

-
摘要: 犯罪行为分析是侦查破案的重要参考,也是学界长期以来关注的热点.目前,犯罪行为分析主要采用现场证据-行为推断的思路,忽略了犯罪过程中犯罪主体和客体之间的复杂互动.本文在基于ACP(Artificial societies(人工社会)+Computational experiments(计算实验)+Parallel execution(平行执行))方法的犯罪现场平行系统框架下,从行为动力学角度提出了故意杀人行为的犯罪主体时间和空间互动模型,并采用真实案例数据对模型参数进行了标定.计算实验结果表明,本文提出的互动模型能较好地模拟真实数据,从而为分析犯罪过程中的复杂互动提供了一个可靠的基础.Abstract: Being important for criminal investigation, criminal behavioral analysis is always an active research topic among scholars. Current methods of criminal behavioral analysis mainly adopt the approach of evidence-behavior inference, and ignore the complex interactions between the criminal and the victim. In the framework of ACP (artificial societies + computational experiments + parallel execution)-based parallel system, this paper proposes temporal-spatial interaction models for artificial criminals from the behavioral dynamics point of view. In addition, actual intentional homicide data is used to demarcate the parameters of the models. Results of computational experiments indicate that the proposed interaction models can simulate the criminal frequencies very well according to the actual data source. Thus they provide a solid foundation for the complex interactions in criminal behavioral analysis.
-
Key words:
- Crime /
- behavior modeling of agent /
- ACP approach /
- parallel system /
- behavioral dynamics
-
受控生态生保系统(Controlled ecological life support systen, CELSS)是载人航天长期驻留任务的必然途径.该系统能够实现氧气、水和食物的自给自足.高等植物能够利用光能将二氧化碳和水合成为有机物, 并产生氧气, 同时通过蒸腾作用实现水的净化, 可以保障人在太空中对环境和食品的需求, 是受控生态生保系统中的关键生物部件[1-7].空间植物栽培技术研究已有40余年的发展历程, 已进行多种植物的空间栽培实验, 重点研究微重力对植物生长发育的影响.
1975年前苏联就开始了空间植物栽培的探索, 他们尝试在飞船中栽种小麦、洋葱等植物. 20世纪90年代, 俄罗斯和保加利亚联合研制了SVET空间温室, 在和平号空间站进行了长期搭载, 并在其中完成了小麦``从种子到种子"的三代完整生长周期培养. 2002年, 俄罗斯针对国际空间站研制了一款名为LADA的空间温室, 至今已进行了20多次空间植物栽培实验, 成功培育了小麦、生菜等植物.近期俄罗斯研制了新一代LADA空间温室, 拟用于多种植物的空间栽培[8-10].
2014年, NASA将Veggie空间蔬菜生产系统运送到空间站, 并进行了Veg-01实验. 2015年, 经过33天的培养, 三名航天员在空间站收获并品尝了第二批种植的蔬菜---红色长叶莴苣. 2015年11月, NASA在轨道实验室进行了百日菊培养实验, 并进行了天地对比.在太空中, 百日菊完成了开花过程, 并于2016年2月进行了收获[11-16].
为将前期CELSS植物栽培研究成果应用于真正的受控生态生保系统, 必须进行空间植物搭载实验.航天员中心在空间实验室任务中搭载一台植物栽培装置, 在轨验证植物在空间环境中的栽培技术和生长发育状况.
空间微重力下水分传导特性与地面有很大不同.在微重力条件下, 流体行为发生根本变化, 植物周围形成边界层, 导致植物与周围物质交换变得困难.同时, 在微重力条件下实现栽培基质水分养分的充分供应, 同时保证栽培基质的通气也具有挑战性.在空间微重力下进行植物光合、蒸腾和呼吸作用效率的测定与评价也具有较大难度.因此, 微重力下的水分养分控制技术是空间植物栽培的关键.航天员中心在空间实验室任务中搭载一台植物栽培装置, 以验证空间微重力下植物栽培水分养分的控制技术.
因此, 微重力下的水分养分控制技术是空间植物栽培的关键.航天员中心在空间实验室任务中搭载一台植物栽培装置, 以验证空间微重力下植物栽培水分养分的控制技术.
1. 材料与方法
1.1 实验条件
实验时间为2016年10月20日到11月15日, 实验地点为天宫二号空间实验室.
空间实验室在轨进行空间植物栽培的同时, 地面同步进行模拟空间实验室大气环境参数的植物栽培对照实验, 实验条件及栽培方法均与天基实验相同, 区别为地基实验为完全重力.
天基实验环境条件控制如表 1所示, 地基实验条件控制以前一天天基环境参数测量平均值为标准.播种过程在地面完成, 种子在萌发结构中播种完毕, 随飞行器进入空间.
表 1 实验条件设置Table 1 Test condition setting参数类别 参数范围 大气温度 23 $^{\circ}$C $\pm$ 0.5 $^{\circ}$C 大气相对湿度 $50 \% \pm 5 \%$ 大气压力 常压 大气氧浓度 $20.9 \% \pm 0.5 \%$ 大气二氧化碳浓度 0.2 %$\sim$ 0.4 % 植物光照条件 光源为红蓝绿发光二极管(LED),红蓝绿三色比例$8:1:1$; 光照周期为14 hr(亮)/8 hr (暗) 生长周期 29天 1.2 实验装置
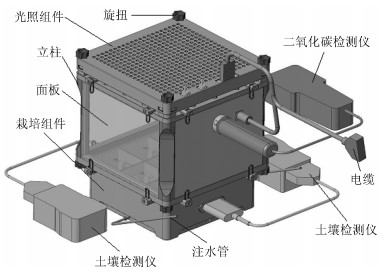
本研究利用自主研制的空间植物栽培装置进行.空间植物栽培装置的结构如图 1所示, 装置主要参数如表 2所示.
