

Adaptive Predictive Proportional-integral-resonant Current Control for Permanent Magnet Synchronous Motors
-
摘要: 考虑数字控制系统一个采样周期输入延时和驱动器功率管非线性特性的影响,为增强永磁同步电机(Permanent magnet synchronous motor,PMSM)电流环稳定性和提高电流控制精度,提出一种自适应预测比例-积分-谐振控制(Adaptive predictive proportional-integral-resonant,APPI-RES)策略.该方法能够在电机电阻和电感参数不确定的条件下,预测电流控制误差和未知周期电压扰动,将所得预测量执行反馈控制,实现了对系统输入延时和相电流谐波的有效补偿.最后,通过仿真分析验证了所提控制策略的有效性.
-
关键词:
- 永磁同步电机 /
- 自适应预测比例-积分-谐振控制器 /
- 输入延时 /
- 参数不确定 /
- 相电流畸变
Abstract: In order to enhance the stability of current loop and to improve the current control accuracy, an adaptive predictive proportional-integral-resonant (APPI-RES) current control strategy is proposed, in which the one cycle delay of digital control system and the nonlinear characteristic of voltage source inverter (VSI) are considered. The proposed method can predict the control errors of currents, unknown constant and periodic voltage disturbances when the resistor and inductance of the motor are unknown. Then, the predicted variables are used to execute the feedback control to compensate the system input delay and the phase current harmonics effectively. At last, simulation results verify the feasibility of the control strategy. -
近些年来, 由于多智能体协同控制在编队控制[1]、机器人网络[2]、群集行为[3]、移动传感器[4-5]等方面的广泛应用, 多智能体系统的协同控制问题受到了众多研究者的广泛关注.一致性问题是多智能体系统协同控制领域的一个关键问题, 其目的是通过与邻居之间的信息交换, 使所有智能体的状态达成一致.迄今为止, 对多智能体一致性的研究也已取得了丰硕的成果, 根据多智能体的动力学模型分类, 主要可以将其分为以下4种情形:一阶[6-9]、二阶[10-13]、三阶[14-15]、高阶[16-18].
在实际应用中, 由于CPU处理速度和内存容量的限制, 智能体不能频繁地进行控制以及与其邻居交换信息.因此, 事件触发控制策略作为减少控制次数和通信负载的有效途径, 受到了越来越多的关注.到目前为止, 对事件触发控制机制的研究也取得了很多成果[19-23].Xiao等[19]基于事件触发控制策略, 解决了带有领航者的离散多智能体系统的跟踪问题.通过利用状态测量误差并且基于二阶离散多智能体系统动力学模型, Zhu等[20]提出了一种自触发的控制策略, 该策略使得所有智能体的状态均达到一致. Huang等[21]研究了基于事件触发策略的Lur$'$e网络的跟踪问题.针对不同的领航者-跟随者系统, Xu等[22]提出了3种不同类型的事件触发控制器, 包含分簇式控制器、集中式控制器和分布式控制器, 以此来解决对应的一致性问题.然而, 大多数现有的事件触发一致性成果集中于考虑一阶多智能体系统和二阶多智能体系统, 很少有成果研究三阶多智能体系统的事件触发控制问题, 特别是对于三阶离散多智能体系统, 成果更是少之又少.所以, 设计相应的事件触发控制协议来解决三阶离散多智能体系统的一致性问题已变得尤为重要.
本文研究了基于事件触发控制机制的三阶离散多智能体系统的一致性问题, 文章主要有以下三点贡献:
1) 利用位置、速度和加速度三者的测量误差, 设计了一种新颖的事件触发控制机制.
2) 利用不等式技巧, 分析得到了保证智能体渐近收敛到一致状态的充分条件.与现有的事件触发文献[19-22]不同的是, 所得的一致性条件与通信拓扑的Laplacian矩阵特征值和系统的耦合强度有关.
3) 给出了排除类Zeno行为的参数条件, 进而使得事件触发控制器不会每个迭代时刻都更新.
1. 预备知识
1.1 代数图论
智能体间的通信拓扑结构用一个有向加权图来表示, 记为.其中, $\vartheta = \left\{ {1, 2, \cdots, n} \right\}$表示顶点集, $\varsigma\subseteq\vartheta\times\vartheta$表示边集, 称作邻接矩阵, ${a_{ij}}$表示边$\left({j, i} \right) \in \varsigma $的权值.当$\left({j, i} \right) \in \varsigma $时, 有${a_{ij}} > 0$; 否则, 有${a_{ij}} = 0$. ${a_{ij}} > 0$表示智能体$i$能收到来自智能体$j$的信息, 反之则不成立.对任意一条边$j$, 节点$j$称为父节点, 节点$i$则称为子节点, 节点$i$是节点$j$的邻居节点.假设通信拓扑中不存在自环, 即对任意$i\in \vartheta $, 有${a_{ii}} = 0$.
