

-
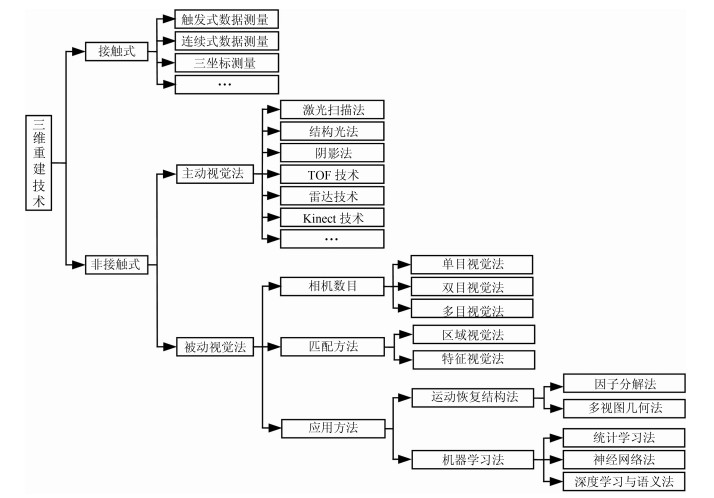
摘要: 三维重建在视觉方面具有很高的研究价值, 在机器人视觉导航、智能车环境感知系统以及虚拟现实中被广泛应用.本文对近年来国内外基于视觉的三维重建方法的研究工作进行了总结和分析, 主要介绍了基于主动视觉下的激光扫描法、结构光法、阴影法以及TOF (Time of flight)技术、雷达技术、Kinect技术和被动视觉下的单目视觉、双目视觉、多目视觉以及其他被动视觉法的三维重建技术, 并比较和分析这些方法的优点和不足.最后对三维重建的未来发展作了几点展望.Abstract: 3D reconstruction is important in vision, which can be widely used in robot vision navigation, intelligent vehicle environment perception and virtual reality. This study systematically reviews and summarizes the progress related to 3D reconstruction technology based on active vision and passive vision, i.e. laser scanning, structured light, shadow method, time of flight (TOF), radar, Kinect technology and monocular vision, binocular vision, multi-camera vision, and other passive visual methods. In addition, extensive comparisons among these methods are analyzed in detail. Finally, some perspectives on 3D reconstruction are also discussed.
-
Key words:
- 3D reconstruction /
- active vision /
- passive vision /
- key techniques
-
现实环境中,感兴趣的语音信号通常会被噪音干扰,严重损害了语音的可懂度,降低了语音识别的性能. 针对噪音,前端语音分离技术是最常用的方法之一.一个好的前端语音分离模块能够极大地提高语音的可懂度和自动语音识别系统的识别性能[1-6]. 然而,在真实环境中,语音分离技术的性能远没有达到令人满意的程度,特别是在非平稳噪音和单声道的情况下,语音分离依然面临着巨大的挑战.本文重点探讨单声道条件下语音分离技术.
几十年来,单声道条件下的语音分离问题被广泛地研究.从信号处理的角度来看,许多方法提出估计噪音的功率谱或者理想维纳滤波器,比如谱减法[7]和维纳滤波法[8-9].其中维纳滤波是最小均方误差意义下分离纯净语音的最优滤波器[9]. 在假定语音和噪音的先验分布的条件下,给定带噪语音,它能推断出语音的谱系数.基于信号处理的方法通常假设噪音是平稳的或者是慢变的[10].在满足假设条件的情况下,这些方法能够取得比较好的分离性能. 然而,在现实情况下,这些假设条件通常很难满足,其分离性能会严重地下降,特别在低信噪比条件下,这些方法通常会失效[9].相比于信号处理的方法,基于模型的方法利用混合前的纯净信号分别构建语音和噪音的模型,例如文献[11-13],在低信噪比的情况下取得了重要的性能提升.但是基于模型的方法严重依赖于事先训练的语音和噪音模型,对于不匹配的语音或者噪音,其性能通常会严重下降.在基于模型的语音分离方法中,非负矩阵分解是常用的建模方法,它能挖掘非负数据中的局部基表示,目前已被广泛地应用到语音分离中[14-15].然而非负矩阵分解是一个浅层的线性模型,很难挖掘语音数据中复杂的非线性结构. 另外,非负矩阵分解的推断过程非常费时,很难应用到实际应用中.计算听觉场景分析是另一个重要的语音分离技术,它试图模拟人耳对声音的处理过程来解决语音分离问题[16].计算听觉场景分析的基本计算目标是估计一个理想二值掩蔽,根据人耳的听觉掩蔽来实现语音的分离. 相对于其他语音分离的方法,计算听觉场景分析对噪音没有任何假设,具有更好的泛化性能. 然而,计算听觉场景分析严重依赖于语音的基音检测,在噪音的干扰下,语音的基音检测是非常困难的. 另外,由于缺乏谐波结构,计算听觉场景分析很难处理语音中的清音成分.
语音分离旨在从被干扰的语音信号中分离出有用的信号,这个过程能够很自然地表达成一个监督性学习问题 [17-20].一个典型的监督性语音分离系统通常通过监督性学习算法,例如深度神经网络,学习一个从带噪特征到分离目标(例如理想掩蔽或者感兴趣语音的幅度谱)的映射函数[17].最近,监督性语音分离得到了研究者的广泛关注,取得了巨大的成功.作为一个新的研究趋势,相对于传统的语音增强技术[9],监督性语音分离不需要声源的空间方位信息,且对噪音的统计特性没有任何限制,在单声道,非平稳噪声和低信噪比的条件下显示出了明显的优势和相当光明的研究前景[21-23].
从监督性学习的角度来看,监督性语音分离主要涉及特征、模型和目标三个方面的内容.语音分离系统通常利用时频分解技术从带噪语音中提取时频域特征,常用的时频分解技术有短时傅里叶变换 (Short-time Fourier transform,STFT)[24]和Gammatone听觉滤波模型[25]. 相应地,语音分离特征可以分为傅里叶变换域特征和Gammatone滤波变换域特征.Wang和Chen等在文献[26-27]中系统地总结和分析了Gammatone滤波变换域特征,提出了一些列组合特征和多分辨率特征. 而Mohammadiha、Xu、Weninger、Le Roux、Huang等使用傅里叶幅度谱或者傅里叶对数幅度谱作为语音分离的输入特征[14, 18, 20, 23, 28-29]. 从建模单元来区分,语音分离的特征又可分为时频单元级别的特征和帧级别的特征.时频单元级别的特征从一个时频单元的信号中提取,帧级别的特征从一帧信号中提取,早期,由于模型学习能力的限制,监督性语音分离方法通常对时频单元进行建模,因此使用时频单元级别的特征,例如文献[1]和文献[30- 34]. 现阶段,监督性语音分离主要使用帧级别的特征[17-21, 23, 35-36].监督性语音分离系统的学习模型主要分为浅层模型和深层模型.早期的监督性语音分离系统主要使用浅层模型,比如高斯混合模型(Gaussian mixture model,GMM)[1]、支持向量机(Support vector machine,SVM)[26, 30, 32]和非负矩阵分解(Nonnegative matrix factorization,NMF)[14]. 然而,语音信号具有明显的时空结构和非线性关系,浅层结构在挖掘这些非线性结构信息的能力上非常有限.而深层模型由于其多层次的非线性处理结构,非常擅长于挖掘数据中的结构信息,能够自动提取抽象化的特征表示,因此,近年来,深层模型被广泛地应用到语音和图像处理中,并取得了巨大的成功[37]. 以深度神经网络(Deep neural network,DNN) 为代表的深度学习[37]是深层模型的典型代表,目前已被广泛应用到语音分离中[5, 18, 20, 22, 29, 38-39].最近,Le Roux、Hershey 和Hsu等将NMF扩展成深层结构并应用到语音分离中,取得了巨大的性能提升[23, 40-41],在语音分离中显示了巨大的研究前景,日益得到人们的重视.理想时频掩蔽和目标语音的幅度谱是监督性语音分离的常用目标,如果不考虑相位的影响,利用估计的掩蔽或者幅度谱能够合成目标语音波形,实验证明利用这种方法分离的语音能够显著地抑制噪音 [42-43],提高语音的可懂度和语音识别系统的性能[38, 44-49]. 但是,最近的一些研究显示,相位信息对于语音的感知质量是重要的[50].为此,一些语音分离方法开始关注相位的估计,并取得了分离性能的提升[51-52].为了将语音的相位信息考虑到语音分离中,Williamson等将浮值掩蔽扩展到复数域,提出复数域的掩蔽目标,该目标在基于深度神经网络的语音分离系统中显著地提高了分离语音的感知质量[53].
语音分离作为一个重要的研究领域,几十年来,受到国内外研究者的广泛关注和重视. 近年来,监督性语音分离技术取得了重要的研究进展,特别是深度学习的应用,极大地促进了语音分离的发展. 然而,对监督性语音分离方法一直以来缺乏一个系统的分析和总结,尽管有一些综述性的工作被提出,但是它们往往局限于其中的一个方面,例如,Wang等在文献[17]中侧重于监督性语音分离的目标分析,而在文献[26]中主要比较了监督性语音分离的特征,并没有一个整体的总结和分析,同时也没有对这些工作的相互联系以及区别进行研究.本文从监督性语音分离涉及到的特征、模型和目标三个主要方面对语音分离的一般流程和整体框架进行了详细的介绍、归纳和总结. 以此希望为该领域的研究及应用提供一个参考.
本文的组织结构如下: 第1节概述了语音分离的主要流程和整体框架;第2~5节分别介绍了语音分离中的时频分解、特征、目标、模型等关键模块;最后,对全文进行了总结和展望,并从建模单元、目标和训练模型三个方面对监督性语音分离方法进行了比较和分析.
1. 系统结构
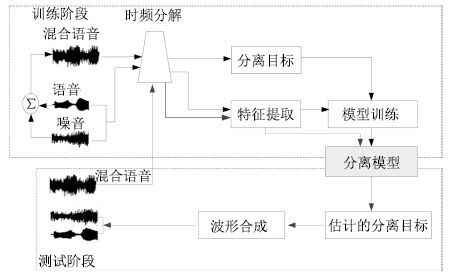
图 1给出了语音分离的一般性结构框图,主要分为5个模块: 1) 时频分解,通过信号处理的方法(听觉滤波器组或者短时傅里叶变换)将输入的时域信号分解成二维的时频信号表示.2) 特征提取,提取帧级别或者时频单元级别的听觉特征,比如,短时傅里叶变换谱(FFT-magnitude)、短时傅里叶变换对数谱(FFT-log)、Amplitude modulation spectrogram (AMS)、Relative spectral transform and perceptual linear prediction (RASTA-PLP)、Mel-frequency cepstral coefficients (MFCC)、Pitch-based features以及Multi-resolution cochleagram (MRCG). 3) 分离目标,利用估计的分离目标以及混合信号合成目标语音的波形信号.针对语音分离的不同应用特点,例如针对语音识别,语音分离在分离语音的过程中侧重减少语音畸变和尽可能地保留语音成分.针对语音通讯,语音分离侧重于提高分离语音的可懂度和感知质量.常用的语音分离目标主要分为时频掩蔽的目标、目标语音幅度谱估计的目标和隐式时频掩蔽目标,时频掩蔽目标训练一个模型来估计一个理想时频掩蔽,使得估计的掩蔽和理想掩蔽尽可能相似;目标语音幅度谱估计的方法训练一个模型来估计目标语音的幅度谱,使得估计的幅度谱与目标语音的幅度谱尽可能相似;隐式时频掩蔽目标将时频掩蔽技术融合到实际应用的模型中,用来增强语音特征或估计目标语音,隐式掩蔽并不直接估计理想掩蔽,而是作为中间的一个计算过程来得到最终学习的目标,隐式掩蔽作为一个确定性的计算过程,并没有参数需要学习,最终的目标误差通过隐式掩蔽的传导来更新模型参数. 4) 模型训练,利用大量的输入输出训练对通过机器学习算法学习一个从带噪特征到分离目标的映射函数,应用于语音分离的学习模型大致可分为浅层模型(GMM,SVM,NMF)和深层模型(DNN,DSN,CNN,RNN,LSTM,Deep NMF). 5) 波形合成,利用估计的分离目标以及混合信号,通过逆变换(逆傅里叶变换或者逆Gammatone 滤波) 获得目标语音的波形信号.
2. 时频分解
时频分解是整个系统的前端处理模块,通过时频分解,输入的一维时域信号能够被分解成二维的时频信号.常用的时频分解方法包括短时傅里叶变换[24]和Gammatone听觉滤波模型[25].
假设w(t)=w(-t)是一个实对称窗函数,X(t,f)是一维时域信号x(k)在第t时间帧、第f个频段的短时傅里叶变换系数,则
$X(t,f)=\int_{-\infty }^{+\infty }{x(k)w(k-t)\exp (-j2\pi fk)dk}$
(1) 对应的傅里叶能量幅度谱px(t,f)为
${{p}_{x}}(t,f)=\left| X(t,f) \right|$
(2) 其中, $|\cdot |$ 表示复数域的取模操作. 为了简化符号表示,用向量 $p\in R_{+}^{F\times 1}$ 表示时间帧为t的幅度谱,这里F是傅里叶变换的频带数.短时傅里叶变换是完备而稳定的[54],可以通过短时傅里叶逆变换(Inverse short-time Fourier transform,ISTFT)从X(t,f)精确重构x(k). 也就是说,可以通过估计目标语音的短时傅里叶变换系数来实现语音的分离或者增强,用 ${{\hat{Y}}_{s}}(t,f)$ 来表示估计的目标语音的短时傅里叶变换系数,那么目标语音的波形 $\hat{s}(k)$ 可以通过ISTFT计算
$\hat{s}(k)=\int_{-\infty }^{+\infty }{\int_{-\infty }^{+\infty }{{{{\hat{Y}}}_{s}}(k)w(k-t)\exp (j2\pi fk)dfdk}}$
(3) 如果不考虑相位的影响,语音分离过程可以转换为目标语音幅度谱的估计问题,一旦估计出目标语音的幅度谱 ${{\widehat{y}}_{s}}\in R_{+}^{F\times 1}$ ,联合混合语音的相位,通过ISTFT,能得到目标语音的估计波形Ŝ(k)[17].
Gammatone听觉滤波使用一组听觉滤波器g(t)对输入信号进行滤波,得到一组滤波输出G(k,f). 滤波器组的冲击响应为
$g(t)=\left\{ \begin{array}{*{35}{l}} {{t}^{l-1}}\exp (-2\pi bt)\cos (2\pi ft), & \ t\ge 0 \\ 0,& 其他 \\ \end{array} \right.$
(4) 其中,滤波器阶数l=4,b为等效矩形带宽(Equivalent rectangle bandwidth,ERB),f为滤波器的中心频率,Gammatone滤波器组的中心频率沿对数频率轴等间隔地分布在[80Hz,5kHz]. 等效矩形带宽与中心频率一般满足式(5) ,可以看出随着中心频率的增加,滤波器带宽加宽.
