

Data-driven Multi-output ARMAX Modeling for Online Estimation of Central Temperatures for Cross Temperature Measuring in Blast Furnace Ironmaking
-
摘要: 高炉(Blast furnace,BF)炼铁中,十字测温作为炉顶温度和煤气流分布监测的最主要手段,对高炉的安全、稳定和高效运行起着重要作用.然而,由于高炉炉顶中心部位温度较高,造成十字测温装置中心位置传感器极易损坏,并且更换周期长,因而无法及时判断炉顶煤气流分布.针对这一实际工程问题,本文基于时间序列建模思想,集成采用多输出自回归移动平均(Multi-output autoregressive moving average,M-ARMAX)建模、因子分析、Pearson相关分析、基于赤池信息准则(Akaike information criterion,AIC)与模型拟合优度联合定阶等混合技术,提出一种模型结构简单、精度较高且易于工程实现的十字测温中心温度在线估计方法.首先,提出利用因子分析与Pearson相关分析相结合的稳健特征选择方法选取多输出建模输入变量.然后,采用样本均值消去法预处理采集的高炉样本数据,使其成为离散随机数.基于离散随机数,建立算法简单、易于工程实现的M-ARMAX温度模型:为了克服传统基于AIC阶数确定造成模型阶次高、结构复杂的问题,提出在AIC准则基础上进一步引入模型拟合优度来选取模型最小阶,可保证模型估计精度的同时降低模型阶次;同时,采用可快速收敛的递推最小二乘算法辨识M-ARMAX模型参数,并用残差分析方法检验模型.工业试验和比较分析表明:建立的M-ARMAX模型能够根据实时数据同时对十字测温装置多个中心温度点进行准确和稳定估计,且模型估计误差符合高斯白噪声特性.
-
关键词:
- 高炉炼铁 /
- 十字测温 /
- 多输出自回归移动平均建模 /
- 温度估计 /
- 赤池信息准则 /
- 拟合优度 /
- Pearson相关分析
Abstract: In a blast furnace (BF) ironmaking process, cross temperature measuring is the most important means for monitoring the temperature and gas flow distribution of furnace top. It plays an important role in safe, stable and efficient operation of the whole BF. However, due to the high temperature in the middle of furnace top, the central position sensors of the cross temperature measurement are easily damaged, and the replacement period always takes a long time, thus the gas flow distribution cannot be monitored in time. To solve such a practical engineering problem, a data-driven model with simple structure and high estimation precision is proposed for online estimation of central temperatures for cross temperature