

Fuzzy Partical Swarm Optimization Based on Filled Function and Transformation Function
-
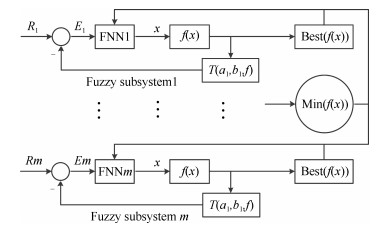
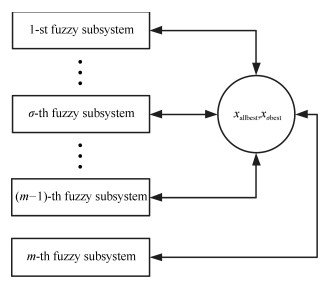
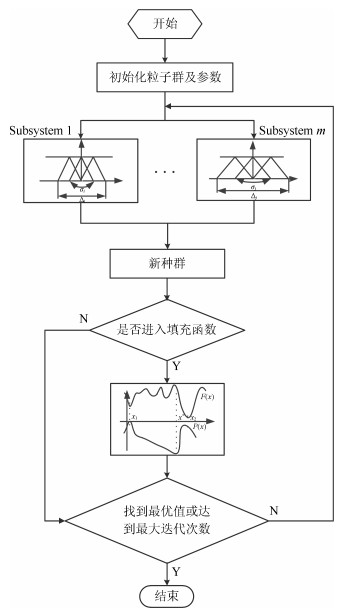
摘要: 本文提出了一种基于变换函数与填充函数的模糊粒子群优化算法(Fuzzy partical swarm optimization based on filled function and transformation function,FPSO-TF).以基于不同隶属度函数的多回路模糊控制系统为基础,进一步结合变换函数与填充函数,使该算法减少了陷入局部最优的可能,又可以跳出局部极小值点至更小的点,快速高效地搜索到全局最优解.最后采用基准函数对此算法进行测试,并与几种不同类型的改进算法进行对比分析,验证了此算法的有效性与优越性.Abstract: A fuzzy partical swarm optimization (PSO) based on filled function and transformation function (FPSO-TF) is proposed. Based on the multi-loop fuzzy controlsystem with different membership function the algorithm combines transformation function and filled function to reduce the chances of falling into local minima, and jumping out of a local minimum. It is fast and efficient to search for the global optimal solution. To compare the proposed algorithm with several different types of improved algorithms, a Matlab simulation is given. The result also verifies the effectiveness of the algorithm.1) 本文责任编委 张毅
-
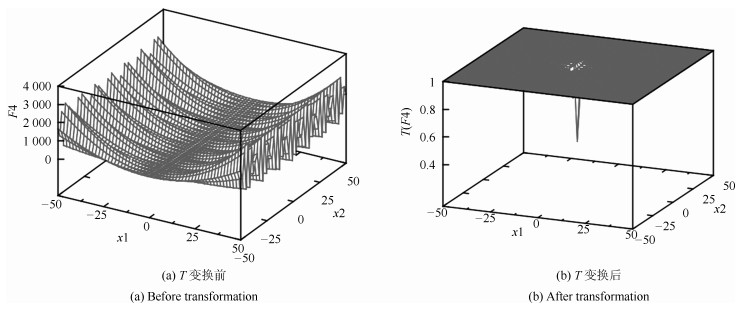
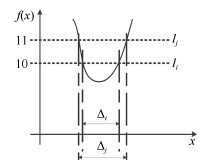
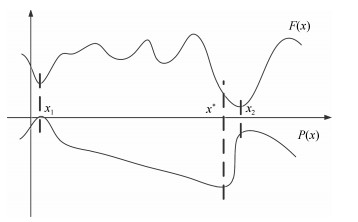
图 4 $F4$变换前后的曲线图即$F4$和$T(1,0,F4)$
Fig. 4 The curves of $F4$ before and after transformation: $F4$ and $T(1,0,F4)$
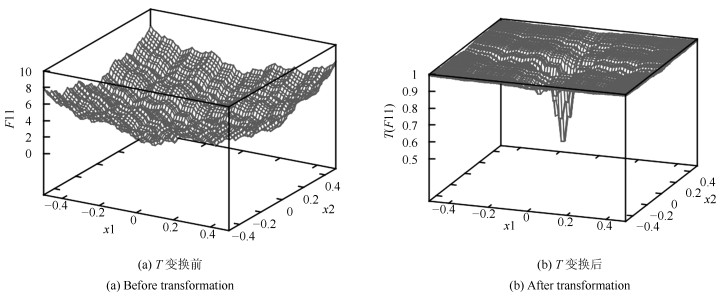
图 5 $F11$变换前后的曲线图即$F11$和$T(1,0,F11)$
Fig. 5 The stereogram of $F11$ before and after transformation: $F11$ and $T(1,0,F11)$
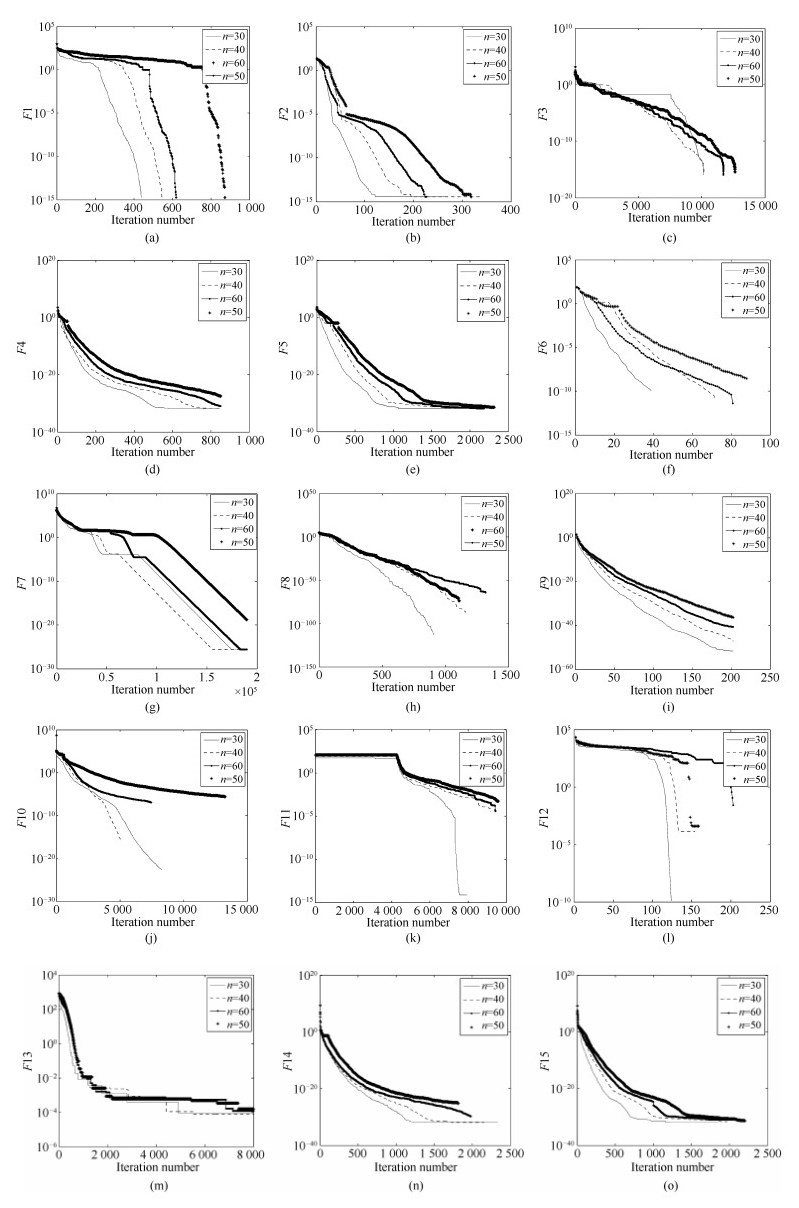
图 11 (a) $F$1, (b) $F$2, (c) $F$3, (d) $F$4, (e) $F$5, (f) $F$6 (这里曲线在每次迭代时都加78.33233140745), (g) $F$7, (h) $F$8, (i) $F$9, (j) $F$10, (k) $F$11, (l) $F$12 (这里曲线在每次迭代时都加0.000381827), (m) $F$13, (n) $F$14和(o) $F$15的收敛曲线
