

Annotation Scheme and Corpus Construction for Cardiovascular Diseases Risk Factors From Chinese Electronic Medical Records
-
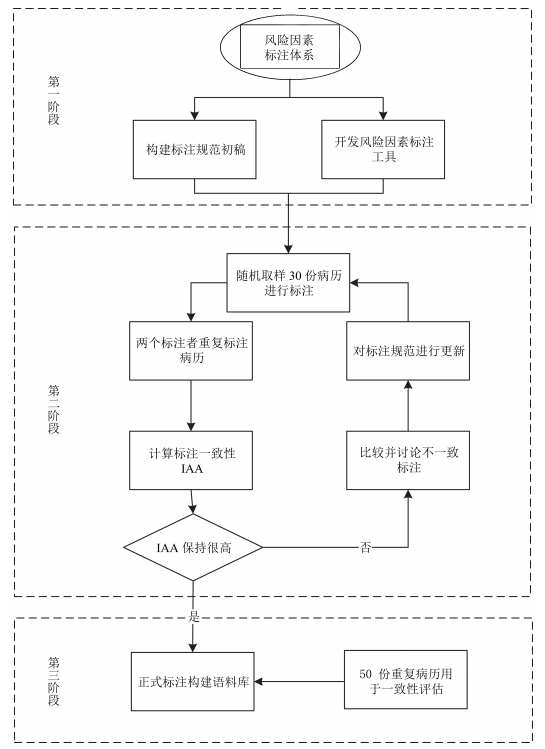
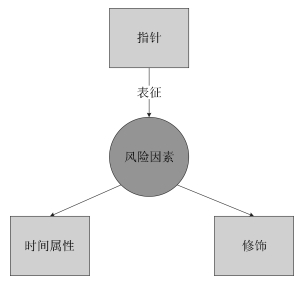
摘要: 本文讨论了从中文电子病历中标注心血管疾病风险因素及其相关信息的问题,提出了适应中文电子病历内容特点的心血管疾病风险因素标注体系,构建了中文健康信息处理领域首份关于心血管疾病风险因素的标注语料库.Abstract: In this paper, the issue of annotating cardiovascular diseases (CVDs) risk factors and the related information from Chinese electronic medical records (CEMRs) is discussed and an annotation scheme of CVDs risk factors appropriate to the content characteristics of CEMRs is put forward. Furthermore, the first annotated corpus of CVDs risk factors in the field of Chinese health information processing is constructed.1) 本文责任编委 张民
-
表 1 中文电子病历心血管疾病风险因素的标注原则
Table 1 Annotation guidelines for CVDs risk factors in CEMR
类别 风险因素 指针 标注原则 超重或肥胖 病历提到 提到体重超重或者肥胖的描述, 如:身材肥胖 腰围值 提到患者的腰围或者腹围值 高血压 病历提到 提到高血压或高血压病史, 如:既往高血压病1年(这里带有持续时间我们将其一同标注) 血压高 提到患者的血压值或任何反映患者血压高的表述, 如:查体: $\cdots$ BP 130/80 mmHg$\cdots$ 调节血压 提到患者需要调压或已有调压效果不理想的描述, 如: 血压控制不理想 药物 明确目的是为了调压的药物, 如:平素口服珍菊降压 糖尿病 病历提到 提到糖尿病或糖尿病病史, 如:无糖尿病病史 血糖高 提到血糖高、血糖的相关检查指标值或者其他可以表明患者血糖高的描述, 如: 随机血糖: 14.5 mmol/L 疾病类 调节血糖 提到患者需要调节血糖或已有调节效果不理想的描述, 如:长期以来血压、血糖控制不佳 药物 明确目的是为了调节血糖的药物、饮食, 如:口服降糖药控制尚可 血脂异常 病历提到 提到血脂异常、高血脂或高血脂史, 如: 高血脂10余年 血脂高 提到患者血脂的相关检查指标值或任何可以表明患者血脂高的描述, 如: 总胆固醇(GPO酶法): 5.39 mmol/L 调节血脂 提到患者需要调脂或已有调脂效果不理想的描述, 如:诊疗计划: 控制血脂 药物 明确目的是为了调脂的药物, 如:调节血脂, 稳定冠脉粥样斑块: 立普妥 20 mg Qn po 慢性肾病 病历提到 提到慢性肾病的描述, 如:病历特点: 肾炎病史20余年 动脉粥样硬化 病历提到 提到动脉粥样硬化、粥样斑块或冠脉狭窄的描述, 如:临床确定诊断: 冠状动脉粥样硬化 阻塞性睡眠呼吸暂停综合征 病历提到 提到阻塞性睡眠呼吸暂停综合征的描述, 如:临床确定诊断:肾囊肿阻塞性睡眠呼吸暂停综合征 吸烟 病历提到 提到患者吸烟或吸烟史的描述, 如: 吸烟40余年 戒烟 提到患者戒烟或未戒烟的描述, 如: 戒烟1年(这里的1年表示戒烟距现在的时常, 不代表吸烟的时间长短, 因此不能反映吸烟的严重程度) 生活方式类 吸烟量 提到患者吸烟量的描述, 如: $\cdots$每天20支 过度饮酒 病历提到 提到患者过度饮酒或饮酒严重程度的描述, 如: 嗜酒40余年 饮酒量 提到患者饮酒量的描述如:饮酒史20余年, 1斤/日 心血管疾病家族史 病历提到 提到患者有心血管疾病家族史或一级亲属(父母、兄弟姐妹、子女)有心血管疾病史, 如:病例特点: $\cdots$母亲患有冠心病$\cdots$ 不可改变类 年龄 病历提到 提到患者的年龄, 如:年龄: 55岁 年龄层 提到患者所处的年龄层, 如: 青年男患 性别 病历提到 提到患者的性别, 如:中年男患  下载: 导出CSV
下载: 导出CSV
表 2 五轮培训的标注一致性
Table 2 The IAA in the training
第一轮 第二轮 第三轮 第四轮 第五轮 $P$ 0.810 0.977 0.967 0.986 0.988 $R$ 0.815 0.977 0.962 0.986 0.988 $F$ 0.812 0.977 0.964 0.986 0.988
下载: 导出CSV
表 3 语料库中各风险因素数量统计
Table 3 The statistics of risk factor annotated corpus
类型 风险因素 数量 疾病类 超重或肥胖 18 高血压 3 729 糖尿病 1 007 血脂异常 372 慢性肾病 26 动脉粥样硬化 144 阻塞性睡眠呼吸暂停综合征 1 行为和生活方式类 吸烟 508 过度饮酒 95 不可改变类 心血管疾病家族史 10 年龄 1 859 性别 1 909
下载: 导出CSV
表 4 心血管疾病诊断实验结果
Table 4 Diagnosis results of CVDs