measuring. This model integrates hybrid modeling technologies, such as multi-output autoregressive moving average (M-ARMAX) modeling, factor analysis, Pearson correlation analysis, co-determination of model order by Akaike information criterion (AIC) and goodness-of-fit evaluation, etc. The input variables are determined by using factor analysis combined with Pearson correlation analysis with robustness, and the sample mean elimination method is used to preprocess the BF data to make them become discrete time random data. Discrete random data based M-ARMAX modeling includes determination of model order and identification model parameters. The conventional AIC based model order determination leads to too high order of model structure. Thus, the model goodness-of-fit is introduced in the AIC to select the minimum model order, which can not only guarantee the model accuracy but also reduce the model order. Finally, the parameters of M-ARMAX model are identified by recursive least squares algorithm and the obtained models are verified using residual analysis method. Industrial tests and comparative analysis show that the established M-ARMAX model can accurately estimate the center temperatures of cross temperature measuring devices, whose estimated error conforms with Gauss white noise characteristics.1) 本文责任编委 谢永芳 -
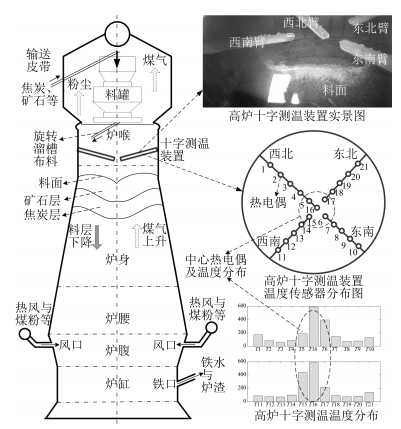
图 1 高炉炼铁过程与十字测温装置
Fig. 1 Blast furnace ironmaking process and cross temperature measuring device

图 3 所有输入与主因子的Pearson相关系数
Fig. 3 Pearson correlation coefficients between all inputs and the main factor
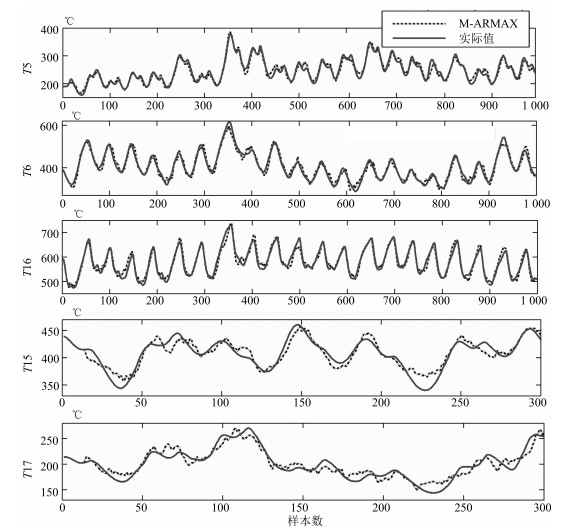
