

-
摘要: 人脸民族特征选取与分析是人脸识别与人类学重要研究方向之一.本文建立了中国三个民族人脸数据库,通过流形结构来研究和分析人脸的民族特征.首先,在体质人类学定义的人脸几何特征指标进行流形分析,未形成按语义分布的子流形.因此本文将人脸特征扩至全部组合的长度、角度和比例特征进行分析,利用mRMR算法对2926个长度特征、21万余个角度特征、427万个比例特征中冗余特征进行筛选,加上人类学指标及混合筛选的数据集共形成5个数据集.利用LPP、Isomap、LE、PCA和LDA等流形方法分析5数据集,其中的4个数据集都形成了民族语义的子流形分布.为验证筛选特征指标的有效性,本文利用分类算法J48、SVM、RBF network、Naive Bayes、Bayes network在Weka平台对数据集以族群语义作为类别进行交叉验证实验,实验结果表明混合特征的人脸数据集族群分类平均准确率最高,且比例特征分类指标优于其他特征数据集.本文通过大量实验揭示了民族人脸数据可在子空间内形成按民族语义分布的子流形结构.中国三个民族人脸特征在低维空间存在不同民族语义的子流形,通过流形分析和特征筛选构建的人脸测量指标不仅可为人脸族群分析提供方法,同时也将丰富和补充体质人类学的相关研究工作.Abstract: Facial ethnic feature selection and analysis is one of the most significant research focuses in face recognition and anthropology. In this paper, we build a Chinese ethnic face database including three ethnic groups. Manifold learning is used to analyze facial ethnic features. Firstly, we conduct manifold analysis on the basis of facial geometric indicators proposed by anthropologist, which, however, does not formulate sub-manifold distributed by semantics. Therefore, we intend to expand the scope of facial features by calculating the complete distances, angles and indexes with landmarks. Then, we adopt mRMR to filter 2926 distance indicators, more than 219450 angle indicators and more than 4279275 index indicators. Finally, we can obtain 5 datasets with features of distance, angle, index, anthropology and mixing. Several popular manifold learning methods including LPP, ISOMAP, LE, PCA and LDA are utilized to study the above mentioned datasets, and we get the distinguishable manifold structure of facial ethic feature and clusters in 4 of the 5 datasets. To evaluate the validity of filtered features, we make use of classification algorithms including J48, SVM, RBF network, Naive Bayes, and Bayes network implemented in Weka for cross validation experiments by ethnic semantics. Experimental results indicate that the average of classification accuracy on the dataset with mixing features is higher than that of other datasets, and that the index is more salient than other geometric features. Moreover, by full experimental investigation, we find that ethnic facial data can generate sub-manifold structure distributed by semantics. Facial features of three Chinese ethnic groups exhibit different ethnic semantic sub-manifolds in the low-dimensional space. Facial measurement indicators obtained by manifold analysis and feature selection not only provide a method for facial ethnic groups analysis, but also enrich and improve the related research work in anthropology.
-
Key words:
- Facial ethnic features /
- biometrics recognition /
- face recognition /
- manifold learning
-
随着无线通信技术的进步以及无线传感器网络(Wireless sensor network, WSN)和物联网等的高速发展, 如何精确定位监控区域内的多个目标已经成为信号处理领域中极具挑战和实际意义的问题.多目标定位可以应用于诸多场景, 例如, WSN中传感器节点定位[1]、室内定位[2]、污染源定位[3]、无线电监控等.
传统的定位算法主要分为两类.一类是基于测距的定位算法, 典型算法有利用到达时间测距(Time of arrival, ToA)、利用到达时间差测距(Time difference of arrival, TDoA)、利用到达角度测距(Angle of arrival, AoA)和利用接收信号强度进行三边测距(Received signal strength indicator, RSSI)[4]; 一类是非测距的定位算法, 典型算法有DVhop定位[5]、基于信道感知定位[6]和RSSI指纹定位[7-8]等.然而这些方法都显示出一定的局限性.
近年来, 压缩感知(Compressive sensing, CS)理论的兴起[9]为我们提供了一种全新的视角去看待多目标定位问题.通过对感知区域的网格化, 目标位置在空间域上的稀疏性为压缩感知理论体系的应用提供了可能.研究表明[10-11], 基于压缩感知的多目标定位方法能够实现比传统的定位方法更好的定位性能. Cevher等[12-13]提出了WSN中多目标定位的估计框架, 提出只需少量的测量, 便可以将目标位置的稀疏向量通过传感矩阵进行恢复.在此之后, Feng等[10]开始将多目标定位问题建立在压缩感知欠定方程上, 并采取了基追踪(Basis pursuit, BP)和基追踪降噪(Basis pursuit denoising, BPDN)等恢复算法进行仿真测试及性能比较. Zhang等[11]使用贪婪匹配追踪(Greedy matching pursuit, GMP)算法替代传统的压缩感知恢复算法, 提高了恢复的准确性, 同时对传感矩阵是否满足有限等距特性(Restricted isometry property, RIP)[9]进行了证明. Lin等[14]通过融合两种网格下的恢复结果获得了分集增益, 提高了定位精度.
然而, 之前基于压缩感知定位的研究有诸多不足. 1)求解基于压缩感知的多目标定位问题时, 基于优化逼近的方法定位精度高但计算复杂, 基于贪婪恢复的方法计算简单却定位精度低; 2)简单使用一般的压缩感知恢复算法来实现定位, 忽略了多目标定位问题中丰富的结构信息, 无法有效提升定位性能; 3)为降低密集网格划分带来的强相关性, 文献中广泛采用的正交预处理方法[10]削弱了原始定位模型中的信噪比, 使得定位算法的抗噪性能大幅降低.
鉴于此, 本文针对多目标定位问题, 给出了明确的系统模型, 证明预处理方法削弱模型信噪比, 提出一种新颖的基于压缩感知的层级贪婪匹配追踪定位算法(Hierarchical greedy matching pursuit, HGMP).所提算法具有线性计算复杂度, 提供了一种利用多目标定位场景中的结构信息实现快速贪婪定位的层级架构, 提高了多目标定位系统的定位精度和抗噪声性能.
1. 系统模型
本节首先阐述基于德劳内三角剖分的空间网格化方法, 介绍基于压缩感知的多目标定位模型及各参数的意义.其次, 从压缩感知理论出发, 讨论定位问题中目标数、传感器数目、网格数目三者的相互制约关系.接着, 证明文献中广泛采用的基于正交的预处理操作本质上降低信噪比.最后, 在讨论部分阐述本文的主要动机.
1.1 空间德劳内三角网格划分
不失一般性, 设已知存在$K$个目标的二维感知区域被离散成$N$个网格点(目标服从感知区域内的连续均匀分布), 其中随机均匀散布$M$个传感器(位置已知), 每个传感器测量该点处的接收信号强度(Received signal strength, RSS).在空间网格点数目足够大的前提下, 可以用网格点近似估计目标的位置来确定$K$个目标发射源的位置.
空间网格化是构建定位模型的第一步, 文献中广泛采用均匀矩形网格划分.理论上, 三角形和四面体是二维和三维空间的单纯形, 可以剖分任意复杂的几何形状.因三角剖分具有良好的灵活性和稳定性, 20世纪80年代后, 对三角剖分的研究飞速发展, 除了在有限元分析, 流体力学等传统领域大放光彩外, 在模式识别, 虚拟现实, 计算机视觉等领域也得到广泛的应用.
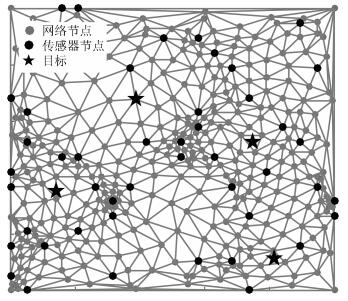
本文采用新提出的基于德劳内三角剖分的空间网格化方法(Delaunay triangulation spatial gridding, DTSG)[14]. DTSG方法利用传感器节点和四个边界点作为原始网格点, 对感知区域进行初步的德劳内三角剖分, 然后依次添加各个德劳内三角形的重心作为新的网格节点, 重新对感知区域进行德劳内三角剖分, 如此迭代分裂, 直至网格点个数满足预设大小.相比均匀矩形网格, 其具有灵活、网格多分辨率、网格密度自适应的特点. Lin等[14]的研究显示, 统计平均意义下, DTSG网格划分方法的定位性能优于传统的均匀矩形网格划分方法.而实际中, 传感器的布置符合一定的先验知识, 如在无线电监控中, 固定监测站点和移动监测平台往往布置在非法电台出现机率大的区域.所以, 这种由传感器节点位置生成网格的空间划分方法更切合实际应用.图 1给出了$M=50$, $N=441$设定下DTSG网格划分结果.其中黑色圆点为随机布置的传感器节点, 灰色圆点为依据DTSG算法生成的网格节点, 五角星为目标发射源.图 1中的目标发射源节点用于示意定位模型, 由DTSG方法可知网格划分与目标无关.
1.2 基于压缩感知的多目标定位模型
由于$K \ll N$, 所以目标的估计位置在空域上具有稀疏性.根据压缩感知理论, 多目标问题可以抽象为通过$M$维接收信号强度的有噪测量(噪声为测量噪声$n$, 近似为高斯噪声), 重建出$N$维空间中的$K$稀疏位置矢量的稀疏近似问题.模型为
$ \begin{align}\label{model1} \boldsymbol{y} = \Phi \Psi \boldsymbol{x} + \boldsymbol{n} = A\boldsymbol{x} + \boldsymbol{n} \end{align} $
(1) 其中, 称为传感矩阵, 是一个过完备字典.在模型(1)中, 我们用网格点来近似真实的目标位置.各参数的意义如下:
1) 目标稀疏位置矢量$\boldsymbol{x} \in {\bf R}_{+}^{N}$
为$K$稀疏矢量, 编码了目标在网格点中的近似位置.如果目标被近似到第$i$个网格点上时, $x_i$为与目标功率有关的正数$C$, 否则为$0$.
2) 基于RSS的稀疏基矩阵$\Psi \in {{\bf R}^{N \times N}}$
的每一列$\pmb \psi_j$代表所有网格点对网格点$j$处目标的RSS测量.在不考虑信号增益的条件下, 网格点$j$处目标在网格点$i$上的接收信号强度满足空间传播的衰落模型[10]
$ \begin{align}\label{propation1} RSS({d_{i, j}}) = {P_0} + {K_e} - 10\eta \lg \frac {{d_{i, \, j}}}{d_0} + \alpha + \beta \end{align} $
(2) 其中, $P_0$为信号发射功率, $K_e$为环境衰减因子, $d_{i, \, j}$为网格点$j$到网格点$i$的物理距离, $d_0$为近场参考距离. $\alpha$为快衰落的影响因子, $\beta$为阴影衰落的影响因子.显而易见, .不同于压缩感知原理中的稀疏基矩阵, 例如离散余弦变换基、快速傅里叶变换基、离散小波变换基等, 在多目标定位模型(1)中的稀疏基矩阵$\Psi$很可能不是$N$维空间的一个基矩阵, 即${\rm span}(\Psi)\subsetneq {{\bf R}^N}$.