$ERB(f)=24.7(0.0043f+1.0) $
(5) 对于4阶的Gammatone滤波器,Patterson等[25]给出了带宽的计算公式
$b=1.093ERB(f)$
(6) 然后,采用交叠分段的方法,以20ms为帧长,10ms为偏移量对每一个频率通道的滤波响应做分帧加窗处理.得到输入信号的时频域表示,即时频单元. 在计算听觉场景分析系统中,时频单元被认为是处理的最小单位,用T-F表示.通过计算时频单元内的内毛细胞输出(或者听觉滤波器输出) 能量,就得到了听觉谱(Cochleagram) ,本文用GF(t,f)表示时间帧t频率为f的时频单元T-F的听觉能量.
3. 特征
语音分离能够被表达成一个学习问题,对于机器学习问题,特征提取是至关重要的步骤,提取好的特征能够极大地提高语音分离的性能.从特征提取的基本单位来看,主要分为时频单元级别的特征和帧级别的特征.时频单元级别的特征是从一个时频单元的信号中提取特征,这种级别的特征粒度更细,能够关注到更加微小的细节,但是缺乏对语音的全局性和整体性的描述,无法获取到语音的时空结构和时序相关性,另外,一个时频单元的信号,很难表征可感知的语音特性(例如,音素).时频单元级别的特征主要用于早期以时频单元为建模单元的语音分离系统中,例如,文献[1, 26, 30-32],这些系统孤立地看待每个时频单元,在每一个频带上训练二值分类器,判断每一个频带上的时频单元被语音主导还是被噪音主导;帧级别的特征是从一帧信号中提取的,这种级别的特征粒度更大,能够抓住语音的时空结构,特别是语音的频带相关性,具有更好的全局性和整体性,具有明显的语音感知特性.帧级别的特征主要用于以帧为建模单元的语音分离系统中,这些系统一般输入几帧上下文帧级别特征,直接预测整帧的分离目标,例如,文献[17-20, 27, 35]. 近年来,随着语音分离研究的深入,已有许多听觉特征被提出并应用到语音分离中,取得了很好的分离性能.下面,我们简要地总结几种常用的听觉特征.
1) 梅尔倒谱系数 (Mel-frequency cepstral coefficient,MFCC).为了计算MFCC,输入信号进行20ms帧长和10ms帧移的分帧操作,然后使用一个汉明窗进行加窗处理,利用STFT计算能量谱,再将能量谱转化到梅尔域,最后,经过对数操作和离散余弦变换(Discrete cosine transform,DCT)并联合一阶和二阶差分特征得到39维的MFCC.
2) PLP (Perceptual linear prediction).PLP能够尽可能消除说话人的差异而保留重要的共振峰结构,一般认为是与语音内容相关的特征,被广泛应用到语音识别中.和语音识别一样,我们使用12阶的线性预测模型,得到13维的PLP特征.
3) RASTA-PLP (Relative spectral transform PLP).RASTA-PLP引入了RASTA滤波到PLP[55],相对于PLP特征,RASTA-PLP对噪音更加鲁棒,常用于鲁棒性语音识别. 和PLP一样,我们计算13维的RASTA-PLP特征.
4) GFCC (Gammatone frequency cepstral coefficient).GFCC特征是通过Gammatone听觉滤波得到的.我们对每一个Gammatone滤波输出按照100Hz的采样频率进行采样.得到的采样通过立方根操作进行幅度压制. 最后,通过DCT得到GFCC.根据文献[56]的建议,一般提取31维的GFCC特征.
5) GF (Gammatone feature). GF特征的提取方法和GFCC类似,只是不需要DCT步骤. 一般提取64维的GF特征.
6) AMS (Amplitude modulation spectrogram). 为了计算AMS特征,输入信号进行半波整流,然后进行四分之一抽样,抽样后的信号按照32ms帧长和10ms帧移进行分帧,通过汉明窗加窗处理,利用STFT得到信号的二维表示,并计算STFT幅度谱,最后利用15个中心频率均匀分布在15.6~400Hz 的三角窗,得到15维的AMS特征.
7) 基于基音的特征 (Pitch-based feature).基于基音的特征是时频单元级别的特征,需要对每一个时频单元计算基音特征.这些特征包含时频单元被目标语音主导的可能性.我们计算输入信号的Cochleagram,然后对每一个时频单元计算6维的基音特征,详细的计算方法可以参考文献[26, 57].
8) MRCG (Multi-resolution cochleagram).MRCG的提取是基于语音信号的Cochleagram表示的. 通过Gammatone滤波和加窗分帧处理,我们能得到语音信号的Cochleagram表示,然后通过以下步骤可以计算MRCG.
步骤 1. 给定输入信号,计算64通道的Cochle- agram,CG1,对每一个时频单元取对数操作.
步骤 2. 同样地,用200ms的帧长和10ms的帧移计算CG2.
步骤 3. 使用一个长为11时间帧和宽为11频带的方形窗对CG1进行平滑,得到CG3.
步骤 4. 和CG3的计算类似,使用23 ×23的方形窗对CG1进行平滑,得到CG4.
步骤 5. 串联CG1,CG2,CG3 和 CG4得到一个64 ×4的向量,即为MRCG.
MRCG是一种多分辨率的特征,既有关注细节的高分辨率特征,又有把握全局性的低分辨率特征.
9) 傅里叶幅度谱(FFT-magnitude). 输入的时域信号进行分帧处理,然后对每帧信号进行STFT,得到STFT系数,然后对STFT进行取模操作即得到STFT幅度谱.
10) 傅里叶对数幅度谱(FFT-log-magnitude).STFT对数幅度谱是在STFT幅度谱的基础上取对数操作得到的,主要目的是凸显信号中的高频成分.
以上介绍的听觉特征是语音分离的主要特征,这些特征之间既存在互补性又存在冗余性. 研究显示,对于单个独立特征,GFCC和RASTA-PLP分别是噪音匹配条件和噪音不匹配条件下的最好特征[26].基音反映了语音的固有属性,基于基音的特征对语音分离具有重要作用,很多研究显示基于基音的特征和其他特征进行组合都会显著地提高语音分离的性能,而且基于基音的特征非常鲁棒,对于不匹配的听觉条件具有很好的泛化性能.然而,在噪音条件下,准确地估计语音的基音是非常困难,又因为缺乏谐波结构,基于基音的特征仅能用于浊音段的语音分离,而无法处理清音段,因此在实际应用中,基于基音的特征很少应用到语音分离中[26],实际上,语音分离和基音提取是一个"鸡生蛋,蛋生鸡"的问题,它们之间相互促进而又相互依赖. 针对这一问题,Zhang等巧妙地将基音提取和语音分离融合到深度堆叠网络(Deep stacking network,DSN) 中,同时提高了语音分离和基音提取的性能 [34].相对于基音特征,AMS 同时具有清音和浊音的特性,能够同时用于浊音段和清音段的语音分离,然而,AMS的泛化性能较差[58]. 针对各个特征之间的不同特性,Wang等利用Group Lasso的特征选择方法得到{AMS} +{RASTA} -{PLP} + {MFCC}的最优特征组合[26],这个组合特征在各种测试条件下取得了稳定的语音分离性能而且显著地优于单独的特征,成为早期语音分离系统最常用的特征. 在低信噪比条件下,特征提取对于语音分离至关重要,相对于其他特征或者组合特征,Chen等提取的多分辨率特征MRCG表现了明显的优势[27],逐渐取代{AMS}+ {RASTA} - {PLP} + {MFCC}的组合特征成为语音分离最常用的特征之一. 在傅里叶变换域条件下,FFT-magnitude或FFT-log-magnitude是最常用的语音分离特征,由于高频能量较小,相对于FFT-magnitude,FFT-log-magnitude能够凸显高频成分,但是,一些研究表明,在语音分离中,FFT-magnitude要略好于FFT-log-magnitude[28].
语音分离发展到现阶段,MRCG和FFT-magnitude分别成为Gammtone域和傅里叶变换域下最主流的语音分离特征.此外,为了抓住信号中的短时变化特征,一般还会计算特征的一阶差分和二阶差分,同时,为了抓住更多的信息,通常输入特征会扩展上下文帧. Chen等还提出使用ARMA模型(Auto-regressive and moving average model)对特征进行平滑处理,来进一步提高语音分离性能[27].
4. 目标
语音分离有许多重要的应用,总结起来主要有两个方面: 1) 以人耳作为目标受体,提高人耳对带噪语音的可懂度和感知质量,比如应用于语音通讯; 2) 以机器作为目标受体,提高机器对带噪语音的识别准确率,例如应用于语音识别.对于这两个主要的语音分离目标,它们存在许多密切的联系,例如,以提高带噪语音的可懂度和感知质量为目标的语音分离系统通常可以作为语音识别的前端处理模块,能够显著地提高语音识别的性能[59],Weninger等指出语音分离系统的信号失真比(Signal-to-distortion ratio,SDR)和语音识别的字错误率(Word error rate,WER)有明显的相关性[5],Weng等将多说话人分离应用于语音识别中也显著地提高了识别性能[6].尽管如此,它们之间仍然存在许多差别,以提高语音的可懂度和感知质量为目标的语音分离系统侧重于去除混合语音中的噪音成分,往往会导致比较严重的语音畸变,而以提高语音识别准确率为目标的语音分离系统更多地关注语音成分,在语音分离过程中尽可能保留语音成分,避免语音畸变.针对语音分离两个主要目标,许多具体的学习目标被提出,常用的分离目标大致可以分为三类: 时频掩蔽、 语音幅度谱估计和隐式时频掩蔽.其中时频掩蔽和语音幅度谱估计的目标被证明能显著地抑制噪音,提高语音的可懂度和感知质量[17-18].而隐式时频掩蔽通常将掩蔽技术融入到实际应用模型中,时频掩蔽作为中间处理过程来提高其他目标的性能,例如语音识别[5, 60]、目标语音波形的估计[21].
4.1 时频掩蔽
时频掩蔽是语音分离的常用目标,常见的时频掩蔽有理想二值掩蔽和理想浮值掩蔽,它们能显著地提高分离语音的可懂度和感知质量.一旦估计出了时频掩蔽目标,如果不考虑相位信息,通过逆变换技术即可合成目标语音的时域波形. 但是,最近的一些研究显示,相位信息对于提高语音的感知质量具有重要的作用[50]. 为此,一些考虑相位信息的时频掩蔽目标被相继提出,例如复数域的浮值掩蔽(Complex ideal ratio mask,CIRM)[53].
1) 理想二值掩蔽(Ideal binary mask,IBM).理想二值掩蔽(IBM)是计算听觉场景分析的主要计算目标[61],已经被证明能够极大地提高分离语音的可懂度[44-47, 62].IBM是一个二值的时频掩蔽矩阵,通过纯净的语音和噪音计算得到.对于每一个时频单元,如果局部信噪比SNR(t,f)大于某一局部阈值(Local criterion,LC),掩蔽矩阵中对应的元素标记为1,否则标记为0. 具体来讲,IBM的定义如下:
$IBM(t,f)=\left\{ \begin{array}{*{35}{l}} 1,& \text{若}SNR(t,f)>LC \\ 0,& \text{其他} \\ \end{array} \right.$
(7) 其中,SNR(t,f)定义了时间帧为t和频率为f的时频单元的局部信噪比.LC的选择对语音的可懂度具有重大的影响[63],一般设置LC小于混合语音信噪比5dB,这样做的目的是为了保留足够多的语音信息. 例如,混合语音信噪比是-5dB,则对应的LC设置为-10dB.
2) 目标二值掩蔽(Target binary mask,TBM). 类似于IBM,目标二值掩蔽(TBM)也是一个二值的时频掩蔽矩阵. 不同的是,TBM是通过纯净语音的能量和一个固定的参照噪音(Speech-shaped noise,SSN) 的能量计算得到的. 也就是说,在式(7) 中的SNR(t,f)项是用参考的SSN而不是实际的噪音计算的.尽管TBM的计算独立于噪音,但是实验测试显示TBM取得了和IBM相似的可懂度提高[63].TBM能够提高语音的可懂度的原因是它保留了与语音感知密切相关的时空结构模式,即语音能量在时频域上的分布. 相对于IBM,TBM可能更加容易学习.
3) Gammtone域的理想浮值掩蔽(Gammtone ideal ratio mask,IRM_Gamm)
理想浮值掩蔽定义如下:
$\begin{align} & IR{{M}_{gamm}}(t,f)\text{=}{{\left( \frac{{{S}^{2}}(t,f)}{{{S}^{2}}(t,f)+{{N}^{2}}(t,f)} \right)}^{\beta }}\text{=} \\ & {{\left( \frac{SNR(t,f)}{SNR(t,f)+1} \right)}^{\beta }} \\ \end{align}$
(8) 其中,S2(t,f)和N2(t,f)分别定义了混合语音中时间帧为t和频率为f的时频单元的语音和噪音的能量.β是一个可调节的尺度因子. 如果假定语音和噪音是不相关的,那么IRM在形式上和维纳滤波密切相关[9, 64].大量的实验表明β = 0.5是最好的选择,此时,式(8) 和均方维纳滤波器非常相似,而维纳滤波是最优的能量谱评估[9].
4) 傅里叶变换域的理想浮值掩蔽(FFT ideal ratio mask,IRM_FFT).类似于Gammtone域的理想浮值掩蔽,傅里叶域的理想浮值掩蔽IRM_FFT的定义如下:
$\begin{align} & IR{{M}_{FFT}}(t,f)\text{=}\frac{{{\left| {{Y}_{s}}(t,f) \right|}^{2}}}{{{\left| {{Y}_{s}}(t,f) \right|}^{2}}+{{\left| {{Y}_{n}}(t,f) \right|}^{2}}}\text{=} \\ & \frac{{{P}_{s}}(t,f)}{{{P}_{s}}(t,f)+{{P}_{n}}(t,f)} \\ \end{align}$
(9) 其中,Ys(t,f)和Yn(t,f)是混合语音中纯净的语音和噪音的短时傅里叶变换系数.Ps(t,f)和Pn(t,f)分别是它们对应的能量密度.
5) 短时傅里叶变换掩蔽(Short-time Fourier transform mask,FFT-Mask).不同于IRM_FFT,FFT-Mask的定义如下:
$Mas{{k}_{FFT}}(t,f)=\frac{\left| {{Y}_{s}}(t,f) \right|}{\left| X(t,f) \right|}$
(10) 其中,Ys(t,f)和X(t,f)是纯净的语音和混合语音的短时傅里叶变换系数.IRM_FFT的取值范围在[0,1],显然FFT-Mask的取值范围可以超过1.
