

-
摘要: 在计算机视觉和模式识别领域,随着多源信息越来越多,图像的描述方法也越来越丰富,多视图学习方法能更充分利用这种多源信息,进而提高聚类的准确率.因此,本文提出了两种基于多视图学习的方法:MultiGNMF和MultiGSemiNMF方法.该方法是在矩阵分解的基础之上,结合以往多视图学习的框架准则,并利用了样本的局部结构形成的.MultiGNMF和MultiGSemiNMF算法不仅能学习视图间的互补信息,同时能保持样本的空间结构.但是,MultiGNMF算法只适用于非负的特征矩阵.因此,考虑到SemiNMF算法相对于NMF算法具有更大的扩展性,结合多视图学习的框架,本文又提出了多视图学习的MultiGSemiNMF算法.实验结果证实了这两种方法有较好的性能.Abstract: In computer vision and pattern recognition fields, more and more data are represented by multiple views which describe different perspectives of the data. And multi-view learning methods are developed for ultilizing the information sufficiently. In this paper, we propose two novel clustering methods called MultiGNMF and MultiGSemiNMF, respectively, which are based on multiview learning with local graph regularization, where the innerview relatedness between data is taken into consideration. However, MultiGNMF is based on NMF, which only applies to non-negative matrix. To eliminate this limit, we propose MultiGSemiNMF based on SemiNMF, which is also applicable for negative matrix. The experimental results demonstrate the effectiveness of our proposed methods.
-
Key words:
- Multi-view learning /
- clustering /
- matrix factorization /
- local graph regularization
1) 本文责任编委 王立威 -
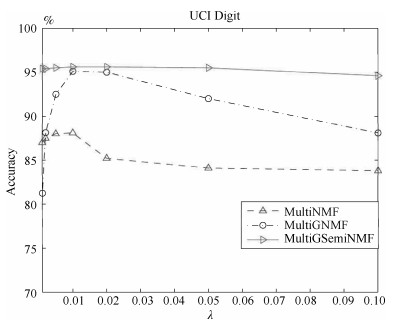
图 1 在UCI Digit数据库中参数$\lambda$对本文算法的影响
Fig. 1 The influences of $\lambda$ on UCI Digit database

图 2 在CMU PIE数据库中参数$\lambda$对本文算法的影响
Fig. 2 The influences of $\lambda$ on CMU PIE database
表 1 4个数据库的资料
Table 1 The information of four databases
数据库 数量 视图个数 聚类个数 CMU PIE 2 856 2 68 UCI Digit 2 000 2 10 3-Sources 169 3 6 ORL 400 2 40  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在4个数据库中的AC值
Table 2 The AC values by different methods in four databases
算法 UCI Digit CMU PIE 3-Sources ORL BSV ${68.5\pm.05}$ ${55.2\pm.02}$ ${60.8\pm.01}$ ${51.8\pm.02}$ WSV ${63.4\pm.04}$ ${47.6\pm.01}$ ${49.1\pm.03}$ ${42.8\pm.05}$ ConcatNMF ${67.8\pm.06}$ ${51.5\pm.00}$ ${58.6\pm.03}$ ${66.8\pm.02}$ ColNMF ${66.0\pm.05}$ ${56.3\pm.00}$ ${61.3\pm.02}$ ${66.3\pm.04}$ Co-reguSC ${86.6\pm.00}$ ${59.5\pm.02}$ ${47.8\pm.01}$ ${70.5\pm.02}$ MultiNMF ${88.1\pm.01}$ ${64.8\pm.02}$ ${68.4\pm.06}$ ${67.3\pm.03}$ SC-ML ${88.1\pm.00}$ ${72.3\pm.00}$ ${54.0\pm.00}$ ${70.8\pm.00}$ MMSC ${89.4\pm.38}$ ${61.6\pm.06}$ ${69.9\pm.04}$ ${70.7\pm.06}$ AMGL ${82.6\pm.74}$ ${63.6\pm.19}$ ${68.3\pm.12}$ ${64.2\pm.10}$ MultiGNMF ${95.1\pm.10}$ ${72.5\pm.02}$ ${73.4\pm.00}$ ${73.5\pm.00}$ MultiGSemiNMF ${95.6\pm.02}$ ${77.2\pm.12}$ ${79.3\pm.00}$ ${76.2\pm.00}$
下载: 导出CSV
表 3 不同方法在4个数据库中的NMI值
Table 3 The NMI values by different methods in four databases
算法 UCI Digit CMU PIE 3-Sources ORL BSV ${63.4\pm.03}$ ${74.1\pm.00}$ ${53.0\pm.01}$ ${69.8\pm.01}$ WSV ${60.3\pm.03}$ ${69.1\pm.02}$ ${44.1\pm.02}$ ${65.4\pm.04}$ ConcatNMF ${60.3\pm.03}$ ${70.5\pm.00}$ ${51.7\pm.03}$ ${85.1\pm.01}$ ColNMF ${62.1\pm.03}$ ${68.3\pm.00}$ ${55.2\pm.02}$ ${84.5\pm.03}$ Co-reguSC ${77.0\pm.00}$ ${80.5\pm.01}$ ${41.4\pm.01}$ ${80.5\pm.01}$ MultiNMF ${80.4\pm.01}$ ${82.2\pm.02}$ ${60.2\pm.06}$ ${87.6\pm.01}$ SC-ML ${87.6\pm.00}$ ${85.1\pm.00}$ ${45.5\pm.00}$ ${85.3\pm.00}$ MMSC ${88.0\pm.05}$ ${80.3\pm.01}$ ${66.3\pm.09}$ ${85.9\pm.01}$ AMGL ${84.9\pm.33}$ ${81.8\pm.10}$ ${56.9\pm.11}$ ${81.9\pm.02}$ MultiGNMF ${90.1\pm.04}$ ${90.2\pm.01}$ ${65.4\pm.00}$ ${88.5\pm.00}$ MultiGSemiNMF ${91.2\pm.01}$ ${93.8\pm.05}$ ${73.4\pm.00}$ ${89.9\pm.00}$