图 6 所提方法十字测温中心温度建模效果
Fig. 6 Modeling results of center temperature estimation model for cross temperature measuring
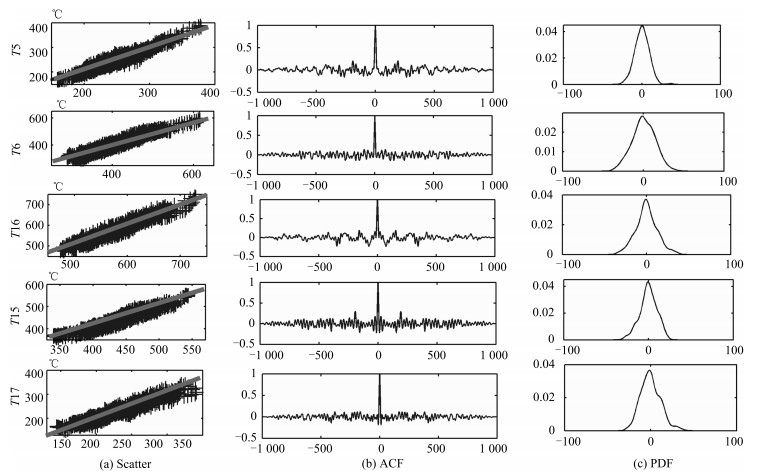
图 7 建模散点图(左)及建模误差自相关函数(中)和PDF曲线(右)
Fig. 7 Scatter diagram of modeling and autocorrelation function and PDF curve of modeling error
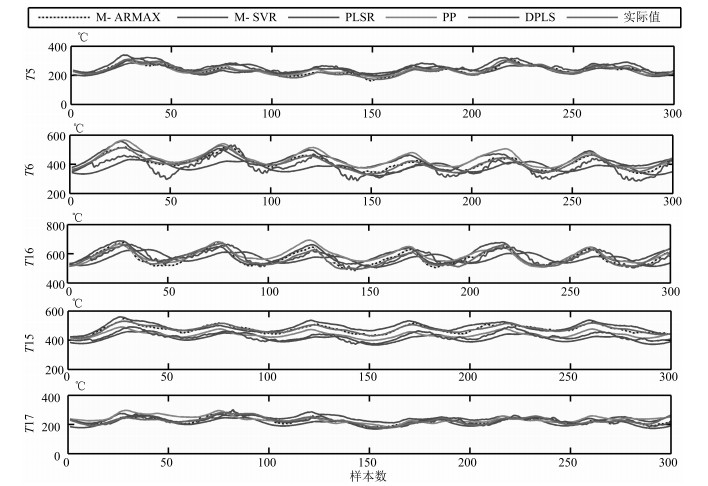
图 8 不同建模方法下的十字测温中心温度估计效果对比
Fig. 8 Estimation results of center temperature estimation model for cross temperature measuring with different method
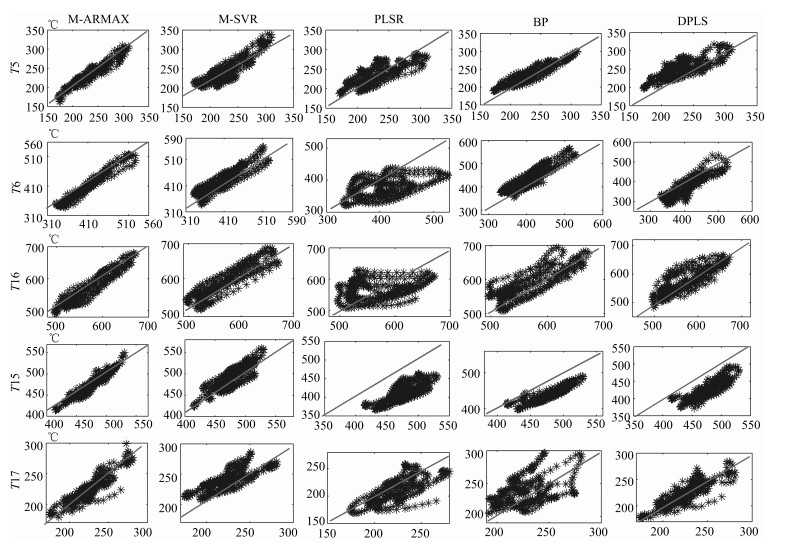
图 9 不同建模方法温度估计值与实际值散点图
Fig. 9 Scatter diagram of estimated temperature and actual temperature by different models
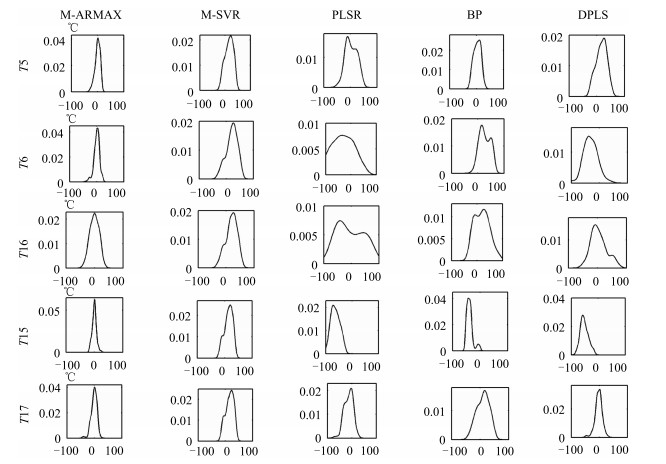
图 10 不同建模方法温度估计误差PDF曲线
Fig. 10 PDF curve of temperature estimation error by different models
表 1 KMO和Bartlett分析结果
Table 1 The results of KMO and Bartlett analysis
取样足够度的KMO度量 Bartlett的球形度检验 近似卡方 df Sig. 0.778 10 051.361 10 0  下载: 导出CSV
下载: 导出CSV
表 2 因子载荷矩阵
Table 2 Factor loading matrix
测温点 $T$5 $T$6 $T$15 $T$16 $T$17 因子载荷 0.756 0.418 0.850 0.889 0.560
下载: 导出CSV
表 3 输入输出变量的Pearson相关系数
Table 3 Pearson correlation coefficients between inputs and outputs
温度点 $T$5 $T$6 $T$15 $T$16 $T$17 $T$3 0.676** 0.131** 0.498** 0.299** 0.556** $T$4 0.860** 0.026 0.538** 0.296** 0.648** $T$8 0.631** 0.246** 0.462** 0.242** 0.591** $T$10 0.677** 0.141** 0.462** 0.325** 0.580** $T$20 0.487** 0.023 0.243** -0.021 0.411** 顶温东南 0.684** 0.634** 0.656** 0.617** 0.467** 顶温西北 0.786** 0.434** 0.734** 0.579** 0.691** 顶温东北 0.616** 0.702** 0.612** 0.545** 0.545** 顶温西南 0.788** 0.569** 0.737** 0.741** 0.620** **相关性在0.01显著. $T$1, $T$2, $\cdots, $ $T$21分别表示测温点1, 2, $\cdots$, 21.
