

-
摘要: 针对目前综合调度算法不能兼顾产品工艺树中并行工序的并行性和串行工序之间紧密度,影响调度结果的问题,提出考虑后续工序的择时综合调度算法.该算法提出工序序列排序策略,从工艺树的整体结构出发,将其划分成若干内部工序只具有串行关系的工序序列,并按路径长度从长到短的顺序确定其调度次序;提出择时调度策略和考虑后续工序策略,根据工艺树自身特点,从来自不同工序序列的并行工序的不同组合方案中,选择最接近调度目标的方案作为工序调度方案,若该工序调度方案不唯一,则在其中选择该工序加工开始时间最早的调度方案.该算法既保证了工序的并行处理,又提高了串行工序的紧密度,优化了综合调度的结果.最后通过实例说明本文算法对解决综合调试问题具有普遍意义.Abstract: Integrated scheduling algorithms currently neglected the compactness of serial processes when handling a general integrated scheduling problem, and it influenced the scheduling result. Aiming at this problem, an time-selective integrated scheduling algorithm considering posterior processes was presented. The strategy of process sequence sorting was proposed. From the overall structure of the process tree, it was divided into several sequence of processes in which the processes only had a serial relationship. According to the path length to determined the order of its scheduling. The strategy of time-selective and considering posterior processes was proposed. According to the characteristics of the process tree, selected the most close to the scheduling objectives as a process scheduling scheme from the different combination of parallel process from different process sequence. If the process scheduling scheme was not unique. selected the process scheduling scheme in which The processing start time of the process was the earliest. This algorithm promises to proceed together the parallel processing of processes, and effectively raises the compactness of serial processes. The results of integrated scheduling are optimized. Finally illustrated by examples.
-
Key words:
- Process sequence sorting /
- posterior processes /
- time-selective /
- integrated scheduling
-
-

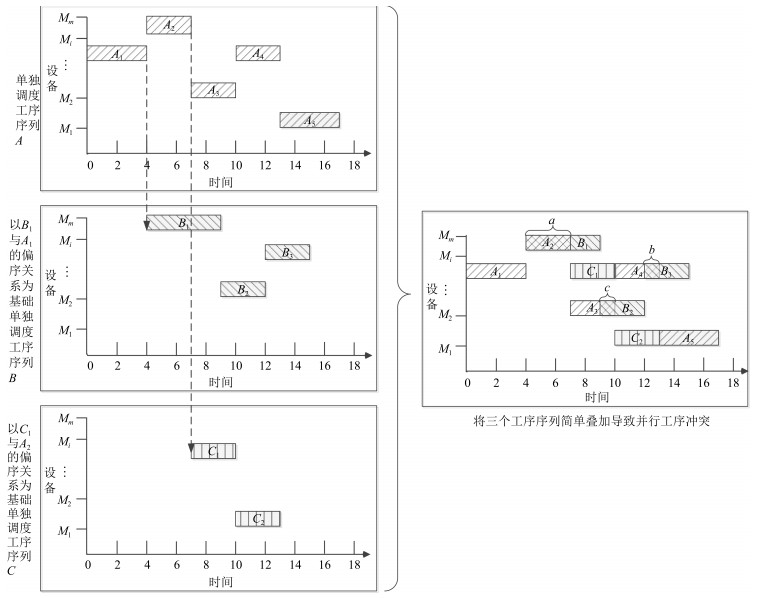
图 6 工序序列排序策略序列划分示意图
Fig. 6 The schematic of sequence divided by operation sequence sorting strategy
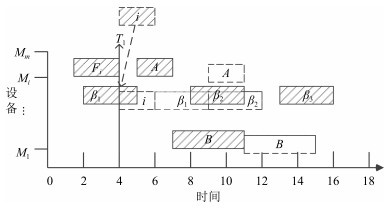
图 8 处理工序$i$试调度后工序发生冲突示意图
Fig. 8 The diagram of process conflict when process $i$ tried to scheduled
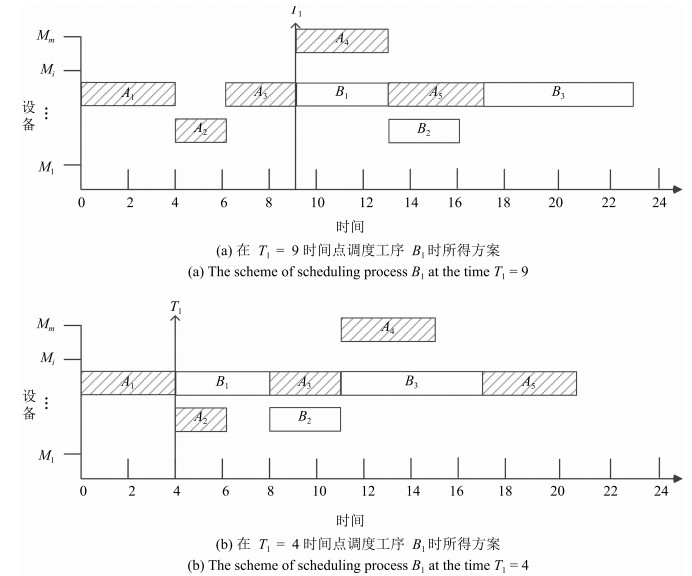
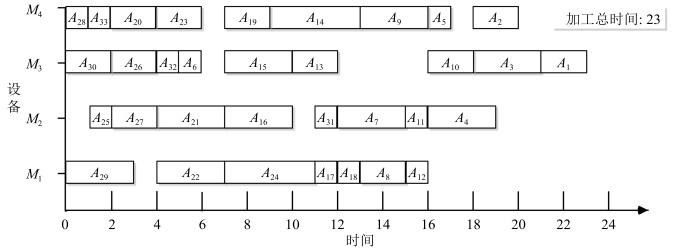
图 10 仅使用择时策略在不同时间点调度工序$B_{1}$方案比较
Fig. 10 Scheme comparison of Scheduling $B_{1}$ in different time when only use timing strategy

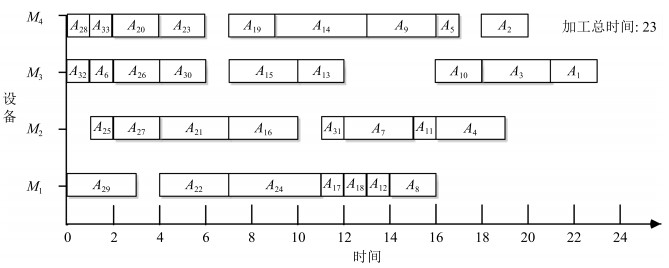
图 11 采用考虑后续工序策略在不同时间点调度工序$B_{1}$方案比较
Fig. 11 The comparison of scheme of scheduling $B_{1}$ in different time
表 1 综合调度问题参数表
Table 1 Parameter list of integrated scheduling problem
