

An Adaptive Method for Moving Object Detection in Atmospheric Turbulence Environment
-
摘要: 在远距离成像过程中,图像序列受到湍流的影响会出现像素点亮度的随机起伏、闪烁和图像中物体的位置漂移,这使得传统的背景建模方法在湍流环境下难以准确检测运动目标.针对图像受到湍流影响在不同区域表现出的不同性质,提出分层次决策判别方法.首先,用高斯模型建模背景平坦区域,用双高斯模型建模背景中的物体边缘区域,设定判别式对每个像素点进行判别,并在线更新模型参数;然后,针对由于湍流影响出现的亮度突变点建立自适应判别模型,结合前一层次的判别结果,构造判别条件消除亮度突变点,分割得到目标点;最后,通过连通区域约束得到目标区域.实验结果表明,本文方法在不同湍流强度下对不同数量和不同运动方向的目标取得了良好的检测效果.Abstract: Image sequences acquired from remote distance remote distance are easily influenced by atmospheric turbulence, and subject to random changes of intensity, twinkle of pixels and shifts of object positions. Traditional background modeling methods are not able to detect the object of interest correctly in the turbulent environment. In this paper, a decision-making approach with multiple hierarchies is proposed to model the effect of atmospheric turbulence. Gaussian and double Gaussian distributions are utilized to model and distinguish the pixels in the flat and edge regions of the background, respectively. All parameters are updated online. Moreover, adaptive threshold is employed to discriminate between abrupt changing pixels and pixels in the object region by fusing the results of the first level. Finally, the region of the moving object is obtained by the connected component constraint. Comparison with other methods shows that the method performs well under different situations, such as different turbulence strength variations, different numbers of objects, and different moving directions.
-
近些年来, 由于多智能体协同控制在编队控制[1]、机器人网络[2]、群集行为[3]、移动传感器[4-5]等方面的广泛应用, 多智能体系统的协同控制问题受到了众多研究者的广泛关注.一致性问题是多智能体系统协同控制领域的一个关键问题, 其目的是通过与邻居之间的信息交换, 使所有智能体的状态达成一致.迄今为止, 对多智能体一致性的研究也已取得了丰硕的成果, 根据多智能体的动力学模型分类, 主要可以将其分为以下4种情形:一阶[6-9]、二阶[10-13]、三阶[14-15]、高阶[16-18].
在实际应用中, 由于CPU处理速度和内存容量的限制, 智能体不能频繁地进行控制以及与其邻居交换信息.因此, 事件触发控制策略作为减少控制次数和通信负载的有效途径, 受到了越来越多的关注.到目前为止, 对事件触发控制机制的研究也取得了很多成果[19-23].Xiao等[19]基于事件触发控制策略, 解决了带有领航者的离散多智能体系统的跟踪问题.通过利用状态测量误差并且基于二阶离散多智能体系统动力学模型, Zhu等[20]提出了一种自触发的控制策略, 该策略使得所有智能体的状态均达到一致. Huang等[21]研究了基于事件触发策略的Lur$'$e网络的跟踪问题.针对不同的领航者-跟随者系统, Xu等[22]提出了3种不同类型的事件触发控制器, 包含分簇式控制器、集中式控制器和分布式控制器, 以此来解决对应的一致性问题.然而, 大多数现有的事件触发一致性成果集中于考虑一阶多智能体系统和二阶多智能体系统, 很少有成果研究三阶多智能体系统的事件触发控制问题, 特别是对于三阶离散多智能体系统, 成果更是少之又少.所以, 设计相应的事件触发控制协议来解决三阶离散多智能体系统的一致性问题已变得尤为重要.
本文研究了基于事件触发控制机制的三阶离散多智能体系统的一致性问题, 文章主要有以下三点贡献:
1) 利用位置、速度和加速度三者的测量误差, 设计了一种新颖的事件触发控制机制.
2) 利用不等式技巧, 分析得到了保证智能体渐近收敛到一致状态的充分条件.与现有的事件触发文献[19-22]不同的是, 所得的一致性条件与通信拓扑的Laplacian矩阵特征值和系统的耦合强度有关.
3) 给出了排除类Zeno行为的参数条件, 进而使得事件触发控制器不会每个迭代时刻都更新.
1. 预备知识
1.1 代数图论
智能体间的通信拓扑结构用一个有向加权图来表示, 记为.其中, $\vartheta = \left\{ {1, 2, \cdots, n} \right\}$表示顶点集, $\varsigma\subseteq\vartheta\times\vartheta$表示边集, 称作邻接矩阵, ${a_{ij}}$表示边$\left({j, i} \right) \in \varsigma $的权值.当$\left({j, i} \right) \in \varsigma $时, 有${a_{ij}} > 0$; 否则, 有${a_{ij}} = 0$. ${a_{ij}} > 0$表示智能体$i$能收到来自智能体$j$的信息, 反之则不成立.对任意一条边$j$, 节点$j$称为父节点, 节点$i$则称为子节点, 节点$i$是节点$j$的邻居节点.假设通信拓扑中不存在自环, 即对任意$i\in \vartheta $, 有${a_{ii}} = 0$.
定义$L = \left({{l_{ij}}}\right)\in{\bf R}^{n\times n}$为图${\cal G}$的Laplacian矩阵, 其中元素满足${l_{ij}} = - {a_{ij}} \le 0, i \ne j$; ${l_{ii}} = \sum\nolimits_{j = 1, j \ne i}^n {{a_{ij}} \ge 0} $.智能体$i$的入度定义为${d_i} = \sum\nolimits_{j = 1}^n {{a_{ij}}} $, 因此可得到$L = D - \Delta $, 其中, .如果有向图中存在一个始于节点$i$, 止于节点$j$的形如的边序列, 那么称存在一条从$i$到$j$的有向路径.特别地, 如果图中存在一个根节点, 并且该节点到其他所有节点都有有向路径, 那么称此有向图存在一个有向生成树.另外, 如果有向图${\cal G}$存在一个有向生成树, 则Laplacian矩阵$L$有一个0特征值并且其他特征值均含有正实部.
