

Video Face Recognition Based on Modified Fisher Criteria and Multi-instance Learning
-
摘要: 视频环境下目标的姿态变化使得人脸关键帧难以准确定位,导致基于关键帧标识的视频人脸识别方法的识别率偏低.为解决上述问题,本文提出一种基于Fisher加权准则的多示例学习视频人脸识别算法.该算法将视频人脸识别视为一个多示例问题,将视频中归一化后的人脸帧图像作为视频包中的示例,采用分块TPLBP级联直方图作为示例纹理特征,示例特征的权值通过改进的Fisher准则获得.在训练集合的示例特征空间中,采用多示例学习算法生成分类器,进而实现对测试视频的分类及预测.通过在Honda/UCSD视频库和Youtube Face数据库中的相关实验,该算法达到了较高的识别精度,从而验证了算法的有效性.同时,该方法对均匀光照变化、姿态变化等具有良好的鲁棒性.Abstract: Due to the pose variation of target in video, it is difficult to accurately locate the face key frame and have a high recognition rate of the video face recognition based on key frame identification. To solve these problems, a video face recognition algorithm based on multi-instance learning is proposed in this paper. The algorithm takes each face video as a bag, and each normalized face frame as an instance in the bag. The feature of each instance is represented by cascading histograms of block TPLBP codes, and the weight of the instance feature is obtained by the improved Fisher criteria. The classifier is obtained in the feature space of training set by using a multiple instance learning algorithm, and then classification and prediction of test bag are realized. Experiments on the Honda/UCSD and YouTube Face databases show that the algorithm can achieve a higher recognition accuracy, and at the same time, the method is robust to illumination variation and expression variation.1) 本文责任编委 杨健
-
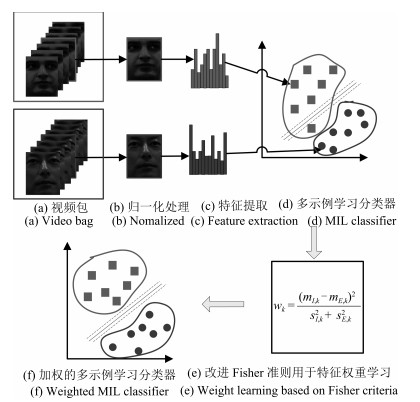
图 1 本文提出的基于多示例学习框架的视频人脸识别算法框架
Fig. 1 The framework of proposed video face recognition algorithm based on multi-instance learning

图 2 通过局部分块特征直方图级联表示人脸示例纹理
Fig. 2 Face instance texture is represented by cascading local block feature histogram
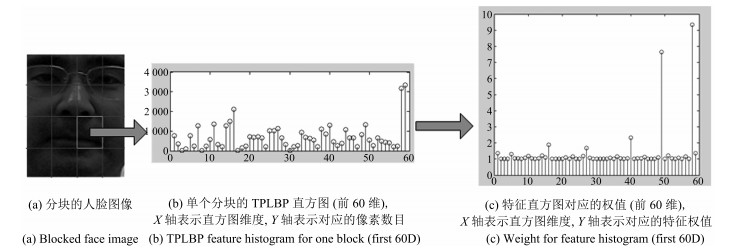
图 3 分块TPLBP特征直方图(前60维)及各特征值对应的权值
Fig. 3 Feature value of the TPLBP histogram (the first 60 dimensions) and the corresponding weights
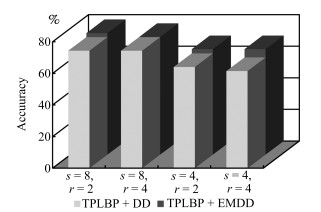
图 4 参数$S$和$\gamma$对算法性能的影响
Fig. 4 Parameter $S$ and $\gamma$ $'$s effect on the performance of the algorithm
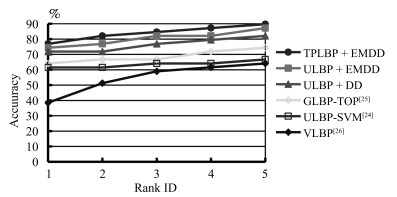
图 5 不同算法在Honda/UCSD上的CMC曲线
Fig. 5 The CMC curves of different algorithms on Honda/UCSD databases
表 1 LBP算子不同参数在Honda/UCSD视频人脸数据库中的首选识别率
Table 1 Recognition rate of different parameters of LBP operator on Honda/UCSD database
Algorithm $P$ $R$ Dim Accuracy (%) ULBP + DD 8 1 59 71.8 ULBP + DD 4 1 15 66.7 ULBP + DD 8 2 59 71.8 ULBP + DD 4 2 15 64.1 LBP + DD 8 1 256 76.9 LBP + DD 4 1 16 66.7 LBP + DD 8 2 256 74.4 LBP + DD 4 2 16 66.7  下载: 导出CSV
下载: 导出CSV
表 2 TPLBP算子不同参数在Honda/UCSD视频人脸数据库中的首选识别率
Table 2 Recognition rate of different parameters of TPLBP operator on Honda/UCSD database
Algorithm $S$ $\gamma$ $\omega$ $\alpha$ Dim Accuracy TPLBP + EMDD 8 2 3 5 256 76.9 TPLBP + EMDD 4 2 3 5 16 66.7 TPLBP + EMDD 8 4 3 5 256 74.4 TPLBP + EMDD 4 4 3 5 16 66.7
下载: 导出CSV
表 3 不同算法在Honda/UCSD视频人脸数据库中的首选识别率
Table 3 Recognition rate of different algorithms on Honda/UCSD database
下载: 导出CSV
表 4 不同算法在YouTube Face视频人脸数据库中的首选识别率(%)
Table 4 Recognition rate of different algorithms on YouTube Face database (%)
类型 算法 TPLBP LBP 1 min dist 71.53 70.66 1 max dist 62.1 61.06 1 mean dist 69.68 68.34 1 median dist 69.86 68.16 2 most frontal 68.54 66.5 2 nearest pose 67.53 66.87 3 MSM 68.34 66.19 3 $\left \|U_1^TU_2\right \|$ 71.31 69.78 4 Proposed 75.28 73.43