特征$\backslash$方法 LR RF GBDT XGboost 自述症状+检查结果 0.662 0.672 0.756 0.720 自述症状+检查结果+风险因素 0.675 0.688 0.798 0.811
下载: 导出CSV
-
[1] World Health Organization. Cardiovascular diseases (CVDs)[Online], available:http://www.who.int/mediacentre/factsheets/fs317/en/, November 3, 2017. [2] Gasparyan A Y. Cardiovascular Risk Factor. Rijeka, Croatia:InTech, 2012. 1-102 [3] Friedman C, Kra P, Rzhetsky A. Two biomedical sublanguages:a description based on the theories of Zellig Harris. Journal of Biomedical Informatics, 2002, 35(4):222-235 doi: 10.1016/S1532-0464(03)00012-1 [4] Stubbs A, Uzuner Ö. Annotating risk factors for heart disease in clinical narratives for diabetic patients. Journal of Biomedical Informatics, 2015, 58(S):S78-S91 http://www.sciencedirect.com/science/article/pii/S1532046415000891 [5] Marcus M P, Marcinkiewicz M A, Santorini B. Building a large annotated corpus of English:the Penn Treebank. Computational linguistics, 1993, 19(2):313-330 http://portal.acm.org/citation.cfm?id=972475 [6] Kim J D, Ohta T, Tateisi Y, Tsujii J. GENIA corpus-semantically annotated corpus for bio-textmining. Bioinformatics, 2003, 19(S1):i180-i182 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=HighWire000005822068 [7] Uzuner Ö, Goldstein I, Luo Y, Kohane I. Identifying patient smoking status from medical discharge records. Journal of the American Medical Informatics Association, 2008, 15(1):14-24 doi: 10.1197/jamia.M2408 [8] Uzuner Ö. Recognizing obesity and comorbidities in sparse data. Journal of the American Medical Informatics Association, 2009, 16(4):561-570 doi: 10.1197/jamia.M3115 [9] Uzuner Ö, Solti I, Cadag E. Extracting medication information from clinical text. Journal of the American Medical Informatics Association, 2010, 17(5):514-518 doi: 10.1136/jamia.2010.003947 [10] Uzuner Ö, South B R, Shen S Y, DuVall S L. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. Journal of the American Medical Informatics Association, 2011, 18(5):552-556 doi: 10.1136/amiajnl-2011-000203 [11] Sun W Y, Rumshisky A, Uzuner Ö. Evaluating temporal relations in clinical text:2012 i2b2 Challenge. Journal of the American Medical Informatics Association, 2013, 20(5):806-813 doi: 10.1136/amiajnl-2013-001628 [12] Pradhan S, Elhadad N, South B R, Martinez D, Christensen L, Vogel A, Suominen H, Chapman W W, Savova G. Evaluating the state of the art in disorder recognition and normalization of the clinical narrative. Journal of the American Medical Informatics Association, 2015, 22(1):143-154 doi: 