

Analysis and System Design of Multi-convex Hull Stabilization Domain for Double-layered Model Predictive Control System
-
摘要: 针对双层模型预测控制(Model predictive control,MPC)中出现的由于系统状态在动态控制(Dynamic control,DC)过程中超出约束集,导致下层优化不可行的问题,本文在综合控制方法的基础上提出一种新的动态控制策略,引入多包镇定域(Multi-convex hull stabilization domain,MHSD)的概念.通过离线计算多包镇定域,并根据系统每一时刻的实测状态值,在线决定(Dynamic control)层的镇定域以及相应的控制时域,结合变约束思想,保证动态控制过程递归可行,从而有效控制在大范围内变化的系统状态.另外,本文通过设计非线性反馈控制器,扩大了终端不变集和多包镇定域的范围,提高了DC层对稳态目标值的跟踪效果.本文的控制算法可以使得DC层在目标跟踪过程中保证递归可行性,并最大程度地实现无静差跟踪.仿真算例验证了本文算法对稳定系统和不稳定系统都有效.Abstract: In order to solve the feasibility problem in double-layered model predictive control (MPC) caused by some states in dynamic control (DC) that violate the constraints, this paper proposes a new control strategy based on the overall control solution and introduces a new definition multi-convex hull stabilization domain (MHSD). This strategy designs the MHSD off line and then chooses a proper stabilization range online according to the real-time system state. The control horizon of the DC layer can be calculated at the same time. What is more, this paper enlarges the invariant sets and the stabilization domain through designing a nonlinear feedback controller so that the system states varying in a wide range can be controlled and the tracking effect is significantly improved. By using the above algorithm, the control process is recursively feasible and the optimal targets can be tracked precisely. The effectiveness of this method is verified in both stable and unstable systems through two examples.
-
证据理论最早由Dempster提出, 后经Shafer对其进行完善和发展, 所以又称为Dempster-Shafer证据理论, 或D-S证据理论[1-2]. 证据理论中使用非精确概率对不确定性进行建模, 相对于概率论中严格的公理化体系而言, 证据理论满足的公理化体系较为宽松, 基于证据理论的推理不仅摆脱了对先验概率的依赖, 而且对自然语言中的模糊概念也有一定的处理能力, 在不确定推理方面有很大优势, 可在一定程度上弥补贝叶斯推理方法的不足[3].证据理论中, 不确定性信息通过基本概率分配函数(Basic probability assignment function, BPAF)、信任函数(Belief function, BF)、似真函数(Plausibility function, PF)、众信度函数(Commonality function, CF)等信任量化函数来描述, 各量化函数均有明确的物理意义, 且各量化函数之间存在对应关系.
在证据理论中, 信度可以分配到辨识框架的所有子集, 通过Dempster组合规则能够对多个独立的证据进行合成, 可以对不确定信息进行有效融合, 因此证据理论在不确定信息处理方面得到了广泛的应用, 证据理论中相关概念的物理意义及与其他不确定性理论之间的关系也引起了一些学者的兴趣[3]. 证据理论在实际应用中遇到的最大问题是冲突证据的组合问题, Zadeh首先指出Dempster组合规则在处理高冲突证据会产生错误的合成结果[4], 自此以后, Dempster组合规则饱受争议, 冲突证据的处理一度成为证据理论研究的热点.国内外学者针对冲突证据的合成问题提出了许多改进方法[5-10], 主要包括基于冲突再分配的合成规则修订以及基于证据折扣和加权平均的数据模型修订两大类.
目前大多数关于信息融合的研究都是在空域开展的, 相关的融合方法也都是基于多传感器信息融合系统提出的.然而, 在信息融合中, 受干扰信息和传感器性能的影响, 单个测量周期内各传感器所获取的信息并不一定准确, 在信息融合中, 往往还需要综合利用多个时间节点的信息进行时域信息融合, 因此信息融合应该是基于多传感器的时空序贯融合的过程.在空域信息融合中, 各传感器所获取的信息可以同时进行融合, 没有时间上的先后顺序, 而时域信息融合所处理的信息不是在同一时间获取的, 而是随时间序列逐步获取的;另外, 时域信息融合系统一般对实时性有较高要求, 不可能在各时间节点的识别信息全部获取以后再进行融合, 因此时域信息的融合具有明显的序贯性、动态性和实时性, 体现为融合结果的继承和更新.
虽然基于证据理论的时域信息融合受到了一些研究者的关注, 但目前仍缺乏有针对性的时域证据组合方法. Hong等[11]首先对基于证据理论的时空不确定信息融合模型进行了研究, 以综合目标识别为背景, 提出了三种时空信息融合模型: 递归集中式融合模型、递归分布无反馈融合模型和递归分布有反馈融合模型, 对三种融合模型的特点进行了分析, 但没有给出具体的时域融合方法.洪昭艺等[12]对这三种融合模型进行了研究与改进, 提出了一种混合式时空信息融合模型, 在进行时域融合时直接运用Dempster规则进行证据组合. 尽管部分学者基于递归集中式融合模型针对融合目标识别中的时空证据组合方法进行了研究[13-14], 但涉及到具体的时域证据组合方法时, 有的直接利用空域证据组合方法[13], 不能反映时域信息序贯性的特点, 时间因素对时域融合的作用不明显;有的则是依据空域中各证据之间的相互关系来确定时域融合方法[15], 没有充分利用时域信息之间的相互关系, 不能很好地处理时域信息间的冲突.因此, 时域证据组合方法还有待于进一步深入研究, 需要基于时域信息融合的特点构建有针对性的时域证据组合方法.
本文面向时域信息融合对证据理论中的相关问题进行研究, 从证据理论的相关研究中可知, 证据组合的关键在于冲突信息的处理, 证据可靠性评估是一种重要的冲突处理方法, 时域证据组合的重点也在于如何处理证据间的冲突, 因此, 本文围绕时域证据序列的动态可靠性评估展开研究.结合证据理论中的BPAF与直觉模糊集之间的关系, 提出一种基于直觉模糊集的证据可靠性评估方法, 以此为基础对时域证据序列中相邻证据间的相对可靠性进行评估, 得到时域证据的相对可靠度;将前期研究中基于可靠度衰减模型提出的实时可靠度与相对可靠度结合, 得到时域证据的复合可靠度, 然后以复合可靠度为折扣因子, 利用Shafer折扣准则对时域证据进行修正, 最后利用Dempster组合规则进行证据组合.本文提出的时域证据组合方法充分考虑了时间因素对时域证据组合的影响, 具有较强的动态性, 而且对时域证据序列中的冲突证据也有较强的处理能力.
本文内容安排如下: 第1节对证据理论相关知识进行简要介绍, 重点介绍证据理论中的基本概念、证据折扣运算、证据组合规则及证据理论中的决策规则; 第2节回顾直觉模糊集相关知识, 分析直觉模糊集与证据理论的关系;第3节基于直觉模糊数之间的排序提出一种基于直觉模糊多属性决策的证据可靠性评估方法, 为时域证据可靠性评估奠定基础;第4节结合时域证据的实时可靠性因子和相对可靠性因子提出一种基于复合可靠度的时域证据组合方法;第5节对本文进行总结.
1. D-S证据理论
D-S证据理论的数学模型要求首先确立辨识框架, 然后确定证据对每个集合的支持程度, 再利用证据合成公式算出对所有命题的支持度. 辨识框架是证据理论中进行证据建模和证据组合的基础, 也正是通过辨识框架将命题与集合对应起来, 实现从抽象逻辑概念向直观集合概念的转化. 在证据理论中, 对于一个判决问题而言, 其所有互不相容的结果组成的完备集合$\Theta = \{{\theta _1}, {\theta _2}, \cdots, {\theta _n}\}$称为辨识框架.由辨识框架Θ的所有子集组成Θ的幂集, 记作2Θ, 它的基数为2|Θ|, 证据理论是基于辨识框架用集合来表示命题的.
1.1 基本概念
辨识框架Θ确定以后, 可以根据可用信息对其命题所对应的子集赋予相应的信任度, 具体表现为基本概率分配函数、信任函数、似真函数等信任量化函数, 这些函数分别从不同角度对信任度进行量化, 各函数之间均存在对应关系, 通过其中一个函数可以同时获取其他所有函数. 下面对证据理论中的几种信任量化函数进行说明.
设$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\}$为辨识框架, 若函数$m:{2^\Theta }\to [0, 1]$满足: 1) $m(\emptyset ) = 0$; 2) $\forall A \subseteq \Theta , 0 \le m(A) \le 1$; 3) $\sum_{A \subseteq \Theta } {m(A)} = 1$.则称之为基本概率分配函数(BPAF).
基本概率分配函数也称为基本信任分配函数(Basic belief assignment function, BBAF)或mass函数.由于基本概率分配函数反映了证据对各子集的支持程度, 通常将BPAF与证据对应起来. $\forall A \subseteq Θ, m(A)$称为A的基本概率质量(Basic probability mass, BPM), 表示证据对命题A的支持度.
对于辨识框架$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\}$上的基本概率分配函数m, $\forall A \subseteq \Theta $, 若$m(A) > 0$, 则称A为m的焦元.如果$|A| = 1$, 则A为单元素焦元;若$|A| \ge 2$, 则A为复合焦元.所有焦元的并集称为m的核(Core), 记为C, 并称m聚焦在C上.如果m的焦元均为辨识框架Θ的单元素子集, 那么退化为Bayesian基本概率分配, 与Θ上的概率分布函数有相同的数学形式.
设m为辨识框架$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\}$上的基本概率分配函数, 与之对应的信任函数表示为$Bel: {2^\Theta } \to [0, 1]$, 满足$Bel(\emptyset ) = 0, \forall A \subseteq \Theta $且$A \ne\emptyset$, 有$Bel(A) = \sum_{X \subseteq A} {m(X)} , Bel(A)$的数值表示证据对A为真的信任程度.与m对应的似真函数定义为函数$Pl:{2^\Theta } \to [0, 1]$, 满足$\forall A \subseteq \Theta $, 有 $Pl(A) = \sum_{X \cap A \ne \emptyset } {m(X)} = 1 - Bel(\bar A), Pl(A)$的取值称为A的似真度, 表示了A为非假的信任度.
$Bel(A)$和$Pl(A)$分别代表了证据对A的支持度的最小值和最大值, 通常用$\left[ {Bel(A), Pl(A)} \right]$来表示A的信任度区间, $Pl(A) - Bel(A)$在某种程度上反映了A的不确定程度.
定义1. Shafer折扣准则[2].若辨识框架$\Theta= \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\}$上的基本概率分配函数m对应的证据源不完全可靠, 且该证据源的可靠性因子为$\lambda, \lambda \in [0, 1]$, 则可通过Shafer折扣准则对m进行折扣运算, 折扣后的证据表示为
$ {m^\lambda }(A) = \left\{ {\begin{array}{*{20}{l}} {\lambda \times m(A),}&{A \subset \Theta }\\ {\lambda \times m(A) + 1 - \lambda ,}&{A = \Theta } \end{array}} \right. $
(1) 可以看出, 经过证据折扣后, ${m^\lambda}$中Θ获得的基本概率质量增加, 其他焦元的基本概率质量则减小, Shafer折扣准则将证据源不可靠性带来的影响转化为${m^\lambda}$中完全未知的部分, 而且可靠性因子取值越接近0, 折扣后的BPAF的不确定性越大. Shafer折扣准则对研究冲突证据的组合具有重要意义.
1.2 证据组合规则
在多源信息系统中, 多个证据源分别获得BPAF ${m_1}, {m_2}, \cdots, {m_p}$, 或同一证据源在不同时刻分别获得BPAF ${m_{{t_1}}}, {m_{{t_2}}}, \cdots, {m_{{t_r}}}$, 则多个BPAF组合后可以得到一个新的BPAF, 这一过程在证据理论中表现为证据的动态更新.
定义2. Dempster组合规则[1]. 设${m_1}$和${m_2}$是辨识框架$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta_n}\}$上两个相互独立的基本概率分配函数, 二者组合后得到新的BPAF为$m = {m_1} \oplus {m_2}$, 简记为${m_{1 \oplus 2}}$, 对$\forall A \subseteq \Theta $满足
$ \begin{array}{l} {m_{1 \oplus 2}}(A) = \\ \qquad \left\{ {\begin{array}{*{20}{l}} {\frac{1}{{1 - k}}\sum\limits_{B \cap C = A} {{m_1}(B){m_2}(C)} ,}&{A \ne \emptyset }\\ {0,}&{A = \emptyset } \end{array}} \right. \end{array} $
(2) 式中,
$ k = \sum\limits_{B \cap C = \emptyset } {{m_1}(B){m_2}(C)} $
(3) 表示两证据间的冲突度, k=1表示${m_1}$和${m_2}$完全冲突, 二者不能通过Dempster组合规则进行组合.
Dempster组合规则可以推广到多组证据组合的情形, Dempster证据组合规则满足交换律和结合律, 这为多个证据的组合提供了方便, 既可以串行计算, 将各个证据依次组合;也可以并行处理, 将若干个证据分别合成, 然后再将它们的合成结果进行组合.而且, 对若干个相同的证据进行组合时, Dempster规则表现出较强的聚焦性, 即元素少的焦元的基本概率质量会增加, 元素多的焦元的基本概率质量会减少, 而且证据数量越大该现象越明显.
