

Modeling Multiple Components Mechanical Signals by Means of Virtual Sample Generation Technique
-
摘要: 采用具有多组分、非平稳、非线性等特性的机械振动/振声信号构建数据驱动软测量模型,是目前工业界测量高能耗旋转机械设备内部难以检测过程参数的常用手段.针对机械信号产生机理的复杂性导致模型解释性弱,以及工业过程连续不间断运行和机械设备旋转封闭的特殊性导致获取完备训练样本的经济性差和周期性长等问题,本文提出一种基于虚拟样本生成(Virtual sample generation,VSG)技术的多组分机械信号建模方法.首先,将机械信号自适应分解为具有不同时间尺度的平稳子信号并变换为多尺度谱数据;接着,采用适合于小样本高维数据建模的改进选择性集成核偏最小二乘(Selective ensemble kernel partial least squares,SENKPLS)算法构建面向真实训练样本的基于可行性的规划(Feasibility-based programming,FBP)模型,提出一种综合先验知识和FBP模型等手段面向高维谱数据的VSG技术,用以弥补真实训练样本的短缺问题;然后,基于互信息(Mutual information,MI)对由真实和虚拟训练样本组成的混合建模数据进行自适应特征选择;最后,基于约简的混合训练样本采用SENKPLS构建软测量模型.以近红外谱数据和磨矿过程实验球磨机的筒体振动/振声信号验证所提VSG技术和面向多组分机械信号建模方法的合理性和有效性.Abstract: Mechanical vibration & acoustic signals with characteristics of multiple components, nonstationarity and nonlinearity are always used to construct the data-driven soft sensor model of industrial processes. It is one of the main approaches to measure the difficulty-to-measure process parameters inside those high energy consumption mechanical devices. Duo to the complexity of the production mechanism of these mechanical signals, most of these soft sensor models are difficult to be explained. Moreover, the characteristics of the industrial process' continuous running and the mechanical equipment' operation modes lead to the difficulty of high economic cost and long period waiting to obtain sufficient training samples. To solve these problems, a new multi-component mechanical signal modeling method based on virtual sample generation (VSG) technology is proposed. Firstly, the mechanical signals are