定义$L = \left({{l_{ij}}}\right)\in{\bf R}^{n\times n}$为图${\cal G}$的Laplacian矩阵, 其中元素满足${l_{ij}} = - {a_{ij}} \le 0, i \ne j$; ${l_{ii}} = \sum\nolimits_{j = 1, j \ne i}^n {{a_{ij}} \ge 0} $.智能体$i$的入度定义为${d_i} = \sum\nolimits_{j = 1}^n {{a_{ij}}} $, 因此可得到$L = D - \Delta $, 其中, .如果有向图中存在一个始于节点$i$, 止于节点$j$的形如的边序列, 那么称存在一条从$i$到$j$的有向路径.特别地, 如果图中存在一个根节点, 并且该节点到其他所有节点都有有向路径, 那么称此有向图存在一个有向生成树.另外, 如果有向图${\cal G}$存在一个有向生成树, 则Laplacian矩阵$L$有一个0特征值并且其他特征值均含有正实部.
1.2 模型描述
考虑多智能体系统由$n$个智能体组成, 其通信拓扑结构由有向加权图${\cal G}$表示, 其中每个智能体可看作图${\cal G}$中的一个节点, 每个智能体满足如下动力学方程:
$ \begin{equation} \left\{ \begin{array}{l} {x_i}\left( {k + 1} \right) = {x_i}\left( k \right) + {v_i}\left( k \right)\\ {v_i}\left( {k + 1} \right) = {v_i}\left( k \right) + {z_i}\left( k \right)\\ {z_i}\left( {k + 1} \right) = {z_i}\left( k \right) + {u_i}\left( k \right) \end{array} \right. \end{equation} $
(1) 其中, ${x_i}\left(k \right) \in \bf R$表示位置状态, ${v_i}\left(k \right) \in \bf R$表示速度状态, ${z_i}\left(k \right) \in \bf R$表示加速度状态, ${u_i}\left(k \right) \in \bf R$表示控制输入.
基于事件触发控制机制的控制器协议设计如下:
$ \begin{equation} {u_i}\left( k \right) = \lambda {b_i}\left( {k_p^i} \right) + \eta {c_i}\left( {k_p^i} \right) + \gamma {g_i}\left( {k_p^i} \right), k \in \left[ {k_p^i, k_{p + 1}^i} \right) \end{equation} $
(2) 其中, $\lambda> 0$, $\eta> 0$, $\gamma> 0$表示耦合强度,
$ \begin{align*}&{b_i}\left( k \right)= \sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{x_j}\left( k \right) - {x_i}\left( k \right)} \right)} , \nonumber\\ &{c_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{v_j}\left( k \right) - {v_i}\left( k \right)} \right)}, \nonumber\\ & {g_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{z_j}\left( k \right) - {z_i}\left( k \right)} \right)} .\end{align*} $
触发时刻序列定义为:
$ \begin{equation} k_{p + 1}^i = \inf \left\{ {k:k > k_p^i, {E_i}\left( k \right) > 0} \right\} \end{equation} $
(3) ${E_i}\left(k \right)$为触发函数, 具有以下形式:
$ \begin{align} {E_i}\left( k \right)= & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|- {\delta _2}{\beta ^k} - \nonumber\nonumber\\ &{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| \end{align} $
(4) 其中, ${\delta _1} > 0$, ${\delta _2} > 0$, $\beta > 0$, , ${e_{ci}}\left(k \right) = {c_i}\left({k_p^i} \right) - {c_i}\left(k \right)$, ${e_{gi}}\left(k \right) = {g_i}\left({k_p^i} \right) - {g_i}\left(k \right)$.
