

-
摘要: 针对推荐系统中普遍存在的数据稀疏和冷启动等问题,本文结合用户自身评分与用户的社会信任关系构建推荐模型,提出了一种基于信任关系传递的社会网络推荐算法(Trust transition recommendation model,TTRM).该方法首先通过计算信任网络中节点的声望值与偏见值来发现信任网络中的不可信节点,并通过对其评分权重进行弱化来减轻其对信任网络产生的负面影响.其次,算法又利用朋友的信任矩阵对用户自身的特征向量进行修正,解决了用户特征向量的精准构建及信任传递问题.同时为了实现修正误差的最小化,算法利用推荐特性进行用户相似度计算并通过带有社会正则化约束的矩阵分解技术实现社会网络推荐.实验结果表明,TTRM算法较传统的社会网络推荐算法在性能上具有显著提高.Abstract: To deal with the data sparsity and cool boot problem, a new method by means of trust relations called trust transition recommendation model (TTRM), as well as user rating and users' social trust network, is proposed. The first step of the methed is to spot the untrustworthy nodes in the trust network through their reputation and deviation values and abate their negative effects on trust network by weakening their rating weights. Secondly, the method revises the users' feature vector from their friends' trust matrix to solve the problems like users' feature vector accuracy establishment and trust transmission. Meanwhile, in order to minimize the round-off error, it calculates the similarity of users based on the recommendation features and realizes social network recommendation through matrix factorization with social regularization constraints. The results of experiments of TTRM on public dataset reveal that the new recommendation performare has been greatly improved compared to the traditional collaborative recommendation.
-
Key words:
- Social network /
- recommendation /
- trust /
- matrix factorization /
- regulation
1) 本文责任编委 赵铁军 -
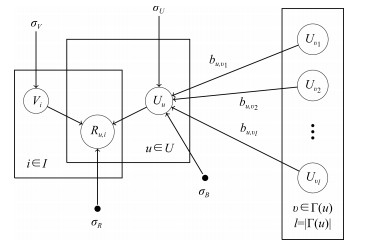
图 2 基于用户信任关系推荐的概率图模型
Fig. 2 Graphic model for recommendation based on trust relationship
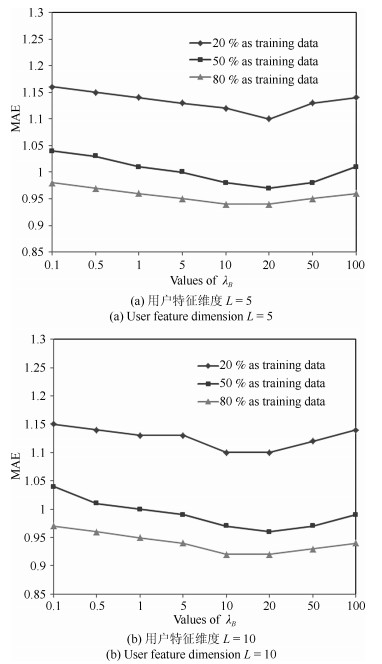
图 5 不同维度与不同训练集比例下参数$\lambda_B$的MAE结果
Fig. 5 Effect experiment of parameter $\lambda_B$ under different training percent

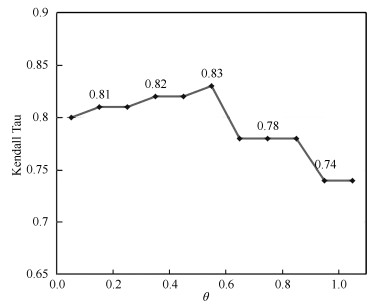
图 6 参数$\alpha$的影响实验(维度$=10$)
Fig. 6 Impact experiment of parameter (dimensionality$=10$)
节点1 节点2 节点3 偏见值(Bias) 0.13 0.08 -0.14 声望值(Prestige) -0.33 0.73 -1.00  下载: 导出CSV
下载: 导出CSV
迭代次数 节点1 节点2 节点3 偏见值 声望值 偏见值 声望值 偏见值 声望值 0 -1.00 -1.00 -1.00 -1.00 -1.00 -1.00 1 0.10 0.00 -0.25 0.8 -0.25 0.00 2 0.12 -0.30 0.01 0.75 -0.16 -0.75 3 0.13 -0.33 0.08 0.73 -0.15 -1.00 4 0.13 -0.33 0.08 0.73 -0.14 -1.00 5 0.13 -0.33 0.08 0.73 -0.14 -1.00
下载: 导出CSV
表 3 不同用户评价数量下各推荐算法对比结果
Table 3 Comparative results of different algorithms under different user evaluation number
评价数量 0 1~5 6~10 11~20 21~40 4~80 81~160 161~320 321~640 $>640$ 90% Trust 1.79 1.25 1.08 1.02 1.00 0.98 0.95 0.92 0.90 0.88 STE 1.69 1.18 1.03 1.00 0.99 0.97 0.95 0.92 0.90 0.88 SocialMF 1.32 1.12 1.01 0.98 0.93 0.91 0.90 0.88 0.86 0.85 TTRM 1.07 1.02 0.95 0.90 0.88 0.86 0.85 0.84 0.83 0.82 80% Trust 1.85 1.28 1.09 1.04 1.02 0.99 0.97 0.95 0.92 0.90 STE 1.68 1.15 1.05 1.03 1.00 0.96 0.95 0.92 0.91 0.89 SocialMF 1.23 1.10 1.02 0.98 0.97 0.94 0.93 0.91 0.90 0.88 TTRM 1.09 1.05 0.95 0.94 0.93 0.92 0.91 0.90 0.88 0.86 50% Trust 1.89 1.32 1.13 1.09 1.06 1.03 1.01 0.99 0.94 0.92 STE 1.75 1.25 1.10 1.07 1.03 0.99 0.97 0.95 0.88 0.86 SocialMF 1.35 1.15 1.08 1.02 1.00 0.98 0.95 0.93 0.85 0.85 TTRM 1.12 1.10 0.98 0.97 0.94 0.93 0.92 0.91 0.89 0.85 20% Trust 1.98 1.30 1.13 1.12 1.11 1.11 1.09 1.04 1.04 1.03 STE 1.78 1.23 1.10 1.08 1.07 1.06 1.05 1.02 1.02 1.01 SocialMF 1.42 1.21 1.09 1.05 1.01 1.02 0.98 0.94 0.89 0.89 TTRM 1.13 1.10 1.00 0.98 0.97 0.96 0.95 0.94 0.88 0.88