Fig. 11 Convergence progress of the FPSO-TF on (a) $F$1, (b) $F$2, (c) $F$3, (d) $F$4, (e) $F$5, (f) $F$6 (where curves are obtained by subtracting 78.33233140745 from the true value of $F$6 for each iteration), (g) $F$7, (h) $F$8, (i) $F$9, (j) $F$10, (k) $F$11, (l) $F$12 (where curves are obtained by subtracting 0.000381827 from the true value of $F$12 for each iteration), (m) $F13$, (n) $F14$ and (o) $F15$
表 1 测试函数
Table 1 Test functions
测试函数 维数 可行域 最优值/最优点 $f_1=\sum\limits_{i=1}^n(x_i^2-10\cos(2\pi x_i)+10)$ 30 $[-5.12,5.12]^D$ 0.0/0, 0, $\cdots$, 0 $f_2=-20\exp(-0.2\sqrt{\sum\limits_{i=1}^n\frac{x_i^2}{n}})-\exp(\sum\limits_{i=1}^n\frac{\cos(2\pi x_i)}{n})+20+\exp(1)$ 30 $[-32,32]^D$ 0.0/0, 0, $\cdots$, 0 $f_3=\sum\limits_{i=1}^n\frac{x_i^2}{4\,000}-\prod\limits_{i=1}^n\cos(\frac{x_i}{\sqrt{i}})+1$ 30 $[-600,600]^D$ 0.0/0, 0, $\cdots$, 0 $f_4=\frac{\pi}{n}(10\sin^2(\pi y_1)+(y_n-1)^2+\sum\limits_{i=1}^{n-1}(y_i-1)^2(1+10\sin^2(\pi y_{i+1}))) y_i=1+\frac{(1+x_i)}{4}$ 30 $[-50,50]^D$ $ 0.0/-1,\ -1, \cdots,\ -1 $ $ f_5=\frac{1}{10}(\sin^2(3\pi x_1)+(x_n-1)^2(1+\sin^2(2\pi x_n))+ \quad \sum\limits_{i=1}^{n-1}(x_n-1)^2(1+\sin^2(3\pi x_{i+1})))$ 30 $[-50,50]^D$ 0.0/1, 1, $\cdots$, 1 $f_6=\sum\limits_{i=1}^n{\frac{(x_i^4-16x_i^2+5x_i)}{n}}$ 30 $[-5,5]^D$ $-78.3323/-2.90353,-2.90353, \cdots,-2.90353$ $f_7=\sum\limits_{i=1}^{n-1}\left({100(x_i^2-x_{i+1})^2+(x_i-1)^2}\right)$ 30 $[-5,10]^D$ 0.0/1, 1, $\cdots$, 1 $f_8=\sum\limits_{i=1}^nx_i^2$ 30 $[-100,100]^D$ 0.0/0, 0, $\cdots$, 0 $f_9=\sum\limits_{i=1}^nx_i^4$ 30 $[-1.28,1.28]^D$ 0.0/0, 0, $\cdots$, 0 $f_{10}=\sum\limits_{i=1}^n\left[{\sum\limits_{j=1}^i x_j}\right]^2$ 30 $[-100,100]^D$ 0.0/0, 0, $\cdots$, 0 $f_{11}=\sum\limits_{i=1}^n\left[\sum\limits_{k=0}^{k\max}\left(a^k\cos(2\pi b^k(x_i+0.5))\right)\right]- \quad n\sum\limits_{k=0}^{k\max}\left(a^k\cos(2\pi b^k0.5)\right) a=0.5,b=3,k\max=20$ 30 $[-0.5,0.5]^D$ 0.0/0, 0, $\cdots$, 0 $f_{12}=418.9829\times n-\sum\limits_{i=1}^nx_i\sin(\sqrt{|x_i|})$ 30 $[-500,500]^D$ 0.000381827/420.97, 420.97, $\cdots$, 420.97 $f_{13}=\sum\limits_{i=1}^ni\times x_i^4+{\rm Random}(0,1)$ 30 $[-1.28,1.28]^D$ 0.0/0, 0, $\cdots$, 0 $f_{14}=\frac{\pi}{n}\Big(10\sin^2(\pi y_1)+(y_n-1)^2+\sum\limits_{i=1}^{n-1}(y_i-1)^2(1+ \quad 10\sin^2(\pi y_{i+1}))\Big) +\sum\limits_{i=1}^nu_i(x_i,10,100,4), \\ y_i=1+\frac{1+x_i}{4} u_i(x_i,a,k,m)=\left\{\!\!\!\begin{array}{ll} k(x_i-a)^m, & x_i>a \\ 0, &-a \leq x_i \leq a \\ k(-x_i-a)^m, & x_i <a \end{array}\right. $ 30 $[-50,50]^D$ $0.0/-1,-1,\cdots,-1 $ $f_{15}=\frac{1}{10}(\sin^2(3\pi x_1)+(x_n-1)^2(1+\sin^2(2\pi x_n))+\quad \sum\limits_{i=1}^{n-1}(x_n-1)^2(1+\sin^2(3\pi x_{i+1})))+\sum\limits_{i=1}^nu_i(x_i,5,100,4)$ 30 $[-50,50]^D$ 0.0/1, 1, $\cdots$, 1  下载: 导出CSV
下载: 导出CSV
表 2 参数初值
Table 2 The initial values of the parameters
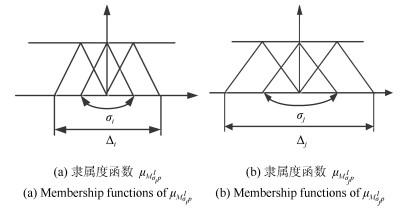
测试函数 $d_1/d_2/d_3/d_4/d_5$ $\eta_1/\eta_2/\eta_3/\eta_4$ $a_1/R/N_\sigma$ $MN/TT/FMN$ $F1 $ 1E-6/1E-18/30/1/12 2E-2/1E-4/1E-4/0.1 1E-3/-1/6 1 000/2 000/100 $F2 $ 1E-4/1E-26/40/0.1/30 5E-3/1E-4/1E-5/0.1 1E-4/-1/5 5 000/8 000/100 $F3 $ 1E-6/1E-15/25/0.3/18 1E-4/1E-3/1E-3/1E-2 1E-3/-1/3 15 000/9 000/60 $F4$ 1E-4/1E-18/35/0.2/15 1.6/0.1/1E-5/0.1 1E-4/-1/5 12 000/20 000/100 $F5 $ 1E-4/1E-18/35/0.05/18 1.4/1E-2/1E-5/0.1 1E-3/0/3 8 000/20 000/100 $F6 $ 1E-5/1E-11/12/1/13 0.6/1E-4/1E-3/1E-2 1E-3/-1/5 1 000/2 000/60 $F7 $ 1E-15/1E-16/19/0.2/10 1/1E-3/1E-4/1E-3 1E-3/-1/4 190 000/40 000/100 $F8 $ 1E-5/1E-24/35/1/30 6E-2/1E-3/1E-4/6E-3 