

Analysis and System Design of Multi-convex Hull Stabilization Domain for Double-layered Model Predictive Control System
-
摘要: 针对双层模型预测控制(Model predictive control,MPC)中出现的由于系统状态在动态控制(Dynamic control,DC)过程中超出约束集,导致下层优化不可行的问题,本文在综合控制方法的基础上提出一种新的动态控制策略,引入多包镇定域(Multi-convex hull stabilization domain,MHSD)的概念.通过离线计算多包镇定域,并根据系统每一时刻的实测状态值,在线决定(Dynamic control)层的镇定域以及相应的控制时域,结合变约束思想,保证动态控制过程递归可行,从而有效控制在大范围内变化的系统状态.另外,本文通过设计非线性反馈控制器,扩大了终端不变集和多包镇定域的范围,提高了DC层对稳态目标值的跟踪效果.本文的控制算法可以使得DC层在目标跟踪过程中保证递归可行性,并最大程度地实现无静差跟踪.仿真算例验证了本文算法对稳定系统和不稳定系统都有效.Abstract: In order to solve the feasibility problem in double-layered model predictive control (MPC) caused by some states in dynamic control (DC) that violate the constraints, this paper proposes a new control strategy based on the overall control solution and introduces a new definition multi-convex hull stabilization domain (MHSD). This strategy designs the MHSD off line and then chooses a proper stabilization range online according to the real-time system state. The control horizon of the DC layer can be calculated at the same time. What is more, this paper enlarges the invariant sets and the stabilization domain through designing a nonlinear feedback controller so that the system states varying in a wide range can be controlled and the tracking effect is significantly improved. By using the above algorithm, the control process is recursively feasible and the optimal targets can be tracked precisely. The effectiveness of this method is verified in both stable and unstable systems through two examples.
-
近些年来, 由于多智能体协同控制在编队控制[1]、机器人网络[2]、群集行为[3]、移动传感器[4-5]等方面的广泛应用, 多智能体系统的协同控制问题受到了众多研究者的广泛关注.一致性问题是多智能体系统协同控制领域的一个关键问题, 其目的是通过与邻居之间的信息交换, 使所有智能体的状态达成一致.迄今为止, 对多智能体一致性的研究也已取得了丰硕的成果, 根据多智能体的动力学模型分类, 主要可以将其分为以下4种情形:一阶[6-9]、二阶[10-13]、三阶[14-15]、高阶[16-18].
在实际应用中, 由于CPU处理速度和内存容量的限制, 智能体不能频繁地进行控制以及与其邻居交换信息.因此, 事件触发控制策略作为减少控制次数和通信负载的有效途径, 受到了越来越多的关注.到目前为止, 对事件触发控制机制的研究也取得了很多成果[19-23].Xiao等[19]基于事件触发控制策略, 解决了带有领航者的离散多智能体系统的跟踪问题.通过利用状态测量误差并且基于二阶离散多智能体系统动力学模型, Zhu等[20]提出了一种自触发的控制策略, 该策略使得所有智能体的状态均达到一致. Huang等[21]研究了基于事件触发策略的Lur$'$e网络的跟踪问题.针对不同的领航者-跟随者系统, Xu等[22]提出了3种不同类型的事件触发控制器, 包含分簇式控制器、集中式控制器和分布式控制器, 以此来解决对应的一致性问题.然而, 大多数现有的事件触发一致性成果集中于考虑一阶多智能体系统和二阶多智能体系统, 很少有成果研究三阶多智能体系统的事件触发控制问题, 特别是对于三阶离散多智能体系统, 成果更是少之又少.所以, 设计相应的事件触发控制协议来解决三阶离散多智能体系统的一致性问题已变得尤为重要.
本文研究了基于事件触发控制机制的三阶离散多智能体系统的一致性问题, 文章主要有以下三点贡献:
1) 利用位置、速度和加速度三者的测量误差, 设计了一种新颖的事件触发控制机制.
2) 利用不等式技巧, 分析得到了保证智能体渐近收敛到一致状态的充分条件.与现有的事件触发文献[19-22]不同的是, 所得的一致性条件与通信拓扑的Laplacian矩阵特征值和系统的耦合强度有关.
3) 给出了排除类Zeno行为的参数条件, 进而使得事件触发控制器不会每个迭代时刻都更新.
1. 预备知识
1.1 代数图论
智能体间的通信拓扑结构用一个有向加权图来表示, 记为.其中, $\vartheta = \left\{ {1, 2, \cdots, n} \right\}$表示顶点集, $\varsigma\subseteq\vartheta\times\vartheta$表示边集, 称作邻接矩阵, ${a_{ij}}$表示边$\left({j, i} \right) \in \varsigma $的权值.当$\left({j, i} \right) \in \varsigma $时, 有${a_{ij}} > 0$; 否则, 有${a_{ij}} = 0$. ${a_{ij}} > 0$表示智能体$i$能收到来自智能体$j$的信息, 反之则不成立.对任意一条边$j$, 节点$j$称为父节点, 节点$i$则称为子节点, 节点$i$是节点$j$的邻居节点.假设通信拓扑中不存在自环, 即对任意$i\in \vartheta $, 有${a_{ii}} = 0$.
