

-
Abstract: Magnetic resonance imaging (MRI) reconstruction from undersampled data has always been a challenging and fascinating task due to its implicit ill-posed nature and its significance accompanied with the emerging compressed sensing (CS) theory. Most state-of-the-art sparse representation based CS approaches partition the image into overlapped patches, and process each patch separately. These methods, however, lose important spatial structures of the signal of interest, and ignore the consistency of pixels, which is a strong constraint for MR image. In this paper, we propose a new reconstruction method, which builds on recently introduced ideas of convolutional sparse coding in gradient domain (GradCSC) to address above mentioned issue. As opposed to patch-based methods, GradCSC directly operates on the whole gradient image to capture the correlation between local neighborhoods and exploits the gradient image global correlation to produce better edges and sharp features of gradient image. It enables local features implicitly existed in the gradient images to be captured effectively. Extensive experimental results demonstrate that the proposed algorithm achieves higher quality reconstructions than alternative methods and converges quickly at various sampling schemes and k-space acceleration factors.
-
Key words:
- Alternating direction method of multipliers /
- convolutional sparse coding(CSC) /
- filter learning /
- gradient image /
- magnetic resonance imaging(MRI)reconstruction
摘要: 从欠采样数据中进行磁共振成像(简称MRI)重建一直是一项具有挑战性和吸引力的任务,因为这是一个病态问题,且伴随着压缩感知理论会具有重要的意义.基于压缩感知的多数先进稀疏表示方法是将图像分割成重叠的图像块,然后每个图像块分开处理.然而,这些方法丢失了信号的重要空间结构,且忽略了对MR图像有强大约束的像素一致性.在文章中我们提出了一种新型的重建方法,这种方法是将最近提出的卷积稀疏编码与梯度域结合起来用于解决上述所提到的问题.不同于基于图像块状的方法,本文提出的算法是直接在整个梯度域图像中获取相邻局部的相关性,利用梯度域图像的全局相关性产生更好的梯度域图像边缘,锐利特征.提出的算法也能够高效的获取暗含在梯度域图像中的局部特征.与对比算法相比,大量的实验结果表明本文算法具有更好的质量重建,且在不同采样方案,不同K-空间加速因子情况下具有更快速的收敛. -
1. Introduction
Magnetic resonance imaging (MRI) is a crucial medical diagnostic technique which offers clinicians with significant anatomical structure for lack of ionizing. Unfortunately, although it enables highly resolution images and distinguishes depiction of soft tissues, the imaging speed is limited by physical and physiological constraints and increasing scan duration may bring in some physiological motion artifacts [1]. Therefore, it is necessary to seek for a method to decrease the acquisition time. Reducing the number of measurements mandated by Nyquist sampling theory is a way to accelerate the data acquisition at the expense of introducing aliasing artifacts in the reconstructed results. In recent years, compressed sensing (CS) theory, as a promising method, has proposed an essential theoretical foundation for improving data acquisition speed. Particularly, the application of CS to MRI is known as CS-MRI [2]-[6].
The CS theory states that the image which has a sparse representation in certain domain can be recovered from a reduced set of measurements largely below Nyquist sampling rates [2]. The traditional CS-MRI usually utilizes predefined dictionaries [1], [7]-[9], which may fail to sparsely represent the reconstructed images. For instance, Lustig et al. [1] employed the total variation (TV) penalty and the Daubechies wavelet transform for MRI reconstruction. Trzasko et al. [6] proposed a homotopic minimization strategy to reconstruct the MR image. Instead, adaptive dictionary updating in CS-MRI can provide less reconstruction errors due to the dictionary learned from sampled data [10], [11]. Recently, Ravishankar et al. supposed that each image patch has sparse representation, and presented a prominent two-step alternating method named dictionary learning based MRI reconstruction (DLMRI) [12]. The first step is for adaptively learning the dictionary, and the second step is for reconstructing image from undersampled $k$-space data. Numerical experiments have indicated that these data-driven-learning approaches obtained considerable improvements than previous predefined dictionaries-based methods. Liu et al. [13] proposed a gradient based dictionary learning method for image reconstruction (GradDL), which alleviated the drawback of the popular TV regularization by employing dictionary learning technique. Specifically, it firstly trained dictionaries from the horizontal and vertical gradients of the image respectively, and then reconstructed the desired image using the sparse representations of both derivatives. They also extended their ideas to the CT reconstruction and InSAR phase noise filtering [14], [15]. Nevertheless, most of existing methods did not consider the geometrical profit information sufficiently, which may lead to the fine details to be lost.
All the above methods use conventional patch-based sparse representation to reconstruct MR image, it has a fundamental disadvantage that the important spatial structures of the image of interest may be lost due to the subdivision into patches that are independent of each other. To make up for deficiencies of conventional patch-based sparse representation method, Zeiler et al. [16] proposed a convolutional implementation of sparse coding method (CSC). In the convolutional decomposition procedure, the decomposition does not need to divide the entire image into overlapped patches, and can naturally utilize the consistency prior. CSC was first introduced in the context of modeling receptive fields in human vision [17]. Recently, it has been demonstrated that CSC has important applications in a wide range of computer vision problems, like low/mid-level feature learning, low-level reconstruction [18], [19], networks in high-level computer vision or hierarchical structures challenges [16], [20], [21], and in physically-motivated computational imaging problems [22], [23]. In addition, CSC can find applications in many other reconstruction tasks and feature-based methods, including denoising, inpainting, super-resolution and classification [24]-[30].
In this paper, we propose a new formulation of convolutional sparse coding tailored to the problem of MRI reconstruction. Moreover, due to the image gradients are a sparser representation than the image itself and therefore may have sparser representation with the CSC than the pixel-domain image, we learn CSC in gradient domain for better quality and efficient reconstruction. The present method has two benefits. First, we introduce CSC for MRI reconstruction. Second, since the image gradients are usually sparser representation than the image itself, it is demonstrated that the CSC in gradient domain could lead to sparser representation than those using the conventional sparse representation methods in the pixel domain.
The remainder of this paper is organized as follows. Section 2 states the prior work in CS and CSC. The proposed algorithm CSC in gradient domain (GradCSC) that employing the augmented Lagrangian (AL) iterative method is detailed in Section 3. Section 4 demonstrates the performance of the proposed algorithm on examples under a variety of sampling schemes and undersampling factors. Conclusions are given in Section 5.
2. Background
In this section, we first review several classical models for CS-MRI, and then introduce the theory of CSC. The following notational conventions are used throughout the paper. Let denotes an image to be reconstructed, and represents the undersampled Fourier measurements. The partially sampled Fourier encoding matrix ${{F}_{p}}$ $\in$ ${{\mathbb{C}}^{Q\times N}}$ maps $u$ to $f$ such that ${{F}_{p}}u=f$. An MRI reconstruction problem is formulated as the retrieval of the vector $u$ based on the observation $f$ and given the encoding matrix ${{F}_{p}}$.