1E-4/-1/3 30 000/4 000/100 $F9$ 1E-3/1E-18/25/1/25 3E-2/1E-4/1E-4/1E-3 1E-3/-1/5 8 000/5 000/60 $F10$ 1E-9/1E-21/35/1/30 0.6/0.3/1E-4/0.8 1E-4/-1/5 50 000/250 000/130 $F11$ 1E-9/1E-20/25/1/25 3E-3/1E-4/1E-3/1E-3 1E-4/-1/5 20 000/18 000/100 $F12 $ 1E-6/1E-4/10/1/14 6E-4/1E-3/1E-5/0.1 1E-4/-1/5 300/1 000/60 $F13$ 1E-15/1E-10/20/1/11 1/1E-3/1E-4/1E-2 1E-4/-1/10 80 000/6 000/60 $F14 $ 1E-4/1E-18/35/0.2/15 1.5/0.1/1E-5/0.1 1E-4/-1/3 12 000/20 000/100 $F15 $ 1E-4/1E-18/35/0.05/18 1.4/0.01/1E-5/0.1 1E-4/0/3 10 000/20 000/100
下载: 导出CSV
表 3 仿真结果
Table 3 Results of simulation
Functions Average value Best value Worst value Confidence interval N/30 CPU times (s) SA $F1 $ 0 0 0 0±0 30/30 12.7 1E-15 $F2$ 2.37E-16 0 3.55E-15 2.37E-16±2.90724E-31 30/30 58.2 1E-10 $F3 $ 0 0 0 0±0 30/30 42.7 1E-15 $F4$ 1.57E-32 1.57E-32 1.60E-32 1.57E-32±1.5E-69 30/30 119 1E-15 $F5$ 1.35E-32 1.35E-32 1.35E-32 1.35E-32±2.5E-95 30/30 118 1E-15 $F6$ -78.33233141 -78.33233141 -78.33233141 -78.33233141±1.9E-24 30/30 7.3 1E-7 $F7 $ 3.23E-22 2.61E-26 4.39E-21 3.23E-22±3.66E-43 30/30 205 1E-15 $F8 $ 1.21E-78 2.91E-221 3.60E-77 1.21E-78±1.54E-155 30/30 42.8 1E-15 $F9$ 1.64E-52 1.94E-53 4.59E-52 1.64E-52±5.11E-105 30/30 18.2 1E-15 $F10$ 2.74E-22 3.35E-32 1.11E-21 2.74E-22±5.12E-44 30/30 219 1E-15 $F11$ 2.75E-07 0 7.87E-06 2.75E-07±7.39168E-13 30/30 1 816 1E-5 $F12$ 3.82E-04 3.82E-04 3.82E-04 3.82E-04±2.71969E-38 30/30 4.1 1E-8 $F13$ 6.36E-04 3.03E-05 2.54E-03 6.36E-04±1.7E-07 30/30 30.9 1E-2 $F14$ 1.57E-32 1.57E-32 1.6E-32 1.57E-32±1.55E-69 30/30 126 1E-15 $F15$ 1.35E-32 1.35E-32 1.35E-32 1.35E-32±2.5E-95 30/30 119 1E-15
下载: 导出CSV
表 4 与现有算法的结果比较
Table 4 Comparison with other algorithms