processed into a set of sub-signals with different time scales by using adaptive multi-component signal decomposition technique; then these sub-signals are transferred to high dimensional multi-scale spectral data. Secondly, an improved selective ensemble kernel partial least squares (SENKPLS) algorithm that suits to model small sample high dimensional data is used to construct a feasibility-based programming (FBP) model with the true training samples; then prior knowledge, FBP models and information entropy are integrated to produce virtual training samples. Thirdly, mutual information (MI) method is used to select the spectral features of the new mixing training samples based on the true and virtual ones. Finally, a soft sensor model is built by using these reduced mixing spectral data. Near-infra spectra data and mechanical vibration and acoustic singals of a laboratory-scale ball mill in grinding process validate the reasonability and effectiveness of the proposed VSG techniques and multi-component mechanical signals-based modeling approach.1) 本文责任编委 侯忠生
-
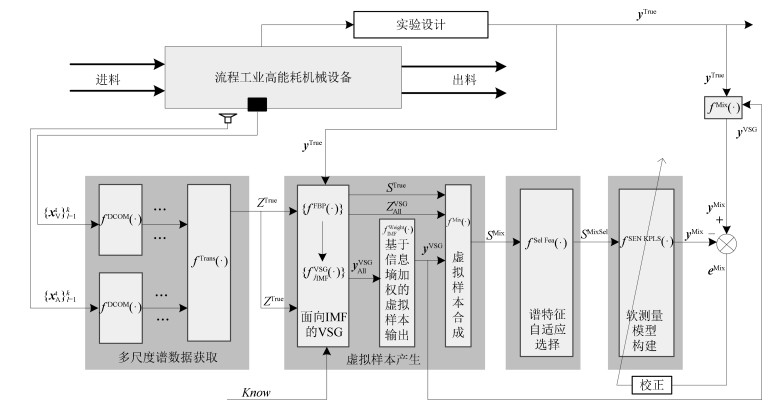
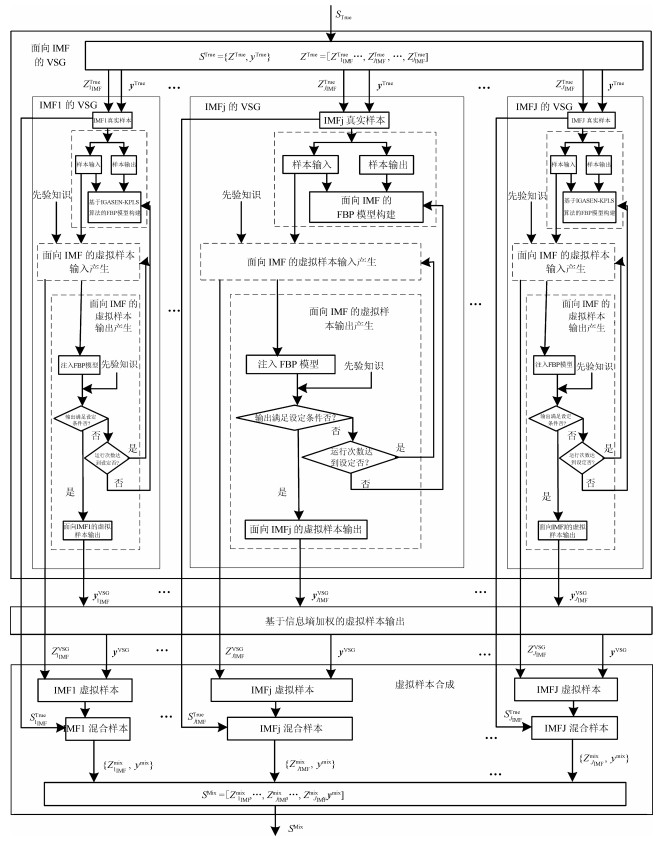
图 1 基于VSG的多组分机械信号建模策略
Fig. 1 Multi-component mechanical signal modeling strategy based on VSG

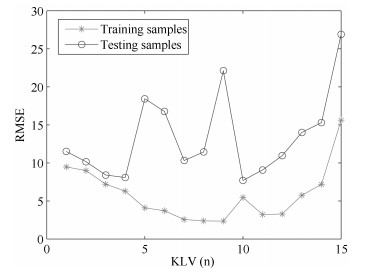
图 7 基于不同数量的虚拟样本构建模型的训练误差
Fig. 7 Training errors of the constructed model based on virtual samples with different numbers
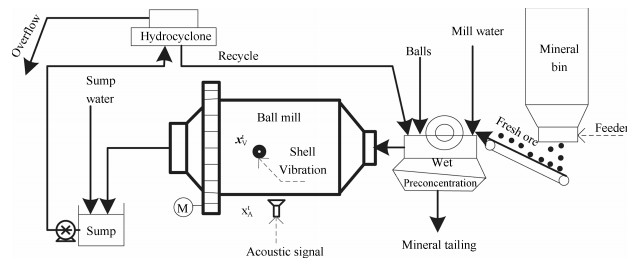
图 8 某选矿厂一段磨矿回路(GC Ⅰ)工艺流程
Fig. 8 Flow chart of the grinding circuit Ⅰ (GC Ⅰ) of some mineral grinding process
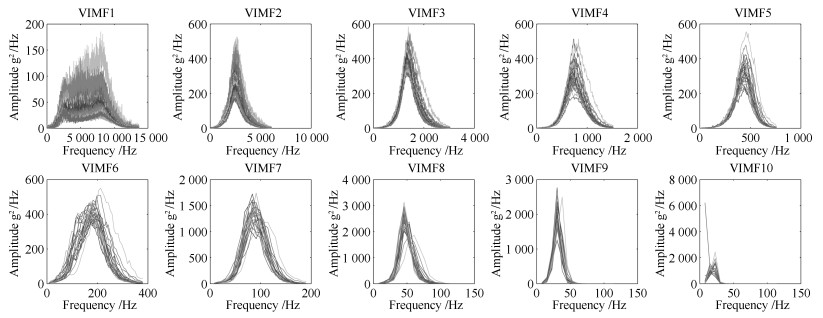
