

-
摘要: 室内定位是近些年国内外研究的热点, 但是目前的室内定位技术在适用性、稳定性和推广性方面仍然存在诸多问题.针对目前室内定位技术的不足, 面向公共室内场景的人员自定位问题, 本文创新性地提出以室内广泛存在、均匀分布的消防安全出口标志为路标(Landmark), 提出以Wi-Vi指纹-WiFi与视觉(Vision)信息相融合的指纹, 为位置表征的多尺度定位方法.该方法首先利用室内广泛存在的WiFi无线信号进行粗定位, 缩小定位范围; 然后在WiFi定位的基础上通过视觉全局和局部特征匹配实现图像级定位和验证; 最后参考消防安全出口标志的空间坐标精确计算用户的位置信息.实验中, 通过市面上流行的不同型号智能手机在12 000平米办公楼和4万平米商场分别进行实地定位测试.测试结果表明:该方法可以达到实时定位的要求, 图像级定位准确率均在97 %以上, 平均定位误差均在0.5米以下.本文所提出的基于Wi-Vi指纹智能手机定位方法为高精度室内定位问题建议了一种新的解决思路.Abstract: Indoor positioning is a hot research topic in recent years. Existing methods still have the problems of poor applicability and low stability in different indoor situations. Aiming at solving the localization problem for public indoor environment, this paper for the first time proposes to use exit signs as landmarks that are widely distributed in the indoor environment. By applying these landmarks, a novel multi-scale positioning method is proposed based on Wi-Vi Fingerprint - WiFi and vision integrated fingerprint. The proposed method consists of coarse positioning from WiFi matching, image-level positioning and verification from holistic and local visual feature matching, and positioning refinement from metric positioning based on the space coordinates of exit sign. The proposed method has been tested in an indoor office building of 12 000 square meters and a shopping mall of 40 000 square meters, respectively, by using different smartphones. Experimental results show that the proposed Wi-Vi fingerprint method can achieve real-time positioning with more than 97 % accuracy rate for image-level positioning. In both test scenarios, the average positioning errors are less than half meters. The proposed Wi-Vi fingerprint method suggests a new solution to accurate indoor positioning.
-
Key words:
- Indoor positioning /
- WiFi fingerprint /
- vision-based positioning /
- multi-scale positioning
1) 本文责任编委 徐德 -
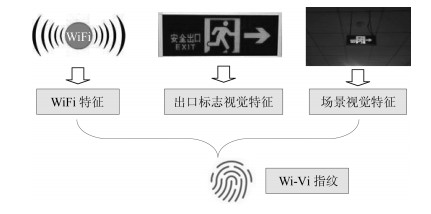
图 1 WiFi与视觉相融合的定位指纹— Wi-Vi指纹
Fig. 1 WiFi and vision integrated positioning fingerprint — Wi-Vi fingerprint

图 3 基于Wi-Vi指纹定位的Android软件使用示意图
Fig. 3 Illustration of the Wi-Vi based Android application
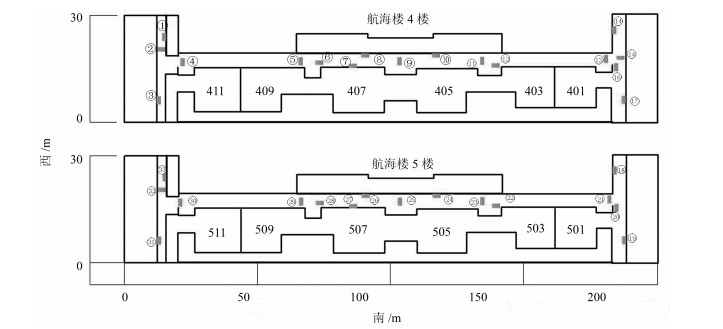
图 4 办公楼4、5楼CAD平面图(方块表示标志消防安全出口标志; 预先对每个出口标志进行编号)
Fig. 4 CAD map of the fourth and fifth floor of office building (Exit signs are represented by blocks; Exit signs are pre-numbered)
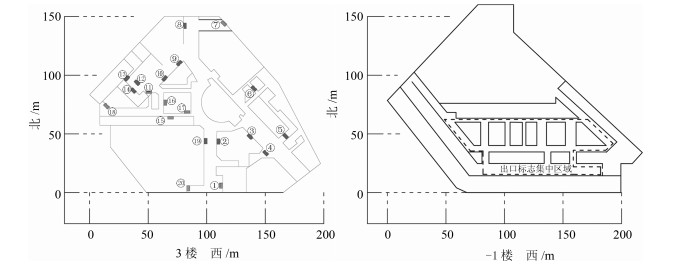
图 5 奥山世纪城3楼和−1楼CAD平面图(方块表示消防安全出口标志, −1楼标志过于密集, 仅用虚线标出出口标志集中区域; 预先对每个出口标志进行编号)
Fig. 5 CAD map of the third floor and −1st floor of Orsun century city (Exit signs are represented by blocks, signs of −1st floor are not listed here due to too dense of signs; Exit signs are pre-numbered)
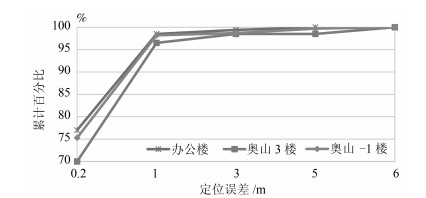
图 10 度量级定位修正后的最终定位结果
Fig. 10 The results of final positioning after matric positioning
表 1 Wi-Vi指纹
Table 1 Wi-Vi fingerprint
索引 Wi-Vi特征 值 1 WiFi指纹 MAC [00238975abc0, 24dec63766a0, 24dec637ac40, 24dec638f120, 00238979acc0, 002389799c80, 24dec6379740, 24dec6390fe0, 24dec63905e0, 24dec6376f40, 002389798be0, 00238975b1b0] RSSI (dBm) [-81, -81, -83, -81, -63, -81, -82, -73, -78, -83, -86, -85] 图像数据 全局特征 [211, 80, 47, 62, 40, 234, 93, 24, 180, 91, 195, 245, 215, 156, 59, 121, 196, 129, 255, 199, 175, 5, 119, 117, 209, 35, 120, 129, 124, 85, 190, 83] 局部特征 (416, 306), [157, 73, 7, 244, 149, 70, 239, 252, 148, 226, 66, 66, 113, 99, 49, 227, 88, 100, 50, 239, 105, 212, 61, 174, 41, 139, 239, 4, 63, 121, 48, 160] …… 单应矩阵 [1.1, 3.2, 336.0; 0, 3.5, 281.0; 0, 0, 1] 参考坐标(mm) (8 000, 7 800, 2 200); (8 000, 8 050, 2 200); (8 000, 8 050, 1 050); (8 000, 7 800, 1 050)  下载: 导出CSV
