

Adaptive Control for High-order Nonlinear Feedforward Systems With Input and State Delays
-
摘要: 本文考虑了一类高阶不确定非线性前馈系统的自适应镇定问题.将高阶非线性进一步放宽到不仅允许状态时滞,而且还具有未知增长率.通过将自适应方法、动态增益控制方法和增加幂次积分器法结合,设计了一个状态反馈控制器.所设计的控制器保证了闭环系统的所有信号有界,平衡点全局稳定,并且原状态收敛到0.Abstract: This paper considers the adaptive stabilization of a class of high-order uncertain nonlinear feedforward systems. The growth condition on nonlinearities is further relaxed by allowing not only input and state delays but also the unknown growth rate. By a combined method of adaptive technique, dynamic gain control approach and adding a power integrator technique, a state feedback controller is designed to guarantee that all signals are bounded, the equilibrium point of the closed-loop system is globally stable and the original state converges to zero.
-
Key words:
- Adaptive control /
- dynamic gain /
- high-order nonlinear feedforward systems /
- input and state delays
-
[1] A. R. Teel, "Feedback stabilization: nonlinear solutions to inherently nonlinear problems, " Ph. D. dissertation, University of California, Berkeley, USA, 1992. http://www.researchgate.net/publication/33801617_Feedback_stabilization_nonlinear_solutions_to_inherently_nonlinear_problems [2] A. R. Teel, "A nonlinear small gain theorem for the analysis of control systems with saturation, " IEEE Trans. Automat. Control, vol. 41, no. 9, pp. 1256-1270, Sep. 1996. https://www.researchgate.net/publication/3022636_A_nonlinear_small_gain_theorem_for_the_analysis_of_control_systemswith_saturation [3] F. Mazenc and S. Bowong, "Tracking trajectories of the cart-pendulum system, " Automatica, vol. 39, no. 4, pp. 677-684, Apr. 2003. https://www.researchgate.net/publication/220159242_Tracking_trajectories_of_the_cart-pendulum_system?ev=sim_pub [4] F. Mazenc, "Stabilization of feedforward systems approximated by a non-linear chain of integrators, " Syst. Control Lett. , vol. 32, no. 4, pp. 223-229, Dec. 1997. https://www.researchgate.net/publication/239374436_Stabilization_of_feedforward_systems_approximated_by_a_non-linear_chain_of_integrators [5] X. D. Ye, "Universal stabilization of feedforward nonlinear systems, " Automatica, vol. 39, no. 1, pp. 141-147, Jan. 2003. https://www.researchgate.net/publication/223027934_Universal_stabilization_of_feedforward_nonlinear_systems [6] H. L. Choi and J. T. Lim, "Global exponential stabilization of a class of nonlinear systems by output feedback, " IEEE Trans. Automat. Control, vol. 50, no. 2, pp. 255-257, Feb. 2005. http://en.cnki.com.cn/Article_en/CJFDTotal-TJFZ200903025.htm [7] S. H. Ding, C. J. Qian, and S. H. Li, "Global stabilization of a class of feedforward systems with lower-order nonlinearities, " IEEE Trans. Automat. Control, vol. 55, no. 3, pp. 691-697, Mar. 2010. https://www.researchgate.net/publication/224106845_Global_Stabilization_of_a_Class_of_Feedforward_Systems_with_Lower-Order_Nonlinearities [8] T. S. Chen and J. Huang, "Disturbance attenuation of feedforward systems with dynamic uncertainty, " IEEE Trans. Automat. Control, vol. 53, no. 7, pp. 1711-1717, Aug. 2008. https://www.researchgate.net/publication/3033181_Disturbance_Attenuation_of_Feedforward_Systems_With_Dynamic_Uncertainty [9] X. Zhang and