图 9 磨机筒体振动的VIMF1~10子信号的真实谱数据
Fig. 9 True spectra data of VIMF1~10 sub-signals from mill shell vibration signal
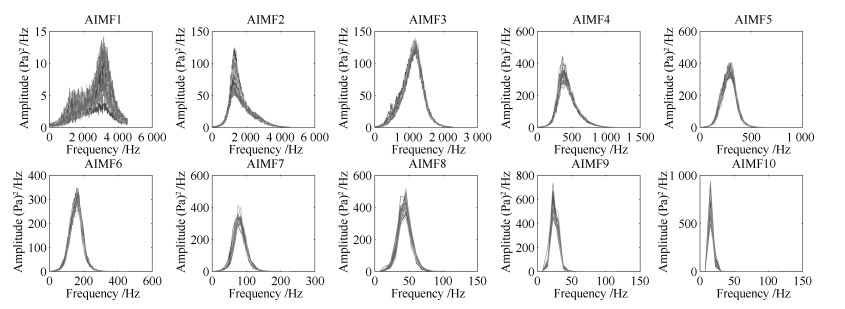
图 10 磨机振声AIMF1~10子信号的真实谱数据
Fig. 10 True spectra data of VIMF1~10 sub-signals from mill acoustic signal
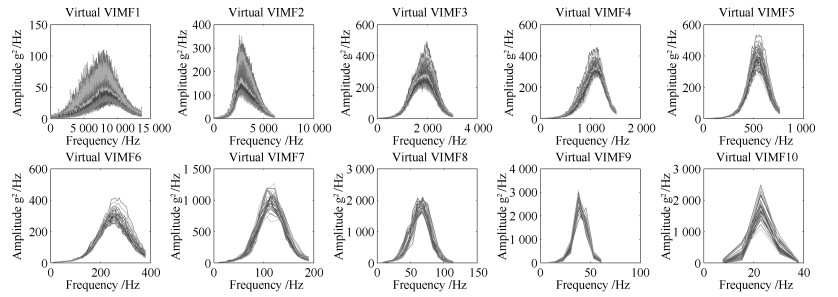
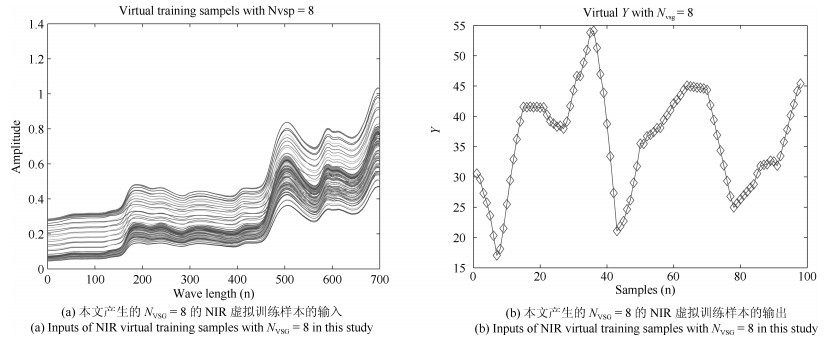
图 11 磨机筒体振动VIMF1~10的虚拟谱数据
Fig. 11 Virtual spectra data of VIMF1~10 sub-signals from mill shell vibration signal
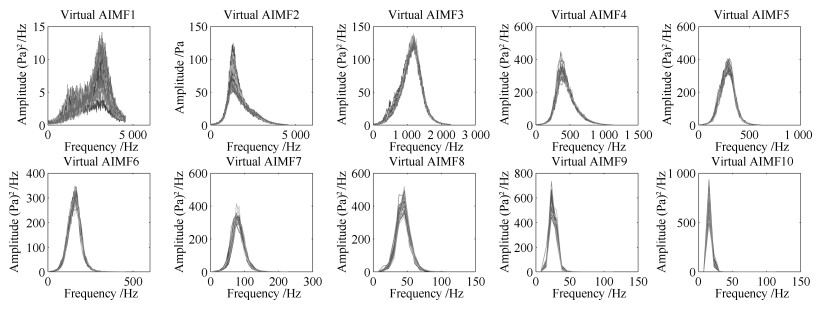
图 12 磨机振声AIMF1~10的虚拟谱数据
Fig. 12 Virtual spectra data of AIMF1~10 sub-signals from mill acoustic signal
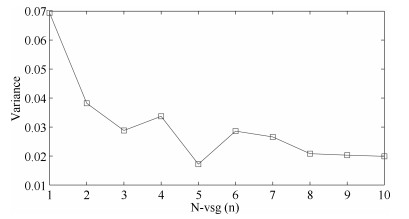
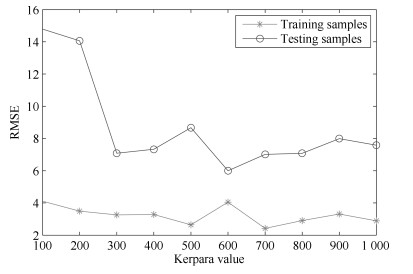
图 13 基于不同${N_{{\rm{VSG}}}}$值构建的软测量模型测试误差的方差
Fig. 13 Variance of the testing errors based on soft sensor models using different ${N_{{\rm{VSG}}}}$ values
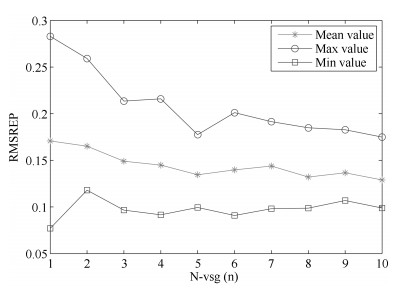
图 14 基于不同${N_{{\rm{VSG}}}}$值构建的软测量模型的测试误差
Fig. 14 Testing errors based on soft sensor models using different ${N_{{\rm{VSG}}}}$ values
表 1 基于PLS提取的潜在特征的贡献率
Table 1 Contribution of the latent features extracted based on PLS
LV# 输入单LV 输入累计 输出单LV 输出累计 1 88.85 88.85 23.78 23.78 2 10.96 99.8 19 42.78 3 0.17 99.97 20.8 63.57 4 0.01 99.98 21.77 85.35 5 0.01 99.99 8.63 93.98  下载: 导出CSV
下载: 导出CSV
表 2 基于混合样本建立的NIR模型统计结果
Table 2 Statistical results of NIR model based on mixed samples
真实样本数量 虚拟样本数量 核半径值 KLV数量 均值(Mean) 最大值(Max) 最小值(Min) 方差(Var) 15 0 600 10 7.188 9.0742 5.6867 0.9779 15 14 65 12 6.9473 9.3558 5.9747 0.8814 15 28 50 15 7.7808 11.2846 6.2231 1.2904 15 42 0.8 13 8.9316 10.3599 7.7212 0.7781 15 56 10 14 7.7027 12.2875 6.0686 1.6912 15 70 60 13 8.3782 11.6499 7.2438 1.0895 15 84 60 10 7.0026 7.6549 6.5843 0.3273 15 98 65 12 7.3832 8.4788 6.8142 0.4051 15 112 75 9 6.0723 6.8627 5.8029 0.2375 15 126 19 12 8.1114 10.0179 6.5984 0.8225