令$\varepsilon _i\left(k\right)={x_i}\left(k\right)-{x_1}\left(k\right)$, ${\varphi _i}\left(k\right)={v_i}\left(k \right)-$ ${v_1}\left(k\right)$, ${\phi _i}(k) = {z_i}(k) - {z_1}\left(k \right)$, $i = 2, \cdots, n$. , $\cdots, {\varphi _n}\left(k \right)]^{\rm T}$, $\phi \left(k \right) = {\left[{{\phi _2}\left(k \right), \cdots, {\phi _n}\left(k \right)} \right]^{\rm T}}$. $\psi \left(k \right) = {\left[{{\varepsilon ^{\rm T}}\left(k \right), {\varphi ^{\rm T}}\left(k \right), {\phi ^{\rm T}}\left(k \right)} \right]^{\rm T}}$, , ${\bar e_b} = {\left[{{e_{b1}}\left(k \right), \cdots, {e_{b1}}\left(k \right)} \right]^{\rm T}}$, , ${e_{c1}}\left(k \right)]^{\rm T}$, , ${\bar e_g} = $ ${\left[{{e_{g1}}\left(k \right), \cdots, {e_{g1}}\left(k \right)} \right]^{\rm T}}$, $\tilde e\left(k \right) = [\tilde e_b^{\rm T}\left(k \right), \tilde e_c^{\rm T}\left(k \right), $ $\tilde e_g^{\rm T}\left(k \right)]^{\rm T}$, $\bar e\left(k \right) = [\bar e_b^{\rm T}\left(k \right), \bar e_c^T\left(k \right), \bar e_g^{\rm T}\left(k \right)]^{\rm T}$,
$ \hat L = \left[ {\begin{array}{*{20}{c}} {{d_2} + {a_{12}}}&{{a_{13}} - {a_{23}}}& \cdots &{{a_{1n}} - {a_{2n}}}\\ {{a_{12}} - {a_{32}}}&{{d_3} + {a_{13}}}& \cdots &{{a_{1n}} - {a_{3n}}}\\ \vdots & \vdots & \ddots & \vdots \\ {{a_{12}} - {a_{n2}}}&{{a_{13}} - {a_{n3}}}& \cdots &{{d_n} + {a_{1n}}} \end{array}} \right] $
再结合式(1)和式(2)可得到:
$ \begin{equation} \psi \left( {k + 1} \right) = {Q_1}\psi \left( k \right) + {Q_2}\left( {\tilde e\left( k \right) - \bar e\left( k \right)} \right) \end{equation} $
(5) 其中, , .
定义1.对于三阶离散时间多智能体系统(1), 当且仅当所有智能体的位置变量、速度变量、加速度变量满足以下条件时, 称系统(1)能够达到一致.
$ \begin{align*} &{\lim _{k \to \infty }}\left\| {{x_j}\left( k \right) - {x_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{v_j}\left( k \right) - {v_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{z_j}\left( k \right) - {z_i}\left( k \right)} \right\| = 0 \\&\quad\qquad \forall i, j = 1, 2, \cdots , n \end{align*} $
定义2.如果$k_{p + 1}^i - k_p^i > 1$, 则称触发时刻序列$\left\{ {k_p^i} \right\}$不存在类Zeno行为.
假设1.假设有向图中存在一个有向生成树.
2. 一致性分析主要结果
假设$\kappa$是矩阵${Q_1}$的特征值, ${\mu _i}$是$L$的特征值, 则有如下等式成立:
$ {\rm{det}}\left( {\kappa {I_{3n - 3}} - {Q_1}} \right)=\nonumber\\ \det \left(\! \!{\begin{array}{*{20}{c}} {\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\!&\!{{0_{n - 1}}}\\ {{0_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\\ {\lambda {{\hat L}_{n - 1}}}\!&\!{\eta {{\hat L}_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}} + \gamma {{\hat L}_{n - 1}}} \end{array}} \!\!\right)=\nonumber\\ \prod\limits_{i = 2}^n {\left[ {{{\left( {\kappa - 1} \right)}^3} + \left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i}} \right]} $
令
$ \begin{align} {m_i}\left( \kappa \right)= &{\left( {\kappa - 1} \right)^3} + \nonumber\\&\left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i} = 0, \nonumber\\& \qquad\qquad\qquad\qquad\qquad i = 2, \cdots , n \end{align} $
(6) 则有如下引理:
引理1[15]. 如果矩阵$L$有一个0特征值且其他所有特征值均有正实部, 并且参数$\lambda $, $\eta $, $\gamma $满足下列条件:
$ \left\{ \begin{array}{l} 3\lambda - 2\eta < 0\\ \left( {\gamma - \eta + \lambda } \right)\left( {\lambda - \eta } \right) < - \dfrac{{\lambda \Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}}\\ \left( {4\gamma + \lambda - 2\eta } \right)<\dfrac{{8\Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}} \end{array} \right. $
那么, 方程(6)的所有根都在单位圆内, 这也就意味着矩阵${Q_1}$的谱半径小于1, 即$\rho \left({{Q_1}} \right) < 1$.其中, 表示特征值${\mu _i}$的实部.