1.2 模型描述
考虑多智能体系统由$n$个智能体组成, 其通信拓扑结构由有向加权图${\cal G}$表示, 其中每个智能体可看作图${\cal G}$中的一个节点, 每个智能体满足如下动力学方程:
$ \begin{equation} \left\{ \begin{array}{l} {x_i}\left( {k + 1} \right) = {x_i}\left( k \right) + {v_i}\left( k \right)\\ {v_i}\left( {k + 1} \right) = {v_i}\left( k \right) + {z_i}\left( k \right)\\ {z_i}\left( {k + 1} \right) = {z_i}\left( k \right) + {u_i}\left( k \right) \end{array} \right. \end{equation} $
(1) 其中, ${x_i}\left(k \right) \in \bf R$表示位置状态, ${v_i}\left(k \right) \in \bf R$表示速度状态, ${z_i}\left(k \right) \in \bf R$表示加速度状态, ${u_i}\left(k \right) \in \bf R$表示控制输入.
基于事件触发控制机制的控制器协议设计如下:
$ \begin{equation} {u_i}\left( k \right) = \lambda {b_i}\left( {k_p^i} \right) + \eta {c_i}\left( {k_p^i} \right) + \gamma {g_i}\left( {k_p^i} \right), k \in \left[ {k_p^i, k_{p + 1}^i} \right) \end{equation} $
(2) 其中, $\lambda> 0$, $\eta> 0$, $\gamma> 0$表示耦合强度,
$ \begin{align*}&{b_i}\left( k \right)= \sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{x_j}\left( k \right) - {x_i}\left( k \right)} \right)} , \nonumber\\ &{c_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{v_j}\left( k \right) - {v_i}\left( k \right)} \right)}, \nonumber\\ & {g_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{z_j}\left( k \right) - {z_i}\left( k \right)} \right)} .\end{align*} $
触发时刻序列定义为:
$ \begin{equation} k_{p + 1}^i = \inf \left\{ {k:k > k_p^i, {E_i}\left( k \right) > 0} \right\} \end{equation} $
(3) ${E_i}\left(k \right)$为触发函数, 具有以下形式:
$ \begin{align} {E_i}\left( k \right)= & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|- {\delta _2}{\beta ^k} - \nonumber\nonumber\\ &{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| \end{align} $
(4) 其中, ${\delta _1} > 0$, ${\delta _2} > 0$, $\beta > 0$, , ${e_{ci}}\left(k \right) = {c_i}\left({k_p^i} \right) - {c_i}\left(k \right)$, ${e_{gi}}\left(k \right) = {g_i}\left({k_p^i} \right) - {g_i}\left(k \right)$.
令$\varepsilon _i\left(k\right)={x_i}\left(k\right)-{x_1}\left(k\right)$, ${\varphi _i}\left(k\right)={v_i}\left(k \right)-$ ${v_1}\left(k\right)$, ${\phi _i}(k) = {z_i}(k) - {z_1}\left(k \right)$, $i = 2, \cdots, n$. , $\cdots, {\varphi _n}\left(k \right)]^{\rm T}$, $\phi \left(k \right) = {\left[{{\phi _2}\left(k \right), \cdots, {\phi _n}\left(k \right)} \right]^{\rm T}}$. $\psi \left(k \right) = {\left[{{\varepsilon ^{\rm T}}\left(k \right), {\varphi ^{\rm T}}\left(k \right), {\phi ^{\rm T}}\left(k \right)} \right]^{\rm T}}$, , ${\bar e_b} = {\left[{{e_{b1}}\left(k \right), \cdots, {e_{b1}}\left(k \right)} \right]^{\rm T}}$, , ${e_{c1}}\left(k \right)]^{\rm T}$, , ${\bar e_g} = $ ${\left[{{e_{g1}}\left(k \right), \cdots, {e_{g1}}\left(k \right)} \right]^{\rm T}}$, $\tilde e\left(k \right) = [\tilde e_b^{\rm T}\left(k \right), \tilde e_c^{\rm T}\left(k \right), $ $\tilde e_g^{\rm T}\left(k \right)]^{\rm T}$, $\bar e\left(k \right) = [\bar e_b^{\rm T}\left(k \right), \bar e_c^T\left(k \right), \bar e_g^{\rm T}\left(k \right)]^{\rm T}$,
$ \hat L = \left[ {\begin{array}{*{20}{c}} {{d_2} + {a_{12}}}&{{a_{13}} - {a_{23}}}& \cdots &{{a_{1n}} - {a_{2n}}}\\ {{a_{12}} - {a_{32}}}&{{d_3} + {a_{13}}}& \cdots &{{a_{1n}} - {a_{3n}}}\\ \vdots & \vdots & \ddots & \vdots \\ {{a_{12}} - {a_{n2}}}&{{a_{13}} - {a_{n3}}}& \cdots &{{d_n} + {a_{1n}}} \end{array}} \right] $
再结合式(1)和式(2)可得到:
$ \begin{equation} \psi \left( {k + 1} \right) = {Q_1}\psi \left( k \right) + {Q_2}\left( {\tilde e\left( k \right) - \bar e\left( k \right)} \right) \end{equation} $
(5) 其中, , .
定义1.对于三阶离散时间多智能体系统(1), 当且仅当所有智能体的位置变量、速度变量、加速度变量满足以下条件时, 称系统(1)能够达到一致.
$ \begin{align*} &{\lim _{k \to \infty }}\left\| {{x_j}\left( k \right) - {x_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{v_j}\left( k \right) - {v_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{z_j}\left( k \right) - {z_i}\left( k \right)} \right\| = 0 \\&\quad\qquad \forall i, j = 1, 2, \cdots , n \end{align*} $
定义2.如果$k_{p + 1}^i - k_p^i > 1$, 则称触发时刻序列$\left\{ {k_p^i} \right\}$不存在类Zeno行为.
假设1.假设有向图中存在一个有向生成树.