表 2 空间植物栽培装置达到的主要性能指标Table 2 Main performance indicators of space plant cultivation device类别 项目名称 主要性能指标 空间植物栽培装置 大小 长方体结构包络尺寸L(268 mm) $\times$ W(268 mm) $\times$ H(306 mm) 重量 5.8 kg (含所有相关配套测试设施及物品) 功耗 峰值16.4 W 栽培单元 1)栽培面积: $0.045 {\rm m}^2$ 2)可栽培株数: 9株 3)栽培基质+导水材料:蛭石+棉质纱布 4)水分管理:具备加水管路, 栽培盒左右两侧可分别进行栽培基质含水量测量, 测量范围0 $\sim$ 100 %, 测量精度±3 %. 5)养分管理:采用长效缓释肥颗粒进行养分供应, 栽培盒左右两侧可分别进行栽培基质电导率测量, 测量范围0 $\sim$ 300 mS/m, 测量精度±0.3 mS/m. 6)种子固定结构:具备2个细缝、1个大圆孔和2个小圆孔等三种固定种子的结构形式. 7)固定盖板:安装固定在在种子固定结构上, 具有9个苗孔; 可方便拆卸. 光照单元 1)光源: LED灯 2)光质:红、蓝、绿比例约为8 : 1 : 1 3)光强:光源正下方5 cm处平均达到105 μmol$ \cdot {\rm m}^{-2}\cdot {\rm s}^{-1}$. 4)光源功率: 13.5 W 5)光周期: 0 $\sim$ 24 hrs手动可调 生长单元 1)四面由立柱和透明有机玻璃制成, 立柱具备长、短两种类型, 可方便更换. 2)在长立柱条件下四周可开放也可密封. 测量单元 1)可进行栽培基质中含水量和电导率的手动监测, 含水量测量范围0 $\sim$ 100 %, 电导率测量范围0 $\sim$ 300 mS/m. 2)装置封闭条件下可手动进行大气CO$_2$浓度监测, 测量范围0 $\sim$ 5 000 ppm, 分辨率1 ppm. 保障单元 具备自主通风组件和12 V直流供电电源接口. 整体设计及接口要求 1)采取了模块化设计, 可方便拆卸、折叠、绑扎、悬挂或固定. 2)结构采用了轻质、无毒无害和非易燃的非金属材料. 3)具有安装机械接口和直流供电电源接口. 4)具备较好的工效学设计. 1.3 水分控制
1.3.1 水分传导结构
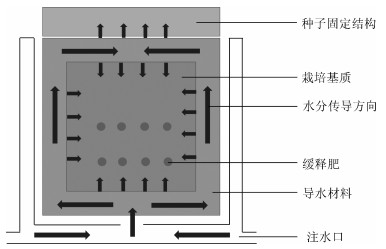
针对空间微重力特点, 在植物栽培盒空间内设计了特殊的水分传导结构和路径, 保证在微重力环境下水分能够在栽培空间内有效传导, 并供给植物的水分需求.水分传导结构由栽培盒体、供水管路、栽培基质、导水材料、种子固定结构组成, 具体的结构如图 2所示.
栽培盒体构成水分传导结构的外边界, 在栽培盒底部, 分布着供水管路.栽培基质作为根系生长介质, 填充在栽培空间内.在栽培基质中间分布着导水材料构成的导水框架.栽培基质上方与种子固定结构连接.
1) 栽培盒体
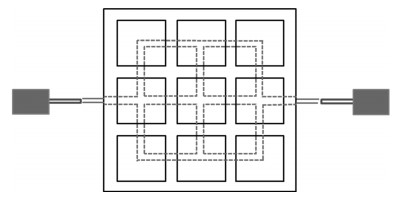
栽培盒体采用3D打印制成, 结构采用九宫格设计, 每一格对应一株生菜.格与格之间由挡板隔开, 使每个格相对独立, 以保证整个栽培结构的稳定性.挡板中间镂空, 用于格与格之间传导水分, 保持每株生菜基质含水率均匀.
2) 供水管路
供水管路位于栽培盒体底部, 使注入的水分迅速流通至每一个格的下方, 如图 3所示.
3) 栽培基质
栽培基质是水分传导的最主要载体, 其理化性能直接影响整个结构水分传导的能力.为保证空间微重力下水分的有效传导, 必须严格筛选栽培基质.筛选标准包括容重、比重、孔隙率、结构强度、导水性、持水性、阳离子交换量等理化指标.
4) 导水材料
导水材料为纤维材质, 导水性强, 其作用是在栽培基质中间构建起导水框架, 协助整个栽培空间内的水分传导, 促进水分在整个空间内的均匀分布.
5) 种子固定结构
种子固定结构材质为聚乙烯醇缩甲醛树脂, 位于栽培基质上方, 与栽培基质连接, 从栽培基质中吸取水分, 为种子萌发提供适宜的水分.
聚乙烯醇缩甲醛树脂具有以下特点:
1) 高吸水性和高导水性.这一特性保证其能够从栽培基质中吸取足够的水分促使种子萌发.