1.3 证据理论中的决策
Dempster-Shafer证据理论中用来量化信任的主要函数(基本概率分配函数、信任函数以及似真函数), 分别从不同角度对辨识框架中各子集的信任度进行度量, 进行最终决策时, 可以分别或共同使用这些函数进行决策, 也可以将它们转化为辨识框架上的概率分布后再进行决策.尽管基于信任度量函数进行决策的方法对实际的决策问题具有一定的指导作用, 但这些方法难以给出具体的决策结果, 因为这些方法都是直接基于证据焦元设计的, 在存在复合焦元或各焦元之间存在共同元素的情况下, 得到的决策结果具有太大的不确定性, 不利于最终的决策. 只有将基本概率分配函数转换为辨识框架上的概率分布函数才能从根本上对决策进行指导, 依据辨识框架中每一个单元素子集的概率函数, 可以利用最大概率准则直接进行决策, 或进一步结合效用函数或损失函数进行决策. 将基本概率分配函数转化为概率的过程称为BPAF概率转换, 或贝叶斯转换. 虽然多种BPAF概率方法已相继被研究者们提出[15], 但Pignistic概率转换方法在决策中的应用最为广泛, Pignistic概率转换方法可表述如下.
定义3. Pignistic概率转换[16].对辨识框架$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta_n}\}$上的BPAF m, $\forall A \subseteq \Theta$, 其Pignistic概率转换定义为
$ Bet{P_m}(A) = \sum\limits_{B \subseteq \Theta } {\frac{{\left| {A \cap B} \right|}}{{|B|}}} \times \frac{{m(B)}}{{1 - m(\emptyset )}} $
(4) 式中, $Bet{P_m}( \cdot )$称为Pignistic概率函数, 在数学形式上与一般的概率函数相同.
特别地, 对于单元素子集而言, $\forall \theta \in \Theta , \{ \theta \}$的Pignistic概率为
$ \begin{align} Bet{P_m}(\{ \theta \} ) = \sum\limits_{\theta \in B} {\frac{1}{{|B|}}} \frac{{m(B)}}{{1 - m(\emptyset )}} \end{align} $
(5) 2. 直觉模糊集与证据理论
2.1 直觉模糊集相关概念
在经典集合论中, 对于论域中的任何一个元素(对象), 它与该论域中集合之间的关系只能是属于或不属于, 即一个元素(对象)是否属于某一集合的特征函数的值域为0和1两个数, 这种二值逻辑为现代数学的发展奠定了基础. 而Zadeh模糊集的核心思想在于把特征函数的值域扩展到闭区间[0, 1]上, 称其为隶属度函数, 而把取定的值称为元素相对于集合的隶属度.
定义4. 模糊集[17]. 设$X=\{{x_1}, {x_2}, \cdots, {x_n}\}$为非空论域, X上的模糊集(Fuzzy set, FS) A定义为
$ \begin{align}A = \left\{ {\left\langle {x, {\mu _A}(x)} \right\rangle \left| {x \in X} \right.} \right\}\end{align} $
(6) 其中, ${\mu _A}(x):X \to [0, 1]$为隶属度函数, 表示x属于A的程度.
论域X上的所有模糊集可表示为$FSs(X)$.在模糊集中, ${v_A}(x) = 1 - {\mu _A}(x)$为x相对于A的非隶属度函数, 因此, x与A 的关系完全是由隶属度来刻画的, ${\mu _A}(x)$越接近于1, 表示x属于模糊集A的程度越高; ${\mu _A}(x)$越接近于0, 表示x属于模糊集A的程度越低;当${\mu _A}(x) \in \{ 0, 1\}$时, A退化为经典集合, 相对于模糊集而言, 经典集合也称为精确集(Crisp set, CS). 因此, 模糊集可以看作是经典集合的推广, 而精确集则是特殊的模糊集.
为了更好地对不确定性信息进行表述和建模, Atanassov提出了直觉模糊集的概念.
定义5. 直觉模糊集[18].设$X=\{{x_1}, {x_2}, \cdots, {x_n}\}$为非空论域, X上的直觉模糊集(Intuitionistic fuzzy set, IFS) A定义为
$ \begin{align} A = \left\{ {\left\langle {x, {\mu _A}(x), {v_A}(x)} \right\rangle \left| {x \in X} \right.} \right\} \end{align} $
(7) 其中, ${\mu _A}(x):X \to [0, 1]$和${v_A}(x):X \to [0, 1]$分别为x相对于A的隶属度函数和非隶属度函数, 且满足
$ \begin{align}{\mu _A}(x) + {v_A}(x) \le 1\end{align} $
(8) 在直觉模糊集中, 由隶属度与非隶属度函数的和不大于1可以导出另一个参数, 即犹豫度函数${\pi _A}(x):$ X→[0, 1], x相对于A的犹豫度函数表示为
$ \begin{align}{\pi _A}(x) = 1 - {\mu _A}(x) - {v_A}(x)\end{align} $
(9) 为方便表述后文, 用$IFSs(X)$表示论域X中所有直觉模糊集;单元素论域$X = \{ x\}$中的直觉模糊集可以简记为$\langle{{\mu_A}(x), {v_A}(x)}\rangle$或$\langle{{\mu_A}, {v_A}}\rangle, A = \langle{\mu_A}, {v_A}\rangle$也常用来表示一个直觉模糊数(Intuitionistic fuzzy value, IFV).
需要说明的是, 除了定义5, 直觉模糊集还有其他表述方式, 已有研究表明, 直觉模糊集与Vague集是等价的[19], 而且也可以用区间的形式表述[20], 直觉模糊集$\langle {{\mu _A}(x), {v_A}(x)} \rangle$可以用区间$[{\mu _A}(x), 1-{v_A}(x)]$表示, ${\mu _A}(x)$和$1 - {v_A}(x)$分别表示x属于A的隶属度的下界和上界, 这与区间值模糊集的表述方式相似, 因此直觉模糊集与区间值模糊集之间可以互相转化. 而且, 在证据理论中曾用区间$[Bel(A), Pl(A)]$表示命题的信任度区间, 这与直觉模糊集的区间表示方法很接近. 后文将基于此对证据理论与直觉模糊集之间的关系进行分析.
对于直觉模糊集A, 当${\pi_A}(x)=0$时, ${v_A}(x)= 1-{\mu_A}(x)$, 直觉模糊集A退化为Zadeh的模糊集. 因此, 模糊集可以看作是特殊的直觉模糊集, 同样, 精确集也是直觉模糊集的一个特例.由此可见, 精确集和模糊集都可以在直觉模糊框架内统一表示.
设A为论域$X = \{ {x_1}, {x_2}, \cdots, {x_n}\}$中的任意非空精确子集, 即$A \subseteq X$且$A \ne \emptyset$, 那么A可以表示为直觉模糊集$\tilde A = \{\langle x, {\mu _{\tilde A}}(x), {v_{\tilde A}}(x) \rangle |x \in X\}$, 其中, 若$x \in A$, 则${\mu _{\tilde A}}(x) = 1, {v_{\tilde A}}(x) = 0$;否则, ${\mu _{\tilde A}}(x) = 0, {v_{\tilde A}}(x) = 1$.
例如, 论域$X = \{ {x_1}, {x_2}, {x_3}, {x_4}\}$中的子集$A= \{ {x_1}, {x_2}\}$和$B=\{{x_1}, {x_2}, {x_3}\}$可分别表示为直觉模糊集$\tilde A$和$\tilde B$.
$ \begin{align*} & \tilde A = \left\{ {\left\langle {{x_1}, 1, 0} \right\rangle, \left\langle {{x_2}, 1, 0} \right\rangle, \left\langle {{x_3}, 0, 1} \right\rangle, \left\langle {{x_4}, 0, 1} \right\rangle } \right\}\\ &\tilde B = \left\{ {\left\langle {{x_1}, 1, 0} \right\rangle, \left\langle {{x_2}, 1, 0} \right\rangle, \left\langle {{x_3}, 1, 0} \right\rangle, \left\langle {{x_4}, 0, 1} \right\rangle } \right\} \end{align*} $
精确集、模糊集、直觉模糊集在形式上的统一进一步表明了直觉模糊集在信息表述方面的灵活性, 在直觉模糊集框架内, 可以对各种不确定信息进行统一建模.
2.2 直觉模糊集与BPAF之间的关系
近年来, 越来越多的学者开始关注直觉模糊集与证据理论之间的关系. 例如, Li等[21]从Vague集的角度分析证据理论, 认为证据理论是一种特殊的Vague集, 并利用Vague集之间相似度的概念讨论了BPAF之间的相似程度问题, 由于Vague集与直觉模糊集是等价的, 因此, 从这个意义上讲, 证据理论也是直觉模糊集的特例;文献[22]和文献[23]从证据理论的角度对直觉模糊集中的相关概念进行了解释, 并提出了基于证据理论的直觉模糊数排序方法和决策规则; Yager[24]则直接从直觉模糊集的角度对证据理论进行研究; 文献[25]通过定义广义信任函数和广义似真函数来确定直觉模糊集中的隶属度与非隶属度函数.下面进一步分析证据理论中的BPAF与直觉模糊集之间的关系.
从集合论的角度来看, 证据理论中的辨识框架对应于直觉模糊理论中的论域, 若将证据理论中辨识框架$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\} $上的基本概率分配函数m看作是论域$\Theta = \{ {\theta _1}, {\theta _2}, \cdots, {\theta _n}\} $上的直觉模糊集M, 那么对于Θ中的元素${\theta _i}$而言, 信任函数$Bel({\theta _i})$表示${\theta _i} \in M$的隶属度, $Bel({\bar \theta _i})$即$1 - Pl({\theta _i})$表示${\theta_i}$相对于直觉模糊集M的非隶属度.通过该方法, 可以将基本概率分配函数的焦元进行简化, 全部聚焦在单元素焦元上, 每个焦元的信任度为直觉模糊数$\langle Bel({\theta _i}), 1 - Pl({\theta _i})\rangle$, 此外, 直觉模糊数$\langle Bel({\theta_i}), 1-Pl({\theta_i})\rangle$也可以看作是对象${\theta _i}$与判决问题真实解之间的匹配程度, 例如在目标识别中, $\langle Bel({\theta_i}), 1- Pl({\theta_i})\rangle$可以表示目标${\theta_i}$与真实目标之间的匹配程度.
另一方面, 定义在论域$X = \{ x\}$上的直觉模糊集$A = \langle x, {\mu _A}(x), {v_A}(x) \rangle$可以看作是对问题"x是否属于A"的回答, 在该问题中, 辨识框架为$\Theta = \{ Yes, No\}$, 根据隶属度函数和非隶属度函数的意义可得$m(\{ Yes\} ) = {\mu _A}, m(\{ No\} ) = {v_A}, m(\Theta ) = {\pi _A}$. 因此$A = \langle x, {\mu _A}(x), {v_A}(x) \rangle$对应于一个二分支持函数m, 表示为
$ \begin{align} \begin{cases} m(\{ Yes\} ) = {\mu _A}\\[1mm] m(\{ No\} ) = {v_A}\\[1mm] m(\Theta ) = {\pi _A} \end{cases} \end{align} $
(10) 显然, 该转换关系可以推广到任意论域上的直觉模糊集.因此, 可以在证据理论框架内对直觉模糊集之间的运算规则以及直觉模糊测度进行研究. 需要说明的是, 从证据理论到直觉模糊集的转换会带来一定的信息损失, 而且基本概率分配函数与直觉模糊集之间不是一一对应的.
3. 直觉模糊框架内的证据可靠性评估
为削弱不可靠信息对融合结果的影响, 在进行证据组合前需要对证据源的可靠性进行评估, 这也是处理高冲突证据的一种有效方法. 近些年, 国内外学者在证据可靠性评估方面做了大量工作[26-29], 在传感器静态可靠性评估中, 需要利用已知训练样本获得传感器的固有属性信息, 然而, 在信息融合实际中, 先验信息总是非常有限的, 因此, 在大多数情况下, 静态可靠性的评估带有较强的不确定性. 而且, 在工程应用中, 传感器的工作环境可能会发生变化, 传感器的性能与其工作环境密切相关, 诸如人为干扰、恶劣天气等因素都会使传感器的可靠度降低, 甚至使其失效.所以传感器静态可靠性评估方法具有一定的局限性, 不能满足工程实际的需求.对于基于证据理论的信息融合系统而言, 证据的可靠性评估更多的是基于传感器实时输出的动态可靠性评估.