Functions FPSO-TF FEP OGA/Q CMA-ES JADE OLPSO-L OLPSO-G $F1$ Mean 0 4.6E-2 0 1.76E+2 0 0 1.07 SD 0 1.2E-2 0 13.89 0 0 0.99 Rank 1 2 1 4 1 1 3 t-test - -19.17 0 -63.36 0 0 -8.5 $F2$ Mean 2.37E-16 1.8E-2 4.4E-16 12.124 4.4E-15 4.14E-15 7.98E-015 SD 2.90724E-31 2.1E-3 3.99E-17 9.28 0 0 2.03E-15 Rank 1 6 2 7 4 3 5 t-test - -42.8 -5 -6.5 -7.2E+16 -6.5+16 -19 $F3$ Mean 0 1.6E-2 0 9.59E-16 2.E-4 0 4.8E-3 SD 0 2.2E-2 0 3.5E-16 1.4E-3 0 8.63E-3 Rank 1 5 1 2 3 1 4 t-test - -3.64 0 -13.7 -0.7 0 -2.7 $F7$ Mean 3.23E-22 5.06 0.75 2.33E-15 0.32 1.26 21.52 SD 3.66E-43 5.87 0.11 7.7E-16 1.1 1.4 29.92 Rank 1 6 4 2 3 5 7 t-test - -4.26 -34.1 -15.1 -1.45 -4.5 -1.2 $F8$ Mean 1.21E-78 5.7E-4 0 4.56E-16 1.3E-54 1.11E-38 4.1E-54 SD 1.54E-155 1.3E-4 0 1.13E-16 9.2E-54 1.3E-38 6.32E-54 Rank 2 7 1 5 3 6 4 t-test - -21.9 0 -20.4 -0.7 --4.3 -3.2 $F12$ Mean 3.82E-4 14.98 3.03E-2 3.15E+3 7.1 3.82E-4 3.84E+2 SD 2.71969E-38 52.6 6.45E-4 5.79E+2 28 0 2.17E+2 Rank 1 4 2 6 3 1 5 t-test - -1.4 -234.8 -27.2 -1.3 0 -8.8 $F13$ Mean 6.36E-4 7.6E-3 6.3E-3 5.92E-2 6.8E-4 1.64E-2 1.16E-2 SD 1.7E-7 2.6E-3 4.07E-4 1.73E-2 2.5E-4 3.25E-3 4.1E-3 Rank 1 4 3 7 2 6 5 t-test - -13.5 -71.3 -16.9 -0.88 -26.3 -12.8 $F14$ Mean 1.57E-32 9.2E-6 6.02E-6 1.63E-15 1.6E-32 1.57E-32 1.57E-32 SD 1.55E-69 3.6E-6 1.16E-6 4.93E-16 5.5E-48 2.79E-48 1.01E-33 Rank 1 5 4 3 2 1 1 t-test - -12.8 -1.65 -16 -2.7E+18 0 0 $F15$ Mean 1.35E-32 1.6E-4 1.87E-4 1.71E-15 1.4E-32 1.35E-32 4.39E-4 SD 2.5E-95 7.3E-5 2.62E-5 3.7E-16 1.1E-47 5.6E-48 2.2E-3 Rank 1 4 5 3 2 1 6 t-test - -10 -35.6 -23 -0.23E+15 0 -0.99 Ave.rank 1.1 4.7 2.5 4 2.6 4.9 5.6 Final rank 1 5 2 4 3 6 7
下载: 导出CSV
-
