

A Real-time Reasoning Engine for Injection-production Optimization of Water and Oil Wells on Account of Bitmap
-
摘要: 针对油田油水井采注优化业务中,油水井数据量大、地层结构复杂以及人类经验多的特点,分析了传统推理方法在油田采注实时优化处理过程中的不足,采用事件处理思想,提出了一种基于Bitmap事件编码与匹配机制的推理引擎,有效地实现了对无效事件的过滤并提升了事件与规则的匹配效率.在油田实际数据试验平台上对该方法进行了验证并与RETE算法、LFA(Linear forward-chaining)算法的性能对比,结果验证了本文方法在实时推理能力上的有效性.Abstract: In the process of optimizing the injection-production in oil and water wells, complex stratigraphic structure and large amount of business data and human experience will be involved. In this situation, traditional reasoning methods cannot be effective. By introducing the event processing theory, a reasoning engine using bitmap event encoding and matching is proposed, which can filter out invalid events efficiently and improve the matching performance between events and rules. The proposed reasoning engine is implemented in a real oilfield data experiment platform. Compared with RETE algorithm and LFA (Linear forward-chaining) algorithm, the proposed method shows a better reasoning capability.
-
Key words:
- Production-injection optimization /
- reasoning engine /
- bitmap /
- rule matching /
- event filtering
-

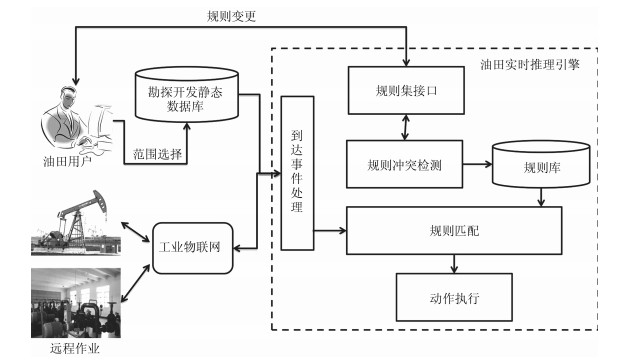
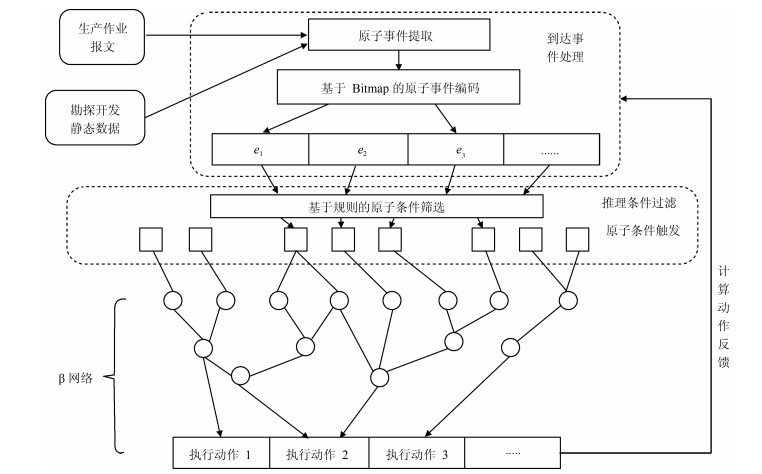
图 7 油水井采注协同优化流程图
Fig. 7 The co-optimization flow chart for injection-production in oil and water wells
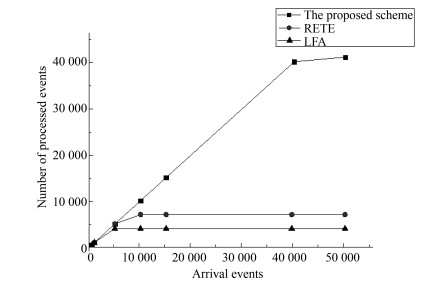
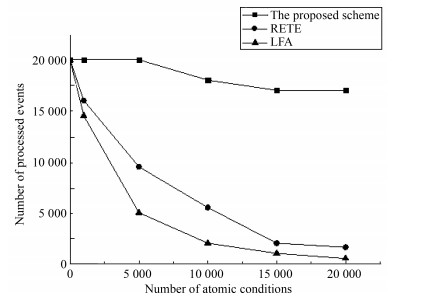
图 8 不同到达事件情况下性能对比图
Fig. 8 The performance comparison with difierent numbers of arrival events
-
[1] O'Neil P E. Model 204 architecture and performance. In: Proceedings of the 2nd International Workshop on High Performance Transaction Systems. London, UK: Springer, 1987. 40-59 [2] O'Neil P E, Quass D. Improved query performance with variant indexes. ACM SIGMOD Record, 1997, 26(2): 38-49 doi: 10.1145/253262 [3] van Schaik S J, de Moor O. A memory efficient reachability data structure through bit vector compression. In: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. Athens, Greece: ACM, 2011. 913-924 [4] Antoshenkov G. Byte-aligned bitmap compression. In: Proceedings of the 5th Data Compression Conference. Snowbird, UT, USA: IEEE, 1995. 476 [5] Wu K S, Otoo E J, Shoshani A. Optimizing bitmap indices with efficient compression. ACM Transactions on Database Systems (TODS), 2006, 31(1): 1-38 doi: 10.1145/1132863 [6] Deliége F, Pedersen T B. Position list word aligned hybrid: optimizing space and performance for compressed bitmaps. In: Proceedings of the 13th International Conference on Extending Database Technology. Lausanne, Switzerland: ACM, 2010. 228-239 [7] Fusco F, Stoecklin M P, Vlachos M. NET-FLi: on-the-fly compression, archiving and indexing of streaming network traffic. Proceedings of the VLDB Endowment, 2010, 3(1-2): 1382-1393 doi: 10.14778/1920841 [8] Kim S, Lee J, Satti S R, Moon B. SBH: super byte-aligned hybrid bitmap compression. Information Systems, 2016, 62: 155-168 doi: 10.1016/j.is.2016.07.004 [9] Wen Y H, Chen Z, Ma G, Cao J W, Zheng W X, Peng G D, Li S W, Huang W L. SECOMPAX: a bitmap index compression algorithm. In: Proceedings of the 23rd International Conference on Computer Communication and Networks (ICCCN). Shanghai, China: IEEE, 2014. 