

-
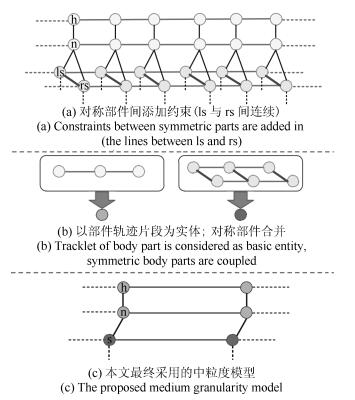
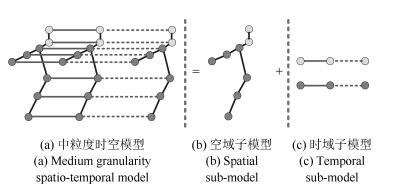
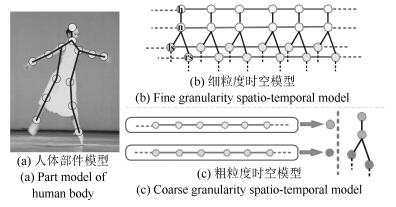
摘要: 人体姿态估计是计算机视觉领域的一个研究热点,在行为识别、人机交互等领域均有广泛的应用.本文综合粗、细粒度模型的优点,以人体部件轨迹片段为实体构建中粒度时空模型,通过迭代的时域和空域交替解析,完成模型的近似推理,为每一人体部件选择最优的轨迹片段,拼接融合形成最终的人体姿态序列估计.为准备高质量的轨迹片段候选,本文引入全局运动信息将单帧图像中的最优姿态检测结果传播到整个视频形成轨迹,然后将轨迹切割成互相交叠的固定长度的轨迹片段.为解决对称部件易混淆的问题,从概念上将模型中的对称部件合并,在保留对称部件间约束的前提下,消除空域模型中的环路.在三个数据集上的对比实验表明本文方法较其他视频人体姿态估计方法达到了更高的估计精度.Abstract: Human pose estimation has attracted much attention in the computer vision community due to its potential applications in action recognition, human-computer interaction, etc. To focus on pose estimation in videos, a medium granularity spatio-temporal probabilistic graphical model using body part tracklets as entities is presented in this paper. The optimal tracklet for each body part is acquired by spatiotemporal approximate reasoning through iterative spatial and temporal parsing, and the final human pose estimation is achieved by merging these optimal tracklets. To generate reliable tracklet proposals, global motion cue is adopted to propagate pose detections from individual frames to the whole video, and the trajectories from this propagation are segmented into fixed-length overlapping tracklets. To deal with the double counting problem, symmetric parts are coupled to one virtual node, so that the loops in spatial model are removed and the constaints between symmetric parts are maintained. The experiment on three datasets shows the proposed method achieves a higher accuracy than other pose estimation methods.1) 本文责任编委 王亮
-

图 4 不同方法的长时运动估计对比
Fig. 4 Long-term performances of different motion estimation approaches