10.1136/amiajnl-2013-002544 [13] Meystre S M, Kim Y, Gobbel G T, Matheny M E, Redd A, Bray B E, Garvin J H. Congestive heart failure information extraction framework for automated treatment performance measures assessment. Journal of the American Medical Informatics Association, 2017, 24(e1):e40-e46 http://jamia.oxfordjournals.org/content/early/2016/07/12/jamia.ocw097 [14] Ford E, Carroll J A, Smith H E, Scott D, Cassell J A. Extracting information from the text of electronic medical records to improve case detection:a systematic review. Journal of the American Medical Informatics Association, 2016, 23(5):1007-1015 doi: 10.1093/jamia/ocv180 [15] Styler IV W F, Bethard S, Finan S, Palmer M, Pradhan S, de Groen P C, Erickson B, Miller T, Lin C, Savova G, Pustejovsky J. Temporal annotation in the clinical domain. Transactions of the Association for Computational Linguistics, 2014, 2:143-154 doi: 10.1162/tacl_a_00172 [16] Bethard S, Savova G, Chen W T, Derczynski L, Pustejovsky J, Verhagen M. Semeval-2016 task 12:clinical tempeval. In:Proceedings of the 2016 SemEval. San Diego, USA:SemEval, 2016. 1052-1062 [17] Roberts A, Gaizauskas R, Hepple M, Demetriou G, Guo Y, Setzer A. Semantic annotation of clinical text:the CLEF corpus. In:Proceedings of the 2008 LREC Workshop on Building and Evaluating Resources for Biomedical Text Mining. Marrakech, Morocco:LREC, 2008. 19-26 [18] Rink B, Harabagiu S, Roberts K. Automatic extraction of relations between medical concepts in clinical texts. Journal of the American Medical Informatics Association, 2011, 18(5):594-600 http://d.old.wanfangdata.com.cn/OAPaper/oai_pubmedcentral.nih.gov_3168312 [19] Quan H D, Sundararajan V, Halfon P, Fong A, Burnand B, Luthi J C, Saunders L D, Beck CA, Feasby T E, Ghali W A. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Medical Care, 2005, 43(11):1130-1139 doi: 10.1097/01.mlr.0000182534.19832.83 [20] Stearns M Q, Price C, Spackman K A, Wang A Y. SNOMED clinical terms:overview of the development process and project status. In:Proceedings of the 2001 AMIA Symposium. Washington DC, USA:AMIA, 2001. 662-666 [21] Bodenreider O. The unified medical language system (UMLS):integrating biomedical terminology. Nucleic Acids Research, 2004, 32(S1):D267-D270 http://d.old.wanfangdata.com.cn/OAPaper/oai_pubmedcentral.nih.gov_2245702 [22] 杨锦锋, 于秋滨, 关毅, 蒋志鹏.电子病历命名实体识别和实体关系抽取研究综述.