2.1 CS-MRI
The choice of sparsifying transform is an important question in CS theory. In the past several years, reconstructing unknown image from undersampled measurements was usually formulated as in (1) where assuming the image gradients are sparse
$ \min\limits_{u}\, \left\{ {{\mu }_{1}}{{\left\| u \right\|}_{TV}}+\frac{1}{2}\left\| {{F}_{p}}u-f \right\|_{2}^{2} \right\} $
(1) where is an anisotropic discretization formulation of the TV regularization, $\nabla u={{[u_{x}^{T}, u_{y}^{T}]}^{T}}$, denotes the difference operators in horizontal and vertical directions. This model is very straightforward and has good ability to preserve edges. However, the application of model (1) is limited in terms of reconstruction quality due to most MR images are not all piecewise constant. Yang et al. [31] presented the RecPF method by adding Wavelet transform to improve the issue.
Sparse and redundant representations of image patches based on learned basis has been drawing considerable attention in recent years. Specifically, Ravishankar et al. [12] presented a method named DLMRI to reconstruct MR image from highly undersampled $k$-space data with its objective shown as follows:
$ \min\limits_{u, D, \Gamma }\, \left\{ \sum\limits_{l}{\left\| D{{\alpha }_{l}}-{{R}_{l}}u \right\|_{2}^{2}+\nu {{\left\| {{F}_{p}}u-f \right\|}^{2}}} \right\}\rm{ }\\ {\rm s.t.}\quad {{\left\| {{\alpha }_{l}} \right\|}_{0}}\le {{T}_{0}}~~~ \forall \, l $
(2) where denotes the sparse coefficient matrix of image patches, $R\left( u \right)=[{{R}_{1}}u, {{R}_{2}}u, \ldots, {{R}_{L}}u]$ con-sisting of $L$ signals, ${{\left\|\cdot \right\|}_{0}}$ denotes the ${{l}_{0}}$ quasi-norm which counts the number of non-zero coefficients of the vector and ${{T}_{0}}$ controls the sparsity of the patch representation. Images are reconstructed by the minimization of a linear combination of two terms corresponding to dictionary learning-based sparse representation and least squares data fitting. The first term enforces sparsity of the image patches with respect to an adaptive dictionary, and the second term enforces data fidelity in $k$-space. The method exhibited superior performance compared to those using fixed basis, through learned adaptive transforms from image. Since DL techniques are more effective and efficient in the sparse domain of the image, Liu et al. [13] proposed a model to reconstruct the image by iteratively reconstructing the gradients via dictionary learning and solving for the final image, instead of learning adaptive structure from the image itself. The method is based on the observation that the gradients are sparser than the image itself. Therefore, it possesses sparser representation in the learned dictionary than the pixel-domain.
Although conventional patch-based sparse representation has widely applications, it has some drawbacks. First, it typically assumes that training image patches are independent from each other, hence the consistency of pixels and important spatial structures of the signal of interest may be lost. This assumption typically results in filters are simply translated versions of each other, and generates highly redundant feature representation. Second, due to the nature of the mathematical formulation that a linear combination of learned patches, these traditional patch-based representation approaches may fail to adequately represent high-frequency and high-contrast image features, thus loses some details and textures of the signal, which is important for MR images.
2.2 Convolutional Sparse Coding
Zeiler et al. [16] proposed an alternative to patch-based approaches named CSC, decomposing the image into spatially-invariant convolutional features. CSC is the sum of a set of convolutions of the feature maps by replacing the linear combination of a set of dictionary vectors. Let $X$ be a training set containing $2D$ images with dimension $m$ $\times$ $n$. Let be the $2D$ convolutional filter bank having $K$ filters, where each ${{d}_{k}}$ is a $h\times h$ convolutional kernel. ${{z}_{k}}$ is the sparse feature maps, each of which is the same size as $X$. CSC aims to decompose the input image $X$ into the sparse feature maps ${{z}_{k}}$ convolved with kernels ${{d}_{k}}$ from the filter bank $D$, by solving the following objective function:
$ \underset{d, z}{\mathop{\rm min}}\, \sum\limits_{i=1}^{2}{\frac{1}{2}\left\| X-\sum\limits_{k=1}^{K}{{{d}_{k}}*{{z}_{k}}} \right\|}_{2}^{2}+\beta \sum\limits_{k=1}^{K}{{{\left\| {{z}_{k}} \right\|}_{1}}} \nonumber\\ {\rm s.t.}\quad\left\| {{d}_{k}} \right\|_{2}^{2}\le 1~~~ \forall\, k\in \left\{ 1, \ldots, K \right\} $
(3) where the first and the second terms represent the reconstruction error and the ${{\ell }_{1}}$-norm penalty respectively; $\beta $ is a regularization parameter that controls the relative weight of the sparsity term; $\ast$ is the $2D$ discrete convolution operator; and filters are restricted to have unit energy to avoid trivial solutions. Note that here represents the entrywise matrix norm, the construction of is realized by balancing the reconstruction error and the ${{\ell }_{1}}$-norm penalty.
However, the CSC has led to some difficulties in optimization, Zeile et al. [16] used the continuation method to relax the equality constraints, and employed the conjugate gradient (CG) decent to solve the convolutional least square approximation problem. By considering the property of block circulant with circulant block (BCCB) matrix in the Fourier domain, Bristow et al. [32] presented a fast CSC method. Recently, Wohlberg [33] presented an efficient alternating direction method of multipliers (ADMM) to further improve this method.
3. Convolutional Sparse Coding in Gradient Domain
The image gradients are sparser than the image itself [13], therefore it has sparser representation in the CSC than that in the pixel-domain image. This motivates us to consider the CSC in the gradient domain. It is expected that such learning is more accurate and robust than that from pixel domain. In this work, we propose an algorithm to reconstruct the image by iteratively reconstructing the gradients via CSC and solving for the final image.
3.1 Proposed Model
To reconstruct image from the image gradients, we propose a new model as follows:
$ \begin{align} & \underset{u, d, z}{\mathop{\min }}\, \left\{ \sum\limits_{i=1}^{2}{\frac{1}{2} \left\| {{\nabla }^{(i)}}u-\sum\limits_{k=1}^{K}{{{d}_{k}}*{{z}_{k}}} \right\|}_{2}^{2}\right. \nonumber\\ &\qquad \left.+~\beta \sum\limits_{k=1}^{K}{{{\left\| {{z}_{k}} \right\|}_{1}}} +\frac{{{\nu }_{1}}}{2}{{\left\| {{F}_{p}}u-f \right\|}^{2}}\right\} \nonumber\\ & \, {\rm s.t.}\quad \left\| {{d}_{k}} \right\|_{2}^{2}\le 1~~~ \forall\, k\in \left\{ 1, \ldots, K \right\} \end{align} $
(4) where . The first term and the second term in the cost function (4) capture the sparse prior of the gradient image patches with respect to CSC, and the third term $\| {{F}_{p}}u-f \|_{2}^{2}$ represents the data fidelity term in $k$-space with ${{l}_{2}}$-norm controlling the error. The weight ${{v}_{1}}$ balances the tradeoff between these three terms, and is set as like the DLMRI algorithm does [13], where ${{\lambda }_{1}}$ is a positive constant. $\beta $ is a regularization parameter and controls the relative weight of the sparsity term with respect to the data term. The constraint $\forall\, k\in$ $\{ 1, $ $\ldots, $ can be included in the objective function via an indicator function $ind_{C}( \cdot )$, which is defined on the convex set of the constraint $C=\{ v\ |\| Sv \|_{2}^{2}\le 1 \}$.