参数 含义 $M_{i}$ 工序$i$的加工设备 $T_{Si}$ 工序$i$的加工开始时间 $T_{i}$ 工序$i$的加工用时 $T_{Ei}$ 工序$i$的加工结束时间 $T_{Mki}$ 调度工序$i$后第$k$台设备上当前加工完成时间, $1\leq k\leq m$ $T_{Mi}$ 调度工序$i$后当前最晚加工完成的已调度工序加工完成时间 $T_{Tij}$ 工序$i$的第$j$个"准调度时间点", $j\geq 1$ $T_{Ti}$ 工序$i$的"准调度时间点"集合 $F_{ij}$ 工序$i$在工艺树中的第$j$个紧前工序, $j\geq 1$ $N_{if}$ 工序$i$在工艺树中的第$f$个紧后工序, $f\geq 1$ $F_{Mi}$ 工序$i$在其加工设备上的紧前工序 $N_{Mig}$ 工序$i$在其加工设备上的第$g$个后工序 $N_{Qik}$ 工序$i$在其工序序列上的第$k$个后续工序  下载: 导出CSV
下载: 导出CSV
表 2 本文算法调度产品$A$过程
Table 2 Scheduling the product $A$ by the algorithm proposed
工序号 加工设备 准调度时间点 试调度方案加工总时间 后续工序静态调度时间 确定调度时间点 当前方案中每个工序调度时间点 $A_{1}$ $M_3$ - - - 0 $A_{1}$: 0; $A_{2}$ $M_4$ - - - 2 $A_{1}$: 0, $A_{2}$: 2; $A_{10}$ $M_3$ - - - 4 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4; $A_{11}$ $M_2$ - - - 6 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6; $A_{18}$ $M_1$ - - - 7 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7;$A_{15}$ $M_3$ - - - 8 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7, $A_{15}$: 8;$A_{21}$ $M_2$ - - - 11 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7, $A_{15}$: 8, $A_{21}$: 11;$A_{26}$ $M_3$ - - - 14 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7, $A_{15}$: 8, $A_{21}$: 11, $A_{26}$: 14;$A_{25}$ $M_2$ - - - 16 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7, $A_{15}$: 8, $A_{21}$: 11, $A_{26}$: 14,
$A_{25}$: 16;$A_{28}$ $M_1$ - - - 17 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 4, $A_{11}$: 6,
$A_{18}$:7, $A_{15}$: 8, $A_{21}$: 11, $A_{26}$: 14,
$A_{25}$: 16, $A_{28}$: 17;$A_{3}$ $M_3$ 2|6|11|16 19|19|18|19 18|22|27|32 2 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$:7,
$A_{18}$: 8, $A_{15}$: 9, $A_{21}$: 12, $A_{26}$: 15,
$A_{25}$: 17, $A_{28}$: 18, $A_{3}$: 2;$A_{9}$ $M_4$ 5|19 19|22 19|32 5 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$:7,
$A_{18}$: 8, $A_{15}$: 9, $A_{21}$: 12, $A_{26}$: 15,
$A_{25}$: 17, $A_{28}$: 18, $A_{3}$: 2, $A_{9}$: 5;$A_{13}$ $M_3$ 8|12|17 20|19|19 18|22|27 8 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$:7,
$A_{18}$: 8, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8;$A_{16}$ $M_2$ 10|16|19 20|21|22 18|24|27 10 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$:7,
$A_{18}$: 8, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10;
下载: 导出CSV
表 3 本文算法调度产品$A$过程(续表 2)
Table 3 Scheduling the product $A$ by the algorithm proposed (continued Table 2)
工序号 加工设备 准调度时间点 试调度方案加工总时间 后续工序静态调度时间 确定调度时间点 当前方案中每个工序调度时间点 $A_{23}$ $M_4$ 13|20 20|22 20|23 13 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 7,
