

Improving Speech Enhancement in Unseen Noise Using Deep Convolutional Neural Network
-
摘要: 为了进一步提高基于深度学习的语音增强方法在未知噪声下的性能,本文从神经网络的结构出发展开研究.基于在时间与频率两个维度上,语音和噪声信号的局部特征都具有强相关性的特点,采用深度卷积神经网络(Deep convolutional neural network,DCNN)建模来表示含噪语音和纯净语音之间的复杂非线性关系.通过设计有效的训练特征和训练目标,并建立合理的网络结构,提出了基于深度卷积神经网络的语音增强方法.实验结果表明,在未知噪声条件下,本文方法相比基于深度神经网络(Deep neural network,DNN)的方法在语音质量和可懂度两种指标上都有明显提高.Abstract: In order to further improve the performance of speech enhancement method based on deep learning in unseen noise, this paper focuses on the architecture of neural network. Based on the strong correlation between local characteristics of speech and noise signals in time and frequency domains, a deep convolutional neural network (DCNN) model is used to represent the complex nonlinear relationship between noisy speech and clean speech. By designing effective training features and training target, and establishing reasonable network architecture, a speech enhancement method based on DCNN is proposed. Experimental results show that under the condition of unseen noise, the proposed method significantly outperforms the methods based on deep neural network (DNN) in terms of both speech quality and intelligibility.1) 本文责任编委 党建武
-

图 5 $-5$ dB的Factory2噪声下的增强语音语谱图示例
Fig. 5 An example of spectrogram of enhanced speech under Factory2 noise at $-5$ dB SNR

图 6 卷积层数量对网络性能的影响
Fig. 6 The influence of the number of convolutional layers on the network performance
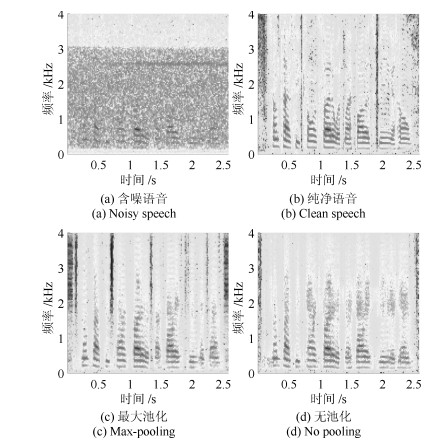
图 8 $-5$ dB的HF channel噪声下的增强语音语谱图示例
Fig. 8 An example of spectrogram of enhanced speech under HF channel noise at $-5$ dB SNR
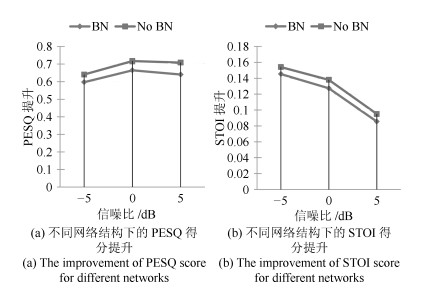
图 9 Batch normalization层对网络性能的影响
Fig. 9 The influence of the batch normalization layers on the network performance

