

-
摘要: 针对一类在有限时间区间上重复作业的不确定非线性系统,本文提出一种重复学习控制方法,用于解决非参数不确定性问题.该方法采用死区修正学习律对期望控制输入与界函数进行估计,以避免参数的正向累加导致系统发散,并使该控制算法较少地依赖于系统信息,更方便于控制器的实现.基于Lyapunov方法所设计的控制器,保证了闭环系统所有信号的有界性,并使得跟踪误差收敛于死区界定的邻域.通过仿真算例及电机实验结果验证所提学习控制算法的有效性.
-
关键词:
- 重复学习控制 /
- 非参数不确定性 /
- 死区修正 /
- Lyapunov方法
Abstract: This paper presents a repetitive learning control method to handle the nonparametric uncertain problem for a class of uncertain nonlinear systems performing a given repetitive task over a finite time interval. The learning laws with dead-zone modification are adopted to estimate the desired control input and bound functions, which avoids the divergency of estimates due to the ceaseless positive accumulation and facilitates the implementation of the controller with less knowledge about the system dynamics. The repetitive learning controller is designed in terms of Lyapunov synthesis, so as to guarantee the boundedness of all closed-loop signals while ensuring the tracking error to converge to the pre-specified neighbourhood. Numerical results for an inverted pendulum system and the AC motor experiment are conducted to testify the effectiveness of the proposed learning control scheme.1) 本文责任编委 王聪 -
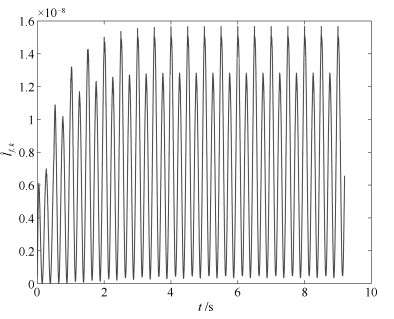
图 10 界函数估计$\hat l_{f, \, k}$
Fig. 10 Estimate of the bound function $\hat l_{f, \, k}$
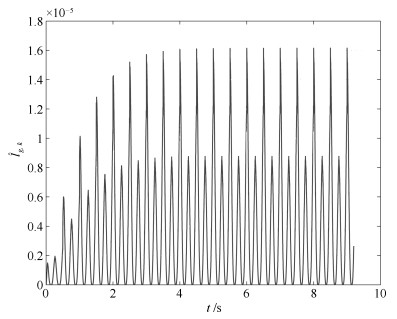
图 11 界函数估计$\hat l_{g, \, k}$
Fig. 11 Estimate of the bound function $\hat l_{g, \, k}$

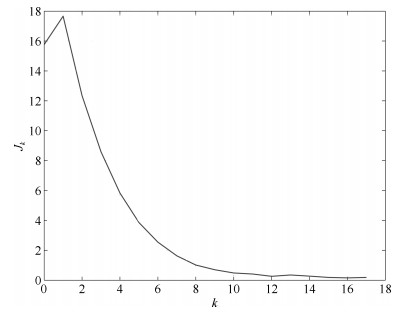
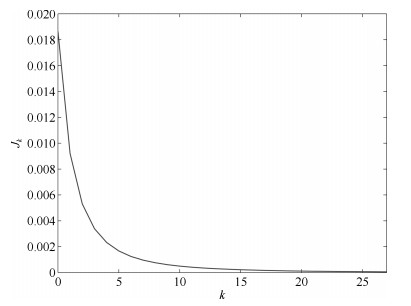
图 12 误差性能指标$J_k$ (其中三条虚线为控制器(31)的实验结果, 实线为控制器(11)的实验结果
Fig. 12 Error performance index $J_k$ (the three dotted lines are the result by controller (31), the solid line is the result by controller (11))
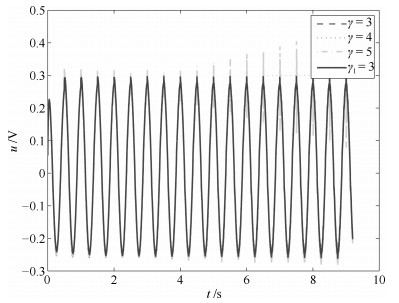
图 13 控制输入$u_k$ (其中三条虚线为控制器(31)的实验结果, 实线为控制器(11)的实验结果)
Fig. 13 Control input $u_k$ (the three dotted lines are the result by controller (31), the solid line is the result by controller (11))
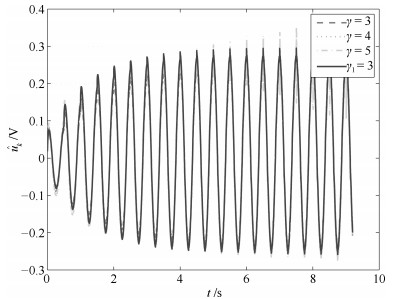
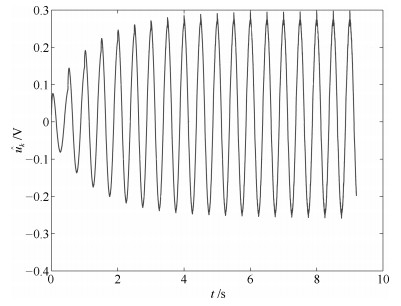
图 14 参考输入的估计$\hat u_k$ (其中三条虚线为控制器(31)的实验结果, 实线为控制器(11)的实验结果)
Fig. 14 Control input $\hat u_k$ (the three dotted lines are the result by controller (31), the solid line is the result by controller (11))
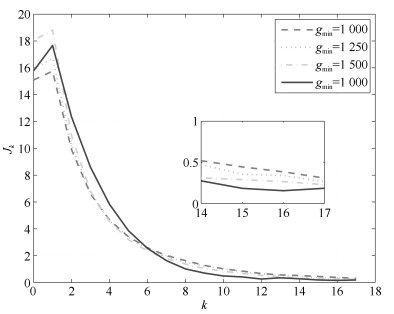
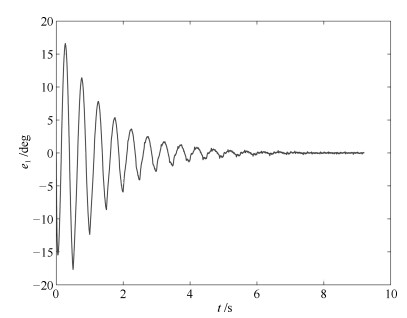
图 15 误差性能指标$J_k$ (其中三条虚线为控制器(31)的实验结果, 实线为控制器(11)的实验结果)
Fig. 15 Error performance index $J_k$ (the three dotted lines are the result by controller $ (31)$, the solid line is the result by controller $ (11)$)