2. 一致性分析主要结果
假设$\kappa$是矩阵${Q_1}$的特征值, ${\mu _i}$是$L$的特征值, 则有如下等式成立:
$ {\rm{det}}\left( {\kappa {I_{3n - 3}} - {Q_1}} \right)=\nonumber\\ \det \left(\! \!{\begin{array}{*{20}{c}} {\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\!&\!{{0_{n - 1}}}\\ {{0_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\\ {\lambda {{\hat L}_{n - 1}}}\!&\!{\eta {{\hat L}_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}} + \gamma {{\hat L}_{n - 1}}} \end{array}} \!\!\right)=\nonumber\\ \prod\limits_{i = 2}^n {\left[ {{{\left( {\kappa - 1} \right)}^3} + \left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i}} \right]} $
令
$ \begin{align} {m_i}\left( \kappa \right)= &{\left( {\kappa - 1} \right)^3} + \nonumber\\&\left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i} = 0, \nonumber\\& \qquad\qquad\qquad\qquad\qquad i = 2, \cdots , n \end{align} $
(6) 则有如下引理:
引理1[15]. 如果矩阵$L$有一个0特征值且其他所有特征值均有正实部, 并且参数$\lambda $, $\eta $, $\gamma $满足下列条件:
$ \left\{ \begin{array}{l} 3\lambda - 2\eta < 0\\ \left( {\gamma - \eta + \lambda } \right)\left( {\lambda - \eta } \right) < - \dfrac{{\lambda \Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}}\\ \left( {4\gamma + \lambda - 2\eta } \right)<\dfrac{{8\Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}} \end{array} \right. $
那么, 方程(6)的所有根都在单位圆内, 这也就意味着矩阵${Q_1}$的谱半径小于1, 即$\rho \left({{Q_1}} \right) < 1$.其中, 表示特征值${\mu _i}$的实部.
引理2[23]. 如果, 那么存在$M \ge 1$和$0 < \alpha < 1$使得下式成立
$ {\left\| {{Q_1}} \right\|^k} \le M{\alpha ^k}, \quad k \ge 0 $
定理1. 对于三阶离散多智能体系统(1), 基于假设1, 如果式(2)中的耦合强度满足引理1中的条件, 触发函数(4)中的参数满足$0 < {\delta _1} < 1$, , $0 < \alpha < \beta < 1$, 则称系统(1)能够实现渐近一致.
证明.令$\omega \left(k \right) = \tilde e\left(k \right) - \bar e\left(k \right)$, 式(5)能够被重新写成如下形式:
$ \begin{equation} \psi \left( k \right) = Q_1^k\psi \left( 0 \right) + {Q_2}\sum\limits_{s = 0}^{k - 1} {Q_1^{k - 1 - s}\omega \left( s \right)} \end{equation} $
(7) 根据引理1和引理2可知, 存在$M \ge 1$和$0 < \alpha < 1$使得下式成立.
$ \begin{align} \left\| {\psi \left( k \right)} \right\|\le & {\left\| {{Q_1}} \right\|^k}\left\| {\psi \left( 0 \right)} \right\| + \nonumber\\ & \left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{{\left\| {{Q_1}} \right\|}^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|}\le \nonumber\\ & M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+\nonumber\\ & M\left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{\alpha ^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|} \end{align} $
(8) 由触发条件可得:
$ \begin{align} & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ & \qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^k}\le\nonumber\\ &\qquad {\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\| + {\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\| + \nonumber\\ &\qquad{\delta _1}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\|+ {\delta _1}\left| {{e_{bi}} \left( k \right)} \right| + \nonumber\\ &\qquad{\delta _1}\left| {{e_{ci}} \left( k \right)} \right|+ {\delta _1}\left| {{e_{gi}}\left( k \right)} \right| + {\delta _2}{\beta ^k} \end{align} $
(9) 对上式移项可求解得:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le \nonumber\\ &\qquad\frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\|}}{{1 - {\delta _1}}} + \frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\|}}{{1 - {\delta _1}}}{\rm{ + }}\nonumber\\ &\qquad\frac{{{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(10) 又因为, 和, 可得出下列不等式:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ &\qquad \frac{{{\delta _1}\left\| L \right\|}}{{1 - {\delta _1}}} \cdot \left( {\left\| {\varepsilon \left( k \right)} \right\|{\rm{ + }}\left\| {\varphi \left( k \right)} \right\|{\rm{ + }}\left\| {\phi \left( k \right)} \right\|} \right) +\nonumber\\ &\qquad \frac{{{\delta _2}{\beta ^k}}}{{1 - {\delta _1}}}\le \frac{{3{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(11) 接着有如下不等式成立:
$ \begin{align} \left\| {e\left( k \right)} \right\|\le \frac{{3\sqrt n {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{\sqrt n {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(12) 其中, , ${e_b}(k) = \left[{{e_{b1}}(k), \cdots, {e_{bn}}(k)} \right]$, ${e_c}(k) = \left[{{e_{c1}}(k), \cdots, {e_{cn}}(k)} \right]$,
注意到
$ \begin{equation} \left\| {\tilde e( k )} \right\| + \left\| {\bar e( k )} \right\| \le \sqrt {6( {n - 1} )} \left\| {e( k )} \right\| \end{equation} $
(13) 于是有
$ \begin{align} \left\| {\omega ( k )} \right\| &= \left\| {\tilde e( k ) - \bar e\left( k \right)} \right\| \le\nonumber\\ & \left\| {\tilde e\left( k \right)} \right\| + \left\| {\bar e\left( k \right)} \right\|\le\nonumber\\ & \frac{{3\sqrt {6n( {n - 1} )} {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| +\nonumber\\ & \frac{{\sqrt {6n( {n - 1} )} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(14) 把式(14)代入式(8)可得
$ \begin{align} \left\| {\psi \left( k \right)} \right\| &\le M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+ \nonumber\\ &\frac{{M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}} {\delta _1}3\sqrt {6n\left( {n - 1} \right)} \left\| L \right\|}}{{1 - {\delta _1}}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}}\left\| {\psi \left( s \right)} \right\|} + M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}} \frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}} {{1 - {\delta _1}}}{\beta ^s}} \end{align} $
(15) 接下来的部分, 将证明下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| \le W{\beta ^k}.\end{equation} $