[1] Kennedy J, Eberhart R. Particle swarm optimization. In:Proceedings of the 1995 IEEE International Conference on Neural Network. Perth, Australia:IEEE, 1995. 1942-1948 [2] 吕强, 刘士荣, 邱雪娜.基于信息素机制的粒子群优化算法的设计与实现.自动化学报, 2009, 35(11):1410-1419 http://www.aas.net.cn/CN/Y2009/V35/I11/1410Lv Qiang, Liu Shi-Rong, Qiu Xue-Na. Design and realization of particle swarm optimization based on pheromone mechanism. Acta Automatica Sinica, 2009, 35(11):1410-1419 http://www.aas.net.cn/CN/Y2009/V35/I11/1410 [3] Wang Y P, Dang C Y. An evolutionary algorithm for global optimization based on level-set evolution and Latin squares. IEEE Transactions on Evolutionary Computation, 2007, 11(5):579-595 doi: 10.1109/TEVC.2006.886802 [4] Lu B Q, Gao G Q, Lu Z Y. The block diagram method for designing the particle swarm optimization algorithm. Journal of Global Optimization, 2012, 52(4):689-710 doi: 10.1007/s10898-011-9699-9 [5] Zhan Z H, Zhang J, Li Y, Shi Y H. Orthogonal learning particle swarm optimization. IEEE Transactions on Evolutionary Computation, 2011, 15(6):832-847 doi: 10.1109/TEVC.2010.2052054 [6] Ustundag B, Eksin I, Bir A. A new approach to global optimization using a closed loop control system with fuzzy logic controller. Advances in Engineering Software, 2002, 33(6):309-318 doi: 10.1016/S0965-9978(02)00036-4 [7] Lee J, Chiang H D. A dynamical trajectory-based methodology for systematically computing multiple optimal solutions of general nonlinear programming problems. IEEE Transactions on Automatic Control, 2004, 49(6):888-889 doi: 10.1109/TAC.2004.829603 [8] Motee N, Jadbabaie A. Distributed multi-parametric quadratic programming. IEEE Transactions on Automatic Control, 2009, 54(10):2279-2289 doi: 10.1109/TAC.2009.2014916 [9] Nedic A. Asynchronous broadcast-based convex optimization over a network. IEEE Transactions on Automatic Control, 2011, 56(6):1337-1351 doi: 10.1109/TAC.2010.2079650 [10] Necoara I. Random coordinate descent algorithms for multi-agent convex optimization over networks. IEEE Transactions on Automatic Control, 2013, 58(8):2001-2012 doi: 10.1109/TAC.2013.2250071 [11] 李宝磊, 施心陵, 苟常兴, 吕丹桔, 安镇宙, 张榆锋.