In order to better understand the benefit of the CSC in the gradient domain, one demonstration of visual inspection between traditional sparse coded dictionaries and GradCSC filter is shown in Fig. 1. The learned dictionaries by DLMRI and GradDL are depicted in Figs. 1(a) and (b), both of which are learned from the Lumbar spine image in Fig. 2. The learned filters by GradCSC shown in Fig. 1(c) are learned from the dataset in [16]. Compared to the traditional sparse coded dictionaries in Figs. 1(a) and (b), it can be seen from Fig. 1(c) that the convolutional filter in GradCSC shows less redundancy, crisper features, and a larger range of feature orientations.
 图 1 One illustration of filters learned. (a) Learned dictionary by DLMRI, (b) Learned dictionary by GradDL, and (c) Learned filter by GradCSC, respectively.Fig. 1 One illustration of filters learned. (a) Learned dictionary by DLMRI, (b) Learned dictionary by GradDL, and (c) Learned filter by GradCSC, respectively.
图 1 One illustration of filters learned. (a) Learned dictionary by DLMRI, (b) Learned dictionary by GradDL, and (c) Learned filter by GradCSC, respectively.Fig. 1 One illustration of filters learned. (a) Learned dictionary by DLMRI, (b) Learned dictionary by GradDL, and (c) Learned filter by GradCSC, respectively.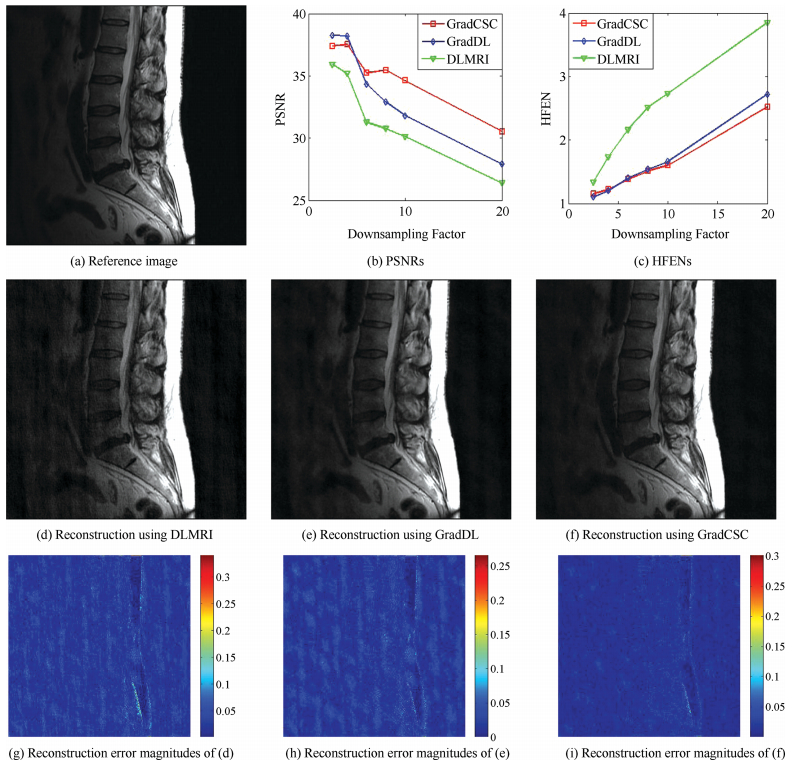 图 2 The reconstruction results of the Lumbar spine image under different undersampling factors with 2D random sampling.Fig. 2 The reconstruction results of the Lumbar spine image under different undersampling factors with 2D random sampling.
图 2 The reconstruction results of the Lumbar spine image under different undersampling factors with 2D random sampling.Fig. 2 The reconstruction results of the Lumbar spine image under different undersampling factors with 2D random sampling.3.2 Algorithm Solver
In the regularization term of (4), the global finite difference operators ${{\nabla }^{(i)}}$ are coupled, hence we resort to the splitting technique to decouple them. Specifically, to find a solution to the model (4), an AL iterative technique is employed and an algorithm called GradCSC is developed. The algorithm alternately updates sparse representations of the image patches, reconstructs the horizontal and vertical gradients, and estimates the original image from both gradients. A full description of the algorithm is given in Algorithm 1.
Algorithm 1. The GradCSC algorithm 1: Initialization: ${{z}_{k}}^{0}=0$, ${{d}_{k}}^{0}=0$, ${{({{b}^{(i)}})}^{0}}=0$, $i=1, 2$; ${{u}^{0}}=F_{p}^{T}f$
2: For $j=1, 2, \ldots $ repeat until a stop-criterion is satisfied
3: ${{({{w}^{(i)}})}^{j+1}}=\ \frac{{{\nu }_{2}}[{{({{b}^{(i)}})}^{j}}+{{({{\nabla }^{(i)}}u)}^{j}}]+\sum\limits_{k=1}^{K}{d_{_{k}}^{j}*z_{_{k}}^{j}}}{2{{\nu }_{2}}+1}, \ \ i=1, 2$
4: Updating $\{{{d}_{k}}^{j+1}, {{z}_{k}}^{j+1}\}$ from difference images ${{({{w}^{(i)}})}^{j+1}}$ by (13), $i=1, 2$
5: Updating $\{ r_{1}^{^{\ell +1}}, r_{2}^{^{\ell +1}}, r_{3}^{^{\ell +1}} \}$ from the coefficients, and the filters by (14)
6: ${{u}^{j+1}}={{F}^{\rm{-}1}}( \frac{F[{{\nu }_{1}}F_{p}^{T}f+{{\nu }_{2}}{{\nabla }^{T}}({{({{w}^{(i)}})}^{j}}^{+1}-{{({{b}^{(i)}})}^{j}})]}{{{\nu }_{1}}FF_{p}^{T}{{F}_{p}}{{F}^{T}}+{{\nu }_{2}}F{{\nabla }^{T}}{{F}^{T}}F\nabla {{F}^{T}}} )$
7: ${{({{b}^{(i)}})}^{j+1}}={{({{b}^{(i)}})}^{j}}+{{({{\nabla }^{(i)}}u)}^{j+1}}-{{({{w}^{(i)}})}^{j+1}}$, $i=1, 2$
8: End
9: Output ${{u}^{j+1}}$Equation (4) can be rewritten as follows by introducing auxiliary variables ${{w}^{(i)}}$, $i=1, 2$.