$A_{18}$: 8, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13;$A_{29}$ $M_1$ 15 20 18 15 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 7,
$A_{18}$: 8, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15;$A_{5}$ $M_4$ 4|8|
15|2020|20|
20|2116|20|
27|324 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$:7,
$A_{18}$: 8, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4;$A_{7}$ $M_2$ 5|8|
13|16|1920|21|
23|21|2216|19|
24|28|305 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5;$A_{17}$ $M_1$ 8|10|18 20|20|20 16|18|26 8 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8;$A_{19}$ $M_4$ 9|15|20 20|20|22 16|22|27 9 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 9;$A_{22}$ $M_1$ 11|18 20|21 16|23 11 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 9,
$A_{22}$: 11;$A_{20}$ $M_4$ 14|15|20 21|20|22 16|17|22 15 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 9,
$A_{22}$: 11, $A_{20}$: 15;$A_{4}$ $M_2$ 2|8|9|
13|16|1920|23|22|
23|21|2213|19|20|
24|28|302 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 9,
$A_{22}$: 11, $A_{20}$: 15, $A_{4}$: 2;
下载: 导出CSV
表 4 本文算法调度产品$A$过程(续表 3)
Table 4 Scheduling the product $A$ by the algorithm proposed (continued Table 3)
工序号 加工设备 准调度时间点 试调度方案加工总时间 后续工序静态调度时间 确定调度时间点 当前方案中每个工序调度时间点 $A_{8}$ $M_1$ 5|9|10|
14|1820|22|20|20|
2013|17|18|
22|265 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 13, $A_{29}$: 15,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 9,
$A_{22}$: 11, $A_{20}$: 15, $A_{4}$: 2, $A_{8}$: 5;$A_{14}$ $M_4$ 7|8|11|
15|17|2026|20|20|
22|22|2413|14|17|
21|23|268 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 5,
$A_{14}$: 8;$A_{27}$ $M_2$ 12|13|
16|1921|22|
20|2114|15|
18|2116 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 5,
$A_{14}$: 8, $A_{27}$: 16;$A_{12}$ $M_1$ 5|7|
9|10|
17|2020|20|
21|20|
21|2113|15|
17|18|
25|285 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5;$A_{31}$ $M_2$ 6|8|
9|13|
16|18|1922|21|
20|21|
21|21|2013|15|
16|20|
23|25|
269 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5, $A_{31}$: 9;$A_{24}$ $M_1$ 10|17|
2020|24|
2416|23|
2610 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16, $A_{25}$: 18,
$A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5, $A_{13}$: 8,
$A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17, $A_{5}$: 4,
$A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12, $A_{22}$: 14,
$A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6, $A_{14}$: 8, $A_{27}$: 16,
$A_{12}$: 5, $A_{31}$: 9, $A_{24}$: 10;
下载: 导出CSV
表 5 本文算法调度产品$A$过程(续表 4)