多元优化算法及其收敛性分析.自动化学报, 2015, 41(5):949-959 http://www.aas.net.cn/CN/Y2015/V41/I5/949Li Bao-Lei, Shi Xin-Ling, Gou Chang-Xing, Lv Dan-Ju, An Zhen-Zhou, Zhang Yu-Feng. Multivariant optimization algorithm and its convergence analysis. Acta Automatica Sinica, 2015, 41(5):949-959 http://www.aas.net.cn/CN/Y2015/V41/I5/949 [12] 陆志君, 安俊秀, 王鹏.基于划分的多尺度量子谐振子算法多峰优化.自动化学报, 2016, 42(2):235-245 http://www.aas.net.cn/CN/Y2016/V42/I2/235Lu Zhi-Jun, An Jun-Xiu, Wang Peng. Partition-based MQHOA for multimodal optimization. Acta Automatica Sinica, 2016, 42(2):235-245 http://www.aas.net.cn/CN/Y2016/V42/I2/235 [13] 陈振兴, 严宣辉, 吴坤安, 白猛.融合张角拥挤控制策略的高维多目标优化.自动化学报, 2015, 41(6):1145-1158 http://www.aas.net.cn/CN/abstract/abstract18689.shtmlChen Zhen-Xing, Yan Xuan-Hui, Wu Kun-An, Bai Meng. Many-objective optimization integrating open angle based congestion control strategy. Acta Automatica Sinica, 2015, 41(6):1145-1158 http://www.aas.net.cn/CN/abstract/abstract18689.shtml [14] Ma S Z, Yang Y J, Liu H Q. A parameter free filled function for unconstrained global optimization. Applied Mathematics and Computation, 2010, 215(10):3610-3619 doi: 10.1016/j.amc.2009.10.057 [15] Gao C L, Yang Y J, Han B S. A new class of filled functions with one parameter for global optimization. Computers & Mathematics with Applications, 2011, 62(6):2393-2403 https://www.researchgate.net/publication/220511247_A_new_class_of_filled_functions_with_one_parameter_for_global_optimization -

 下载:
下载:


计量
- 文章访问数: 2676
- HTML全文浏览量: 460
- PDF下载量: 811
- 被引次数: 0