定义$L = \left({{l_{ij}}}\right)\in{\bf R}^{n\times n}$为图${\cal G}$的Laplacian矩阵, 其中元素满足${l_{ij}} = - {a_{ij}} \le 0, i \ne j$; ${l_{ii}} = \sum\nolimits_{j = 1, j \ne i}^n {{a_{ij}} \ge 0} $.智能体$i$的入度定义为${d_i} = \sum\nolimits_{j = 1}^n {{a_{ij}}} $, 因此可得到$L = D - \Delta $, 其中, .如果有向图中存在一个始于节点$i$, 止于节点$j$的形如的边序列, 那么称存在一条从$i$到$j$的有向路径.特别地, 如果图中存在一个根节点, 并且该节点到其他所有节点都有有向路径, 那么称此有向图存在一个有向生成树.另外, 如果有向图${\cal G}$存在一个有向生成树, 则Laplacian矩阵$L$有一个0特征值并且其他特征值均含有正实部.
1.2 模型描述
考虑多智能体系统由$n$个智能体组成, 其通信拓扑结构由有向加权图${\cal G}$表示, 其中每个智能体可看作图${\cal G}$中的一个节点, 每个智能体满足如下动力学方程:
$ \begin{equation} \left\{ \begin{array}{l} {x_i}\left( {k + 1} \right) = {x_i}\left( k \right) + {v_i}\left( k \right)\\ {v_i}\left( {k + 1} \right) = {v_i}\left( k \right) + {z_i}\left( k \right)\\ {z_i}\left( {k + 1} \right) = {z_i}\left( k \right) + {u_i}\left( k \right) \end{array} \right. \end{equation} $
(1) 其中, ${x_i}\left(k \right) \in \bf R$表示位置状态, ${v_i}\left(k \right) \in \bf R$表示速度状态, ${z_i}\left(k \right) \in \bf R$表示加速度状态, ${u_i}\left(k \right) \in \bf R$表示控制输入.
基于事件触发控制机制的控制器协议设计如下:
$ \begin{equation} {u_i}\left( k \right) = \lambda {b_i}\left( {k_p^i} \right) + \eta {c_i}\left( {k_p^i} \right) + \gamma {g_i}\left( {k_p^i} \right), k \in \left[ {k_p^i, k_{p + 1}^i} \right) \end{equation} $
(2) 其中, $\lambda> 0$, $\eta> 0$, $\gamma> 0$表示耦合强度,
$ \begin{align*}&{b_i}\left( k \right)= \sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{x_j}\left( k \right) - {x_i}\left( k \right)} \right)} , \nonumber\\ &{c_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{v_j}\left( k \right) - {v_i}\left( k \right)} \right)}, \nonumber\\ & {g_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{z_j}\left( k \right) - {z_i}\left( k \right)} \right)} .\end{align*} $
触发时刻序列定义为:
$ \begin{equation} k_{p + 1}^i = \inf \left\{ {k:k > k_p^i, {E_i}\left( k \right) > 0} \right\} \end{equation} $
(3) ${E_i}\left(k \right)$为触发函数, 具有以下形式:
$ \begin{align} {E_i}\left( k \right)= & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|- {\delta _2}{\beta ^k} - \nonumber\nonumber\\ &{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| \end{align} $
(4) 其中, ${\delta _1} > 0$, ${\delta _2} > 0$, $\beta > 0$, , ${e_{ci}}\left(k \right) = {c_i}\left({k_p^i} \right) - {c_i}\left(k \right)$, ${e_{gi}}\left(k \right) = {g_i}\left({k_p^i} \right) - {g_i}\left(k \right)$.