现有的证据动态可靠性评估大都是基于"大多数原则"开展的, 在多个传感器提供的证据中, 如果某个证据被其他大多数证据都支持, 那么可以认为该证据的可靠度较高;对于两个证据而言, 如果它们之间存在较大的冲突, 那么至少有一个是不可靠的[26].所以, 证据动态可靠性评估大都是基于证据间的冲突度量和距离度量进行的, 这类证据动态可靠性的评估方法最终都归结为证据冲突度量和距离度量的定义问题, 而证据冲突度量问题依然未能很好地解决, 不同的冲突度量标准可能会得到不同的评估结果.而且, 当只有两个证据时, 通过以上方法得到两个证据的可靠性因子均为1, 与具体的BPAF无关, 即使二者之间存在较大冲突, 根据相等的可靠性因子无法确定哪一个证据不可靠, 因此基于"大多数原则"的可靠性评估方法不适用于只有两个证据的情况, 无法利用此类方法对时域证据序列中相邻两个证据的可靠性进行评估.为了对证据的动态可靠性进行全面客观的评估, 更好地适应时域证据可靠性评估的需要, 本节将提出一种基于直觉模糊多属性决策(Intuitionistic fuzzy multiple criteria decision making, IFMCDM)的证据动态可靠性评估方法.
3.1 基于可能度的直觉模糊数排序
定义6. 基于可能度的区间数排序[30].设两个区间数分别为$\alpha = [{a^L}, {a^U}]$和$\beta = [{b^L}, {b^U}]$, 满足${a^L} \le {a^U}, {b^L} \le {b^U}$, 那么α不小于β的可能度${P_{(\alpha \ge \beta )}}$可定义为
$ \begin{align} {P_{(\alpha \ge \beta )}} &= \nonumber\\ &\min \left\{ {1, \max \left\{ {\frac{{{a^U} - {b^L}}}{{({a^U} - {a^L}) + ({b^U} - {b^L})}}, 0} \right\}} \right\} \end{align} $
(11) 当${a^L} = {a^U} = a, {b^L} = {b^U} = b$同时成立时, 分母为零, 式(11)不再适用.此时, α和β退化为精确的实数, 因此有$a > b \Rightarrow {P_{(\alpha \ge \beta )}} = 1, a <b \Rightarrow {P_{(\alpha \ge \beta )}} = 0, a = b \Rightarrow {P_{(\alpha \ge \beta )}} = 0.5$.
对于区间数$\alpha = [{a^L}, {a^U}]$和$\beta = [{b^L}, {b^U}]$, α不小于β的可能度${P_{(\alpha \ge \beta )}}$满足下列性质:
1) $0 \le {P_{(\alpha \ge \beta )}} \le 1$;
2) ${P_{(\alpha \ge \alpha )}} = 0.5$;
3) ${P_{(\alpha \ge \beta )}} = 1 \Leftrightarrow {a^L} \ge {b^U}$;
4) ${P_{(\alpha \ge \beta )}} + {P_{(\beta \ge \alpha )}} = 1$.
由于直觉模糊数$A = \langle {{\mu _A}, {v_A}} \rangle$和$B = \langle {{\mu _B}, {v_B}} \rangle $可分别表示为区间数的形式$A = [{{\mu _A}, 1 -{v_A}}]$和$B = [{{\mu _B}, 1-{v_B}} ]$, 于是, 基于区间数间的排序规则, 可对A、B进行排序.
定义7. 基于可能度的直觉模糊数排序. $A = \langle {{\mu _A}, {v_A}} \rangle $和$B = \langle {{\mu _B}, {v_B}} \rangle $为两个直觉模糊数, 其中${\pi _A}$和${\pi _B}$不同时为零, 那么$A \ge B$的可能度${P_{(A \ge B)}}$定义为
$ \begin{align} {P_{(A \ge B)}} = \min \left\{ {1, \max \left\{ {\frac{{1 - {v_A} - {\mu _B}}}{{{\pi _A} + {\pi _B}}}, 0} \right\}} \right\} \end{align} $
(12) 当$\pi _A $和$\pi _B $同时为零时, A和B都表示精确数, 于是有$\mu _A >\mu _B \Rightarrow P_{(A\ge B)} =1, \mu _A <\mu _B \Rightarrow P_{(A\ge B)} =0, \mu _A =\mu _B \Rightarrow P_{(A\ge B)} =0.5$.
对于两个直觉模糊数$A=\langle {\mu _A, v_A } \rangle $和$B= \langle \mu _B, v_B \rangle, P_{(A\ge B)} $满足以下性质:
1) $0\le P_{(A\ge B)} \le 1$;
2) $P_{(A\ge A)} =0.5$;
3) $P_{(A\ge B)} =1\Leftrightarrow \mu _A \ge 1-v_B $;
4) $P_{(A\ge B)} +P_{(B\ge A)} =1$.
值得注意的是, 根据性质3)可得$P_{(A\ge B)} =1\Rightarrow \mu _A\ge 1-v_B $, 由$1-v_A \ge \mu _A , 1-v_B \ge \mu _B $, 可得$1 - v_A \ge \mu _A \ge 1-v_B \ge \mu _B $, 由此可进一步得到$\mu _A \ge \mu _B , v_A \le v_B $, 即$P_{(A\ge B)} =1\Rightarrow \mu _A \ge \mu _B, v_A \le v_B $, 但其逆命题不成立.
假设有N个直觉模糊数$A_1, A_2, \cdots, A_N $, 表示为$A_i =\langle {\mu _{A_i }, v_{A_i } } \rangle , i=1, 2, \cdots , N$, 那么根据定义7中的排序规则可对N个直觉模糊数进行排序, 过程如下:
1) 计算$A_i \ge A_j $的可能度.
$ \begin{align} P_{(A_i \ge A_j )} =\min \left\{ {1, \max \left\{ {\frac{1-v_{A_i } -\mu _{A_j } }{\pi _{A_i } +\pi _{A_j } }, 0} \right\}} \right\}, i, j=1, 2, \cdots, N \end{align} $
(13) 为简化表述, 可令$P_{ij} =P_{(A_i \ge A_j )} $.
2) 构造N个直觉模糊数之间的对比关系矩阵.
$ \begin{align} P=\left[{{\begin{array}{*{20}c} {P_{11} } \hfill & {P_{12} } \hfill & \cdots \hfill & {P_{1N} } \hfill \\ {P_{21} } \hfill & {P_{22} } \hfill & \cdots \hfill & {P_{2N} } \hfill \\ \vdots & \vdots & \ddots\hfill & \vdots \\ {P_{N1} } \hfill & {P_{N2} } \hfill & \cdots \hfill & {P_{NN} } \hfill \\ \end{array} }} \right] \end{align} $
(14) 显然, P满足$\forall i, j\in \{1, 2, \cdots, N\}, 0\le P_{ij} \le 1, P_{ij} + P_{ji} =1, P_{ii} =0.5$.
3) 计算矩阵P中每一行中所有元素的和, 可以得到
$ \begin{align} P_i =\sum\limits_{j=1}^N {P_{ij} } \end{align} $
(15) 4) 由于$P_i $反映了$A_i $不小于其他元素的可能度, 即$P_i \ge P_j \Rightarrow A_i \ge A_j $.因此, 可以根据$P_i $的大小顺序对$A_1, A_2, \cdots, A_n $进行排序.
该排序方法的具体实施过程, 如例1所示.
例1. 已知三个直觉模糊数分别为$A_1 =\langle 0.6, 0.3 \rangle , A_2 =\langle {0.45, 0.2} \rangle , A_3 =\langle {0.5, 0.25} \rangle $.
$A_1 $、$A_2 $和$A_3 $之间基于可能度的对比关系矩阵为
$ P=\left[{{\begin{array}{*{20}c} {0.50} & {0.56} & {0.57} \\ {0.44} & {0.50} & {0.50} \\ {0.43} & {0.50} & {0.50} \\ \end{array} }} \right] $
计算行和可得
$ \begin{align*} &P_1 =0.50+0.56+0.57=1.63 &P_2 =0.44+0.50+0.50=1.44 &P_3 =0.43+0.50+0.50=1.43 \end{align*} $
由于$P_1 >P_2 >P_3 $, 因此$A_1 $、$A_2 $和$A_3 $的排序结果为$A_1 >A_2 >A_3 $.
3.2 基于IFMCDM的证据可靠性评估
设$A=\{A_1, A_2, \cdots, A_m \}$为方案集, $X=\{x_1$, $x_2, \cdots, x_n \}$为属性集, 方案$A_i $在属性$x_j $下的评估结果表示为直觉模糊数$\langle {\mu _{ij}, v_{ij} } \rangle , i=1, 2, \cdots, m; j =1, 2, \cdots, n$. $\langle {\mu _{ij}, v_{ij} } \rangle $也可认为是方案$A_i $在属性$x_j$下满足理想方案的程度.直觉模糊多属性决策模型表述为A在X上的决策矩阵:
$ \begin{array}{l} F = {\left( {\left\langle {{\mu _{ij}},{v_{ij}}} \right\rangle } \right)_{m \times n}} = \\ \begin{array}{*{20}{c}} {{A_1}}\\ {{A_2}}\\ \vdots \\ {{A_m}} \end{array}\left( {\begin{array}{*{20}{l}} {{x_1}}&{{x_2}}& \cdots &{{x_n}}\\ {\left\langle {{\mu _{11}},{v_{11}}} \right\rangle }&{\left\langle {{\mu _{12}},{v_{12}}} \right\rangle }& \cdots &{\left\langle {{\mu _{1n}},{v_{1n}}} \right\rangle }\\ {\left\langle {{\mu _{21}},{v_{21}}} \right\rangle }&{\left\langle {{\mu _{22}},{v_{22}}} \right\rangle }& \cdots &{\left\langle {{\mu _{2n}},{v_{2n}}} \right\rangle }\\ \vdots & \vdots & \ddots & \vdots \\ {\left\langle {{\mu _{m1}},{v_{m1}}} \right\rangle }&{\left\langle {{\mu _{m2}},{v_{m2}}} \right\rangle }& \cdots &{\left\langle {{\mu _{mn}},{v_{mn}}} \right\rangle } \end{array}} \right) \end{array} $
(16) 根据前面的介绍, 可以将辨识框架$\Theta =\{\theta _1, \theta _2, \cdots, \theta _n \}$上的BPAF m转化为直觉模糊集, 直觉模糊数$\langle Bel(\theta _i ), 1-Pl(\theta _i )\rangle$可以看作该证据对$\theta _i $的支持度.在基于证据理论的目标融合识别系统中, 每个传感器以BPAF的形式给出对待识别目标身份的识别信息, 通常每个传感器反映了目标的不同属性, 对于传感器$S_k $提供的BPAF m而言, $\langle Bel(\theta _i ), 1 - Pl(\theta _i )\rangle$可以视为$\theta _i $在属性$S_k $下满足待识别目标真实类别的程度, 从这个意义上讲, 证据组合问题与直觉模糊多属性决策是等价的.
设$\Theta =\{\theta _1, \theta _2, \cdots, \theta _p \}$为辨识框架, q个待组合证据对应的BPA为$m_1, m_2, \cdots, m_q , Su_{ij} = \langle\mu _j (\theta _i ), v_j (\theta _i )\rangle$是$m_j $对$\theta _i $的支持度, 其中$\mu _j (A_i )= Bel_j (A_i ), v_j (A_i )=1-Pl_j (A_i ), i=1, 2, \cdots, p; j = 1, 2, \cdots , q$.那么, 该证据组合问题等价于如式(17)所示的直觉模糊多属性决策模型.
因此, 证据组合问题就转化为多属性条件下的方案评估问题, 各个证据的动态可靠性等价于多属性决策中各属性的权重, 接下来, 将提出一种基于IFMCDM的证据动态可靠性评估方法.
将证据组合问题转化为直觉模糊多属性决策问题以后, 可以利用直觉模糊多属性决策中属性权重的估计方法来对证据动态可靠性进行评估, 尽管相关学者提出了大量属性权重确定方法, 但这些方法大都是基于有序加权平均运算(Ordered weighted averaging, OWA)和非线性优化模型开展的, 有的还需要先验信息来提供所谓的理想方案.显然, 这些方法并不适用于缺乏先验知识条件下的证据动态可靠性评估.因此, 我们提出一种基于自我评估的证据动态可靠性评估方法.
在多属性决策中, 已知各个备选方案在各属性下的评估结果, 如果假设每一种方案为独立的"经济人", 由于"经济人"的显著特点在于追逐最大利益, 因此每一个"经济人" (方案)会将最大的权重赋给那些最支持它的属性.例如对于方案$A_i $而言, 在属性$x_j $下的评估结果为$\langle\mu _{ij}, v_{ij} \rangle$, 如果$\langle\mu _{ik} , v_{ik} \rangle = \max \{\langle\mu _{ij}, v_{ij} \rangle\}$, 那么$A_i $会给$x_k $赋予最大的权重, 但是这会带来另外一个问题, 即每一个方案把所有的权重都分配给最支持它的属性, 即$A_i $会给$x_k $赋予权重1, 其他各属性的权重为0, 这将会带来极大的信息损失, 并不利于最终的决策.我们需要既能够尊重最大评估结果所对应的属性$x_k $的优先地位, 又要充分利用各属性下的评估结果. 因此, 我们可以借助基于可能度的直觉模糊数排序方法构建一种属性权重估计方法, 进而实现证据动态可靠性评估.