2) 轻质.这一特性保证其不会增加太多重量, 有利于控制整套装置重量.
3) 干燥时为刚性, 吸水后为柔性.干燥时为刚性, 保证了在随飞行器上行震荡过程中栽培结构的稳定; 在轨实验开始后, 通过注水, 使树脂材料变为柔性, 满足种子萌发和扎根需求.
1.3.2 水分传导路径
水分传导路径设计: 1)纤维导水材料导水速度比蛭石快; 2)水注入供水管路后, 首先沿着纤维导水材料传导至整个纤维导水框架; 3)而后水分通过纤维导水材料组成的导水框架渗透至蛭石; 4)种子固定结构从纤维导水材料吸取水分, 支持种子萌发.
1.3.3 水分测定
水分测定采用土壤多参数分析仪, 其测定原理为频域反射.仪器探头有3个探针, 覆盖面积大, 可测定较大基质范围内的含水率.栽培盒两侧各有一个探头插入栽培基质, 用于验证基质含水率的均匀性.每天读取一次含水率数据, 最后绘制成含水率变化曲线, 用于分析整个实验周期内含水率变化规律, 为水分控制技术研究提供数据支撑.
1.3.4 补水机制
补水机制的确定采用地面确定标准--在轨曲线测定--天地比对--修正的基本方法: 1)栽培基质种类筛选完毕后, 针对该基质特点, 确定适合植物生长的基质含水率范围. 2)在地基验证实验中, 根据含水率控制范围, 确定补水时间和补水量. 3)在天基实验中, 根据地面确定的补水时间和补水量进行补水.同时每天测定基质含水率. 4)根据含水率数据绘制天基实验含水率曲线, 并与地基验证实验含水率曲线进行比对.
1.4 养分控制
1.4.1 养分供应
养分供应方式:缓释肥.缓释肥是一种可以持续缓慢释放养分的特殊肥料, 通过硫基树脂等包衣材料控制内部养分释放速率; 针对本次实验, 专门研制了适合生菜生长发育规律的缓释肥, 肥效30天, 成分配比如表 3.
表 3 缓释肥成分配比Table 3 Ingredient ratio of slow release fertilizer成分 质量分数(%) 氮 NO3-N 9 NH4-N 11 磷 水溶性P 6.2 枸溶性P 1.8 钾 10 硫 4 钙 2 镁 0.2 铁锰铜锌硼 0.08 缓释肥放置位置为栽培基质中层和下层, 如图 2所示.
2. 结果与分析
2.1 栽培基质水分养分控制情况及分析
2.1.1 栽培基质水分控制情况及分析
由于水分和养分情况对植物生长发育具有重要影响, 因此在研究空间微重力对植物生长发育影响的同时, 必须监测微重力下基质水分养分控制情况, 了解微重力对水分养分传导和分布的影响.整个实验期间, 天基和地基同步对照实验栽培盒基质中水分的动态变化监测情况如图 4所示.
 图 4 天基和地基同步对照实验栽培基质含水率变化曲线Fig. 4 Change curves of moisture content of substrates in space-based and ground-based synchronous controlled trials
图 4 天基和地基同步对照实验栽培基质含水率变化曲线Fig. 4 Change curves of moisture content of substrates in space-based and ground-based synchronous controlled trials从图 4中可以看出, 实验前期, 天基水分测量值明显高于地基对照测量值, 而且天基与地基的变化趋势相反, 即天基基质水分大约在第1 $\sim$ 10天期间, 其每天在不断缓慢上升, 之后在约第11 $\sim$ 15天内基本保持平稳, 再后在约第16 $\sim$ 18天三天内则开始逐步缓慢下降.在第18天补充水分和营养液后, 天基基质含水率测量值较地基急剧上升, 之后则急速下降.由此可以看出, 天基栽培基质水分测量值与地基测量值存在较大差异, 但从第15天后开始变化趋势接近, 这在一定程度上能够大致反映水分的变化趋势. 1995年, 美俄科学家在``和平号"空间站利用空间温室-2联合进行过在轨植物栽培基质含水量测试.其采用的是热脉冲湿度传感器(Heat pulse moisture sensors), 实验结果表明其天基测量数据也要明显高于地基, 高出约2.5倍.该实验的天地栽培基质水分监测差异性原因的分析过程与结果是:在地面上, 土壤中水分受到重力、吸附力和表面张力(即毛细管力)等三种力的作用, 保持土壤水分的力主要是吸附力和表面张力, 而重力主要影响水分进行垂直分布.此时, 当给基质浇水后, 水分由于受到重力作用(当然同时也受到吸附力和表面张力作用)而不断下沉, 在基质颗粒表面不易形成水膜, 因此其含水量测量值会逐渐呈下降趋势.而在天基微重力条件下, 由于基质水分失去重力作用, 水分运动和分布的主要影响力变为吸附力和表面张力, 这两种力会使水分在基质颗粒中缓慢进行同心圆均匀化分布, 并在其表面极易形成较厚的一层水膜[17].
因此, 在天基开始浇水后探头周围的水分含量会逐渐上升, 过一定时间后会达到水分平衡, 之后随着基质蒸发和植株吸收水分等作用导致失水, 基质含水量则会逐渐下降.