令$\varepsilon _i\left(k\right)={x_i}\left(k\right)-{x_1}\left(k\right)$, ${\varphi _i}\left(k\right)={v_i}\left(k \right)-$ ${v_1}\left(k\right)$, ${\phi _i}(k) = {z_i}(k) - {z_1}\left(k \right)$, $i = 2, \cdots, n$. , $\cdots, {\varphi _n}\left(k \right)]^{\rm T}$, $\phi \left(k \right) = {\left[{{\phi _2}\left(k \right), \cdots, {\phi _n}\left(k \right)} \right]^{\rm T}}$. $\psi \left(k \right) = {\left[{{\varepsilon ^{\rm T}}\left(k \right), {\varphi ^{\rm T}}\left(k \right), {\phi ^{\rm T}}\left(k \right)} \right]^{\rm T}}$, , ${\bar e_b} = {\left[{{e_{b1}}\left(k \right), \cdots, {e_{b1}}\left(k \right)} \right]^{\rm T}}$, , ${e_{c1}}\left(k \right)]^{\rm T}$, , ${\bar e_g} = $ ${\left[{{e_{g1}}\left(k \right), \cdots, {e_{g1}}\left(k \right)} \right]^{\rm T}}$, $\tilde e\left(k \right) = [\tilde e_b^{\rm T}\left(k \right), \tilde e_c^{\rm T}\left(k \right), $ $\tilde e_g^{\rm T}\left(k \right)]^{\rm T}$, $\bar e\left(k \right) = [\bar e_b^{\rm T}\left(k \right), \bar e_c^T\left(k \right), \bar e_g^{\rm T}\left(k \right)]^{\rm T}$,
$ \hat L = \left[ {\begin{array}{*{20}{c}} {{d_2} + {a_{12}}}&{{a_{13}} - {a_{23}}}& \cdots &{{a_{1n}} - {a_{2n}}}\\ {{a_{12}} - {a_{32}}}&{{d_3} + {a_{13}}}& \cdots &{{a_{1n}} - {a_{3n}}}\\ \vdots & \vdots & \ddots & \vdots \\ {{a_{12}} - {a_{n2}}}&{{a_{13}} - {a_{n3}}}& \cdots &{{d_n} + {a_{1n}}} \end{array}} \right] $
再结合式(1)和式(2)可得到:
$ \begin{equation} \psi \left( {k + 1} \right) = {Q_1}\psi \left( k \right) + {Q_2}\left( {\tilde e\left( k \right) - \bar e\left( k \right)} \right) \end{equation} $
(5) 其中, , .
定义1.对于三阶离散时间多智能体系统(1), 当且仅当所有智能体的位置变量、速度变量、加速度变量满足以下条件时, 称系统(1)能够达到一致.
$ \begin{align*} &{\lim _{k \to \infty }}\left\| {{x_j}\left( k \right) - {x_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{v_j}\left( k \right) - {v_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{z_j}\left( k \right) - {z_i}\left( k \right)} \right\| = 0 \\&\quad\qquad \forall i, j = 1, 2, \cdots , n \end{align*} $
定义2.如果$k_{p + 1}^i - k_p^i > 1$, 则称触发时刻序列$\left\{ {k_p^i} \right\}$不存在类Zeno行为.
假设1.假设有向图中存在一个有向生成树.
2. 一致性分析主要结果
假设$\kappa$是矩阵${Q_1}$的特征值, ${\mu _i}$是$L$的特征值, 则有如下等式成立:
$ {\rm{det}}\left( {\kappa {I_{3n - 3}} - {Q_1}} \right)=\nonumber\\ \det \left(\! \!{\begin{array}{*{20}{c}} {\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\!&\!{{0_{n - 1}}}\\ {{0_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\\ {\lambda {{\hat L}_{n - 1}}}\!&\!{\eta {{\hat L}_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}} + \gamma {{\hat L}_{n - 1}}} \end{array}} \!\!\right)=\nonumber\\ \prod\limits_{i = 2}^n {\left[ {{{\left( {\kappa - 1} \right)}^3} + \left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i}} \right]} $
令
$ \begin{align} {m_i}\left( \kappa \right)= &{\left( {\kappa - 1} \right)^3} + \nonumber\\&\left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i} = 0, \nonumber\\& \qquad\qquad\qquad\qquad\qquad i = 2, \cdots , n \end{align} $
(6) 则有如下引理:
引理1[15]. 如果矩阵$L$有一个0特征值且其他所有特征值均有正实部, 并且参数$\lambda $, $\eta $, $\gamma $满足下列条件:
$ \left\{ \begin{array}{l} 3\lambda - 2\eta < 0\\ \left( {\gamma - \eta + \lambda } \right)\left( {\lambda - \eta } \right) < - \dfrac{{\lambda \Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}}\\ \left( {4\gamma + \lambda - 2\eta } \right)<\dfrac{{8\Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}} \end{array} \right. $
那么, 方程(6)的所有根都在单位圆内, 这也就意味着矩阵${Q_1}$的谱半径小于1, 即$\rho \left({{Q_1}} \right) < 1$.其中, 表示特征值${\mu _i}$的实部.
引理2[23]. 如果, 那么存在$M \ge 1$和$0 < \alpha < 1$使得下式成立
$ {\left\| {{Q_1}} \right\|^k} \le M{\alpha ^k}, \quad k \ge 0 $
定理1. 对于三阶离散多智能体系统(1), 基于假设1, 如果式(2)中的耦合强度满足引理1中的条件, 触发函数(4)中的参数满足$0 < {\delta _1} < 1$, , $0 < \alpha < \beta < 1$, 则称系统(1)能够实现渐近一致.
证明.令$\omega \left(k \right) = \tilde e\left(k \right) - \bar e\left(k \right)$, 式(5)能够被重新写成如下形式:
$ \begin{equation} \psi \left( k \right) = Q_1^k\psi \left( 0 \right) + {Q_2}\sum\limits_{s = 0}^{k - 1} {Q_1^{k - 1 - s}\omega \left( s \right)} \end{equation} $
(7) 根据引理1和引理2可知, 存在$M \ge 1$和$0 < \alpha < 1$使得下式成立.