方案$A_i $在属性$x_j $下的评估结果为$\langle\mu _{ij}, v_{ij} \rangle, i = 1, 2, \cdots, p; j=1, 2, \cdots, q$, 对于任意两个属性$x_j $和$x_k $下的评估结果$\langle\mu _{ij}, v_{ij} \rangle$和$\langle\mu _{ik}, v_{ik} \rangle$, 可以设$P_{_{(x_j \ge x_k )} }^{(i)} $为$\langle\mu _{ij}, v_{ij} \rangle$大于$\langle\mu _{ik}, v_{ik} \rangle$的可能度, 那么
$ \begin{align} F=&\ \left( {\left\langle {\mu _j (\theta _i ), v_j (\theta _i )} \right\rangle } \right)_{p\times q} ={\kern 1pt}{\begin{array}{*{20}c} & {\begin{array}{*{10}{l}}{\kern -9pt}{m_1}& ~~~{m_2}&~ \cdots &~ {m_q}\\ \end{array}}\\ {\begin{array}{c} \theta _1 \\ \theta _2 \\ \vdots \\ \theta _p \\ \end{array}} \hfill & {\left( {{\begin{array}{*{20}c} {Su_{11} } \hfill & {Su_{12} } \hfill & \cdots \hfill & {Su_{1q} } \hfill \\ {Su_{21} } \hfill & {Su_{22} } \hfill & \cdots \hfill & {Su_{2q} } \hfill \\ \vdots & \vdots & \ddots & \vdots \\ {Su_{p1} } \hfill & {Su_{p2} } \hfill & \cdots \hfill & {Su_{pq} } \hfill \\ \end{array} }} \right)} \hfill =\\ \end{array} } \notag\\[5mm] &{\begin{array}{*{20}c} & {\begin{array}{*{10}{l}}{\kern 7pt}{m_1}&\qquad\quad~~~~~~~ {m_2}&\qquad~~~ \cdots &\qquad~~~ {m_q}\\ \end{array}}\\ {\begin{array}{l} \theta _1 \\ \theta _2 \\ \vdots \\ \theta _p \\ \end{array}} \hfill & {\left( {{\begin{array}{*{20}c} {\left\langle {\mu _1 (\theta _1 ), v_1 (\theta _1 )} \right\rangle } \hfill & {\left\langle {\mu _2 (\theta _1 ), v_2 (\theta _1 )} \right\rangle } \hfill & \cdots \hfill & {\left\langle {\mu _q (\theta _1 ), v_q (\theta _1 )} \right\rangle } \hfill \\ {\left\langle {\mu _1 (\theta _2 ), v_1 (\theta _2 )} \right\rangle } \hfill & {\left\langle {\mu _2 (\theta _2 ), v_2 (\theta _2 )} \right\rangle } \hfill & \cdots \hfill & {\left\langle {\mu _q (\theta _2 ), v_q (\theta _2 )} \right\rangle } \hfill \\ \vdots & \vdots & \ddots & \vdots \\ {\left\langle {\mu _1 (\theta _p ), v_1 (\theta _p )} \right\rangle } \hfill & {\left\langle {\mu _2 (\theta _p ), v_2 (\theta _p )} \right\rangle } \hfill & \cdots \hfill & {\left\langle {\mu _q (\theta _p ), v_q (\theta _p )} \right\rangle } \hfill \\ \end{array} }} \right)} \hfill \\ \end{array} }\tag{17} \end{align} $
(17) $ P_{({x_j} \ge {x_k})}^{\left( i \right)} = \min \left\{ {1,\max \left\{ {\frac{{1 - {v_{ij}} - {\mu _{ik}}}}{{{\pi _{ij}} + {\pi _{ik}}}},0} \right\}} \right\} $
(18) 据此可以构建q个直觉模糊数之间的对比关系矩阵$P^{(i)}$
$ \begin{align} P^{(i)}=\left( {{\begin{array}{*{20}c} {P_{_{(x_1 \ge x_1 )} }^{(i)} } \hfill & {P_{_{(x_1 \ge x_2 )} }^{(i)} } \hfill & \cdots \hfill & {P_{_{(x_1 \ge x_q )} }^{(i)} } \hfill \\ {P_{_{(x_2 \ge x_1 )} }^{(i)} } \hfill & {P_{_{(x2\ge x_2 )} }^{(i)} } \hfill & \cdots \hfill & {P_{_{(x_2 \ge x_q )} }^{(i)} } \hfill \\ \vdots & \vdots & \ddots & \vdots \\ {P_{_{(x_q \ge x1)} }^{(i)} } \hfill & {P_{_{(xq\ge x_2 )} }^{(i)} } \hfill & \cdots \hfill & {P_{_{(x_q \ge x_q )} }^{(i)} } \hfill \\ \end{array} }} \right) \end{align} $
(19) 矩阵$P^{(i)}$第k行的和可以作为$x_k $大于其他各属性的可能度, 于是有
$ \begin{align} P_k^{(i)} =\sum\limits_{m=1}^q P _{km}^{(i)}, ~~~k=1, 2, \cdots, q \end{align} $
(20) 由于$P_k^{(i)} $反映了属性$x_k $下对$A_i $的评价结果不小于其他属性下评价结果的可能度, 即$P_k^{(i)}\ge P_j^{(i)} \Rightarrow \langle\mu _{ik}, v_{ik} \rangle\ge \langle\mu _{ij}, v_{ij} \rangle$, 因此, 可以根据$P_k^{(i)} $的大小顺序对$\langle\mu _{ij}, v_{ij} \rangle$进行排序, $j=1, 2, \cdots, q$.
根据"经济人"的假设, 最好的评估结果对应的属性应该被赋予最大的权重系数, 因此, 方案$A_i $对属性$x_j $赋予的权重可表示为
$ \begin{align} w_j^{(i)} =\frac{P_j^{(i)} }{\sum\limits_{m=1}^q {P_m^{(i)} } } \end{align} $
(21) 最终可以得到依据方案$A_i $获得的属性权重向量
$ \begin{align} {\boldsymbol w}^{(i)}=\left( {w_1^{(i)}, w_2^{(i)}, \cdots, w_q^{(i)} } \right)^{\rm T} \end{align} $
(22) 由于各个属性的权重是每个方案根据其在各个属性下的评价结果而得到的, 因此该方法也称为自主评价法.然而不难发现, 各个方案对赋予每个属性的权重系数不尽相同, 因此需要确定最终的权重系数.在此, 可以借鉴群决策的思想, 将每个方案提供的权重向量${\boldsymbol w}^{(i)}$视为不同专家对属性权重做出的决策, 可以假设最终的理想权重向量与所有${\boldsymbol w}^{(i)}$之间的夹角之和最小. 可以运用特征根法来求解理想权重向量, 设矩阵$W= ({\boldsymbol w}^{(1)}, {\boldsymbol w}^{(2)}, \cdots, {\boldsymbol w}^{(p)} )$, 那么方阵$WW^{\rm T}$的最大特征值所对应的特征向量${\boldsymbol w}$ (Perron-Frobenius向量)即为理想权重向量.由于同一特征值对应的特征向量并不唯一, 因此需要将${\boldsymbol w}$进行归一化
$ \begin{align} {\boldsymbol w}'=\frac{\boldsymbol w}{\sum\limits_{j=1}^q {w_j}} \end{align} $
(23) 最终, 基于证据动态可靠性与属性权重之间的关系, 可以得到证据的动态可靠性因子, 但是在证据动态可靠性评估中, 通常令最可靠的证据的可靠度为1, 因此归一化的证据动态可靠性因子可表示为
$ \begin{align} w_E =\frac{w}{\mathop {\max }\limits_{j=1, 2, \cdots, q} \{w_j\}} \end{align} $
(24) 以上证据可靠性评估方法称为基于直觉模糊多属性决策的证据可靠性评估(Evidence reliability evaluation based on IFMCDM, ERE-IFMCDM).
4. 基于复合可靠度的时域证据组合方法
文献[31]对时域证据融合中的可信度衰减模型进行了研究, 提出了基于实时可靠度的时域证据序贯组合方法, 时域证据的实时可靠性因子定义如下.
定义8. 实时可靠性因子(Real-time reliability factor, RTRF). 系统在$t_j $时刻所获取的BPAF $m_j $在时刻$t_i (t_i >t_j )$的实时可靠性因子为
$ \begin{align} \alpha _{ij} ={\rm e}^{-\lambda (t_i -t_j )} \end{align} $
(25) 其中, $\lambda >0$为可靠度衰减因子, 为减小信息损失, λ的取值范围为$0<\lambda <\ln 2$.
为便于表述, 当前时刻k记为$t_k $, 前一时刻k-1记为$t_{k-1}$, 各时刻的证据对应的BPAF为$m_k $和$m_{k-1}$, 根据可靠度衰减模型可知, 前一时刻的累积融合结果$m_{k-1}$在当前时刻的可靠性因子为$\alpha= {\rm e}^{-\lambda (t_k -t_{k-1} )}$, 因此当前时刻需要考虑的两个BPAF为$m_{k-1} $折扣后的BPAF $m_{k-1}^\alpha$和当前时刻各传感器的融合结果$m_k $.
时域证据融合的关键在于如何处理当前获得的最新证据$m_k$与前一时刻累积结果$m_{k-1}$之间的冲突, 虽然文献[31]提出的可靠度衰减模型可以用于冲突证据的组合, 但在计算证据可靠度只利用了时域信息本身的时效性, 与各时间节点的证据对应的BPAF无关, 而且没有考虑$m_k$与$m_{k-1}$之间的相互关系, 因此单纯依靠可信度衰减模型进行时域证据组合不够全面.为进一步增强时域融合算法对冲突信息的处理能力, 本节将在直觉模糊框架内对$m_k$和$m_{k-1}$的相对可靠性进行评估, 结合实时可靠性因子得到两个相邻时间节点间证据的复合可靠度, 进而确定折扣因子, 实现时域冲突信息的有效融合.
4.1 证据相对可靠性评估
根据第3节关于证据可靠性评估的论述可知, 基于证据距离的可靠性评估并不能用来对$m(k)$和$m(k-1)$的可靠性进行评估, 因为在只有两个证据的情况下, 最终的评估结果为两个证据的可靠性都为1, 无法对证据源进行折扣. 基于直觉模糊多属性决策模型的证据动态可靠性评估方法摆脱了对证据距离度量的依赖, 可用于对两个证据的动态可靠性进行评估, 因此可以基于此方法对时域证据$m(k)$和$m(k-1)$的可靠性进行评估, 其主要目的在于通过可靠性评估, 综合分析$m(k)$和$m(k-1)$在对当前时刻融合结果的影响程度.
设辨识框架为$\Theta =\{\theta _1, \theta _2, \cdots, \theta _n\}$, 根据基于IFMCDM的证据动态可靠性评估方法, 可以按如下流程对相邻时间节点间的证据进行可靠性评估.
1)根据可靠度衰减模型, 计算$m_{k-1} $在当前时刻的可靠度因子α:
$ \begin{align} \alpha ={\rm e}^{-\lambda (t_k -t_{k-1} )} \end{align} $
(26) 2)按照Shafer折扣准则, 对$m_{k-1} $进行折扣运算, 折扣后的BPAF为$m_{k-1}^\alpha $:
$ \begin{align} m_{k - 1}^\alpha (A) = \begin{cases} {{\rm e}^{ - \lambda ({t_k} - {t_{k - 1}})}} \times {m_{k - 1}}(A), &A \subset \Theta \\ {{\rm e}^{ - \lambda ({t_k} - {t_{k - 1}})}} \times {m_{k - 1}}(A) ~+&\\ \quad \ 1 - {{\rm e}^{ - \lambda ({t_k} - {t_{k - 1}})}}, &A = \Theta \end{cases} \end{align} $
(27) 3)将$m_{k-1}^\alpha $和$m_k $分别转换为对Θ的各单元素子集的支持度$Su_1 (\theta _i )$和$Su_2 (\theta _i ), i=1, 2, \cdots, n$, 设$Bel_1 $和$Bel_2 $分别为$m_{k-1}^\alpha $和$m_k $对应的信任函数, $Pl_1 $和$Pl_2 $分别为$m_{k-1}^\alpha $和$m_k $对应的似真函数, 那么$\forall \theta \in \Theta $, 其直觉模糊支持度表示为
$ \begin{align} Su_j (\theta )=\left\langle {Bel_j (\theta ), 1-Pl_j (\theta )} \right\rangle, \ \ j=1, 2 \end{align} $
(28) 4)根据$m_{k-1}^\alpha $和$m_k $对应的直觉模糊支持度建立多属性决策模型, 如式(29)所示.
