. Learning to detect a salient object. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2): 353-367 doi: 10.1109/TPAMI.2010.70 [28] Wei Y C, Wen F, Zhu W J, Sun J. Geodesic saliency using background priors. In: Proceedings of the 12th European Conference on Computer Vision. Firenze, Italy: Springer, 2012. 29-42 [29] 钱生, 陈宗海, 林名强, 张陈斌.基于条件随机场和图像分割的显著性检测.自动化学报, 2015, 41(4): 711-724 doi: 10.16383/j.aas.2015.c140328Qian Sheng, Chen Zong-Hai, Lin Ming-Qiang, Zhang Chen-Bin. Saliency detection based on conditional random field and image segmentation. Acta Automatica Sinica, 2015, 41(4): 711-724 doi: 10.16383/j.aas.2015.c140328 [30] Shen X H, Wu Y. A unified approach to salient object detection via low rank matrix recovery. In: Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 853-860 [31] Jiang H Z, Wang J D, Yuan Z J, Liu T, Zheng N N, Li S P. Automatic salient object segmentation based on context and shape prior. In: Proceedings of 2011 British Machine Vision Conference. Dundee, UK: BMVA Press, 2011. 110.1-110.12 [32] Yang C, Zhang L H, Lu H C, Ruan X, Yang M H. Saliency detection via graph-based manifold ranking. In: Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 3166-3173 [33] Zhao R, Ouyang W L, Li H S, Wang X G. Saliency detection by multi-context deep learning. In: Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 1265-1274 [34] Li G B, Yu Y Z. Visual saliency detection based on multiscale deep CNN features. IEEE Transactions on Image Processing, 2016, 25(11): 5012-5024 doi: 10.1109/TIP.2016.2602079 [35] Lang C Y, Nguyen T V, Katti H, Yadati K, Kankanhalli M, Yan S C. Depth matters: influence of depth cues on visual saliency. In: Proceedings of 12th European Conference on Computer Vision. Firenze, Italy: Springer, 2012. 101-115 [36] Desingh K, Krishna K M, Rajan D, Jawahar C V. Depth really matters: improving visual salient region detection with depth. In: Proceedings of 2013 British Machine Vision Conference. Bristol, England: BMVA Press, 2013. 98.1-98.11 [37] Niu Y Z, Geng Y J, Li X Q, Liu F. Leveraging stereopsis for saliency analysis. In: Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 454-461 [38] Ju R, Ge L, Geng W J, Ren T W, Wu G S. Depth saliency based on anisotropic center-surround difference. In: Proceedings of 2014 IEEE International Conference on Image Processing. Pairs, France: IEEE, 2014. 1115-1119 http://www.researchgate.net/publication/282375096_Depth_saliency_based_on_anisotropic_center-surround_difference [39] Ren J Q, Gong X J, Yu L, Zhou W H, Yang M Y. Exploiting global priors for RGB-D saliency detection. In: Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Boston, MA, USA: IEEE, 2015. 25-32 http://www.researchgate.net/publication/288507923_Exploiting_global_priors_for_RGB-D_saliency_detection [40] Peng H W, Li B, Xiong W H, Hu W M, Ji R R. RGBD salient object detection: a benchmark and algorithms. In: Proceedings of 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 92-109 [41] Fang Y M, Wang J L, Narwaria M, Le Callet P, Lin W S. Saliency detection for stereoscopic images. IEEE Transactions on Image Processing, 2014, 23(6): 2625-2636 doi: 10.1109/TIP.2014.2305100 [42] Ciptadi A, Hermans T, Rehg J. An in depth view of saliency. In: Proceedings of 2013 British Machine Vision Conference. Bristol, United Kingdom: BMVA Press, 2013. 112.1-112.11 [43] Wu P L, Duan L L, Kong L F. RGB-D salient object detection via feature fusion and multi-scale enhancement. In: Proceedings of 2015 CCF Chinese Conference on Computer Vision. Xi'an, China: Springer, 2015. 359-368 doi: 10.1007/978-3-662-48570-5_35 [44] Iatsun I, Larabi M C, Fernandez-Maloigne C. Using monocular depth cues for modeling stereoscopic 3D saliency. In: Proceedings of 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Florence, Italy: IEEE, 2014. 