$ \begin{align} \left\| {\psi \left( k \right)} \right\|\le & {\left\| {{Q_1}} \right\|^k}\left\| {\psi \left( 0 \right)} \right\| + \nonumber\\ & \left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{{\left\| {{Q_1}} \right\|}^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|}\le \nonumber\\ & M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+\nonumber\\ & M\left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{\alpha ^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|} \end{align} $
(8) 由触发条件可得:
$ \begin{align} & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ & \qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^k}\le\nonumber\\ &\qquad {\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\| + {\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\| + \nonumber\\ &\qquad{\delta _1}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\|+ {\delta _1}\left| {{e_{bi}} \left( k \right)} \right| + \nonumber\\ &\qquad{\delta _1}\left| {{e_{ci}} \left( k \right)} \right|+ {\delta _1}\left| {{e_{gi}}\left( k \right)} \right| + {\delta _2}{\beta ^k} \end{align} $
(9) 对上式移项可求解得:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le \nonumber\\ &\qquad\frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\|}}{{1 - {\delta _1}}} + \frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\|}}{{1 - {\delta _1}}}{\rm{ + }}\nonumber\\ &\qquad\frac{{{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(10) 又因为, 和, 可得出下列不等式:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ &\qquad \frac{{{\delta _1}\left\| L \right\|}}{{1 - {\delta _1}}} \cdot \left( {\left\| {\varepsilon \left( k \right)} \right\|{\rm{ + }}\left\| {\varphi \left( k \right)} \right\|{\rm{ + }}\left\| {\phi \left( k \right)} \right\|} \right) +\nonumber\\ &\qquad \frac{{{\delta _2}{\beta ^k}}}{{1 - {\delta _1}}}\le \frac{{3{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(11) 接着有如下不等式成立:
$ \begin{align} \left\| {e\left( k \right)} \right\|\le \frac{{3\sqrt n {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{\sqrt n {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(12) 其中, , ${e_b}(k) = \left[{{e_{b1}}(k), \cdots, {e_{bn}}(k)} \right]$, ${e_c}(k) = \left[{{e_{c1}}(k), \cdots, {e_{cn}}(k)} \right]$,
注意到
$ \begin{equation} \left\| {\tilde e( k )} \right\| + \left\| {\bar e( k )} \right\| \le \sqrt {6( {n - 1} )} \left\| {e( k )} \right\| \end{equation} $
(13) 于是有
$ \begin{align} \left\| {\omega ( k )} \right\| &= \left\| {\tilde e( k ) - \bar e\left( k \right)} \right\| \le\nonumber\\ & \left\| {\tilde e\left( k \right)} \right\| + \left\| {\bar e\left( k \right)} \right\|\le\nonumber\\ & \frac{{3\sqrt {6n( {n - 1} )} {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| +\nonumber\\ & \frac{{\sqrt {6n( {n - 1} )} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(14) 把式(14)代入式(8)可得
$ \begin{align} \left\| {\psi \left( k \right)} \right\| &\le M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+ \nonumber\\ &\frac{{M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}} {\delta _1}3\sqrt {6n\left( {n - 1} \right)} \left\| L \right\|}}{{1 - {\delta _1}}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}}\left\| {\psi \left( s \right)} \right\|} + M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}} \frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}} {{1 - {\delta _1}}}{\beta ^s}} \end{align} $
(15) 接下来的部分, 将证明下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| \le W{\beta ^k}.\end{equation} $
(16) 其中, $W = \max \left\{ {{\Theta _1}, {\Theta _2}} \right\}$,
首先, 证明对任意的$\rho > 1$, 下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| < \rho W{\beta ^k} \end{equation} $
(17) 利用反证法, 先假设式(17)不成立, 则必将存在${k^ * } > 0$使得并且当$k \in \left({0, {k^ * }} \right)$时$\left\| {\psi \left(k \right)} \right\| < \rho W{\beta ^k}$成立.因此, 根据式(17)可得:
$ \begin{align*} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le\\ &\qquad M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} +\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}M\times \end{align*} $
$ \begin{align*} &\qquad\sum\limits_{s = 0}^{{k^ * } - 1} {\alpha ^{ - s}}\left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot \left\| {\psi \left( s \right)} \right\|}}{{1 - {\delta _1}}}} \right]+ \\ &\qquad M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^s}} \right]} < \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} + \rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}\times\\ &\qquad \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot W{\beta ^s}}} {{1 - {\delta _1}}}} \right]} +\\ &\qquad\rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}{\beta ^s}}}{{1 - {\delta _1}}}} \right]=} \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}}- \nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\alpha ^{{k^ * }}}+\nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\beta ^{{k^ * }}} \end{align*} $
1) 当$W = M\left\| {\psi \left(0 \right)} \right\|$时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\| - \nonumber\\ &\qquad \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} \ge 0 \end{aligned} \end{equation*} $
所以可得到
$ \begin{equation} \rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le \rho M\left\| {\psi \left( 0 \right)} \right\|{\beta ^{{k^ * }}}=\rho W{\beta ^{{k^ * }}} \end{equation} $
(18) 2) 当时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\|- \nonumber\\ &\qquad\frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} < 0 \end{aligned} \end{equation*} $
所以有
$ \begin{align} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\|\le\nonumber\\ & \frac{{\rho {\delta _2}M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} {\beta ^{{k^ * }}}}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right) - 3{\delta _1}M\left\| {{Q_2}} \right\|\left\| L \right\|\sqrt {6n\left( {n - 1} \right)} }}=\nonumber\\ &\rho W{\beta ^{{k^ * }}} \end{align} $
(19) 根据以上结果, 式(18)和式(19)都与假设相矛盾.这说明原命题成立, 即对任意的$\rho > 1$, 式(17)成立.易知, 如果$\rho \to 1$, 则式(16)成立.根据式(16)可知, 当$k \to + \infty $时, 有, 则系统(5)是收敛的.由$\psi \left(k \right)$的定义可知, 系统(1)能够实现渐近一致.