$ \begin{align} F=&\ \left( {\left\langle {\mu _j (\theta _i ), v_j (\theta _i )} \right\rangle } \right)_{n\times 2} {\begin{array}{*{20}c} \hfill & {{\begin{array}{*{20}c}&~~{m_{k-1}^\alpha } &\quad~{m_k}\\ \end{array} }} \hfill \\ {\begin{array}{l} \theta _1 \\ \theta _2 \\ \vdots \\ \theta _n \\ \end{array}} \hfill & {\left( {{\begin{array}{*{20}c} {Su_1 (\theta _1 )} \hfill & {Su_2 (\theta _1 )} \hfill \\ {Su_1 (\theta _2 )} \hfill & {Su_2 (\theta _2 )} \hfill \\ \vdots & \vdots \\ {Su_1 (\theta _n )} \hfill & {Su_2 (\theta _n )} \hfill \\ \end{array} }} \right)}= \hfill \\ \end{array} }\notag \\[5mm] &\ {\begin{array}{*{20}c} \hfill & {{\begin{array}{*{20}c} &\qquad\quad {m_{k-1}^\alpha }&\qquad\qquad\qquad\quad~~~~~{m_k}\\ \end{array} }} \hfill \\ {\begin{array}{l} \theta _1 \\ \theta _2 \\ \vdots \\ \theta _n \\ \end{array}} \hfill & {\left( {{\begin{array}{*{20}c} {\left\langle {Bel_1 (\theta _1 ), 1-Pl_1 (\theta _1 )} \right\rangle } \hfill & {\left\langle {Bel_2 (\theta _1 ), 1-Pl_2 (\theta _1 )} \right\rangle } \hfill \\ {\left\langle {Bel_1 (\theta _2 ), 1-Pl_1 (\theta _2 )} \right\rangle } \hfill & {\left\langle {Bel_2 (\theta _1 ), 1-Pl_2 (\theta _1 )} \right\rangle } \hfill \\ \vdots& \vdots \\ {\left\langle {Bel_1 (\theta _n ), 1-Pl_1 (\theta _n )} \right\rangle } \hfill & {\left\langle {Bel_2 (\theta _n ), 1-Pl_2 (\theta _n )} \right\rangle } \hfill \\ \end{array} }} \right)} \end{array} }\tag{29} \end{align} $
(29) 5)根据基于可能度的直觉模糊数排序规则, 在$\theta _i (i=1, 2, \cdots , n)$的条件下计算$Su_1 (\theta _i )$大于$Su_2 (\theta _i )$的可能度为
$ \begin{array}{l} P_{(S{u_1} \ge S{u_2})}^{\left( i \right)} = \\ \;\;\;\;\;\;\min \left\{ {1,\max \{ \frac{{P{l_1}({\theta _i}) - Be{l_2}({\theta _i})}}{{P{l_1}({\theta _i}) + P{l_2}({\theta _i}) - Be{l_1}({\theta _i}) - Be{l_2}({\theta _i})}},0\} } \right\} \end{array} $
(30) 6) $\theta _i (i=1, 2, \cdots, n)$条件下$Su_1 (\theta _i )$与$Su_2 (\theta _i )$之间的对比关系矩阵为
$ \begin{align} {P^{(i)}} =&\ \left( {\begin{array}{*{20}{c}} {P_{_{(S{u_1} \ge S{u_1})}}^{(i)}}&{P_{_{(S{u_2} \ge S{u_1})}}^{(i)}}\\ {P_{_{(S{u_1} \ge S{u_2})}}^{(i)}}&{P_{_{(S{u_2} \ge S{u_2})}}^{(i)}} \end{array}} \right)=\notag \\[2mm] &\ \left( {\begin{array}{*{20}{c}} {0.5}&{P_{_{(S{u_2} \ge S{u_1})}}^{(i)}}\\ {P_{_{(S{u_1} \ge S{u_2})}}^{(i)}}&{0.5} \end{array}} \right) \end{align} $
(31) 7)根据$P^{(i)}$的行和, 可得到$\theta _i $赋予$m_{k-1}^\alpha $和$m_k $的权重分别为
$ \begin{align} \beta _1^{(i)} =&\ \dfrac{{\sum\limits_{j = 1}^2 P _{j1}^{(i)}}}{{\sum\limits_{j = 1}^2 P _{j1}^{(i)} + \sum\limits_{j = 1}^2 P _{j2}^{(i)}}}=\notag\\[2mm] &\ \dfrac{{0.5 + P_{_{(S{u_1} \ge S{u_2})}}^{(i)}}}{{0.5 + P_{_{(S{u_1} \ge S{u_2})}}^{(i)} + 0.5 + P_{_{(S{u_2} \ge S{u_1})}}^{(i)}}} \end{align} $
(32) $ \begin{align} \beta _2^{(i)} =&\ \dfrac{{\sum\limits_{j = 1}^2 P _{j2}^{(i)}}}{{\sum\limits_{j = 1}^2 P _{j1}^{(i)} + \sum\limits_{j = 1}^2 P _{j2}^{(i)}}}=\notag\\[2mm] &\ \dfrac{{0.5 + P_{_{(S{u_2} \ge S{u_1})}}^{(i)}}}{{0.5 + P_{_{(S{u_1} \ge S{u_2})}}^{(i)} + 0.5 + P_{_{(S{u_2} \ge S{u_1})}}^{(i)}}} \end{align} $
(33) 由于$P_{_{(Su_1 \ge Su_2 )} }^{(i)} +P_{_{(Su_2 \ge Su_1 )} }^{(i)} =1$, 因此, 依据$\theta _i $得到的权重向量为
$ \begin{align} {\boldsymbol \beta} ^{(i)}=\left( {\frac{0.5+P_{_{(Su_1 \ge Su_2 )} }^{(i)} }{2}, \frac{0.5+P_{_{(Su_2 \ge Su_1 )} }^{(i)} }{2}} \right)^{\rm T} \end{align} $
(34) 8)构造矩阵$W=\left( {\beta ^{(1)}, \beta ^{(2)}, \cdots, \beta ^{(n)}} \right)$, 矩阵$WW^{\rm T}$的最大特征值对应的特征向量即为$m_{k-1}^\alpha $和$m_k $的权重向量${\boldsymbol \beta} =(\beta _1, \beta _2 )^{\rm T}$, 即${\boldsymbol \beta} $满足
$ \begin{align} {\boldsymbol \beta} \left( {WW^{\rm T}} \right)=\lambda _{\max } \times WW^{\rm T} \end{align} $
(35) 9)为保证${\boldsymbol \beta}$的各分量均为正值, 对${\boldsymbol \beta}$进行归一化可得
$ \begin{align} {\boldsymbol \beta}'=\frac {{\boldsymbol \beta}}{\beta _1 +\beta _2}=\left( {{\beta }'_1, {\beta }'_2 } \right)^{\rm T} \end{align} $
(36) 10)对于证据$m_{k-1}^\alpha $和$m_k $而言, 权重较大的可以认为是完全可靠, 于是最终可得到$m_{k-1}^\alpha$和$m_k $的动态可靠性因子为
$ {r_1} = \frac{{{{\beta '}_1}}}{{\max \{ {{\beta '}_1},{{\beta '}_2}\} }} $
(37) $ {r_2} = \frac{{{{\beta '}_2}}}{{\max \{ {{\beta '}_1},{{\beta '}_2}\} }} $
(38) 由于$r_1 $为证据$m_{k-1}^\alpha $相对于$m_k $的可靠性因子, $r_2 $为$m_k $相对于$m_{k-1}^\alpha $的可靠性因子, 因此, 以上证据可靠性评估方法称为相对可靠性评估(Relative reliability evaluation, RRE), $r_1 $和$r_2 $称为相对可靠性因子(Relative reliability factor, RRF).
4.2 时域证据复合可靠度与证据折扣组合方法
在获得证据$m_{k-1}^\alpha $和$m_k $的相对可靠性因子以后, 需要依据Shafer折扣准则对相邻时间节点间的证据进行折扣运算, $m_{k-1}^\alpha $和$m_k $折扣后分别为
$ \begin{align} (m_{k-1}^\alpha )^{r_1}(A)=\begin{cases} r_1 \times m_{k-1}^\alpha (A), &A\subset \Theta \\ r_1 \times m_{k-1}^\alpha (A)+1-r_1, &A=\Theta \end{cases} \end{align} $
(39) $ \begin{align} m_k^{r_2 } (A)= \begin{cases} r_2 \times m_k (A), &A\subset \Theta \\ r_2 \times m_k (A)+1-r_2, &A=\Theta \\ \end{cases} \end{align} $
(40) 根据证据折扣运算的性质不难得到$(m_{k-1}^\alpha )^{r_1 }=m_{k-1}^{\alpha \cdot r_1 } $, 由于$m_k $在当前时刻的实时可靠性因子为1, 因此, $m_k^{r_2 } $可表示为$m_k^{1\cdot r_2 } $, 由此可见, 依据相对可靠性因子$r_1 $和$r_2 $分别对$m_{k-1}^\alpha $和$m_k $进行折扣, 等价于依据$r_1 \alpha $和$r_2 \times 1$对$m_{k-1} $和$m_k $进行折扣, 由此可得在当前时刻$m_{k-1} $和$m_k $的可靠度因子分别为$c_1 =r_1 \alpha $和$c_2 =r_2 \times 1$, 称$c_1 $和$c_2 $为时域证据的复合可靠性因子(Composite reliability factor, CRF). 显然, 时域证据融合中, 相邻时间节点的两个证据的复合可靠性因子(CRF)为实时可靠性因子(RTRF)与相对可靠性因子(RRF)的乘积.
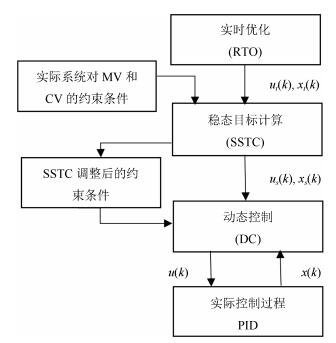
得到$m_{k-1} $和$m_k $的复合可靠性因子后, 可以按照Shafer折扣准则对$m_{k-1} $和$m_k$进行折扣运算, 然后再运用Dempster组合规则进行组合, 该过程称为基于复合可靠度的时域证据组合方法(Temporal evidence combination based on CRF, TEC-CRF), 按照此方法进行递归融合即可获得最终融合结果.根据时空信息递归分布无反馈融合模型[11], 可以得到基于复合可靠度的时空证据序贯组合方法, 如图 1所示. 其中, 虚线箭头表示证据折扣运算, 点划线箭头表示运用Dempster组合规则进行证据组合, 运用该方法可以对基于多传感器的时空信息进行融合.
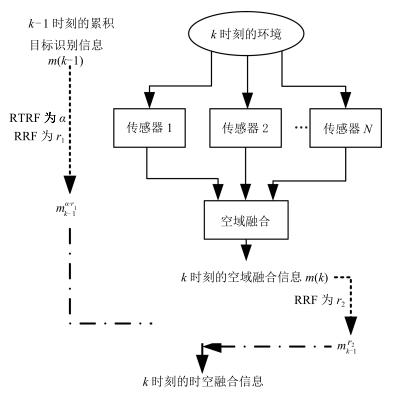 图 1 基于复合可靠度的时空证据序贯组合流程Fig. 1 The flowchart of spatial-temporal evidence combination based on TEC-CRF
图 1 基于复合可靠度的时空证据序贯组合流程Fig. 1 The flowchart of spatial-temporal evidence combination based on TEC-CRF4.3 数值算例与仿真
本小节通过决策层融合中的数值算例和实验仿真对基于复合可靠度的时域证据组合(TEC-CRF)方法的性能进行分析.
4.3.1 冲突处理能力分析
例2. 设辨识框架为$\Theta =\{\theta _1, \theta _2, \theta _3 \}$, 融合识别系统在$t_1 =10s$时的累积识别结果对应的BPAF为$m_1 $, 在当前时刻$t_2=12s$获得的最新识别信息对应的BPAF为$m_2 $, $m_1 $和$m_2 $分别表示如下:
$ \begin{align*} &m_1 (\{\theta _1 \})=0.6, ~m_1 (\{\theta _2 \})=0.1, ~m_1 (\{\theta _3 \})=0.3\\[1mm] &m_2 (\{\theta _1 \})=0.0, ~m_2 (\{\theta _2 \})=0.8, ~m_2 (\{\theta _3 \})=0.2\end{align*} $
在本算例中计算实时可靠性因子时, 取$\lambda =0.1$.
$m_1 $与$m_2 $在$t_2 $时刻的实时可靠性因子(RTRF)为
$ \begin{align*} &\alpha _1 ={\rm e}^{-0.1(12-10)}=0.82\\ &\alpha _2 =1\end{align*} $
$m_1 $按照其在当前时刻的RTRF折扣后的BPAF为
$ \begin{align*} &m_1^{\alpha_1} (\{ {\theta _1}\} ) = 0.492, ~~~{m_1^{\alpha_1}}(\{ {\theta _2}\} ) = 0.082 \\[1mm] &{m_1^{\alpha_1}}(\{ {\theta _3}\} ) = 0.246, ~~~{m_1^{\alpha_1}}(\Theta ) = 0.18 \end{align*} $
$m_1^{\alpha_1} $与$m_2 $的相对可靠性因子分别为$r_1 =1$, $r_2 = 0.48$.
由此可得$m_1 $与$m_2 $在$t_2 $时刻的复合可靠性因子为$c_1 =0.82, c_2=0.48$.