3) 测量矩阵$\Phi \in {{\bf R}^{M \times N}}$
测量矩阵表示网格点中的传感器部署方案.多目标定位问题中, 稀疏基矩阵$\Phi$的前$M$列为传感器所在网格点, 所以测量矩阵形式为$\Phi =I_{M \times N}^M$ $=$ , 其中, $I_M$为$M$阶单位矩阵, 为全零矩阵.
4) 测量结果矢量$\boldsymbol{y} \in {{\bf R}^M}$
测量结果矢量$\boldsymbol{y}$为$M$个传感器的实际RSS测量结果. 中的任一元素$y_i$代表第$i$个传感器感知到的所有目标的功率叠加结果.
$ \begin{align} {y_i} = \sum\limits_{j = 1}^K {RSS({d_{i, j}})} \end{align} $
(3) 1.3 模型参数的约束关系
在多目标定位问题中, 研究者感兴趣的问题是需要多少个接收传感器才能成功定位给定数目的目标发射源?网格划分越密集, 是否定位精度会越高?借由压缩感知理论, 可以获得关于这些问题的初步结论.
对于无噪声压缩感知方程$\boldsymbol{y} = A\boldsymbol{x}$, 文献[11]证明, 若且$A$满足$(2K, \sigma)$的RIP条件, 则$\ell_1$范数最小化问题
$ \begin{align}\label{L1min} \min{\lVert \boldsymbol{x} \rVert}_{1} ~~{\rm s.t.}~~\boldsymbol{y} = A\boldsymbol{x} \end{align} $
(4) 的解为$\hat{\boldsymbol{x}}$, 若$\boldsymbol{x}$是严格$K$稀疏信号, 则; 若$\pmb x$是非严格$K$稀疏信号, 则$\hat{\boldsymbol{x}}$能重建出$\boldsymbol{x}$最主要的$K$个系数.当$\boldsymbol{y}$受到噪声污染时, 压缩感知方程(1)的$\ell_1$范数最小化解的重建误差为${{c_0}{\epsilon_0}+{c_1}{\epsilon}}$, 其中${c_0}$, ${c_1}$为很小的正常数, $\epsilon_0$为$\boldsymbol{y}$的重建允许误差范围, ${\epsilon}$为无噪声时的重建误差.
Zhang等[11]证明了多目标定位模型(1)的传感矩阵$A$以大概率满足RIP条件.所以从压缩感知的重构的角度来看, 给定网格划分结果确定了$A$的构成, 而$A$满足的RIP条件阶数又进一步确定了在当前传感矩阵下能够重构出的最大目标数$K$.同时, 为了重构出稀疏位置矢量$\boldsymbol{x}$, 传感器个数需满足$M$ $\ge$ ${\rm O}(K\lg (N/K))$.
在多目标定位问题中, 目标位置的参数空间是连续的.基于压缩感知的定位方法通过把参数空间网格离散化获得对目标位置的网格点近似估计, 然后由这些网格点构成有限离散的过完备字典(即传感矩阵$A$).网格划分越精细, 网格点和真实目标之间的误差就越小, 但过密的网格会造成稀疏基字典中原子间的相关性越强, 进而使得压缩感知的重构性能下降[15], 有如下定理[12].
定理1 [12]. 令$A \in {{\bf R}^{M \times N}}$为一个过完备字典, $\boldsymbol{a_j}$为其第$j$列, 定义相干性(Coherence) $\mu(A)$为
$ \begin{align} \mu \left( A \right) = \mathop {\max }\limits_{1 \le i \ne j \le N} \frac{{\left| {\left\langle {\boldsymbol{a_i}, \boldsymbol{a_j}} \right\rangle } \right|}}{{{{\left\| {\boldsymbol{a_i}} \right\|}_2}{{\left\| {\boldsymbol{a_j}} \right\|}_2}}} \end{align} $
(5) 令$K \le 1 + 1/16u$, 当$M \ge {\rm O}(K\lg (N/K))$时, 任何$K$稀疏向量$\boldsymbol{x}$可以从测量$\boldsymbol{y} = A\boldsymbol{x}$中通过求解式(4)以大概率恢复.
Cevher等[12]的研究表明, 在基于压缩感知的多目标定位场景中, $ \mu \left( A \right) $依赖于$\Delta /2D$.其中$\Delta$为网格精度, $D$为网格点和传感器之间的最大距离(由传感器部署和网格划分共同决定).从而, $\Delta$决定能够成功定位的目标数的下界, 而$D$决定其上界.
另一方面, 为了缓解密集网格划分造成的传感矩阵各列之间的强相关性对压缩感知重建性能的影响, Feng等[10]提出一种基于正交的预处理方法降低了原始传感矩阵各列之间的相关性.此后, 这种预处理方法被研究者广泛使用[10, 14, 16], 下面对基于正交的预处理方法做出了详细介绍, 并证明在有噪情况下, 其本质上放大了噪声的影响, 降低了信噪比.
1.4 基于正交的预处理方法及其不足
定义1 (预处理算子T). 给定模型$\boldsymbol{y} = A\boldsymbol{x}+\boldsymbol{n}$, 定义线性预处理算子为.其中, $A^†$表示$A$的伪逆, 表示对矩阵$A$的规范正交化操作.
设矩阵$A \in {\bf R}_r^{M \times N}$有SVD分解, 其中$U$和$V$均为正交矩阵, $\Sigma$的主对角线元素为$A$的奇异值, 非主对角元素为$0$. $r$为$A$的秩, $r \le M$.对测量结果矢量进行预处理
$ \begin{align} T\boldsymbol{y} = &\ T ( A\boldsymbol{x} + \boldsymbol{n} ) = \notag \\ &\ { V^{\rm T}(:, 1:r) } V {\Sigma ^† } { U^{\rm T} } ( U \Sigma{ V^{\rm T} }\boldsymbol{x} +\boldsymbol{n} ) = \notag \\ &\ {V^{\rm T}(:, 1:r) } \boldsymbol{x} + \boldsymbol{n}' \end{align} $
(6) 其中, $\boldsymbol{n}' = I_{r \times N}^r{\Sigma ^† }{U^{\rm T}}\boldsymbol{n}$.记$\boldsymbol{z} = T\boldsymbol{y}$, 经过预处理后, 多目标定位模型(1)可以表示为
$ \begin{align}\label{model2} \boldsymbol{z}= Q\boldsymbol{x} + \boldsymbol{n}' \end{align} $
(7) 其中, $V(:, 1:r)$为正交矩阵$V$的前$r$列构成的子矩阵.可以证明, 正交矩阵的随机子矩阵满足RIP条件[17].下文中, 称模型(1)为原始模型, 模型(7)为预处理模型, 相应地, $A$称为原始传感矩阵, $Q$称为预处理传感矩阵.
可见, 相对原始传感矩阵$A$, 预处理传感矩阵$Q$的列间相关性已被大大降低.但预处理算子$T$并不是一个无损操作.从原始模型(1)到预处理模型(7), 相对信号功率, 预处理算子$T$放大了噪声水平, 即预处理算子$T$削弱了信噪比(Signal to noise ratio, SNR), 有如下定理.
定义2 (信噪比SNR). 给定模型$\boldsymbol{y} = A\boldsymbol{x} + \boldsymbol{n}$, $\boldsymbol{x}$为随机向量.其中信号为$A\boldsymbol{x}$, 噪声.模型信噪比定义为
$ \begin{align} SNR = \frac{{\rm E}({\lVert A\boldsymbol{x} \rVert}_2^2)}{{\rm E}({\lVert \boldsymbol{n} \rVert}_2^2)} \end{align} $
(8) 定理2. 给定模型$\boldsymbol{y} = A\boldsymbol{x} + \boldsymbol{n}$, 其中$A \in {\bf R}_M^{M \times N}$, 为随机向量且各分量$x_i$满足i.i.d. 条件.模型信噪比为$SNR_1$.对应预处理模型为, 模型信噪比为$SNR_2$.如果存在E$(x_i^2)$, $i=1, 2, \cdots, N$, 则$SNR_2$ $\le$ $SNR_1$.
证明. $A =U \Sigma_1 V^{\rm T}$.其中,
$ \Sigma_1 =[\Sigma \, \, O_{M \times (N-M)}], \ \ \Sigma = {\rm diag}\{s_1, s_2, \cdots, s_M\} $
$s_i$为$A$的奇异值.
记$V^{\rm T}\boldsymbol{x}=(v_1, v_2, \cdots, v_N)^{\rm T}$, , $1/s_2$, $\cdots, 1/s_M\}$.所以
$ \begin{align*} &\lVert A\boldsymbol{x}\rVert_2^2 = \boldsymbol{x}^{\rm T}V\Sigma_1^{\rm T}U^{\rm T}U{\Sigma_1}V^{\rm T}\boldsymbol{x}=\mathop\sum\limits_{i=1}^{M}{s_i^2}{v_i}^2\\ &T=QA^† =[I_M, O_{M\times(N-M)}]V^{\rm T}\\ &\lVert TA\boldsymbol{x}\rVert_2^2 = \!\boldsymbol{x}^{\rm T}V\Sigma_1^{\rm T}U^{\rm T}U\Sigma^{†}\Sigma^{†}U^{\rm T}U{\Sigma_1}V^{\rm T}\boldsymbol{x}=\!\mathop\sum\limits_{i=1}^{M}{v_i}^2\\ &{\rm E}(\boldsymbol{n}^{\rm T}\boldsymbol{n})=M\sigma^2 \end{align*} $
接下来考虑${\rm E}\{\lVert T\boldsymbol{n}\rVert_2^2\}$:
$ {\rm E}\left\{ {\lVert T\boldsymbol{n}\rVert}_2^2 \right\}={\rm E}\left\{ {\lVert \Sigma^{†}U^{\rm T}\boldsymbol{n}\rVert}_2^2 \right\} $
令$\boldsymbol{z}=U^{\rm T}\boldsymbol{n}$, $U$为正交矩阵.因为高斯白噪的正交变换仍为高斯白噪.所以, $ \boldsymbol{z}\sim {\rm N}(0, \sigma^{2}I)$.从而有
$ {\rm E} \left\{ {\lVert \Sigma^{†}U^{\rm T}\boldsymbol{n}\rVert}_2^2 \right\} ={\rm E}\left\{ {\mathop\sum\limits_{i=1}^{M}{\dfrac{z_i^2}{s_i^2}}}\right\}= {\mathop\sum\limits_{i=1}^{M}{\dfrac{\sigma^2}{s_i^2}}} $
所以
$ \begin{align} &\frac{SNR_1}{SNR_2} = \frac{{\rm E}({\lVert A\boldsymbol{x} \rVert}_2^2){\rm E}({\lVert T\boldsymbol{n} \rVert}_2^2)} {{\rm E}({\lVert TA\boldsymbol{x} \rVert}_2^2){\rm E}({\lVert \boldsymbol{n} \rVert}_2^2)} \notag = \\ &\qquad \frac{{\rm E}\left(\mathop\sum\limits_{i=1}^{M}{s_i^2}{v_i}^2\right)\mathop\sum\limits_{i=1}^{M}{\frac{\sigma^2}{s_i^2}}} {{\rm E}\left(\mathop\sum\limits_{i=1}^{M}{v_i}^2\right)M\sigma^2}= \frac{\mathop\sum\limits_{i=1}^{M}{s_i^2}\mathop\sum\limits_{i=1}^{M}{\frac{1}{s_i^2}}} {M^2}\notag \end{align} $
由Cauchy-Schwarz不等式, 有
$ \begin{align} \mathop\sum\limits_{i=1}^{M}{s_i^2}\mathop\sum\limits_{i=1}^{M}{\frac{1}{s_i^2}} \ge \left(\mathop\sum\limits_{i=1}^{M}{s_i \frac{1}{s_i}}\right)^2=M^2 \notag \end{align} $
综上所述
$ \begin{align} SNR_2 \le SNR_1 \notag \end{align} $
等号成立的条件为: $A$的所有奇异值都为1.