引理2[23]. 如果, 那么存在$M \ge 1$和$0 < \alpha < 1$使得下式成立
$ {\left\| {{Q_1}} \right\|^k} \le M{\alpha ^k}, \quad k \ge 0 $
定理1. 对于三阶离散多智能体系统(1), 基于假设1, 如果式(2)中的耦合强度满足引理1中的条件, 触发函数(4)中的参数满足$0 < {\delta _1} < 1$, , $0 < \alpha < \beta < 1$, 则称系统(1)能够实现渐近一致.
证明.令$\omega \left(k \right) = \tilde e\left(k \right) - \bar e\left(k \right)$, 式(5)能够被重新写成如下形式:
$ \begin{equation} \psi \left( k \right) = Q_1^k\psi \left( 0 \right) + {Q_2}\sum\limits_{s = 0}^{k - 1} {Q_1^{k - 1 - s}\omega \left( s \right)} \end{equation} $
(7) 根据引理1和引理2可知, 存在$M \ge 1$和$0 < \alpha < 1$使得下式成立.
$ \begin{align} \left\| {\psi \left( k \right)} \right\|\le & {\left\| {{Q_1}} \right\|^k}\left\| {\psi \left( 0 \right)} \right\| + \nonumber\\ & \left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{{\left\| {{Q_1}} \right\|}^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|}\le \nonumber\\ & M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+\nonumber\\ & M\left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{\alpha ^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|} \end{align} $
(8) 由触发条件可得:
$ \begin{align} & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ & \qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^k}\le\nonumber\\ &\qquad {\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\| + {\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\| + \nonumber\\ &\qquad{\delta _1}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\|+ {\delta _1}\left| {{e_{bi}} \left( k \right)} \right| + \nonumber\\ &\qquad{\delta _1}\left| {{e_{ci}} \left( k \right)} \right|+ {\delta _1}\left| {{e_{gi}}\left( k \right)} \right| + {\delta _2}{\beta ^k} \end{align} $
(9) 对上式移项可求解得:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le \nonumber\\ &\qquad\frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\|}}{{1 - {\delta _1}}} + \frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\|}}{{1 - {\delta _1}}}{\rm{ + }}\nonumber\\ &\qquad\frac{{{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(10) 又因为, 和, 可得出下列不等式:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ &\qquad \frac{{{\delta _1}\left\| L \right\|}}{{1 - {\delta _1}}} \cdot \left( {\left\| {\varepsilon \left( k \right)} \right\|{\rm{ + }}\left\| {\varphi \left( k \right)} \right\|{\rm{ + }}\left\| {\phi \left( k \right)} \right\|} \right) +\nonumber\\ &\qquad \frac{{{\delta _2}{\beta ^k}}}{{1 - {\delta _1}}}\le \frac{{3{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(11) 接着有如下不等式成立:
$ \begin{align} \left\| {e\left( k \right)} \right\|\le \frac{{3\sqrt n {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{\sqrt n {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(12) 其中, , ${e_b}(k) = \left[{{e_{b1}}(k), \cdots, {e_{bn}}(k)} \right]$, ${e_c}(k) = \left[{{e_{c1}}(k), \cdots, {e_{cn}}(k)} \right]$,
注意到
$ \begin{equation} \left\| {\tilde e( k )} \right\| + \left\| {\bar e( k )} \right\| \le \sqrt {6( {n - 1} )} \left\| {e( k )} \right\| \end{equation} $
(13) 于是有
$ \begin{align} \left\| {\omega ( k )} \right\| &= \left\| {\tilde e( k ) - \bar e\left( k \right)} \right\| \le\nonumber\\ & \left\| {\tilde e\left( k \right)} \right\| + \left\| {\bar e\left( k \right)} \right\|\le\nonumber\\ & \frac{{3\sqrt {6n( {n - 1} )} {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| +\nonumber\\ & \frac{{\sqrt {6n( {n - 1} )} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(14) 把式(14)代入式(8)可得
$ \begin{align} \left\| {\psi \left( k \right)} \right\| &\le M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+ \nonumber\\ &\frac{{M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}} {\delta _1}3\sqrt {6n\left( {n - 1} \right)} \left\| L \right\|}}{{1 - {\delta _1}}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}}\left\| {\psi \left( s \right)} \right\|} + M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}} \frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}} {{1 - {\delta _1}}}{\beta ^s}} \end{align} $
(15) 接下来的部分, 将证明下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| \le W{\beta ^k}.\end{equation} $
(16) 其中, $W = \max \left\{ {{\Theta _1}, {\Theta _2}} \right\}$,
首先, 证明对任意的$\rho > 1$, 下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| < \rho W{\beta ^k} \end{equation} $
(17) 利用反证法, 先假设式(17)不成立, 则必将存在${k^ * } > 0$使得并且当$k \in \left({0, {k^ * }} \right)$时$\left\| {\psi \left(k \right)} \right\| < \rho W{\beta ^k}$成立.因此, 根据式(17)可得:
$ \begin{align*} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le\\ &\qquad M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} +\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}M\times \end{align*} $
$ \begin{align*} &\qquad\sum\limits_{s = 0}^{{k^ * } - 1} {\alpha ^{ - s}}\left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot \left\| {\psi \left( s \right)} \right\|}}{{1 - {\delta _1}}}} \right]+ \\ &\qquad M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^s}} \right]} < \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} + \rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}\times\\ &\qquad \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot W{\beta ^s}}} {{1 - {\delta _1}}}} \right]} +\\ &\qquad\rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}{\beta ^s}}}{{1 - {\delta _1}}}} \right]=} \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}}- \nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\alpha ^{{k^ * }}}+\nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\beta ^{{k^ * }}} \end{align*} $
1) 当$W = M\left\| {\psi \left(0 \right)} \right\|$时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\| - \nonumber\\ &\qquad \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} \ge 0 \end{aligned} \end{equation*} $
所以可得到
$ \begin{equation} \rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le \rho M\left\| {\psi \left( 0 \right)} \right\|{\beta ^{{k^ * }}}=\rho W{\beta ^{{k^ * }}} \end{equation} $
(18) 2) 当时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\|- \nonumber\\ &\qquad\frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} < 0 \end{aligned} \end{equation*} $
所以有
$ \begin{align} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\|\le\nonumber\\ & \frac{{\rho {\delta _2}M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} {\beta ^{{k^ * }}}}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right) - 3{\delta _1}M\left\| {{Q_2}} \right\|\left\| L \right\|\sqrt {6n\left( {n - 1} \right)} }}=\nonumber\\ &\rho W{\beta ^{{k^ * }}} \end{align} $
(19) 根据以上结果, 式(18)和式(19)都与假设相矛盾.这说明原命题成立, 即对任意的$\rho > 1$, 式(17)成立.易知, 如果$\rho \to 1$, 则式(16)成立.根据式(16)可知, 当$k \to + \infty $时, 有, 则系统(5)是收敛的.由$\psi \left(k \right)$的定义可知, 系统(1)能够实现渐近一致.
定理2. 对于系统(1), 如果定理1中的条件成立, 并且控制器(2)中的设计参数满足如下条件,
$ {\delta _1} \in \left( {\frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}}, 1} \right)\\ {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } $
那么触发序列中的类Zeno行为将被排除.
证明. 易知排除类Zeno行为的关键是要证明不等式$k_{p + 1}^i - k_p^i > 1$成立.根据事件触发机制可知, 下一个触发时刻将会发生在触发函数(4)大于0时.进而可得到如下不等式
$ \begin{align} &\left| {{e_{bi}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{ci}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{gi}}\left( {k_{p + 1}^i} \right)} \right|\ge\nonumber\\ &\qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{align} $
(20) 定义, .结合式(20), 可得到下式
$ \begin{equation} {G_i}\left( {k_{p + 1}^i} \right) \ge {\delta _1}{H_i}\left( {k_p^i} \right) + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{equation} $
(21) 结合式(16)和式(21)可得
$ \begin{align} {\delta _2}{\beta ^{k_{p + 1}^i}} &\le {G_i}\left( {k_{p + 1}^i} \right) - {\delta _1}{H_i}\left( {k_p^i} \right)\le\nonumber\\ & \left\| L \right\|\left( {\left\| {\psi \left( {k_p^i} \right)} \right\| + \left\| {\psi \left( {k_{p + 1}^i} \right)} \right\|} \right)\le\nonumber\\ & W\left\| L \right\|\left( {{\beta ^{k_p^i}} + {\beta ^{k_{p + 1}^i}}} \right) \end{align} $
(22) 求解上式得
$ \begin{equation} \left( {{\delta _2} - \left\| L \right\|W} \right){\beta ^{k_{p + 1}^i}} \le \left\| L \right\|W{\beta ^{k_p^i}} \end{equation} $
(23) 根据式(23)可得
$ \begin{equation} k_{p + 1}^i - k_p^i > \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}} } {\ln \beta } \end{equation} $
(24) 基于(24)易知当时, 有如下不等式成立
$ \begin{equation} \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}}} {\ln \beta } > 1 \end{equation} $
(25) 此外, 因为$W = M\left\| {\psi \left(0 \right)} \right\|$以及
$ \begin{equation} {\delta _1} > \frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}} \end{equation} $
(26) 又可以得出
$ \begin{equation} {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } = \frac{{\left\| L \right\|W\left( {1 + \beta } \right)}}{\beta } \end{equation} $
(27) 该式意味着式(25)成立, 又结合式(24)易知$k_{p + 1}^i - k_p^i > 1$, 即排除类Zeno行为的条件得已满足.