依据复合可靠性因子分别对$m_1$和$m_2$进行折扣可得
$ \begin{align*} &m_1^{c_1 } (\{\theta _1 \})=0.492, ~~~m_1^{c_1 } (\{\theta _2 \})=0.082\\ & m_1^{c_1 } (\{\theta _3 \})=0.246, ~~~m_1^{c_1 } (\Theta )=0.18 \\[2mm] &m_2^{c_2 } (\{\theta _1 \})=0.000, ~~~m_2^{c_2 } (\{\theta _2 \})=0.384\\ &m_2^{c_2 } (\{\theta _3 \})=0.096, ~~~m_2^{c_2 } (\Theta )=0.520 \end{align*} $
运用Dempster组合规则将$m_1^{c_1 } $和$m_2^{c_2 } $组合, 可得$t_2 $时刻的识别结果为
$ \begin{align*} &m_{12} (\{\theta _1 \})=0.38, ~~~m_{12} (\{\theta _2 \})=0.22 \\[1mm] &m_{12} (\{\theta _3 \})=0.25, ~~~m_{12} (\Theta )=0.15\end{align*} $
可以看出, 最终的融合结果中对$\{\theta _1 \}$的支持度最大, 与$m_1 $支持的命题一致.如果直接采用Dempster组合规则, 那么将会出现$m_{12} (\{\theta _1 \})=0$, 即使后面再获取的证据支持$\{\theta _1 \}$, 聚焦在$\{\theta _1 \}$上的BPM将一直为0, 从而陷入"一票否决"的困境.单纯依靠实时可靠性因子得到的结果中, $m_{12} (\{\theta _1 \})=0, m_{12} (\{\theta _2 \})=0.71, m_{12} (\{\theta _3\})=0.29$, 虽然随着后续证据的加入, $\{\theta _1\}$的支持度可能会上升, 但如果$t_2$时刻就是最后的识别节点, 系统在该时刻受到严重干扰, 那么基于实时可靠性因子的方法将会得到错误的结果, 导致决策失误.由此可知, 基于复合可靠度的时域证据融合方法能够较好地处理相邻证据之间的冲突, 有利于做出合理的决策.
4.3.2 抗干扰能力分析
例3. 在例2的基础上, 系统在$t_3=15s$获得的识别信息对应的BPAF为$m_3$, 为进一步说明该组合方法的性能, 分别考虑$m_3$支持$\theta _1$和$\theta _2$这两种情况.
1) $m_3 (\{\theta _1 \})=0.5, m_3 (\{\theta _2 \})=0.3, m_3 (\{\theta _3\}) = 0.2$;
2) $m_3 (\{\theta _1 \})=0.1, m_3 (\{\theta _2 \})=0.75, m_3 (\{\theta _3\}) = 0.15$.
按照基于复合可靠度的时域证据组合方法分别对以上两种情况下的证据进行组合, 时域组合结果如表 1所示. 从表 1可以看出, 在这两种情况下获得的最终结果明显不同. 在情况1)下得到的融合结果支持$\{\theta _1\}$, 而情况2)下的结果则支持$\{\theta_2\}$. 情况1)下的$m_3$与$m_1$比较接近, 都倾向于支持 $\{\theta_1\}$, 这种情况可以理解为在$t_2$时刻系统受到干扰, 获得错误的识别信息, 导致在$t_2$时刻的累积识别信息中, $\{\theta_1\}$的支持度有所下降;在$t_3$时刻, 系统恢复正常, 因此此时的融合结果中$\{\theta_1\}$的支持度明显上升, 最终决策结果为$\{\theta _1 \}$. 在情况2)下, $m_3$与$m_2 $比较接近, 都倾向于支持$\{\theta _2 \}$, 可以理解为在$t_1$时刻系统获得的识别结果有较大偏差, 随着时间的推移, 获取的信息越来越准确, 对$\{\theta_2 \}$的支持度逐渐上升, 最终决策结果为$\{\theta_2\}$.这表明TEC-CRF方法对证据的变化较为敏感, 能够较好地处理时域融合识别中的冲突信息, 有助于提升融合识别系统的抗干扰能力.
表 1 两种情况下TEC-CRF方法的融合结果Table 1 The combination results obtained by TEC-CRF for two cases$m_3$ RTRF ${m_{12}}$折扣后的BPA RRF CRF 最终融合结果 ${m_3}(\{{\theta_1}\})=0.5$ $m_{12}^{{\alpha_1}}(\{{\theta_1}\})=0.2815$ $m_{13}^{{\alpha_1}}(\{{\theta_1}\})=0.4930$ ${m_3}(\{{\theta_2}\})=0.3$ ${\alpha _1}=0.7408$ $m_{12}^{{\alpha_1}}(\{{\theta_2}\})=0.1630$ $r_1=1$ $c_1=0.7408$ $m_{13}^{{\alpha_1}}(\{{\theta_2}\})=0.2491$ ${m_3}(\{{\theta_3}\})=0.2$ ${\alpha _2} = 1$ $m_{12}^{{\alpha_1}}(\{{\theta_3}\})=0.1852$ $r_2=0.8785$ $c_2=0.8785$ $m_{13}^{{\alpha_1}}(\{{\theta_3}\})=0.1853$ ${m_3}(\Theta)=0$ $m_{12}^{{\alpha_1}}(\Theta)=0.4092$ $m_{13}^{{\alpha_1}}(\Theta)=0.0726$ ${m_3}(\{{\theta_1}\})=0.1$ $m_{12}^{{\alpha_1}}(\{{\theta_1}\})=0.2815$ $m_{13}^{{\alpha_1}}(\{{\theta_1}\})=0.2183$ ${m_3}(\{{\theta_2}\})=0.15$ ${\alpha _1}=0.7408$ $m_{12}^{{\alpha_1}}(\{{\theta_2}\})=0.1630$ $r_1=1 $ $c_1=0.7408$ $m_{13}^{{\alpha_1}}(\{{\theta_2}\})=0.3540$ ${m_3}(\{{\theta_3}\})=0.75$ ${\alpha _2} = 1$ $m_{12}^{{\alpha_1}}(\{{\theta_3}\})=0.1630$ $r_2=0.4806$ $c_2=0.4806$ $m_{13}^{{\alpha_1}}(\{{\theta_3}\})=0.1691$ ${m_3}(\Theta)=0$ $m_{12}^{{\alpha_1}}(\Theta)=0.4092$ $m_{13}^{{\alpha_1}}(\Theta)=0.2586$ 为了与Dempster组合方法和文献[31]中基于实时可靠度的时域证据组合方法进行对比, 表 2和表 3给出了两种情况下分别运用Dempster方法和基于实时可靠度的时域证据组合方法(Temporal evidence combination based on RTRF, TEC-RTRF)的融合结果.
表 2 两种情况下Dempster方法的融合结果Table 2 The combination results obtained by Dempster's rule for two cases$m_3$ $t_{2}$时刻融合结果 $t_{3}$时刻融合结果 ${m_3}(\{{\theta_1}\})=0.5$ $m_{12}(\{{\theta_1}\})=0$ $m_{13}(\{{\theta_1}\})=0$ ${m_3}(\{{\theta_2}\})=0.3$ $m_{12}(\{{\theta_2}\})=0.57$ $m_{13}(\{{\theta_2}\})=0.67$ ${m_3}(\{{\theta_3}\})=0.2$ $m_{12}(\{{\theta_3}\})=0.43$ $m_{13}(\{{\theta_3}\})=0.33$ ${m_3}(\{{\theta_1}\})=0.1$ $m_{12}(\{{\theta_1}\})=0$ $m_{13}(\{{\theta_1}\})=0$ ${m_3}(\{{\theta_2}\})=0.15$ $m_{12}(\{{\theta_2}\})=0.57$ $m_{13}(\{{\theta_2}\})=0.87$ ${m_3}(\{{\theta_3}\})=0.75$ $m_{12}(\{{\theta_3}\})=0.43$ $m_{13}(\{{\theta_3}\})=0.13$ 表 3 两种情况下TEC-RTRF方法的融合结果Table 3 The combination results obtained by TEC-RTRF for two cases$m_3$ $t_{2}$时刻融合结果 $t_{3}$时刻融合结果 ${m_3}(\{{\theta_1}\})=0.5$ $m_{12}(\{{\theta_1}\})=0$ $m_{13}(\{{\theta_1}\})=0.35$ ${m_3}(\{{\theta_2}\})=0.3$ $m_{12}(\{{\theta_2}\})=0.71$ $m_{13}(\{{\theta_2}\})=0.44$ ${m_3}(\{{\theta_3}\})=0.2$ $m_{12}(\{{\theta_3}\})=0.29$ $m_{13}(\{{\theta_3}\})=0.21$ ${m_3}(\{{\theta_1}\})=0.1$ $m_{12}(\{{\theta_1}\})=0$ $m_{13}(\{{\theta_1}\})=0.05$ ${m_3}(\{{\theta_2}\})=0.15$ $m_{12}(\{{\theta_2}\})=0.71$ $m_{13}(\{{\theta_2}\})=0.83$ ${m_3}(\{{\theta_3}\})=0.75$ $m_{12}(\{{\theta_3}\})=0.29$ $m_{13}(\{{\theta_3}\})=0.12$ 可以看出, 在情况1)下, 系统在$t_2$时刻受到干扰, 运用Dempster组合方法时, 由于没有考虑证据的可靠性, 得到的融合结果对$\{\theta_1\}$的支持度为0, 尽管后续的证据对$\{\theta _1\}$的支持度较大, 但最终的融合结果依然不支持$\{\theta _1 \}$, 系统无法从干扰状态恢复出来; 运用TEC-RTRF方法虽然在$t_3$的融合结果中$\{\theta_1\}$的支持度有所上升, 但增幅较小, 系统虽然可以从干扰状态恢复, 但恢复速度较慢.
在情况2)下, 可以认为是初始时刻的信息偏差较大, 运用Dempster组合方法和TEC-RTRF方法都有利于得到正确的结果, 但存在较大风险, 如果后续时刻再次受到干扰, 那么融合识别系统将无法恢复或恢复速度较慢.对比这三种方法可知, TEC-CRF方法的抗干扰能力最强, 具有较高的可靠性, 对初始干扰、识别过程中的干扰都有较强的抵抗能力, 适合用来进行时域信息融合. 不考虑证据折扣的经典Dempster组合方法和TEC-RTRF方法的抗干扰能力则非常有限, 在时域证据融合中的适用性较差.
4.3.3 数值仿真
本仿真基于弹道中段目标综合识别仿真系统开展, 本系统立足于在多传感器平台, 在有限时间内对目标进行连续观测, 多次识别采用图 1所示的时空证据组合流程进行融合识别.
在综合识别仿真系统中, 6个传感器位于不同的平台上, 各传感器之间以及同一雷达各时间节点之间的探测信息互不影响, 满足证据理论中各证据源相互独立的要求, 特征提取及分类器设计不属于本文研究范畴, 故在此不作具体说明.待识别目标可能的类别为: 弹头、气球和碎片, 因此, 辨识框架为$\Theta = \{\theta_1(弹头), \theta_2(气球), \theta_3(碎片)\}$, 根据6个传感器在连续5个时间节点的探测信息对目标类别进行识别, 基于某特定战情设置, 各传感器在各识别节点的识别结果对应的BPAF如表 4所示.
表 4 各传感器在不同时间节点的识别结果Table 4 Recognition results of each sensor at all time nodes时间节点(s) BPM $S_{1}$ $S_{2}$ $S_{3}$ $S_{4}$ $S_{5}$ $S_{6}$ $m(\{{\theta_1}\})$ 0.250 0.300 0.211 0.333 0.629 0.305 $t_{1}=5$ $m(\{{\theta_2}\})$ 0.299 0.256 0.350 0.273 0.352 0.212 $m(\{{\theta_3}\})$ 0.451 0.444 0.429 0.394 0.019 0.483 $m(\{{\theta_1}\})$ 0.440 0.628 0.435 0.348 0.642 0.530 $t_{2}=8$ $m(\{{\theta_2}\})$ 0.323 0.136 0.325 0.262 0.252 0.118 $m(\{{\theta_3}\})$ 0.237 0.236 0.240 0.390 0.106 0.352 $m(\{{\theta_1}\})$ 0.251 0.454 0.269 0.460 0.623 0.124 $t_{3}=16$ $m(\{{\theta_2}\})$ 0.276 0.236 0.336 0.215 0.142 0.420 $m(\{{\theta_3}\})$ 0.473 0.310 0.395 0.325 0.235 0.456 $m(\{{\theta_1}\})$ 0.337 0.318 0.262 0.246 0.435 0.312 $t_{4}=23$ $m(\{{\theta_2}\})$ 0.303 0.269 0.203 0.262 0.259 0.342 $m(\{{\theta_3}\})$ 0.360 0.413 0.535 0.492 0.306 0.346 $m(\{{\theta_1}\})$ 0.336 0.346 0.241 0.368 0.330 0.303 $t_{5}=26$ $m(\{{\theta_2}\})$ 0.312 0.305 0.258 0.262 0.301 0.391 $m(\{{\theta_3}\})$ 0.352 0.349 0.501 0.370 0.369 0.306 表 5和表 6给出了在5个时间节点对各传感器的识别结果进行融合得到的空域融合结果. 在空域融合中可以选用的方法较多, 因此这里只给出了利用经典Dempster组合方法和文献[32]中提出的基于证据信任度和虚假度的证据组合方法(EC-CF方法)的计算结果.