Table 5 Scheduling the product $A$ by the algorithm proposed (continued Table 4)
工序号 加工设备 准调度时间点 试调度方案加工总时间 后续工序静态调度时间 确定调度时间点 当前方案中每个工序调度时间点 $A_{30}$ $M_3$ 14|18 20|20 16|20 14 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 5, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5, $A_{31}$: 9,
$A_{24}$: 10, $A_{30}$: 14;$A_{6}$ $M_3$ 5|7|
10|13|
16|1820|20|
21|20|
21|206|8|
11|14|
17|195 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 6, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5, $A_{31}$: 9,
$A_{24}$: 10, $A_{30}$: 14, $A_{6}$: 5;$A_{32}$ $M_3$ 13|16|18 20|21|20 14|17|19 13 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 6, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5, $A_{31}$: 9,
$A_{24}$: 10, $A_{30}$: 14, $A_{6}$: 5,
$A_{32}$: 13;$A_{33}$ $M_4$ 16|19|
2020|21|
2117|20|
2116 $A_{1}$: 0, $A_{2}$: 2, $A_{10}$: 6, $A_{11}$: 8,
$A_{18}$: 9, $A_{15}$: 10, $A_{21}$: 13, $A_{26}$: 16,
$A_{25}$: 18, $A_{28}$: 19, $A_{3}$: 2, $A_{9}$: 5,
$A_{13}$: 8, $A_{16}$: 10, $A_{23}$: 14, $A_{29}$: 17,
$A_{5}$: 4, $A_{7}$: 5, $A_{17}$: 8, $A_{19}$: 12,
$A_{22}$: 14, $A_{20}$: 17, $A_{4}$: 2, $A_{8}$: 6,
$A_{14}$: 8, $A_{27}$: 16, $A_{12}$: 5, $A_{31}$: 9,
$A_{24}$: 10, $A_{30}$: 14, $A_{6}$: 5, $A_{32}$: 13,
$A_{33}$: 16;
下载: 导出CSV
-
[1] 王大志, 刘士新, 郭希旺.求解总拖期时间最小化流水车间调度问题的多智能体进化算法.自动化学报, 2014, 40 (3):548-555 http://www.aas.net.cn/CN/abstract/abstract18320.shtmlWang Da-Zhi, Liu Shi-Xin, Guo Xi-Wang. A multi-agent evolutionary algorithm for solving total tardiness permutation flow-shop scheduling problem. Acta Automatica Sinica, 2014, 40 (3):548-555 http://www.aas.net.cn/CN/abstract/abstract18320.shtml [2] 黄敏, 付亚平, 王洪峰, 朱兵虎, 王兴伟.设备带有恶化特性的作业车间调度模型与算法.自动化学报, 2015, 41(3):551-558 http://www.aas.net.cn/CN/abstract/abstract18633.shtmlHuang Min, Fu Ya-Ping, Wang Hong-Feng, Zhu Bing-Hu, Wang Xing-Wei. Job-shop scheduling model and algorithm with machine deterioration. Acta Automatica Sinica, 2015, 41 (3):551-558 http://www.aas.net.cn/CN/abstract/abstract18633.shtml [3] 王圣尧, 王凌, 许烨, 周刚.求解混合流水车间调度问题的分布估计算法.自动化学报, 2012, 38 (3):437-443 http://www.aas.net.cn/CN/abstract/abstract17695.shtmlWang Sheng-Yao, Wang Ling, Xu Ye, Zhou Gang. An estimation of distribution algorithm for solving hybrid flow-shop scheduling problem. Acta Automatica Sinica, 2012, 38 (3):437-443 http://www.aas.net.cn/CN/abstract/abstract17695.shtml [4] 贾文友, 江志斌, 李友.面向产品族优化时间窗下可重入批处理机调度.