下载: 导出CSV
-
[1] Lee D D, Seung S. Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401(6755):788-791 doi: 10.1038/44565 [2] Gaussier E, Goutte C. Relation between PLSA and NMF and implications. In: Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Salvador, Brazil: ACM, 2005. 601-602 http://dl.acm.org/citation.cfm?id=1076148 [3] Huang J, Nie F P, Huang H, Ding C. Robust manifold nonnegative matrix factorization. ACM Transactions on Knowledge Discovery from Data, 2014, 8(3):Article No.11 http://d.old.wanfangdata.com.cn/NSTLHY/NSTL_HYCC0215059381/ [4] Zhao S C, Yao H X, Yang Y. Affective image retrieval via multi-graph learning. In: Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, Florida, USA: ACM, 2014. 1025-1028 http://www.mendeley.com/catalog/affective-image-retrieval-via-multigraph-learning/ [5] Zheng L, Yang Y, Tian Q. SIFT meets CNN:a decade survey of instance retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, DOI: 10.1109/TPAMI.2017.2709749 [6] Zheng L, Wang S J, Wang J J, Tian Q. Accurate image search with multi-scale contextual evidences. International Journal of Computer Vision, 2016, 120(1):1-13 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=4f7a6598af368f8eee72bf7a06a26b81 [7] Cao X C, Zhang C Q, Fu H Z, Liu S, Zhang H. Diversity-induced multi-view subspace clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA: IEEE, 2015. 586-594 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=7298657 [8] Guo D Y, Zhang J, Liu X W, Cui Y, Zhao C X. Multiple kernel learning based multi-view spectral clustering. In: Proceedings of the 22nd International Conference on Pattern Recognition. Columbus, Ohio, USA: IEEE, 2014. 3774-3779 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/multiple-kernel-learning-based-multi-view-spectral-clustering-kNa3dnYybl [9] Wang H X, Weng C Q, Yuan J S. Multi-feature spectral clustering with minimax optimization. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio, USA: IEEE, 2014. 4106-4113 http://dl.acm.org/citation.cfm?id=2679912 [10] Cai X, Nie F P, Huang H, Kamangar F. Heterogeneous image feature integration via multi-modal spectral clustering. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado, USA: IEEE, 2011. 1977-1984 http://www.mendeley.com/catalog/heterogeneous-image-feature-integration-via-multimodal-spectral-clustering/ [11] Nie F P, Li J, Li X L. Parameter-free auto-weighted multiple graph learning: a framework for multiview clustering and semi-supervised classification. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: AAAI, 2016. 1881-1887 http://ir.opt.ac.cn/handle/181661/28575 [12] Cai X, Nie F P, Huang H. Multi-view K-means clustering on big data. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. New York, USA: AAAI, 2013. 2598-2604. http://www.mendeley.com/catalog/multiview-kmeans-clustering-big-data/ [13] Xu J L, Han J W, Nie F P. Discriminatively embedded k-means for multi-view clustering. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA: IEEE, 2016. 5356-5364 [14] Kumar A, Rai P, Daume Ⅲ H. Co-regularized multi-view spectral clustering. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Granada, Spain: Curran Associates Inc., 2011. 1413-1421 http://www.mendeley.com/catalog/coregularized-multiview-spectral-clustering/ [15] Kong S, Wang X K, Wang D H, Wu F. Multiple feature fusion for face recognition. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai, China: IEEE, 2013. 1-7 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6553718 [16] Akata Z, Thurau C, Bauckhage C. Non-negative matrix factorization in multimodality data for segmentation and label prediction. In: Proceedings of the 16th Computer Vision Winter Workshop. Mitterberg, Austria: Verlag der Technischen Universität Graz, 2011. [17] Liu J L, Wang C, Gao J, Han J W. Multi-view clustering via joint nonnegative matrix factorization. In: Proceedings of the 2013 SIAM International Conference on Data Mining. Texas, USA: SIAM, 2013. 252-260 [18] He X F, Yan S C, Hu Y X, Niyogi P, Zhang H J. Face recognition using Laplacianfaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(3):328-340 doi: 10.1109/TPAMI.2005.55 [19] Cai D, He X F, Han J W, Huang T S. Graph regularized nonnegative matrix factorization for data representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8):1548-1560 doi: 10.1109/TPAMI.2010.231 [20] Nie F P, Wang X Q, Jordan M I, Huang H. The constrained Laplacian rank algorithm for graph-based clustering. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, Arizona, USA: AAAI, 2016. 1969-1976 http://www.cs.berkeley.edu/~jordan/papers/CLR_aaai16_ready.pdf [21] Li S Z, Hou X W, Zhang H J, Cheng Q S. Learning spatially localized, parts-based representation. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA: IEEE, 2001, 1: I-207-I-212 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.16.294 [22] Ding C H Q, Li T, Jordan M I. Convex and semi-nonnegative matrix factorizations. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(1):45-55 doi: 10.1109/TPAMI.2008.277 [23] Kumar A, Rai P, Daume Ⅲ H. Co-regularized multi-view spectral clustering. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Granada, Spain: Curran Associates Inc., 2011. 1413-1421 http://dl.acm.org/citation.cfm?id=2986459.2986617 [24] Dong X W, Frossard P, Vandergheynst P, Nefedov N. Clustering on multi-layer graphs via subspace analysis on grassmann manifolds. IEEE Transactions on Signal Processing, 2014, 62(4):905-918 doi: 10.1109/TSP.2013.2295553 [25] Lovász L, Plummer M D. Matching Theory. Providence, R.I.: American Mathematical Society, 2009. -

 下载:
下载:

计量
- 文章访问数: 3444
- HTML全文浏览量: 707
- PDF下载量: 899
- 被引次数: 0