(16) 其中, $W = \max \left\{ {{\Theta _1}, {\Theta _2}} \right\}$,
首先, 证明对任意的$\rho > 1$, 下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| < \rho W{\beta ^k} \end{equation} $
(17) 利用反证法, 先假设式(17)不成立, 则必将存在${k^ * } > 0$使得并且当$k \in \left({0, {k^ * }} \right)$时$\left\| {\psi \left(k \right)} \right\| < \rho W{\beta ^k}$成立.因此, 根据式(17)可得:
$ \begin{align*} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le\\ &\qquad M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} +\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}M\times \end{align*} $
$ \begin{align*} &\qquad\sum\limits_{s = 0}^{{k^ * } - 1} {\alpha ^{ - s}}\left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot \left\| {\psi \left( s \right)} \right\|}}{{1 - {\delta _1}}}} \right]+ \\ &\qquad M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^s}} \right]} < \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} + \rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}\times\\ &\qquad \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot W{\beta ^s}}} {{1 - {\delta _1}}}} \right]} +\\ &\qquad\rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}{\beta ^s}}}{{1 - {\delta _1}}}} \right]=} \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}}- \nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\alpha ^{{k^ * }}}+\nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\beta ^{{k^ * }}} \end{align*} $
1) 当$W = M\left\| {\psi \left(0 \right)} \right\|$时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\| - \nonumber\\ &\qquad \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} \ge 0 \end{aligned} \end{equation*} $
所以可得到
$ \begin{equation} \rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le \rho M\left\| {\psi \left( 0 \right)} \right\|{\beta ^{{k^ * }}}=\rho W{\beta ^{{k^ * }}} \end{equation} $
(18) 2) 当时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\|- \nonumber\\ &\qquad\frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} < 0 \end{aligned} \end{equation*} $
所以有
$ \begin{align} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\|\le\nonumber\\ & \frac{{\rho {\delta _2}M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} {\beta ^{{k^ * }}}}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right) - 3{\delta _1}M\left\| {{Q_2}} \right\|\left\| L \right\|\sqrt {6n\left( {n - 1} \right)} }}=\nonumber\\ &\rho W{\beta ^{{k^ * }}} \end{align} $
(19) 根据以上结果, 式(18)和式(19)都与假设相矛盾.这说明原命题成立, 即对任意的$\rho > 1$, 式(17)成立.易知, 如果$\rho \to 1$, 则式(16)成立.根据式(16)可知, 当$k \to + \infty $时, 有, 则系统(5)是收敛的.由$\psi \left(k \right)$的定义可知, 系统(1)能够实现渐近一致.
定理2. 对于系统(1), 如果定理1中的条件成立, 并且控制器(2)中的设计参数满足如下条件,
$ {\delta _1} \in \left( {\frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}}, 1} \right)\\ {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } $
那么触发序列中的类Zeno行为将被排除.
证明. 易知排除类Zeno行为的关键是要证明不等式$k_{p + 1}^i - k_p^i > 1$成立.根据事件触发机制可知, 下一个触发时刻将会发生在触发函数(4)大于0时.进而可得到如下不等式
$ \begin{align} &\left| {{e_{bi}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{ci}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{gi}}\left( {k_{p + 1}^i} \right)} \right|\ge\nonumber\\ &\qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{align} $
(20) 定义, .结合式(20), 可得到下式
$ \begin{equation} {G_i}\left( {k_{p + 1}^i} \right) \ge {\delta _1}{H_i}\left( {k_p^i} \right) + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{equation} $
(21) 结合式(16)和式(21)可得
$ \begin{align} {\delta _2}{\beta ^{k_{p + 1}^i}} &\le {G_i}\left( {k_{p + 1}^i} \right) - {\delta _1}{H_i}\left( {k_p^i} \right)\le\nonumber\\ & \left\| L \right\|\left( {\left\| {\psi \left( {k_p^i} \right)} \right\| + \left\| {\psi \left( {k_{p + 1}^i} \right)} \right\|} \right)\le\nonumber\\ & W\left\| L \right\|\left( {{\beta ^{k_p^i}} + {\beta ^{k_{p + 1}^i}}} \right) \end{align} $
(22) 求解上式得
$ \begin{equation} \left( {{\delta _2} - \left\| L \right\|W} \right){\beta ^{k_{p + 1}^i}} \le \left\| L \right\|W{\beta ^{k_p^i}} \end{equation} $
(23) 根据式(23)可得
$ \begin{equation} k_{p + 1}^i - k_p^i > \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}} } {\ln \beta } \end{equation} $
(24) 基于(24)易知当时, 有如下不等式成立
$ \begin{equation} \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}}} {\ln \beta } > 1 \end{equation} $
(25) 此外, 因为$W = M\left\| {\psi \left(0 \right)} \right\|$以及
$ \begin{equation} {\delta _1} > \frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}} \end{equation} $
(26) 又可以得出
$ \begin{equation} {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } = \frac{{\left\| L \right\|W\left( {1 + \beta } \right)}}{\beta } \end{equation} $
(27) 该式意味着式(25)成立, 又结合式(24)易知$k_{p + 1}^i - k_p^i > 1$, 即排除类Zeno行为的条件得已满足.
注2.类Zeno行为广泛存在于基于事件触发控制机制的离散系统中.然而, 当前极少有文献研究如何排除类Zeno行为, 尤其是对于三阶多智能体动态模型.定理2给出了排除三阶离散多智能体系统的类Zeno行为的参数条件.
3. 仿真实验
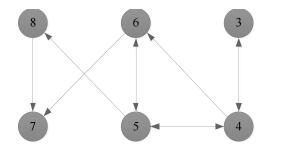
本部分将利用一个仿真实验来验证本文所提算法及理论的正确性和有效性.假设三阶离散多智能体系统(1)包含6个智能体, 且有向加权通信拓扑结构如图 1所示, 权重取值为0或1, 可以明显地看出该图包含有向生成树(满足假设1).
通过简单的计算可得, ${\mu _1} = 0$, ${\mu _2} = 0.6852$, ${\mu _3} = 1.5825 + 0.3865$i, ${\mu _4} = 1.5825 - 0.3865$i, ${\mu _5} = 3.2138$, ${\mu _6} = 3.9360$.令$M = 1$, 结合定理1和定理2可得到$0.035 < {\delta _1} < 1$, ${\delta _2} > 44.0025$, $0 < \alpha < \beta < 1$.令${\delta _1} = 0.2$, ${\delta _2} = 200$, $\alpha = 0.6$, $\beta = 0.9$, $\lambda = 0.02$, $\eta = 0.3$, $\gamma = 0.5$, 不难验证满足引理1的条件并且计算可知$\rho \left({{Q_1}} \right) = 0.9958 < 1$.三阶离散多智能体系统(1)的一致性结果如图 2~图 6所示.根据定理1可知, 基于控制器(2)和事件触发函数(4)的系统(1)能实现一致.从图 2~图 6可以看出, 仿真结果与理论分析符合.