在多目标定位模型(1)中, 按照空间传播损耗模型构建的原始传感矩阵$A$, 其奇异值一般远小于1, 根据定理2, 经过预处理算子$T$处理后, 预处理模型(7)的信噪比将远小于原始模型(1)的信噪比.
1.5 讨论
由上述分析可知, 密集划分网格会造成$A$各列间的强相关性, 进而影响重建性能.而文献中为降低列间相关性而采取的正交预处理操作又被证明是放大噪声影响, 降低模型信噪比.然而, 对于定位场景, 只有目标附近的字典原子才会对真实的信号构成具有明显贡献, 远离目标的位置的原子划分并不会给定位带来益处.所以, 对于给定的网格化空间和相应的过完备字典$A$, 可以将观测子空间视为信号子空间和噪声子空间的叠加.
此外, 在求解压缩感知定位问题上, 文献中采用的$\ell_1$范数最小化方法, 例如BP算法, 定位精度高, 抗噪声性能强, 但当$N$很大时, 其${\rm O}(N^3)$的计算成本过于昂贵. RIP条件意味着$A$近似正交的, 这启发了一系列通过迭代求解$\boldsymbol{x}$的$K$个最大稀疏的贪婪算法, 例如正交匹配追踪算法(Orthogonal matching pursuit, OMP)等.这些贪婪算法通常具有直观, 易于理解, 计算简单的优点.但在定位问题中, 其对噪声较为敏感, 且容易陷入局部最优解中.
所以, 本文的主要动机为以贪婪重建的方式, 利用多目标定位场景中隐含的结构信息, 从观测子空间中分离出信号子空间, 降低测量噪声和网格密集划分所带来的强相关性的影响, 提升贪婪恢复的定位准确性.更具体地, 原始模型(1)中隐藏着丰富的结构信息, 预处理模型(7)适合于贪婪求解, 利用原始模型(1)和预处理模型(7)进行联合迭代贪婪定位, 将获得更优异的定位表现.
2. 层级贪婪匹配追踪定位算法
本节首先分析多目标定位场景中隐含的结构信息.其次, 利用这些结构信息提出一种分层贪婪匹配追踪的多目标定位方法(HGMP).最后, 对所提算法的收敛性和计算复杂度做出分析.
2.1 多目标定位场景中的结构信息
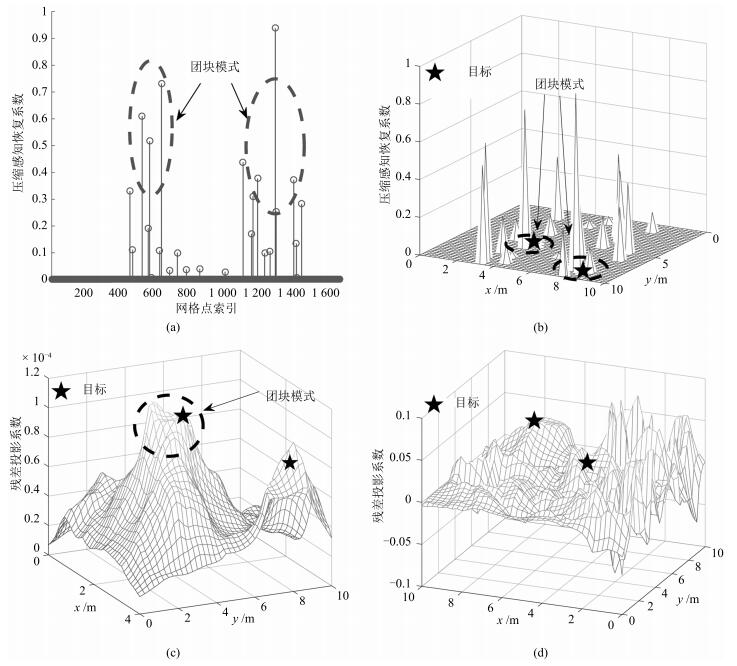
1) 团块模式
原始模型(1)是对多目标定位问题的网格点近似, 真实的目标位置可能分布在感知区域的任何位置, 不一定精确地在网格点上.所以, 接收信号投影到网格空间上的能量将分散在真实目标附近的原子团上.迭代过程中, 残差投影到网格空间上的能量将分散在对当前残差贡献最大目标附近的原子团上.具体地, 在真实目标位置附近的网格点上, 压缩感知恢复系数或残差在网格空间上的投影具有相近的取值, 且幅度明显高于远离目标位置的网格点上的, 称这种模式为团块模式.图 2 (a)和2 (b)分别展示的是恢复系数在网格点索引集上和网格空间上的团块模式. Yang等[16]注意到了恢复系数的团块模式, 其在BP算法的定位结果上利用KNN聚类对恢复位置进行加权平均, 鉴于BP算法的计算复杂度, 其很难被应用到实际中; 图 2 (c)展示的是在原始传感矩阵$A$上在OMP算法迭代过程中残差的团块模式, 可以清晰看到, 左边的目标对当前残差贡献最大, 其附近的原子团呈现出明显的团块模式; 图 2 (d)展示的是预处理传感矩阵$Q$上OMP算法迭代过程中残差在网格空间上的投影, 由于基于正交的预处理操作打乱了原始传感矩阵$A$中的相关性, 所以不再具有明显的团块模式.本文研究OMP算法迭代过程中残差在原始传感矩阵A的团块模式.
2) 冗余信息
如前所述, 为了在多目标定位问题中应用贪婪类压缩感知恢复算法, 文献中常采用预处理算子$T$.数学上, $T$是一个不可逆算子, 它把$M$维非稀疏矢量$\boldsymbol{y}$映射成$r$维()矢量$\boldsymbol{z}$, 再通过$\boldsymbol{z}$重建$N$维$K$稀疏矢量$\boldsymbol{x}$.前文的分析显示, $T$放大噪声的影响, 降低模型信噪比.此外, 预处理传感矩阵$Q$是一个正交矩阵的子矩阵, 相对原始传感矩阵而言, 其列之间的相关性已被大大降低.所以相对原始模型(1), 预处理模型损失了冗余的信息.对于一个系统来说, 冗余虽然带来有效性的降低, 但是另一方面, 却是系统可靠性的重要保障.在多目标定位问题中, 这种冗余信息的损失可以从$A$和$Q$的列相关性中得到解释. $A$中的每一列$\boldsymbol{a_j}$代表所有传感器对网格点$j$处目标的RSS测量, 空域中网格点$i$和网格点$j$距离越近, $\boldsymbol{a_i}$和$\boldsymbol{a_j}$就越相关.所以$A$的列之间的相关性具有清晰的物理意义.作为这种相关性在残差投影上的反映, 投影结果也会在空域上呈现出清晰的相关性, 如图 2 (c)所示, 残差在原始传感矩阵$A$上的投影呈现出清晰的团块模式.与此相反, 预处理传感矩阵$Q$是正交矩阵$V$的子矩阵, $Q$的列相关性已经无法直接体现空域上网格点间的相关性.如图 2 (d)所示, 残差在传感矩阵$Q$上的投影无清晰的团块模式.
2.2 算法步骤
提出的HGMP算法是一种层级的贪婪算法, 利用多目标定位场景中的结构信息, 具有线性计算复杂度和很好的可解释性. HGMP算法的思想是以贪婪的方式, 逐步发掘多目标定位问题中的残差在原始传感矩阵中投影的团块模式, 进而利用预处理模型获得贪婪恢复.算法特征为:全局估计层获得目标可能位置的全局估计, 稀疏恢复层利用全局估计信息进行目标稀疏位置矢量压缩感知贪婪重建.有以下核心算法步骤.
输入. 测量结果矢量$\boldsymbol{y}$, 原始感知矩阵$A$, 目标数$K$;
输出. 目标位置恢复点集$P$, $\boldsymbol{x}$的$K$稀疏逼近$\hat{\boldsymbol{x}}$;
初始化. 候选集$\Omega \leftarrow \phi $, 残差相关集$\Lambda \leftarrow \phi $, 删除集$\Delta \leftarrow \phi $, 残差$\boldsymbol{v} \leftarrow \boldsymbol{y}$, 格点索引集$\mathbb{N} \leftarrow \{ 1, 2$, $\cdots$, $N\}$;
预处理. 计算预处理感知矩阵$Q$, 计算;
全局估计层. 迭代量, 循环执行步骤$1$ $\sim$ $5$.
步骤1. 寻找对当前残差贡献最大的原子团$\Lambda$ $\leftarrow$ $\{ j| \langle {\boldsymbol{v}, \boldsymbol{a_j}} \rangle > Th( {\boldsymbol{v}, A} )$, ;
步骤2. 利用$\boldsymbol{z}$和$Q$, 在中进行局部正交匹配追踪, 得到$\Lambda$上的的恢复系数$\boldsymbol{\theta}$及其支撑集$\Pi$;
步骤3. 对$\boldsymbol{\theta}$及其支撑集$ \Pi$正则化, 结果为;
步骤4. 迭代更新. , ${\Delta \leftarrow \Delta \cup \Omega}$, $\boldsymbol{v}$ $\leftarrow$ $\boldsymbol{y}-A_{\Omega }A_{\Omega }^{†} \boldsymbol{y}$, ${i \leftarrow i + 1}$;
步骤5. 如果, 进入下一次迭代, 返回步骤1;否则, 进入稀疏恢复层, 执行步骤6;
稀疏恢复层.