机械工程学报, 2015, 51 (12):192-201 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201512031&dbname=CJFD&dbcode=CJFQJia Wen-You, Jiang Zhi-Bin, Li You. Family-oriented to optimize scheduling problem of re-entrant batch processing machine with due window. Journal of Mechanical Engineering, 2015, 51 (12):192-201 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201512031&dbname=CJFD&dbcode=CJFQ [5] 张洁, 张朋, 刘国宝.基于两阶段蚁群算法的带非等效并行机的作业车间调度.机械工程学报, 2013, 49 (6):136-144 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201306020&dbname=CJFD&dbcode=CJFQZhang Jie, Zhang Peng, Liu Guo-Bao. Two-stage ant colony algorithm based job shop scheduling with unrelated parallel machines. Journal of Mechanical Engineering, 2013, 49 (6):136-144 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201306020&dbname=CJFD&dbcode=CJFQ [6] 羌磊, 肖田元.应用扩展贝叶斯进化算法求解混流装配调度问题.计算机集成制造系统, 2007, 13 (2):317-322 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjj200702017&dbname=CJFD&dbcode=CJFQQiang Lei, Xiao Tian-Yuan. Model extended BOA to solve hybrid assembly scheduling problems. Computer Integrated Manufacturing Systems, 2007, 13 (2):317-322 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjj200702017&dbname=CJFD&dbcode=CJFQ [7] 汪浩祥, 严洪森, 汪峥.知识化制造环境中基于双层Q学习的航空发动机自适应装配调度.计算机集成制造系统, 2014, 20(12):3000-3010 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjj201412010&dbname=CJFD&dbcode=CJFQWang Hao-Xiang, Yan Hong-Sen, Wang Zheng. Adaptive assembly scheduling of aero-engine based on double-layer Q-learning in knowledgeable manufacturing. Computer Integrated Manufacturing Systems, 2014, 20 (12):3000-3010 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjj201412010&dbname=CJFD&dbcode=CJFQ [8] 谢志强, 刘胜辉, 乔佩利.基于ACPM和BFSM的动态Job-Shop调度算法.计算机研究与发展, 2003, 40 (7):977-983 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jfyz200307011&dbname=CJFD&dbcode=CJFQXie Zhi-Qiang, Liu Sheng-Hui, Qiao Pei-Li. Dynamic job-shop scheduling algorithm based on ACPM and BFSM. Journal of Computer Research and Development, 2003, 40 (7):977-983 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jfyz200307011&dbname=CJFD&dbcode=CJFQ [9] 谢志强, 杨静, 杨光, 谭光宇.可动态生成具有优先级工序集的动态Job-Shop调度算法.计算机学报, 2008, 31 (3):502-508 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200803017&dbname=CJFD&dbcode=CJFQXie Zhi-Qiang, Yang Jing, Yang Guang, Tan Guang-Yu. Dynamic job-shop scheduling algorithm with dynamic set of operation having priority. Chinese Journal of Computers, 2008, 31 (3):502-508 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200803017&dbname=CJFD&dbcode=CJFQ [10] 谢志强, 杨静, 周勇, 张大力, 谭光宇.