本实验采用的是频域反射湿度传感器(Frequency-domain reflection moisture sensors), 实验所测得基质含水量数据变化情况与上述文献资料报道的情况相似, 因此, 尽管双方的测量原理不同, 但我们认为本次实验其栽培基质水分监测天地差异性的原因与上述文献报道的差异原因分析相同, 即本实验利用另外一种测量原理真实反映了天基微重力条件下植物栽培基质中水分的动态传导与分布特征, 而并非仪器受微重力等影响而测试不准确所致.因此, 本次实验研究结果证明, 基于频域反射原理的土壤湿度传感器可用于空间微重力条件下的植物栽培基质含水量测试, 能够较为精确反映在轨植物栽培基质水分的动态分布特征与规律, 而且证明该测试方法对周围环境的电子仪器设备等没有任何干扰或破坏作用(国外担心该方法会对周围仪器设备造成影响而一直未做过尝试), 因此, 本次实验为今后利用频域反射原理实施空间植物栽培技术水分管理奠定了重要基础.
2.1.2 栽培基质养分控制情况及分析
天基实验与地基同步对照实验的栽培基质电导率均呈现先上升后稳定的趋势, 天基实验达到130 ms/m左右后趋于稳定, 而地基同步对照实验达到140 ms/m左右后趋于稳定, 即地基略高于天基.这与前期地面1:1验证实验的规律一致.实验第18天补营养液后, 天基和地基同步对照实验的栽培基质电导率均上升, 天基测量值略高于地基, 之后天基与地基电导率均逐日较快下降, 趋势较为一致, 如图 5所示.
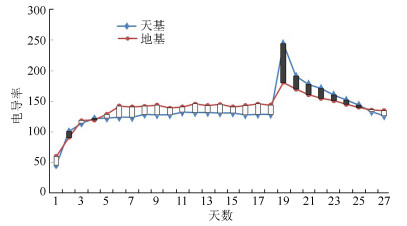 图 5 天基和地基同步对照实验栽培基质电导率变化曲线Fig. 5 Electrical conductivity curves of space-based and ground-based synchronous controlled culture media
图 5 天基和地基同步对照实验栽培基质电导率变化曲线Fig. 5 Electrical conductivity curves of space-based and ground-based synchronous controlled culture media整个栽培过程中, 天基与地基实验电导率在大部分时间均保持在100 $\sim$ 150 mS/m水平范围内, 吻合度较好.由此可以说明, 天基和地基条件下栽培基质的养分释放和传导分布情况相似, 因此, 基于频域反射原理的土壤水分仪同样能够基本正常测量栽培基质的养分电导率.另外, 到目前为止, 尚未见有关在轨植物栽培基质电导率监测的文献资料报道, 因此, 本次在轨植物栽培基质电导率监测技术实验在国际上尚属首次.
2.2 种子发芽情况
实验结果表明, 实验启动后第三天, 种子开始萌发.天基实验发芽时间与地基同步对照实验的种子开始发芽时间基本一致.实验结果表明, 在三种种子萌发结构中, 吸水材料切缝结构发芽率最高, 其次为海绵材料发芽结构, 丸粒化结构发芽率较低.这与地基同步对照实验的种子发芽率变化趋势是一致的.然而, 相比地基同步对照实验, 天基实验三种播种方式发芽率均有所下降, 具体情况如表 4所示.
表 4 天基和地基同步对照实验发芽情况统计Table 4 Germination statistics of space-based and ground-based synchronous controlled trials实验类别 发芽结构类别 发芽个数/播种个数 发芽率 天基实验 切缝结构 33/99 37 % 圆孔+海绵 11/45 24 % 小圆孔+大粒化 0/18 0 % 地基同步对照实验 拉缝 65/90 72 % 圆孔+海绵 29/45 64 % 小圆孔+大粒化 5/18 28 % 种子在空间微重力下发芽率降低的原因可能有两个: 1)微重力直接作用于种子萌发过程, 导致发芽率降低; 2)微重力影响了种子萌发的环境条件, 间接导致发芽率降低.
在之前进行的空间微重力条件种子萌发实验表明, 微重力并不会影响种子的萌发过程[18-19].因此可以判断, 微重力并未直接影响种子萌发过程, 而是通过改变种子萌发的环境条件间接降低了发芽率.天地差异可能导致水分传输条件不同从而造成发芽效果不同.地基同步对照实验由于重力作用, 吸水材料、海绵与种子表皮之间贴合紧实程度较高, 水分容易被种子吸收; 天基实验在微重力条件下, 吸水材料、海绵与种子表皮之间贴合紧实程度没有地面高, 因此水分传导不如地基同步对照实验.种子吸水难易程度的差异导致发芽率不同.丸粒化结构在天基发芽不理想, 10粒种子均未发芽.究其原因是大粒化种子的外表包裹层虽具有纤维导水材料, 但在微重力条件下其与周围接触不好, 阻碍其获取了种子发芽所需的适宜水分.
2.3 植株生长状况及分析
实验期间, 天基实验与地基同步对照实验的植株生长发育均正常, 如图 6所示.
天基实验植株基本株型未出现明显异常, 前期相比地基实验叶片显得散乱, 第27天时天基与地基整体株型无明显差异.天基实验茎秆长度大于地基实验, 平均株高高于地基实验.生长初期天基实验植株发育稍慢于地基实验(进入三叶期稍晚), 12天以后天基实验和地基实验平均叶片数无显著差异.叶片颜色方面, 天基实验植株呈深绿色, 整个叶片从叶片基部到叶片边缘颜色均匀, 无颜色过渡; 地基实验植株呈浅绿色, 叶片基部(叶柄部分)近乳白色, 从叶片基部到叶片边缘绿色逐渐加深.