步骤6. 扩大候选集
$ {\Omega \leftarrow \Omega \cup \left\{ {l\left. {\left| {l \in Neighbor(j, D), j \in \Omega , l \in \mathbb{N} \backslash \Omega } \right.} \right\}} \right.} $
步骤7. 利用$\boldsymbol{z}$和$Q$, 在候选集$\Omega$中进行正交匹配追踪, 得到$\boldsymbol{x}$的$K$稀疏逼近$\hat{\boldsymbol{x}}$及其支撑集$P$; 其中, $A_\Omega$表示$A$的索引集为$\Omega$的列构成的子矩阵.步骤1中, $Th(\boldsymbol{v}, A)$是自适应动态门限, 定义为
$ {Th(\boldsymbol{v}, A)=\max \{ A_{\mathbb{N} \backslash \Delta}^{\rm T}\boldsymbol{v} \}-{\rm std}(\{ A_{\mathbb{N} \backslash \Delta}^{\rm T}\boldsymbol{v} \}} $
动态门限能够自适应地提取对当前残差贡献最大的原子团, 噪声水平高时, 残差投影系数的方差较大, 动态门限自适应地降低门限值来对抗噪声的干扰, 保证空域上与当前残差相关的目标附近格点能够被选入残差相关集$\Lambda$.反之, 当噪声水平低时, 动态门限会提高门限值, 减少选入残差相关集$\Lambda$中弱相关格点的数目.
步骤3中, 正则化[18]处理旨在从恢复系数中找出幅度相近且具有最大能量的子集.给定恢复系数$\theta$及其下标集合$\Pi$, 在集合$\Pi$中寻找子集$\Pi_0$, 满足
$ \left| {\theta_i} \right| \le 2\left| {\theta_j} \right|, \quad\forall i, j \in {\Pi _0} $
正则化操作选择所有满足要求的子集$\Pi_0$中具有最大能量(的$\Pi_0$作为输出.
步骤6中, $Neighbor(j, D)$指在空域上与格点$j$的欧氏距离小于门限值的格点集合.
2.3 讨论和分析
1) 收敛性和抗噪声性能
不同于一般的基于压缩感知的定位方法, HGMP通过全局估计层获得目标可能位置的候选原子集合, 然后稀疏重建层在候选原子集合上获得最终的稀疏贪婪重建结果.这等效于从观测空间中分离出信号子空间, 然后在信号子空间上进行贪婪正交匹配追踪.在进行全局估计时, 利用原始传感矩阵$A$上残差投影的团块模式, 筛选出对当前残差贡献最大的原子团, 然后利用预处理传感矩阵$Q$易于贪婪恢复的优势获得局部正交匹配追踪恢复结果, 最后通过正则化处理从局部恢复结果中挑选出能量最大且贡献类似的原子团.由正则化操作的分析[18]可知, 最终全局估计层的输出原子团中一定包含OMP最终估计的$K$个原子, 而稀疏重建层算法是子空间上的OMP算法.所以, 在高信噪比条件下, HGMP将和OMP算法保持一致的收敛性.当信噪比较低时, OMP算法易受噪声干扰, 陷入局部最优解中, 而HGMP挑选原子的方法比OMP更为谨慎, 每次挑选出原子团而非单个最相关原子的模式也使得算法对噪声的鲁棒性更强.全局估计层把可能位置从$\mathbb{N}$缩小到候选集$\Omega$, 已经极大地去除了噪声造成的虚假目标位置候选点.所以, 在此基础上进行贪婪恢复定位具有明显的抗噪声优势.
2) 计算复杂度
步骤1中投影操作实质是矩阵向量乘法, 门限比对操作实质是一个遍历过程, 所以步骤1的复杂度为.
步骤2把残差的能量正交投影到残差相关集$\Lambda$上, 实质上是一个OMP子问题, 复杂度为, 其中$C_1 = card(\Lambda)$且$C_1 \ll N$.
步骤3中正则化操作实质上是大小为$C_1$的数集上的排序和二重循环遍历过程, 复杂度为 $+$ $K^{2})$.
步骤4在候选集$\Omega$中更新残差涉及一个最小二乘问题, 复杂度为, 其中$C_2 =card(\Omega)$, 且满足$C_2 \ll N$.
步骤6扩大候选集, 包含$C_2$个遍历格点集合的操作, 复杂度为.
所以, 全局恢复层的复杂度为${\rm O}(K(MN +$ $MC_1^2$ $+$ .渐进地, 当$N$很大时, 占主导作用, 全局估计层的渐进复杂度为${\rm O}(KMN)$.
稀疏恢复层是候选集上的稀疏度为$K$的OMP操作, 其复杂度为.
综上所述, 当$N$较小时, HGMP算法计算复杂度不高于.当$N$很大时, HGMP算法的渐进复杂度为${\rm O}(KMN)$.
3. 算法仿真
为验证所提算法在抗噪性能和计算复杂度方面的提升, 采用经典的OMP算法和BP算法作为对比.此外, 为了对比算法在DTSG网格划分和均匀矩形网格划分上的性能, 对于同样的仿真参数设置, 每一次蒙特卡洛仿真中在两种网格上分别进行定位.仿真的硬件环境为Intel Core i7-6700处理器, 主频3.4 GHz, 8 GB内存; 软件环境为Windows 10 + MATLAB R2016a.
3.1 评价度量
平均定位正确率(Mean localization accuracy rate, MLAR).如果在距离真实目标$T_i$小于1 m的范围内能够找到恢复点$\hat{T_i}$, 认为目标$T_i$被成功定位, 恢复点$\hat{T_i}$被称为目标$T_i$的匹配恢复点.把被成功定位的目标个数${\#Successful\_Localized\_Targets}$与总目标个数${\#Targets}$的比值记为恢复的正确率.
$ \begin{align} MLAR = \frac{{\#Successful\_ Localized\_Targets}}{{\#Targets}} \end{align} $
(9) 平均定位误差距离(Mean localization error distance, MLED)定义为目标$T_i$的真实位置$({x_i}$, ${y_i})$和最近的匹配恢复点位置$({\hat{x}_i, \hat{y}_i})$之间的平均欧氏距离, 公式为
$ \begin{align} MLED = \frac{1}{K}\sum\limits_{i = 1}^K {\sqrt {{{({x_i} - {{\hat x}_i})}^2} + ({y_i} - {{\hat y}_i})^2} } \end{align} $
(10) 平均运行时间(Mean run time, MRT)指每次蒙特卡洛仿真中算法运行时间的平均值, 以此来评价算法的时间复杂度.
3.2 仿真参数选择
感知区域设为$10\, {\rm m} \times 10\, {\rm m}$的方形区域, 网格点$N$ $=21 \times 21$, 目标数$K = 4$.目标有效全向辐射功率.稀疏基字典$\Psi$采用IEEE802.15.4标准中的室内传播损耗模型[14].
$ \begin{align} & RSS(d) = \begin{cases} {P_t} - 40.2 - 20\lg d, &D \le 8\\ {P_t} - 58.5 - 33\lg \frac{d}{8}, &D > 8 \end{cases} \end{align} $
(11) 测量噪声为高斯白噪声, 为了有效验证算法的定位性能, 消除随机因素的影响, 取3 000次仿真的均值作为实验结果(每一次仿真均重新撒布目标和传感器, 重新构造空间网格).
3.3 仿真结果和分析
下文中均匀矩形网格划分简称为矩形网格, DTSG网格划分简称为三角网格.
1) 抗噪声性能和计算复杂度
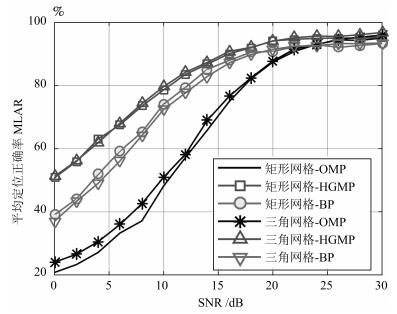
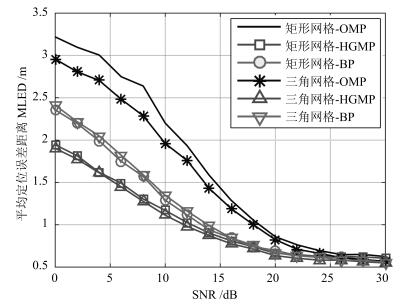
图 3和图 4分别给出了$M=50$时, 在均匀矩形网格划分和DTSG网格划分下各算法的平均定位正确率和平均定位误差距离受信噪比的影响.可以看出:
a) 随着信噪比的增加, 各算法的平均定位正确率不断上升, 平均定位误差距离不断下降.当SNR $>$ 25 dB时, BP和OMP的定位性能趋于收敛, 当SNR $>$ 22 dB时, HGMP的定位性能趋于收敛.由于基于压缩感知的多目标定位模型是对真实目标位置的一个逼近模型, 当信噪比大于一定程度时, 多目标定位问题中的测量噪声不再是主要矛盾.对于图 3, 限制MLAR继续增加的主要因素为定义成功定位的精度(仿真中为1 m)和网格精度(网格划分带来的模型逼近误差, 仿真中平均网格间距为0.5 m); 对于图 4, 限制MLED继续降低的主要因素为网格精度.
b) 在统计平均意义上, 对于BP算法和HGMP算法, DTSG三角网格划分和传统的均匀矩形网格划分的定位性能保持一致; 对于OMP, 在同样的噪声水平下, 三角网格划分能实现比均匀矩形划分更高的定位正确率和更低的定位误差距离.
c) 在噪声占主要影响因素的前提下(SNR $<$ 25 dB), 通过在迭代过程中利用残差的团块模式, 限制在信号子空间上进行贪婪重建, HGMP的定位正确率和定位误差距离优于BP的, 远远优于OMP的, 显示出良好的抗噪能力.
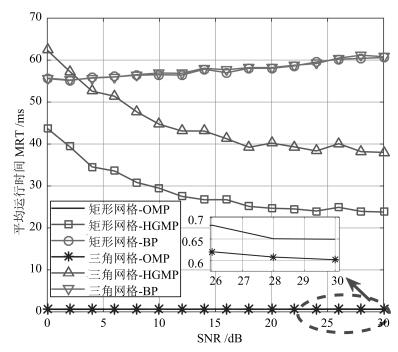
图 5给出上述实验过程中各算法的平均运行时间. HGMP算法的计算复杂度显著低于BP算法.随着信噪比的提高, HGMP的平均运行时间降低.这是因为噪声水平越低, 残差投影的团块结构越明显, 投影方差越小, 每次选入残差相关集$\Lambda$中的格点数目也越少, 从而运行时间也越少.同样的噪声水平下, HGMP算法在三角网格划分上的运行时间要高于矩形网格划分的, 近似是矩形网格划分的常数倍.这是因为计算残差相关集采取的动态门限函数和残差投影标准差相关, 由于三角网格划分的非均匀性和非规则性, 其投影方差大于均匀矩形网格划分的, 导致三角网格中的残差相关集包含更多的格点, 使得三角网格上的运行时间高于矩形网格上的.相对BP算法和HGMP算法, OMP只包含投影、最小二乘、更新残差三个步骤, 所以其计算最为简单, 但从图 3和图 4可以看出, OMP低计算复杂度的代价是对噪声敏感, 当SNR较低时, 定位性能低于HGMP和BP.