Y. Lin, "Global adaptive stabilisation of feedforward systems by smooth output feedback, " IET Control Theory Appl. , vol. 6, no. 13, pp. 2134-2141, Sep. 2012. https://www.researchgate.net/publication/260586919_global_adaptive_stabilisation_of_feedforward_systems_by_smooth_output_feedback_brief_paper [10] F. Mazenc, S. Mondie, and R. Francisco, "Global asymptotic stabilization of feedforward systems with delay in the input, " IEEE Trans. Automat. Control, vol. 49, no. 5, pp. 844-850, May2004. https://www.researchgate.net/publication/3031797_Global_asymptotic_stabilization_of_feedforward_systems_with_delay_in_the_input [11] X. F. Zhang, H. Y. Gao, and C. H. Zhang, "Global asymptotic stabilization of feedforward nonlinear systems with a delay in the input, " Int. J. Syst. Sci. , vol. 37, no. 3, pp. 141-148, Feb. 2006. http://dl.acm.org/citation.cfm?id=1149050 [12] X. D. Ye, "Adaptive stabilization of time-delay feedforward nonlinear systems, " Automatica, vol. 47, no. 5, pp. 950-955, May2011. https://www.researchgate.net/publication/220157713_Adaptive_stabilization_of_time-delay_feedforward_nonlinear_systems [13] X. F. Zhang, Q. R. Liu, L. Baron, and E. K. Boukas, "Feedback stabilization for high order feedforward nonlinear time-delay systems, " Automatica, vol. 47, no. 5, pp. 962-967, May 2011. [14] J. Tsinias and M. P. Tzamtzi, "An explicit formula of bounded feedback stabilizers for feedforward systems, " Syst. Control Lett. , vol. 43, no. 4, pp. 247-261, Jul. 2001. https://www.researchgate.net/publication/245217905_An_explicit_formula_of_bounded_feedback_stabilizers_for_feedforward_systems [15] M. T. Frye, R. Trevino, and C. J. Qian, "Output feedback stabilization of nonlinear feedforward systems using low gain homogeneous domination, " in Proc. IEEE Int. Conf. Control and Automation, Guangzhou, China, 2007, pp. 422-427. https://www.researchgate.net/publication/4288114_Output_Feedback_Stabilization_of_Nonlinear_Feedforward_Systems_using_Low_Gain_Homogeneous_Domination [16] X. D. Ye and H. Unbehauen, "Global adaptive stabilization for a class of feedforward nonlinear systems, " IEEE Trans. Automat. Control, vol. 49, no. 5, pp. 786-792, May2004. https://www.researchgate.net/publication/3031805_Global_adaptive_stabilization_for_a_class_of_feedforward_nonlinear_systems [17] C. J. Qian and W. Lin, "A continuous feedback approach to global strong stabilization of nonlinear systems, " IEEE Trans. Automat. Control, vol. 46, no. 7, pp. 1061-1079, Jul. 2001. https://www.researchgate.net/publication/3024112_A_continuous_feedback_approach_to_global_strong_stabilization_ofnonlinear_systems [18] H. K. Khalil, Nonlinear Systems. 3rd ed. New Jersey: Prentice Hall, 2002, pp. 145-145. [19] M. Krstić, I. Kanellakopoulos, and P. V. Kokotović, Nonlinear and Adaptive Control Design. New York: John Wiley and Sons, 1995, pp. 491-491. [20] H. Deng, M. Krstić, and R. J. Williams, "Stabilization of stochastic nonlinear systems driven by noise of unknown covariance, " IEEE Trans. Automat. Control, vol. 46, no. 8, pp. 1237-1253, Aug. 2001. https://www.researchgate.net/publication/3758995_Stabilization_of_stochastic_nonlinear_systems_driven_by_noise_of_unknown_covariance?ev=auth_pub [21] Z. J. Wu, X. J. Xie, and