注2.类Zeno行为广泛存在于基于事件触发控制机制的离散系统中.然而, 当前极少有文献研究如何排除类Zeno行为, 尤其是对于三阶多智能体动态模型.定理2给出了排除三阶离散多智能体系统的类Zeno行为的参数条件.
3. 仿真实验
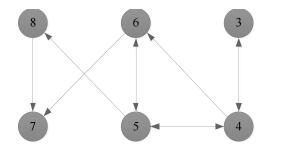
本部分将利用一个仿真实验来验证本文所提算法及理论的正确性和有效性.假设三阶离散多智能体系统(1)包含6个智能体, 且有向加权通信拓扑结构如图 1所示, 权重取值为0或1, 可以明显地看出该图包含有向生成树(满足假设1).
通过简单的计算可得, ${\mu _1} = 0$, ${\mu _2} = 0.6852$, ${\mu _3} = 1.5825 + 0.3865$i, ${\mu _4} = 1.5825 - 0.3865$i, ${\mu _5} = 3.2138$, ${\mu _6} = 3.9360$.令$M = 1$, 结合定理1和定理2可得到$0.035 < {\delta _1} < 1$, ${\delta _2} > 44.0025$, $0 < \alpha < \beta < 1$.令${\delta _1} = 0.2$, ${\delta _2} = 200$, $\alpha = 0.6$, $\beta = 0.9$, $\lambda = 0.02$, $\eta = 0.3$, $\gamma = 0.5$, 不难验证满足引理1的条件并且计算可知$\rho \left({{Q_1}} \right) = 0.9958 < 1$.三阶离散多智能体系统(1)的一致性结果如图 2~图 6所示.根据定理1可知, 基于控制器(2)和事件触发函数(4)的系统(1)能实现一致.从图 2~图 6可以看出, 仿真结果与理论分析符合.
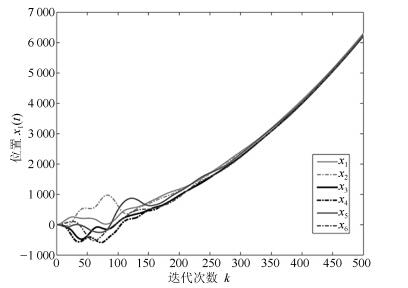 图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems
图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems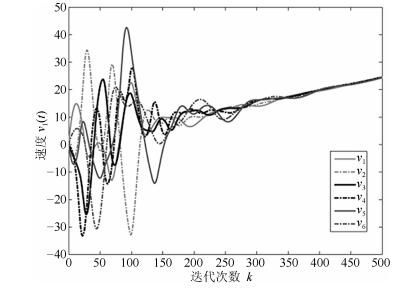 图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems
图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems 图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems
图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems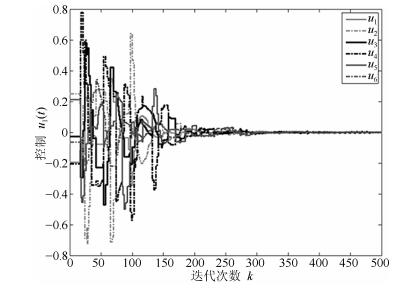 图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems
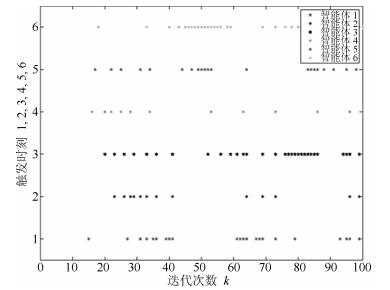
图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems图 2~图 4分别表征了系统(1)中所有智能体的位置、速度和加速度的轨迹, 从图中可以看出以上3个变量确实达到了一致.图 5展示了控制输入的轨迹.为了更清楚地体现事件触发机制的优点, 图 6给出了0$ \sim $100次迭代内的各智能体的触发时刻轨迹.从图 6可以看出, 本文设计的事件触发协议确实达到了减少更新次数, 节省资源的目的.