颜色的差异反应的是植株叶绿素含量及分布的差异.有研究表明, 叶绿体数量及活性受到微重力作用的影响, 数量及活性均有所提高[20], 这也解释了为什么天基实验植株绿色比地基实验更深.而颜色均匀性的差异说明, 在微重力条件下, 生菜在地面形成的叶绿素分布规律被打破, 而呈现均匀分布的特点.这与微重力下物质转运特性有关.在地面环境下, 植株为了最大限度的提高光合效率, 叶绿素更多的向叶片边缘转运, 而这种机理受到重力调控, 与细胞内重力信号转导受体有关, 因此在微重力下叶绿素分布规律被打破, 呈现均匀分布.
3. 结论
通过实验, 验证了微重力下水分养分传导结构的合理性, 了解了空间微重力下水分养分的传导和分布规律, 为研究空间植物栽培水分养分供应方法和测试方法提供了依据.生菜在空间实验室微重力环境下的顺利萌发、生长发育, 表明了种子萌发结构、水分养分传导及控制方法的合理性和可行性, 为后续开展更大规模的空间植物栽培奠定了基础.
-
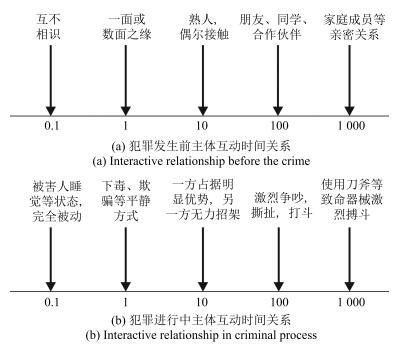
图 2 犯罪不同阶段时间互动关系简化
Fig. 2 Simplified temporal interactive relationship in different stages of crime
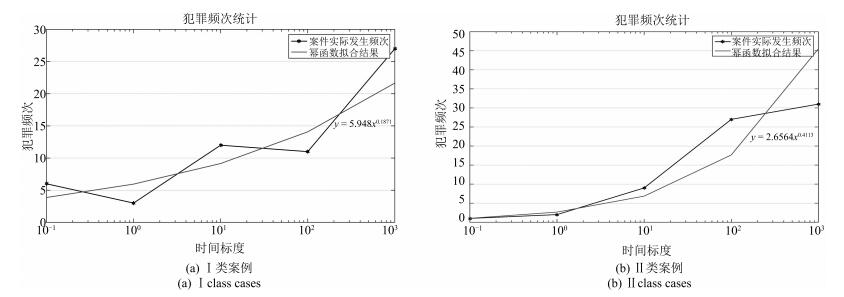
图 5 犯罪进行中双方互动时间关系:现场激烈程度分析
Fig. 5 Temporal interactive relationship in criminal process: analysis of scene fierce degree
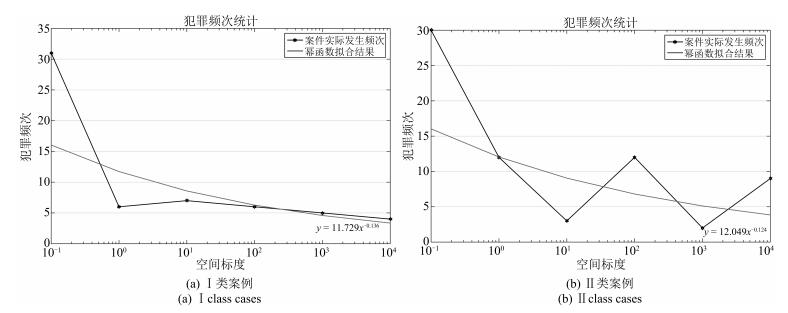
图 8 犯罪发生后犯罪人逃逸轨迹:距犯罪现场
Fig. 8 Criminal escape trajectory after the crime: distance from the crime scene
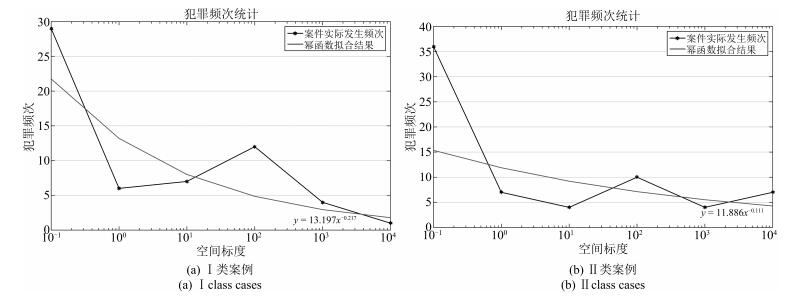
图 9 犯罪发生后犯罪人逃逸轨迹:距犯罪人住处
Fig. 9 Criminal escape trajectory after the crime: distance from the criminal residence
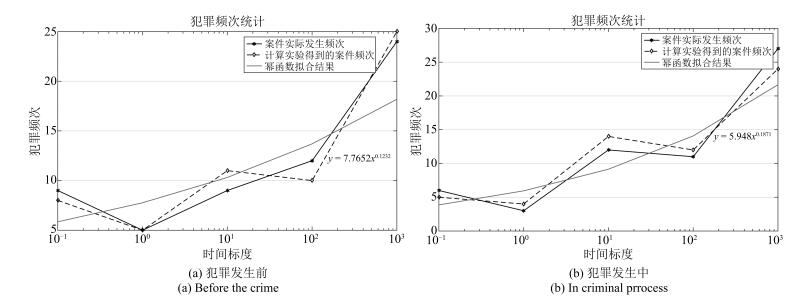
图 10 犯罪行为时间模型计算实验结果
Fig. 10 Results of computational experiment for the temporal criminal model
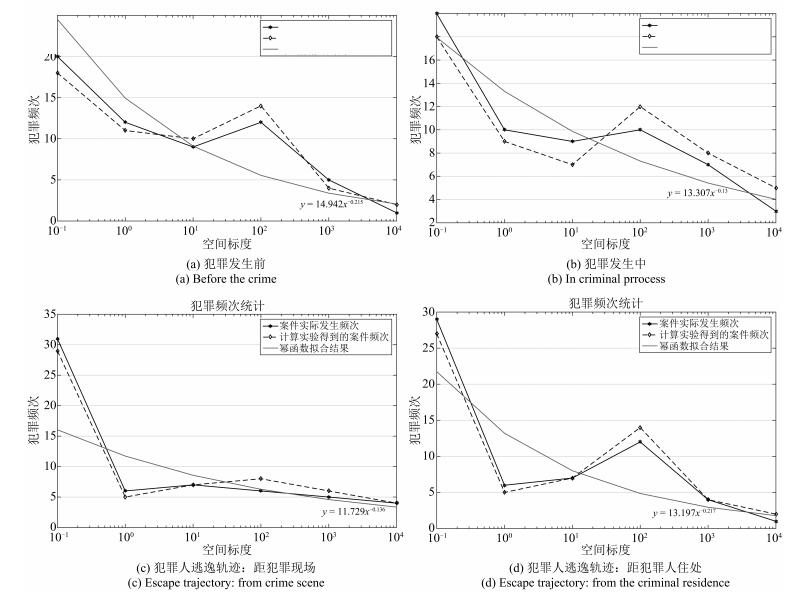
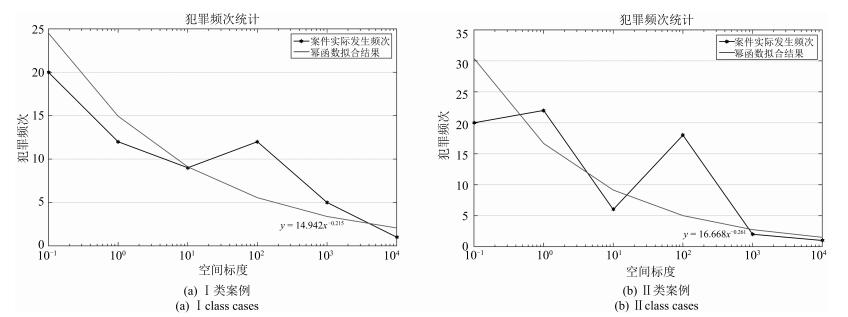
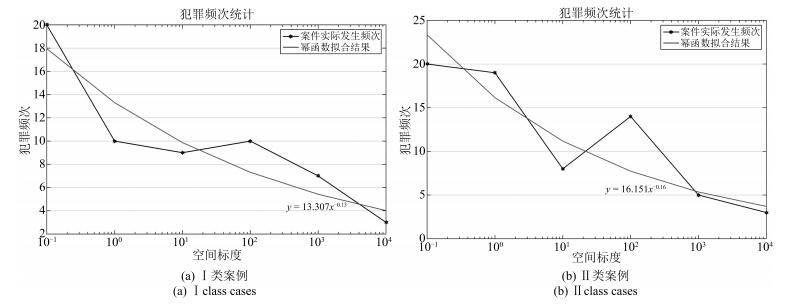
图 11 犯罪行为空间模型计算实验结果
Fig. 11 Results of computational experiment for the spatial criminal model
表 1 犯罪主体行为模型参数值
Table 1 Parameter values of criminal subject behavior model
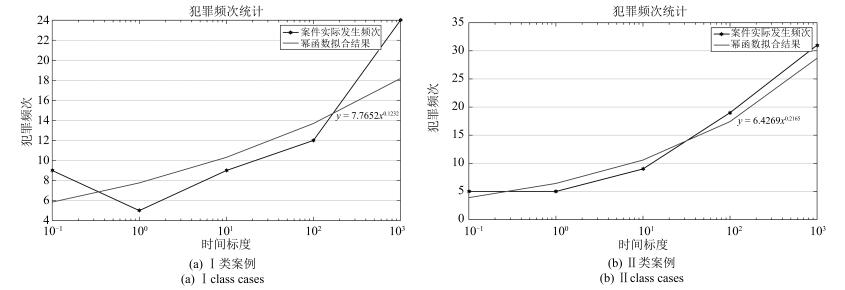
类别 表达式 犯罪阶段 Ⅰ类案例 Ⅱ类案例 $ \alpha_{t} $或$ \alpha_{s} $ $ \beta_{t} $或$ \beta_{s} $ $ \alpha_{t} $或$ \alpha_{s} $ $ \beta_{t} $或$ \beta_{s} $ 犯罪主体行为时间模型 $ y= \alpha_{t} \times x_{t}^{ \beta_{t}}$ 犯罪发生前 7.7652 0.1232 6.4269 0.2165 犯罪进行中 5.948 0.1871 2.6564 0.4113 犯罪主体行为空间模型 $ y= \alpha_{s} \times x_{s}^{- \beta_{s}}$ 犯罪发生前 14.942 0.215 16.668 0.261 犯罪进行中 13.307 0.13 16.151 0.16 犯罪后逃逸(与犯罪现场距离) 11.729 0.136 12.049 0.124 犯罪后逃逸(与原住处距离) 13.197 0.217 11.886 0.111  下载: 导出CSV
下载: 导出CSV
-
[1] Douglas J E, Ressler R K, Burgess A W, Hartman C R. Criminal profiling from crime scene analysis. Behavioral Sciences and the Law, 1986, 4 (4):401-421 doi: 10.1002/(ISSN)1099-0798 [2] Canter D. Offender profiling and investigative psychology. Journal of Investigative Psychology and Offender Profiling, 2004, 1 (1):1-15 doi: 10.1002/(ISSN)1544-4767 [3] Chisum W, Turvey B. Evidence dynamics:locard's exchange principle and crime reconstruction. Journal of Behavioral Profiling, 2000, 1 (1):1-15 http://citeseerx.ist.psu.edu/showciting?cid=1452058 [4] Baumgartner K, Ferrari S, Palermo G. Constructing Bayesian networks for criminal profiling from limited data. Knowledge-Based Systems, 2008, 21 (7):563-572 doi: 10.1016/j.knosys.2008.03.019 [5] Bitzer S, Ribaux O, Albertini N, Delémont O. To analyse a trace or not? evaluating the decision-making process in the criminal investigation. Forensic Science International, 2016, 262:1-10 doi: 10.1016/j.forsciint.2016.02.022 [6] 刘烁, 王帅, 傅焕章, 王飞跃.软件定义的犯罪现场分析过程及其知识自动化方案.模式识别与人工智能, 2016, 29 (10):876-883 http://www.analog.com/cn/applications/markets/process-control-and-industrial-automation.htmlLiu Shuo, Wang Shuai, Fu Huan-Zhang, Wang Fei-Yue. Software-defined crime scene analysis process and its knowledge automation scheme. Pattern Recognition and Artificial Intelligence, 2016, 29 (10):876-883 http://www.analog.com/cn/applications/markets/process-control-and-industrial-automation.html [7] 钟武魁, 周旭科.杀人案中犯罪嫌疑人处理现场行为分析.刑事技术, 2015, 40 (6):474-476Zhong Wu-Kui, Zhou Xu-Ke. An investigation into suspect's behavior of staging homicidal crime scenes. Forensic Science and Technology, 2015, 40 (6):474-476 [8] van den Eeden Claire A J, de Poot C J, van Koppen P J. Forensic expectations:investigating a crime scene with prior information. Science and Justice, 2016, 56 (6):475-481 doi: 10.1016/j.scijus.2016.08.003 [9] 王珏, 姚佳, 刘刚强.新形势下加强现场勘查工作的几点思考.辽宁警察学院学报, 2016, 18 (5):30-34 http://www.qikan.com.cn/article/qiwh20171037.htmlWang Jue, Yao Jia, Liu Gang-Qiang. Reflections on strengthening crime scenes investigation under the new situation. Journal of Liaoning Police College, 2016, 18 (5):30-34 http://www.qikan.com.cn/article/qiwh20171037.html [10] 王飞跃.人工社会, 计算实验, 平行系统-关于复杂社会经济系统计算研究的讨论.复杂系统与复杂性科学, 2004, 1(4):25-35 http://mall.cnki.net/magazine/Article/FZXT200404001.htmWang Fei-Yue. Artificial societies, computational experiments, and parallel systems:a discussion on computational theory of complex social-economic systems. Complex Systems and Complexity Science, 2004, 1 (4):25-35 http://mall.cnki.net/magazine/Article/FZXT200404001.htm [11] Wang F Y, Wong P K. Intelligent systems and technology for integrative and predictive medicine:an ACP approach. ACM Transactions on Intelligent Systems and Technology, 2013, 4 (2):Article No.32 [12] 王飞跃.软件定义的系统与知识自动化:从牛顿到默顿的平行升华.