2) 传感器个数的影响
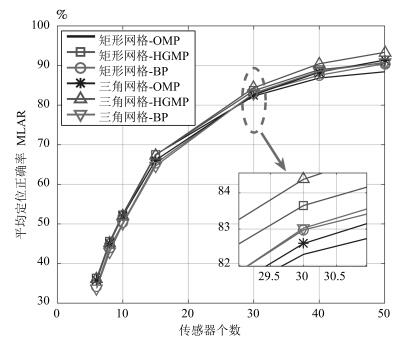
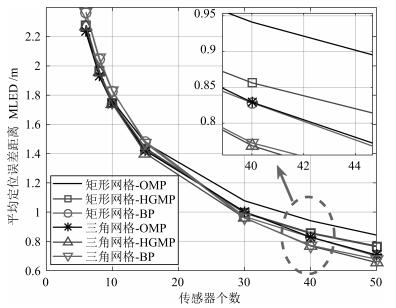
图 6和图 7分别给出了$SNR = 25$ dB条件下, 传感器数目为6, 8, 10, 15, 30, 40, 50时, 均匀矩形网格划分和DTSG网格划分下各算法的平均定位正确率和平均定位误差距离.可以清晰看出, 随着传感器的个数不断增加, 各算法的平均定位正确率不断上升, 平均定位误差距离不断下降, 但变化趋于平缓.对于$K=4$, $M=441$, 理论上需要传感器的下界为.从图 6和图 7可以看出, 当传感器个数小于20时, 所有算法的平均定位误差距离都大于1 m, 平均定位正确率小于70 %.当传感器个数大于30时, 除了在矩形网格划分上的OMP算法外, 其他算法的平均定位误差距离都小于1 m, 相应的平均定位正确率大于82 %.统计意义上, 对于1 m范围的成功定位精度, 经验值和理论值之间的差距为11个传感器.其次, 对于同一传感器数目, HGMP在DTSG三角网格划分和均匀矩形网格划分下都显示出优于其他算法的定位性能, 且在DTSG三角网格划分下的HGMP定位性能最优.
4. 结论
本文给出了一种新颖的基于压缩感知的多目标分层贪婪匹配定位方法(HGMP), 并证明了文献中广泛采用的正交预处理操作降低定位信噪比.所提算法从观测子空间中分离出信号子空间, 利用原始传感矩阵和预处理传感矩阵进行联合迭代贪婪定位, 提供一种利用多目标定位问题中丰富的结构信息实现鲁棒性贪婪定位的层级架构.理论分析和计算仿真表明, HGMP定位算法具有渐进线性复杂度${\rm O}(KMN)$.相同信噪比下, HGMP在不同网格划分上均展示出更好的定位性能.
-
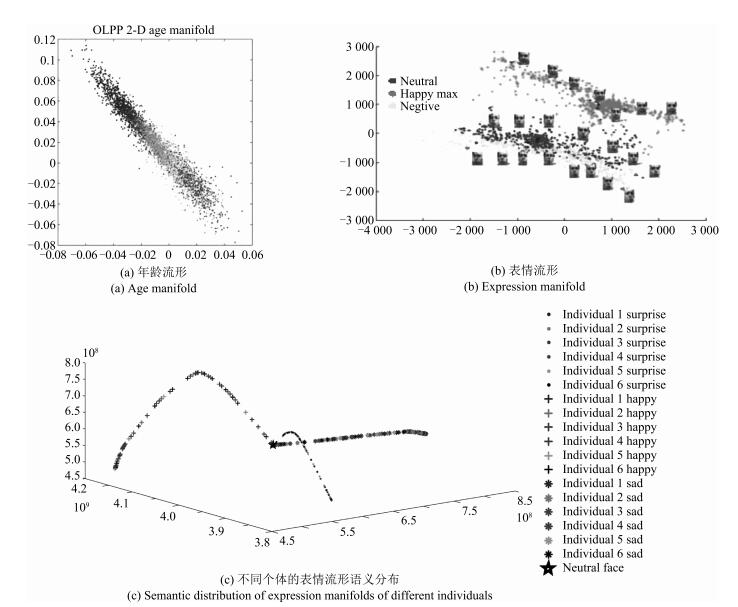
图 2 人脸年龄和表情属性的流形语义分布
Fig. 2 Semantic distribution of age and facial expression attributes
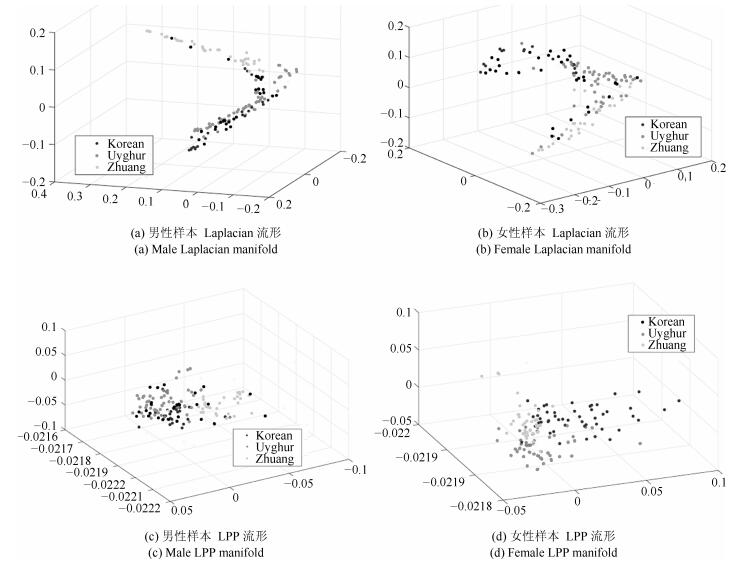
图 4 壮族(浅色)、维吾尔族(中浅色)、朝鲜族(深色)男女流形结构
Fig. 4 Male and female manifold structure of three ethnies (Zhuang, Uygur, Korean)

图 12 筛选长度特征数据集的流形结构
Fig. 12 The illustration of ethnic manifold structure based on selected features
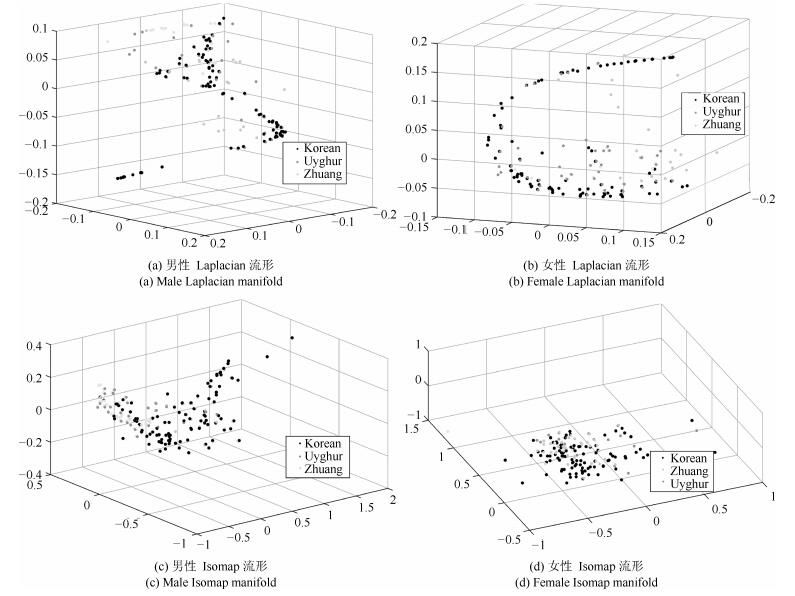
图 15 壮族(浅色)、维吾尔族(中浅色)、朝鲜族(深色)男女流形结构
Fig. 15 The male and female manifold structure of the Zhuang (light), Uygur (middle light) and Korean (dark)

图 20 不同指标下的民族判别决策树
Fig. 20 Ethnic classification decision trees with different indicators
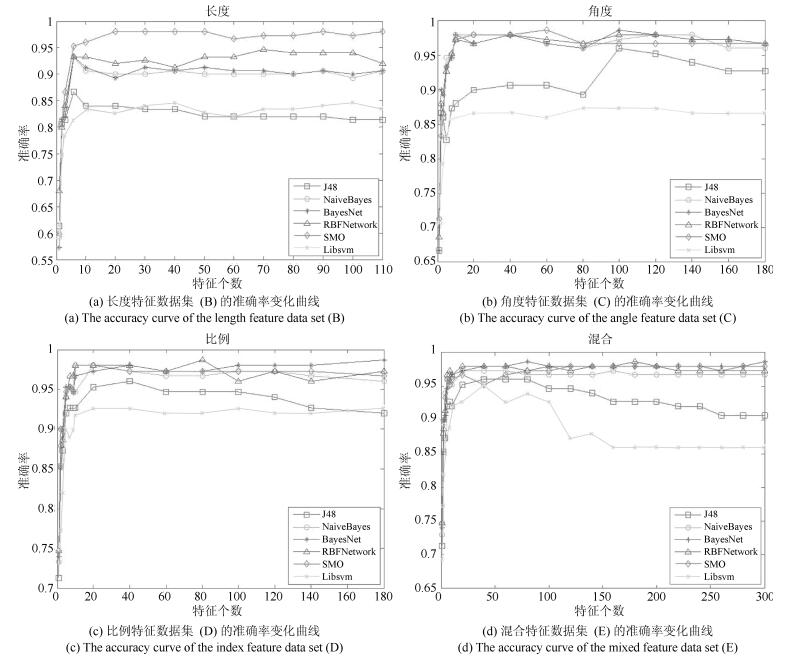
图 21 不同类型特征增量下的准确率变化曲线
Fig. 21 The recongnition rates comparison based on different types of features
民族 人口数量 人口比例(%) 地理位置 壮族 16 926 381 1.27 广西 维吾尔族 10 069 346 0.76 新疆 朝鲜族 1 830 929 0.14 吉林  下载: 导出CSV
下载: 导出CSV
表 2 筛选的几何特征
Table 2 The selected geometric features
长度几何特征 角度几何特征 比例几何特征 特征维度 2 926 219 450 4 279 275 筛选后特征维度 195 250 500
下载: 导出CSV
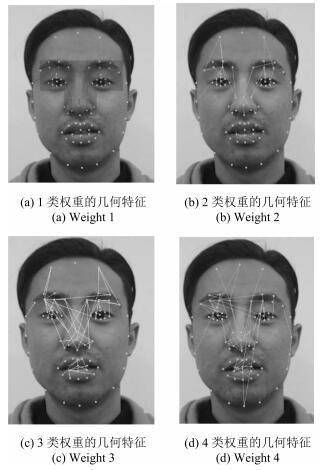
表 3 mRMR筛选的4个权重范围的长度特征
Table 3 The selected distance-based features by mRMR
权重 权重区域特点 1 眼裂宽度、眉眼距离、眉与鼻翼距离、鼻翼长度特征 2 眉毛各长度特征、额头宽度、鼻翼与眼内角距离、下唇厚度 3 更为精细的鼻部和嘴部几何长度特征 4 嘴部与眉尖距离, 嘴部与下颚距离, 眉与耳朵距离 人类学常用指标体系 头长、头宽、面宽、鼻宽、鼻高、唇厚、口裂宽、内眼角宽、外眼角间距、内眼角间距、颧间宽、下颌长度、下颌角间距
下载: 导出CSV
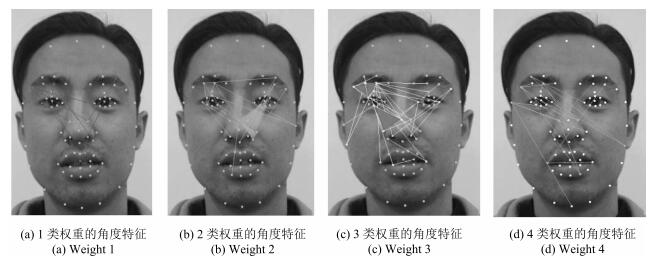
表 4 mRMR筛选的4个权重范围的角度特征
Table 4 The selected angle features by mRMR
权重 角点 权重区域特点 1 眉尖点 眉毛与内眼角点和鼻根部形成的角度关系 2 鼻根点, 眉尖点, 形成鼻翼与鼻眼角度关系热区, 耳位置点 通过角度度量眉眼距离关系 3 眉、眼角点 眼裂角度, 眉眼之间角度关系, 鼻翼角度关系 4 眉和嘴部 更为精细的眼鼻嘴之间定位关系
下载: 导出CSV
表 5 体质人类学定义的15个正脸指数
Table 5 The 15 Physical anthropological definition of 15 frontal face index
序号 指数特征名称 1 头宽高指数 2 额顶宽指数 3 头面宽指数 4 形态面指数 5 形态上面指数 6 容貌面指数 7 颧下颌宽度指数 8 颧额宽指数 9 容貌上面指数 10 额面指数 11 容貌上面高 12 头面高指数 13 鼻指数 14 鼻宽深指数 15 唇指数
下载: 导出CSV
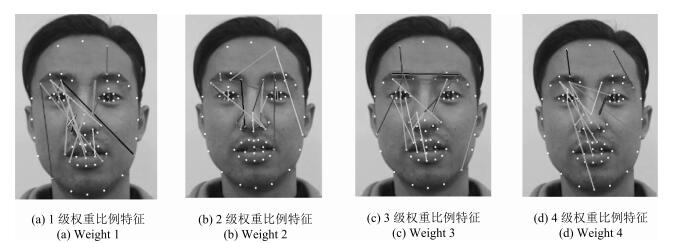
表 6 不同权重的比例特征
Table 6 The index features with different weight
序号 权重区域特点 权重值 (眼裂高度) / (眉眼距离) 0.329 1 (眼裂高度) / (鼻翼与眉毛距离) 0.362 (鼻翼与眉毛距离)/ (嘴部与眉尖) 0.312 (鼻翼与眼内角点距离) / (额头高度) 0.35 (眼裂高度) / (鼻翼与眉毛距离) 0.302 2 (鼻翼长度) / (眉眼距离) 0.302 (眉眼距离) / (眉毛与鼻翼距离) 0.301 (鼻翼长度) / (眉毛与嘴部距离) 0.302 (眼裂高度) / (鼻翼与眉毛距离) 0.30 3 (鼻翼与眼内角点距离) / (额头高度) 0.294 (鼻翼距离) / (嘴巴与眼外角点距离) 0.297 (眉间距) / (鼻翼与眼内角距离) 0.297 (眼裂高度) / (鼻翼与眼内角点距离) 0.274 4 (眉毛与上唇距离) / (眉毛与下唇距离) 0.283 (鼻翼长度) / (眼睛与下颌距离) 0.281
下载: 导出CSV
表 7 长度、角度筛选出的51个人脸几何特征
Table 7 The selected 51 geometric features from distance-based and angular attributes
ID 类型 详细 权重 ID 类型 详细 权重 1 I (49, 57)/(22, 7) 0.669 27 I (39, 43)/(7, 22) 0.299 2 I (35, 47)/(23, 51) 0.362 28 I (49, 69)/(34, 72) 0.296 3 I (37, 51)/(16, 24) 0.35 29 I (22, 73)/(21, 64) 0.298 4 I (39, 43)/(22, 36) 0.329 30 I (49, 52)/(15, 7) 0.296 5 I (50, 71)/(33, 60) 0.33 31 I (35, 47)/(28, 51) 0.298 6 I (49, 52)/(5, 17) 0.312 32 I (25, 50)/(21, 27) 0.292 7 I (22, 76)/(21, 54) 0.312 33 I (37, 51)/(14, 19) 0.294 8 I (51, 59)/(22, 45) 0.302 34 A ∠(21, 55, 26) 0.289 9 I (31, 35)/(37, 51) 0.305 35 I (39, 43)/(28, 51) 0.287 10 A ∠(51, 59, 27) 0.311 36 I (49, 52)/(22, 38) 0.289 11 I (39, 43)/(20, 58) 0.302 37 I (49, 76)/(35, 72) 0.289 12 I (37, 59)/(14, 22) 0.302 38 I (50, 52)/(22, 60) 0.286 13 I (17, 36)/(23, 50) 0.302 39 I (35, 47)/(23, 50) 0.287 14 I ∠(31, 22, 33) 0.297 40 I (49, 52)/(7, 35) 0.287 15 I (49, 52)/(60, 74) 0.304 41 I (22, 53)/(21, 50) 0.284 16 I (50, 55)/(17, 55) 0.301 42 I (50, 70)/(33, 60) 0.285 17 I (18, 21)/(33, 49) 0.302 43 A ∠(17, 49, 21) 0.285 18 I (35, 60)/(21, 54) 0.305 44 I (37, 51)/(16, 24) 0.285 19 I (39, 43)/(23, 51) 0.303 45 I (37, 51)/(16, 24) 0.282 20 I (37, 51)/(18, 25) 0.301 46 A ∠(51, 25, 59) 0.283 21 I (22, 73)/(21, 76) 0.347 47 A ∠(35, 29, 49) 0.284 22 I (49, 52)/(24, 66) 0.303 48 I (49, 57)/(22, 43) 0.282 23 I (49, 57)/(14, 22) 0.302 49 I (39, 43)/(19, 49) 0.282 24 I (50, 57)/(29, 61) 0.296 50 A ∠(21, 49, 25) 0.281 25 A ∠(21, 36, 22) 0.299 51 I (31, 35)/(24, 51) 0.279 26 A ∠(22, 60, 50) 0.298 注: I代表长度, A代表角度
下载: 导出CSV
表 8 混合指标中的特征边与点的频繁项集
Table 8 The frequent itemsets of the characteristic edge and point in the mixed attributes
ID 边 支持度 说明 ID 点 支持度 部位 1 39 ~ 43 6 眼裂 1 22 16 眉 2 49 ~ 52 6 鼻翼长度 2 49 16 鼻 3 37 ~ 51 4 鼻眼距离 3 51 14 鼻 4 35 ~ 47 3 眼裂 4 21 11 眉 5 49 ~ 57 3 鼻翼宽度 5 50 10 鼻 6 22 ~ 73 2 眉嘴距离 6 35 9 眼 7 31 ~ 35 2 眼裂 7 37 7 眼 8 14 ~ 22 2 额头高度1 8 43 7 眼 9 16 ~ 24 2 额头高度2 9 52 7 鼻 10 21 ~ 54 2 眉鼻距离1 10 39 6 眼 11 23 ~ 50 2 眉鼻距离2 11 24 5 眉 12 23 ~ 51 2 眉鼻距离3 12 57 4 鼻 13 23 4 眉 14 31 3 眼 15 46 3 眼 16 14 3 额头 17 16 3 额头 18 73 2 嘴 19 54 2 鼻
下载: 导出CSV
表 9 J48交叉验证学习后结果指标
Table 9 J48 cross validation results after feature learning
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.753 0.123 0.753 0.753 0.753 0.814 B M 0.833 0.083 0.834 0.833 0.833 0.879 C M 0.92 0.04 0.921 0.921 0.921 0.935 D M 0.90 0.05 0.902 0.9 0.90 0.935 E M 0.96 0.02 0.96 0.96 0.96 0.975 A F 0.727 0.137 0.725 0.727 0.724 0.775 B F 0.773 0.113 0.776 0.773 0.773 0.863 C F 0.813 0.093 0.814 0.813 0.812 0.853 D F 0.767 0.117 0.765 0.767 0.764 0.844 E F 0.813 0.093 0.818 0.813 0.814 0.888
下载: 导出CSV
表 10 Naive Bayes实验结果
Table 10 Naive Bayes experimental results