$ \begin{align} & \nonumber\underset{u, {{w}^{(i)}}, d, z}{\mathop{\min }}\, \left\{ \sum\limits_{i=1}^{2}{\frac{1}{2}\left\| {{w}^{(i)}}-\sum\limits_{k=1}^{K}{{{d}_{k}}*{{z}_{k}}} \right\|_{2}^{2}} \right. \\ &\nonumber \qquad \left. +~\beta \sum\limits_{k=1}^{K}{{{\left\| {{z}_{k}} \right\|}_{1}}} +\frac{{{\nu }_{1}}}{2}{{\left\| {{F}_{p}}u-f \right\|}^{2}}+\sum\limits_{k=1}^{K}{in{{d}_{C}}({{d}_{k}})} \right\} \\ & \, {\rm s.t.}\quad {{w}^{(i)}}={{\nabla }^{(i)}} u~~~\forall \, i \end{align} $
(5) then, by employing the AL technique and denoting , and , it yields a sequence of constrained subproblems as follows:
$ \begin{align} & \left\{{{u}^{j+1}}, {{w}^{j+1}}, {{d}^{j+1}}, {{z}^{j+1}}\right\} \nonumber\\ & \qquad={\arg} \underset{u, {{w}^{(i)}}, d, z}{\mathop{\rm min}}\, \sum\limits_{i=1}^{2}{\frac{1}{2}\left\| {{w}^{(i)}}-\sum\limits_{k=1}^{K}{{{d}_{k}}* {{z}_{k}}} \right\|_{2}^{2}}\nonumber\\ &\qquad\quad+\frac{{{\nu }_{1}}}{2}\left\| {{F}_{p}}u-f \right\|_{2}^{2} +\beta \sum\limits_{k=1}^{K}{{{\left\| {{z}_{k}} \right\|}_{p}}}+ \sum\limits_{k=1}^{K}{in{{d}_{C}}({{d}_{k}})}\nonumber\\ &\qquad\quad+\frac{{{\nu }_{2}}}{2}\left\| {{\left({{b}^{(i)}}\right)}^{j}}+\nabla u-{{w}^{(i)}} \right\|_{2}^{2} \end{align} $
(6) $ {{\left({{b}^{(i)}}\right)}^{j+1}}={{\left({{b}^{(i)}}\right)}^{j}}+\nabla {{u}^{j+1}}-{{\left({{w}^{(i)}}\right)}^{j+1}} $
(7) where ${{\nu }_{2}}$ denotes the positive penalty parameter. The ADMM can be used to address the minimization of (6) with respect to $u$, $w$, $z$, and $d$. This technique carries out approximation via alternating minimization with respect to one variable while keeping other variables fixed.
1) Updating the Solution $u$: At the $j$th iteration, we assume $w$, $z$, and $d$ to be fixed with their values denoted as ${{w}^{j}}$, ${{z}^{j}}$, and ${{d}^{j}}$, respectively. Eliminating the constant variables, the objective function for updating $u$ is given as
$ \begin{align} \nonumber{{u}^{j+1}}=\, & \arg \underset{u}{\mathop{\min }}\, \bigg\{ {{\nu }_{1}}\left\| {{F}_{p}}u-f \right\|_{2}^{2} \\ & +~{{\nu }_{2}}\left\| {{({{b}^{(i)}})}^{j}}+\nabla u-{{({{w}^{(i)}})}^{j}} \right\|_{2}^{2} \bigg\}. \end{align} $
(8) Recognizing that (8) is a simple least squares problem admitting an analytical solution. The least squares solution satisfies the normal equation
$ \left( {{\nu }_{1}}F_{p}^{T}{{F}_{p}}+{{\nu }_{2}}{{\nabla }^{T}}\nabla \right){{u}^{j+1}}={{\nu }_{1}}F_{p}^{T}f+{{\nu }_{2}}{{\nabla }^{T}}({{w}^{j}}-{{b}^{j}}). $
(9) However, directly solving the equation can be tedious due to (9) has a high computation complexity ($O({{P}^{3}})$). Fortunately, we can use the convolution theorem of Fourier transform to obtain the solution:
$ {{u}^{j+1}}={{F}^{-1}}\left( \frac{F\left[{{\nu }_{1}}F_{p}^{T}f+{{\nu }_{2}}{{\nabla }^{T}}({{w}^{j}}-{{b}^{j}})\right]}{{{\nu }_{1}}FF_{p}^{T}{{F}_{p}}{{F}^{T}}+{{\nu }_{2}}F{{\nabla }^{T}}{{F}^{T}}F\nabla {{F}^{T}}} \right) $
(10) similarly as described in DLMRI and GradDL method [12], the matrix $FF_{p}^{T}{{F}_{p}}{{F}^{T}}$ is a diagonal matrix consisting of ones and zeroes corresponding to the sampled location in $k$-space.
2) Updating the Gradient Image Variables ${w}^{(i)}$, $i$ = 1, 2: The minimization in (6) with respect to ${{w}^{(1)}}$ and ${{w}^{(2)}}$ are decoupled, and then can be solved separately. It yields:
$ \begin{align} \nonumber{{({{w}^{(i)}})}^{j+1}}=&\ \arg ~\underset{{{w}^{(i)}}}{\mathop{\min }}\, \Bigg\{ \frac{1}{2}\left\| \sum\limits_{k=1}^{K}{d_{_{k}}^{j}*z_{_{k}}^{j}}-{{w}^{(i)}} \right\|_{2}^{2} \\ & \ +\frac{{{\nu }_{2}}}{2}\left\| {{\left({{b}^{(i)}}\right)}^{j}}+{{ \left({{\nabla }^{(i)}}u\right)}^{j+1}}-{{w}^{(i)}} \right\|_{2}^{2} \Bigg\}. \end{align} $
(11) The least squares solution satisfies the normal equation, and the solution of (11) is as follow:
$ {{\left({{w}^{(i)}}\right)}^{j+1}}=\frac{{{\nu }_{2}}\left[{{\left({{b}^{(i)}}\right)}^{j}}+{{\left({{\nabla }^{(i)}}u\right)}^{j+1}}\right]+\sum\limits_{k=1}^{K}{d_{_{k}}^{j}*z_{_{k}}^{j}}}{{{\nu }_{2}}+1}. $
(12) 3) Updating the Coefficients $z$, and the Filters $d$: The minimization (6) with respect to CSC and coefficient variables of the gradient image in horizontal and vertical yields:
$ \begin{align} &\underset{{{d}^{j+1}}, {{z}^{j+1}}}{\mathop{\min }}\, \frac{1}{2}\left\| {{w}^{(i)}}-\sum\limits_{k=1}^{K}{{{d}_{k}}*{{z}_{k}}} \right\|_{2}^{2}\nonumber\\ &\qquad +\beta \sum\limits_{k=1}^{K}{{{\left\| {{z}_{k}} \right\|}_{1}}}+\sum\limits_{k=1}^{K}{in{{d}_{C}}({{d}_{k}})}. \end{align} $
(13) The problem in (13) can be solved by employing an AL algorithm like mentioned above, (13) needs to introduce auxiliary variables ${{r}_{1}}=\sum_{k=1}^{K}d_{_{k}}^{j+1}\ast z_{_{k}}^{j+1}$, ${{r}_{2}}={{d}^{j+1}}$, ${{r}_{3}}$ $=$ $z_{_{k}}^{j+1}$, it solves:
$ \begin{align} & \nonumber\left\{ d_{k}^{j+1, \ell +1}, z_{k}^{j+1, \ell +1}, r_{1}^ {^{\ell +1}}, r_{2}^{^{\ell +1}}, r_{3}^{^{\ell +1}} \right\} \\ \nonumber&\qquad ={\rm arg }\ \underset{{{d}^{j+1}}, {{z}^{j+1}}, {{r}_{1}}, {{r}_{2}}, {{r}_{3}}}{\mathop{\min }}\, \Bigg\{ \frac{1}{2}\left\| {{\left({{w}^{(i)}}\right)}^ {j+1}}-{{r}_{1}} \right\|_{2}^{2} \\ \nonumber&\qquad\quad +\sum\limits_{k=1}^{ K}{in{{d}_{C}}({{r}_{2, k}})}\ +\beta \sum\limits_{k=1}^{K}{ {{\left\| {{r}_{3, k}} \right\|}_{1}}}\\ \nonumber&\qquad\quad +\frac{{{\mu }_{1}}}{2}\left\| {{r}_{1}}-\sum\limits_{k=1}^{K}{d_{_{k}}^{j+1}*z_{_{k}}^{j+1}}+\lambda _{_{1}}^{j} \right\|_{2}^{2}\ \\ &\qquad\quad +\frac{{{\mu }_{2}}}{2}\left\| {{r}_{2}}-d_{_{k}}^{j+1}+ \lambda _{_{2}}^{j} \right\|_{2}^{2}+\frac{{{\mu }_{3}}}{2}\left\| {{r}_{3}}-z_{_{k}}^{j+1}+\lambda _{3}^{\ell } \right\|_{2}^{2} \Bigg\} \end{align} $
(14) at the $\ell$th iteration for ${{d}^{j+1, \ell +1}}$, , $r_{^{1}}^{\ell +1}$, $r_{^{2}}^{\ell +1}$, , then updates the multipliers ${{\lambda }_{1}}$, and ${{\lambda }_{3}}$ by the formula
$ \begin{align} &\nonumber \lambda _{_{1}}^{\ell +1}=\lambda _{_{1}}^{\ell }+r_{_{1}}^{\ell +1}-\sum\limits_{k=1}^{K}{d_{_{k}}^{j+1, \ell +1}*z_{_{k}}^{j+1, \ell +1}} \\ \nonumber& \lambda _{2}^{\ell +1}=\lambda _{_{2}}^{\ell }+r_{_{2}}^{\ell +1}-d_{_{k}}^{j+1, \ell +1} \\ & \lambda _{3}^{\ell +1}=\lambda _{3}^{\ell }+r_{3}^{\ell +1}-d_{_{k}}^{j+1, \ell +1}. \end{align} $
(15) ADMM is chosen to solve the (14). The corresponding five subproblems can be solved as follows:
$ \begin{align} \nonumber d_{k}^{j+1, \ell +1}=&\ {{\left( {{\left(z_{k}^{j+1, \ell }\right)}^{T}}z_{k}^{j+1, \ell }+\frac{{{\mu }_{2}}}{{{\mu }_{1}}}I \right)}^{-1}} \\ \nonumber &\ \times\left( {{\left(z_{k}^{j+1, \ell }\right)}^{T}}\left( r_{_{1}}^{\ell }+\lambda _{_{1}}^{\ell } \right)+\frac{{{\mu }_{2}}}{{{\mu }_{1}}}\left( r_{2}^{\ell }+\lambda _{_{2}}^{\ell } \right) \right) \\ \end{align} $
(16) $ \begin{align} \nonumber z_{k}^{j+1, \ell +1}=&\ {{\left( {{\left(d_{k}^{j+1, \ell +1}\right)}^{T}}d_{k}^{j+1, \ell +1}+\frac{{{\mu }_{4}}}{{{\mu }_{3}}}I \right)}^{-1}} \\ &\ \times\left( {{\left(d_{k}^{j+1, \ell +1}\right)}^{T}}\left(r_{_{3}}^{\ell }+\lambda _{_{3}}^{\ell }\right) +\frac{{{\mu }_{4}}}{{{\mu }_{3}}}\left(r_{_{4}}^{\ell }+\lambda _{_{4}}^{\ell }\right) \right) \end{align} $
(17) $ \begin{align} r_{1}^{^{\ell +1}}=&\ \left({{\mu }_{1}}+1\right){{I}^{-1}}\nonumber\\ &\ \times\left[\left({{\mu }_{1}}\sum\limits_{k=1}^{K}{z_{_{k}}^{j+1, \ell }*d_{_{k}}^{j+1, \ell +1}}-\lambda _{_{1}}^{\ell }\right)+{{\left({{w}^{(i)}}\right)}^{j+1}}\right]\\ \end{align} $
(18) $ \begin{align} r_{2, k}^{^{l+1}}=&\ \begin{cases} \frac{d_{_{k}}^{j+1, \ell +1}-\lambda _{_{2}}^{\ell }}{{{\left\| d_{_{k}}^{j+1}-\lambda _{_{2}}^{j} \right\|}_{2}}}, &d_{_{k}}^{j+1, \ell +1}-\lambda _{_{2}}^{\ell }\ge 1\\[4mm] d_{_{k}}^{j+1, \ell +1}-\lambda _{_{2}}^{\ell }, & {\rm else} \end{cases} \end{align} $
(19) where .
$ \begin{align} r_{3}^{^{\ell +1}}=&\ \max \left\{ 1-\frac{\beta }{{{\mu }_{3}}{{\left\| z_{_{k}}^{j+1, \ell +1}-\lambda _{3}^{\ell } \right\|}_{2}}}, 0 \right\}\nonumber\\&\ \circ \left( z_{_{k}}^{j+1, \ell +1}-\lambda _{3}^{\ell } \right) \end{align} $
(20) where $\circ $ represents the point-wise product function and the operation is implemented by component-wise manner.
4. Experimental Results
In this section, we evaluate the performance of proposed method at a variety of sampling schemes and undersampling factors. The sampling schemes employed in the experiments contain the 2D random sampling, pseudo radial sampling, and Cartesian sampling with random phase encoding (1D random). The size of images we use in the synthetic experiments are $512\times 512$. The CS data acquisition was simulated by subsampling the 2D discrete Fourier transform of the MR images (except the test with real acquired data) in the light of many prior work on CS-MRI approaches, . In order to find the sparse feature map ${{z}_{k}}$, we use a fixed filter $D$ which is trained from reference MR images. We find that learning $K=100$ filters of size $11\times 11$ pixels fulfills these conditions for our data and works well for all the images tested. In the experiment, the proposed method GradCSC is compared with the leading DLMRI [12] and GradDL [13] methods that have shown the substantially outperform other CS-MRI methods. In addition, we use the peak signal-to-noise ratio (PSNR) and high-frequency error norm (HFEN) [20] to evaluate the quality of reconstruction. All of these algorithms are implemented in MATLAB 7.1 on a PC equipped with AMD 2.31 GHz CPU and 3 GByte RAM.
