

Remaining Useful Lifetime Prediction Method of Controlled Systems Considering Performance Degradation of Actuator
-
摘要: 工程控制系统在运行过程中,由于内外部应力的综合作用以及外部环境等的影响,其部件性能将逐渐退化,最终会导致控制系统失效.然而,由于控制系统中闭环反馈的作用,系统的输出残差可能仍在较小范围内变动,使得早期性能退化这种微小故障难以被检测到,呈现隐含退化的特点.现有文献中,针对此类在闭环反馈控制作用下部件存在隐含退化过程的控制系统剩余寿命(Remaining useful lifetime,RUL)预测问题,鲜有研究.为此,本文针对一类仅考虑执行器性能退化的确定闭环控制系统,提出一种基于解析模型的剩余寿命预测方法.该方法首先基于权值优选粒子滤波算法,利用系统的监测数据在线估计出执行器的隐含退化量,然后在每一个预测时刻通过蒙特卡洛(Monte Carlo,MC)仿真计算得到合理的失效阈值,建立基于该失效阈值的系统失效判断准则,最后将隐含退化量的估计值代入退化模型中外推出剩余寿命分布.惯性平台稳定回路控制系统的仿真实验结果验证了该方法的可行性、有效性.Abstract: When engineering controlled system is operating, the performance of its components will degrade gradually due to the combined effects of internal and external stress, environment and so on, which will eventually lead to the failure of the controlled system. However, due to the closed-loop feedback in the controlled system, the output residual may still change in a small range, making such incipient fault of performance degradation difficult to detect and show a characteristic of hidden. In view of the existing literatures, the researches are still scarce which are on the remaining useful lifetime (RUL) prediction of the controlled system with hidden degradation process under the closed-loop feedback control. To this end, this paper proposes a prediction method of RUL for a class of deterministic closed-loop controlled systems only considering actuator performance degradation, which is based on analytic model. Firstly, the algorithm of weight selected particle filter is used to estimate the hidden variable of the actuator, using the monitoring data of the system on-line. Then, Monte Carlo (MC) simulation is used to obtain a reasonable failure threshold at each predicting moment and a failure criterion is established based on it. Finally, the estimation of the hidden degradation variable is brought into the degradation model to extrapolate the distribution of RUL. The simulation results of stabilization loop controlled system in inertial platform show that the proposed method is feasible and effective.
-
Key words:
- Life prediction /
- particle filter /
- controlled system /
- performance degradation /
- reliability /
- stabilization loop
1) 本文责任编委 钟麦英 -

图 1 考虑执行器性能退化的闭环控制系统失效过程
Fig. 1 Failure process of closed-loop controlled system considering performance degradation of an actuator
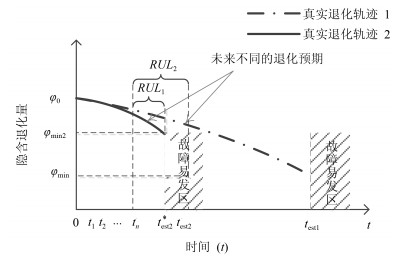
图 2 变失效阈值和固定失效阈值的对比
Fig. 2 Comparison of variable failure threshold and fixed failure threshold
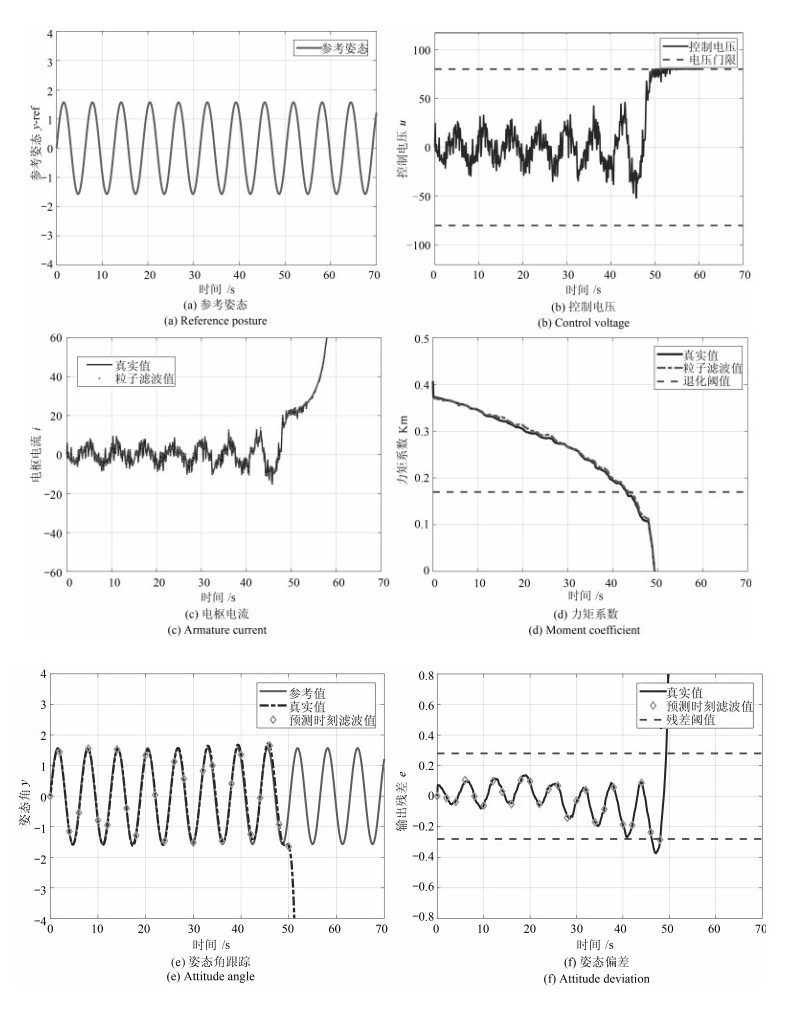
图 5 惯性平台稳定回路控制系统仿真
Fig. 5 Simulation of stabilization loop controlled system for inertial platform
表 1 惯性平台稳定回路模型
Table 1 Stabilization loop model in inertial platform