下载: 导出CSV
-
[1] Wang B, Chen Q Y, Yang L T, Chao H C. Indoor smartphone localization via fingerprint crowdsourcing: challenges and approaches. IEEE Wireless Communications, 2016, 23(3): 82-89 doi: 10.1109/MWC.2016.7498078 [2] 陈锐志, 陈亮.基于智能手机的室内定位技术的发展现状和挑战.测绘学报, 2017, 46(10): 1316-1326 doi: 10.11947/j.AGCS.2017.20170383Chen Rui-Zhi, Chen Liang. Indoor positioning with smartphones: the state-of-the-art and the challenges. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1316-1326 doi: 10.11947/j.AGCS.2017.20170383 [3] Subbu K, Zhang C, Luo J, Vasilakos A. Analysis and status quo of smartphone-based indoor localization systems. IEEE Wireless Communications, 2014, 21(4): 106-112 doi: 10.1109/MWC.2014.6882302 [4] 王飞, 崔金强, 陈本美, 李崇兴.一套完整的基于视觉光流和激光扫描测距的室内无人机导航系统.自动化学报, 2013, 39(11): 1889-1900 doi: 10.3724/SP.J.1004.2013.01889Wang Fei, Cui Jin-Qiang, Chen Ben-Mei, Lee T H. A comprehensive UAV indoor navigation system based on vision optical flow and laser FastSLAM. Acta Automatica Sinica, 2013, 39(11): 1889-1900 doi: 10.3724/SP.J.1004.2013.01889 [5] Davidson P, Piché R. A survey of selected indoor positioning methods for smartphones. IEEE Communications Surveys & Tutorials, 2017, 19(2): 1347-1370 [6] 桂振文, 吴侹, 彭欣.一种融合多传感器信息的移动图像识别方法.自动化学报, 2015, 41(8): 1394-1404 doi: 10.16383/j.aas.2015.c140177Gui Zhen-Wen, Wu Ting, Peng Xin. A novel recognition approach for mobile image fusing inertial sensors. Acta Automatica Sinica, 2015, 41(8): 1394-1404 doi: 10.16383/j.aas.2015.c140177 [7] Khalajmehrabadi A, Gatsis N, Pack D J, Akopian D. A joint indoor WLAN localization and outlier detection scheme using LASSO and elastic-net optimization techniques. IEEE Transactions on Mobile Computing, 2017, 16(8): 2079-2092 doi: 10.1109/TMC.2016.2616465 [8] Au A W S, Feng C, Valaee S, Reyes S, Sorour S, Markowitz S N, et al. Indoor tracking and navigation using received signal strength and compressive sensing on a mobile device. IEEE Transactions on Mobile Computing, 2013, 12(10): 2050-2062 doi: 10.1109/TMC.2012.175 [9] 袁鑫, 吴晓平, 王国英.线性最小二乘法的RSSI定位精确计算方法.传感技术学报, 2014, 27(10): 1412-1417 doi: 10.3969/j.issn.1004-1699.2014.10.020Yuan Xin, Wu Xiao-Ping, Wang Guo-Ying. Accurate computation approach of RSSI-based localization with linear least square method. Chinese Journal of Sensors and Actuators, 2014, 27(10): 1412-1417 doi: 10.3969/j.issn.1004-1699.2014.10.020 [10] Zhuang Y, Yang J, Li Y, Qi L N, N. Smartphone-based indoor localization with Bluetooth low energy beacons. Sensors, 2016, 16(5): Article No. 596 [11] Xiao J, Wu K S, Yi Y W, Wang L, Ni L M. Pilot: passive device-free indoor localization using channel state information. In: Proceedings of the 33rd IEEE International Conference on Distributed Computing Systems. Philadelphia, PA, USA: IEEE, 2013. 236-245 [12] Song Q W, Guo S T, Liu X, Yang Y Y. CSI amplitude fingerprinting based NB-IoT indoor localization. IEEE Internet of Things Journal, 2017, DOI: 10.1109/JIOT.2017.2782479 [13] He S N, Hu T Y, Chan S H G. Contour-based trilateration for indoor fingerprinting localization. In: Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems. Seoul, South Korea: ACM, 2015. 