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.82 0.09 0.821 0.82 0.82 0.927 B M 0.90 0.05 0.903 0.90 0.901 0.96 C M 0.96 0.02 0.96 0.96 0.96 0.993 D M 0.967 0.017 0.968 0.967 0.967 0.992 E M 0.973 0.013 0.974 0.973 0.973 0.999 A F 0.773 0.113 0.779 0.773 0.772 0.882 B F 0.753 0.123 0.755 0.753 0.750 0.902 C F 0.893 0.053 0.894 0.893 0.893 0.947 D F 0.887 0.057 0.889 0.887 0.887 0.956 E F 0.92 0.04 0.921 0.92 0.92 0.979
下载: 导出CSV
表 11 Bayes network实验结果
Table 11 Bayes network experimental results
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.793 0.103 0.793 0.793 0.793 0.923 B M 0.893 0.053 0.897 0.893 0.894 0.962 C M 0.967 0.017 0.967 0.967 0.967 0.995 D M 0.967 0.017 0.967 0.967 0.967 0.992 E M 0.967 0.017 0.967 0.987 0.987 1.0 A F 0.733 0.133 0.735 0.733 0.734 0.883 B F 0.767 0.117 0.766 0.767 0.766 0.898 C F 0.887 0.057 0.888 0.887 0.887 0.951 D F 0.900 0.05 0.901 0.9 0.9 0.964 E F 0.913 0.043 0.914 0.913 0.913 0.983
下载: 导出CSV
表 12 RBF network实验结果
Table 12 RBF network experimental results
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.773 0.113 0.775 0.773 0.773 0.871 B M 0.913 0.043 0.915 0.913 0.914 0.947 C M 0.967 0.017 0.967 0.967 0.967 0.978 D M 0.973 0.013 0.974 0.973 0.973 0.976 E M 0.993 0.003 0.993 0.993 0.993 0.994 A F 0.753 0.123 0.753 0.753 0.753 0.866 B F 0.807 0.097 0.805 0.807 0.805 0.904 C F 0.900 0.050 0.900 0.900 0.900 0.937 D F 0.893 0.053 0.893 0.893 0.893 0.943 E F 0.907 0.047 0.909 0.907 0.907 0.94
下载: 导出CSV
表 13 SVM中LibSVM实验结果
Table 13 SVM in LibSVM experimental results
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.773 0.113 0.775 0.773 0.772 0.83 B M 0.82 0.09 0.823 0.82 0.823 0.865 C M 0.86 0.07 0.858 0.86 0.857 0.895 D M 0.933 0.033 0.934 0.933 0.933 0.95 E M 0.953 0.023 0.953 0.953 0.953 0.965 A F 0.733 0.133 0.752 0.733 0.734 0.8 B F 0.720 0.14 0.758 0.72 0.713 0.79 C F 0.667 0.167 0.715 0.667 0.608 0.75 D F 0.860 0.07 0.862 0.86 0.859 0.895 E F 0.92 0.04 0.922 0.92 0.92 0.94
下载: 导出CSV
表 14 SVM中SMO实验结果
Table 14 SVM in SMO experimental results
DataSet Sex TP Rate FP Rate Precision Recall F-Measure AUC A M 0.893 0.053 0.895 0.893 0.893 0.944 B M 0.967 0.017 0.967 0.967 0.967 0.982 C M 0.967 0.017 0.967 0.967 0.967 0.983 D M 0.973 0.013 0.974 0.973 0.973 0.985 E M 0.973 0.013 0.973 0.973 0.973 0.985 A F 0.867 0.067 0.868 0.867 0.867 0.922 B F 0.907 0.047 0.907 0.907 0.907 0.947 C F 0.907 0.047 0.907 0.907 0.907 0.943 D F 0.933 0.033 0.934 0.933 0.934 0.965 E F 0.953 0.023 0.954 0.953 0.953 0.97
下载: 导出CSV
表 15 SVM中SMO实验结果
Table 15 SVM in SMO experimental results
性别 J48 Naive Bayes BayesNet M(20长度特征) 80.00±1.83 89.33±1.04 79.30±1.62 M(195长度特征) 83.33±2.21 90.00±1.06 89.33±0.69 M(250角度特征) 92.00±1.05 96.00±0.55 96.70±0.85 M(400角度特征) 90.00±1.11 96.70±0.47 96.70±0.28 M(51混合特征) 96.00±0.55 97.33±0.21 98.67±0.53 F(20长度特征) 72.67±2.31 77.33±1.44 73.33±1.94 F(195长度特征) 77.33±1.51 75.33±1.21 76.67±1.20 F(250角度特征) 81.33±2.78 89.33±0.95 88.67±0.47 F(400角度特征) 76.67±2.51 88.67±0.55 90.00±0.38 F(51混合特征) 81.33±2.10 92.00±0.35 91.33±0.32 M(20长度特征) 77.33±2.17 89.33±1.65 77.33±1.03 M(195长度特征) 91.33±0.95 96.67±0.54 82.00±0.99 M(250角度特征) 96.70±0.85 96.70±0.56 86.00±0.32 M(400角度特征) 97.30±0.35 97.30±0.61 93.30±0.52 M(51混合特征) 99.33±1.25 97.33±0.49 95.33±0.49 F(20长度特征) 75.33±2.87 86.67±1.19 73.33±1.67 F(195长度特征) 80.67±1.14 90.67±1.29 72.00±1.43 F(250角度特征) 90.00±1.10 90.67±0.88 66.67±1.08 F(400角度特征) 89.33±0.85 93.33±1.30 86.00±0.73 F(51混合特征) 90.67±0.94 95.33±0.76 92.00±0.89
下载: 导出CSV
-
[1] Calder A J, Rhodes G, Johnson M, Haxby J. The Oxford Handbook of Face Perception. Oxford:Oxford University Press, 2011. [2] Bruce V, Young A. Understanding face recognition. British Journal of Psychology, 1986, 77(3):305-327 doi: 10.1111/bjop.1986.77.issue-3 [3] 苏连成, 朱枫.一种新的全向立体视觉系统的设计.自动化学报, 2006, 32(1):67-72 http://www.aas.net.cn/CN/abstract/abstract15769.shtmlSu Lian-Cheng, Zhu Feng. Design of a novel omnidirectional stereo vision system. Acta Automatica Sinica, 2006, 32(1):67-72 http://www.aas.net.cn/CN/abstract/abstract15769.shtml [4] O'Toole A J, Roark D A, Abdi H. Recognizing moving faces:a psychological and neural synthesis. Trends in Cognitive Sciences, 2002, 6(6):261-266 doi: 10.1016/S1364-6613(02)01908-3 [5] Eberhardt J L, Dasgupta N, Banaszynski T L. Believing is seeing:the effects of racial labels and implicit beliefs on face perception. Personality and Social Psychology Bulletin, 2003, 29(3):360-370 doi: 10.1177/0146167202250215 [6] Kumar N, Berg A, Belhumeur P N, Nayar S. Describable visual attributes for face verification and image search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(10):1962-1977 doi: 10.1109/TPAMI.2011.48 [7] Demirkus M, Garg K, Guler S. Automated person categorization for video surveillance using soft biometrics. In: Proceedings of the 2010 SPIE 7667, biometric technology for human identification Ⅶ. Orlando, Florida, USA: SPIE, 2010. Article No. 76670P doi: 10.1117/12.851424 [8] Senior A, Pankanti S, Hampapur A, Brown L, Tian Y L, Ekin A, Connell J, Shu C F, Lu M. Enabling video privacy through computer vision. IEEE Security and Privacy, 2005, 3(3):50-57 doi: 10.1109/MSP.2005.65 [9] Ito T A, Bartholow B D. The neural correlates of race. Trends in Cognitive Sciences, 2009, 13(12):524-531 doi: 10.1016/j.tics.2009.10.002 [10] 张继宗.中国体质人类学研究.北京:科学出版社, 2010.Zhang Ji-Zong. The Research of Chinese Physical Anthropology. Beijing:Science Press, 2010. [11] 席焕久.体质人类学.