6) 最优浮值掩蔽(Optimal ratio time-frequency mask,ORM).理想浮值掩蔽(IRM) 是假定在语音和噪音不相关的条件下,能够取得最小均方误差意义下最大信噪比增益[42-43].然而在真实环境中,语音和噪音通常存在一定的相关性,针对这个问题,Liang等[42-43]推导出一般意义下的最小均方误差的最优浮值掩蔽,定义如下:
$\begin{align} & ORM(t,f)= \\ & \frac{{{P}_{s}}(t,f)+\Re ({{Y}_{s}}(t,f)Y_{n}^{*}(t,f))}{{{P}_{s}}(t,f)+{{P}_{n}}(t,f)+2\Re ({{Y}_{s}}(t,f)Y_{n}^{*}(t,f))} \\ \end{align}$
(11) 其中, $\Re (\cdot )$ 表示取复数的实部,*表示共轭操作.相对于IRM,ORM考虑了语音和噪音的相关性,其变化范围更大,估计难度也更大.
7) 复数域的理想浮值掩蔽(Complex ideal ratio mask,CIRM).传统的IRM定义在幅度域,而CIRM定义在复数域.其目标是通过将CIRM作用到带噪语音的STFT系数得到目标语音的STFT系数.具体地,给定带噪语音在时间帧为t和频率为f的时频单元的STFT系数X,那么目标语音在对应时频单元的STFT系数Y可以通过下式计算得到:
$Y=M\times X$
(12) 其中,×定义复数乘法操作,M定义时间帧为t和频率为f的时频单元的CIRM.通过数学推导我们能计算得到:
$M=\frac{{{X}_{r}}{{Y}_{r}}+{{X}_{i}}{{Y}_{i}}}{X_{r}^{2}+X_{i}^{2}}+j\frac{{{X}_{r}}{{Y}_{i}}-{{X}_{i}}{{Y}_{r}}}{X_{r}^{2}+X_{i}^{2}}$
(13) 其中,Xr和Yr分别是X和Y的实部,Xi和Yi分别是X和Y的虚部,j是虚数单位.定义Mr和Mi分别是M的实部和虚部,那么,
${{M}_{r}}=\frac{{{X}_{r}}{{Y}_{r}}+{{X}_{i}}{{Y}_{i}}}{X_{r}^{2}+X_{i}^{2}}$
(14) ${{M}_{i}}=\frac{{{X}_{r}}{{Y}_{i}}-{{X}_{i}}{{Y}_{r}}}{X_{r}^{2}+X_{i}^{2}}$
(15) 在实际语音分离中通常不会直接估计复数域的M,而是通过估计其实部Mr和虚部Mi.但Mr和Mi的取值可能会超过[0,1],这往往会增大Mr和Mi估计难度. 因此,在实际应用中通常会利用双曲正切函数对Mr和Mi进行幅度压制.
4.2 语音幅度谱估计
如果不考虑相位的影响,语音分离问题可以转化为目标语音幅度谱的评估,一旦从混合语音中评估出了目标语音的幅度谱,利用混合语音的相位信息,通过逆变换即可得到目标语音的波形.常见的幅度谱包括Gammtone域幅度谱和STFT幅度谱.
1) Gammtone域幅度谱 (Gammatone frequency power spectrum,GF-POW).时域信号经过Gammtone滤波器组滤波和分帧加窗处理,可以得到二维的时频表示Cochleagram.直接估计目标语音的Gammtone域幅度谱(GF-POW)能够实现语音的分离.对于Gammtone滤波,由于没有直接的逆变换方法,我们可以通过估计的GF-POW和混合语音的GF-POW构造一个时频掩蔽 $\sqrt{S_{GF}^{2}(t,f)/X_{GF}^{2}(t,f)}$ 来合成目标语音的波形,其中, $S_{GF}^{2}(t,f)$ 和 $X_{GF}^{2}(t,f)$ 分别是纯净语音和混合语音在Gammtone域下时间帧为t和频带为f的时频单元的能量.
2) 短时傅里叶变换幅度谱 (Short-time Fourier transform spectral magnitude,FFT-magnitude). 时域信号经过分帧加窗处理,然后通过STFT,可以得到二维的时频表示,如果不考虑相位的影响,我们可以直接估计目标语音的STFT幅度谱,利用原始混合语音的相位,通过IFTST可以估计得到目标语音的时域波形.
4.3 隐式时频掩蔽
语音分离旨在从混合语音中分离出语音成分,尽管可以通过估计理想时频掩蔽来分离目标语音,但理想时频掩蔽是一个中间目标,并没有针对实际的语音分离应用直接优化最终的实际目标. 针对这些问题,隐式时频掩蔽被提取,在这些方法中,时频掩蔽作为一个确定性的计算过程被融入到具体应用模型中,例如识别模型或者分离模型,它们并没有估计理想时频掩蔽,其最终的目标是估计目标语音的幅度谱甚至是波形,或者提高语音识别的准确率.
Huang等提出将掩蔽融合到目标语音的幅度谱估计中[19, 28].在文献[29]中,深度神经网络作为语音分离模型,时频掩蔽函数作为额外的处理层加入到网络的原始输出层,如图 2所示,通过时频掩蔽,目标语音的幅度谱从混合语音的幅度谱中估计出来.其中时频掩蔽函数Ms和Mn通过神经网络原始输出(语音和噪音幅度谱的初步估计)计算得到的,如下:
${{M}_{s}}=\frac{\left| {{\widehat{y}}_{s}} \right|}{\left| {{\widehat{y}}_{s}} \right|+\left| {{\widehat{y}}_{n}} \right|},{{M}_{n}}=\frac{\left| {{\widehat{y}}_{n}} \right|}{\left| {{\widehat{y}}_{s}} \right|+\left| {{\widehat{y}}_{n}} \right|}$
(16) 
一旦时频掩蔽被计算出来,就可以通过掩蔽技术从混合语音的幅度谱{X}估计出语音和噪音的幅度谱 ${{\widetilde{y}}_{s}}$ 和 ${{\widetilde{y}}_{n}}$ :
${{\widetilde{y}}_{s}}={{M}_{s}}\otimes X,\ {{\widetilde{y}}_{n}}={{M}_{n}}\otimes X$
(17) 需要注意的是原始的网络输出并不用来计算误差函数,仅仅用来计算时频掩蔽函数,时频掩蔽函数是确定性的,并没有连接权重,掩蔽输出用来计算误差并以此来更新模型参数.
Wang等提出将时频掩蔽融合到目标语音波形估计中[21],在文献[21]中,时频掩蔽作为神经网络的一部分,掩蔽函数从混合语音的STFT幅度谱估计目标语音的STFT幅度谱,然后通过ISTFT,利用混合语音的相位信息和估计的STFT幅度谱合成目标语音的时域波形,如图 3所示,估计的时域波形与目标波形计算误差,最后通过反向传播更新网络权重.假设m是最后一个隐层的输出,它可以看成是估计的掩蔽,用来从混合语音的STFT幅度谱x中估计目标语音的STFT幅度谱 ${{\widetilde{y}}_{s}}$ .
${{\widetilde{y}}_{s}}=m\otimes x$
(18) 评估的目标语音幅度谱加上对应的混合语音的相位p输入到逆傅里叶变换层能够得到目标语音的时域波形信号.
$\widehat{s}=\operatorname{IFFT}({{[c,\operatorname{flipud}({{({{c}_{2:d}})}^{*}})]}^{T}})$
(19) 其中,c是目标语音的傅里叶变换系数,它能够通过下面的公式得到:
$c={{\widetilde{y}}_{s}}\otimes {{e}^{jp}}$
(20) d = F/2,F是傅里叶变换的分析窗长.flipud定义了向量的上下翻转操作,*是复数的共轭操作.下标m:n取向量从m到n的元素的操作.
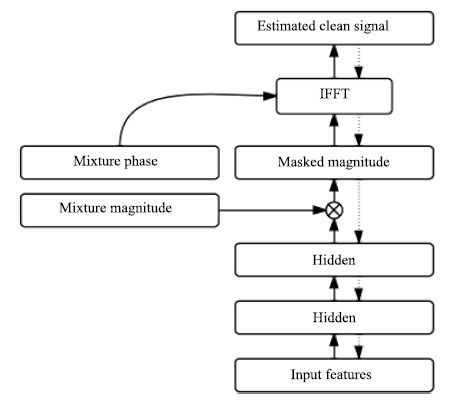
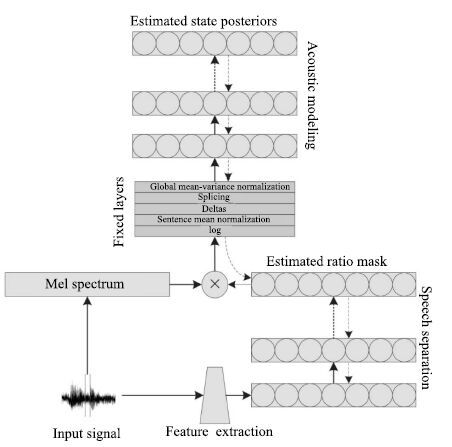
Narayanan等[60]提出将时频掩蔽融入到语音识别的声学模型中,时频掩蔽作为神经网络的中间处理层,从带噪的梅尔谱特征中掩蔽出语音的梅尔谱特征,然后输入到下层网络中进行状态概率估计,如图 4 所示.注意时频掩蔽仅仅是神经网络的中间处理层的输出,并不是以理想时频掩蔽作为目标学习而来的,确切地说是根据语音识别的状态目标学习而来的,实验结果显示,时频掩蔽输出具有明显的降噪效果,这从侧面显示了语音识别与语音分离之间存在密切联系.
以上介绍的是监督性语音分离的主要目标. 在时频掩蔽目标中,理想二值掩蔽具有最为简单的形式,而且具有听觉感知掩蔽的心理学依据,是早期监督性语音分离最常用的分离目标,其分离的语音能够极大地提高语音的可懂度,然而语音的听觉感知质量往往得不到提高.理想浮值掩蔽具有0到1的平滑形式,近似于维纳滤波,不仅能够提高分离语音的可懂度而且能够显著地提高语音的感知质量,在语音和噪音独立的情况下能够取得最优信噪比增益. 相比于理想二值掩蔽,最优浮值掩蔽是更为一般意义下的最优信噪比增益目标,它考虑了语音和噪音之间的相关性,但是最优浮值掩蔽的学习难度也相对较大,目前尚未应用到监督性语音分离中. 之前大部分时频掩蔽,都没有考虑语音的相位信息,而研究表明相位信息对于提高语音的感知质量具有重要作用.复数域的理想浮值掩蔽考虑了语音的相位信息,被应用到监督性语音分离中,取得了显著的性能提高. 语音幅度谱估计的目标直接估计目标语音的幅度谱,相对于时频掩蔽目标,更为直接也更为灵活,然而其学习难度也更大,常用的语音幅度谱估计的目标是短时傅里叶变换域的语音幅度谱.隐式时频掩蔽目标并没有直接估计理想时频掩蔽,而是将时频掩蔽融入到实际应用的模型中,直接估计最终的目标,例如目标语音的波形或者语音识别的状态概率,这种方式学习到的时频掩蔽和实际目标最相关,目前,正广泛应用于语音分离系统中.
5. 模型
语音分离能够很自然地表达成一个监督性学习问题,一个典型的监督性语音分离系统利用学习模型学习一个从带噪特征到分离目标的映射函数.目前已有许多学习模型应用到语音分离中,常用的模型大致可以分为两类:浅层模型和深层模型. 在早期的监督性语音分离中[1, 14, 31],浅层模型通常直接对输入的带噪时频单元的分布进行概率建模或区分性建模,例如GMM[1]和SVM[31],或者直接对输入的带噪特征数据进行矩阵分解,以推断混合数据中语音和噪音的成分,例如NMF[14].由于浅层模型没有从数据中自动抽取有用特征的能力,因此,它们严重依赖于人工设计的特征,另外,浅层模型对高维数据处理的能力通常比较有限,很难通过扩展上下文帧来挖掘语音信号中的时频相关性.深层模型是近几年来受到极大关注的学习模型,在语音和图像等领域都取得了巨大的成功.由于深层模型层次化的非线性处理,使得它能够自动抽取输入数据中对目标最有力的特征表示,相比于浅层模型,深层模型能够处理更原始的高维数据,对特征设计的知识要求相对较低,而且深层模型擅长于挖掘数据中的结构化特性和结构化输出预测.由于语音的产生机制,语音分离的输入特征和输出目标都呈现了明显的时空结构,这些特性非常适合用深层模型来进行建模.许多深层模型广泛应用到语音分离中,包括DNN[18]、 DSN[33-34]、 CNN[22]、 RNN[19-20, 28]、 Deep NMF[23] 和 LSTM[39].
5.1 浅层模型
1) 高斯混合模型(GMM). 高斯混合模型能够刻画任意复杂的分布,Kim等[1]利用GMM分别对每一个频带被目标语音主导的时频单元和被噪音主导的时频单元进行建模,这里各个频带是独立建模的,在测试阶段,给定时频单元的输入特征,计算被目标语音主导和被噪音主导的概率,然后进行贝叶斯推断,判断时频单元是被目标语音主导还是被噪音主导,如果被语音主导标记为1,否则标记为0,当所有的时频单元被判断出来,则二值掩蔽被估计出来. 最后,利用估计的二值掩蔽和混合语音的Gammtone滤波输出合成目标语音的时域波形.
高斯混合模型是一种生成式的模型,目标语音主导的时频单元的概率分布和噪音主导的时频单元的概率分布有很多重叠部分,并且它不能挖掘特征中的区分信息,不能进行区分性训练.孤立地对每一个频带建模,无法利用频带间的相关性,同时会导致训练和测试代价过大,很难具有实用性.
2) 支持向量机(SVM). 支持向量机能够学习数据中的最优分类面,以区分不同类别的数据.Han等[32]提出用SVM对每一个频带的时频单元进行建模,学习被目标语音主导的时频单元和被噪音主导的时频单元最优区分面.在测试阶段,输入时频单元的特征,通过计算到分类面的距离实现时频单元的分类.
相比于GMM,SVM取得了更好的分类准确性和泛化性能.这主要得益于SVM的区分性训练.但是SVM仍然是对每一个时频单元进行单独建模,忽略了它们之间的相关性和语音的时空结构特性,同时SVM是浅层模型,并没有特征抽象和层次化学习的能力.