自动化学报, 2015, 41 (1):1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtmlWang Fei-Yue. Software-defined systems and knowledge automation:a parallel paradigm shift from Newton to Merton. Acta Automatica Sinica, 2015, 41 (1):1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtml [13] Wang F Y, Wang X, Li L X, Li L. Steps toward parallel intelligence. IEEE/CAA Journal of Automatica Sinica, 2016, 3 (4):345-348 doi: 10.1109/JAS.2016.7510067 [14] Wang F Y, Zhang J, Wei Q L, Zheng X H, Li L. PDP:parallel dynamic programming. IEEE/CAA Journal of Automatica Sinica, 2017, 4 (1):1-5 doi: 10.1109/JAS.2017.7510310 [15] 王飞跃.平行控制:数据驱动的计算控制方法.自动化学报, 2013, 39(4):293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtmlWang Fei-Yue. Parallel control:a method for data-driven and computational control. Acta Automatica Sinica, 2013, 39 (4):293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtml [16] 鲍媛媛. 人类行为动力学的实证及生成机制研究[博士学位论文], 北京邮电大学, 中国, 2012Bao Yuan-Yuan. Research on Empirical Study and Mechanisms of Human Dynamics[Ph. D. dissertation], Beijing University of Posts and Telecommunications, China, 2012 [17] Barabási A L. The origin of bursts and heavy tails in human dynamics. Nature, 2005, 435 (7039):207-211 doi: 10.1038/nature03459 [18] Zhou T, Kiet H A T, Kim B J, Wang B H, Holme P. Role of activity in human dynamics. Europhysics Letters, 2008, 82 (2):28002, DOI: 10.1209/0295-5075/82/28002 [19] 赵金楼, 成俊会, 刘家国.兴趣, 习惯, 交互三重驱动的微博用户动力学模型.哈尔滨工程大学学报, 2015, 36(9):1292-1296 https://www.cnki.com.cn/lunwen-1017167228.htmlZhao Jin-Lou, Cheng Jun-Hui, Liu Jia-Guo. Microblog users' dynamic model driven by interest, habit, and interaction. Journal of Harbin Engineering University, 2015, 36 (9):1292-1296 https://www.cnki.com.cn/lunwen-1017167228.html [20] Hong W, Han X P, Zhou T, Wang B H. Heavy-tailed statistics in short-message communication. Chinese Physics Letters, 2009, 26 (2):028902, DOI: 10.1088/0256-307X/26/2/028902 [21] Gabrielli A, Caldarelli G. Invasion percolation and critical transient in the Barabási model of human dynamics. Physical Review Letters, 2007, 98 (20):208701, DOI: 10.1103/PhysRevLett.98.208701 [22] Cesar A, Hidalgo R. Conditions for the emergence of scaling in the inter-event time of uncorrelated and seasonal systems. Physica A Statistical Mechanics and Its Applications, 2006, 369 (2):877-883 doi: 10.1016/j.physa.2005.12.035 [23] Dean Malmgren R, Stouffer D B, Motter A E, Amaral L A. A poissonian explanation for heavy tails in e-mail communication. Proceedings of the National Academy of Sciences of the United States of America, 2008, 105 (47):18153-18158 doi: 10.1073/pnas.0800332105 [24] 樊超, 郭进利, 韩筱璞, 汪秉宏.人类行为动力学研究综述.