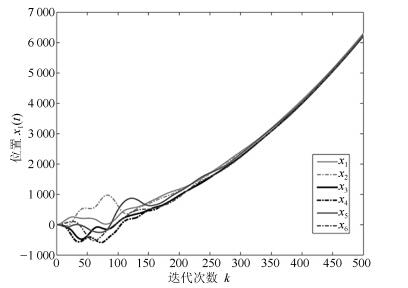 图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems
图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems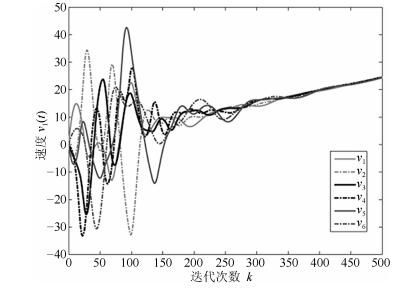 图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems
图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems 图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems
图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems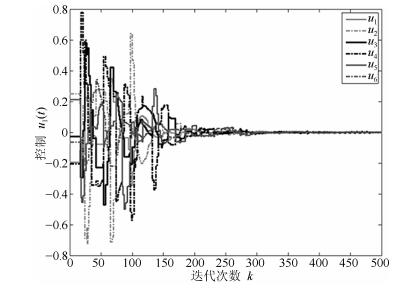 图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems
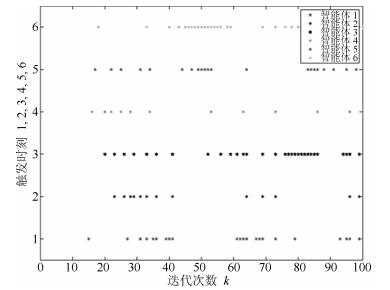
图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems图 2~图 4分别表征了系统(1)中所有智能体的位置、速度和加速度的轨迹, 从图中可以看出以上3个变量确实达到了一致.图 5展示了控制输入的轨迹.为了更清楚地体现事件触发机制的优点, 图 6给出了0$ \sim $100次迭代内的各智能体的触发时刻轨迹.从图 6可以看出, 本文设计的事件触发协议确实达到了减少更新次数, 节省资源的目的.
4. 结论
针对三阶离散多智能体系统的一致性问题, 构造了一个新颖的事件触发一致性协议, 分析得到了在通信拓扑为有向加权图且包含生成树的条件下, 系统中所有智能体的位置状态、速度状态和加速度状态渐近收敛到一致状态的充分条件.同时, 该条件指出了通信拓扑的Laplacian矩阵特征值和系统的耦合强度对系统一致性的影响.另外, 给出了排除类Zeno行为的参数条件.仿真实验结果也验证了上述结论的正确性.将文中获得的结论扩展到拓扑结构随时间变化的更高阶多智能体网络是极有意义的.这将是未来研究的一个具有挑战性的课题.
-
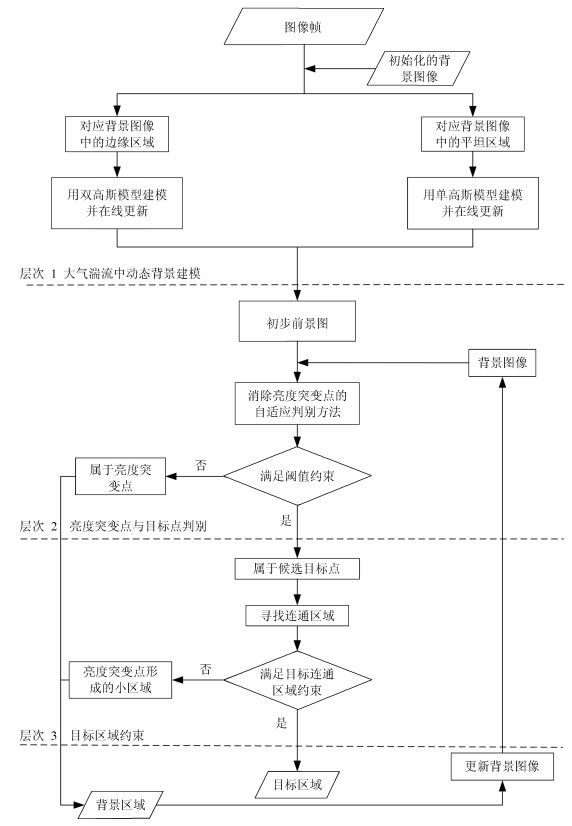
图 1 大气湍流中分层次运动目标检测框架
Fig. 1 Hierarchical framework of moving object detection in atmospheric turbulence environment
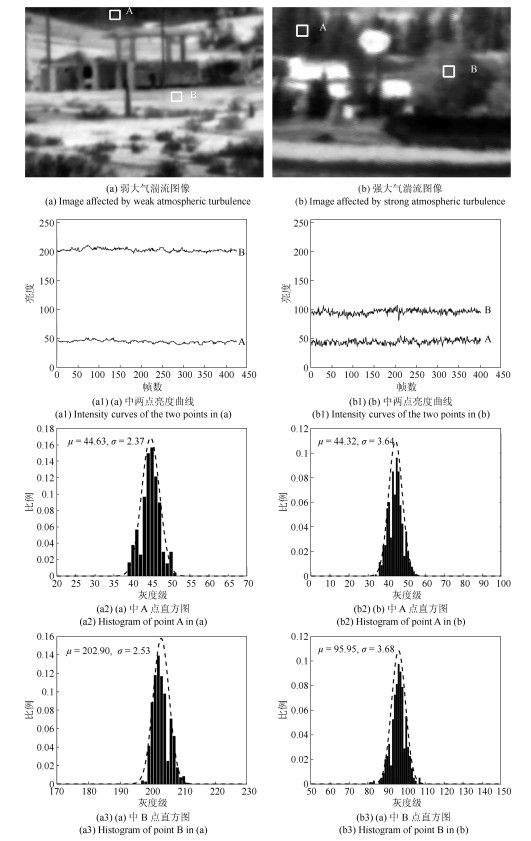
图 2 不同大气湍流强度的图像序列中不同像素点随时间变化的亮度变化曲线图和分布直方图
Fig. 2 The intensity curves and histograms of points in image sequences affected by atmospheric turbulence with different strength
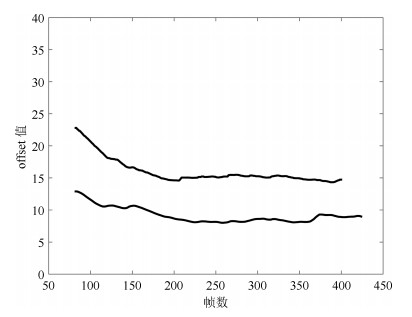
图 4 两个不同大气湍流强度的图像序列得到的$Offset$变化曲线
Fig. 4 The curves of $Offset$ values in two image sequences affected by atmospheric turbulence with different strength
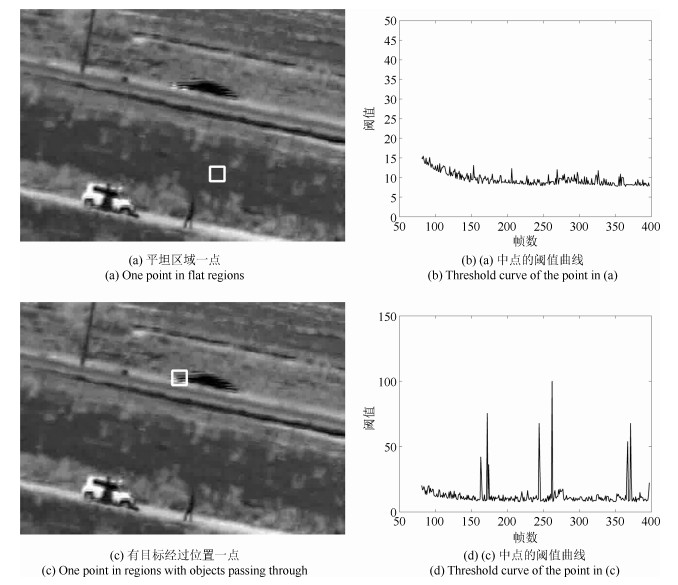
图 5 平坦区域一点和有目标经过位置一点的阈值随时间的变化
Fig. 5 The threshold curves of two points in flat regions and regions with objects passing through
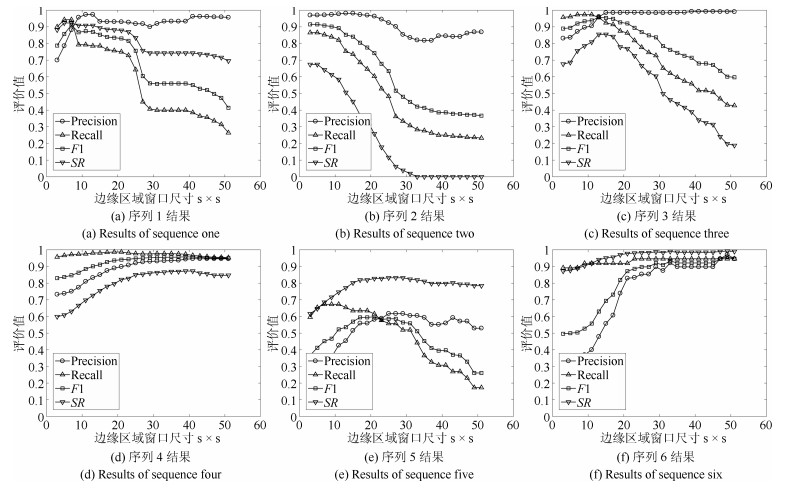
图 6 各个评价值随边缘区域窗口尺寸变化的曲线
Fig. 6 The curves of criteria varying over window sizes of the edge region

图 7 各个评价值随式(10)中比例因子$\lambda$变化的曲线
Fig. 7 The curves of criteria varying over $\lambda$
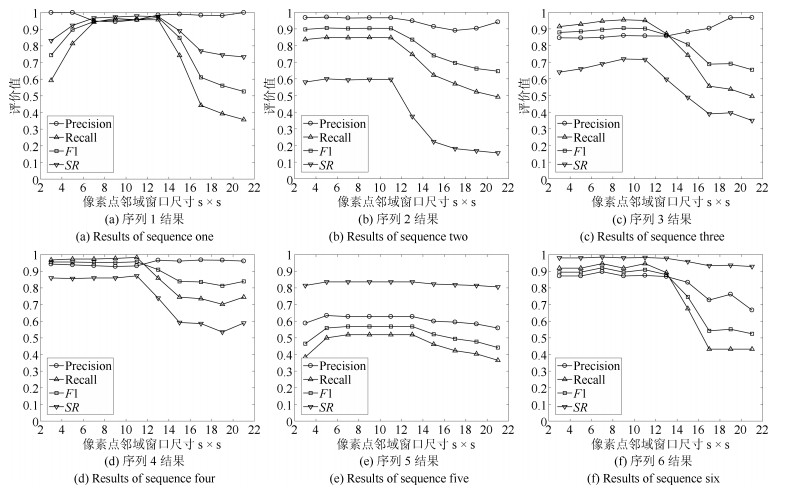
图 8 各个评价值随像素点邻域窗口尺寸变化的曲线
Fig. 8 The curves of criteria varying over window sizes of the neighborhood
序号 分辨率 帧频(Hz) 帧数 大气湍流强弱/信噪比(dB) 图像序列描述 序列1 $720 \times 576$ 30 425 弱/26.70 有一个向右缓慢移动的目标, 目标较小, 速度较慢. 序列2 $672 \times 480$ 30 397 弱/25.59 有多个左右缓慢移动的目标和多个左右快速移动的目标. 序列3 $672 \times 480$ 30 390 弱/28.08 有多个左右缓慢移动的目标和一个向左快速移动的目标. 序列4 $672 \times 480$ 30 401 强/19.59 有多个向右快速移动的目标. 序列5 $672 \times 480$ 30 400 强/15.31 只有少部分图像帧存在向右快速移动的目标. 序列6 $672 \times 480$ 30 493 强/16.66 只有第120帧前有向右快速移动的目标.  下载: 导出CSV
下载: 导出CSV
表 2 序列1中背景模型更新与否得到的评价值对比
Table 2 Comparison between updating models and not updating models for sequence one
Precision Recall $F1$ $SR$ 更新模型 0.89 0.95 0.92 0.97 不更新模型 0.47 0.95 0.63 0.73
下载: 导出CSV
表 3 各方法在6个图像序列中检测目标得到的Precision/Recall值比较
Table 3 Precision and Recall results of different methods