图 10 两种特征训练得到的DNN和DCNN的性能比较
Fig. 10 The performance comparisons for DNN and DCNN trained using two kinds of feature
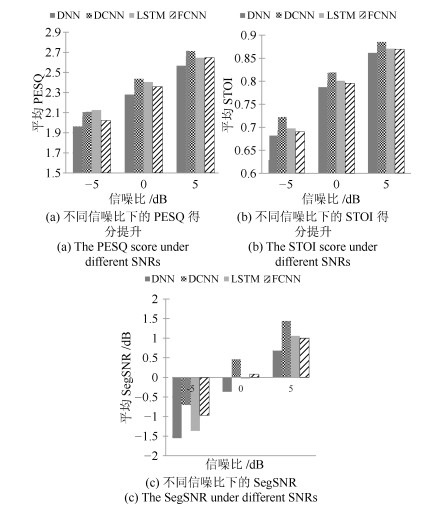
图 11 两种特征训练得到的DNN和DCNN的性能比较
Fig. 11 The performance comparisons for DNN and DCNN trained using two kinds of feature
表 1 三种方法的平均PESQ得分
Table 1 The average PESQ score for three methods
噪声类型 信噪比
(dB)含噪语音 DNN_11F DNN_15F DCNN Factory2 -5 1.73 2.25 2.27 ${\bf 2.33}$ 0 2.07 2.57 2.58 ${\bf 2.65}$ 5 2.40 2.83 2.82 ${\bf 2.89}$ Buccaneer1 -5 1.36 1.88 1.92 ${\bf 1.93}$ 0 1.63 2.24 2.26 ${\bf 2.27}$ 5 1.95 2.54 2.54 ${\bf 2.56} $ Destroyer engine -5 1.59 2.01 1.99 ${\bf 2.15} $ 0 1.81 2.27 2.26 ${\bf 2.46}$ 5 2.10 2.53 2.55 $ {\bf 2.76}$ HF channel -5 1.36 1.7 1.71 ${\bf 2.03} $ 0 1.58 2.04 2.06 ${\bf 2.37}$ 5 1.85 2.38 2.39 ${\bf 2.65}$  下载: 导出CSV
下载: 导出CSV
表 2 三种方法的平均STOI得分
Table 2 The average STOI score for three methods
噪声类型 信噪比
(dB)含噪语音 DNN_11F DNN_15F DCNN Factory2 -5 0.65 0.76 0.76 ${\bf 0.78 }$ 0 0.76 0.85 0.84 ${\bf 0.86 } $ 5 0.85 0.89 0.89 ${\bf 0.91 }$ Buccaneer1 -5 0.51 0.66 0.66 ${\bf 0.68 }$ 0 0.63 0.77 0.77 ${\bf 0.78 }$ 5 0.75 0.85 0.85 ${\bf 0.86 }$ Destroyer engine -5 0.57 0.62 0.63 ${\bf 0.70 }$ 0 0.69 0.75 0.75 ${\bf 0.82 }$ 5 0.81 0.85 0.85 ${\bf 0.90 }$ HF channel -5 0.57 0.69 0.69 ${\bf 0.73 }$ 0 0.69 0.78 0.79 ${\bf 0.82 }$ 5 0.80 0.86 0.86 ${\bf 0.88 }$
下载: 导出CSV
表 3 三种方法的平均SegSNR
Table 3 The average SegSNR for three methods
噪声类型 信噪比
(dB)含噪语音
(dB)DNN_11F
(dB)DNN_15F
(dB)DCNN
(dB)Factory2 -5 -6.90 -0.69 -0.59 -0.05 0 -4.50 0.34 0.42 0.95 5 -1.57 1.24 1.29 1.80 Buccaneer1 -5 -7.21 -1.52 -1.40 -0.96 0 -4.90 -0.50 -0.39 0.11 5 -2.03 0.46 0.53 1.03 Destroyer engine -5 -7.15 -2.86 -2.81 -2.16 0 -4.90 -1.37 -1.24 -0.54 5 -1.91 0.04 0.21 0.89 HF channel -5 -7.24 -1.13 -1.21 0.35 0 -4.91 0.05 -0.02 1.34 5 -2.09 1.04 1.02 2.03
下载: 导出CSV
-
[1] Loizou P C. Speech Enhancement:Theory and Practice. Florida:CRC Press, 2013. [2] Ephraim Y, Malah D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1985, 33(2):443-445 http://ieeexplore.ieee.org/document/1164550/ [3] Cohen I. Noise spectrum estimation in adverse environments:Improved minima controlled recursive averaging. IEEE Transactions on speech and audio processing, 2003, 11(5):466-475 http://www.researchgate.net/publication/3333946_Noise_spectrum_estimation_in_adverse_environments_improved_minima_controlled_recursive_averaging [4] Mohammadiha N, Smaragdis P, Leijon A. Supervised and unsupervised speech enhancement using nonnegative matrix factorization. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(10):2140-2151 doi: 10.1109/TASL.2013.2270369 [5] 刘文举, 聂帅, 梁山, 张学良.基于深度学习语音分离技术的研究现状与进展.自动化学报, 2016, 42(6):819-833 http://www.aas.net.cn/CN/abstract/abstract18873.shtmlLiu Wen-Ju, Nie Shuai, Liang Shan, Zhang Xue-Liang. Deep learning based speech separation technology and its developments. Acta Automatica Sinica, 2016, 42(6):819-833 http://www.aas.net.cn/CN/abstract/abstract18873.shtml [6] Wang Y X, Wang D L. Towards scaling up classification-based speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(7):1381-1390 doi: 10.1109/TASL.2013.2250961 [7] Wang Y X, Narayanan A, Wang D L. On training targets for supervised speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2014, 22(12):1849-1858 doi: 10.1109/TASLP.2014.2352935 [8] Xu Y, Du J, Dai L R, Lee C H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Letters, 2014, 21(1):65-68 doi: 10.1109/LSP.2013.2291240 [9] Xu Y, Du J, Dai L R, Lee C H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1):7-19 http://www.researchgate.net/publication/272436458_A_Regression_Approach_to_Speech_Enhancement_Based_on_Deep_Neural_Networks [10] Williamson D S, Wang Y X, Wang D L. Complex ratio masking for monaural speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3):483-492 doi: 10.1109/TASLP.2015.2512042 [11] Xu Y, Du J, Huang Z, Dai L R, Lee C H. Multi-objective learning and mask-based post-processing for deep neural network based speech enhancement. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany: ISCA, 2015. 1508-1512 [12] Wang Y X, Chen J T, Wang D L. Deep Neural Network Based Supervised Speech Segregation Generalizes to Novel Noises Through Large-scale Training, Technical Report OSU-CISRC-3/15-TR02, Department of Computer Science and Engineering, The Ohio State University, Columbus, Ohio, USA, 2015 [13] Chen J T, Wang Y X, Yoho S E, Wang D L, Healy E W. Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises. The Journal of the Acoustical Society of America, 2016, 139(5):2604-2612 doi: 10.1121/1.4948445 [14] Chen J T, Wang Y X, Wang D L. Noise perturbation for supervised speech separation. Speech Communication, 2016, 78:1-10 https://www.sciencedirect.com/science/article/pii/S0167639315001405 [15] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the International Conference on Neural Information Processing Systems. Nevada, USA: Curran Associates Inc. 2012. 1097-1105 http://www.researchgate.net/publication/267960550_ImageNe [16] Abdel-Hamid O, Mohamed A, Jiang H, Penn G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In: Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing. Kyoto, Japan: IEEE, 2012. 4277-4280 [17] Abdel-Hamid O, Deng L, Yu D. Exploring convolutional neural network structures and optimization techniques for speech recognition. In: Proceedings of the 14th Annual Conference of the International Speech Communication Association. Lyon, France: ISCA, 2013. 3366-3370 http://www.researchgate.net/publication/264859599_Exploring_Convolutional_Neural_Network_Structures_and_Optimization_Techniques_for_Speech_Recognition [18] Sainath T N, Kingsbury B, Saon G, Soltau H, Mohamed A R, Dahl G, Ramabhadran B. Deep convolutional neural networks for large-scale speech tasks. Neural Networks, 2015, 64:39-48 https://www.sciencedirect.com/science/article/pii/S0893608014002007 [19] Qian Y M, Bi M X, Tan T, Yu K. Very deep convolutional neural networks for noise robust speech recognition. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2016, 24(12):2263-2276 http://www.researchgate.net/publication/308823854_Very_Deep_Convolutional_Neural_Networks_for_Robust_Speech_Recognition [20] Bi M X, Qian Y M, Yu K. Very deep convolutional neural networks for LVCSR. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany: ISCA, 2015. 3259-3263 [21] Qian Y, Woodland P C. Very deep convolutional neural networks for robust speech recognition. In: Proceedings of the 2016 IEEE Spoken Language Technology Workshop. San Juan, Puerto Rico: IEEE, 2016. 481-488 http://www.researchgate.net/publication/313587893_Very_deep_convolutional_neural_networks_for_robust_speech_recognition [22] Sercu T, Puhrsch C, Kingsbury B, LeCun Y. Very deep multilingual convolutional neural networks for LVCSR. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 4955-4959 [23] Sercu T, Goel V. Advances in very deep convolutional neural networks for LVCSR. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. California, USA: ISCA, 2016. 3429-3433 http://www.researchgate.net/publication/307889292_Advances_in_Very_Deep_Convolutional_Neural_Networks_for_LVCSR [24] Park S R, Lee J. A fully convolutional neural network for speech enhancement. arXiv: 1609. 07132, 2016. [25] Fu S W, Tsao Y, Lu X. SNR-Aware convolutional neural network modeling for speech enhancement. In: Proceedings of the 17th Annual Conference of the International Speech Communication Association. San Francisco, USA: ISCA, 2016. 8-12 http://www.researchgate.net/publication/307889660_SNR-Aware_Convolutional_Neural_Network_Modeling_for_Speech_Enhancement [26] Garofolo J S, Lamel L F, Fisher W M, Fiscus J G, Pallett D S, Dahlgren N L, Zue V. TIMIT acoustic-phonetic continuous speech corpus. Linguistic Data Consortium, Philadelphia, 1993. https://www.researchgate.net/publication/243787812_TIMIT_acoustic-phonetic_continuous_speech_corpus [27] Hu G N. 100 nonspeech sounds[online], available: http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html, April 20, 2004 [28] Varga A, Steeneken Herman J M. Assessment for automatic speech recognition:Ⅱ. NOISEX-92:a database and an experiment to study the effect of additive noise on speech recognition systems. Speech Communication, 1993, 12(3):247-251 doi: 10.1016/0167-6393(93)90095-3 [29] Beerends J G, Rix A W, Hollier M P, Hekstra A P. Perceptual evaluation of speech quality (PESQ)——a new method for speech quality assessment of telephone networks and codecs. In: Proceedings of the 2001 IEEE International Conference on Acoustics, Speech and Signal Processing. Utah, USA: IEEE, 2001. 749-752 http://dl.acm.org/citation.cfm?id=1259107 [30] Taal C H, Hendriks R C, Heusdens R, Jensen J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(7):2125-2136 doi: 10.1109/TASL.2011.2114881 [31] Yu D, Eversole A, Seltzer M L, Yao K S, Huang Z H, Guenter B, Kuchaiev O, Zhang Y, Seide F, Wang H M, Droppo J, Zweig G, Rossbach C, Currey J, Gao J, May A, Peng B L, Stolcke A, Slaney M. An Introduction to Computational Networks and the Computational Network Toolkit, Technical Report, Tech. Rep. MSR, Microsoft Research, 2014. -

 下载:
下载:





计量
- 文章访问数: 2677
- HTML全文浏览量: 553
- PDF下载量: 1360
- 被引次数: 0