表 5 运用Dempster组合规则获得的空域融合结果Table 5 Spatial evidence combination results obtained by Dempster's rule时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.5529 0.2850 0.1621 $t_{2}=8$ 0.9489 0.0077 0.0134 $t_{3}=16$ 0.3216 0.0829 0.5955 $t_{4}=23$ 0.1715 0.0703 0.7582 $t_{5}=26$ 0.2365 0.1737 0.5898 表 6 运用EC-CF方法获得的空域融合结果Table 6 Spatial evidence combination results obtained by EC-CF时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.2322 0.1299 0.6379 $t_{2}=8$ 0.9509 0.0189 0.0302 $t_{3}=16$ 0.4425 0.0993 0.5482 $t_{4}=23$ 0.1951 0.0920 0.7129 $t_{5}=26$ 0.2546 0.1956 0.5498 从表 5和表 6中可以看出, 在$t_1 $时刻两种方法的计算结果有较大差异, 这是由于在该时刻的识别结果中, 传感器$S_5$获得的结果与其他5个传感器的识别结果直接有较大的冲突, 直观来看, $S_1, S_2, S_3 , S_4 , S_6 $这5个传感器的识别结果都支持$\{\theta _3 \}$, 只有$S_5 $倾向于$\{\theta _1 \}$, 因此该时刻的融合结果应该赋予$\{\theta _3\}$最大的支持度, 可见运用EC-CF方法可以得到与直观分析一致的融合结果. 从$t_2 \sim t_5$时刻的空域融合结果可看出, 对于低冲突证据而言, EC-CF方法与Dempster方法的结果相差不大; 另外, 由于该实验中识别框架的基数不大, 而且各BPAF均聚焦在单元素子集上, 相对于Dempster方法, EC-CF方法不会带来时间复杂度的大幅提升, 因此在空域融合中, 可以运用EC-CF方法对各传感器的识别结果进行融合, 以降低冲突信息的影响.接下来的时域融合即为对在各时间节点使用EC-CF方法获得的空域融合结果进行序贯融合, 该仿真实验中证据可靠度衰减因子λ的取值为0.05.
为了对比分析TEC-CRF方法在时空信息融合中的性能, 表 7给出了使用Dempster组合规则进行时域证据累积的结果, 表 8给出了运用TEC-CRF方法获得各时间节点的时域累积识别结果.
表 7 运用Dempster组合规则获得的时域累积融合结果Table 7 Spatial evidence combination results obtained by Dempster's rule时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.2322 0.1299 0.6379 $t_{2}=8$ 0.9105 0.0101 0.0794 $t_{3}=16$ 0.9151 0.0023 0.0827 $t_{4}=23$ 0.7512 0.0009 0.2480 $t_{5}=26$ 0.5835 0.0005 0.4160 表 8 运用TEC-CRF方法获得的时域累积融合结果Table 8 Temporal evidence accumulation results obtained by TEC-CRF时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $m(\Theta)$ $t_{1}=5$ 0.2322 0.1299 0.6379 0 $t_{2}=8$ 0.9414 0.0168 0.0418 0.1247 $t_{3}=16$ 0.6570 0.0360 0.1466 0.1633 $t_{4}=23$ 0.4241 0.0445 0.3610 0.1704 $t_{5}=26$ 0.2903 0.1275 0.5823 0 从表 7和表 8中可以看出, 在$t_2 =8s$的时候, 系统受到干扰, 导致该时刻的累积识别结果对$\{\theta _1\}$的支持度大于$\{\theta _3\}$, 但随着后续识别信息的加入, 两种组合方法都可以使$\{\theta_3\}$的支持度逐渐上升, 但由于TEC-CRF方法考虑了时域证据可靠性的衰减以及相邻证据间的相对可靠度, 因此运用TEC-CRF方法可以使系统尽快地从干扰状态恢复过来, 到$t_5 =26s$时, 可以得到最终的识别结果为$\{\theta _3\}$, 而在此时运用Dempster组合方法的结果则依然将目标识别为$\{\theta _1 \}$, 与直观分析不一致.
为便于进行直观分析, 图 2和图 3分别给出了基于Dempster方法和TEC-CRF方法进行时域融合时Pignistic概率分布随时间的变化趋势. 从图中可以看出, 运用Dempster方法进行时域融合时, 在$t_2 $时刻以后, $BetP_m \{\theta _1 \}$下降的较慢, 而$BetP_m \{\theta _3 \}$上升的也较慢, 到$t_5 =26s$时, $BetP_m \{\theta _1 \}$依然大于$BetP_m \{\theta _3 \}$, 因此目标被识别为$\{\theta _1 \}$.而运用TEC-CRF方法进行时域融合时, 在干扰过后, $BetP_m \{\theta _1 \}$急剧下降, $BetP_m \{\theta _3 \}$上升的速度也较快, 在最终时刻由$BetP_m \{\theta _2 \}<BetP_m \{\theta _1 \}<BetP_m \{\theta _3 \}$, 可将目标识别为$\{\theta _3 \}$, 符合直观分析.这说明基于TEC-CRF的时域融合方法更有利于进行实时决策.
 图 2 基于Dempster组合方法的时域累积融合结果Fig. 2 Temporal evidence accumulation results obtained by Dempster's rule
图 2 基于Dempster组合方法的时域累积融合结果Fig. 2 Temporal evidence accumulation results obtained by Dempster's rule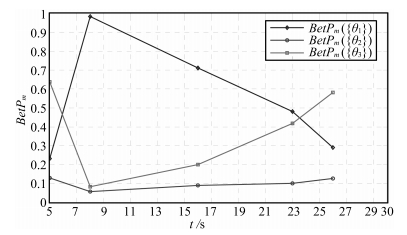 图 3 基于TEC-CRF方法的时域累积融合结果Fig. 3 Temporal evidence accumulation results obtained by TEC-CRF
图 3 基于TEC-CRF方法的时域累积融合结果Fig. 3 Temporal evidence accumulation results obtained by TEC-CRF根据两种方法的计算过程可知, 运用Dempster组合方法进行时域证据组合时, 没有考虑时间因素的影响, 只是单纯地将证据序列依次组合.本文提出的TEC-CRF方法则充分考虑了时域证据融合的两个显著特点, 即证据可靠度随时间的变化和相邻两个时间节点获得的证据之间的相互关系.为了说明时间因素对时域证据融合的影响, 对本例中$t_1 $时刻获得的证据$m_{t_1 } $与$t_2 $时刻获得的证据$m_{t_2 } $进行交换, 即各传感器在$t_1 $时刻和$t_2 $时刻获得的识别结果对应的BPAF如表 9所示, 其余各时间节点的识别结果保持不变.
表 9 各传感器在$t_{1}$和$t_{2}$时刻的识别结果Table 9 Recognition results of each sensor at $t_{1}$ and $t_{2}$时间节点(s) BPM $S_{1}$ $S_{2}$ $S_{3}$ $S_{4}$ $S_{5}$ $S_{6}$ $m(\{{\theta_1}\})$ 0.440 0.628 0.435 0.348 0.642 0.530 $t_{1}=5$ $m(\{{\theta_2}\})$ 0.323 0.136 0.325 0.262 0.252 0.118 $m(\{{\theta_3}\})$ 0.237 0.236 0.240 0.390 0.106 0.352 $m(\{{\theta_1}\})$ 0.250 0.300 0.211 0.333 0.629 0.305 $t_{2}=8$ $m(\{{\theta_2}\})$ 0.299 0.256 0.350 0.273 0.352 0.212 $m(\{{\theta_3}\})$ 0.451 0.444 0.429 0.394 0.019 0.483 表 10和表 11给出了${m_{{t_1}}}$与${m_{{t_2}}}$交换后各时刻的空域融合结果, 可以看出在$t_1$和$t_2$时刻的空域融合结果进行了互换, 其余时刻的空域融合结果则保持不变, 符合空域证据融合的特点.
表 10 基于Dempster方法的空域融合结果Table 10 Spatial evidence combination results based on Dempster's rule时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.9789 0.0077 0.0134 $t_{2}=8$ 0.5529 0.2850 0.1621 $t_{3}=16$ 0.3216 0.0829 0.5955 $t_{4}=23$ 0.1715 0.0703 0.7582 $t_{5}=26$ 0.2365 0.1737 0.5898 表 11 基于EC-CF方法的空域融合结果Table 11 Spatial evidence combination results based on EC-CF时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.9509 0.0189 0.0302 $t_{2}=8$ 0.2322 0.1299 0.6379 $t_{3}=16$ 0.4425 0.0993 0.5482 $t_{4}=23$ 0.1951 0.0920 0.7129 $t_{5}=26$ 0.2546 0.1956 0.5498 运用Dempster组合方法和TEC-CRF方法对表 11中运用EC-CF方法获得的空域融合结果进行时域累积, 各时刻的时域累积融合结果如表 12和表 13所示.
表 12 基于Dempster方法的时域累积融合结果Table 12 Temporal evidence combination results based on Dempster's rule时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $t_{1}=5$ 0.9509 0.0189 0.0302 $t_{2}=8$ 0.9105 0.0101 0.0794 $t_{3}=16$ 0.9151 0.0023 0.0827 $t_{4}=23$ 0.7512 0.0009 0.2480 $t_{5}=26$ 0.5835 0.0005 0.4160 表 13 基于TEC-CRF方法的时域累积融合结果Table 13 Temporal evidence accumulation results based on TEC-CRF时间节点(s) $m({\theta _1})$ $m({\theta _2})$ $m({\theta _3})$ $m(\Theta)$ $t_{1}=5$ 0.9509 0.0189 0.0302 0 $t_{2}=8$ 0.5427 0.0751 0.3822 0 $t_{3}=16$ 0.4300 0.0558 0.3441 0.1701 $t_{4}=23$ 0.2854 0.0510 0.4868 0.1768 $t_{5}=26$ 0.2321 0.1158 0.6521 0 对比表 12和表 7可看出, 运用Dempster组合规则时, 除了$t_1 $时刻的累积融合结果即该时刻的空域融合结果发生变化外, 其余各时间节点的累积识别结果不会发生变化, 表现出了与空域融合相同的特点, 没能体现时域证据融合动态性的特点.
从表 13可以看出, TEC-CRF方法在任一时刻获得的累积融合结果都与表 8中对应的结果不同, 由于$t_1 $时刻的空域融合结果与后续的结果冲突较大, 而后续各时刻的空域融合结果之间冲突较小, 因此可以认为系统在$t_1 $时刻受到干扰或信息不准确而导致识别信息有较大偏差.随着对目标的不断识别, $t_1 $时刻结果的可靠度逐渐降低, 新到的识别信息较为准确而且可靠度较高, 因此时域累积识别结果不断更新.可以看出在新的条件下, 根据$t_4 $时刻的累积结果即可做出合理的决策, $t_5$时刻的累积结果则进一步增强了决策的合理性, 充分体现了时域证据融合结果的继承与更新. 而且, 容易验证, 使用TEC-CRF方法时, 任何两个时间间隔的改变、识别信息获取顺序的改变都可能会带来时域融合结果的变化, 这说明TEC-CRF方法对时间是敏感的, 符合时域信息融合的特点.
同样, 为直观分析$m_{t_1 } $与$m_{t_2 } $的交换带来时域累积融合结果的变化, 图 4和图 5分别给出了$m_{t_1}$与$m_{t_2}$交换后, 两种方法获得的Pignistic概率变化趋势. 对比图 4与图 2可以看出, 运用Dempster组合方法进行时域融合时, 除了在初始时刻的Pignistic概率分布不相同以外, 前两个时间节点信息的交换并不影响后续各时刻的Pignistic概率分布. 对图 5和图 3进行对比可知, 运用TEC-CRF方法时, $m_{t_1}$与$m_{t_2}$的交换造成所有时刻的累积融合结果都发生了变化, 表明TEC-CRF方法可以充分体现时间因素对时域融合的影响.
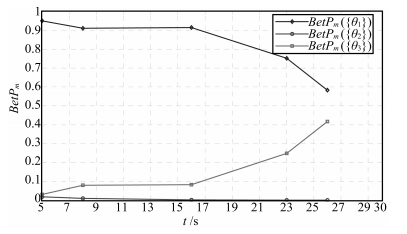 图 4 Dempster方法获得的Pignistic概率Fig. 4 The Pignistic probability obtained by Dempster's rule
图 4 Dempster方法获得的Pignistic概率Fig. 4 The Pignistic probability obtained by Dempster's rule5. 结束语
为了实现基于证据理论的时域不确定信息融合, 进一步增强时空信息融合系统对冲突信息的处理能力, 本文在对时域证据融合中相邻时间节点间的信息进行对比分析的基础上, 结合基于直觉模糊多属性决策的证据可靠性评估方法, 给出了相对可靠度的概念, 在此基础上结合时域证据可靠度衰减模型及时域证据实时可靠度的概念, 提出了一种基于复合可靠度的时域证据组合方法(TEC-CRF)方法, 基于TEC-CRF方法构建了时空信息序贯融合模型.数值算例和实验仿真验证了TEC-CRF方法的性能特点, 结果表明, TEC-CRF方法可以较好地处理时域信息间的冲突, 对时间变化较为敏感, 充分体现了时域融合动态性的特点, 即当前时刻融合结果是对前一时刻融合结果的继承与更新.需要说明的是, 时域信息融合是一个复杂的工程问题, 在实际应用中还有诸多因素需要考虑, 为实现时域信息的有效融合, 有必要将本文所提方法与其他相关理论结合起来, 这也是我们下一步的研究方向.
