

-
摘要: 针对从给定2D特征点的单目图像中重构对象的3D形状问题,本文在形状空间模型的基础上,结合L1/2正则化和谱范数的性质提出一种基于L1/2正则化的凸松弛方法,将形状空间模型的非凸求解问题通过凸松弛方法转化为凸规划问题;在采用ADMM算法对凸规划问题进行优化求解过程中,提出谱范数近端梯度算法保证解的正交性与稀疏性.利用所提的优化方法,基于形状空间模型和3D可变形状模型在卡内基梅隆大学运动捕获数据库上进行3D人体姿态重构,定性和定量对比实验结果表明本文方法均优于现有的优化方法,验证了所提方法的有效性.Abstract: In order to estimate the 3D shape with the given 2D feature points for a single image, we present a convex relaxation approach based on L1/2 regularization by using the shape space model and combining L1/2 regularization and the properties of spectral norm. Thereby we transform the non-convex optimization problem in a shape space model into a convex programming problem. When optimizing the solution to the convex programming problem by using the ADMM algorithm, we further propose a spectral norm proximal operator to satisfy the orthogonality and sparsity constraint of the solution. Using the proposed optimization algorithm, we conduct experiments on the CMU motion capture dataset for 3D human body pose reconstruction based on the shape space model and 3D deformable shape model. Comparison experimental results show qualitatively and quantitatively that the proposed algorithm outperforms the existing optimization algorithms. The effectiveness of the proposed algorithm is validated.
-
Key words:
- 3D reconstruction /
- sparse representation /
- L1/2 regularization /
- convex program
1) 本文责任编委 杨健 -
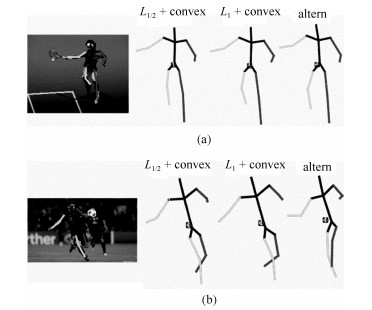
图 1 三种方法的定性实验效果对比图
Fig. 1 The comparison of qualitative experiment results of three methods