下载: 导出CSV
表 3 用于产生虚拟样本的真实训练样本分布
Table 3 Distribution of the true training samples for generating virtual samples
样本序号 1 2 3 4 5 6 7 8 9 10 11 12 13 固定负荷(kg) 料10 料10 料10 水2 水2 水2 料20 料20 料20 水10 水10 水10 水10 变化负荷(kg) 水5 水15 水20 料10 料1 6 料20 水7.5 水12.5 水20 料24 料28 料35 料45
下载: 导出CSV
表 4 面向CVR的谱特征选择的统计结果
Table 4 Statistical results of spectra feature selection for CVR
真实样本数量 虚拟样本数量 振动特征数量 振声特征数量 特征数量总和 MI阈值 13 9 1 344 190 1 534 0.8 13 18 473 71 514 0.9 13 27 3 388 1 878 5 266 0.2 13 36 895 175 1 070 0.8 13 45 3 396 1 870 5 266 0.2 13 54 3 387 1 869 5 256 0.2 13 63 3 403 1 880 5 283 0.1 13 72 3 384 1 865 5 249 0.2 13 81 3 403 1 879 5 282 0.1
下载: 导出CSV
表 5 基于不同数量混合样本构建的软测量模型的统计结果
Table 5 Statistical results of soft sensor models based on mix samples with different number
真实样本数量 虚拟样本数量 RMSREP均值
(Mean)RMSREP最小值
(Min)RMSREP最大值
(Max)RMSREP方差
(Var)PLS 26 0 0.3445 0.1492 0.5803 0.0977 KPLS 26 0 0.1839 0.0704 0.4598 0.0947 文献[24] 26 0 0.1265 0.0381 0.4263 0.0677 文献[20] 26 0 0.3424 0.1967 0.4773 0.0778 文献[21] 26 0 0.2184 0.0968 0.4418 0.0858 本文 26 0 0.1708 0.0771 0.2829 0.0694 方法 26 9 0.1651 0.118 0.2591 0.0382 26 18 0.149 0.0966 0.2135 0.0288 26 27 0.1449 0.0916 0.2159 0.0337 26 36 0.1345 0.0994 0.1775 0.0172 26 45 0.1397 0.0909 0.2011 0.0286 26 54 0.1439 0.0981 0.1914 0.0266 26 63 0.1321 0.0987 0.1849 0.0208 26 72 0.1366 0.1069 0.1828 0.0203 26 81 0.129 0.0988 0.1749 0.0199 注: 表 5中的26个真实样本中, 仅是表 3中所示的13个用于产生虚拟样本.