3) 非负矩阵分解(NMF). 非负矩阵分解是著名的表示学习方法,它能挖掘隐含在非负数据中的局部表示. 给定非负矩阵 $X\in {{R}_{+}}$ ,非负矩阵分解将X 近似分解成两个非负矩阵的乘积, $X\approx WH$ ,其中W是非负基矩阵,H是对应的激活系数矩阵.当非负矩阵分解应用到纯净语音或者噪音的幅度谱时,NMF能挖掘出语音或者噪音的基本谱模式. 在语音分离中,首先在训练阶段,在纯净的语音和噪音上分别训练NMF模型,得到语音和噪音的基矩阵. 然后,在测试阶段,联合语音和噪音的基矩阵得到一个既包含语音成分又包含噪音成分的更大的基矩阵,利用得到的基矩阵,通过非负线性组合重构混合语音幅度谱,当重构误差收敛时,语音基和噪音基对应的激活矩阵被计算出来,然后利用非负线性组合即可分离出混合语音中的语音和噪音.
NMF是单层线性模型,很难刻画语音数据中的非线性关系,另外,在语音分离过程中,NMF的推断过程非常费时,很难达到实时性要求,大大限制了NMF在语音分离中的实际应用.
5.2 深层模型
1) 深度神经网络(DNN). DNN是最常见的深层模型,一个典型的DNN通常由一个输入层,若干个非线性隐含层和一个输出层组成,各个层依次堆叠,上层的输出输入到下一层中,形成一个深度的网络.层次化的非线性处理使得DNN具有强大的表示学习的能力,能够从原始数据中自动学习对目标最有用的特征表示,抓住数据中的时空结构. 然而,深度网络的多个非线性隐含层使得它的优化非常困难,往往陷入性能较差的局部最优点. 为解决这个问题,2006年Hinton等提出了一种无监督的预训练方式,极大地改善了深度神经网络的优化问题[65]. 自此,深度神经网络得到广泛的研究,在语音和图像等领域取得巨大的成功.Xu等将DNN应用于语音分离中,取得了显著的性能提升. 在文献[18]中,DNN被用来学习一个从带噪特征到目标语音的对数能量幅度谱的映射函数,如图 5所示. 上下文帧的对数幅度谱作为输入特征,通过两个隐层的非线性变换和输出层的线性变换,估计得到对应帧的目标语音的对数幅度谱. 最后,使用混合语音的相位,利用ISTFT得到目标语音的时域波形信号.
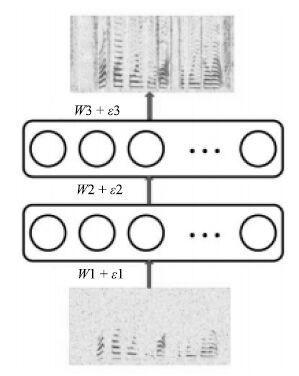
实验结果显示Xu等提出的方法在大规模训练数据上取得了优异的语音分离性能.然而,直接估计目标语音的对数幅度谱是一个非常困难的任务,需要大量的训练数据才能有效地训练模型,同时其泛化性能也是一个重要的问题.
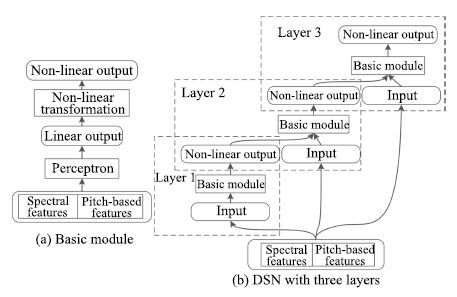
2) 深度堆叠网络(DSN). 语音信号具有很强的时序相关性,探究这些特性能够提高语音分离的性能,为此,Nie等[33]利用DSN的层次化模块结构对时频单元的时序相关性进行建模,定义为DSN-TS,如图 6所示. DSN的基本模块是一个由一个输入层,一个隐层和一个线性输出层组成的前向传播网络. 模块之间相互堆叠,每一个模块依次对应一个时刻帧,前一个模块的输出连接上下一个时刻的输入特征作为下一个模块的输入,如此类推,便可估计所有时刻的时频单元的掩蔽.

相比于之前的模型,DSN-TS考虑了时频单元之间的时序关系,在分离性能上取得进一步提高.然而,DSN-TS对每一个频带单独建模,忽略了频带之间的相关性.
基音是语音的一个显著的特征,在传统的计算听觉场景分析中常被用作语音分离的组织线索.基于基音的特征也常被用于语音分离,然而,噪音环境下,基音的提取是一个挑战性的工作,Zhang等[34]巧妙地将噪声环境下的基音提取和语音分离融合到DSN中,定义为DSN-Pitch,如图 7所示. 在DSN-Pitch中,基音提取和语音分离交替进行,相互促进.DSN-Pitch同时提高了语音分离的性能和基音提取的准确性,然而,DSN-Pitch依然对每一个时频单元单独建模,严重忽略了它们之间的时空相关性.
3) 深度循环神经网络(Deep recurrent neural network,DRNN).由于语音的产生机制,语音具有明显的长短时谱依赖性,这些特性能够被用来帮助语音分离. 尽管DNN具有强大的学习能力,但是DNN仅能通过上下文或者差分特征对数据中的时序相关性进行有限的建模,而且会极大地增加输入数据的维度,大大地增加了学习的难度.RNN是非常常用的时序模型,利用其循环连接能够对时序数据中长短时依赖性进行建模.Huang等将RNN应用到语音分离中,取得比较好的语音分离性能[29].标准的RNN仅有一个隐层,为了对语音数据进行层次化抽象,Huang等[29]使用深度的RNN作为最终的分离模型,如图 8所示.
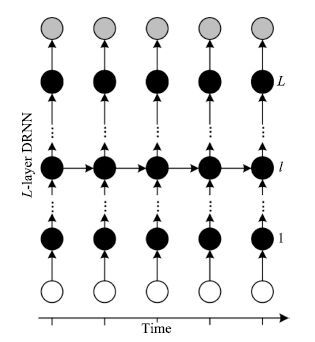
相对于DNN,DRNN能够抓住数据中时序相关性,但是由于梯度消失的问题,DRNN不容易训练,对长时依赖的建模能力有限. 实验结果表明,相对于DNN,DRNN在语音分离中的性能提升比较有限.
4) 长短时记忆网络(Long short-term memory,LSTM). 作为RNN的升级版本,在网络结构上,LSTM增加了记忆单元、输入门、遗忘门和输出门,这些结构单元使得LSTM相比于RNN在时序建模能力上得到巨大的提升,能够记忆更多的信息,并能有效抓住数据中的长时依赖.语音信号具有明显的长短时依赖性,Weninger等将LSTM应用到语音分离中,取得了显著的性能提升[5, 39].
5) 卷积神经网络(Convolutional neural network,CNN).CNN在二维信号处理上具有天然的优势,其强大的建模能力在图像识别等任务已得到验证. 在语音分离中,一维时域信号经过时频分解技术变成二维的时频信号,各个时频单元在时域和频域上具有很强的相关性,呈现了明显的时空结构.CNN 擅长于挖掘输入信号中的时空结构,具有权值共享,形变鲁棒性特性,直观地看,CNN适合于语音分离任务. 目前CNN已应用到语音分离中,在相同的条件下取得了最好的分离性能,超过了基于DNN的语音分离系统[22, 66].
6) 深度非负矩阵分解(Deep nonnegative matrix factorization,Deep NMF). 尽管NMF能抓住隐含在非负数据中的局部基表示,但是,NMF是一个浅层线性模型,很难对非负数据中的结构特性进行层次化的抽象,也无法处理数据中的非线性关系.而语音数据中存在丰富的时空结构和非线性关系,挖掘这些信息能够提高语音分离的性能. 为此,Le Roux等将NMF扩展成深度结构,在语音分离应用上取得巨大的性能提升[23, 40-41].
总结以上介绍的语音分离模型,可以看到: 浅层模型,复杂度低但泛化性能好,无法自动学习数据中的特征表示,其性能严重依赖于人工设计的特征,基于浅层模型的语音分离系统其性能和实用性有限; 深度模型,复杂度高建模能力强,其泛化性能可以通过扩大训练数据量来保证,另外,深度模型能够自动学习数据中有用的特征表示,因此对特征设计的要求不高,而且,能够处理复杂的高维数据,可以通过将上下文帧级联输入到深度模型中,以便为语音分离提供更多的信息. 同时,深度模型具有丰富的结构,能够抓住语音数据的很多特性,例如时序性、时空相关性、长短时谱依赖性和自回归性等. 深度模型能够处理复杂的结构映射,因此,能够为基于深度模型的语音分离设计更加复杂的目标来提高语音分离的性能.目前,监督性语音分离的主流模型是深度模型,并开始将浅层模型扩展成深度模型.
6. 总结与展望
6.1 总结
本文从时频分解、特征、目标和模型四个方面对基于深度学习的语音分离技术的整体框架和主要流程进行综合概述和分析比较.对于时频分解,听觉滤波器组和傅里叶变换是最常用的技术,它们在分离性能上没有太大的差异. 听觉滤波器组在低频具有更高的分辨率,但是计算复杂度比较高,傅里叶变换具有快速算法而且是一个可逆变换,在监督性语音分离中日益成为主流. 对于特征,目前帧级别的MRCG和FFT-magnitude分别是Gammtone域下和傅里叶变换域下最主流的特征,已经在许多研究中得到验证,是目前语音分离使用最多的特征.时频掩蔽是监督性语音分离最主要的分离目标,浮值掩蔽在可懂度和感知质量上都优于二值掩蔽,目前是语音分离的主流目标. 然而,时频掩蔽并不能优化实际的分离目标,傅里叶幅度谱是一种更接近实际目标的分离目标,相对于时频掩蔽具有更好的灵活性,能够进行区分性学习,日益得到研究者的重视,但是,其学习难度更大.目前结合时频掩蔽和傅里叶幅度谱的隐式掩蔽目标显示了光明的研究前景,正被日益广泛地应用到语音分离中,而且各种变形的隐式掩蔽目标正不断地被提出.自从语音分离被表达成监督性学习问题,各种学习模型被尝试着应用到语音分离中,在各种模型中,深度模型在语音分离任务中显示了强大的建模能力,取得了巨大的成功,目前已经成为语音分离的主流方法.
语音分离在近几年来得到研究者的广泛关注,针对时频分解,特征、目标和模型都有许多方法被提出. 对现存的方法,我们从建模单元、分离目标和学习模型三个方面进行简单的分类总结:
1) 建模单元. 语音分离的建模单元主要有两类: a) 时频单元的建模;b) 帧级别的建模. 时频单元的建模对每一个时频单元单独建模,通过分类模型估计每一个时频单元是被语音主导还是被噪音主导,早期,基于二值分类的监督性语音分离通常是基于时频单元建模的.帧级别的建模将一帧或者若干帧语音的所有时频单元看成一个整体,同时对它们进行建模,估计的目标也是帧级别的. 相对于时频单元的建模,帧级别的建模能够抓住语音的时频相关性,一般认为帧级别的建模能取得更好的语音分离性能. 目前,帧级别的建模已成为监督性语音分离的主流建模方法,从时频单元到帧级别的建模单元转变是一个巨大的进步,这主要得益于深度学习强大的表示与学习能力,能够进行结构性输出学习.传统的浅层学习能力很难学习结构复杂的高维度的输出.
2) 分离目标. 语音分离的目标主要分为三类: a) 时频掩蔽;b) 目标语音的幅度谱估计; c) 隐式时频掩蔽.时频掩蔽是语音分离的主要目标,许多监督性语音分离系统从带噪特征中估计目标语音的二值掩蔽或者浮值掩蔽,然而,时频掩蔽是一个中间目标,并没有直接优化实际的语音分离目标.相对于时频掩蔽,估计目标语音的幅度谱更接近实际的语音分离目标,而且更为灵活,能够更充分利用语音和噪音的特性构造区分性的训练目标.但是,由于幅度谱的变化范围比较大,在学习难度上要比时频掩蔽目标的学习难度大.深度学习具有强大的学习能力,现在已有许多基于深度学习的语音分离方法直接估计目标语音的幅度谱.隐式的时频掩蔽方法将时频掩蔽融合到深度神经网路中,并不直接估计理想时频掩蔽,而是作为中间处理层帮助实际目标的估计.在这里,时频掩蔽并不是神经网络学习的目标,它是通过实际应用的目标的估计误差隐式地得到的.相对于时频掩蔽和目标语音幅度谱估计的方法,隐式时频掩蔽方法融合了时频掩蔽和目标语音幅度谱估计方法的优势,能够取得更好的语音分离性能,目前已有几个基于隐式的时频掩蔽方法的监督性语音分离方法被提出,并且取得了显著的性能提升.
3) 学习模型. 监督性语音分离的学习模型主要分为两类: a) 浅层模型;b) 深层模型. 早期的监督性语音分离主要使用浅层模型,一般对每一个频带的时频单元单独建模,并没有考虑时频单元之间的时空相关性.基于浅层模型的语音分离系统分离的语音的感知质量通常比较差.随着深度学习的兴起,深层模型开始广泛应用到语音分离中,目前已经成为监督性语音分离最主流的学习模型.深层模型具有强大的建模能力,能够挖掘数据中的深层结构,相对于浅层模型,深层模型分离的语音不仅在感知质量和可懂度方便都得到巨大的提升,而且随着数据的增大,其泛化性能和分离性能得到不断的提高.
6.2 展望
最近几年,在全世界研究者的共同努力下,监督性语音分离得到巨大的发展. 针对监督性语音分离的特征、目标和模型三个主要方面都进行了深入细致的研究,取得许多一致性的共识. 目前,监督性语音分离的框架基本成熟,即利用深度模型学习一个从带噪特征到分离目标的映射函数.很难在框架层面进行重大的改进,针对现有的框架,特别是基于深度学习的语音分离框架,我们认为,未来监督性语音分离可能在下面几个方面.
1) 泛化性. 尽管监督性语音分离取得了很好的分离性能,特别是深度学习的应用,极大地促进了监督性语音分离的发展.但在听觉条件或者训练数据不匹配的情况下,例如噪音不匹配和信噪比不匹配的情况下,分离性能会急剧下降.目前解决这个问题最有效方法是扩大数据的覆盖面,但现实情况很难做到覆盖大部分的听觉环境,同时训练数据增大又带来训练时间的增加,不利于模型更新.我们认为解决这个问题的两个可行的方向是: a) 挖掘人耳的听觉心理学知识,例如将计算听觉场景分析的知识融入到监督性语音分离模型中.人耳对于声音的处理具有很好的鲁棒性.早期计算听觉场景分析的许多研究表明基音和听觉掩蔽等对噪音是非常鲁棒的,将这些积累的人工知识和计算听觉场景分析的处理过程有效融入到监督性语音分离中可能会提高监督性语音分离的泛化性能.b) 更多地关注和挖掘语音的固有特性. 由于人声产生的机理,人声具有很多明显的特性,例如稀疏性、 时空连续性、明显的谐波结构、自回归性、长短时依赖性等,对于噪音,这些特性具有明显的区分性,而且,对于不同的人发出的人声,不同的语言和内容,人声都具有这些特性. 而噪音的变化却多种多样,很难找到共有的模式.因此应该将更多的精力放到对语音固有特性的研究和挖掘上而不是只关注噪音.将语音固有的特性融入到监督性语音分离模型中可能会提高语音分离的性能和泛化能力.