4. 结论
针对三阶离散多智能体系统的一致性问题, 构造了一个新颖的事件触发一致性协议, 分析得到了在通信拓扑为有向加权图且包含生成树的条件下, 系统中所有智能体的位置状态、速度状态和加速度状态渐近收敛到一致状态的充分条件.同时, 该条件指出了通信拓扑的Laplacian矩阵特征值和系统的耦合强度对系统一致性的影响.另外, 给出了排除类Zeno行为的参数条件.仿真实验结果也验证了上述结论的正确性.将文中获得的结论扩展到拓扑结构随时间变化的更高阶多智能体网络是极有意义的.这将是未来研究的一个具有挑战性的课题.
-
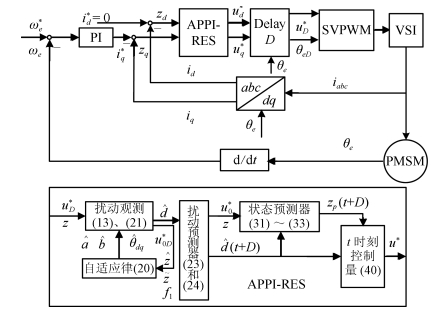
图 1 采用APPI-RES电流控制器的PMSM驱动系统框图
Fig. 1 Block diagram of PMSM driving system using APPI-RES current controller

图 16 $q$轴电流误差及其预测值(APPI-RES)
Fig. 16 Current error and its predictive value of $q$ axis (APPI-RES)
-
[1] Chou M C, Liaw C M. Dynamic control and diagnostic friction estimation for an SPMSM-driven satellite reaction wheel. IEEE Transactions on Industrial Electronics, 2011, 42(10):4693-4707 http://ieeexplore.ieee.org/document/5699362/ [2] Abdel-Rady Y, Mohamed I. A newly designed instantaneous-torque control of direct-drive PMSM servo actuator with improved torque estimation and control characteristics. IEEE Transactions on Industrial Electronics, 2007, 54(5):2864-2873 doi: 10.1109/TIE.2007.901356 [3] EL-Refaie A M. Fractional-slot concentrated-windings synchronous permanent magnet machines:opportunities and challenges. IEEE Transactions on Industrial Electronics, 2010, 57(1):107-121 doi: 10.1109/TIE.2009.2030211 [4] Jung J W, Leu V Q, Do T D, Kim E K, Choi H H. Adaptive PID speed control design for permanent magnet synchronous motor drives. IEEE Transactions on Power Electronics, 2015, 30(2):900-908 doi: 10.1109/TPEL.2014.2311462 [5] Chang S H, Chen P Y, Ting Y H, Hung S W. Robust current control-based sliding mode control with simple uncertainties estimation in permanent magnet synchronous motor drive systems. IET Electric Power Applications, 2010, 4(6):441-450 doi: 10.1049/iet-epa.2009.0146 [6] 牛里, 杨明, 王庚, 徐殿国.基于无差拍控制的永磁同步电机鲁棒电流控制算法研究.中国电机工程学报, 2013, 33(15):78-85 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=zgdc201315009&dbname=CJFD&dbcode=CJFQNiu Li, Yang Ming, Wang Geng, Xu Dian-Guo. Research on the robust current control algorithm of permanent magnet synchronous motor based on deadbeat control principle. Proceedings of the CSEE, 2013, 33(15):78-85 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=zgdc201315009&dbname=CJFD&dbcode=CJFQ [7] Errouissi R, Ouhrouche M, Chen W H, Trzynadlowski A. Robust nonlinear predictive controller for permanent-magnet synchronous motors with an optimized cost function. IEEE Transactions on Industrial Electronics, 2012, 59(7):2849-2858 doi: 10.1109/TIE.2011.2157276 [8] 孔小兵, 刘向杰.永磁同步电机高效非线性模型预测控制.自动化学报, 2014, 40(9):1958-1966 http://www.aas.net.cn/CN/abstract/abstract18466.shtmlKong Xiao-Bing, Liu Xiang-Jie. Efficient nonlinear model predictive control for permanent magnet synchronous motor. Acta Automatica Sinica, 2014, 40(9):1958-1966 http://www.aas.net.cn/CN/abstract/abstract18466.shtml [9] 王恩德, 黄声华.表贴式永磁同步电机伺服系统电流环设计.中国电机工程学报, 2012, 32(33):82-88 http://www.cnki.com.cn/Article/CJFDTotal-ZGDC201233011.htmWang En-De, Huang Sheng-Hua. Current Regulator design for surface permanent magnet synchronous motor servo systems. Proceedings of the CSEE, 2012, 32(33):82-88 http://www.cnki.com.cn/Article/CJFDTotal-ZGDC201233011.htm [10] Escobar G, Hernandez-Briones P G, Martinez P R, Hernandez-Gomez M, Torres-Olguin R E. A repetitive-based controller for the compensation of 6l ±1 harmonic components. IEEE Transactions on Industrial Electronics, 2008, 55(8):3150-3158 doi: 10.1109/TIE.2008.921200 [11] 匡敏驰, 朱纪洪, 吉敬华.