系统参数 $ J=0.83\, {\rm kg}\cdot {\rm m}^{2} $ $ L_{{\rm m}} =2.7\, {\rm mH} $ $ R_{{\rm m}} =3.6\, \Omega $ $ K_{{\rm m}} =0.407\, {{\rm N}\cdot {\rm m}}/{{\rm A}} $ $ K_{{\rm e}} =0.478\, {{\rm V}}/({\rm rad}\cdot {\rm s}) $ $ \left| u \right|_{\max } =80\, {\rm V} $ 控制器参数 $ K_{{\rm P}} =10.54 $ $ T_{{\rm I}} =15.58 $ $ T_{{\rm D}} =15.37 $ 初始状态量 $ x_{1} (0)=0 $ $ x_{2} (0)=0 $ $ x_{3} (0)=0 $ $ x_{4} (0)=0.407 $ $ y(0)=0 $ 过程噪声参数 $ q_{1} =0.2 $ $ q_{2} ={\rm 0.00008} $ $ q_{3} ={\rm 0.0000000003} $ 退化过程参数 $ \lambda =-0.000257 $ $ \sigma_{{\rm B}} =0.0000002 $  下载: 导出CSV
下载: 导出CSV
表 2 基于固定阈值不同时刻预测结果对比
Table 2 Comparison of prediction results based on fixed threshold at different times
预测时刻 10 s 20 s 30 s 40 s 失效阈值 0.12205 0.12205 0.12205 0.12205 真实剩余寿命 36.2 26.2 16.2 6.2 剩余阈值寿命 36.1 26.1 16.1 6.1 $ MSE_{K_{{\rm m}} } $ 5.6135 10.9825 7.6921 3.1061 $ MSE_{e} $ 5.5925 10.5087 7.2746 2.8566
下载: 导出CSV
表 3 基于变阈值不同时刻预测结果对比
Table 3 Comparison of prediction results based on variable threshold at different times
预测时刻 10 s 20 s 30 s 40 s 失效阈值 0.16321 0.17461 0.13787 0.12205 真实剩余寿命 36.2 26.2 16.2 6.2 剩余阈值寿命 33.4 22.9 15.5 6.1 $ MSE_{K_{{\rm m}} } $ 6.7076 6.2822 5.9862 3.1061 $ MSE_{e} $ 8.1668 7.8860 4.0403 2.8566
下载: 导出CSV
-
[1] Jardine A K S, Lin D M, Banjevic D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mechanical Systems and Signal Processing, 2006, 20(7):1483-1510 doi: 10.1016/j.ymssp.2005.09.012 [2] 周东华, 魏慕恒, 司小胜.工业过程异常检测、寿命预测与维修决策的研究进展.自动化学报, 2013, 39(6):711-722 http://www.aas.net.cn/CN/abstract/abstract18097.shtmlZhou Dong-Hua, Wei Mu-Heng, Si Xiao-Sheng. A survey on anomaly detection, life prediction and maintenance decision for industrial processes. Acta Automatica Sinica, 2013, 39(6):711-722 http://www.aas.net.cn/CN/abstract/abstract18097.shtml [3] Jha M S, Dauphin-Tanguy G, Ould-Bouamama B. Particle filter based hybrid prognostics for health monitoring of uncertain systems in bond graph framework. Mechanical Systems and Signal Processing, 2016, 75:301-329 doi: 10.1016/j.ymssp.2016.01.010 [4] 李鑫, 吕琛, 王自力, 陶小创.考虑退化模式动态转移的健康状态自适应预测.自动化学报, 2014, 40(9):1889-1895 http://www.aas.net.cn/CN/abstract/abstract18458.shtmlLi Xin, Lv Chen, Wang Zi-Li, Tao Xiao-Chuang. Self-adaptive health condition prediction considering dynamic transfer of degradation mode. Acta Automatica Sinica, 2014, 40(9):1889-1895 http://www.aas.net.cn/CN/abstract/abstract18458.shtml [5] Si X S, Wang W B, Hu C H, Zhou D H. Remaining useful life estimation——a review on the statistical data driven approaches. European Journal of Operational Research, 2011, 213(1):1-14 doi: 10.1016/j.ejor.2010.11.018 [6] Nguyen D N, Dieulle L, Grall A. A deterioration model for feedback control systems with random environment. In: Proceedings of the 22nd Annual Conference on European Safety and Reliability. Amsterdam, the Netherlands: Elsevier, 2014. DOI: 10.1201/b15938-273 [7] Yin S, Xiao B, Ding S X, Zhou D H. A review on recent development of spacecraft attitude fault tolerant control system. IEEE Transactions on Industrial Electronics, 2016, 63(5):3311-3320 doi: 10.1109/TIE.2016.2530789 [8] Yadegar M, Afshar A, Meskin N. Fault-tolerant control of non-linear systems based on adaptive virtual actuator. IET Control Theory & Applications, 2017, 11(9):1371-1379 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=d2b7e51e75dac77f96e70f1f60c756aa [9] Nguyen D N, Dieulle L, Grall A. Remaining useful lifetime prognosis of controlled systems:a case of stochastically deteriorating actuator. Mathematical Problems in Engineering, 2015, 2015:Article No.356916 [10] 冯磊, 王宏力, 司小胜, 杨晓君, 王标标.