方法 序列1 序列2 序列3 序列4 序列5 序列6 本文方法 0.89/0.95 0.97/0.85 0.87/0.97 0.92/0.98 0.62/0.56 0.83/0.95 Chen等[19] 0.93/0.36 0.90/0.50 0.98/0.20 0.95/0.63 0.77/0.38 0.87/0.89 Oreifej等[17] 0.56/0.60 0.85/0.57 0.92/0.80 0.20/0.52 0.00/0.00 0.00/0.00 Stauffer等[3] 0.00/0.00 0.90/0.46 0.96/0.48 0.25/0.68 0.06/0.81 0.03/0.59 Barnich等[8] (阈值40) 0.19/0.48 0.71/0.86 0.63/0.67 0.19/0.83 0.02/0.44 0.02/0.73 Barnic等[8] (阈值80) 0.00/0.00 0.81/0.47 1.00/0.03 0.53/0.82 0.03/0.58 0.06/0.76 Noh等[13] 0.00/0.00 0.98/0.67 1.00/0.19 0.67/0.56 0.00/0.02 0.21/0.73 St-Charles等[14] (SuBSENSE) 0.76/0.93 0.90/0.90 0.96/0.64 0.35/0.75 0.05/0.63 0.04/0.84 St-Charles等[15] (PAWCS) 0.40/0.99 0.86/0.87 0.85/0.97 0.18/0.69 0.02/0.40 0.02/0.70
下载: 导出CSV
表 4 各方法在6个图像序列中检测目标得到的$F1$值比较
Table 4 The $F1$ results of different methods
方法 序列1 序列2 序列3 序列4 序列5 序列6 本文方法 0.92 0.91 0.92 0.95 0.59 0.89 Chen等[19] 0.52 0.64 0.33 0.76 0.51 0.88 Oreifej等[17] 0.58 0.68 0.86 0.29 0.00 0.00 Stauffer等[3] 0.00 0.61 0.64 0.36 0.12 0.05 Barnich等[8] (阈值40) 0.28 0.78 0.65 0.31 0.03 0.04 Barnich等[8] (阈值80) 0.00 0.59 0.05 0.65 0.06 0.11 Noh等[13] 0.00 0.80 0.32 0.61 0.01 0.32 St-Charles等[14] (SuBSENSE) 0.84 0.90 0.77 0.47 0.09 0.08 St-Charles等[15] (PAWCS) 0.57 0.86 0.91 0.29 0.03 0.04
下载: 导出CSV
表 5 各方法在6个图像序列中检测目标得到的$SR$值比较
Table 5 The $SR$ results of different methods
方法 序列1 序列2 序列3 序列4 序列5 序列6 本文方法 0.97 0.64 0.76 0.85 0.84 0.98 Chen等[19] 0.72 0.18 0.06 0.43 0.84 0.99 Oreifej等[17] 0.78 0.22 0.64 0.01 0.04 0.00 Stauffer等[3] 0.55 0.15 0.33 0.05 0.14 0.27 Barnich等[8] (阈值40) 0.75 0.41 0.24 0.00 0.00 0.00 Barnich等[8] (阈值80) 0.59 0.08 0.02 0.12 0.00 0.05 Noh等[13] 0.59 0.20 0.12 0.27 0.50 0.83 St-Charles等[14] (SuBSENSE) 0.93 0.72 0.50 0.16 0.19 0.24 St-Charles等[15] (PAWCS) 0.76 0.63 0.74 0.02 0.00 0.18
下载: 导出CSV
-
[1] Brutzer S, Höferlin B, Heidemann G. Evaluation of background subtraction techniques for video surveillance. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA: IEEE, 2011. 1937-1944 doi: 10.1109/CVPR.2011.5995508 [2] Wren C R, Azarbayejani A, Darrell T, Pentland A P. Pfinder:real-time tracking of the human body. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19 (7):780-785 doi: 10.1109/34.598236 [3] Stauffer C, Grimson W E L. Adaptive background mixture models for real-time tracking. In: Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins, USA: IEEE, 1999, 2: 246-252 http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=784637 [4] Haritaoglu I, Harwood D, Davis L S. W4:Real-time surveillance of people and their activities. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22 (8):809-830 doi: 10.1109/34.868683 [5] Kim K, Chalidabhongse T H, Harwood D, Davis L. Real-time foreground-background segmentation using codebook model. Real-Time Imaging, 2005, 11 (3):172-185 doi: 10.1016/j.rti.2004.12.004 [6] Elgammal A, Harwood D, Davis L. Non-parametric model for background subtraction. In: Proceedings of the 2000 European Conference on Computer Vision. Dublin, Ireland: Springer-Verlag, 2000. 