下载: 导出CSV
-
[1] 柴天佑.工业过程控制系统研究现状与发展方向.中国科学:信息科学, 2016, 46 (8):1003-1015 http://www.cnki.com.cn/Article/CJFDTOTAL-PZKX201608005.htmChai Tian-You. Industrial process control systems:research status and development direction. Scientia Sinica Informationis, 2016, 46 (8):1003-1015 http://www.cnki.com.cn/Article/CJFDTOTAL-PZKX201608005.htm [2] 孙备, 张斌, 阳春华, 桂卫华.有色冶金净化过程建模与优化控制问题探讨.自动化学报, 2017, 43 (6):880-892 http://www.aas.net.cn/CN/abstract/abstract19067.shtmlSun Bei, Zhang Bin, Yang Chun-Hua, Gui Wei-Hua. Discussion on modeling and optimal control of nonferrous metallurgical purification process. Acta Automatica Sinica, 2017, 43 (6):880-892 http://www.aas.net.cn/CN/abstract/abstract19067.shtml [3] 宋贺达, 周平, 王宏, 柴天佑.高炉炼铁过程多元铁水质量非线性子空间建模及应用.自动化学报, 2016, 42(11):1664-1679 http://www.aas.net.cn/CN/abstract/abstract18956.shtmlSong He-Da, Zhou Ping, Wang Hong, Chai Tian-You. Nonlinear subspace modeling of multivariate molten iron quality in blast furnace ironmaking and its application. Acta Automatica Sinica, 2016, 42 (11):1664-1679 http://www.aas.net.cn/CN/abstract/abstract18956.shtml [4] Zhou P, Chai T Y, Wang H. Intelligent optimal-setting control for grinding circuits of mineral processing. IEEE Transactions on Automation Science and Engineering, 2009, 6 (4):730-743 doi: 10.1109/TASE.2008.2011562 [5] 柴天佑.复杂工业过程运行优化与反馈控制.自动化学报, 2013, 39(11):1744-1757 http://www.aas.net.cn/CN/abstract/abstract18214.shtmlChai Tian-You. Operational optimization and feedback control for complex industrial processes. Acta Automatica Sinica, 2013, 39 (11):1744-1757 http://www.aas.net.cn/CN/abstract/abstract18214.shtml [6] 汤健, 田福庆, 贾美英, 李东.基于频谱数据驱动的旋转机械设备负荷软测量.北京:国防工业出版社, 2015. 1-63Tang Jian, Tian Fu-Qing, Jia Mei-Ying, Li Dong. Load Soft Sensor of Rotating Mechanical Device based on Frequency Spectral Data-Driven. Beijing:National Defense Industrial Press, 2015. 1-63 [7] Tang J, Chai T Y, Liu Z, Yu W. Selective ensemble modeling based on nonlinear frequency spectral feature extraction for predicting load parameter in ball mills. Chinese Journal of Chemical Engineering, 2015, 23 (12):2020-2028 doi: 10.1016/j.cjche.2015.10.006 [8] Tang J, Qiao J F, Wu Z W, Chai T Y, Zhang J, Yu W. Vibration and acoustic frequency spectra for industrial process modeling using selective fusion multi-condition samples and multi-source features. Mechanical Systems and Signal Processing, 2018, 99:142-168 doi: 10.1016/j.ymssp.2017.06.008 [9] Zeng Y, Forssberg E. Monitoring grinding parameters by vibration signal measurement-a primary application. Minerals Engineering, 1994, 7(4):495-501 doi: 10.1016/0892-6875(94)90162-7 [10] Tang J, Zhao L J, Zhou J W, Yue H, Chai T Y. Experimental analysis of wet mill load based on vibration signals of laboratory-scale ball mill shell. Minerals Engineering, 2010, 23 (9):720-730 doi: 10.1016/j.mineng.2010.05.001 [11] Lei Y G, He Z J, Zi Y Y. Application of the EEMD method to rotor fault diagnosis of rotating machinery. Mechanical Systems and Signal Processing, 2009, 23 (4):1327-1338 doi: 10.1016/j.ymssp.2008.11.005 [12] Singh G K, AlKazzaz S A S. Isolation and identification of dry bearing faults in induction machine using wavelet transform. Tribology International, 2009, 42 (6):849-861 doi: 10.1016/j.triboint.2008.11.008 [13] Cusido J, Romeral L, Ortega J A, Rosero J A, Garcia Espinosa A G. Fault detection in induction machines using power spectral density in wavelet decomposition. IEEE Transactions on Industrial Electronics, 2008, 55 (2):633-643 doi: 10.1109/TIE.2007.911960 [14] Riera-Guasp M, Antonino-Daviu J A, Pineda-Sanchez M, Puche-Panadero R, Perez-Cruz J. A general approach for the transient detection of slip-dependent fault components based on the discrete wavelet transform. IEEE Transactions on Industrial Electronics, 2008, 55 (12):4167-4180 doi: 10.1109/TIE.2008.2004378 [15] Kankar P K, Sharma S C, Harsha S P. Rolling element bearing fault diagnosis using autocorrelation and continuous wavelet transform. Journal of Vibration and Control, 2011, 17 (14):2081-2094 doi: 10.1177/1077546310395970 [16] Huang N E, Shen Z, Long S R, Wu M C, Shih H H, Zheng Q, Yen N C, Tung C C, Liu H H. The empirical mode decomposition and the Hilbert spectrum for non-linear and non-stationary time series analysis. Proceedings of the Royal Society A:Mathematical, Physical and Engineering Sciences, 1998, 454 (1971):903-995 doi: 10.1098/rspa.1998.0193 [17] Faiz J, Ghorbanian V, Ebrahimi B M. EMD-Based analysis of industrial