4.1 Experiments Under Different Undersampling Factors
In this subsection, we evaluate the performance of GradCSC under different undersampling factors with same sampling scheme. Fig. 2 illustrates the reconstruction results at a range of undersampling factors with 2.5, 4, 6, 8, 10 and 20. We added the zero-mean complex white Gaussian noise with $\sigma =10.2$ in the 2D random sampled $k$-space. The PSNR and HFEN values for DLMRI, GradDL and GradCSC at various undersampling factors are presented in Figs. 2(b) and (c), additionally the PSNR values are listed in Table Ⅰ. For the subjective comparison, the construction results and magnitude image of the reconstruction error provided by the three methods at 8-fold undersampling are presented in Figs. 2(d), (e), (f) and (g), (h), (i), respectively. In this case, it can be seen that the image reconstructed by the DLMRI method (shown in Fig. 2(d)) is blurred and loses some textures. Although both GradDL and GradCSC present excellent performances on suppressing aliasing artifacts, our GradCSC provides a better reconstruction of object edges (such as the spine) and preserves finer texture information (such as the bottom-right of the reconstruction). Such difference in reconstruction quality is particularly clear in the image errors shown in Figs. 2(g), (h) and (i). In general, our proposed method provides greater intensity fidelity to the image reconstructed from the full data.
表 Ⅰ Reconstruction PSNR Values at Different Undersampling Factors With the Same 2D Random Sampling TrajectoriesTable Ⅰ Reconstruction PSNR Values at Different Undersampling Factors With the Same 2D Random Sampling TrajectoriesUndersampling factors 2.5-fold 4-fold 6-fold 8-fold 10-fold 20-fold DLMRI 35.92 35.19 31.26 30.76 30.13 26.39 GradDL 38.26 38.20 34.35 32.89 31.81 27.90 GradCSC 37.39 37.53 35.23 35.45 34.62 30.54 4.2 Impact of Undersampling Schemes
In this subsection, we evaluate the performance of GradCSC at various sampling schemes. The results are presented in Fig. 3 which reconstructed an axial T2-weighted brain image at 8-fold undersampling factors by applying three different sampling schemes, including 2D random sampling, 1D Cartesian sampling, and pseudo radial sampling. The PSNR and HFEN indexes versus iterative number for method DLMRI, GradDL and GradCSC are plotted in Figs. 3(b) and (c). Particularly, we present the reconstructions of DLMRI, GradDL and GradCSC with 2D random sampling in Figs. 3(d), (e), and (f), respectively. In order to facilitate the observation, the difference image between reconstruction results are shown in Figs. 3(g), (h), and (i). As can be expected, the convolution operator enables CSC outperform DLMRI and GradDL methods for most of specified undersampling ratios and trajectories. This exhibits the benefits of employing the convolutional filter for sparse coding. In particular, in Fig. 3(d), (e), and (f) the skeletons in the top half part of the GradCSC reconstruction appear less obscured than those in the DLMRI and GradDL results. the proposed method GradCSC reconstructs the images more accurately with larger PSNR and lower HFEN values than the GradDL approach. Particularly when sampled at 2D random trajectory, our method GradCSC outperforms others with a remarkable improvement from 0.7 dB to 5.8 dB.
 图 3 The reconstruction results of the axial T2-weighted brain image under different undersampling schemes.Fig. 3 The reconstruction results of the axial T2-weighted brain image under different undersampling schemes.
图 3 The reconstruction results of the axial T2-weighted brain image under different undersampling schemes.Fig. 3 The reconstruction results of the axial T2-weighted brain image under different undersampling schemes.4.3 Performances at Different Noise Levels
We also conduct experiments to investigate the sensitivity of GradCSC to different levels of complex white Gaussian noise. DLMRI, GradDL and GradCSC are applied to reconstruct a noncontrast MRA of the circle of Willis under pseudo radial sampling at 6.67-fold acceleration. Fig. 4 presents the reconstruction results of three methods at different levels of complex white Gaussian noise, which are added to the $k$-space samples. Fig. 4(c) presents the PSNRs of DLMRI, GradDL and GradCSC at a sequence of different standard deviations (0, 2, 5, 8, 10, 12, 15). Reconstruction results with noise 5 are shown in Figs. 4(d), (e), and (f). The PSNRs gained by DLMRI and GradDL are 27.03 dB and 29.78 dB, while the GradCSC method achieves 30.45 dB. Obviously, the reconstruction obtained by GradCSC is clearer than those by DLMRI and GradDL. It can be observed that our GradCSC method can reconstruct the images more precisely than DLMRI and GradDL, in terms of extracting more structural and detail information from gradient domain. The corresponding error magnitudes of the reconstruction are displayed in Figs. 4(g), (h), and (i). It reveals that our method provides a more accurate reconstruction of image contrast and sharper anatomical depiction in noisy case.
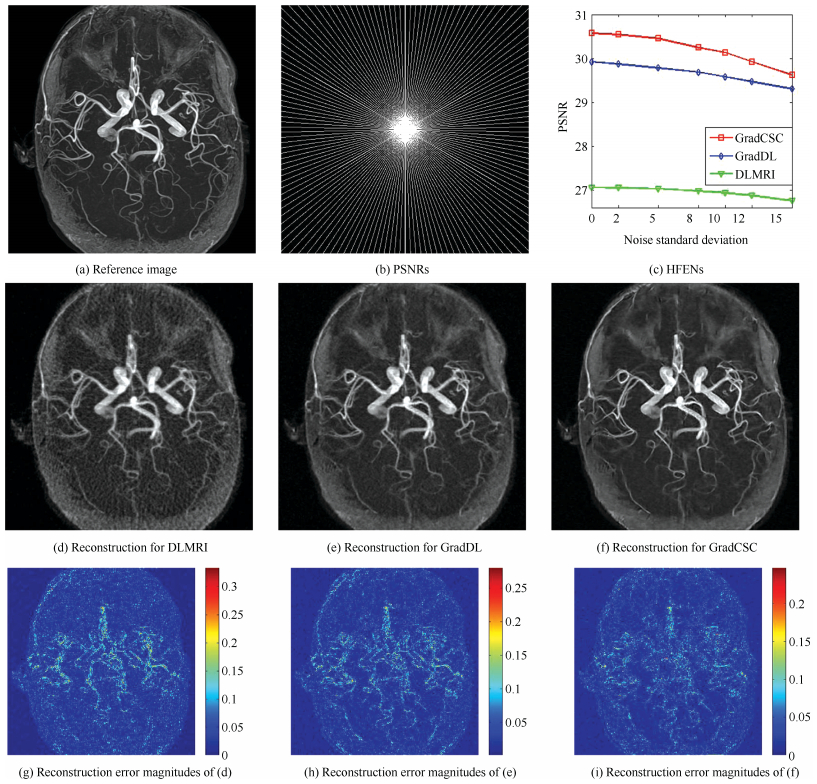 图 4 The reconstruction results of the COW image under different noise levels.Fig. 4 The reconstruction results of the COW image under different noise levels.