751-767 doi: 10.1007/3-540-45053-X_48 [7] Sheikh Y, Shah M. Bayesian modeling of dynamic scenes for object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27 (11):1778-1792 doi: 10.1109/TPAMI.2005.213 [8] Barnich O, Van Droogenbroeck M. ViBe:a universal background subtraction algorithm for video sequences. IEEE Transactions on Image Processing, 2011, 20 (6):1709-1724 doi: 10.1109/TIP.2010.2101613 [9] Oliver N M, Rosario B, Pentland A P. A Bayesian computer vision system for modeling human interactions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22 (8):831-843 doi: 10.1109/34.868684 [10] Heikkilä M, Pietikäinen M. A texture-based method for modeling the background and detecting moving objects. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28 (4):657-662 doi: 10.1109/TPAMI.2006.68 [11] Javed O, Shafique K, Shah M. A hierarchical approach to robust background subtraction using color and gradient information. In: Proceedings of the 2002 Workshop on Motion and Video Computing. Orlando, USA: IEEE, 2002. 22-27 http://doi.ieeecomputersociety.org/resolve?ref_id=doi:10.1109/MOTION.2002.1182209&rfr_id=trans/tp/2003/10/ttp2003101355.htm [12] Mason M, Duric Z. Using histograms to detect and track objects in color video. In: Proceedings of the 30th Applied Imagery Pattern Recognition Workshop. Washington, USA: IEEE, 2001. 154-159 doi: 10.1109/AIPR.2001.991219 [13] Noh S J, Jeon M. A new framework for background subtraction using multiple cues. In: Proceedings of the 2012 Asian Conference on Computer Vision. Daejeon, Korea: Springer-Verlag, 2012. 493-506 http://www.mendeley.com/research/new-framework-background-subtraction-using-multiple-cues-2/ [14] St-Charles P L, Bilodeau G A, Bergevin R. SuBSENSE:a universal change detection method with local adaptive sensitivity. IEEE Transactions on Image Processing, 2015, 24 (1):359-373 doi: 10.1109/TIP.2014.2378053 [15] St-Charles P L, Bilodeau G A, Bergevin R. Universal background subtraction using word consensus models. IEEE Transactions on Image Processing, 2016, 25 (10):4768-4781 doi: 10.1109/TIP.2016.2598691 [16] Li D L, Mersereau R M, Simske S. Atmospheric turbulence-degraded image restoration using principal components analysis. IEEE Geoscience and Remote Sensing Letters, 2007, 4 (3):340-344 doi: 10.1109/LGRS.2007.895691 [17] Oreifej O, Li X, Shah M. Simultaneous video stabilization and moving object detection in turbulence. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (2):450-462 doi: 10.1109/TPAMI.2012.97 [18] Zhu X, Milanfar P. Image reconstruction from videos distorted by atmospheric turbulence. In: Proceedings of SPIE 7543, Visual Information Processing and Communication. San Jose, USA: SPIE, 2010. Article No.75430S http://www.mendeley.com/research/image-reconstruction-videos-distorted-atmospheric-turbulence/ [19] Chen E L, Haik O, Yitzhaky Y. Detecting and tracking moving objects in long-distance imaging through turbulent medium. Applied Optics, 2014, 53 (6):1181-1190 doi: 10.1364/AO.53.001181 [20] Elkabetz A, Yitzhaky Y. Background modeling for moving object detection in long-distance imaging through turbulent medium. Applied Optics, 2014, 53 (6):1132-1141 doi: 10.1364/AO.53.001132 [21] 齐玉娟, 王延江, 李永平.