图 3 不同方法的短时运动估计对比
Fig. 3 Short-term performances of different motion estimation approaches
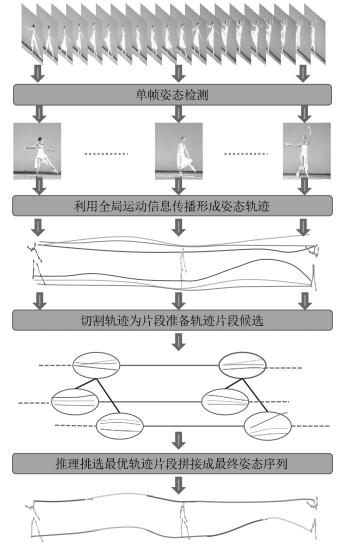
图 5 基于中粒度模型的视频人体姿态估计方法示意图
Fig. 5 Overview of the video pose estimation method based on medium granularity model
表 1 UnusualPose视频集上的PCK评分对比
Table 1 PCK on UnusualPose dataset
Method Head Shld. Elbow Wrist Hip Knee Ankle Avg Nbest 99.8 99.4 76.2 65.0 87.8 70.8 71.5 81.5 UVA 99.4 93.8 72.7 56.2 89.3 66.3 62.4 77.2 PE_GM 98.7 98.3 89.9 73.8 91.0 76.4 88.9 88.1 Ours 98.7 98.1 90.1 75.1 95.9 88.4 89.5 90.8  下载: 导出CSV
下载: 导出CSV
表 2 FYDP视频集上的PCK评分对比
Table 2 PCK on FYDP dataset
Method Head Shld. Elbow Wrist Hip Knee Ankle Avg Nbest 95.7 89.7 75.2 59.1 83.3 81.4 79.5 80.6 UVA 96.2 91.7 78.4 60.3 85.4 83.8 79.2 82.1 PE_GM 98.4 89.2 80.9 60.5 84.4 89.3 83.7 83.8 Ours 97.9 93.4 84 63.1 88.4 88.9 84.4 85.7
下载: 导出CSV
表 3 Sub_Nbest视频集上的PCP评分对比
Table 3 PCP on Sub_Nbest dataset
Method Head Torso U.A. L.A. U.L. L.L. Nbest 100 61.0 66.0 41.0 86.0 84.0 SYM 100 69.0 85.0 42.0 91.0 89.0 PE_GM 100 97.9 97.9 67.0 94.7 86.2 HPEV 100 100 93.0 65.0 92.0 94.0 Ours 100 98.1 96.6 58.6 95.1 94.8
下载: 导出CSV
-
[1] 李毅, 孙正兴, 陈松乐, 李骞.基于退火粒子群优化的单目视频人体姿态分析方法.自动化学报, 2012, 38(5):732-741 http://www.aas.net.cn/CN/abstract/abstract13545.shtmlLi Yi, Sun Zheng-Xing, Chen Song-Le, Li Qian. 3D Human pose analysis from monocular video by simulated annealed particle swarm optimization. Acta Automatica Sinica, 2012, 38(5):732-741 http://www.aas.net.cn/CN/abstract/abstract13545.shtml [2] 朱煜, 赵江坤, 王逸宁, 郑兵兵.基于深度学习的人体行为识别算法综述.自动化学报, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtmlZhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtml [3] Shotton J, Girshick R, Fitzgibbon A, Sharp T, Cook M, Finocchio M, Moore R, Kohli P, Criminisi A, Kipman A, Blake A. E-cient human pose estimation from single depth images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12):2821-2840 doi: 10.1109/TPAMI.2012.241 [4] Cristani M, Raghavendra R, del Bue A, Murino V. Human behavior analysis in video surveillance:a social signal processing perspective. Neurocomputing, 2013, 100:86-97 doi: 10.1016/j.neucom.2011.12.038 [5] Wang L M, Qiao Y, Tang X O. Video action detection with relational dynamic-poselets. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 565-580 [6] Felzenszwalb P F, Huttenlocher D P. Pictorial structures for object recognition. International Journal of Computer Vision, 2005, 61(1):55-79 doi: 10.1023/B:VISI.0000042934.15159.49 [7] Yang Y, Ramanan D. Articulated human detection with flexible mixtures of parts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12):2878-2890 doi: 10.1109/TPAMI.2012.261 [8] Sapp B, Jordan C, Taskar B. Adaptive pose priors for pictorial structures. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 422-429 [9] Andriluka M, Roth S, Schiele B. Pictorial structures revisited: people detection and articulated pose estimation. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 1014-1021 [10] Eichner M, Marin-Jimenez M, Zisserman A, Ferrari V. 2D articulated human pose estimation and retrieval in (almost) unconstrained still images. International Journal of Computer Vision, 2012, 99(2):190-214 doi: 10.1007/s11263-012-0524-9 [11] Ferrari V, Marin-Jimenez M, Zisserman A. Progressive search space reduction for human pose estimation. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK, USA: IEEE, 2008. 1-8 [12] Shi Q X, Di H J, Lu Y, Lü F. Human pose estimation with global motion cues. In: Proceedings of the 2015 IEEE International Conference on Image Processing. Quebec, Canada: IEEE, 2015. 