图 4 The reconstruction results of the COW image under different noise levels.Fig. 4 The reconstruction results of the COW image under different noise levels.5. Conclusion
In this work, a novel CSC method in gradient domain for MR image reconstruction was proposed. The important spatial structures of the signal were preserved by convolutional sparse coding. For the new derived model, we utilized the AL method to implement the algorithm in a few number of iterations. A variety of experimental results demonstrated the superior performance of the method under various sampling trajectories and $k$-space acceleration factors. The proposed method can produce highly accurate reconstructions for severely undersampled factors. It provided superior performance in both noiseless and noisy cases. The presented framework will be extended to parallel imaging applications in the future work.
-
Fig. 1 One illustration of filters learned. (a) Learned dictionary by DLMRI, (b) Learned dictionary by GradDL, and (c) Learned filter by GradCSC, respectively.
Fig. 2 The reconstruction results of the Lumbar spine image under different undersampling factors with 2D random sampling.
Fig. 3 The reconstruction results of the axial T2-weighted brain image under different undersampling schemes.
Algorithm 1. The GradCSC algorithm 1: Initialization: ${{z}_{k}}^{0}=0$, ${{d}_{k}}^{0}=0$, ${{({{b}^{(i)}})}^{0}}=0$, $i=1, 2$; ${{u}^{0}}=F_{p}^{T}f$
2: For $j=1, 2, \ldots $ repeat until a stop-criterion is satisfied
3: ${{({{w}^{(i)}})}^{j+1}}=\ \frac{{{\nu }_{2}}[{{({{b}^{(i)}})}^{j}}+{{({{\nabla }^{(i)}}u)}^{j}}]+\sum\limits_{k=1}^{K}{d_{_{k}}^{j}*z_{_{k}}^{j}}}{2{{\nu }_{2}}+1}, \ \ i=1, 2$
4: Updating $\{{{d}_{k}}^{j+1}, {{z}_{k}}^{j+1}\}$ from difference images ${{({{w}^{(i)}})}^{j+1}}$ by (13), $i=1, 2$
5: Updating $\{ r_{1}^{^{\ell +1}}, r_{2}^{^{\ell +1}}, r_{3}^{^{\ell +1}} \}$ from the coefficients, and the filters by (14)
6: ${{u}^{j+1}}={{F}^{\rm{-}1}}( \frac{F[{{\nu }_{1}}F_{p}^{T}f+{{\nu }_{2}}{{\nabla }^{T}}({{({{w}^{(i)}})}^{j}}^{+1}-{{({{b}^{(i)}})}^{j}})]}{{{\nu }_{1}}FF_{p}^{T}{{F}_{p}}{{F}^{T}}+{{\nu }_{2}}F{{\nabla }^{T}}{{F}^{T}}F\nabla {{F}^{T}}} )$
7: ${{({{b}^{(i)}})}^{j+1}}={{({{b}^{(i)}})}^{j}}+{{({{\nabla }^{(i)}}u)}^{j+1}}-{{({{w}^{(i)}})}^{j+1}}$, $i=1, 2$
8: End
9: Output ${{u}^{j+1}}$ 下载: 导出CSV
下载: 导出CSV
Table Ⅰ Reconstruction PSNR Values at Different Undersampling Factors With the Same 2D Random Sampling Trajectories
Undersampling factors 2.5-fold 4-fold 6-fold 8-fold 10-fold 20-fold DLMRI 35.92 35.19 31.26 30.76 30.13 26.39 GradDL 38.26 38.20 34.35 32.89 31.81 27.90 GradCSC 37.39 37.53 35.23 35.45 34.62 30.54
下载: 导出CSV
-
[1] M. Lustig, D. Donoho, and J. M. Pauly, "Sparse MRI:The application of compressed sensing for rapid MR imaging, " Magn. Reson. Med., vol. 58, no. 6, pp. 1182-1195, Dec. 2007. doi: 10.1002/(ISSN)1522-2594 [2] D. L. Donoho, "Compressed sensing, " IEEE Trans. Inform. Theory, vol. 52, no. 4, pp. 1289-1306, Apr. 2006. doi: 10.1109/TIT.2006.871582 [3] D. Liang, B. Liu, J. Wang, and L. Ying, "Accelerating SENSE using compressed sensing, " Magn. Reson. Med., vol. 62, no. 6, pp. 1574-1584, Dec. 2009. doi: 10.1002/mrm.v62:6 [4] M. Lustig, J. M. Santos, D. L. Donoho, and J. M. Pauly, "k-t SPARSE: high frame rate dynamic MRI exploiting spatiotemporal sparsity, " in Proc. 13th Ann. Meeting of ISMRM, Seattle, USA, 2006. [5] S. Q. Ma, W. T. Yin, Y. Zhang, and A. Chakraborty, "An efficient algorithm for compressed MR imaging using total variation and wavelets, " in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Anchorage, AK, USA, 2008, pp. 1-8. [6] J. Trzasko and A. Manduca, "Highly undersampled magnetic resonance image reconstruction via homotopic e0-minimization, " IEEE Trans. Med. Imaging, vol. 28, no. 1, pp. 106-121, Jan. 2009. doi: 10.1109/TMI.2008.927346 [7] S. M. Gho, Y. Nam, S. Y. Zho, E. Y. Kim, and D. H. Kim, "Three dimension double inversion recovery gray matter imaging using compressed sensing, " Magn. Reson. Imaging, vol. 28, no. 10, pp. 1395-1402, Dec. 2010. doi: 10.1016/j.mri.2010.06.029 [8] M. Guerquin-Kern, M. Haberlin, K. P. Pruessmann, and M. Unser, "A fast wavelet-based reconstruction method for magnetic resonance imaging, " IEEE Trans. Med. Imaging, vol. 30, no. 9, pp. 1649-1660, Sep. 2011. doi: 10.1109/TMI.2011.2140121 [9] L. Y. Chen, M. C. Schabel, and E. V. R. DiBella, "Reconstruction of dynamic contrast enhanced magnetic resonance imaging of the breast with temporal constraints, " Magn. Reson. Imaging, vol. 28, no. 5, pp. 637-645, Jun. 2010. doi: 10.1016/j.mri.2010.03.001 [10] Q. G. Liu, S. S. Wang, K. Yang, J. H. Luo, Y. M. Zhu, and D. Liang, "Highly undersampled magnetic resonance image reconstruction using two-level Bregman method with dictionary updating, " IEEE Trans. Med. Imaging, vol. 32, no. 7, pp. 1290-1301, Jul. 2013. doi: 10.1109/TMI.2013.2256464 [11] X. B. Qu, D. Guo, B. D. Ning, Y. K. Hou, Y. L. Lin, S. H. Cai, and Z. Chen, "Undersampled MRI reconstruction with patch-based directional wavelets, " Magn. Reson. Imaging, vol. 30, no. 7, pp. 964-977, Sep. 2012. doi: 10.1016/j.mri.2012.02.019 [12] S. Ravishankar and Y. Bresler, "MR image reconstruction from highly undersampled k-space data by dictionary learning, " IEEE