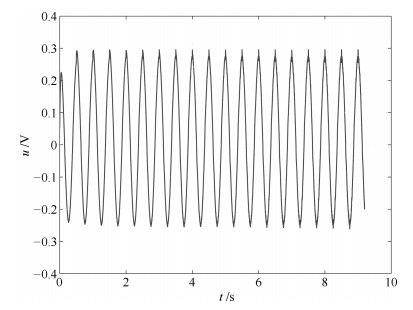
图 16 控制输入$u_k$ (其中三条虚线为控制器(31)的实验结果, 实线为控制器(11)的实验结果)
Fig. 16 Control input $u_k$ (the three dotted lines are the result by controller (31), the solid line is the result by controller (11))
-
[1] Arimoto S, Kawamura S, Miyazaki F. Bettering operation of robots by learning. Journal of Robotic Systems, 1984, 1(2):123-140 doi: 10.1002/(ISSN)1097-4563 [2] Mezghani M, Roux G, Cabassud M, Le Lann M V, Dahhou B, Casamatta G. Application of iterative learning control to an exothermic semibatch chemical reactor. IEEE Transactions on Control Systems Technology, 2002, 10(6):822-834 doi: 10.1109/TCST.2002.804117 [3] Tayebi A, Chien C J. A Unified adaptive iterative learning control framework for uncertain nonlinear systems. IEEE Transactions on Automatic Control, 2007, 52(10):1907-1913 doi: 10.1109/TAC.2007.906215 [4] Chien C J, Yao C Y. Iterative learning of model reference adaptive controller for uncertain nonlinear systems with only output measurement. Automatica, 2004, 40(5):855-864 doi: 10.1016/j.automatica.2003.12.009 [5] Xu J X. A survey on iterative learning control for nonlinear systems. International Journal of Control, 2011, 84(7):1275-1294 doi: 10.1080/00207179.2011.574236 [6] Norrlof M. An adaptive iterative learning control algorithm with experiments on an industrial robot. IEEE Transactions on Robotics and Automation, 2002, 18(2):245-251 doi: 10.1109/TRA.2002.999653 [7] Kuc T Y, Kwanghee N, Lee J S. An iterative learning control of robot manipulators. IEEE Transactions on Robotics and Automation, 1991, 7(6):835-842 doi: 10.1109/70.105392 [8] Choi J Y, Lee J S. Adaptive iterative learning control of uncertain robotic systems. IEEE Proceedings-Control Theory and Applications, 2000, 147(2):217-223 doi: 10.1049/ip-cta:20000138 [9] Sun M X, Ge S S, Mareels I M Y. Adaptive repetitive learning control of robotic manipulators without the requirement for initial repositioning. IEEE Transactions on Robotics, 2006, 22(3):563-568 doi: 10.1109/TRO.2006.870650 [10] French M, Rogers E. Non-linear iterative learning by an adaptive Lyapunov technique. International Journal of Control, 2000, 73(10):840-850 doi: 10.1080/002071700405824 [11] Tayebi A. Adaptive iterative learning control for robot manipulators. Automatica, 2004, 40(7):1195-1203 doi: 10.1016/j.automatica.2004.01.026 [12] Yin C K, Xu J X, Hou Z S. A high-order internal model based iterative learning control scheme for nonlinear systems with time-iteration-varying parameters. IEEE Transactions on Automatic Control, 2010, 55(11):2665-2670 doi: 10.1109/TAC.2010.2069372 [13] Sun M, Ge S S. Adaptive repetitive control for a class of nonlinearly parametrized systems. IEEE Transactions on Automatic Control, 2006, 51(10):1684-1688 doi: 10.1109/TAC.2006.883028 [14] Dong W J, Kuhnert K D. Robust adaptive control of nonholonomic mobile robot with parameter and nonparameter uncertainties. IEEE Transactions on Robotics, 2005, 21(2):261-266 doi: 10.1109/TRO.2004.837236 [15] Chen W S, Jiao L C. Adaptive tracking for periodically time-varying and nonlinearly parameterized systems using multilayer neural network. IEEE Transactions on Neural Networks, 2010, 21(2):345-351 doi: 10.1109/TNN.2009.2038999 [16] 庆吕庆.