induction motors with broken rotor bars for identification of operating point at different supply modes. IEEE Transactions on Industrial Informatics, 2014, 10 (2):957-966 doi: 10.1109/TII.2013.2289941 [18] Shukla S, Mishra S, Singh B. Power quality event classification under noisy conditions using EMD-Based De-Noising techniques. IEEE Transactions on Industrial Informatics, 2014, 10 (2):1044-1054 doi: 10.1109/TII.2013.2289392 [19] Li R Y, He D. Rotational machine health monitoring and fault detection using EMD-based acoustic emission feature quantification. IEEE Transactions on Instrumentation and Measurement, 2012, 61 (4):990-1001 doi: 10.1109/TIM.2011.2179819 [20] Zhao L, Tang J, Zheng W. Ensemble modeling of mill load based on empirical mode decomposition and partial least squares. Journal of Theoretical and Applied Information Technology, 2012, 45 (1):179-191 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC0212714595 [21] 汤健, 柴天佑, 丛秋梅, 苑明哲, 赵立杰, 刘卓, 余文.基于EMD和选择性集成学习算法的磨机负荷参数软测量.自动化学报, 2014, 40 (9):1853-1866 http://www.aas.net.cn/CN/abstract/abstract18454.shtmlTang Jian, Chai Tian-You, Cong Qiu-Mei, Yuan Ming-Zhe, Zhao Li-Jie, Liu Zhuo, Yu Wen. Soft sensor approach for modeling mill load parameters based on EMD and selective ensemble learning algorithm. Acta Automatica Sinica, 2014, 40 (9):1853-1866 http://www.aas.net.cn/CN/abstract/abstract18454.shtml [22] Wu Z H, Huang N E. Ensemble empirical mode decomposition:a noise-assisted data analysis method. Advances in Adaptive Data Analysis, 2009, 1 (1):1-41 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201305033 [23] 汤健, 柴天佑, 丛秋梅, 刘卓, 余文.选择性融合多尺度筒体振动频谱的磨机负荷参数建模.控制理论与应用, 2015, 32 (12):1582-1591 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201512002Tang Jian, Chai Tian-You, Cong Qiu-Mei, Liu Zhuo, Yu Wen. Modeling mill load parameters based on selective fusion of multi-scale shell vibration frequency spectrum. Control Theory Applications, 2015, 32 (12):1582-1591 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201512002 [24] Tang J, Chai T, Yu W, Zhao L J. Modeling load parameters of ball mill in grinding process based on selective ensemble multisensor information. IEEE Transactions on Automation Science and Engineering, 2013, 10 (3):726-740 doi: 10.1109/TASE.2012.2225142 [25] 汤健, 柴天佑, 赵立杰, 岳恒, 郑秀萍.融合时频信息的磨矿过程磨机负荷软测量.控制理论与应用, 2012, 29(5):564-570 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK201202054009Tang Jian, Chai Tian-You, Zhao Li-Jie, Yue Heng, Zheng Xiu-Ping. Soft sensing mill load in grinding process by time/frequency information fusion. Control Theory and Applications, 2012, 29 (5):564-570 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK201202054009 [26] 汤健, 柴天佑, 刘卓.一种磨机负荷参数软测量方法, 国家发明专利, 201510303525, 2015年6月Tang Jian, Chai Tian-You, Liu Zhuo. A Soft Measuring Method for Mill Load Parameter, China, Patent 201510303525, June 2015 [27] Liu H W, Sun J G, Liu L, Zhang H J. Feature selection with dynamic mutual information. Pattern Recognition, 2009, 42 (7):1330-1339 doi: 10.1016/j.patcog.2008.10.028 [28] Zhou Z H, Wu J X, Tang W. Ensembling neural networks:many could be better than all. Artificial Intelligence, 2002, 137 (1-2):239-263 doi: 10.1016/S0004-3702(02)00190-X [29] Tang J, Zhang J, Wu Z W, Liu Z, Chai T Y, Yu W. Modeling collinear data using double-layer GA-based selective ensemble kernel partial least squares algorithm. Neurocomputing, 2017, 219:248-262 doi: 10.1016/j.neucom.2016.09.019 [30] Zhang X M, Kano M, Li Y. Locally weighted kernel partial least squares regression based on sparse nonlinear features for virtual sensing of nonlinear time-varying processes. Computers and Chemical Engineering, 2017, 104:164-171 doi: 10.1016/j.compchemeng.2017.04.014 [31] Poggio T, Vetter T. Recognition and Structure from One 2D Model View: Observations on Prototypes, Object Classes and Symmetries, Technical Report A. I. Memo 1347, Massachusetts Institute of Technology Cambridge, MA, USA, 1992. [32] Li L J, Peng Y L, Qiu G Y, Sun Z G, Liu S G. A survey of virtual sample generation technology for face recognition. Artificial Intelligence Review, 2017, 1:1-20 doi: 10.1007/s10462-016-9537-z [33] Du Y, Wang Y. Generating virtual training samples for sparse representation of face images and face recognition. Journal of Modern Optics, 2016, 63 (6):536-544 doi: 10.1080/09500340.2015.1083131 [34] Li D C, Wu C S, Tsai T I, Lina Y S. Using mega-trend-diffusion and artificial samples in small data set learning