基于工序集的动态关键路径多产品制造调度算法.计算机学报, 2011, 34(2):406-412 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx201102020&dbname=CJFD&dbcode=CJFQXie Zhi-Qiang, Yang Jing, Zhou Yong, Zhang Da-Li, Tan Guang-Yu. Dynamic critical paths multi-product manufacturing scheduling algorithm based on operation set. Chinese Journal of Computers, 2011, 34 (2):406-412 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx201102020&dbname=CJFD&dbcode=CJFQ [11] 谢志强, 辛宇, 杨静.基于设备空闲事件驱动的综合调度算法.机械工程学报, 2011, 47 (11):139-147 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201111021&dbname=CJFD&dbcode=CJFQXie Zhi-Qiang, Xin Yu, Yang Jing. Integrated scheduling algorithm based on event driven by machines' idle. Journal of Mechanical Engineering, 2011, 47 (11):139-147 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jxxb201111021&dbname=CJFD&dbcode=CJFQ [12] 谢志强, 辛宇, 杨静.可回退抢占的设备驱动综合调度算法.自动化学报, 2011, 37 (11):1332-1343 http://www.aas.net.cn/CN/abstract/abstract17623.shtmlXie Zhi-Qiang, Xin Yu, Yang Jing. Machine-driven integrated scheduling algorithm with rollback-preemptive. Acta Automatica Sinica, 2011, 37 (11):1332-1343 http://www.aas.net.cn/CN/abstract/abstract17623.shtml [13] Xie Z Q, Hao S Z, Ye G J, Tan G Y. A new algorithm for complex product flexible scheduling with constraint between jobs. Computers and Industrial Engineering, 2009, 57 (3):766-772 doi: 10.1016/j.cie.2009.02.004 [14] Xie Z Q, Yang J, He Y J, Li Z M. An algorithm of simple multi-product scheduling problem with no-wait constraint between operations. Advanced Materials Research, 2010, 129-131:902-907 doi: 10.4028/www.scientific.net/AMR.129-131 [15] Xie Z Q, Gui Z Y, Yang J. Integrated scheduling algorithm based on dynamic essential short path by device driver. Journal of Information and Computer Science, 2013, 10 (4):1075-1084 doi: 10.12733/issn.1548-7741 [16] Xie Z Q, Yang J, He Y J, Ye G J. Dynamic integrated scheduling algorithm of complex multi-products with identical machines. Advanced Materials Research, 2010, 129-131:897-901 doi: 10.4028/www.scientific.net/AMR.129-131 [17] Xie Z Q, He Y J, Liu C H, Yang J. Study on data storage of dynamic integrated scheduling. Procedia Engineering, 2012, 29:4017-4024 doi: 10.1016/j.proeng.2012.01.612 [18] Xie Z Q, Wang P, Gui Z Y, Yang J. Integrated scheduling algorithm based on dynamic essential short path. Advances in Intelligent and Soft Computing. 2012, 169:709-715 doi: 10.1007/978-3-642-30223-7 -








计量
- 文章访问数: 2919
- HTML全文浏览量: 368
- PDF下载量: 948
- 被引次数: 0