下载: 导出CSV
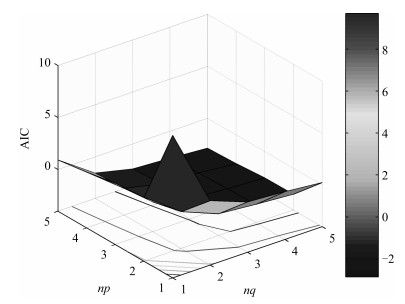
表 4 不同阶次对应的模型拟合优度
Table 4 The goodness of model fit value corresponding to different order
模型阶次组合 (1, 1) (2, 1) (2, 2) (3, 3) 模型拟合优度函数值 91.03 95.42 96.27 96.7 模型阶次组合 (4, 1) (5, 1) (4, 4) (5, 5) 模型拟合优度函数值 95.32 95.89 96.29 94.61
下载: 导出CSV
-
[1] 宋贺达, 周平, 王宏, 柴天佑.高炉炼铁过程多元铁水质量非线性子空间建模及应用.自动化学报, 2015, 42(11):1664-1679 http://www.aas.net.cn/CN/abstract/abstract18956.shtmlSong He-Da, Zhou Ping, Wang Hong, Chai Tian-You. Nonlinear subspace modeling of multivariate molten iron quality in blast furnace ironmaking and its application. Acta Automatica Sinica, 2015, 42(21):1664-1679 http://www.aas.net.cn/CN/abstract/abstract18956.shtml [2] Zhou P, Yuan M, Wang H, Wang Z, Chai T Y. Multivariable dynamic modeling for molten iron quality using online sequential random vector functional-link networks with self-feedback connections. Information Sciences, 2015, 325:237-255 doi: 10.1016/j.ins.2015.07.002 [3] Jian L, Gao C H, Xia Z H. Constructing multiple kernel learning framework for blast furnace automation. IEEE Transactions on Automation Science and Engineering, 2012, 9(4):763-777 doi: 10.1109/TASE.2012.2211100 [4] Birk M, Marklund O, Medvedev A. Video monitoring of pulverized coal injection in the blast furnace. IEEE Transactions on Industry Applications, 2002, 38(2):571-576 doi: 10.1109/28.993181 [5] 王贤.高炉十字测温冷却装置优化设计方案的探讨.钢铁技术, 2010, (1):1-3 http://www.cqvip.com/qk/95056X/201001/index.shtmlWang Xian. Discussion on optimum design scheme of cross temperature measuring and cooling device for blast furnace. Iron and Steel Technology, 2010, (1):1-3 http://www.cqvip.com/qk/95056X/201001/index.shtml [6] 涂正环.高炉十字测温枪快速更换的研究.中国机械, 2015, (22):185-186 http://www.cqvip.com/QK/90643X/201522/666413521.htmlTu Zheng-Huan. Research on quick replacement of cross temperature measuring gun for blast furnace. Machine China, 2015, (22):185-186 http://www.cqvip.com/QK/90643X/201522/666413521.html [7] 唐振浩, 唐立新, 杨阳.基于数据驱动和智能优化的高炉十字测温温度预报.信息与控制, 2014, 43(3):355-360 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201403018.htmTang Zhen-Hao, Tang Li-Xin, Yang Yang. Blast furnace cross temperature prediction based on data-driven and intelligent optimization. Information and Control, 2014, 43(3):355-360 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201403018.htm [8] 徐化冰, 徐华岩.基于TD算法的时序神经网络高炉炉喉十字测温预报.工业炉, 2013, 35(3):44-48 http://www.cnki.com.cn/Article/CJFDTotal-GYLZ201303015.htmXu Hua-Bing, Xu Hua-Yan. Blast fuenace throat cross temperature forecast by time-sequence neural network based on TD algorithm. Industrial Furnace, 2013, 35(3):44-48 http://www.cnki.com.cn/Article/CJFDTotal-GYLZ201303015.htm [9] Ueda S, Natsui S, Nogami H, Yagi J I, Ariyama T. Recent progress and future perspective on mathematical modeling of blast furnace. ISIJ International, 2010, 50(7):914-923 doi: 10.2355/isijinternational.50.914 [10] Nurkkala A, Pettersson F, Saxén H. Blast furnace dynamics using multiple autoregressive models with exogenous inputs. ISIJ International, 2012, 52(10):1764-1771 doi: 10.2355/isijinternational.52.1764 [11] Cai M L, Cai F, Shi A G, Zhou B, Zhang Y S. Chaotic time series prediction based on local-region multi-steps forecasting model. Advances in Neural Networks-ISNN 2004. Lecture Notes in Computer Science. Berlin, Heidelberg, Germany:Springer, 2004. 418-423 [12] 许美玲, 韩敏.多元混沌时间序列的因子回声状态网络预测模型.