589-593 [45] Ouerhani N, Hugli H. Computing visual attention from scene depth. In: Proceedings of the 15th International Conference on Pattern Recognition. Barcelona, Spain: IEEE, 2000. 375-378 [46] Xue H Y, Gu Y, Li Y J, Yang J. RGB-D saliency detection via mutual guided manifold ranking. In: Proceedings of 2015 IEEE International Conference on Image Processing. Quebec City, QC, Canada: IEEE, 2015. 666-670 [47] Wang J L, Da Silva M P, Le Callet P, Ricordel V. Computational model of stereoscopic 3D visual saliency. IEEE Transactions on Image Processing, 2013, 22(6): 2151-2165 doi: 10.1109/TIP.2013.2246176 [48] Iatsun I, Larabi M C, Fernandez-Maloigne C. Visual attention modeling for 3D video using neural networks. In: Proceedings of 2014 International Conference on 3D Imaging. Liege, Belglum: IEEE, 2014. 1-8 [49] Fang Y M, Lin W S, Fang Z J, Lei J J, Le Callet P, Yuan F N. Learning visual saliency for stereoscopic images. In: Proceedings of 2014 IEEE International Conference on Multimedia and Expo Workshops. Chengdu, China: IEEE, 2014. 1-6 [50] Bertasius G, Park H S, Shi J B. Exploiting egocentric object prior for 3D saliency detection. arXiv: 1511.02682, 2015. [51] Achanta R, Shaji A, Smith K, Lucchi A, Fua P, Süsstrunk S. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274-2282 doi: 10.1109/TPAMI.2012.120 [52] Qu L Q, He S F, Zhang J W, Tian J D, Tang Y D, Yang Q X. RGBD salient object detection via deep fusion. IEEE Transactions on Image Processing, 2017, 26(5): 2274-2285 doi: 10.1109/TIP.2017.2682981 [53] Gupta S, Hoffman J, Malik J. Cross modal distillation for supervision transfer. In: Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 2827-2836 [54] Shan H H, Banerjee A, Oza N C. Discriminative mixed-membership models. In: Proceedings of the 9th IEEE International Conference on Data Mining. Miami, Florida, USA: IEEE, 2009. 466-475 [55] Wang S T, Zhou Z, Qu H B, Li B. Visual saliency detection for RGB-D images with generative model. In: Proceedings of the 13th Asian Conference on Computer Vision. Taipei, China: Springer, 2016. 20-35 [56] Rish I. An empirical study of the naive Bayes classifier. Journal of Universal Computer Science, 2001, 3(22): 41-46 [57] Blei D M, Jordan M I. Variational inference for dirichlet process mixtures. Bayesian Analysis, 2006, 1(1): 121-143 doi: 10.1214/06-BA104 [58] Sun D Q, Roth S, Black M J. Secrets of optical flow estimation and their principles. In: Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 2432-2439 期刊类型引用(18)
1. 丁先,李汪繁,徐佳敏,臧剑南,吴何来. 融合多策略改进的灰狼优化算法及其在汽轮机转子应力监测上的应用. 汽轮机技术. 2024(02): 138-144 .  百度学术
百度学术2. 吴桂联,陈浩,林佳. 基于组合赋权法和模糊综合评估法对110 kV线路防雷策略的研究. 电瓷避雷器. 2024(05): 21-29+38 . 百度学术3. 李佳媛,张莹. 一个新的单参数填充函数及其在水库年径流预报中的应用. 高等学校计算数学学报. 2023(03): 254-271 . 百度学术4. 姚信威,王佐响,姚远,黄伟. 融合改进天牛须和正余弦的双重搜索优化算法. 小型微型计算机系统. 2022(08): 1644-1652 . 百度学术5. 李子旭,吴凌宇,葛婉贞,赵新超. 一种基于搜索历史信息的粒子群算法. 燕山大学学报. 2022(05): 446-454 . 百度学术6. 张志文,杜文杰,梁君飞,张艳岗,武雅文. 基于燃料电池的复合电源式装载机分层控制. 北京航空航天大学学报. 2022(11): 2165-2176 . 百度学术7. 张新明,姜云,刘尚旺,刘国奇,窦智,刘艳. 灰狼与郊狼混合优化算法及其聚类优化. 自动化学报. 2022(11): 2757-2776 . 本站查看8. 周宏宇,王小刚,单永志,赵亚丽,崔乃刚. 基于改进粒子群算法的飞行器协同轨迹规划. 自动化学报. 2022(11): 2670-2676 . 本站查看9. 王正通,程凤芹,尤文,李双. 基于改进灰狼优化算法的校园电采暖软启动应用. 现代电子技术. 2021(03): 167-171 . 百度学术10. 王正通,程凤芹,尤文,李双. 基于翻筋斗觅食策略的灰狼优化算法. 计算机应用研究. 2021(05): 1434-1437 . 百度学术11. 林安平,李翔,于盈. 环形综合学习粒子群算法研究. 湘南学院学报. 2021(05): 36-42+50 . 百度学术12. 刘耿耿,庄震,郭文忠,陈国龙. VLSI中高性能X结构多层总体布线器. 自动化学报. 2020(01): 79-93 . 本站查看13. 刘庆国,刘新学,武健,李亚雄. 单个天基对地飞行器停泊轨道的优化设计. 系统工程与电子技术. 2020(01): 157-165 . 百度学术14. 杜玉香,赵月爱. 基于PSO优化极限学习机的机器人控制研究. 辽宁科技大学学报. 2020(04): 299-303 . 百度学术15. 龙文,伍铁斌,唐明珠,徐明,蔡绍洪. 基于透镜成像学习策略的灰狼优化算法. 自动化学报. 2020(10): 2148-2164 . 本站查看16. 朱经纬,方虎生,邵发明,蒋成明. 具有自适应弹射机制的粒子群算法. 模式识别与人工智能. 2019(02): 108-116 . 百度学术17. 任林,王东风. 基于QPSO优化模糊—SVM的电站锅炉燃煤结渣特性预测. 山东电力技术. 2019(07): 38-43+60 . 百度学术18. 薛南,吕柏权,倪陈龙. 基于自编码器和填充函数的深度学习优化算法. 电子测量技术. 2019(23): 79-84 . 百度学术其他类型引用(10)
-


 下载:
下载:







计量
- 文章访问数: 5399
- HTML全文浏览量: 805
- PDF下载量: 343
- 被引次数: 28