442-446 [13] Sapp B, Toshev A, Taskar B. Cascaded models for articulated pose estimation. In: Proceedings of the Eeuropean Conference on Computer Vision. Heraklion, Greece: Springer, 2010. 406-420 [14] Zhao L, Gao X B, Tao D C, Li X L. Tracking human pose using max-margin Markov models. IEEE Transactions on Image Processing, 2015, 24(12):5274-5287 doi: 10.1109/TIP.2015.2473662 [15] Ramakrishna V, Kanade T, Sheikh Y. Tracking human pose by tracking symmetric parts. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 3728-3735 [16] Cherian A, Mairal J, Alahari K, Schmid C. Mixing bodypart sequences for human pose estimation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 2361-2368 [17] Tokola R, Choi W, Savarese S. Breaking the chain: liberation from the temporal Markov assumption for tracking human poses. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2424-2431 [18] Zhang D, Shah M. Human pose estimation in videos. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2012-2020 [19] Sigal L, Bhatia S, Roth S, Black M J, Isard M. Tracking loose-limbed people. In: Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition. Washington, D. C., USA: IEEE, 2004. 421-428 [20] Sminchisescu C, Triggs B. Estimating articulated human motion with covariance scaled sampling. The International Journal of Robotics Research, 2003, 22(6):371-391 doi: 10.1177/0278364903022006003 [21] Weiss D, Sapp B, Taskar B. Sidestepping intractable inference with structured ensemble cascades. In: Proceedings of the 23rd International Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2010. 2415-2423 [22] Park D, Ramanan D. N-best maximal decoders for part models. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2627-2634 [23] Wang C Y, Wang Y Z, Yuille A L. An approach to posebased action recognition. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 915-922 [24] Zu-S, Romero J, Schmid C, Black M J. Estimating human pose with flowing puppets. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 3312-3319 [25] Sapp B, Weiss D, Taskar B. Parsing human motion with stretchable models. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO, USA: IEEE, 2011. 1281-1288 [26] Fragkiadaki K, Hu H, Shi J B. Pose from flow and flow from pose. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 2059-2066 [27] Brox T, Malik J. Large displacement optical flow:descriptor matching in variational motion estimation. IEEE Transactions on Pattern Recognition and Machine Intelligence, 2011, 33(3):500-513 doi: 10.1109/TPAMI.2010.143 [28] Wang H, Klaser A, Schmid C, Liu C L. Action recognition by dense trajectories. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, D. C., USA: IEEE, 2011. 3169-3176 [29] Shen H Q, Yu S I, Yang Y, Meng D Y, Hauptmann A. Unsupervised video adaptation for parsing human motion. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 347-360 [30] Di H J, Tao L M, Xu G Y. A mixture of transformed hidden Markov models for elastic motion estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(10):1817-1830 doi: 10.1109/TPAMI.2009.111 [31] 吕峰, 邸慧军, 陆耀, 徐光祐.基于分层弹性运动分析的非刚体跟踪方法.自动化学报, 2015, 41(2):295-303 http://www.aas.net.cn/CN/abstract/abstract18608.shtmlLü Feng, Di Hui-Jun, Lu Yao, Xu Guang-You. Non-rigid tracking method based on layered elastic motion analysis. Acta Automatica Sinica, 2015, 41(2):295-303 http://www.aas.net.cn/CN/abstract/abstract18608.shtml -

 下载:
下载:





计量
- 文章访问数: 2131
- HTML全文浏览量: 323
- PDF下载量: 772
- 被引次数: 0