基于半随机滤波——期望最大化算法的剩余寿命在线预测.航空学报, 2015, 36(2):555-563 http://d.old.wanfangdata.com.cn/Periodical/hkxb201502016Feng Lei, Wang Hong-Li, Si Xiao-Sheng, Yang Xiao-Jun, Wang Biao-Biao. Real-time residual life prediction based on semi-stochastic filter and expectation maximization algorithm. Acta Aeronautica et Astronautica Sinica, 2015, 36(2):555-563 http://d.old.wanfangdata.com.cn/Periodical/hkxb201502016 [11] Ghasemi A, Yacout S, Ouali M S. Evaluating the reliability function and the mean residual life for equipment with unobservable states. IEEE Transactions on Reliability, 2010, 59(1):45-54 doi: 10.1109/TR.2009.2034947 [12] Peng Y, Dong M. A prognosis method using age-dependent hidden semi-Markov model for equipment health prediction. Mechanical Systems and Signal Processing, 2011, 25(1):237-252 doi: 10.1016/j.ymssp.2010.04.002 [13] 尚永爽, 李文海, 刘长捷, 盛沛.部分可观测信息条件下装备剩余寿命预测.航空学报, 2012, 33(5):848-854 http://d.old.wanfangdata.com.cn/Periodical/hkxb201205009Shang Yong-Shuang, Li Wen-Hai, Liu Chang-Jie, Sheng Pei. Prediction of remaining useful life for equipment with partially observed information. Acta Aeronautica et Astronautica Sinica, 2012, 33(5):848-854 http://d.old.wanfangdata.com.cn/Periodical/hkxb201205009 [14] Zhang Y M, Jiang J, Theilliol D. Incorporating performance degradation in fault tolerant control system design with multiple actuator failures. International Journal of Control, Automation, and Systems, 2008, 6(3):327-338 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=a9d918d2fd92620c2a98be01a24c8fe7 [15] Boussaid B, Aubrun C, Abdelkrim M, Gayed M. Performance evaluation based fault tolerant control with actuator saturation avoidance. International Journal of Applied Mathematics and Computer Science, 2011, 21(3):457-466 doi: 10.2478/v10006-011-0034-x [16] Yu X, Jiang J. Hybrid fault-tolerant flight control system design against partial actuator failures. IEEE Transactions on Control Systems Technology, 2012, 20(4):871-886 doi: 10.1109/TCST.2011.2159606 [17] Yang H J, Zhang L Y, Zhao L, Yuan Y. Fault-tolerant control of delta operator systems with actuator saturation and effectiveness loss. International Journal of Systems Science, 2016, 47(10):2428-2439 doi: 10.1080/00207721.2014.998320 [18] Han S Y, Chen Y H, Tang G Y. Fault diagnosis and fault-tolerant tracking control for discrete-time systems with faults and delays in actuator and measurement. Journal of the Franklin Institute, 2017, 354(12):4719-4738 doi: 10.1016/j.jfranklin.2017.05.027 [19] 文成林, 吕菲亚, 包哲静, 刘妹琴.基于数据驱动的微小故障诊断方法综述.