复杂系统与复杂性科学, 2011, 8 (2):1-17 http://www.docin.com/p-1276732280.htmlFan Chao, Guo Jin-Li, Han Xiao-Pu, Wang Bing-Hong. A review of research on human dynamics. Complex System and Complexity Science, 2011, 8 (2):1-17 http://www.docin.com/p-1276732280.html [25] Miritello G, Moro E, Lara R. Dynamical strength of social ties in information spreading. Physical Review E Statistical Nonlinear and Soft Matter Physics, 2011, 83 (4 Pt 2):045102, DOI: 10.1103/PhysRevE.83.045102 [26] Vázquez A, Oliveira J G, Dezsö Z, Goh K I, Kondor I, Barabási A L. Modeling bursts and heavy-tails in human dynamics. Physical Review E-Statistical, Nonlinear, and Soft Matter Physics, 2006, 73 (3):80-98 http://adsabs.harvard.edu/abs/2006PhRvE..73c6127V [27] González M C, Hidalgo C A, Barabási A L. Understanding individual human mobility patterns. Nature, 2008, 453 (7196):779-782 doi: 10.1038/nature06958 [28] Ramos-fernández G, Mateos J L, Miramontes O, Cocho G, Larralde H, Ayalaorozco B. Lévy walk patterns in the foraging movements of spider monkeys. Behavioral Ecology and Sociobiology, 2003, 55 (3):223-230 https://www.researchgate.net/publication/2168422_Levy_Walk_Patterns_in_the_Foraging_Movements_of_Spider_Monkeys_Ateles_geoffroyi [29] 李亚可.论犯罪现场勘查中的信息管理.湖南警察学院学报, 2015, 27(5):59-64Li Ya-Ke. The management of information in the crime scene investigation. Journal of Hunan Police Academy, 2015, 27 (5):59-64 [30] 赵阳, 傅晓海. 3S技术在现代刑事侦查工作中的应用.中国公共安全(学术版), 2016, (4):126-130 http://edu.wanfangdata.com.cn/Periodical/Detail/fzbl201613082Zhao Yang, Fu Xiao-Hai. Application of 3S technology in the work of criminal investigation. China Public Security (Academy Edition), 2016, (4):126-130 http://edu.wanfangdata.com.cn/Periodical/Detail/fzbl201613082 [31] Li Z, Liu J, Tang J, Lu H H. Robust structured subspace learning for data representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37 (10):2085-2098 doi: 10.1109/TPAMI.2015.2400461 [32] 白天翔, 王帅, 沈震, 曹东璞, 郑南宁, 王飞跃.平行机器人与平行无人系统:框架, 结构, 过程, 平台及其应用.自动化学报, 2017, 43 (2):161-175 http://www.aas.net.cn/CN/abstract/abstract17915.shtmlBai Tian-Xiang, Wang Shuai, Shen Zhen, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel robotics and parallel unmanned systems:framework, structure, process, platform and applications. Acta Automatica Sinica, 2017, 43 (2):161-175 http://www.aas.net.cn/CN/abstract/abstract17915.shtml [33] 戎静. 犯罪被害人的被害性分析-以被害人与犯罪人的相互作用为视角[硕士学位论文], 吉林大学, 中国, 2007Rong Jing. On Victimity of Victim-to Take Interaction of Criminal and Victim as Visual Angle[Master thesis], Jilin University, China, 2007 -

 下载:
下载:

计量
- 文章访问数: 2784
- HTML全文浏览量: 409
- PDF下载量: 711
- 被引次数: 0