for early flexible manufacturing system scheduling knowledge. Computers and Operations Research, 2007, 34 (4):966-982 doi: 10.1016/j.cor.2005.05.019 [35] Abu-Mostafa Y S. Hints. Neural Computation, 1995, 7 (4):639-671 doi: 10.1162/neco.1995.7.4.639 [36] An G Z. The effects of adding noise during backpropagation training on a generalization performance. Neural Computation, 1996, 8 (3):643-674 doi: 10.1162/neco.1996.8.3.643 [37] Li D C, Lin Y S. Using virtual sample generation to build up management knowledge in the early manufacturing stages. European Journal of Operational Research, 2006, 175 (1):413-434 doi: 10.1016/j.ejor.2005.05.005 [38] Li D C, Fang Y H, Lai Y Y, Hu S C. Utilization of virtual samples to facilitate cancer identification for DNA microarray data in the early stages of an investigation. Information Sciences, 2009, 179 (16):2740-2753 doi: 10.1016/j.ins.2009.04.003 [39] Chang C J, Li D C, Chen C C, Chen C S. A forecasting model for small non-equigap data sets considering data weights and occurrence possibilities. Computers and Industrial Engineering, 2014, 67 (1):139-145 http://www.sciencedirect.com/science/article/pii/S0360835213003598 [40] Cho S, Jang M, Chang S. Virtual sample generation using a population of networks. Neural Processing Letters, 1997, 5 (2):21-27 doi: 10.1023/A:1009653706403 [41] Huang C F, Moraga C. A diffusion-neural-network for learning from small samples. International Journal of Approximate Reasoning, 2004, 35 (2):137-161 doi: 10.1016/j.ijar.2003.06.001 [42] Li D C, Wen I H. A genetic algorithm-based virtual sample generation technique to improve small data set learning. Neurocomputing, 2014, 143:222-230 doi: 10.1016/j.neucom.2014.06.004 [43] Chen Z S, Zhu B, He Y L, Yu L A. A PSO based virtual sample generation method for small sample sets:applications to regression datasets. Engineering Applications of Artificial Intelligence, 2017, 59:236-243 doi: 10.1016/j.engappai.2016.12.024 [44] Gong H F, Chen Z S, Zhu Q X, He Y L. A monte carlo and PSO based virtual sample generation method for enhancing the energy prediction and energy optimization on small data problem:an empirical study of petrochemical industries. Applied Energy, 2017, 197:405-415 doi: 10.1016/j.apenergy.2017.04.007 [45] Coqueret G. Approximate norta simulations for virtual sample generation. Expert Systems with Applications, 2017, 73:69-81 doi: 10.1016/j.eswa.2016.12.027 [46] 汤健, 孙春来, 毛克峰.一种虚拟样本生成方法, 国家发明专利, 201510496474, 2015年8月Tang Jian, Sun Chun-Lai, Mao Ke-Feng. A Virtual Sample Generation Method China Patent 201510303525, August 2015 [47] Wang F Y. A big-data perspective on AI:Newton, Merton, and analytics intelligence. IEEE Intelligent Systems, 2012, 27 (5):24-34 http://dl.acm.org/citation.cfm?id=2412706 [48] 李力, 林懿伦, 曹东璞, 郑南宁, 王飞跃.平行学习-机器学习的一个新型理论框架.自动化学报, 2017, 43(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtmlLi Li, Lin Yi-Lun, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel learning-a new framework for machine learning. Acta Automatica Sinica, 2017, 43 (1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtml [49] Tang J, Chai T Y, Zhao L J, Yue H. Soft sensor for parameters of mill load based on multi-spectral segments PLS sub-models and on-line adaptive weighted fusion algorithm. Neurocomputing, 2012, 78 (1):38-47 doi: 10.1016/j.neucom.2011.05.028 [50] Rosipal R, Trejo L J. Kernel partial least squares regression in reproducing kernel Hilbert space. Journal of Machine Learning Research, 2002, 2:97-123 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_0902.4380 [51] Dhanjal C, Gunn S R, Shawetaylor J. Efficient sparse kernel feature extraction based on partial least squares. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31 (8):1347-1361 doi: 10.1109/TPAMI.2008.171 [52] Tang J, Yu W, Chai T, Liu Z, Zhou X J. Selective ensemble modeling load parameters of ball mill based on multi-scale frequency spectral features and sphere criterion. Mechanical Systems and Signal Processing, 2016, 66-67:485-504 doi: 10.1016/j.ymssp.2015.04.028 [53] Joe Qin S. Survey on data-driven industrial process monitoring and diagnosis. Annual Reviews in Control, 2012, 36 (2):220-234 doi: 10.1016/j.arcontrol.2012.09.004 [54] Yin S, Ding S X, Haghani A, Hao H Y, Zhang P. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. Journal of Process Control, 2012, 22 (9):1567-1581 doi: 10.1016/j.jprocont.2012.06.009 [55] Ge Z Q, Song Z H, Gao F R. Review of recent research on data-based process monitoring. Industrial and Engineering Chemistry Research, 2013, 52 (10):3543-3562 doi: 10.1021/ie302069q [56] Yin S, Li X W, Gao H J, Kaynak O. Data-based techniques focused on modern industry:an overview. IEEE Transactions on Industrial Electronics, 2014, 62 (1):657-667 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6748057 [57] Cong Y, Wang S, Fan B J, Yang Y S, Yu H B. UDSFS:unsupervised deep sparse feature selection. Neurocomputing, 2016, 196:150-158 doi: 10.1016/j.neucom.2015.10.130 [58] Liu Z, Chai T Y, Yu W, Tang J. Multi-frequency signal modeling using empirical mode decomposition and PCA with application to mill load estimation, Neurocomputing, 2014, 169:392-402 http://www.sciencedirect.com/science/article/pii/S092523121500421X [59] Motai, Y. Kernel association for classification and prediction:a survey. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26 (2):208-223 doi: 10.1109/TNNLS.2014.2333664 [60] de Lázaro J M B, Moreno A P, Santiago O L, da Silva Neto A J. Optimizing kernel methods to reduce dimensionality in fault diagnosis of industrial systems. Computers and Industrial Engineering, 2015, 87:140-149 doi: 10.1016/j.cie.2015.05.012 [61] Tang J, Liu Z, Zhang J, Chai T Y, Yu W. Kernel latent features adaptive extraction and selection method for multi-component non-stationary signal of industrial mechanical device. Neurocomputing, 2016, 216:296-309 doi: 10.1016/j.neucom.2016.07.043 [62] Li D C, Liu C W. Extending attribute information for small data set classfication. IEEE Transactions on Knowledge and Data Engineering, 2010, 24 (3):452-464 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5677515 [63] Shawe-Taylor J, Anthony M, Biggs N L. Bounding sample size with the Vapnik-Chervonenkis dimension. Discrete Applied Mathematics, 1993, 42 (1):65-73 doi: 10.1016/0166-218X(93)90179-R [64] Muto Y, Hamamoto Y. Improvement of the Parzen classifier in small training sample size. Intelligent Data Analysis, 2001, 5 (6):477-490 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=JJ024560770 [65] Raudys S J, Jain A K. Small sample size effects in statistical pattern recognition:Recommendations for Practitioners. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1991, 13 (3):252-264 doi: 10.1109/34.75512 [66] Duin R P W. Small sample size generalization. In: Proceedings of the 9th Scandinavian Conference on Image Analysis. Uppsala, Sweden: Mendeley, 1995. 957-964 https://www.mendeley.com/research-papers/small-sample-size-generalization/ [67] Yang J, Yu X, Xie Z Q, Zhang J P. A novel virtual sample generation method based on Gaussian distribution. Knowledge-Based Systems, 2011, 24 (6):740-748 doi: 10.1016/j.knosys.2010.12.010 [68] Li D C, Chen L S, Lin Y S. Using Functional Virtual Population as assistance to learn scheduling knowledge in dynamic manufacturing environments. International Journal of Production Research, 2003, 41 (17):4011-4024 doi: 10.1080/0020754031000149211 [69] Li D C, Wu C S, Tsai T I, Chang F M. Using mega-fuzzification and data trend estimation in small data set learning for early FMS scheduling knowledge. Computers and Operations Research, 2006, 33 (6):1857-1869 doi: 10.1016/j.cor.2004.11.022 [70] Lin Y S, Li D C. The Generalized-Trend-Diffusion modeling algorithm for small data sets in the early stages of manufacturing systems. European Journal of Operational Research, 2010, 207 (1):121-130 doi: 10.1016/j.ejor.2010.03.026 [71] Lei Y G, Lin J, He Z J, Zuo M J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mechanical Systems and Signal Processing, 2013, 35 (1-2):108-126 doi: 10.1016/j.ymssp.2012.09.015 [72] Efron B, Tibshirani R. Improvements on Cross-Validation:the 632+ bootstrap method. Journal of the American Statistical Association, 1997, 92 (438):548-560 http://biostatistics.oxfordjournals.org/external-ref?access_num=10.2307/2965703&link_type=DOI [73] Krzanowski W J, Hand D J. Assessing error rate estimators:the leave-one-out method reconsiderd. Australian and New Zealand Journal of Statistics, 2010, 39 (1):35-46 http://www.mendeley.com/research/assessing-error-rate-estimators-leave-one-method-reconsidered/ [74] Mevik B H, Cederkvist H R. Mean squared error of prediction (MSEP) estimates for principal component regression (PCR) and partial least squares regression (PLSR). Journal of Chemometrics, 2004, 18 (9):422-429 doi: 10.1002/(ISSN)1099-128X -

 下载:
下载:


计量
- 文章访问数: 3302
- HTML全文浏览量: 720
- PDF下载量: 1133
- 被引次数: 0