定理2. 对于系统(1), 如果定理1中的条件成立, 并且控制器(2)中的设计参数满足如下条件,
$ {\delta _1} \in \left( {\frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}}, 1} \right)\\ {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } $
那么触发序列中的类Zeno行为将被排除.
证明. 易知排除类Zeno行为的关键是要证明不等式$k_{p + 1}^i - k_p^i > 1$成立.根据事件触发机制可知, 下一个触发时刻将会发生在触发函数(4)大于0时.进而可得到如下不等式
$ \begin{align} &\left| {{e_{bi}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{ci}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{gi}}\left( {k_{p + 1}^i} \right)} \right|\ge\nonumber\\ &\qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{align} $
(20) 定义, .结合式(20), 可得到下式
$ \begin{equation} {G_i}\left( {k_{p + 1}^i} \right) \ge {\delta _1}{H_i}\left( {k_p^i} \right) + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{equation} $
(21) 结合式(16)和式(21)可得
$ \begin{align} {\delta _2}{\beta ^{k_{p + 1}^i}} &\le {G_i}\left( {k_{p + 1}^i} \right) - {\delta _1}{H_i}\left( {k_p^i} \right)\le\nonumber\\ & \left\| L \right\|\left( {\left\| {\psi \left( {k_p^i} \right)} \right\| + \left\| {\psi \left( {k_{p + 1}^i} \right)} \right\|} \right)\le\nonumber\\ & W\left\| L \right\|\left( {{\beta ^{k_p^i}} + {\beta ^{k_{p + 1}^i}}} \right) \end{align} $
(22) 求解上式得
$ \begin{equation} \left( {{\delta _2} - \left\| L \right\|W} \right){\beta ^{k_{p + 1}^i}} \le \left\| L \right\|W{\beta ^{k_p^i}} \end{equation} $
(23) 根据式(23)可得
$ \begin{equation} k_{p + 1}^i - k_p^i > \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}} } {\ln \beta } \end{equation} $
(24) 基于(24)易知当时, 有如下不等式成立
$ \begin{equation} \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}}} {\ln \beta } > 1 \end{equation} $
(25) 此外, 因为$W = M\left\| {\psi \left(0 \right)} \right\|$以及
$ \begin{equation} {\delta _1} > \frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}} \end{equation} $
(26) 又可以得出
$ \begin{equation} {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } = \frac{{\left\| L \right\|W\left( {1 + \beta } \right)}}{\beta } \end{equation} $
(27) 该式意味着式(25)成立, 又结合式(24)易知$k_{p + 1}^i - k_p^i > 1$, 即排除类Zeno行为的条件得已满足.
注2.类Zeno行为广泛存在于基于事件触发控制机制的离散系统中.然而, 当前极少有文献研究如何排除类Zeno行为, 尤其是对于三阶多智能体动态模型.定理2给出了排除三阶离散多智能体系统的类Zeno行为的参数条件.
3. 仿真实验
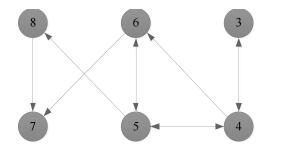
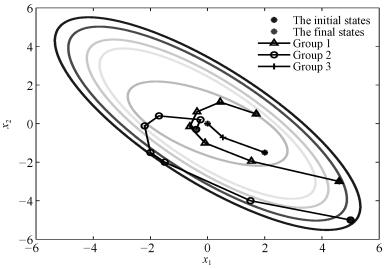
本部分将利用一个仿真实验来验证本文所提算法及理论的正确性和有效性.假设三阶离散多智能体系统(1)包含6个智能体, 且有向加权通信拓扑结构如图 1所示, 权重取值为0或1, 可以明显地看出该图包含有向生成树(满足假设1).