225-238 [14] 李炜, 金亮, 陈曦.基于Android平台的室内定位系统设计与实现.华中科技大学学报(自然科学版), 2013, 41(S1): 422-424 http://d.old.wanfangdata.com.cn/Conference/8300488Li Wei, Jin Liang, Chen Xi. Indoor positioning system design and implementation based on Android platform. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2013, 41(S1): 422-424 http://d.old.wanfangdata.com.cn/Conference/8300488 [15] Shen L L, Hui W W S. Improved pedestrian Dead-Reckoning-based indoor positioning by RSSI-based heading correction. IEEE Sensors Journal, 2016, 16(21): 7762-7773 doi: 10.1109/JSEN.2016.2600260 [16] 李楠, 陈家斌, 袁燕.基于WiFi/PDR的室内行人组合定位算法.中国惯性技术学报, 2017, 25(4): 483-487 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zggxjsxb201704011Li Nan, Chen Jia-Bin, Yuan Yan. Indoor pedestrian integrated localization strategy based on WiFi/PDR. Journal of Chinese Inertial Technology, 2017, 25(4): 483-487 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zggxjsxb201704011 [17] Liu Z G, Zhang L M, Liu Q, Yin Y F, Cheng L, Zimmermann R. Fusion of magnetic and visual sensors for indoor localization: infrastructure-free and more effective. IEEE Transactions on Multimedia, 2017, 19(4): 874-888 doi: 10.1109/TMM.2016.2636750 [18] Elloumi W, Latoui A, Canals R, Chetouani A, Treuillet S. Indoor pedestrian localization with a smartphone: a comparison of inertial and vision-based methods. IEEE Sensors Journal, 2016, 16(13): 5376-5388 doi: 10.1109/JSEN.2016.2565899 [19] Guan K, Ma L, Tan X Z. Vision-based indoor localization approach based on SURF and landmark. In: Proceedings of the 2016 International Wireless Communications and Mobile Computing Conference (IWCMC). Paphos, Cyprus: IEEE, 2016. 655-659 [20] Fang J B, Yang Z, Long S, Wu Z Q, Zhao X M, Liang F N, et al. high-speed indoor navigation system based on visible light and mobile phone. IEEE Photonics Journal, 2017, 9(2): Article No. 8200711 [21] Hu Z Z, Huang G, Hu Y Z, Yang Z. WI-VI fingerprint: WiFi and vision integrated fingerprint for smartphone-based indoor self-localization. In: Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP). Beijing, China: IEEE, 2017. 4402-4406 [22] Dong J, Xiao Y, Noreikis M, Ou Z H, Ylä-Jääski A. iMoon: using smartphones for image-based indoor navigation. In: Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems. Seoul, South Korea: ACM, 2015. 85-97 [23] 李乃鹏.视觉-WiFi联合无线终端用户识别算法研究[硕士学位论文], 北京交通大学, 中国, 2016Li Nai-Peng. Research on Wireless Terminal User Identification Algorithm Based on Vision and Wi-Fi Network[Master dissertation], Beijing Jiaotong University, China, 2016 [24] 消防安全标志设置要求, GB 15630-1995, 2004Requirements for the Placement of Fire Safety Signs, GB 15630-1995, 2004 [25] 消防应急照明和疏散指示系统, GB 17945-2010, 2011Fire Emergency Lighting and Evacuate Indicating System, GB 17945-2010, 2011 [26] Rublee E, Rabaud V, Konolige K, Bradski G. ORB: an efficient alternative to SIFT or SURF. In: Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV). Barcelona, Spain: IEEE, 2011. 2564-2571 [27] Wu C C. VisualSFM: a visual structure from motion system[Online], available: http://ccwu.me/vsfm/, January 22, 2018 -

 下载:
下载:





计量
- 文章访问数: 2245
- HTML全文浏览量: 712
- PDF下载量: 251
- 被引次数: 0