航空油泵电机的相电流畸变纠正控制.控制与决策, 2015, 30(5):899-904 http://www.cnki.com.cn/Article/CJFDTotal-KZYC201505019.htmKuang Min-Chi, Zhu Ji-Hong, Ji Jing-Hua. Phase current distortion correction control for aerospace fuel pump motor. Control and Decision, 2015, 30(5):899-904 http://www.cnki.com.cn/Article/CJFDTotal-KZYC201505019.htm [12] 李毅拓, 陆海峰, 瞿文龙, 盛爽.基于谐振调节器的永磁同步电机电流谐波抑制方法.中国电机工程学报, 2014, 34(3):423-430 http://industry.wanfangdata.com.cn/yj/Detail/Periodical?id=Periodical_zgdjgcxb201403035Li Yi-Tuo, Lu Hai-Feng, Qu Wen-Long, Sheng Shuang. A permanent magnet synchronous motor current suppression method based on resonant controllers. Proceedings of the CSEE, 2014, 34(3):423-430 http://industry.wanfangdata.com.cn/yj/Detail/Periodical?id=Periodical_zgdjgcxb201403035 [13] McGrath B P, Parker S G, Holmes D G. High-performance current regulation for low-pulse-ratio inverters. IEEE Transactions on Industry Applications, 2013, 49(1):149-158 doi: 10.1109/TIA.2012.2229252 [14] Vidal A, Freijedo F D, Yepes A G, Fernandez-Comesana P, Malvar J, Lopez O, Doval-Gandoy J. Assessment and optimization of the transient response of proportional-resonant current controllers for distributed power generation systems. IEEE Transactions on Industrial Electronics, 2013, 60(4):1367-1383 doi: 10.1109/TIE.2012.2188257 [15] Yim J S, Sul S K, Bae B H, Patel N R, Hiti S. Modified current control schemes for high-performance permanent-magnet ac drives with low sampling to operating frequency ratio. IEEE Transactions on Industry Applications, 2009, 45(2):763-771 doi: 10.1109/TIA.2009.2013600 [16] Yepes A G, Vidal A, Malvar J, López O, Doval-Gandoy J. Tuning method aimed at optimized settling time and overshoot for synchronous proportional-integral current control in electric machines. IEEE Transactions on Power Electronics, 2014, 29(6):3041-3054 doi: 10.1109/TPEL.2013.2276059 [17] Franklin G F, Powell J D, Emami-Naeini A[著], 朱齐丹, 张丽珂, 原新[译]. 动态系统的反馈控制. 第4版. 北京: 电子工业出版社, 2004. 401-408Franklin G F, Powell J D, Emami-Naeini A[Author], Zhu Qi-Dan, Zhang Li-Ke, Yuan Xin[Translator]. Feedback Control of Dynamic Systems (Fourth Edition). Beijing: Publishing House of Electronics Industry, 2004. 401-408 [18] Léchappé V, Moulay E, Plestan F, Glumineau A, Chriette A. New predictive scheme for the control of LTI systems with input delay and unknown disturbances. Automatica, 2014, 52:179-184 https://www.sciencedirect.com/science/article/pii/S0005109814005342 期刊类型引用(5)
1. 刘晏,李前胜,姜彦辰,王永富. 输出约束的有限时间自适应区间二型模糊输出反馈PMSM伺服控制. 控制与决策. 2024(04): 1212-1222 .  百度学术
百度学术2. 王树青,孙炜伟,王高然. 输入饱和下永磁同步风力发电机的协调控制. 控制工程. 2023(02): 275-283 . 百度学术3. 汪凤翔,何龙. 永磁直线电机快速终端滑模预测电流控制. 电机与控制学报. 2023(06): 160-169 . 百度学术4. 齐歌,徐福博,张智伟,高帅军,肖景博. 双三相永磁同步电动机的改进抗饱和滑模控制. 微电机. 2020(04): 39-44 . 百度学术5. 夏薇,王凯,张建亚,刘东. 基于谐振控制器的谐波削极型永磁同步电机转矩脉动抑制策略. 中国电机工程学报. 2019(18): 5499-5508+5598 . 百度学术其他类型引用(11)
-

 下载:
下载:
 下载:
下载:



计量
- 文章访问数: 2396
- HTML全文浏览量: 272
- PDF下载量: 859
- 被引次数: 16