Trans. Med. Imaging, vol. 30, no. 5, pp. 1028-1041, May 2011. doi: 10.1109/TMI.2010.2090538 [13] Q. G. Liu, S. S. Wang, L. Ying, X. Peng, Y. J. Zhu, and D. Liang, "Adaptive dictionary learning in sparse gradient domain for image recovery, " IEEE Trans. Image Process., vol. 22, no. 12, pp. 4652-4663, Dec. 2013. doi: 10.1109/TIP.2013.2277798 [14] Z. L. Hu, Q. G. Liu, N. Zhang, Y. W. Zhang, X. Peng, P. Z. Wu, H. R. Zheng, and D. Liang, "Image reconstruction from few-view CT data by gradient-domain dictionary learning, " J. X-Ray Sci. Technol., vol. 24, no. 4, pp. 627-638, Jul. 2016. doi: 10.3233/XST-160579 [15] X. M. Luo, Z. Y. Suo, and Q. G. Liu, "Efficient InSAR phase noise filtering based on adaptive dictionary learning in gradient vector domain, " Chin. J. Eng. Math., vol. 32, no. 6, pp. 801-811, Dec. 2015. doi: 10.1162/neco.1995.7.6.1129 [16] M. D. Zeiler, D. Krishnan, G. W. Taylor, and R. Fergus, "Deconvolutional networks, " in Proc. 2010 IEEE Conf. Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 2010, pp. 2528-2535. [17] B. A. Olshausen and D. J. Field, "Sparse coding with an overcomplete basis set:a strategy employed by V1?, " Vision Res., vol. 37, no. 23, pp. 3311-3325, Dec. 1997. doi: 10.1016/S0042-6989(97)00169-7 [18] A. Szlam, K. Kavukcuoglu, and Y. LeCun, "Convolutional matching pursuit and dictionary training, " arXiv: 1010. 0422, Oct. 2010. [19] B. Chen, G. Polatkan, G. Sapiro, D. Blei, D. Dunson, and L. Carin, "Deep learning with hierarchical convolutional factor analysis, " IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 8, pp. 1887-1901, Aug. 2013. doi: 10.1109/TPAMI.2013.19 [20] K. Kavukcuoglu, P. Sermanet, Y. L. Boureau, K. Gregor, M. Mathieu, and Y. LeCun, "Learning convolutional feature hierarchies for visual recognition, " in Proc. 23rd Int. Conf. Neural Information Processing Systems, Vancouver, British Columbia, Canada, 2010, pp. 1090-1098. [21] M. D. Zeiler, G. W. Taylor, and R. Fergus, "Adaptive deconvolutional networks for mid and high level feature learning, " in Proc. 2011 IEEE Int. Conf. Computer Vision (ICCV), Barcelona, USA, 2011, pp. 2018-2025. [22] F. Heide, L. Xiao, A. Kolb, M. B. Hullin, and W. Heidrich, "Imaging in scattering media using correlation image sensors and sparse convolutional coding, " Opt. Express, vol. 22, no. 21, pp. 26338-26350, Oct. 2014. doi: 10.1364/OE.22.026338 [23] X. M. Hu, Y. Deng, X. Lin, J. L. Suo, Q. H. Dai, C. Barsi, and R. Raskar, "Robust and accurate transient light transport decomposition via convolutional sparse coding, " Opt. Lett., vol. 39, no. 11, pp. 3177-3180, Jun. 2014. doi: 10.1364/OL.39.003177 [24] J. Y. Xie, L. L. Xu, and E. H. Chen, "Image denoising and inpainting with deep neural networks, " in Proc. 25th Int. Conf. Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 2012, pp. 341-349. [25] S. H. Gu, W. M. Zuo, Q. Xie, D. Y. Meng, X. C. Feng, and L. Zhang, "Convolutional sparse coding for image superresolution, " in Proc. 2015 IEEE Int. Conf. Computer Vision (ICCV), Santiago, Chile, 2015, pp. 1823-1831. [26] A. Krizhevsky, I. Sutskever, and G. E. Hinton, "Imagenet classification with deep convolutional neural networks, " in Proc. 25th Int. Conf. Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 2012, pp. 1097-1105. [27] Y. Y. Zhu, M. Cox, and S. Lucey, "3D motion reconstruction for real-world camera motion, " in Proc. 2011 IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 2011, pp. 1-8. [28] Y. Y. Zhu and S. Lucey, "Convolutional sparse coding for trajectory reconstruction, " IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp. 529-540, Mar. 2015. doi: 10.1109/TPAMI.2013.2295311 [29] Y. Y. Zhu, D. Huang, F. De La Torre, and S. Lucey, "Complex non-rigid motion 3D reconstruction by union of subspaces, " in Proc. 2014 IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 2014, pp. 1542-1549. [30] A. Serrano, F. Heide, D. Gutierrez, G. Wetzstein, and B. Masia, "Convolutional sparse coding for high dynamic range imaging, " Computer Graphics, vol. 35, no. 2, pp. 153-163, May 2016. http://dl.acm.org/citation.cfm?id=3028600 [31] J. F. Yang, Y. Zhang, and W. T. Yin, "A fast alternating direction method for TVL1-L2 signal reconstruction from partial Fourier data, " IEEE J. Sel. Topics Signal Process., vol. 4, no. 2, pp. 288-297, Apr. 2010. doi: 10.1109/JSTSP.2010.2042333 [32] H. Bristow, A. Eriksson, and S. Lucey, "Fast convolutional sparse coding, " in Proc. 2013 IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 2013, pp. 391-398. [33] B. Wohlberg, "Efficient convolutional sparse coding, " in Proc. 2014 IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 2014, pp. 7173-7177. 期刊类型引用(7)
1. 石保顺,吴一凡,练秋生. 基于无监督学习的编码衍射成像方法研究. 燕山大学学报. 2023(01): 54-63 .  百度学术
百度学术2. 王天琪,邢藏菊,肖亮. 一种高分辨率的磁共振成像梯度信号发生器. 现代电子技术. 2023(13): 49-54 . 百度学术3. 周登文,马路遥,田金月,孙秀秀. 基于特征融合注意网络的图像超分辨率重建. 自动化学报. 2022(09): 2233-2241 . 本站查看4. 李雨,史娜,孔慧华,雷肖雪. 基于全变分和梯度域卷积稀疏编码的稀疏角度CT重建算法. 激光与光电子学进展. 2021(12): 339-348 . 百度学术5. 李建武,康杨,周金鹏. PF-FICOTA-SENSE:一种MRI快速重构方法. 自动化学报. 2020(05): 897-908 . 本站查看6. 周登文,赵丽娟,段然,柴晓亮. 基于递归残差网络的图像超分辨率重建. 自动化学报. 2019(06): 1157-1165 . 本站查看7. 姚红革,沈新霞,李宇,喻钧,雷松泽. 多模态融合的深度学习脑肿瘤检测方法. 光子学报. 2019(07): 165-176 . 百度学术其他类型引用(12)
-

 下载:
下载:
计量
- 文章访问数: 2175
- HTML全文浏览量: 338
- PDF下载量: 992
- 被引次数: 19