自动化学报, 2015, 41(5):1042-1046 http://www.aas.net.cn/CN/abstract/abstract18678.shtmlXu Mei-Ling, Han Min. Factor echo state network for multivariate chaotic time series prediction. Acta Automatica Sinica, 2015, 41(5):1042-1046 http://www.aas.net.cn/CN/abstract/abstract18678.shtml [13] Burnham K P, Anderson D R. Multimodel inference:understanding AIC and BIC in model selection. Sociological Methods and Research, 2004, 33(2):261-304 doi: 10.1177/0049124104268644 [14] Chaurasia A, Harel O. Using AIC in multiple linear regression framework with multiply imputed data. Health Services and Outcomes Research Methodology, 2012, 12(2-3):219-233 doi: 10.1007/s10742-012-0088-8 [15] Resende P A A, Dorea C C Y. Model identification using the efficient determination criterion. Journal of Multivariate Analysis, 2016, 150:229-244 doi: 10.1016/j.jmva.2016.06.002 [16] 辛斌, 白永强, 陈杰.基于偏差消除最小二乘估计和Durbin方法的两阶段ARMAX参数辨识.自动化学报, 2012, 38(3):491-496 http://www.aas.net.cn/CN/abstract/abstract17669.shtmlXin Bin, Bai Yong-Qiang, Chen Jie. Two-stage ARMAX parameter identification based on bias-eliminated least squares estimation and Durbin's method. Acta Automatica Sinica, 2012, 38(3):491-496 http://www.aas.net.cn/CN/abstract/abstract17669.shtml [17] Wang C, Tang T. Recursive least squares estimation algorithm applied to a class of linear-in-parameters output error moving average systems. Applied Mathematics Letters, 2014, 29:36-41 http://www.doc88.com/p-7864453437298.html [18] 杜大军, 商立立, 漆波, 费敏锐.一种不完全信息下递推辨识方法及收敛性分析.自动化学报, 2015, 41(8):1502-1515 http://www.aas.net.cn/CN/abstract/abstract18724.shtmlDu Da-Jun, Shang Li-Li, Qi Bo, Fei Min-Rui. Convergence analysis of an online recursive identification method with uncomplete communication constraints. Acta Automatica Sinica, 2015, 41(8):1502-1515 http://www.aas.net.cn/CN/abstract/abstract18724.shtml [19] Karimi M. On the residual variance and the prediction error for the LSF estimation method and new modified finite sample criteria for autoregressive model order selection. IEEE Transactions on Signal Processing, 2005, 53(7):2432-2441 doi: 10.1109/TSP.2005.849182 [20] Frandsen S. Relevant criteria for testing the quality of models for turbulent wind speed fluctuations. Journal of Solar Energy Engineering Transactions of the Asme, 2008, 130(3):1047-1057 [21] 高燕, 周成虎, 苏奋振.基于OLI影像多参数设置的SVM分类研究.测绘工程, 2014, 23(6):1-5, 10 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chgc201406001Gao Yan, Zhou Cheng-Hu, Su Fen-Zhen. Study on SVM classifications with multi-features of OLI images. Engineering of Surveying and Mapping, 2014, 23(6):1-5, 10 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chgc201406001 [22] Ahmad A S, Hassan M Y, Abdullah M P, Rahman H A, Hussin F, Abdullah H, Saidur R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renewable and Sustainable Energy Reviews, 2014, 33:102-109 doi: 10.1016/j.rser.2014.01.069 [23] Kuo B C, Ho H H, Li C H, Hung C C, Taur J S. A kernel-based feature selection method for SVM with RBF kernel for hyperspectral image classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(1):317-326 doi: 10.1109/JSTARS.2013.2262926 [24] Ren T, Liu S, Yan G C, Wu H P. Temperature prediction of the molten salt collector tube using BP neural network. IET Renewable Power Generation, 2016, 10(2):212-220 doi: 10.1049/iet-rpg.2015.0065 [25] Zhang Y X, Gao X D, Katayama S. Weld appearance prediction with BP neural network improved by genetic algorithm during disk laser welding. Journal of Manufacturing Systems, 2015, 34:53-59 doi: 10.1016/j.jmsy.2014.10.005 [26] Farifteh J, van der Meer F, Atzberger C, Carranza E J M. Quantitative analysis of salt-affected soil reflectance spectra:a comparison of two adaptive methods (PLSR and ANN). Remote Sensing of Environment, 2007, 110(1):59-78 doi: 10.1016/j.rse.2007.02.005 [27] Sarkar A, Karki V, Aggarwal S K, Maurya G S, Kumar R, Rai A K, Mao X L, Russo R E. Evaluation of the prediction precision capability of partial least squares regression approach for analysis of high alloy steel by laser induced breakdown spectroscopy. Spectrochimica Acta Part B:Atomic Spectroscopy, 2015, 108:8-14 doi: 10.1016/j.sab.2015.04.002 -

 下载:
下载:

计量
- 文章访问数: 2443
- HTML全文浏览量: 457
- PDF下载量: 874
- 被引次数: 0