2) 生成式模型和监督性模型联合.人耳对声音的处理过程可能是模式驱动的,即在大脑高层可能存储有许多关于语音的基本模式,当我们听到带噪语音的时候,带噪语音会激发大脑中相似的语音模式响应,这些先后被激活的语音模式组合起来即可形成大脑可理解的语义单元,使得人们能从带噪语音中听清语音.而这些语音模式一方面是从父母继承而来的,一方面是后天学习来的.我们可以利用生成式模型从大量纯净的语音中学习语音的基本谱模式,然后利用监督性学习模型来估计语音基本谱模式的激活量,利用这些激活的基本谱模式可以重构纯净的语音.基本谱模式的学习可以利用很多生成式模型,而它们之间的融合也可以有多种形式,这方面有许多内容值得进一步探讨.
-

图 3 结构光三角测量原理示意图
Fig. 3 Schematic diagram of the principle of structured light triangulation
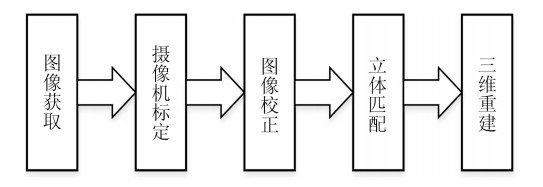
图 9 双目视觉三维重建系统组成
Fig. 9 The composition of the binocular vision 3D reconstruction system
表 1 主动视觉方法对比
Table 1 Active visual method comparison
方法 激光扫描法[28-31] 结构光法[32-42] 阴影法[43-48] TOF技术[49-53] 雷达技术[54-58] Kinect技术[59-67] 优点 1.重建结果很精确;
2.能建立形状不规则物体的三维模型.1.简单方便、无破坏性;
2.重建结果速率快、精度高、能耗低、抗干扰能力强.1.设备简单, 图像直观;
2.密度均匀, 简单低耗, 对图像的要求非常低.1.数据采集频率高;
2.垂直视场角大;
3.可以直接提取几何信息.1.视场大、扫描距离远、灵敏度高、功耗低;
2.直接获取深度信息, 不用对内部参数进行标定.1.价格便宜、轻便;
2.受光照条件的影响较小;
3.同时获取深度图像和彩色图像.缺点 1.需要采用算法来修补漏洞;
2.得到的三维点云数据量非常庞大, 而且还需要对其进行配准, 耗时较长;3.价格昂贵.1.测量速度慢;
2.不适用室外场景.1.对光照的要求较高, 需要复杂的记录装置;
2.涉及到大口径的光学部件的消像差设计、加工和调整.1.深度测量系统误差大;
2.灰度图像对比度差、分辨率低;
3.搜索空间大、效率低;
4.算法扩展性差, 空间利用率低.1.受环境的影响较大;
2.计算量较大, 实时性较差;1.深度图中含有大量的噪声;
2.对单张图像的重建效果较差. 下载: 导出CSV
下载: 导出CSV
表 2 单目、双目和多目视觉方法对比
Table 2 Comparison of monocular, binocular and multiocular vision methods
单目视觉[68] 双目视觉[101-110, 112] 多目视觉[111, 113-119] 优点 1.简单方便、灵活可靠、使用范围广;
2.可以实现重建过程中的摄像机自标定, 处理时间短;
3.价格便宜.1.方法成熟;
2.能够稳定地获得较好的重建效果;
3.应用广泛.1.避免双目视觉方法中难以解决的假目标、边缘模糊及误匹配等问题;
2.在多种条件下进行非接触、自动、在线的测量和检测;
3.简单方便、重建效果更好, 能够适应各种场景;缺点 1.不能够得到深度信息, 重建效果较差;
2.重建速度较慢.1.运算量大;
2.基线距离较大时重建效果降低;
3.价格较贵.1.设备结构复杂, 成本更高, 控制上难以实现;
2.实时性较低, 易受光照的影响.
下载: 导出CSV
表 3 基于视觉的三维重建技术对比与分析
Table 3 Comparison and analysis of 3D reconstruction based on vision
方法 优点 缺点 自动化程度 重建效果 实时性 应用场景 接触式方法[18] 快速直接测量物体的三维信息; 重建结果精度比较高 必须接触测量物体, 测量时物体表面容易被划伤 难以实现自动化重建 重建质量效果较好 实时 不能被广泛的应用, 只能应用到测量仪器能接触到的场景 激光扫描法[28-31] 重建的模型很精确; 重建形状不规则物体的三维模型 形成的三维点云数据量非常庞大, 不容易处理; 重建的三维模型会产生漏洞; 设备比较复杂, 价格非常昂贵 一定程度的自动化重建 重建的三维模型很好 实时 目前主要应用在工厂的生产和检测中, 无法被广泛使用 结构光法[32-42] 仅需要一幅图像就能获得物体形状; 简单方便; 无破坏性 重建速度较慢 一定程度的自动化重建 重建效果的精度比较高 实时 适用于室内场景 阴影法[43-48] 设备简单低耗; 对图像的要求非常低 对光源有一定的要求 自动化重建较低 重建效果较差, 重建过程比较复杂 实时 无法被广泛使用 TOF技术[49-53] 数据采集频率高; 垂直视场角大; 可以直接提取几何信息 深度测量系统误差大; 灰度图像对比度差、分辨率低; 搜索空间大、效率低; 算法扩展性差, 空间利用率低 一定程度的自动化重建 重建效果的精度较低 实时 能够广泛应用在人脸检测、车辆安全等方面 雷达技术[54-58] 视场大、扫描距离远、灵敏度高、功耗低; 直接获取深度信息, 不用对内部参数进行标定 受环境的影响较大; 计算量较大, 实时性较差; 价格较贵 一定程度的自动化重建 重建效果一般 实时 能够广泛应用于各行各业 Kinect技术[59-67] 价格便宜、轻便; 受光照条件的影响较小; 同时获取深度图像和彩色图像 深度图中含有大量的噪声; 对单张图像的重建效果较差 一定程度的自动化重建 重建效果较好 实时 能够被广泛应用于室内场景 明暗度法[69-72] 重建结果比较精确应用范围广泛 易受光源影响; 依赖数学运算; 鲁棒性较差 完全自动化重建 在光源比较差的情况下重建效果较差 非实时 难以应用于镜面物体以及室外场景物体的三维重建 光度立体视觉法[73-82] 避免了明暗度法存在的一些问题; 重建精度较高 易受光源影响; 鲁棒性较差 一定程度的自动化重建 重建效果较好 非实时 难以应用于镜面物体以及室外场景物体的三维重建 纹理法[83-86] 对光照和噪声都不敏感; 重建精度较高 通用性较低; 速度较快; 鲁棒性较好 完全自动化重建 重建效果的精度较高 非实时 只适用于具有规则纹理的物体 轮廓法[87-93] 重建效率非常高; 复杂度较低 对输入信息的要求很苛刻; 无法对物体表面的空洞和凹陷部分进行重建 完全自动化重建 重建效果取决于轮廓图像数量, 轮廓图像越多重建越精确 非实时 通常应用于对模型细节精度要求不是很高的三维重建中 调焦法[94-96] 对光源条件要求比较宽松; 可使用少量图像测量物体表面信息 很难实现自动重建; 需要多张图片才能进行重建 不能实现自动化重建 重建效果比较好 非实时 对纹理复杂物体的重建效果较差, 不能广泛应用 亮度法[97-100] 可全自动、无手工交互地进行高精度建模; 对光照条件要求宽松 鲁棒性较低; 灵活性较低; 复杂度较高 自动化重建 重建效果比较精细 非实时 可应用于文物数字化和人脸自动建模等领域 单目视觉法[68] 简单方便、价格便宜、灵活可靠、使用范围广; 可以实现重建过程中的摄像机自标定, 处理时间短 不能够得到深度信息, 重建速度较慢 自动化重建 重建效果较差 实时 可应用于各种场景 双目视觉法[101-110, 112] 方法成熟; 能够获得较好的重建效果 运算量大; 价格较贵; 在基线距离较大时重建效果降低 完全自动化重建 基线在一定条件下重建效果较好 实时 适用于室外场景, 应用范围广泛 多目视觉法[111, 113-119] 识别精度高, 适应性较强, 视野范围大 运算量较大; 价格昂贵, 重建时间长 完全自动化重建 基线距离较大的情况下重建效果明显降低, 而且测量精度下降, 速度受限 实时 能够适应各种场景, 在很多范围内都可以使用 区域视觉法[120-126] 计算简单; 匹配速度有所提高; 匹配精度较高; 提高了稠密匹配效率 受光线干扰较大; 对图像要求较高; 实验对象偏少 一定程度的自动化重建 重建结果较好 非实时 适用于各种领域, 例如, 视觉导航、遥感测绘 特征视觉法[154-166] 提取简单; 抗干扰能力强; 鲁棒性好; 时间和空间复杂度低 不能够对图像信息进行全面的描述 完全自动化重建 能够较精确地对物体实现三维重建 实时 应用范围较广 运动恢复结构法[127-139] 实用价值较高; 鲁棒性较强; 对图像的要求较低 计算量较大, 重建时间较长 完全自动化重建 重建效果取决于获取图像数量, 图像越多重建效果越好 实时 一般适用于大规模场景中 因子分解法[145-148] 简便灵活, 抗噪能力强, 不依赖于其他模型 精度较低, 运算时间较长 完全自动化重建 重建效果精度较低 实时 一般适用于大场景中 多视图几何法[149-163] 实用性较高; 通用性较强; 能够解决运动恢复结构法中的一些问题 计算量较大, 重建时间较长 一定程度完全自动化重建 重建效果比较好 实时 一般应用于静止的场景 统计学习法[164-173] 重建质量和效率都很高; 基本不需要人工交互 获取的信息和数据库目标不一致时, 重建结果与目标相差甚远 一定程度的自动化重建 重建效果取决于数据库的完整程度, 数据库越完备重建效果越好 非实时 适用于大场景、识别和视频检索系统 神经网络法[174-177] 精度较高, 具有很强的鲁棒性 收敛速度慢, 运算量较大 一定程度完全自动化重建 重建效果较好 实时 能够应用于各种领域, 例如计算机视觉、军事及航天等 深度学习与语义法[178-181] 计算简单, 精度较高, 不需要进行复杂的几何运算, 实时性较好 训练时间较长, 对CPU的要求较高 一定程度完全自动化重建 重建结果取决于训练的好坏 实时 适用于各种大规模场景
下载: 导出CSV
-
[1] Shen S H. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Transactions on Image Processing, 2013, 22(5): 1901-1914 doi: 10.1109/TIP.2013.2237921 [2] Qu Y F, Huang J Y, Zhang X. Rapid 3D reconstruction for image sequence acquired from UAV camera. Sensors, 2018, 18(1): 225-244 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=sensors-18-00225 [3] Lee D Y, Park S A, Lee S J, Kim T H, Heang S, Lee J H, et al. Segmental tracheal reconstruction by 3D-printed scaffold: Pivotal role of asymmetrically porous membrane. The Laryngoscope, 2016, 126(9): E304-E309 doi: 10.1002/lary.25806 [4] Roberts L G. Machine Perception of Three-Dimensional Solids[Ph.D. dissertation], Massachusetts Institute of Technology, USA, 1963 http://www.researchgate.net/publication/37604327_Machine_perception_of_three-dimensional_solids [5] Kiyasu S, Hoshino H, Yano K, Fujimura S. Measurement of the 3-D shape of specular polyhedrons using an m-array coded light source. IEEE Transactions on Instrumentation and Measurement, 1995, 44(3): 775-778 doi: 10.1109/19.387330 [6] Snavely N, Seitz S M, Szeliski R. Photo tourism: exploring photo collections in 3D. ACM Transactions on Graphics, 2006, 25(3): 835-846 http://cn.bing.com/academic/profile?id=6d3ecda51169cc021bfe50dd9473002b&encoded=0&v=paper_preview&mkt=zh-cn [7] Pollefeys M, Nistér D, Frahm J M, Akbarzadeh A, Mordohai P, Clipp B, et al. Detailed real-time urban 3D reconstruction from video. International Journal of Computer Vision, 2008, 78(2-3): 143-167 doi: 10.1007/s11263-007-0086-4 [8] Furukawa Y, Ponce J. Carved visual hulls for image-based modeling. International Journal of Computer Vision, 2009, 81(1): 53-67 doi: 10.1007/s11263-008-0134-8 [9] Han J G, Shao L, Xu D, Shotton J. Enhanced computer vision with Microsoft Kinect sensor: a review. IEEE Transactions on Cybernetics, 2013, 43(5): 1318-1334 doi: 10.1109/TCYB.2013.2265378 [10] Ondrúška P, Kohli P, Izadi S. Mobilefusion: real-time volumetric surface reconstruction and dense tracking on mobile phones. IEEE Transactions on Visualization and Computer Graphics, 2015, 21(11): 1251-1258 doi: 10.1109/TVCG.2015.2459902 [11] 李利, 马颂德.从二维轮廓线重构三维二次曲面形状.计算机学报, 1996, 19(6): 401-408 doi: 10.3321/j.issn:0254-4164.1996.06.001Li Li, Ma Song-De. On the global quadric shape from contour. Chinese Journal of Computers, 1996, 19(6): 401-408 doi: 10.3321/j.issn:0254-4164.1996.06.001 [12] Zhong Y D, Zhang H F. Control points based semi-dense matching. In: Proceedings of the 5th Asian Conference on Computer Vision. Melbourne, Australia: ACCV, 2002. 23-25 https://www.researchgate.net/publication/237134453_Control_Points_Based_Semi-Dense_Matching [13] 雷成, 胡占义, 吴福朝, Tsui H T.一种新的基于Kruppa方程的摄像机自标定方法.计算机学报, 2003, 26(5): 587-597 doi: 10.3321/j.issn:0254-4164.2003.05.010Lei Cheng, Hu Zhan-Yi, Wu Fu-Chao, Tsui H T. A novel camera self-calibration technique based on the Kruppa equations. Chinese Journal of Computers, 2003, 26(5): 587-597 doi: 10.3321/j.issn:0254-4164.2003.05.010 [14] 雷成, 吴福朝, 胡占义.一种新的基于主动视觉系统的摄像机自标定方法.计算机学报, 2000, 23(11): 1130-1139 doi: 10.3321/j.issn:0254-4164.2000.11.002Lei Cheng, Wu Fu-Chao, Hu Zhan-Yi. A new camera self-calibration method based on active vision system. Chinese Journal of Computer, 2000, 23(11): 1130-1139 doi: 10.3321/j.issn:0254-4164.2000.11.002 [15] 张涛.基于单目视觉的三维重建[硕士学位论文], 西安电子科技大学, 中国, 2014 http://cdmd.cnki.com.cn/Article/CDMD-10701-1014325012.htmZhang Tao. 3D Reconstruction Based Monocular Vision[Master thesis], Xidian University, China, 2014 http://cdmd.cnki.com.cn/Article/CDMD-10701-1014325012.htm [16] Ebrahimnezhad H, Ghassemian H. Robust motion from space curves and 3D reconstruction from multiviews using perpendicular double stereo rigs. Image and Vision Computing, 2008, 26(10): 1397-1420 doi: 10.1016/j.imavis.2008.01.002 [17] Hartley R, Zisserman A. Multiple View Geometry in Computer Vision. New York: Cambridge University Press, 2003 [18] Várady T, Martin R R, Cox J. Reverse engineering of geometric models—an introduction. Computer-Aided Design, 1997, 29(4): 255-268 doi: 10.1016/S0010-4485(96)00054-1 [19] Isgro F, Odone F, Verri A. An open system for 3D data acquisition from multiple sensor. In: Proceedings of the 7th International Workshop on Computer Architecture for Machine Perception. Palermo, Italy: IEEE, 2005. 52-57 https://www.researchgate.net/publication/221210593_An_Open_System_for_3D_Data_Acquisition_from_Multiple_Sensor?ev=auth_pub [20] Williams C G, Edwards M A, Colley A L, Macpherson J V, Unwin P R. Scanning micropipet contact method for high-resolution imaging of electrode surface redox activity. Analytical Chemistry, 2009, 81(7): 2486-2495 doi: 10.1021/ac802114r [21] Kraus K, Pfeifer N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS Journal of Photogrammetry and Remote Sensing, 1998, 53(4): 193-203 doi: 10.1016/S0924-2716(98)00009-4 [22] Göbel W, Kampa B M, Helmchen F. Imaging cellular network dynamics in three dimensions using fast 3D laser scanning. Nature Methods, 2007, 4(1): 73-79 doi: 10.1038/nmeth989 [23] Rocchini C, Cignoni P, Montani C, Pingi P, Scopigno R. A low cost 3D scanner based on structured light. Computer Graphics Forum, 2001, 20(3): 299-308 doi: 10.1111/1467-8659.00522 [24] Al-Najdawi N, Bez H E, Singhai J, Edirisinghe E A. A survey of cast shadow detection algorithms. Pattern Recognition Letters, 2012, 33(6): 752-764 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=0edff8a864c6e0b39fa06480e789be36 [25] Park J, Kim H, Tai Y W, Brown M S, Kweon I. High quality depth map upsampling for 3d-tof cameras. In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1623-1630 https://www.researchgate.net/publication/221110931_High_Quality_Depth_Map_Upsampling_for_3D-TOF_Cameras [26] Schwarz B. LIDAR: mapping the world in 3D. Nature Photonics, 2010, 4(7): 429-430 doi: 10.1038/nphoton.2010.148 [27] Khoshelham K, Elberink S O. Accuracy and resolution of kinect depth data for indoor mapping applications. Sensors, 2012, 12(2): 1437-1454 doi: 10.3390/s120201437 [28] 杨耀权, 施仁, 于希宁, 高镗年.激光扫描三角法大型曲面测量中影响参数分析.西安交通大学学报, 1999, 33(7): 15-18 doi: 10.3321/j.issn:0253-987X.1999.07.005Yang Yao-Quan, Shi Ren, Yu Xi-Ning, Gao Tang-Nian. Laser scanning triangulation for large profile measurement. Journal of Xi'an Jiaotong University, 1999, 33(7): 15-18 doi: 10.3321/j.issn:0253-987X.1999.07.005 [29] Boehler W, Vicent M B, Marbs A. Investigating laser scanner accuracy. The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2003, 34(5): 696-701 https://www.researchgate.net/publication/246536800_Investigating_laser_scanner_accuracy [30] Reshetyuk Y. Investigation and Calibration of Pulsed Time-of-Flight Terrestrial Laser Scanners[Master dissertation], Royal Institute of Technology, Switzerland, 2006. 14-17 https://www.researchgate.net/publication/239563997_Investigation_and_calibration_of_pulsed_time-of-flight_terrestrial_laser_scanners [31] Voisin S, Foufou S, Truchetet F, Page D L, Abidi M A. Study of ambient light influence for three-dimensional scanners based on structured light. Optical Engineering, 2007, 46(3): Article No. 030502 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=dd6f1c5d53c51efe4c6ad10b4ed19e5e [32] Scharstein D, Szeliski R. High-accuracy stereo depth maps using structured light. In: Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Madison, WI, USA: IEEE, 2003. I-195-I-202 https://www.researchgate.net/publication/4022931_High-accuracy_stereo_depth_maps_using_structured_light [33] Chen F, Brown G M, Song M M. Overview of 3-D shape measurement using optical methods. Optical Engineering, 2000, 39(1): 10-22 doi: 10.1117/1.602438 [34] Pollefeys M, Van Gool L. Stratified self-calibration with the modulus constraint. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 707-724 doi: 10.1109/34.784285 [35] O'Toole M, Mather J, Kutulakos K N. 3D shape and indirect appearance by structured light transport. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7): 1298-1312 doi: 10.1109/TPAMI.2016.2545662 [36] Song Z, Chung R. Determining both surface position and orientation in structured-light-based sensing. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(10): 1770-1780 doi: 10.1109/TPAMI.2009.192 [37] Kowarschik R, Kuehmstedt P, Gerber J, Schreiber W, Notni G. Adaptive optical 3-D-measurement with structured light. Optical Engineering, 2000, 39(1): 150-158 doi: 10.1117/1.602346 [38] Shakhnarovich G, Viola P A, Moghaddam B. A unified learning framework for real time face detection and classification. In: Proceedings of the 5th IEEE International Conference on Automatic Face Gesture Recognition. Washington, USA: IEEE, 2002. 14-21 https://www.researchgate.net/publication/262436645_A_unified_learning_framework_for_real_time_face_detection_and_classification [39] Salvi J, Pagès J, Batlle J. Pattern codification strategies in structured light systems. Pattern Recognition, 2004, 37(4): 827-849 doi: 10.1016/j.patcog.2003.10.002 [40] 张广军, 李鑫, 魏振忠.结构光三维双视觉检测方法研究.仪器仪表学报, 2002, 23(6): 604-607, 624 doi: 10.3321/j.issn:0254-3087.2002.06.014Zhang Guang-Jun, Li Xin, Wei Zhen-Zhong. A method of 3D double-vision inspection based on structured light. Chinese Journal of Scientific Instrument, 2002, 23(6): 604-607, 624 doi: 10.3321/j.issn:0254-3087.2002.06.014 [41] 王宝光, 贺忠海, 陈林才, 倪勇.结构光传感器模型及特性分析.光学学报, 2002, 22(4): 481-484 doi: 10.3321/j.issn:0253-2239.2002.04.022Wang Bao-Guang, He Zhong-Hai, Chen Lin-Cai, Ni Yong. Model and performance analysis of structured light sensor. Acta Optica Sinica, 2002, 22(4): 481-484 doi: 10.3321/j.issn:0253-2239.2002.04.022 [42] 罗先波, 钟约先, 李仁举.三维扫描系统中的数据配准技术.清华大学学报(自然科学版), 2004, 44(8): 1104-1106 doi: 10.3321/j.issn:1000-0054.2004.08.028Luo Xian-Bo, Zhong Yue-Xian, Li Ren-Ju. Data registration in 3-D scanning systems. Journal of Tsinghua University (Science and Technology), 2004, 44(8): 1104-1106 doi: 10.3321/j.issn:1000-0054.2004.08.028 [43] Savarese S, Andreetto M, Rushmeier H, Bernardini F, Perona P. 3D reconstruction by shadow carving: theory and practical evaluation. International Journal of Computer Vision, 2007, 71(3): 305-336 doi: 10.1007/s11263-006-8323-9 [44] Wang Y X, Cheng H D, Shan J. Detecting shadows of moving vehicles based on HMM. In: Proceedings of the 19th International Conference on Pattern Recognition. Tampa, FL, USA: IEEE, 2008. 1-4 [45] Rüfenacht D, Fredembach C, Süsstrunk S. Automatic and accurate shadow detection using near-infrared information. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1672-1678 doi: 10.1109/TPAMI.2013.229 [46] Daum M, Dudek G. On 3-D surface reconstruction using shape from shadows. In: Proceedings of the 1998 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Santa Barbara, CA, USA: IEEE, 1998. 461-468 http://www.researchgate.net/publication/3758700_On_3-D_surface_reconstruction_using_shape_from_shadows [47] Woo A, Poulin P, Fournier A. A survey of shadow algorithms. IEEE Computer Graphics and Applications, 1990, 10(6): 13-32 http://d.old.wanfangdata.com.cn/Periodical/xxykz201502016 [48] Hasenfratz J M, Lapierre M, Holzschuch N, Sillion F, Gravir/Imag-Inria A. A survey of real-time soft shadows algorithms. Computer Graphics Forum, 2003, 22(4): 753-774 doi: 10.1111/j.1467-8659.2003.00722.x [49] May S, Droeschel D, Holz D, Wiesen C. 3D pose estimation and mapping with time-of-flight cameras. In: Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. Nice, France: IEEE, 2008. 120-125 https://www.researchgate.net/publication/228662715_3D_pose_estimation_and_mapping_with_time-of-flight_cameras [50] Hegde G P M, Ye C. Extraction of planar features from swissranger sr-3000 range images by a clustering method using normalized cuts. In: Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems. St. Louis, MO, USA: IEEE, 2009. 4034-4039 https://www.researchgate.net/publication/224090431_Extraction_of_Planar_Features_from_Swissranger_SR-3000_Range_Images_by_a_Clustering_Method_Using_Normalized_Cuts [51] Pathak K, Vaskevicius N, Poppinga J, Pfingsthorn M, Schwertfeger S, Birk A. Fast 3D mapping by matching planes extracted from range sensor point-clouds. In: Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems. St. Louis, MO, USA: IEEE, 2009. 1150-1155 http://www.researchgate.net/publication/224090528_Fast_3D_mapping_by_matching_planes_extracted_from_range_sensor_point-clouds?ev=auth_pub [52] Stipes J A, Cole J G P, Humphreys J. 4D scan registration with the SR-3000 LIDAR. In: Proceedings of the 2008 IEEE International Conference on Robotics and Automation. Pasadena, CA, USA: IEEE, 2008. 2988-2993 http://www.researchgate.net/publication/224318679_4d_scan_registration_with_the_sr-3000_lidar [53] May S, Droeschel D, Fuchs S, Holz D, Nüchter A. Robust 3D-mapping with time-of-flight cameras. In: Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems. St. Louis, MO, USA: IEEE, 2009. 1673-1678 https://www.researchgate.net/publication/46160281_3D_mapping_with_time-of-flight_cameras [54] Streller D, Dietmayer K. Object tracking and classification using a multiple hypothesis approach. In: Proceedings of the 2004 IEEE Intelligent Vehicles Symposium. Parma, Italy: IEEE, 2004. 808-812 https://www.researchgate.net/publication/4092472_Object_tracking_and_classification_using_a_multiple_hypothesis_approach [55] Schwalbe E, Maas H G, Seidel F. 3D building model generation from airborne laser scanner data using 2D GIS data and orthogonal point cloud projections. In: Proceedings of ISPRS WG Ⅲ/3, Ⅲ/4, V/3 Workshop "Laser Scanning 2005". Enschede, the Netherlands: IEEE, 2005. 12-14 https://www.researchgate.net/publication/228681223_3D_building_model_generation_from_airborne_laser_scanner_data_using_2D_GIS_data_and_orthogonal_point_cloud_projections [56] Weiss T, Schiele B, Dietmayer K. Robust driving path detection in urban and highway scenarios using a laser scanner and online occupancy grids. In: Proceedings of the 2007 IEEE Intelligent Vehicles Symposium. Istanbul, Turkey: IEEE, 2007. 184-189 https://www.researchgate.net/publication/4268869_Robust_Driving_Path_Detection_in_Urban_and_Highway_Scenarios_Using_a_Laser_Scanner_and_Online_Occupancy_Grids [57] 胡明.基于点云数据的重建算法研究[硕士学位论文], 华南理工大学, 中国, 2010 http://cdmd.cnki.com.cn/Article/CDMD-10561-1011044410.htmHu Ming. Algorithm Reconstruction Based on Cloud Data[Master thesis], South China University of Technology, China, 2010 http://cdmd.cnki.com.cn/Article/CDMD-10561-1011044410.htm [58] 魏征.车载LiDAR点云中建筑物的自动识别与立面几何重建[博士学位论文], 武汉大学, 中国, 2012 http://cdmd.cnki.com.cn/Article/CDMD-10486-1013151916.htmWei Zheng. Automated Extraction of Buildings and Facades Reconstructon from Mobile LiDAR Point Clouds[Ph.D. dissertation], Wuhan University, China, 2012 http://cdmd.cnki.com.cn/Article/CDMD-10486-1013151916.htm [59] Zhang Z Y. Microsoft kinect sensor and its effect. IEEE Multimedia, 2012, 19(2): 4-10 doi: 10.1109/MMUL.2012.24 [60] Zhang Z. A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334 doi: 10.1109/34.888718 [61] Smisek J, Jancosek M, Pajdla T. 3D with Kinect. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1154-1160 http://www.researchgate.net/publication/221429935_3D_with_Kinect [62] Zollhöfer M, Nießner M, Izadi S, Rehmann C, Zach C, Fisher M, et al. Real-time non-rigid reconstruction using an RGB-D camera. ACM Transactions on Graphics, 2014, 33(4): Article No. 156 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0234048647/ [63] Henry P, Krainin M, Herbst E, Ren X F, Fox D. RGB-D mapping: using depth cameras for dense 3D modeling of indoor environments. Experimental Robotics: the 12th International Symposium on Experimental Robotics. Heidelberg, Germany: Springer, 2014. 477-491 doi: 10.1007%2F978-3-642-28572-1_33 [64] Henry P, Krainin M, Herbst E, Ren X F, Fox D. RGB-D mapping: using Kinect-style depth cameras for dense 3D modeling of indoor environments. The International Journal of Robotics Research, 2012, 31(5): 647-663 doi: 10.1177/0278364911434148 [65] Newcombe R A, Izadi S, Hilliges O, Molyneaux D, Kim D, Davison A J, et al. KinectFusion: real-time dense surface mapping and tracking. In: Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality. Basel, Switzerland: IEEE, 2011. 127-136 http://www.researchgate.net/publication/224266200_KinectFusion_Real-time_dense_surface_mapping_and_tracking [66] Izadi S, Kim D, Hilliges O, Molyneaux D, Newcombe R, Kohli P, et al. KinectFusion: real-time 3D reconstruction and interaction using a moving depth camera. In: Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology. Santa Barbara, California, USA: ACM, 2011. 559-568 https://www.researchgate.net/publication/220877151_KinectFusion_Real-time_3D_reconstruction_and_interaction_using_a_moving_depth_camera [67] 吴侗.基于点云多平面检测的三维重建关键技术研究[硕士学位论文], 南昌航空大学, 中国, 2013 http://cdmd.cnki.com.cn/Article/CDMD-10406-1014006472.htmWu Tong. Research on Key Technologies of 3D Reconstruction Based on Multi-plane Detection in Point Clouds[Master thesis], Nanchang Hangkong University, China, 2013 http://cdmd.cnki.com.cn/Article/CDMD-10406-1014006472.htm [68] 佟帅, 徐晓刚, 易成涛, 邵承永.基于视觉的三维重建技术综述.计算机应用研究, 2011, 28(7): 2411-2417 doi: 10.3969/j.issn.1001-3695.2011.07.003Tong Shuai, Xu Xiao-Gang, Yi Cheng-Tao, Shao Cheng-Yong. Overview on vision-based 3D reconstruction. Application Research of Computers, 2011, 28(7): 2411-2417 doi: 10.3969/j.issn.1001-3695.2011.07.003 [69] Horn B K P. Shape from Shading: A Method for Obtaining the Shape of A Smooth Opaque Object from One View[Ph.D. dissertation], Massachusetts Institute of Technology, USA, 1970 http://www.researchgate.net/publication/37602086_Shape_from_shading_a_method_for_obtaining_the_shape_of_a_smooth_opaque_object_from_one_view [70] Penna M A. A shape from shading analysis for a single perspective image of a polyhedron. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1989, 11(6): 545-554 doi: 10.1109/34.24790 [71] Bakshi S, Yang Y H. Shape from shading for non-Lambertian surfaces. In: Proceedings of the 1st International Conference on Image Processing. Austin, USA: IEEE, 1994. 130-134 https://www.researchgate.net/publication/2822887_Shape_From_Shading_for_Non-Lambertian_Surfaces [72] Vogel O, Breuß M, Weickert J. Perspective shape from shading with non-Lambertian reflectance. Pattern Recognition. Heidelberg, Germany: Springer, 2008. 517-526 doi: 10.1007/978-3-540-69321-5_52.pdf [73] Woodham R J. Photometric method for determining surface orientation from multiple images. Optical Engineering, 1980, 19(1): Article No. 191139 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC024631993 [74] Noakes L, Kozera R. Nonlinearities and noise reduction in 3-source photometric stereo. Journal of Mathematical Imaging and Vision, 2003, 18(2): 119-127 doi: 10.1023/A:1022104332058 [75] Horovitz I, Kiryati N. Depth from gradient fields and control points: bias correction in photometric stereo. Image and Vision Computing, 2004, 22(9): 681-694 doi: 10.1016/j.imavis.2004.01.005 [76] Tang K L, Tang C K, Wong T T. Dense photometric stereo using tensorial belief propagation. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 132-139 http://www.researchgate.net/publication/4156302_Dense_photometric_stereo_using_tensorial_belief_propagation [77] Xie H, Pierce L E, Ulaby F T. SAR speckle reduction using wavelet denoising and Markov random field modeling. IEEE Transactions on Geoscience and Remote Sensing, 2002, 40(10): 2196-2212 doi: 10.1109/TGRS.2002.802473 [78] Sun J A, Smith M, Smith L, Midha S, Bamber J. Object surface recovery using a multi-light photometric stereo technique for non-Lambertian surfaces subject to shadows and specularities. Image and Vision Computing, 2007, 25(7): 1050-1057 doi: 10.1016/j.imavis.2006.04.025 [79] Vlasic D, Peers P, Baran I, Debevec P, Popović J, Rusinkiewicz S, et al. Dynamic shape capture using multi-view photometric stereo. ACM Transactions on Graphics, 2009, 28(5): Article No. 174 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0216027840/ [80] Shi B X, Matsushita Y, Wei Y C, Xu C, Tan P. Self-calibrating photometric stereo. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 1118-1125 http://www.researchgate.net/publication/221363790_Self-calibrating_photometric_stereo [81] Morris N J W, Kutulakos K N. Dynamic refraction stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1518-1531 doi: 10.1109/TPAMI.2011.24 [82] Higo T, Matsushita Y, Ikeuchi K. Consensus photometric stereo. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 1157-1164 http://www.researchgate.net/publication/221363482_Consensus_photometric_stereo [83] Brown L G, Shvaytser H. Surface orientation from projective foreshortening of isotropic texture autocorrelation. In: Proceedings of the 1988 Computer Society Conference on Computer Vision and Pattern Recognition. Ann Arbor, USA: IEEE, 1988. 510-514 http://www.researchgate.net/publication/3497773_Surface_orientation_from_projective_foreshortening_of_isotropictexture_autocorrelation [84] Clerc M, Mallat S. The texture gradient equation for recovering shape from texture. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(4): 536-549 doi: 10.1109/34.993560 [85] Witkin A P. Recovering surface shape and orientation from texture. Artificial Intelligence, 1981, 17(1-3): 17-45 doi: 10.1016/0004-3702(81)90019-9 [86] Warren P A, Mamassian P. Recovery of surface pose from texture orientation statistics under perspective projection. Biological Cybernetics, 2010, 103(3): 199-212 doi: 10.1007/s00422-010-0389-3 [87] Martin W N, Aggarwal J K. Volumetric descriptions of objects from multiple views. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1983, PAMI-5(2): 150-158 doi: 10.1109/TPAMI.1983.4767367 [88] Laurentini A. The visual hull concept for silhouette-based image understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(2): 150-162 doi: 10.1109/34.273735 [89] Bongiovanni G, Guerra C, Levialdi S. Computing the Hough transform on a pyramid architecture. Machine Vision and Applications, 1990, 3(2): 117-123 doi: 10.1007/BF01212195 [90] Darell T, Wohn K. Depth from focus using a pyramid architecture. Pattern Recognition Letters, 1990, 11(12): 787-796 doi: 10.1016/0167-8655(90)90032-W [91] Kavianpour A, Bagherzadeh N. Finding circular shapes in an image on a pyramid architecture. Pattern Recognition Letters, 1992, 13(12): 843-848 doi: 10.1016/0167-8655(92)90083-C [92] Forbes K, Nicolls F, De Jager G, Voigt A. Shape-from-silhouette with two mirrors and an uncalibrated camera. In: Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer, 2006. 165-178 doi: 10.1007/11744047_13.pdf [93] Lehtinen J, Aila T, Chen J W, Laine S, Durand F. Temporal light field reconstruction for rendering distribution effects. ACM Transactions on Graphics, 2011, 30(4): Article No. 55 http://cn.bing.com/academic/profile?id=f48b75e3f65df6c92db0ec3ba3f22ce9&encoded=0&v=paper_preview&mkt=zh-cn [94] Nayar S K, Nakagawa Y. Shape from focus. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(8): 824-831 doi: 10.1109/34.308479 [95] Hasinoff S W, Kutulakos K N. Confocal stereo. International Journal of Computer Vision, 2009, 81(1): 82-104 doi: 10.1007/s11263-008-0164-2 [96] Pradeep K S, Rajagopalan A N. Improving shape from focus using defocus cue. IEEE Transactions on Image Processing, 2007, 16(7): 1920-1925 doi: 10.1109/TIP.2007.899188 [97] Slabaugh G G, Culbertson W B, Malzbender T, Stevens M R, Schafer R W. Methods for volumetric reconstruction of visual scenes. International Journal of Computer Vision, 2004, 57(3): 179-199 doi: 10.1023/B:VISI.0000013093.45070.3b [98] de Vries S C, Kappers A M L, Koenderink J J. Shape from stereo: a systematic approach using quadratic surfaces. Perception & Psychophysics, 1993, 53(1): 71-80 http://cn.bing.com/academic/profile?id=23f384adcd3565fda27091b0a353d075&encoded=0&v=paper_preview&mkt=zh-cn [99] Seitz S M, Dyer C R. Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision, 1999, 35(2): 151-173 doi: 10.1023/A:1008176507526 [100] Kutulakos K N, Seitz S M. A theory of shape by space carving. International Journal of Computer Vision, 2000, 38(3): 199-218 doi: 10.1023/A:1008191222954 [101] Li D W, Xu L H, Tang X S, Sun S Y, Cai X, Zhang P. 3D imaging of greenhouse plants with an inexpensive binocular stereo vision system. Remote Sensing, 2017, 9(5): Article No. 508 doi: 10.3390/rs9050508 [102] Helveston E M, Boudreault G. Binocular vision and ocular motility: theory and management of strabismus. American Journal of Ophthalmology, 1986, 101(1): 135 http://d.old.wanfangdata.com.cn/OAPaper/oai_pubmedcentral.nih.gov_2590061 [103] Qi F, Zhao D B, Gao W. Reduced reference stereoscopic image quality assessment based on binocular perceptual information. IEEE Transactions on Multimedia, 2015, 17(12): 2338-2344 doi: 10.1109/TMM.2015.2493781 [104] Sizintsev M, Wildes R P. Spacetime stereo and 3D flow via binocular spatiotemporal orientation analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2241-2254 doi: 10.1109/TPAMI.2014.2321373 [105] Marr D, Poggio T. A computational theory of human stereo vision. Proceedings of the Royal Society B: Biological Sciences, 1979, 204(1156): 301-328 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC026931228 [106] Zou X J, Zou H X, Lu J. Virtual manipulator-based binocular stereo vision positioning system and errors modelling. Machine Vision and Applications, 2012, 23(1): 43-63 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0225968290/ [107] 李占贤, 许哲.双目视觉的成像模型分析.机械工程与自动化, 2014, (4): 191-192 doi: 10.3969/j.issn.1672-6413.2014.04.081Li Zhan-Xian, Xu Zhe. Analysis of imaging model of binocular vision. Mechanical Engineering & Automation, 2014, (4): 191-192 doi: 10.3969/j.issn.1672-6413.2014.04.081 [108] 张文明, 刘彬, 李海滨.基于双目视觉的三维重建中特征点提取及匹配算法的研究.光学技术, 2008, 34(2): 181-185 doi: 10.3321/j.issn:1002-1582.2008.02.039Zhang Wen-Ming, Liu Bin, Li Hai-Bin. Characteristic point extracts and the match algorithm based on the binocular vision in three dimensional reconstruction. Optical Technique, 2008, 34(2): 181-185 doi: 10.3321/j.issn:1002-1582.2008.02.039 [109] Bruno F, Bianco G, Muzzupappa M, Barone S, Razionale A V. Experimentation of structured light and stereo vision for underwater 3D reconstruction. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66(4): 508-518 doi: 10.1016/j.isprsjprs.2011.02.009 [110] Fusiello A, Trucco E, Verri A. A compact algorithm for rectification of stereo pairs. Machine Vision and Applications, 2000, 12(1): 16-22 doi: 10.1007/s001380050120 [111] Baillard C, Zisserman A. A plane-sweep strategy for the 3D reconstruction of buildings from multiple images. In: Proceedings of the 2000 International Archives of Photogrammetry and Remote Sensing. Amsterdam, Netherlands: ISPRS, 2000. 56-62 https://www.researchgate.net/publication/2813005_A_Plane-Sweep_Strategy_For_The_3D_Reconstruction_Of_Buildings_From_Multiple_Images [112] Hirschmuller H, Scharstein D. Evaluation of stereo matching costs on images with radiometric differences. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(9): 1582-1599 doi: 10.1109/TPAMI.2008.221 [113] Zhang T, Liu J H, Liu S L, Tang C T, Jin P. A 3D reconstruction method for pipeline inspection based on multi-vision. Measurement, 2017, 98: 35-48 doi: 10.1016/j.measurement.2016.11.004 [114] Saito K, Miyoshi T, Yoshikawa H. Noncontact 3-D digitizing and machining system for free-form surfaces. CIRP Annals, 1991, 40(1): 483-486 doi: 10.1016/S0007-8506(07)62035-6 [115] 陈明舟.主动光栅投影双目视觉传感器的研究[硕士学位论文], 天津大学, 中国, 2002 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y456511Chen Ming-Zhou. Research on Active Grating Projection Stereo Vision Sensor[Master thesis], Tianjin University, China, 2002 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y456511 [116] 王磊.三维重构技术的研究与应用[硕士学位论文], 清华大学, 中国, 2002Wang Lei. The Research and Application of 3D Reconstruction Technology[Master thesis], Tsinghua University, China, 2002 [117] Hernández C, Vogiatzis G, Cipolla R. Overcoming shadows in 3-source photometric stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2): 419-426 doi: 10.1109/TPAMI.2010.181 [118] Park H, Lee H, Sull S. Efficient viewer-centric depth adjustment based on virtual fronto-parallel planar projection in stereo 3D images. IEEE Transactions on Multimedia, 2014, 16(2): 326-336 doi: 10.1109/TMM.2013.2286567 [119] Bai X, Rao C, Wang X G. Shape vocabulary: a robust and efficient shape representation for shape matching. IEEE Transactions on Image Processing, 2014, 23(9): 3935-3949 doi: 10.1109/TIP.2014.2336542 [120] Goshtasby A, Stockman G C, Page C V. A region-based approach to digital image registration with subpixel accuracy. IEEE Transactions on Geoscience and Remote Sensing, 1986, GE-24 (3): 390-399 doi: 10.1109/TGRS.1986.289597 [121] Flusser J, Suk T. A moment-based approach to registration of images with affine geometric distortion. IEEE Transactions on Geoscience and Remote Sensing, 1994, 32(2): 382-387 doi: 10.1109/36.295052 [122] Alhichri H S, Kamel M. Virtual circles: a new set of features for fast image registration. Pattern Recognition Letters, 2003, 24(9-10): 1181-1190 doi: 10.1016/S0167-8655(02)00300-8 [123] Schmid C, Mohr R. Local grayvalue invariants for image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(5): 530-535 doi: 10.1109/34.589215 [124] Matas J, Chum O, Urban M, Pajdla T. Robust wide-baseline stereo from maximally stable extremal regions. Image and Vision Computing, 2004, 22(10): 761-767 doi: 10.1016/j.imavis.2004.02.006 [125] Tuytelaars T, Van Gool L. Matching widely separated views based on affine invariant regions. International Journal of Computer Vision, 2004, 59(1): 61-85 doi: 10.1023/B:VISI.0000020671.28016.e8 [126] Kadir T, Zisserman A, Brady M. An affine invariant salient region detector. In: Proceedings of the 8th European Conference on Computer Vision. Prague, Czech Republic: Springer, 2004. 228-241 http://www.researchgate.net/publication/2909469_An_Ane_Invariant_Salient_Region_Detector [127] Harris C, Stephens M. A combined corner and edge detector. In: Proceedings of the 4th Alvey Vision Conference. 1988. 1475-151 https://www.researchgate.net/publication/215458771_A_Combined_Corner_and_Edge_Detector [128] Morevec H P. Towards automatic visual obstacle avoidance. In: Proceedings of the 5th International Joint Conference on Artificial Intelligence. Cambridge, USA: ACM, 1977. 