通过简单的计算可得, ${\mu _1} = 0$, ${\mu _2} = 0.6852$, ${\mu _3} = 1.5825 + 0.3865$i, ${\mu _4} = 1.5825 - 0.3865$i, ${\mu _5} = 3.2138$, ${\mu _6} = 3.9360$.令$M = 1$, 结合定理1和定理2可得到$0.035 < {\delta _1} < 1$, ${\delta _2} > 44.0025$, $0 < \alpha < \beta < 1$.令${\delta _1} = 0.2$, ${\delta _2} = 200$, $\alpha = 0.6$, $\beta = 0.9$, $\lambda = 0.02$, $\eta = 0.3$, $\gamma = 0.5$, 不难验证满足引理1的条件并且计算可知$\rho \left({{Q_1}} \right) = 0.9958 < 1$.三阶离散多智能体系统(1)的一致性结果如图 2~图 6所示.根据定理1可知, 基于控制器(2)和事件触发函数(4)的系统(1)能实现一致.从图 2~图 6可以看出, 仿真结果与理论分析符合.
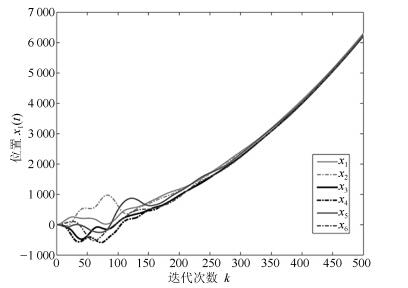 图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems
图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems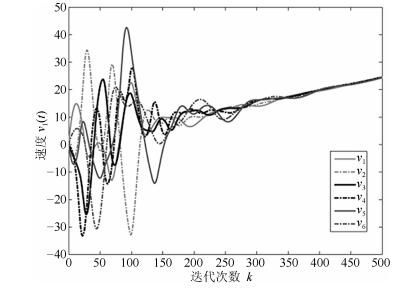 图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems
图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems 图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems
图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems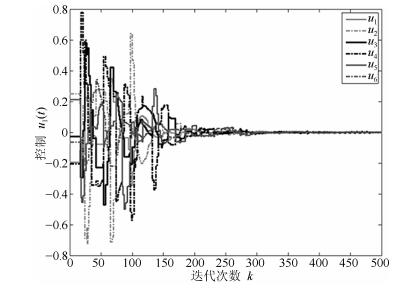 图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems
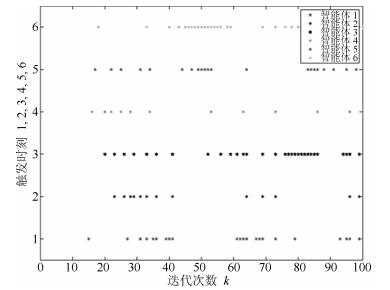
图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems图 2~图 4分别表征了系统(1)中所有智能体的位置、速度和加速度的轨迹, 从图中可以看出以上3个变量确实达到了一致.图 5展示了控制输入的轨迹.为了更清楚地体现事件触发机制的优点, 图 6给出了0$ \sim $100次迭代内的各智能体的触发时刻轨迹.从图 6可以看出, 本文设计的事件触发协议确实达到了减少更新次数, 节省资源的目的.
4. 结论
针对三阶离散多智能体系统的一致性问题, 构造了一个新颖的事件触发一致性协议, 分析得到了在通信拓扑为有向加权图且包含生成树的条件下, 系统中所有智能体的位置状态、速度状态和加速度状态渐近收敛到一致状态的充分条件.同时, 该条件指出了通信拓扑的Laplacian矩阵特征值和系统的耦合强度对系统一致性的影响.另外, 给出了排除类Zeno行为的参数条件.仿真实验结果也验证了上述结论的正确性.将文中获得的结论扩展到拓扑结构随时间变化的更高阶多智能体网络是极有意义的.这将是未来研究的一个具有挑战性的课题.