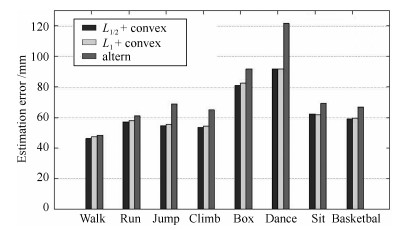
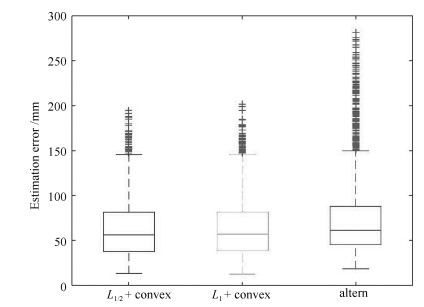
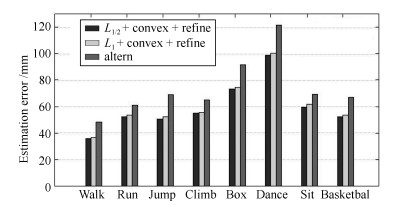
图 5 三种方法的定性实验效果对比图
Fig. 5 The qualitative experiment effect contrast chart of the three methods
-
[1] Fidler S, Dickinson S, Urtasun R. 3D object detection and viewpoint estimation with a deformable 3D cuboid model. In: Proceedings of the 2012 International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012. 611-619 http://dl.acm.org/citation.cfm?id=2999134.2999203 [2] Simo-Serra E, Quattoni A, Torras C, Moreno-Noguer F. A joint model for 2D and 3D pose estimation from a single image. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 3634-3641 http://dl.acm.org/citation.cfm?id=2516195 [3] Cootes T F, Taylor C J, Cooper D H, Graham J. Active shape models-their training and application. Computer Vision and Image Understanding, 1995, 61(1): 38-59 doi: 10.1006/cviu.1995.1004 [4] Hejrati M, Ramanan D. Analyzing 3D objects in cluttered images. In: Proceeding of the 2012 International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012. 593-601 http://dl.acm.org/citation.cfm?id=2999134.2999201 [5] Zia M Z, Stark M, Schiele B, Schindler K. Detailed 3d representations for object recognition and modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2608-2623 doi: 10.1109/TPAMI.2013.87 [6] 方红, 杨海蓉.贪婪算法与压缩感知理论.自动化学报, 2011, 37(12): 1413-1421 http://www.aas.net.cn/CN/abstract/abstract17639.shtmlFang Hong, Yang Hai-Rong. Greedy algorithms and compressed sensing. Acta Automatica Sinica, 2011, 37(12): 1413-1421 http://www.aas.net.cn/CN/abstract/abstract17639.shtml [7] 周瑜, 刘俊涛, 白翔.形状匹配方法研究与展望.自动化学报, 2012, 38(6): 889-910 http://www.aas.net.cn/CN/abstract/abstract13357.shtmlZhou Yu, Liu Jun-Tao, Bai Xiang. Research and perspective on shape matching. Acta Automatica Sinica, 2012, 38(6): 889-910 http://www.aas.net.cn/CN/abstract/abstract13357.shtml [8] Wang C Y, Wang Y Z, Lin Z C, Yuille A L, Gao W. Robust estimation of 3D human poses from a single image. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE, 2014. 2369-2376 http://arxiv.org/abs/1406.2282 [9] Blanz V, Vetter T. Face recognition based on fitting a 3D morphable model. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(9): 1063-1074 doi: 10.1109/TPAMI.2003.1227983 [10] Gu L, Kanade T. 3D alignment of face in a single image. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA: IEEE, 2006. 1305-1312 http://dl.acm.org/citation.cfm?id=1153537 [11] Cao C, Weng Y L, Lin S, Zhou K. 3D shape regression for real-time facial animation. ACM Transactions on Graphics, 2013, 32(4): Article No. 41 https://download.csdn.net/download/u012496255/7799641 [12] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK, USA: IEEE, 2008. 1-8 doi: 10.1109/CVPR.2008.4587597 [13] Lin Y L, Morariu V I, Hsu W, Davis L S. Jointly optimizing 3D model fitting and fine-grained classification. In: Proceedings of the 2014 European Conference on Computer Vision, Lecture Notes in Computer Science, Vol. 8692. Heidelberg, Berlin, Germany: Springer, 2014. 466-480 doi: 10.1007/978-3-319-10593-2_31 [14] Ramakrishna V, Kanade T, Sheikh Y. Reconstructing 3D human pose from 2D image landmarks. In: Proceedings of the 2012 European Conference on Computer Vision, Lecture Notes in Computer Science, Vol. 7575. Heidelberg, Berlin, Germany: Springer, 2012. 573-586 doi: 10.1007/978-3-642-33765-9_41 [15] Fan X C, Zheng K, Zhou Y J, Wang S. Pose locality constrained representation for 3D human pose reconstruction. In: Proceedings of the 2014 European Conference on Computer Vision, Lecture Notes in Computer Science, Vol. 8689. Heidelberg, Berlin, Germany: Springer, 2014. 174-188 [16] Zhou F, de la Torre F. Spatio-temporal Matching for human detection in video. In: Proceedings of the 2014 Computer Vision, Lecture Notes in Computer Science, Vol. 8694. Heidelberg, Berlin, Germany: Springer, 2014. 62-77 [17] Akhter I, Black M J. Pose-conditioned joint angle limits for 3D human pose reconstruction. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 1446-1455 https://www.researchgate.net/publication/298380919_Pose-Conditioned_Joint_Angle_Limits_for_3D_Human_Pose_Reconstruction [18] Cashman T J, Fitzgibbon A W. What shape are dolphins? Building 3D morphable models from 2D images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 232-244 doi: 10.1109/TPAMI.2012.68 [19] Vicente S, Carreira J, Agapito L, Batosta J. Reconstructing PASCAL VOC. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 41-48 http://dl.acm.org/citation.cfm?id=2679600.2679960 [20] Carreira J, Kar A, Tulsiani S, Malik J. Virtual view networks for object reconstruction. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 2937-2946 http://arxiv.org/abs/1411.6091 [21] Kar A, Tulsiani S, Carreira J, Malik J. Category-specific object reconstruction from a single image. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 1966-1974 http://arxiv.org/abs/1411.6069 [22] Su H, Huang Q X, Mitra N J, Li Y Y, Guibas L. Estimating image depth using shape collections. ACM Transactions on Graphics, 2014, 33(4): Article No. 37 http://vecg.cs.ucl.ac.uk/Projects/SmartGeometry/image_shape_net/imageShapeNet_sigg14.html [23] Huang Q X, Wang H, Koltun V. Single-view reconstruction via joint analysis of image and shape collections. ACM Transactions on Graphics, 2015, 34(4): Article No. 87 http://vladlen.info/publications/single-view-reconstruction-via-joint-analysis-of-image-and-shape-collections/ [24] Zhou X W, Leonardos S, Hu X Y, Daniilidis K. 3D shape estimation from 2d landmarks: a convex relaxation approach. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 4447-4455 http://ieeexplore.ieee.org/document/7299074/ [25] Zhou X W, Zhu M L, Leonardos S, Daniilidis K. Sparse representation for 3D shape estimation: a convex relaxation approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(8): 1648-1661 doi: 10.1109/TPAMI.2016.2605097 [26] Tibshirani R. Regression shrinkage and selection via the lasso: a retrospective. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 2011, 73(3): 273-282 doi: 10.1111/rssb.2011.73.issue-3 [27] Chen S, Donoho D. Basis pursuit. In: Proceedings of the 1994 Conference Record of the Twenty-Eighth Asilomar Conference on Signals, Systems and Computers. Pacific Grove, CA, USA: IEEE, 2002, 1: 41-44 [28] Chen S S, Donoho D L, Saunders M A. Atomic decomposition by basis pursuit. Siam Review, 2001, 43(1): 129-159 doi: 10.1137/S003614450037906X [29] Elad M, Bruckstein A M. A generalized uncertainty principle and sparse representation in pairs of bases. IEEE Transactions on Information Theory, 2002, 48(9): 2558-2567 doi: 10.1109/TIT.2002.801410 [30] Donoho D L, Huo X. Uncertainty principles and ideal atomic decomposition. IEEE Transactions on Information Theory, 2001, 47(7): 2845-2862 doi: 10.1109/18.959265 [31] Xu Z B, Zhang H, Wang Y, Change X Y, Liang Y. L1/2 regularization. Science China Information Sciences, 2010, 53(6): 1159-1169 doi: 10.1007/s11432-010-0090-0 [32] Del Bue A, Xavier J, Agapito L, Paladini M. Bilinear modeling via augmented lagrange multipliers (BALM). IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(8): 1496-1508 doi: 10.1109/TPAMI.2011.238 [33] Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 2010, 3(1): 1-122 http://www.nowpublishers.com/article/Details/MAL-016 [34] Parikh N, Boyd S. Proximal algorithms. Foundations and Trends in Optimization, 2013, 1(3): 123-231 https://web.stanford.edu/~boyd/papers/prox_algs.html [35] Mairal J, Bach F, Ponce J, Sapiro G. Online learning for matrix factorization and sparse coding. Journal of Machine Learning Research, 2010, 11: 19-60 https://www.researchgate.net/publication/45865402_Online_Learning_for_Matrix_Factorization_and_Sparse_Coding [36] Mocap: Carnegie Mellon university motion capture database[Online], available: http://Mocap.cs.cmu.edu/, March 1, 2017 [37] 朱煜, 赵江坤, 王逸宁, 郑兵兵.基于深度学习的人体行为识别算法综述.自动化学报, 2016, 42(6): 848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtmlZhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6): 848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtml [38] Zhou X W, Zhu M L, Pavlakos G, Leonardos S, Derpanis K G, Daniilidis K. MonoCap: monocular human motion capture using a CNN coupled with a geometric prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, DOI: 10.1109/TPAMI.2018.2816031 [39] Zhou X W, Zhu M L, Leonardos S, Derpanis K G, Daniilidis K. Sparseness meets deepness: 3D human pose estimation from monocular video. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 4966-4975 -

 下载:
下载:

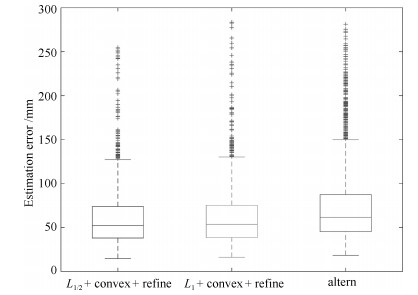


图(8)
计量
- 文章访问数: 2222
- HTML全文浏览量: 327
- PDF下载量: 806
- 被引次数: 0