基于记忆的混合高斯背景建模.自动化学报, 2010, 36 (11):1520-1526 http://www.aas.net.cn/CN/abstract/abstract17339.shtmlQi Yu-Juan, Wang Yan-Jiang, Li Yong-Ping. Memory-based Gaussian mixture background modeling. Acta Automatica Sinica, 2010, 36 (11):1520-1526 http://www.aas.net.cn/CN/abstract/abstract17339.shtml [22] 王永忠, 梁彦, 潘泉, 程咏梅, 赵春晖.基于自适应混合高斯模型的时空背景建模.自动化学报, 2009, 35 (4):371-378 http://www.aas.net.cn/CN/abstract/abstract15852.shtmlWang Yong-Zhong, Liang Yan, Pan Quan, Cheng Yong-Mei, Zhao Chun-Hui. Spatiotemporal background modeling based on adaptive mixture of Gaussians. Acta Automatica Sinica, 2009, 35 (4):371-378 http://www.aas.net.cn/CN/abstract/abstract15852.shtml [23] Bouwmans T, Baf F E, Vachon B. Background modeling using mixture of Gaussians for foreground detection:a survey. Recent Patents on Computer Science, 2008, 1 (3):219-237 doi: 10.2174/2213275910801030219 [24] Bouwmans T. Traditional and recent approaches in background modeling for foreground detection:an overview. Computer Science Review, 2014, 11-12:31-66 doi: 10.1016/j.cosrev.2014.04.001 [25] Zhu X, Milanfar P. Removing atmospheric turbulence via space-Invariant deconvolution. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (1):157-170 doi: 10.1109/TPAMI.2012.82 [26] Çaliskan T, Arica N. Atmospheric turbulence mitigation using optical flow. In: Proceedings of the 2nd International Conference on Pattern Recognition (ICPR). Stockholm, Sweden: IEEE, 2014. 883-888 http://mobile.computer.org/csdl/proceedings/icpr/2014/5209/00/5209a883-abs.html [27] Arica N, Caliskan T. Moving object detection in turbulence degraded video. International Journal of Applied Mathematics, Electronics and Computers, 2015, 3 (4):232-236 doi: 10.18100/ijamec.97614 [28] Deshmukh A S, Medasani S S, Reddy G R. Moving object detection from images distorted by atmospheric turbulence. In: Proceedings of the 2013 International Conference on Intelligent Systems and Signal Processing (ISSP). Gujarat, India: IEEE, 2013. 122-127 http://www.mendeley.com/research/moving-object-detection-images-distorted-atmospheric-turbulence/ [29] Ganzalez R C, Woods R E[著], 阮秋琦, 阮宇智[译].数字图像处理第.第3版.北京: 电子工业出版社, 2011.Ganzalez R C, Woods R E[Author], Ruan Qiu-Qi, Ruan Yu-Zhi[Translator]. Digital Image Processing (Third edition). Beijing: Publishing House of Electronics Industry, 2011. [30] Zamek S, Yitzhaky Y. Turbulence strength estimation from an arbitrary set of atmospherically degraded images. Journal of the Optical Society of America A, 2006, 23 (12):3106-3113 doi: 10.1364/JOSAA.23.003106 期刊类型引用(3)
1. 岳振宇,范大昭,董杨,纪松,李东子. 一种星载平台轻量化快速影像匹配方法. 地球信息科学学报. 2022(05): 925-939 .  百度学术
百度学术2. 王若兰,潘万彬,曹伟娟. 图像局部区域匹配驱动的导航式拼图方法. 计算机辅助设计与图形学学报. 2020(03): 452-461 . 百度学术3. 胡敬双,聂洪玉. 灰度序模式的局部特征描述算法. 中国图象图形学报. 2017(06): 824-832 . 百度学术其他类型引用(9)
-

 下载:
下载:

计量
- 文章访问数: 1838
- HTML全文浏览量: 236
- PDF下载量: 589
- 被引次数: 12