自动化学报, 2016, 42(9):1285-1299 http://www.aas.net.cn/CN/abstract/abstract18918.shtmlWen Cheng-Lin, Lv Fei-Ya, Bao Zhe-Jing, Liu Mei-Qin. A review of data driven-based incipient fault diagnosis. Acta Automatica Sinica, 2016, 42(9):1285-1299 http://www.aas.net.cn/CN/abstract/abstract18918.shtml [20] Langeron Y, Grall A, Barros A. A modeling framework for deteriorating control system and predictive maintenance of actuators. Reliability Engineering & System Safety, 2015, 140:22-36 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=448ff466bb36d6e45674edcf8b8d87d4 [21] Xu Z G, Ji Y D, Zhou D H. Real-time reliability prediction for a dynamic system based on the hidden degradation process identification. IEEE Transactions on Reliability, 2008, 57(2):230-242 doi: 10.1109/TR.2008.916882 [22] Xu Z G, Ji Y D, Zhou D H. A new real-time reliability prediction method for dynamic systems based on on-line fault prediction. IEEE Transactions on Reliability, 2009, 58(3):523-538 doi: 10.1109/TR.2009.2026785 [23] Chehade A, Bonk S, Liu K B. Sensory-based failure threshold estimation for remaining useful life prediction. IEEE Transactions on Reliability, 2017, 66(3):939-949 doi: 10.1109/TR.2017.2695119 [24] Wang P, Coit D W. Reliability and degradation modeling with random or uncertain failure threshold. In: Proceedings of the 2007 Annual Reliability and Maintainability Symposium. Orlando, USA: IEEE, 2007. 392-397 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=4126383 [25] Liu K B, Gebraeel N Z, Shi J J. A data-level fusion model for developing composite health indices for degradation modeling and prognostic analysis. IEEE Transactions on Automation Science and Engineering, 2013, 10(3):652-664 doi: 10.1109/TASE.2013.2250282 [26] Liu K B, Huang S. Integration of data fusion methodology and degradation modeling process to improve prognostics. IEEE Transactions on Automation Science and Engineering, 2016, 13(1):344-354 doi: 10.1109/TASE.2014.2349733 [27] Nguyen D N, Dieulle L, Grall A. Remaining useful life estimation of stochastically deteriorating feedback control systems with a random environment and impact of prognostic result on the maintenance process. In: Proceedings of the 2nd European Conference of the Prognostics and Health Management Society. Nantes, France: Elsevier, 2014. DOI: 10.1.1.653.8986 [28] Lorton A, Fouladirad M, Grall A. A methodology for probabilistic model-based prognosis. European Journal of Operational Research, 2013, 225(3):443-454 doi: 10.1016/j.ejor.2012.10.025 [29] Yang H, Jiang B. Fault detection and accommodation via neural network and variable structure control. Journal of Control Theory and Applications, 2007, 5(3):253-260 doi: 10.1007/s11768-005-5204-7 [30] Langeron Y, Grall A, Barros A. Actuator health prognosis for designing LQR control in feedback systems. Chemical Engineering Transactions, 2013, 33:979-984 [31] Si X S, Wang W B, Hu C H, Zhou D H, Pecht M G. Remaining useful life estimation based on a nonlinear diffusion degradation process. IEEE Transactions on Reliability, 2012, 61(1):50-67 doi: 10.1109/TR.2011.2182221 [32] 司小胜, 胡昌华, 周东华.带测量误差的非线性退化过程建模与剩余寿命估计.