自动化学报, 2014, 40 (8):1537-1562 http://www.aas.net.cn/CN/abstract/abstract18425.shtmlYang Jin-Feng, Yu Qiu-Bin, Guan Yi, Jiang Zhi-Peng. An overview of research on electronic medical record oriented named entity recognition and entity relation extraction. Acta Automatica Sinica, 2014, 40(8):1537-1562 http://www.aas.net.cn/CN/abstract/abstract18425.shtml [23] Lei J B. Named Entity Recognition in Chinese Clinical Text[Ph.D. dissertation], The University of Texas, USA, 2014. [24] Xu Y, Wang Y, Liu T, Liu J, Fan Y, Qian Y. Joint segmentation and named entity recognition using dual decomposition in Chinese discharge summaries. Journal of the American Medical Informatics Association, 2014, 21(e1):e84-e92 doi: 10.1136/amiajnl-2013-001806 [25] Wang H, Zhang W D, Zeng Q, Li Z F, Feng K Y, Liu L. Extracting important information from Chinese Operation Notes with natural language processing methods. Journal of Biomedical Informatics, 2014, 48:130-136 doi: 10.1016/j.jbi.2013.12.017 [26] Wu Y H, Jiang M, Lei J B, Xu H. Named entity recognition in Chinese clinical text using deep neural network. Studies in Health Technology & Informatics, 2015, 216:624-628 http://europepmc.org/articles/PMC4624324 [27] Lei J B, Tang B Z, Lu X Q, Gao K H, Jiang M, Xu H. A comprehensive study of named entity recognition in Chinese clinical text. Journal of the American Medical Informatics Association, 2014, 21(5):808-814 doi: 10.1136/amiajnl-2013-002381 [28] Wang Y Q, Yu Z H, Chen L, Chen Y H, Liu Y G, Hu X G. Supervised methods for symptom name recognition in free-text clinical records of traditional Chinese medicine:an empirical study. Journal of Biomedical Informatics, 2014, 47:91-104 doi: 10.1016/j.jbi.2013.09.008 [29] Stubbs A, Kotfila C, Xu H, Uzuner Ö. Identifying risk factors for heart disease over time:overview of 2014 i2b2/UTHealth shared task Track 2. Journal of Biomedical Informatics, 2015, 58(S):S67-S77 http://www.sciencedirect.com/science/article/pii/S1532046415001409 [30] World Heart Federation. Cardiovascular disease risk factors[Online], available:https://www.world-heart-federation.org/resources/risk-factors/, March 28, 2017. [31] Tesseract[Online], available:https://github.com/tesseract-ocr, November 3, 2017. [32] Artstein R, Poesio M. Inter-coder agreement for computational linguistics. Computational Linguistics, 2008, 34(4):555-596 doi: 10.1162/coli.07-034-R2 [33] Chen T Q, Guestrin C. Xgboost:a scalable tree boosting system. In:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA:ACM, 2016. 785-794 -

 下载:
下载:

图(2) / 表(4)
计量
- 文章访问数: 2585
- HTML全文浏览量: 597
- PDF下载量: 838
- 被引次数: 0