-
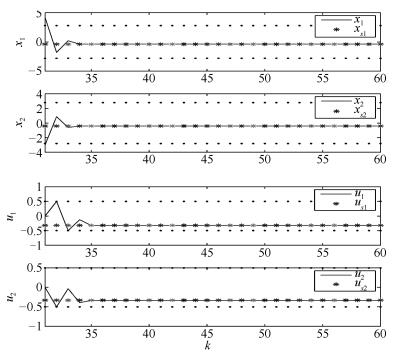
图 3 控制时刻$k$从31到60对应的纸机系统控制过程
Fig. 3 Control process of the paper system with the control moment $k$ from 31 to 60
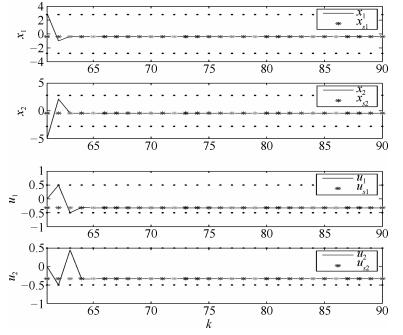
图 4 控制时刻$k$从61到90对应的纸机系统控制过程
Fig. 4 Control process of the paper system with the control moment $k$ from 61 to 90
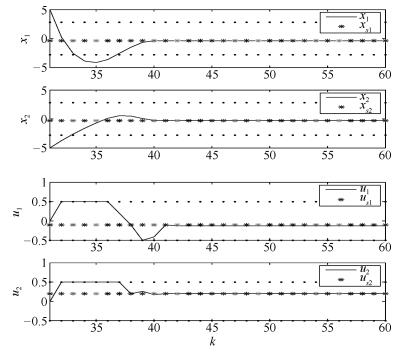
图 5 控制时刻$k$从31到60对应的双积分系统控制过程
Fig. 5 Control process of the double-integrator system with the control moment $k$ from 31 to 60
表 1 本文符号及其含义
Table 1 The meanings of the notations in this paper
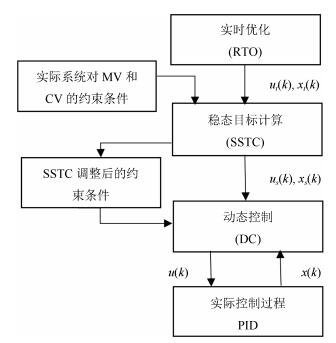
符号 含义 $x^*$ $x$的最优值 ${\bf R}^n$ $n$维欧氏空间 $k$ 离散采样间隔 $x$ 系统状态, $x \in {\bf R}^{n_x}$ $u$ 系统输入, $u \in {\bf R}^{n_u}$ $x_s(u_s)$ 稳态状态(输入) $x_t(u_t)$ 期望稳态状态(输入) $\bar{x}(\bar{u})$ 状态(输入)上界 $I_n $ $n$维单位矩阵 $Q_s, R_s$ 适维权重矩阵 $N_i$ 第$i$个镇定域所对应的控制时域 ${\| x\|}_{Q_s}^2$ $x^{\rm T}$$Q_s$$x$ $x(k+i|k)$ $k$时刻对未来状态的预测值 $u(k+i|k) $ $k$时刻对未来输入的预测值  下载: 导出CSV
下载: 导出CSV
表 2 纸机系统的稳态目标计算结果
Table 2 The results of the SSTC in the AS DPS system
$k$ $u_{s, 1}$ $u_{s, 2}$ $x_{s, 1}$ $x_{s, 2}$ $1\sim90$ -0.39 -0.41 -0.32 -0.33
下载: 导出CSV
表 3 双积分器系统的稳态目标计算结果
Table 3 The results of SSTC in the double-integrator system
k $u_t$ $x_t$ $u_s$ $x_s$ $1\sim30$ (0, 0) (2, -2) (0, 0) (2, 0.5) $31\sim60$ (0, 0) (0, -2) (-0.1, 0.2) (-0.38, 0.2998) $61\sim90$ (0, 0) (0, 0) (0, 0) (0, 0)
下载: 导出CSV
-
[1] 席裕庚, 李德伟.预测控制定性综合理论的基本思想和研究现状.自动化学报, 2008, 34 (10):1225-1234 http://www.aas.net.cn/CN/abstract/abstract17992.shtmlXi Yu-Geng, Li De-Wei. Fundamental philosophy and status of qualitative synthesis of model predictive control. Acta Automatica Sinica, 2008, 34 (10):1225-1234 http://www.aas.net.cn/CN/abstract/abstract17992.shtml [2] 席裕庚, 李德伟, 林姝.模型预测控制-现状与挑战.自动化学报, 2013, 39 (3):222-236 http://www.aas.net.cn/CN/abstract/abstract17874.shtmlXi Yu-Geng, Li De-Wei, Lin Shu. Model predictive control-status and challenges. Acta Automatica Sinica, 2013, 39 (3):222-236 http://www.aas.net.cn/CN/abstract/abstract17874.shtml [3] 席裕庚.预测控制.第2版.北京:国防工业出版社, 2013. 15-67Xi Yu-Geng. Predictive Control (Second Edition). Beijing:National Defense Industry Press, 2013. 15-67 [4] Sildir H, Arkun Y, Cakal B, Gokce D, Kuzu E. Plant-wide hierarchical optimization and control of an industrial hydrocracking process. Journal of Process Control, 2013, 23 (9):1229-1240 doi: 10.1016/j.jprocont.2013.07.007 [5] Darby M L, Nikolaou M, Jones J, Nicholson D. RTO:an overview and assessment of current practice. Journal of Process Control, 2011, 21 (6):874-884 doi: 10.1016/j.jprocont.2011.03.009 [6] Scattolini R. Architectures for distributed and hierarchical model predictive control-a review. Journal of Process Control, 2009, 19 (5):723-731 doi: 10.1016/j.jprocont.2009.02.003 [7] 李世卿, 丁宝苍.基于动态矩阵控制的双层结构预测控制的整体解决方案.自动化学报, 2015, 41 (11):1857-1866 http://www.aas.net.cn/CN/abstract/abstract18761.shtmlLi Shi-Qing, Ding Bao-Cang. An overall solution to double-layered model predictive control based on dynamic matrix control. Acta Automatica Sinica, 2015, 41 (11):1857-1866 http://www.aas.net.cn/CN/abstract/abstract18761.shtml [8] 李世卿, 丁宝苍, 孙耀.双层预测控制中基于操作变量增量的多优先级稳态目标计算.