自动化学报, 2013, 39(5):530-541 http://www.aas.net.cn/CN/abstract/abstract17879.shtmlSi Xiao-Sheng, Hu Chang-Hua, Zhou Dong-Hua. Nonlinear degradation process modeling and remaining useful life estimation subject to measurement error. Acta Automatica Sinica, 2013, 39(5):530-541 http://www.aas.net.cn/CN/abstract/abstract17879.shtml [33] Pan Z Q, Balakrishnan N. Reliability modeling of degradation of products with multiple performance characteristics based on Gamma processes. Reliability Engineering & System Safety, 2011, 96(8):949-957 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=5e4ac1bf7516c611de384af4cd2cf241 [34] Beganovic N, Söffker D. Remaining lifetime modeling using State-of-Health estimation. Mechanical Systems and Signal Processing, 2017, 92:107-123 doi: 10.1016/j.ymssp.2017.01.031 [35] Daigle M J, Goebel K. A model-based prognostics approach applied to pneumatic valves. International Journal of Prognostics and Health Management, 2011, 2(2):84-99 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_2ad1fcf570b0e0ba635ed4a2f0e6052b [36] 周东华, 刘洋, 何潇.闭环系统故障诊断技术综述.自动化学报, 2013, 39(11):1933-1943 http://www.aas.net.cn/CN/abstract/abstract18232.shtmlZhou Dong-Hua, Liu Yang, He Xiao. Review on fault diagnosis techniques for closed-loop systems. Acta Automatica Sinica, 2013, 39(11):1933-1943 http://www.aas.net.cn/CN/abstract/abstract18232.shtml [37] Nguyen D N, Dieulle L, Grall A. Feedback control system with stochastically deteriorating actuator: remaining useful life assessment. In: Proceedings of the 19th World Congress of the International Federation of Automatic Control. Cape Town, South Africa: IFAC, 2014. 3244-3249 [38] 李天成, 范红旗, 孙树栋.粒子滤波理论、方法及其在多目标跟踪中的应用.自动化学报, 2015, 41(12):1981-2002 http://www.aas.net.cn/CN/abstract/abstract18773.shtmlLi Tian-Cheng, Fan Hong-Qi, Sun Shu-Dong. Particle filtering:theory, approach, and application for multitarget tracking. Acta Automatica Sinica, 2015, 41(12):1981-2002 http://www.aas.net.cn/CN/abstract/abstract18773.shtml [39] Gordon N J, Salmond D J, Smith A F M. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proceedings F-Radar and Signal Processing, 1993, 140(2):107-113 doi: 10.1049/ip-f-2.1993.0015 [40] 张琪, 胡昌华, 乔玉坤, 蔡艳宁.基于权值选优粒子滤波器的故障预测算法.系统工程与电子技术, 2009, 31(1):221-224 doi: 10.3321/j.issn:1001-506X.2009.01.050Zhang Qi, Hu Chang-Hua, Qiao Yu-Kun, Cai Yan-Ning. Fault prediction algorithm based on weight selected particle filter. Systems Engineering and Electronics, 2009, 31(1):221-224 doi: 10.3321/j.issn:1001-506X.2009.01.050 [41] 钟麦英, 矫成斌, 李树胜, 赵岩.基于PMI的三轴惯性稳定平台干扰力矩补偿方法研究.仪器仪表学报, 2014, 35(4):781-787 http://d.old.wanfangdata.com.cn/Periodical/yqyb201404009Zhong Mai-Ying, Jiao Cheng-Bin, Li Shu-Sheng, Zhao Yan. Study on the compensation method for disturbance torque of three-axis inertially stabilized platform based on PMI. Chinese Journal of Scientific Instrument, 2014, 35(4):781-787 http://d.old.wanfangdata.com.cn/Periodical/yqyb201404009 -

 下载:
下载:




计量
- 文章访问数: 3358
- HTML全文浏览量: 549
- PDF下载量: 578
- 被引次数: 0