抑制初态误差影响的自适应迭代学习控制.自动化学报, 2015, 41(7):1365-1372 http://www.aas.net.cn/CN/abstract/abstract18710.shtmlLv Qing. Adaptive iterative learning control for inhibition effect of initial state random error. Acta Automatica Sinica, 2015, 41(7):1365-1372 http://www.aas.net.cn/CN/abstract/abstract18710.shtml [17] Li D, Li J M. Adaptive iterative learning control for nonlinearly parameterized systems with unknown time-varying delay and unknown control direction. International Journal of Automation and Computing, 2012, 9(6):578-586 doi: 10.1007/s11633-012-0682-9 [18] 陶洪峰, 霰学会, 杨慧中.输入饱和非线性系统的周期自适应补偿学习控制.自动化学报, 2014, 40(9):1998-2004 http://www.aas.net.cn/CN/abstract/abstract18471.shtmlTao Hong-Feng, Xian Xue-Hui, Yang Hui-Zhong. Periodic adaptive compensating learning control of nonlinear systems with saturated input. Acta Automatica Sinica, 2014, 40(9):1998-2004 http://www.aas.net.cn/CN/abstract/abstract18471.shtml [19] Zhang C L, Li J M. Adaptive iterative learning control of non-uniform trajectory tracking for strict feedback nonlinear time-varying systems. International Journal of Automation and Computing, 2014, 11(6):621-626 doi: 10.1007/s11633-014-0819-0 [20] Jin X, Huang D Q, Xu J X. Iterative learning control for systems with nonparametric uncertainties under alignment condition. In: Proceedings of the 51st Conference on Decision and Control (CDC). Maui, HI, USA: IEEE, 2012. 3942-3947 [21] Yu M, Huang D Q, He W. Robust adaptive iterative learning control for discrete-time nonlinear systems with both parametric and nonparametric uncertainties. International Journal of Adaptive Control and Signal Processing, 2016, 30(7):972-985 doi: 10.1002/acs.v30.7 [22] Zhang C L, Li J M. Adaptive iterative learning control for nonlinear pure-feedback systems with initial state error based on fuzzy approximation. Journal of the Franklin Institute, 2014, 351(3):1483-1500 doi: 10.1016/j.jfranklin.2013.11.018 [23] Xu J X, Jin X, Huang D Q. Composite energy function-based iterative learning control for systems with nonparametric uncertainties. International Journal of Adaptive Control and Signal Processing, 2014, 28(1):1-13 doi: 10.1002/acs.2380/full [24] Li X F, Huang D Q, Chu B, Xu J X. Robust iterative learning control for systems with norm-bounded uncertainties. International Journal of Robust and Nonlinear Control, 2016, 26(4):697-718 doi: 10.1002/rnc.v26.4 [25] Xu J X, Yan R. On initial conditions in iterative learning control. IEEE Transactions on Automatic Control, 2005, 50(9):1349-1354 doi: 10.1109/TAC.2005.854613 -

 下载:
下载:



计量
- 文章访问数: 2166
- HTML全文浏览量: 286
- PDF下载量: 750
- 被引次数: 0