下载: 导出CSV
表 4 各推荐算法的性能对比结果
Table 4 Performance comparison results of different recommendation algorithm
UserMean ItemMean PMF NMF Trust SocialMF TTRM 90% MAE 0.913 0.877 0.865 0.871 0.832 0.802 0.789 RMSE 1.169 1.238 1.154 1.162 1.101 1.051 1.021 URMSE 1.740 1.652 1.156 1.142 1.132 0.937 0.902 80% MAE 0.929 0.891 0.889 0.895 0.854 0.813 0.801 RMSE 1.182 1.259 1.177 1.183 1.126 1.053 1.028 URMSE 1.802 1.756 1.215 1.192 1.168 0.988 0.875 50% MAE 0.932 0.955 0.923 0.921 0.912 0.875 0.832 RMSE 1.192 1.263 1.185 1.193 1.236 1.089 1.092 URMSE 1.820 1.752 1.237 1.214 1.192 1.017 1.002 20% MAE 0.946 0.957 0.932 0.929 0.918 0.904 0.885 RMSE 1.205 1.206 1.185 1.123 1.056 1.094 1.085 URMSE 1.840 1.756 1.255 1.210 1.177 1.036 1.011
下载: 导出CSV
-
[1] Saravanan M, Buveneswari S, Divya S, Ramya V. Bayesian filters for mobile recommender systems. In: Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining. Kaohsiung City, Taiwan, China: IEEE, 2011. 715-721 [2] Yeung K F, Yang Y Y, Ndzi D. A proactive personalised mobile recommendation system using analytic hierarchy process and Bayesian network. Journal of Internet Services and Applications, 2012, 3 (2):195-214 doi: 10.1007/s13174-012-0061-3 [3] 印桂生, 张亚楠, 董宇欣, 韩启龙.基于受限信任关系和概率分解矩阵的推荐.电子学报, 2014, 42 (5):904-911 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=dzxu201405011&dbname=CJFD&dbcode=CJFQYin Gui-Sheng, Zhang Ya-Nan, Dong Yu-Xin, Han Qi-Long. A constrained trust recommendation using probabilistic matrix factorization. Acta Electronica Sinica, 2014, 42 (5):904-911 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=dzxu201405011&dbname=CJFD&dbcode=CJFQ [4] 郭磊, 马军, 陈竹敏.一种信任关系强度敏感的社会化推荐算法.计算机研究与发展, 2013, 50 (9):1805-1813 doi: 10.7544/issn1000-1239.2013.20130449Guo Lei, Ma Jun, Chen Zhu-Min. Trust strength aware social recommendation method. Journal of Computer Research and Development, 2013, 50 (9):1805-1813 doi: 10.7544/issn1000-1239.2013.20130449 [5] Granovetter M S. The strength of weak ties. American Journal of Sociology, 1973, 78 (6):1360-1380 doi: 10.1086/225469 [6] Gilbert E, Karahalios K. Predicting tie strength with social media. In: Proceedings of the 2009 SIGCHI Conference on Human Factors in Computing Systems. New York, NY, USA: ACM, 2009. 211-220 [7] Xiang R J, Neville J, Rogati M. Modeling relationship strength in online social networks. In: Proceedings of the 19th International Conference on World Wide Web. New York, NY, USA: ACM, 2010. 981-990 [8] 张燕平, 张顺, 钱付兰, 张以文.基于用户声誉的鲁棒协同推荐算法.自动化学报, 2015, 41 (5):1004-1012 http://www.aas.net.cn/CN/abstract/abstract18674.shtmlZhang Yan-Ping, Zhang Shun, Qian Fu-Lan, Zhang Yi-Wen. Robust collaborative recommendation algorithm based on user's reputation. Acta Automatica Sinica, 2015, 41 (5):1004-1012 http://www.aas.net.cn/CN/abstract/abstract18674.shtml [9] Golbeck J. Computing and Applying Trust in Web-based Social Networks[Ph. D. dissertation], University of Maryland, USA, 2005 [10] Massa P, Avesani P. Trust metrics on controversial users:balancing between tyranny of the majority. International Journal on Semantic Web and Information Systems, 2007, 3 (1):39-64 doi: 10.4018/IJSWIS [11] Jamali M, Ester M. TrustWalker: a random walk model for combining trust-based and item-based recommendation. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM, 2009. 397-406 [12] Li B Y S, Yeung L F, Yang G K. Pathogen host interaction prediction via matrix factorization. In: Proceedings of the 2014 IEEE International Conference on Bioinformatics and Biomedicine. Belfast, United Kingdom: IEEE, 2014. 357-362 [13] Menon A K, Elkan C. Link prediction via matrix factorization. Machine Learning and Knowledge Discovery in Databases. Berlin Heidelberg: Springer, 2011. 437-452 [14] Ma H, Yang H X, Lyu M R, King I. SoRec: social recommendation using probabilistic matrix factorization. In: Proceedings of the 17th ACM Conference on Information and Knowledge Management. New York, NY, USA: ACM, 2008. 931-940 [15] Tang J L, Hu X, Gao H J, Liu H. Exploiting local and global social context for recommendation. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. New York, NY, USA: ACM 2013. 2712-2718 [16] Ma H, King I, Lyu M R. Learning to recommend with social trust ensemble. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY, USA: ACM, 2009. 203-210 [17] Tang J L, Gao H J, Liu H. mTrust: discerning multi-faceted trust in a connected world. In: Proceedings of the 5th ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM, 2012. 93-102 [18] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks. In: Proceedings of the 4th ACM Conference on Recommender Systems. New York, NY, USA: ACM, 2010. 135-142 [19] Ma H, Zhou D Y, Liu C, Lyu M R, King I. Recommender systems with social regularization. In: Proceedings of the 4th ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM, 2011. 287-296 [20] Xiao R L, Li Y N, Chen H T, Ni Y C, Du X. SRSP-PMF: a novel probabilistic matrix factorization recommendation algorithm using social reliable similarity propagation. Intelligent Computing Theories and Methodologies: Lecture Notes in Computer Science. Switzerland: Springer, 2015. 80-91 [21] Ji K, Sun R Y, Li X, Shu W H. Improving matrix approximation for recommendation via a clustering-based reconstructive method. Neurocomputing, 2016, 173:912-920 doi: 10.1016/j.neucom.2015.08.046 [22] Yu Z, Wang C, Bu J J, Wang X, Wu Y, Chen C. Friend recommendation with content spread enhancement in social networks. Information Sciences, 2015, 309:1102-118 http://www.sciencedirect.com/science/article/pii/s0020025515001772 [23] Kayacan E, Khanesar M A. Gradient descent methods for type-2 fuzzy neural networks. Fuzzy Neural Networks for Real Time Control Applications: Concepts, Modeling and Algorithms for Fast Learning. Amsterdam: Elsevier, 2016. 45-70 [24] Kendall M G. A new measure of rank correlation. Biometrika, 1938, 30 (1-2):81-93 doi: 10.1093/biomet/30.1-2.81 [25] Salakhutdinov R, Mnih A. Probabilistic matrix factorization. In:Advances in Neural Information Processing Systems 20. Cambridge, MA, USA:MIT Press, 2008. 1257-1264 [26] Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401 (6755):788-791 doi: 10.1038/44565 [27] Yahyaoui H, Al-Mutairi A. A feature-based trust sequence classification algorithm. Information Sciences, 2016, 328:455-484 doi: 10.1016/j.ins.2015.08.008 -

 下载:
下载:

计量
- 文章访问数: 2724
- HTML全文浏览量: 540
- PDF下载量: 1306
- 被引次数: 0