S. Y. Zhang, "Adaptive backstepping controller design using stochastic small-gain theorem, " Automatica, vol. 43, no. 4, pp. 608-620, Apr. 2007. https://www.researchgate.net/publication/222213338_Adaptive_backstepping_controller_design_using_stochastic_small-gain_theorem?ev=auth_pub [22] S. J. Liu, Z. P. Jiang, and J. F. Zhang, "Global output-feedback stabilization for a class of stochastic non-minimum-phase nonlinear systems, " Automatica, vol. 44, no. 8, pp. 1944-1957, Aug. 2008. https://www.researchgate.net/profile/Shu-Jun_Liu/publication/222541154_Global_output-feedback_stabilization_for_a_class_of_stochastic_non-minimum-phase_nonlinear_systems/links/0046351795d18822a6000000 [23] X. J. Xie and J. Tian, "Adaptive state-feedback stabilization of high-order stochastic systems with nonlinear parameterization, " Automatica, vol. 45, no. 1, pp. 126-133, Jan. 2009. https://www.researchgate.net/publication/222686926_Adaptive_state-feedback_stabilization_of_high-order_stochastic_systems_with_nonlinear_parameterization [24] W. Q. Li and X. J. Xie, "Inverse optimal stabilization for stochastic nonlinear systems whose linearizations are not stabilizable, " Automatica, vol. 45, no. 2, pp. 498-503, Feb. 2009. https://www.researchgate.net/publication/220159927_Inverse_optimal_stabilization_for_stochastic_nonlinear_systems_whose_linearizations_are_not_stabilizable [25] Z. J. Wu, X. J. Xie, P. Shi, and Y. Q. Xia, "Backstepping controller design for a class of stochastic nonlinear systems with Markovian switching, " Automatica, vol. 45, no. 4, pp. 997-1004, Apr. 2009. http://cpfd.cnki.com.cn/Article/CPFDTOTAL-KZLL200807002175.htm [26] X. Yu and X. J. Xie, "Output feedback regulation of stochastic nonlinear systems with stochastic iISS inverse dynamics, " IEEE Trans. Automat. Control, vol. 55, no. 2, pp. 304-320, Feb. 2010. https://www.researchgate.net/publication/224090231_Output_Feedback_Regulation_of_Stochastic_Nonlinear_Systems_With_Stochastic_iISS_Inverse_Dynamics [27] X. J. Xie and N. Duan, "Output tracking of high-order stochastic nonlinear systems with application to benchmark mechanical system, " IEEE Trans. Automat. Control, vol. 55, no. 5, pp. 1197-1202, May2010. https://www.researchgate.net/publication/224113801_Output_Tracking_of_High-Order_Stochastic_Nonlinear_Systems_with_Application_to_Benchmark_Mechanical_System [28] L. Liu and X. J. Xie, "Decentralized adaptive stabilization for interconnected systems with dynamic input-output and nonlinear interactions, " Automatica, vol. 46, no. 6, pp. 1060-1067, Jun. 2010. https://www.researchgate.net/publication/220156728_Decentralized_adaptive_stabilization_for_interconnected_systems_with_dynamic_input-output_and_nonlinear_interactions [29] X. Yu, X. J. Xie, and N. Duan, "Small-gain control method for stochastic nonlinear systems with stochastic iISS inverse dynamics, " Automatica, vol. 46, no. 11, pp. 1790-1798, Nov. 2010. https://www.researchgate.net/publication/220159463_Small-gain_control_method_for_stochastic_nonlinear_systems_with_stochastic_iISS_inverse_dynamics [30] N. Duan and X. J. Xie, "Further results on output-feedback stabilization for a class of stochastic nonlinear systems, " IEEE Trans. Automat. Control, vol. 