584 https://www.researchgate.net/publication/220814569_Towards_Automatic_Visual_Obstacle_Avoidance [129] Schmid C, Mohr R, Bauckhage C. Evaluation of interest point detectors. International Journal of Computer Vision, 2000, 37(2): 151-172 doi: 10.1023/A:1008199403446 [130] Van de Weijer J, Gevers T, Bagdanov A D. Boosting color saliency in image feature detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(1): 150-156 doi: 10.1109/TPAMI.2006.3 [131] Mikolajczyk K, Schmid C. Scale & affine invariant interest point detectors. International Journal of Computer Vision, 2004, 60(1): 63-86 https://www.researchgate.net/publication/215721498_Scale_Affine_Invariant_Interest_Point_Detectors [132] Smith S M, Brady J M. SUSAN — a new approach to low level image processing. International Journal of Computer Vision, 1997, 23(1): 45-78 doi: 10.1023/A:1007963824710 [133] Lindeberg T, Gårding J. Shape-adapted smoothing in estimation of 3-D shape cues from affine deformations of local 2-D brightness structure. Image and Vision Computing, 1997, 15(6): 415-434 doi: 10.1016/S0262-8856(97)01144-X [134] Lindeberg T. Feature detection with automatic scale selection. International Journal of Computer Vision, 1998, 30(2): 79-116 doi: 10.1023/A:1008045108935 [135] Baumberg A. Reliable feature matching across widely separated views. In: Proceedings of the 2000 IEEE Conference on Computer Vision and Pattern Recognition. Hilton Head Island, USA: IEEE, 2000. 774-781 [136] Lowe D G. Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999. 1150-1157 [137] Ke Y, Sukthankar R. PCA-SIFT: a more distinctive representation for local image descriptors. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington D.C., USA: IEEE, 2004. Ⅱ-506-Ⅱ-513 http://www.researchgate.net/publication/2926479_PCA-SIFT_A_More_Distinctive_Representation_for_Local_Image_Descriptors [138] Bay H, Tuytelaars T, Van Gool L. SURF: speeded up robust features. In: Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer, 2006. 404-417 [139] 葛盼盼, 陈强, 顾一禾.基于Harris角点和SURF特征的遥感图像匹配算法.计算机应用研究, 2014, 31(7): 2205-2208 doi: 10.3969/j.issn.1001-3695.2014.07.069Ge Pan-Pan, Chen Qiang, Gu Yi-He. Algorithm of remote sensing image matching based on Harris corner and SURF feature. Application Research of Computers, 2014, 31(7): 2205-2208 doi: 10.3969/j.issn.1001-3695.2014.07.069 [140] Wu C C. Towards linear-time incremental structure from motion. In: Proceedings of the 2013 International Conference on 3D Vision. Seattle, WA, USA: IEEE, 2013. 127-134 http://www.researchgate.net/publication/261447449_Towards_Linear-Time_Incremental_Structure_from_Motion [141] Cui H N, Shen S H, Gao W, Hu Z Y. Efficient large-scale structure from motion by fusing auxiliary imaging information. IEEE Transactions on Image Processing, 2015, 24(11): 3561-3573 doi: 10.1109/TIP.2015.2449557 [142] Sturm P, Triggs B. A factorization based algorithm for multi-image projective structure and motion. In: Proceedings of the 4th European conference on computer vision. Cambridge, UK: Springer, 1996. 709-720 https://www.researchgate.net/publication/47387653_A_Factorization_Based_Algorithm_for_multi-Image_Projective_Structure_and_Motion [143] Crandall D, Owens A, Snavely N, Huttenlocher D. Discrete-continuous optimization for large-scale structure from motion. In: Proceedings of CVPR 2011. Colorado Springs, CO, USA: IEEE, 2011. 3001-3008 [144] Irschara A, Hoppe C, Bischof H, Kluckner S. Efficient structure from motion with weak position and orientation priors. In: Proceedings of CVPR 2011 WORKSHOPS. Colorado Springs, CO, USA: IEEE, 2011. 21-28 http://www.researchgate.net/publication/224253054_Efficient_structure_from_motion_with_weak_position_and_orientation_priors [145] Tomasi C, Kanade T. Shape and motion from image streams: a factorization method. Carnegie Mellon University, USA, 1992. 9795-9802 http://www.researchgate.net/publication/2457353_Shape_and_Motion_from_Image_Streams_aFactorization_Method [146] Poelman C J, Kanade T. A paraperspective factorization method for shape and motion recovery. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(3): 206-218 doi: 10.1109/34.584098 [147] Triggs B. Factorization methods for projective structure and motion. In: Proceedings of the 1996 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 1996. 845-851 https://www.researchgate.net/publication/3637798_Factorization_Methods_for_Projective_Structure_and_Motion [148] Han M, Kanade T. Multiple motion scene reconstruction from uncalibrated views. In: Proceedings of the 8th IEEE International Conference on Computer Vision. Vancouver, Canada: IEEE, 2001. 163-170 https://www.researchgate.net/publication/3906057_Multiple_motion_scene_reconstruction_from_uncalibrated_views [149] 于海雁.基于多视图几何的三维重建研究[博士学位论文], 哈尔滨工业大学, 中国, 2007 http://cdmd.cnki.com.cn/Article/CDMD-10287-1012041345.htmYu Hai-Yan. 3D Reconstruction Based on Multiple View Geometry[Ph.D. dissertation], Harbin Institute of Technology, China, 2007 http://cdmd.cnki.com.cn/Article/CDMD-10287-1012041345.htm [150] Sivic J, Zisserman A. Video Google: a text retrieval approach to object matching in videos. In: Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France: IEEE, 2003. 1470-1477 [151] Faugeras O. Three-dimensional Computer Vision: A Geometric Viewpoint. Cambridge: MIT Press, 1993 [152] Xie R P, Yao J, Liu K, Lu X H, Liu X H, Xia M H, et al. Automatic multi-image stitching for concrete bridge inspection by combining point and line features. Automation in Construction, 2018, 90: 265-280 doi: 10.1016/j.autcon.2018.02.021 [153] Yan W Q, Hou C P, Lei J J, Fang Y M, Gu Z Y, Ling N. Stereoscopic image stitching based on a hybrid warping model. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(9): 1934-1946 doi: 10.1109/TCSVT.2016.2564838 [154] Pei J F, Huang Y L, Huo W B, Zhang Y, Yang J Y, Yeo T S. SAR automatic target recognition based on multiview deep learning framework. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2196-2210 doi: 10.1109/TGRS.2017.2776357 [155] Longuet-Higgins H C. A computer algorithm for reconstructing a scene from two projections. Nature, 1981, 293(5828): 133-135 doi: 10.1038/293133a0 [156] Faugeras O D, Maybank S. Motion from point matches: multiplicity of solutions. International Journal of Computer Vision, 1990, 4(3): 225-246 doi: 10.1007/BF00054997 [157] Luong Q T, Deriche R, Faugeras O D, Papadopoulo T. On determining the fundamental matrix: analysis of different methods and experimental results. RR-1894, INRIA, 1993. 24-48 http://www.researchgate.net/publication/243671119_On_determining_the_fundamental_matrix_Analysis_of_different_methods_and_experimental_results [158] Luong Q T, Faugeras O D. The fundamental matrix: theory, algorithms, and stability analysis. International Journal of Computer Vision, 1996, 17(1): 43-75 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_0908.0449 [159] Wu C C, Agarwal S, Curless B, Seitz S M. Multicore bundle adjustment. In: Proceedings of CVPR 2011. Providence, RI, USA: IEEE, 2011. 3057-3064 https://www.researchgate.net/publication/221361999_Multicore_bundle_adjustment?ev=auth_pub [160] Lourakis M I A, Argyros A A. SBA: a software package for generic sparse bundle adjustment. ACM Transactions on Mathematical Software, 2009, 36(1): Article No. 2 http://d.old.wanfangdata.com.cn/Periodical/wjclxb200304024 [161] Choudhary S, Gupta S, Narayanan P J. Practical time bundle adjustment for 3D reconstruction on the GPU. In: Proceedings of the 11th European Conference on Trends and Topics in Computer Vision. Heraklion, Crete, Greece: Springer, 2010. 423-435 [162] Hu Z Y, Gao W, Liu X, Guo F S. 3D reconstruction for heritage preservation[Online], available: http://vision.ia.ac.cn, March 29, 2012. [163] Fang T, Quan L. Resampling structure from motion. In: Proceedings of the 11th European Conference on Computer Vision. Crete, Greece: Springer, 2010. 1-14 https://www.researchgate.net/publication/221304471_Resampling_Structure_from_Motion [164] Tanimoto J, Hagishima A. State transition probability for the Markov model dealing with on/off cooling schedule in dwellings. Energy and Buildings, 2005, 37(3): 181-187 https://www.sciencedirect.com/science/article/pii/S0378778804000994 [165] Eddy S R. Profile hidden Markov models. Bioinformatics, 1998, 14(9): 755-763 doi: 10.1093/bioinformatics/14.9.755 [166] Chang M T, Chen S Y. Deformed trademark retrieval based on 2D pseudo-hidden Markov model. Pattern Recognition, 2001, 34(5): 953-967 doi: 10.1016/S0031-3203(00)00053-4 [167] Saxena A, Chung S H, Ng A Y. 3-D depth reconstruction from a single still image. International Journal of Computer Vision, 2008, 76(1): 53-69 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f823a58e5ab3cd194d7e8f70359c345b [168] Handa A, Whelan T, McDonald J, Davison A J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Hong Kong, China: IEEE, 2014. 1524-1531 http://www.researchgate.net/publication/286680449_A_benchmark_for_RGB-D_visual_odometry_3D_reconstruction_and_SLAM [169] Kemelmacher-Shlizerman I, Basri R. 3D face reconstruction from a single image using a single reference face shape. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2): 394-405 doi: 10.1109/TPAMI.2010.63 [170] Lee S J, Park K R, Kim J. A SFM-based 3D face reconstruction method robust to self-occlusion by using a shape conversion matrix. Pattern Recognition, 2011, 44(7): 1470-1486 doi: 10.1016/j.patcog.2010.11.012 [171] Song M L, Tao D C, Huang X Q, Chen C, Bu J J. Three dimensional face reconstruction from a single image by a coupled RBF network. IEEE Transactions on Image Processing, 2012, 21(5): 2887-2897 doi: 10.1109/TIP.2012.2183882 [172] Seo H, Yeo Y I, Wohn K. 3D body reconstruction from photos based on range scan. In: Proceedings of the 1st International Conference on Technologies for E-Learning and Digital Entertainment. Hangzhou, China: Springer, 2006. 849-860 https://www.researchgate.net/publication/221247718_3D_Body_Reconstruction_from_Photos_Based_on_Range_Scan [173] Allen B, Curless B, Popovi Z. The space of human body shapes: reconstruction and parameterization from range scans. ACM Transactions on Graphics, 2003, 22(3): 587-594 doi: 10.1145/882262.882311 [174] Funahashi K I. On the approximate realization of continuous mappings by neural networks. Neural Networks, 1989, 2(3): 183-192 doi: 10.1016/0893-6080(89)90003-8 [175] Do Y. Application of neural networks for stereo-camera calibration. In: Proceedings of the 1999 International Joint Conference on Neural Networks. Washington, USA: IEEE, 1999. 2719-2722 https://www.researchgate.net/publication/3839747_Application_of_neural_networks_for_stereo-camera_calibration [176] 袁野, 欧宗瑛, 田中旭.应用神经网络隐式视觉模型进行立体视觉的三维重建.计算机辅助设计与图形学学报, 2003, 15(3): 293-296 doi: 10.3321/j.issn:1003-9775.2003.03.009Yuan Ye, Ou Zong-Ying, Tian Zhong-Xu. 3D reconstruction of stereo vision using neural networks implicit vision model. Journal of Computer-Aided Design & Computer Graphics, 2003, 15(3): 293-296 doi: 10.3321/j.issn:1003-9775.2003.03.009 [177] Li X P, Chen L Z. Research on the application of BP neural networks in 3D reconstruction noise filter. Advanced Materials Research, 2014, 998-999: 911-914 doi: 10.4028/www.scientific.net/AMR.998-999.911 [178] Savinov N, Ladický L, Häne C, Pollefeys M. Discrete optimization of ray potentials for semantic 3D reconstruction. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 5511-5518 [179] Bláha M, Vogel C, Richard A, Wegner J D, Pock T, Schindler K. Large-scale semantic 3D reconstruction: an adaptive multi-resolution model for multi-class volumetric labeling. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 3176-3184 https://www.researchgate.net/publication/311611435_Large-Scale_Semantic_3D_Reconstruction_An_Adaptive_Multi-resolution_Model_for_Multi-class_Volumetric_Labeling [180] Sünderhauf N, Pham T T, Latif Y, Milford M, Reid I. Meaningful maps with object-oriented semantic mapping. In: Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver, BC, Canada: IEEE, 2017. 5079-5085 [181] 赵洋, 刘国良, 田国会, 罗勇, 王梓任, 张威, 等.基于深度学习的视觉SLAM综述.机器人, 2017, 39(6): 889-896 http://d.old.wanfangdata.com.cn/Periodical/jqr201706015Zhao Yang, Liu Guo-Liang, Tian Guo-Hui, Luo Yong, Wang Zi-Ren, Zhang Wei, et al. A survey of visual SLAM based on deep learning. Robot, 2017, 39(6): 889-896 http://d.old.wanfangdata.com.cn/Periodical/jqr201706015 -

 下载:
下载:



计量
- 文章访问数: 19983
- HTML全文浏览量: 10156
- PDF下载量: 4514
- 被引次数: 0