控制理论与应用, 2015, 32 (2):239-245 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=kzllyyy201502014Li Shi-Qing, Ding Bao-Cang, Sun Yao. Multi-priority rank steady-state target calculation in double-layered model predictive control by optimizing increments of manipulated variables. Control Theory & Applications, 2015, 32 (2):239-245 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=kzllyyy201502014 [9] Mayne D Q, Rawlings J B, Rao C V, Scokaert P O M. Constrained model predictive control:stability and optimality. Automatica, 2000, 36 (6):789-814 doi: 10.1016/S0005-1098(99)00214-9 [10] Gutman P O, Cwikel M. An algorithm to find maximal state constraint sets for discrete-time linear dynamical systems with bounded controls and states. IEEE Transactions on Automatic Control, 1987, 32 (3):251-254 doi: 10.1109/TAC.1987.1104567 [11] Gilbert E G, Tan K T. Linear systems with state and control constraints:the theory and application of maximal output admissible sets. IEEE Transactions on Automatic Control, 1991, 36 (9):1008-1020 doi: 10.1109/9.83532 [12] 潘红光, 高海南, 孙耀, 张英, 丁宝苍.基于多优先级稳态优化的双层结构预测控制算法及软件实现.自动化学报, 2014, 40 (3):405-414 http://www.aas.net.cn/CN/abstract/abstract18305.shtmlPan Hong-Guang, Gao Hai-Nan, Sun Yao, Zhang Ying, Ding Bao-Cang. The algorithm and software implementation for double-layered model predictive control based on multi-priority rank steady-state optimization. Acta Automatica Sinica, 2014, 40 (3):405-414 http://www.aas.net.cn/CN/abstract/abstract18305.shtml [13] Blanchini F. Set invariance in control. Automatica, 1999, 35 (11):1747-1767 doi: 10.1016/S0005-1098(99)00113-2 [14] Li Z J, Tan W, Nian S C, Liu J Z. A stabilizing model predictive control for linear systems with input saturation. In: Proceedings of the 2006 International Conference on Machine Learning and Cybernetics. Dalian, China: IEEE, 2006. 671-675 [15] Li Z J, Liu J Z, Tan W. Multi-model H_∞ loop shaping controller for nonlinear system based on gap metric. In: Proceedings of the ICARCV 8th Control, Automation, Robotics and Vision Conference. Kunming, China: IEEE, 2004, 3: 1940-1944 [16] Kosut R. Design of linear systems with saturating linear control and bounded states. IEEE Transactions on Automatic Control, 1983, 28 (1):121-124 doi: 10.1109/TAC.1983.1103127 [17] 李志军. 约束模型预测控制的稳定性与鲁棒性研究[博士学位论文], 华北电力大学(北京), 中国, 2005.Li Zhi-Jun. Research on Stability and Robustness of Constrained Model Predictive Control[Ph. D. dissertation], North China Electric Power University (Beijing), China, 2005. [18] Limon D, Alvarado I, Alamo T, Camacho E F. MPC for tracking piecewise constant references for constrained linear systems. Automatica, 2008, 44 (9):2382-2387 doi: 10.1016/j.automatica.2008.01.023 [19] Chen H, Allgöwer F. A quasi-infinite horizon nonlinear model predictive control scheme with guaranteed stability. Automatica, 1998, 34 (10):1205-1217 doi: 10.1016/S0005-1098(98)00073-9 [20] 曹永岩, 毛维杰, 孙优贤, 冯旭.现代控制理论的工程应用.杭州:浙江大学出版社, 2000.Cao Yong-Yan, Mao Wei-Jie, Sun You-Xian, Feng Xu. Engineering Application of Modern Control Theory. Hangzhou:Zhejiang University Press, 2000. [21] Pluymers B, Rossiter J A, Suykens J A K, Moor B D. The efficient computation of polyhedral invariant sets for linear systems with polytopic uncertainty. In: Proceedings of the 2005 American Control Conference. Portland, OR, USA: IEEE, 2005, 2: 804-809 期刊类型引用(3)
1. 岳振宇,范大昭,董杨,纪松,李东子. 一种星载平台轻量化快速影像匹配方法. 地球信息科学学报. 2022(05): 925-939 .  百度学术
百度学术2. 王若兰,潘万彬,曹伟娟. 图像局部区域匹配驱动的导航式拼图方法. 计算机辅助设计与图形学学报. 2020(03): 452-461 . 百度学术3. 胡敬双,聂洪玉. 灰度序模式的局部特征描述算法. 中国图象图形学报. 2017(06): 824-832 . 百度学术其他类型引用(9)
-

 下载:
下载:

计量
- 文章访问数: 2017
- HTML全文浏览量: 246
- PDF下载量: 876
- 被引次数: 12