北京:知识产权出版社, 2012.Xi Huan-Jiu. Physical Anthropology. Beijing:Intellectual Property Publish House, 2012. [12] Bledsoe W W. Man-Machine Facial Recognition. Panoramic Research Inc. Palo Alto, CA, Report PRI: 22, 1966. [13] Kanade T. Picture Processing System by Computer Complex and Recognition of Human Faces[Ph. D. dissertation]. Kyoto University, Japan, 1973 http://www.researchgate.net/publication/239021259_Picture_Processing_by_Computer_Complex_and_Recognition_of_Human_Faces [14] Brunelli R, Poggio T. Face recognition:features versus templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993, 15(10):1042-1052 doi: 10.1109/34.254061 [15] Malpass R S, Kravitz J. Recognition for faces of own and other race. Journal of Personality and Social Psychology, 1969, 13(4):330-334 doi: 10.1037/h0028434 [16] Lindsay D S, Jack P C, Christian M A. Other-race face perception. Journal of Applied Psychology, 1991, 76(4):587-589 doi: 10.1037/0021-9010.76.4.587 [17] Li Z, Duan X, Zhang Q, Wang C R, Wang Y G, Liu W Q. Multi-ethnic facial features extraction based on axiomatic fuzzy set theory. Neurocomputing, 2017, 242:161-177 doi: 10.1016/j.neucom.2017.02.070 [18] Hadid A, Pietikäinen M. Demographic classification from face videos using manifold learning. Neurocomputing, 2013, 100:197-205 doi: 10.1016/j.neucom.2011.10.040 [19] Seung H S, Lee D D. The manifold ways of perception. Science, 2000, 290(5500):2268-2269 doi: 10.1126/science.290.5500.2268 [20] Fu S Y, He H B, Hou Z G. Learning race from face:a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(12):2483-2509 doi: 10.1109/TPAMI.2014.2321570 [21] Duan X D, Wang C R, Liu X D, Li Z J, Wu J, Zhang H L. Ethnic features extraction and recognition of human faces. In: Proceedings of the 2nd International Conference on Advanced Computer Control (ICACC). Shenyang, China: IEEE, 2010. 125-130 [22] 段晓东, 王存睿, 刘向东, 刘慧.人脸的民族特征抽取及其识别.计算机科学, 2010, 37(8):276-279, 301 http://www.docin.com/p-1301615906.htmlDuan Xiao-Dong, Wang Cun-Rui, Liu Xiang-Dong, Liu Hui. Minorities features extraction and recognition of human faces. Computer Science, 2010, 37(8):276-279, 301 http://www.docin.com/p-1301615906.html [23] Li Z D, Duan X D, Zhang Q L. A novel survey based on multiethnic facial semantic web. TELKOMNIKA, 2013, 11(9):5076-5083 https://www.researchgate.net/profile/Qingling_Zhang4/publication/275415292_A_Novel_Survey_Based_on_Multiethnic_Facial_Semantic_Web/links/5675798408aebcdda0e46b5e.pdf?inViewer=0&pdfJsDownload=0&origin=publication_detail [24] 段晓东, 李泽东, 王存睿, 张庆灵, 刘晓东.基于AFS的多民族人脸语义描述与挖掘方法研究.计算机学报, 2016, 39(7):1435-1449 doi: 10.11897/SP.J.1016.2016.01435Duan Xiao-Dong, Li Ze-Dong, Wang Cun-Rui, Zhang Qing-Ling, Liu Xiao-Dong. Multi-ethnic face semantic description and mining method based on AFS. Chinese Journal of Computer, 2016, 39(7):1435-1449 doi: 10.11897/SP.J.1016.2016.01435 [25] Turk M, Pentland A. Eigenfaces for recognition. Journal of Cognitive Neuroscience, 1991, 3(1):71-86 doi: 10.1162/jocn.1991.3.1.71 [26] Belhumeur P N, Hespanha J P, Kriegman D J. Eigenfaces vs. fisherfaces:recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7):711-720 doi: 10.1109/34.598228 [27] Bartlett M S, Movellan J R, Sejnowski T J. Face recognition by independent component analysis. IEEE Transactions on Neural Networks, 2002, 13(6):1450-1464 doi: 10.1109/TNN.2002.804287 [28] Yang J, Zhang D, Frangi A F, Yang J Y. Two-dimensional PCA:a new approach to appearance-based face representation and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1):131-137 doi: 10.1109/TPAMI.2004.1261097 [29] Li M, Yuan B Z. 2D-LDA:a statistical linear discriminant analysis for image matrix. Pattern Recognition Letters, 2005, 26(5):527-532 doi: 10.1016/j.patrec.2004.09.007 [30] Tenenbaum J B, de Silva V, Langford J C. A global geometric framework for nonlinear dimensionality reduction. Science, 2000, 290(5500):2319-2323 doi: 10.1126/science.290.5500.2319 [31] Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Computation, 2003, 15(6):1373-1396 doi: 10.1162/089976603321780317 [32] He X F, Niyogi X. Locality preserving projections. Neural Information Processing Systems, 2004, 16(4):153-160 [33] He X F, Yan S C, Hu Y X, Niyogi P, Zhang H J. Face recognition using Laplacianfaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(3):328-340 doi: 10.1109/TPAMI.2005.55 [34] He X F, Cai D, Yan S C, Zhang H J. Neighborhood preserving embedding. In: Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China: IEEE, 2005, 2: 1208-1213 [35] 詹德川, 周志华.基于集成的流形学习可视化.计算机研究与发展, 2005, 42(9):1533-1537 http://www.cnki.com.cn/Article/CJFDTOTAL-WXJY201508008.htmZhan De-Chuan, Zhou Zhi-Hua. Ensemble-based manifold learning for visualization. Journal of Computer Research and Development, 2005, 42(9):1533-1537 http://www.cnki.com.cn/Article/CJFDTOTAL-WXJY201508008.htm [36] 何力, 张军平, 周志华.基于放大因子和延伸方向研究流形学习算法.计算机学报, 2005, 28(12):2000-2009 doi: 10.3321/j.issn:0254-4164.2005.12.007He Li, Zhang Jun-Ping, Zhou Zhi-Hua. Investigating manifold learning algorithms based on magnification factors and principal spread directions. Chinese Journal of Computers, 2005, 28(12):2000-2009 doi: 10.3321/j.issn:0254-4164.2005.12.007 [37] 曾宪华, 罗四维.动态增殖流形学习算法.计算机研究与发展, 2007, 44(9):1462-1468 https://www.wenkuxiazai.com/doc/d9249222a32d7375a417801c.htmlZeng Xian-Hua, Luo Si-Wei. A dynamically incremental manifold learning algorithm. Journal of Computer Research and Development, 2007, 44(9):1462-1468 https://www.wenkuxiazai.com/doc/d9249222a32d7375a417801c.html [38] Chen S B, Zhao H F, Kong M, Luo B. 2D-LPP:a two-dimensional extension of locality preserving projections. Neurocomputing, 2007, 70(4-6):912-921 doi: 10.1016/j.neucom.2006.10.032 [39] 张大明, 符茂胜, 罗斌.基于二维近邻保持嵌入的图像识别.模式识别与人工智能, 2011, 24(6):810-815 http://www.oalib.com/paper/4238112Zhang Da-Ming, Fu Mao-Sheng, Luo Bin. Image recognition with two-dimensional neighbourhood preserving embedding. Pattern Recognition and Artificial Intelligence, 2011, 24(6):810-815 http://www.oalib.com/paper/4238112 [40] Li Z D, Zhang Q L, Duan X D, Wang C R, Shi Y. New semantic descriptor construction for facial expression recognition based on axiomatic fuzzy set. Multimedia Tools and Applications, 2017, 1:1-31 doi: 10.1007/s11042-017-4818-3 [41] Roweis S T, Saul L K. Nonlinear dimensionality reduction by locally linear embedding. Science, 2000, 290(5500):2323-2326 doi: 10.1126/science.290.5500.2323 [42] Li Z D, Zhang Q L, Duan X D, Wei W. Semantic knowledge based on fuzzy system for describing facial expression. In: Proceedings of the 2017 Chinese Control Conference. 