下载: 导出CSV
-
[1] Barr J R, Bowyer K W, Flynn P J, Biswas S. Face recognition from video:a review. International Journal of Pattern Recognition and Artificial Intelligence, 2012, 26(5):Article No. 1266002 doi: 10.1142/S0218001412660024 [2] Belhumer P N, Hespanha J P, Kriegman D J. Eigenfaces vs fisherfaces:recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7):711-720 doi: 10.1109/34.598228 [3] Wang R P, Shan S G, Chen X L, Gao W. Manifold-manifold distance with application to face recognition based on image set. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK, USA: IEEE, 2008. 1-8 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=4587719 [4] Huang Z W, Wang R P, Shan S G, Chen X L. Projection metric learning on Grassmann manifold with application to video based face recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 140-149 http://www.mendeley.com/catalog/projection-metric-learning-grassmann-manifold-application-video-based-face-recognition/ [5] Harandi M T, Sanderson C, Shirazi S, Lovell B C. Graph embedding discriminant analysis on Grassmannian manifolds for improved image set matching. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO, USA: IEEE, 2011. 2705-2712 http://www.mendeley.com/catalog/graph-embedding-discriminant-analysis-grassmannian-manifolds-improved-image-set-matching/ [6] Yang M, Zhu P F, van Gool L, Zhang L. Face recognition based on regularized nearest points between image sets. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Shanghai, China: IEEE, 2013. 1-7 https://ieeexplore.ieee.org/document/6553727 [7] Hu Y Q, Mian A S, Owens R. Sparse approximated nearest points for image set classification. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado Springs, CO, USA, USA: IEEE, 2011. 121-128 http://dl.acm.org/citation.cfm?id=2192133 [8] Wang R P, Guo H M, Davis L S, Dai Q H. Covariance discriminative learning: a natural and efficient approach to image set classification. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA: IEEE, 2012. 2496-2503 http://www.mendeley.com/catalog/covariance-discriminative-learning-natural-efficient-approach-image-set-classification/ [9] Cevikalp H, Triggs B. Face recognition based on image sets. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 2567-2573 https://ieeexplore.ieee.org/document/5539965 [10] Hu Y Q, Mian A S, Owens R. Face recogniton using sparse approximated nearest points between image sets. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10):1992-2004 doi: 10.1109/TPAMI.2011.283 [11] 于谦, 高阳, 霍静, 庄韫恺.视频人脸识别中判别性联合多流形分析.软件学报, 2015, 26(11):2897-2911 http://d.old.wanfangdata.com.cn/Periodical/rjxb201511013Yu Qian, Gao Yang, Huo Jing, Zhuang Yun-Kai. Discriminative joint multi-manifold analysis for video-based face recognition. Journal of Software, 2015, 26(11):2897-2911 http://d.old.wanfangdata.com.cn/Periodical/rjxb201511013 [12] Zhao G Y, Ahonen T, Matas J, Pietikainen M. Rotation-invariant image and video description with local binary pattern features. IEEE Transactions on Image Processing, 2012, 21(4):1465-1477 doi: 10.1109/TIP.2011.2175739 [13] Wang W, Wang R P, Huang Z W, Chen X L. Discriminant analysis on Riemannian manifold of Gaussian distributions for face recognition with image sets. IEEE Transactions on Image Processing, 2018, 21(1):151-163 http://ieeexplore.ieee.org/xpl/articleDetails.jsp?reload=true&arnumber=7298816 [14] Dietterich T G, Lathrop R H, Lozano P T. Solving the multiple instance problem with axis parallel rectangles. Artificial Intelligence, 1997, 89(1-2):31-71 doi: 10.1016/S0004-3702(96)00034-3 [15] Lai K T, Yu F X, Chen M S, Chang S F. Video event detection by inferring temporal instance labels. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 2251-2258 https://ieeexplore.ieee.org/document/6909685 [16] 丁昕苗, 李兵, 胡卫明, 郭文, 王振翀.基于多视角融合稀疏表示的恐怖视频识别.电子学报, 2014, 42(2):301-305 doi: 10.3969/j.issn.0372-2112.2014.02.014Ding Xin-Miao, Li Bing, Hu Wei-Ming, Guo Wen, Wang Zhen-Chong. Horror video scene recognition based on multi-view joint sparse coding. Acta Electronica Sinica, 2014, 42(2):301-305 doi: 10.3969/j.issn.0372-2112.2014.02.014 [17] Yang J, Yan R, Hauptmann A G. Multiple instance learning for labeling faces in broadcasting news video. In: Proceedings of the 13th ACM International Conference on Multimedia. Hilton, Singapore: ACM, 2005. 31-40 http://www.mendeley.com/research/multiple-instance-learning-labeling-faces-broadcasting-news-video/ [18] Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7):971-987 doi: 10.1109/TPAMI.2002.1017623 [19] Wolf L, Hassner T, Taigman Y. Descriptor based methods in the wild. In: Proceedings of the 2008 Workshop on Faces in Real Life Images Detection Alignment and Recognition. Marseille, France, 2008. [20] Maron O, Lozano-Pérez T. A framework for multiple-instance learning. In: Proceedings of the 10th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 1998. 570-576 http://www.mendeley.com/catalog/framework-multipleinstance-learning/ [21] Zhang Q, Goldman S A. EM-DD: an improved multiple-instance learning technique. In: Proceedings of the 14th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2002. 1073-1080 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.28.5283 [22] Moghaddam B, Jebara T, Pentland A. Bayesian face recognition. Pattern Recognition, 2000, 33(11):1771-1782 doi: 10.1016/S0031-3203(99)00179-X [23] Lee K C, Ho J, Yang M H, Kriegman D. Video-based face recognition using probabilistic appearance manifolds. In: Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Madison, WI, USA: IEEE, 2003. 313-320 https://dl.acm.org/citation.cfm?id=1965880 [24] Chang C C, Lin C J. LIBSVM:a library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3):Article No. 27 http://d.old.wanfangdata.com.cn/Periodical/jdq201315008 [25] Wang Y, Shen X J, Chen H P, Zhai Y J. Dynamic biometric identification from multiple views using the GLBP-TOP method. Bio-Medical Materials and Engineering, 2014, 24(6):2715-2724 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10104d1c5bab58e9dad2b8ad417b85ce [26] Zhao G Y, Pietikainen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6):915-928 doi: 10.1109/TPAMI.2007.1110 [27] Wolf L, Hassner T, Maoz I. Face recognition in unconstrained videos with matched background similarity. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO, USA, USA: IEEE, 2011. 529-534 https://www.mendeley.com/catalogue/face-recognition-unconstrained-videos-matched-background-similarity/ -

 下载:
下载:


计量
- 文章访问数: 1633
- HTML全文浏览量: 450
- PDF下载量: 660
- 被引次数: 0