-
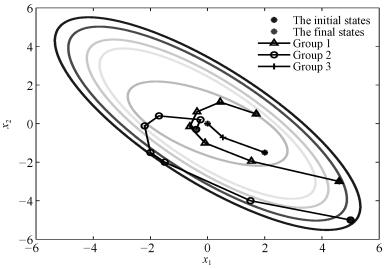
图 3 控制时刻$k$从31到60对应的纸机系统控制过程
Fig. 3 Control process of the paper system with the control moment $k$ from 31 to 60
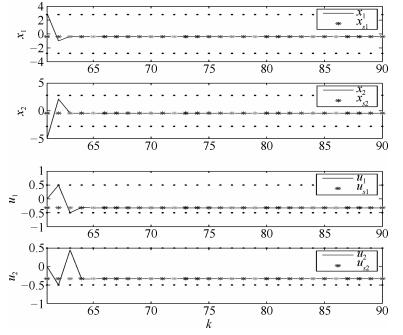
图 4 控制时刻$k$从61到90对应的纸机系统控制过程
Fig. 4 Control process of the paper system with the control moment $k$ from 61 to 90
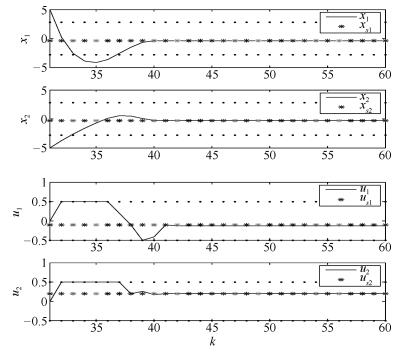
图 5 控制时刻$k$从31到60对应的双积分系统控制过程
Fig. 5 Control process of the double-integrator system with the control moment $k$ from 31 to 60
表 1 本文符号及其含义
Table 1 The meanings of the notations in this paper
符号 含义 $x^*$ $x$的最优值 ${\bf R}^n$ $n$维欧氏空间 $k$ 离散采样间隔 $x$ 系统状态, $x \in {\bf R}^{n_x}$ $u$ 系统输入, $u \in {\bf R}^{n_u}$ $x_s(u_s)$ 稳态状态(输入) $x_t(u_t)$ 期望稳态状态(输入) $\bar{x}(\bar{u})$ 状态(输入)上界 $I_n $ $n$维单位矩阵 $Q_s, R_s$ 适维权重矩阵 $N_i$ 第$i$个镇定域所对应的控制时域 ${\| x\|}_{Q_s}^2$ $x^{\rm T}$$Q_s$$x$ $x(k+i|k)$ $k$时刻对未来状态的预测值 $u(k+i|k) $ $k$时刻对未来输入的预测值  下载: 导出CSV
下载: 导出CSV
表 2 纸机系统的稳态目标计算结果
Table 2 The results of the SSTC in the AS DPS system
$k$ $u_{s, 1}$ $u_{s, 2}$ $x_{s, 1}$ $x_{s, 2}$ $1\sim90$ -0.39 -0.41 -0.32 -0.33
下载: 导出CSV
表 3 双积分器系统的稳态目标计算结果
Table 3 The results of SSTC in the double-integrator system
k $u_t$ $x_t$ $u_s$ $x_s$ $1\sim30$ (0, 0) (2, -2) (0, 0) (2, 0.5) $31\sim60$ (0, 0) (0, -2) (-0.1, 0.2) (-0.38, 0.2998) $61\sim90$ (0, 0) (0, 0) (0, 0) (0, 0)
下载: 导出CSV
-
[1] 席裕庚, 李德伟.预测控制定性综合理论的基本思想和研究现状.自动化学报, 2008, 34 (10):1225-1234 http://www.aas.net.cn/CN/abstract/abstract17992.shtmlXi Yu-Geng, Li De-Wei. Fundamental philosophy and status of qualitative synthesis of model predictive control. Acta Automatica Sinica, 2008, 34 (10):1225-1234 http://www.aas.net.cn/CN/abstract/abstract17992.shtml [2] 席裕庚, 李德伟, 林姝.模型预测控制-现状与挑战.自动化学报, 2013, 39 (3):222-236 http://www.aas.net.cn/CN/abstract/abstract17874.shtmlXi Yu-Geng, Li De-Wei, Lin Shu. Model predictive control-status and challenges. Acta Automatica Sinica, 2013, 39 (3):222-236 http://www.aas.net.cn/CN/abstract/abstract17874.shtml [3] 席裕庚.预测控制.第2版.北京:国防工业出版社, 2013. 15-67Xi Yu-Geng. Predictive Control (Second Edition). Beijing:National Defense Industry Press, 2013. 15-67 [4] Sildir H, Arkun Y, Cakal B, Gokce D, Kuzu E. Plant-wide hierarchical optimization and control of an industrial hydrocracking process. Journal of Process Control, 2013, 23 (9):1229-1240 doi: 10.1016/j.jprocont.2013.07.007 [5] Darby M L, Nikolaou M, Jones J, Nicholson D. RTO:an overview and assessment of current practice. Journal of Process Control, 2011, 21 (6):874-884 doi: 10.1016/j.jprocont.2011.03.009 [6] Scattolini R. Architectures for distributed and hierarchical model predictive control-a review. Journal of Process Control, 2009, 19 (5):723-731 doi: 10.1016/j.jprocont.2009.02.003 [7] 李世卿, 丁宝苍.基于动态矩阵控制的双层结构预测控制的整体解决方案.自动化学报, 2015, 41 (11):1857-1866 http://www.aas.net.cn/CN/abstract/abstract18761.shtmlLi Shi-Qing, Ding Bao-Cang. An overall solution to double-layered model predictive control based on dynamic matrix control. Acta Automatica Sinica, 2015, 41 (11):1857-1866 http://www.aas.net.cn/CN/abstract/abstract18761.shtml [8] 李世卿, 丁宝苍, 孙耀.双层预测控制中基于操作变量增量的多优先级稳态目标计算.控制理论与应用, 2015, 32 (2):239-245 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=kzllyyy201502014Li Shi-Qing, Ding Bao-Cang, Sun Yao. Multi-priority rank steady-state target calculation in double-layered model predictive control by optimizing increments of manipulated variables. Control Theory & Applications, 2015, 32 (2):239-245 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=kzllyyy201502014 [9] Mayne D Q, Rawlings J B, Rao C V, Scokaert P O M. Constrained model predictive control:stability and optimality. Automatica, 2000, 36 (6):789-814 doi: 10.1016/S0005-1098(99)00214-9 [10] Gutman P O, Cwikel M. An algorithm to find maximal state constraint sets for discrete-time linear dynamical systems with bounded controls and states. IEEE Transactions on Automatic Control, 1987, 32 (3):251-254 doi: 10.1109/TAC.1987.1104567 [11] Gilbert E G, Tan K T. Linear systems with state and control constraints:the theory and application of maximal output admissible sets. IEEE Transactions on Automatic Control, 1991, 36 (9):1008-1020 doi: 10.1109/9.83532 [12] 潘红光, 高海南, 孙耀, 张英, 丁宝苍.基于多优先级稳态优化的双层结构预测控制算法及软件实现.自动化学报, 2014, 40 (3):405-414 http://www.aas.net.cn/CN/abstract/abstract18305.shtmlPan Hong-Guang, Gao Hai-Nan, Sun Yao, Zhang Ying, Ding Bao-Cang. The algorithm and software implementation for double-layered model predictive control based on multi-priority rank steady-state optimization. Acta Automatica Sinica, 2014, 40 (3):405-414 http://www.aas.net.cn/CN/abstract/abstract18305.shtml [13] Blanchini F. Set invariance in control. Automatica, 1999, 35 (11):1747-1767 doi: 10.1016/S0005-1098(99)00113-2 [14] Li Z J, Tan W, Nian S C, Liu J Z. A stabilizing model predictive control for linear systems with input saturation. In: Proceedings of the 2006 International Conference on Machine Learning and Cybernetics. Dalian, China: IEEE, 2006. 671-675 [15] Li Z J, Liu J Z, Tan W. Multi-model H_∞ loop shaping controller for nonlinear system based on gap metric. In: Proceedings of the ICARCV 8th Control, Automation, Robotics and Vision Conference. Kunming, China: IEEE, 2004, 3: 1940-1944 [16] Kosut R. Design of linear systems with saturating linear control and bounded states. IEEE Transactions on Automatic Control, 1983, 28 (1):121-124 doi: 10.1109/TAC.1983.1103127 [17] 李志军. 约束模型预测控制的稳定性与鲁棒性研究[博士学位论文], 华北电力大学(北京), 中国, 2005.Li Zhi-Jun. Research on Stability and Robustness of Constrained Model Predictive Control[Ph. D. dissertation], North China Electric Power University (Beijing), China, 2005. [18] Limon D, Alvarado I, Alamo T, Camacho E F. MPC for tracking piecewise constant references for constrained linear systems. Automatica, 2008, 44 (9):2382-2387 doi: 10.1016/j.automatica.2008.01.023 [19] Chen H, Allgöwer F. A quasi-infinite horizon nonlinear model predictive control scheme with guaranteed stability. Automatica, 1998, 34 (10):1205-1217 doi: 10.1016/S0005-1098(98)00073-9 [20] 曹永岩, 毛维杰, 孙优贤, 冯旭.现代控制理论的工程应用.杭州:浙江大学出版社, 2000.Cao Yong-Yan, Mao Wei-Jie, Sun You-Xian, Feng Xu. Engineering Application of Modern Control Theory. Hangzhou:Zhejiang University Press, 2000. [21] Pluymers B, Rossiter J A, Suykens J A K, Moor B D. The efficient computation of polyhedral invariant sets for linear systems with polytopic uncertainty. In: Proceedings of the 2005 American Control Conference. Portland, OR, USA: IEEE, 2005, 2: 804-809 期刊类型引用(17)
1. 左常祁,张秋荣,周偲怡. 基于IFCM-DEMATEL的海员职业健康与安全风险评价. 中国航海. 2024(02): 25-31+39 .  百度学术
百度学术2. 董煜,张友鹏. 基于聚类赋权的冲突证据组合方法. 通信学报. 2023(03): 157-163 . 百度学术3. 董煜,董雪旺,董红生,周科. 基于Lance可信度的冲突证据组合方法. 现代电子技术. 2023(17): 29-33 . 百度学术4. 卢盈齐,范成礼,付强,朱晓雯,李威. 基于改进IFRS相似度和信息熵的反导作战目标威胁评估. 系统工程与电子技术. 2022(04): 1230-1238 . 百度学术5. 周志杰,唐帅文,胡昌华,曹友,王杰. 证据推理理论及其应用. 自动化学报. 2021(05): 970-984 . 本站查看6. 苏建烨. 毕达哥拉斯模糊信息集成算法应用于企业资源计划系统. 模糊系统与数学. 2020(03): 89-97 . 百度学术7. 郑焕科,张晶,杨亚琦,熊梅惠. 多属性决策的时间不确定事件流时序推理方法. 山东大学学报(理学版). 2020(07): 67-80 . 百度学术8. Yafei SONG,Jingwei ZHU,Lei LEI,Xiaodan WANG. Self-adaptive combination method for temporal evidence based on negotiation strategy. Science China(Information Sciences). 2020(11): 56-68 . 必应学术9. 李旭峰,宋亚飞,李晓楠. 考虑决策者时序偏好的时域证据融合方法. 计算机应用. 2019(06): 1626-1631 . 百度学术10. 方明清,丁刚毅,赵艳玲. 毕达哥拉斯决策算法应用于云计算产品选择. 计算机工程与应用. 2019(18): 241-246 . 百度学术11. 尹亮,袁飞,谢文波,王栋志,孙崇敬. 关联图谱的研究进展及面临的挑战. 计算机科学. 2018(S1): 1-10+35 . 百度学术12. 陈云翔,罗承昆,王攀,蔡忠义,李超. 考虑可靠性的时域证据组合方法. 控制与决策. 2018(03): 463-470 . 百度学术13. 黄大荣,柴彦冲,赵玲,孙国玺. 考虑多源不确定信息的路网交通拥堵状态辨识方法. 自动化学报. 2018(03): 533-544 . 本站查看14. 王沫楠. 基于血液供给条件和力学环境的骨折愈合仿真. 自动化学报. 2018(02): 240-250 . 本站查看15. 高晓阳,王刚. 基于改进时域证据融合的目标识别. 系统工程与电子技术. 2018(12): 2629-2635 . 百度学术16. LUO Chengkun,CHEN Yunxiang,XIANG Huachun,WANG Weijia,WANG Zezhou. Evidence combination method in time domain based on reliability and importance. Journal of Systems Engineering and Electronics. 2018(06): 1308-1316 . 必应学术17. Ju Wang,Fuxian Liu. Temporal evidence combination method for multi-sensor target recognition based on DS theory and IFS. Journal of Systems Engineering and Electronics. 2017(06): 1114-1125 . 必应学术其他类型引用(11)
-

 下载:
下载:


计量
- 文章访问数: 2017
- HTML全文浏览量: 246
- PDF下载量: 876
- 被引次数: 28