2017: 9865-9870 http://www.researchgate.net/publication/320114803_Semantic_knowledge_based_on_fuzzy_system_for_describing_facial_expression [43] Guo G D, Fu Y, Dyer C R, Huang T S. Image-based human age estimation by manifold learning and locally adjusted robust regression. IEEE Transactions on Image Processing, 2008, 17(7):1178-1188 doi: 10.1109/TIP.2008.924280 [44] Yan S C, Xu D, Zhang B Y, Zhang H J. Graph embedding: a general framework for dimensionality reduction. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005, 2: 830-837 [45] 续爽, 贾云得.基于表情相似性的人脸表情流形.软件学报, 2009, 20(8):2191-2198 http://mall.cnki.net/magazine/Article/JSJF201702007.htmXu Shuang, Jia Yun-De. Facial expression manifold based on expression similarity. Journal of Software, 2009, 20(8):2191-2198 http://mall.cnki.net/magazine/Article/JSJF201702007.htm [46] 李小林. 中国南方五个少数民族人群面部五官形态特征研究[硕士学位论文], 重庆医科大学, 中国, 2008 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y1353533Li Xiao-Lin. Analysis of Morphous Characteristics of Facial Reconstruction and the Five Organs in Chinese South Five National Minorities Crowd[Master dissertation], Chongqing Medical University, China, 2008 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y1353533 [47] 赵明, 文建军, 赵霞, 孙嬿嬿.藏、蒙、土、回、汉五民族青年面部测量数据分析.青海医学院学报, 1995, 16(3):7-8 http://paper.usc.cuhk.edu.hk/Details.aspx?id=5247Zhao Ming, Wen Jian-Jun, Zhao Xia, Sun Yan-Yan. An analysis on measuring data of face in 169 young students of Tibetan, Mongolian, Tu, Huis, and Han nationality. Journal of Qinghai Medical College, 1995, 16(3):7-8 http://paper.usc.cuhk.edu.hk/Details.aspx?id=5247 [48] 席焕久, 陈昭.人体测量方法.第2版.北京:科学出版社, 2010.Xi Huan-Jiu, Chen Zhao. Anthropometric Methods (Second edition). Beijing:Science Press, 2010. [49] Wang X, Liu X, Zhang L. A rapid fuzzy rule clustering method based on granular computing. Applied Soft Computing, 2014, 24(C):534-542 https://www.sciencedirect.com/science/article/pii/S156849461400369X [50] Heo J, Savvides M. Gender and ethnicity specific generic elastic models from a single 2D image for novel 2D pose face synthesis and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(12):2341-2350 doi: 10.1109/TPAMI.2011.275 [51] Feng Ding-Cheng, Chen Feng, Xu Wen-Li. Detecting local manifold structure for unsupervised feature selection. Acta Automatica Sinica, 2014, 40(10):2253-2261 doi: 10.1016/S1874-1029(14)60362-1 [52] 王朝云, 蒋刚毅, 郁梅, 陈芬.基于流形特征相似度的感知图像质量评价.自动化学报, 2016, 42(7):1113-1124 http://www.aas.net.cn/CN/Y2016/V42/I7/1113Wang Chao-Yun, Jiang Gang-Yi, Yu Mei, Chen Fen. Manifold feature similarity based perceptual image quality assessment. Acta Automatica Sinica, 2016, 42(7):1113-1124 http://www.aas.net.cn/CN/Y2016/V42/I7/1113 [53] Huang D, Shan C, Ardabilian M, Wang Y, Chen L. Local binary patterns and its application to facial image analysis:a survey. IEEE Transactions on Systems, Man, and Cybernetics, Part C:Applications and Reviews. 2011, 41:765-781 doi: 10.1109/TSMCC.2011.2118750 [54] Wang Y G, Duan X D, Liu X D, Wang C R, Li Z D. Semantic description method for face features of larger Chinese ethnic groups based on improved WM method. Neurocomputing, 2016, 175:515-528 doi: 10.1016/j.neucom.2015.10.089 [55] Milborrow S, Nicolls F. Active shape models with SIFT descriptors and MARS. In: Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP). Lisbon, Portugal: IEEE, 2014. 380-387 [56] Ding C, Peng H C. Minimum redundancy feature selection from microarray gene expression data. Journal of Bioinformatics and Computational Biology, 2005, 3(2):185-205 doi: 10.1142/S0219720005001004 [57] Peng H C, Long F H, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8):1226-1238 doi: 10.1109/TPAMI.2005.159 [58] 洪泉, 陈松灿, 倪雪蕾.子模式典型相关分析及其在人脸识别中的应用.自动化学报, 2008, 34(1):21-30 http://www.aas.net.cn/CN/abstract/abstract16043.shtmlHong Quan, Chen Song-Can, Ni Xue-Lei. Sub-pattern canonical correlation analysis with application in face recognition. Acta Automatica Sinica, 2008, 34(1):21-30 http://www.aas.net.cn/CN/abstract/abstract16043.shtml [59] 高全学, 潘泉, 梁彦, 张洪才, 程咏梅.基于描述特征的人脸识别研究.自动化学报, 2006, 32(3):386-392 http://www.aas.net.cn/CN/abstract/abstract15824.shtmlGao Quan-Xue, Pan Quan, Liang Yan, Zhang Hong-Cai, Cheng Yong-Mei. Face recognition based on expressive features. Acta Automatica Sinica, 2006, 32(3):386-392 http://www.aas.net.cn/CN/abstract/abstract15824.shtml [60] Bouckaert R R, Frank E, Hall M A, Holmes G, Pfahringer B, Reutemann P, Witten I H. WEKA-experiences with a java open-source project. The Journal of Machine Learning Research, 2010, 11:2533-2541 https://researchcommons.waikato.ac.nz/handle/10289/4766 [61] Han J W, Kamber M, Pei J. Data Mining: Concepts and Techniques (Third edition). Amsterdam: Elsevier, 2011. [62] Quinlan J R. C4. 5: Programs for Machine Learning. San Mateo, CA, USA: Morgan Kaufmann Publishers, 1993. [63] Zhang M L, Peña J M, Robles V. Feature selection for multi-label naive Bayes classification. Information Sciences, 2009, 179(19):3218-3229 doi: 10.1016/j.ins.2009.06.010 [64] Gopnik A, Glymour C, Sobel D M, Schulz L E, Kushnir T, Danks D. A theory of causal learning in children:causal maps and Bayes nets. Psychological Review, 2004, 111(1):3-32 doi: 10.1037/0033-295X.111.1.3 [65] Kokshenev I, Braga A P. A multi-objective approach to RBF network learning. Neurocomputing, 2008, 71(7-9):1203-1209 doi: 10.1016/j.neucom.2007.11.021 [66] Joachims T. Making Large Scale SVM Learning Practical[Ph. D. dissertation]. Universität Dortmund, Germany, 1999 http://www.researchgate.net/publication/28355923_Making_Large-Scale_SVM_Learning_Practical [67] Keerthi S S, Shevade S K, Bhattacharyya C, Murthy K R K. Improvements to Platt's SMO algorithm for SVM classifier design. Neural Computation, 2001, 13(3):637-649 doi: 10.1162/089976601300014493 -

 下载:
下载:










计量
- 文章访问数: 3405
- HTML全文浏览量: 622
- PDF下载量: 642
- 被引次数: 0