56, no. 5, pp. 1208-1213, May 2011. https://www.researchgate.net/publication/220387044_Further_Results_on_Output-Feedback_Stabilization_for_a_Class_of_Stochastic_Nonlinear_Systems [31] X. J. Xie, N. Duan, and X. Yu, "State-feedback control of high-order stochastic nonlinear systems with SiISS inverse dynamics, " IEEE Trans. Automat. Control, vol. 56, no. 8, pp. 1921-1926, Aug. 2011. [32] L. Liu and X. J. Xie, "Output-feedback stabilization for stochastic high-order nonlinear systems with time-varying delay, " Automatica, vol. 47, no. 12, pp. 2772-2779, Dec. 2011. https://www.researchgate.net/publication/220156150_Output-feedback_stabilization_for_stochastic_high-order_nonlinear_systems_with_time-varying_delay [33] X. J. Xie and L. Liu, "Further results on output feedback stabilization for stochastic high-order nonlinear systems with time-varying delay, " Automatica, vol. 48, no. 10, pp. 2577-2586, Oct. 2012. http://dl.acm.org/citation.cfm?id=2364789 [34] X. J. Xie and L. Liu, "A homogeneous domination approach to state feedback of stochastic high-order nonlinear systems with time-varying delay, " IEEE Trans. Automat. Control, vol. 58, no. 2, pp. 494-499, Feb. 2013. https://www.researchgate.net/publication/260661770_a_homogeneous_domination_approach_to_state_feedback_of_stochastic_high-order_nonlinear_systems_with_time-varying_delay [35] C. R. Zhao and X. J. Xie, "Output feedback stabilization using small-gain method and reduced-order observer for stochastic nonlinear systems, " IEEE Trans. Automat. Control, vol. 58, no. 2, pp. 523-528, Feb. 2013. https://www.researchgate.net/publication/260516630_Output_Feedback_Stabilization_Using_Small-Gain_Method_and_Reduced-Order_Observer_for_Stochastic_Nonlinear_Systems [36] M. Y. Cui, X. J. Xie, and Z. J. Wu, "Dynamics modeling and tracking control of robot manipulators in random vibration environment, " IEEE Trans. Automat. Control, vol. 58, no. 6, pp. 1540-1545, Jun. 2013. https://www.researchgate.net/publication/260661796_dynamics_modeling_and_tracking_control_of_robot_manipulators_in_random_vibration_environment [37] X. J. Xie, N. Duan, and C. R. Zhao, "A combined homogeneous domination and sign function approach to output-feedback stabilization of stochastic high-order nonlinear systems, " IEEE Trans. Automat. Control, vol. 59, no. 5, pp. 1303-1309, May2014. https://www.researchgate.net/publication/270766254_A_Combined_Homogeneous_Domination_and_Sign_Function_Approach_to_Output-Feedback_Stabilization_of_Stochastic_High-Order_Nonlinear_Systems [38] L. Liu and X. J. Xie, "State feedback stabilization for stochastic feedforward nonlinear systems with time-varying delay, " Automatica, vol. 49, no. 4, pp. 936-942, Apr. 2013. https://www.researchgate.net/publication/256660916_State_feedback_stabilization_for_stochastic_feedforward_nonlinear_systems_with_time-varying_delay [39] C. R. Zhao and X. J. Xie, "Global stabilization of stochastic high-order feedforward nonlinear systems with time-varying delay, " Automatica, vol. 50, no. 1, pp. 203-210, Jan. 2014. http://dl.acm.org/citation.cfm?id=2576254.2576563 -

 下载:
下载:

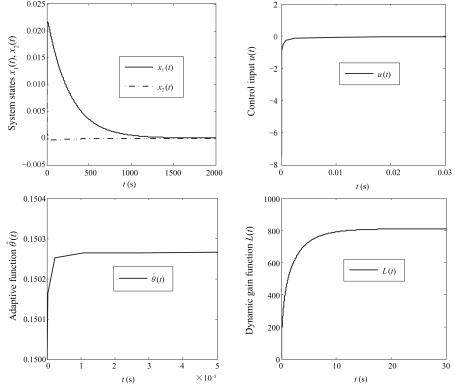
图(1)
计量
- 文章访问数: 2443
- HTML全文浏览量: 402
- PDF下载量: 859
- 被引次数: 0