1-7 [10] Wen Y H, Wang H, Chen Z, Cao J W, Peng G D, Huang W L, Hu Z W, Zhou J, Guo J H. MASC: a bitmap index encoding algorithm for fast data retrieval. In: Proceedings of the 2016 IEEE International Conference on Communications (ICC). Kuala Lumpur, Malaysia: IEEE, 2016. 1-6 [11] 王飞跃.软件定义的系统与知识自动化:从牛顿到默顿的平行升华.自动化学报, 2015, 41(1): 1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtmlWang Fei-Yue. Software-defined systems and knowledge automation: a parallel paradigm shift from Newton to Merton. Acta Automatica Sinica, 2015, 41(1): 1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtml [12] 武丹凤, 曾广平, 闫京颖.支持演化规则引擎的rete算法研究.计算机应用研究, 2013, 30(6): 1747-1750 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ201306039.htmWu Dan-Feng, Zeng Guang-Ping, Yan Jing-Ying. Research on rete algorithm supporting evolution rules engine. Application Research of Computers, 2013, 30(6): 1747-1750 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ201306039.htm [13] Forgy C L. Rete: a fast algorithm for the many pattern/many object pattern match problem. Artificial Intelligence, 1982, 19(1): 17-37 doi: 10.1016/0004-3702(82)90020-0 [14] Hong Y G, Kim H J, Park H D, Kim D H. Adaptive GTS allocation scheme to support QoS and multiple devices in 802.15.4. In: Proceedings of the 11th International Conference on Advanced Communication Technology. Phoenix Park, Ireland: IEEE, 2009. 1697-1702 [15] 徐久强, 卢锁, 刘大鹏, 孔求实.基于改进Rete算法的RFID复合事件检测方法.东北大学学报(自然科学版), 2012, 33(6): 806-809, 814 http://cdmd.cnki.com.cn/Article/CDMD-10145-1015529793.htmXu Jiu-Qiang, Lu Suo, Liu Da-Peng, Kong Qiu-Shi. Research on RFID composite events detection based on improved rete algorithm. Journal of Northeastern University (Natural Science), 2012, 33(6): 806-809, 814 http://cdmd.cnki.com.cn/Article/CDMD-10145-1015529793.htm [16] Kawakami T, Yoshihisa T, Yanagisawa Y, Tsukamoto M. A rule processing scheme using the rete algorithm in grid topology networks. In: Proceedings of the 29th International Conference on Advanced Information Networking and Applications (AINA). Gwangju, Korea: IEEE, 2015. 674-679 [17] Kawakami T, Yoshihisa T, Tsukamoto M. A control method of ubiquitous computers using the RETE algorithm in grid topology network. In: Proceedings of the 3rd Global Conference on Consumer Electronics (GCCE). Tokyo, Japan: IEEE, 2014. 551-552 [18] Kawakami T, Yoshihisa T, Fujita N, Tsukamoto M. A rule-based home energy management system using the RETE algorithm. In: Proceedings of the 2nd Global Conference on Consumer Electronics (GCCE). Tokyo, Japan: IEEE, 2013. 162-163 [19] Kawakami T, Fujita N, Yoshihisa T, Tsukamoto M. An evaluation and implementation of rule-based home energy management system using the RETE algorithm. The Scientific World Journal, 2014, 2014: Article No. 591478 [20] Pallavi M S, Vaisakh P, Reshna N P. Implementation of rete algorithm using course finder system. In: Proceedings of the 2016 International Conference on Data Mining and Advanced Computing (SAPIENCE). Ernakulam, India: IEEE, 2016. 96-100 [21] Wu X D. LFA: a linear forward-chaining algorithm for AI production systems. Expert Systems, 1993, 10(4): 237-242 doi: 10.1111/exsy.1993.10.issue-4 [22] 冯建周, 宋沙沙, 孔令富.物联网语义关联和决策方法的研究.自动化学报, 2016, 42(11): 1691-1701 http://www.aas.net.cn/CN/abstract/abstract18958.shtmlFeng Jian-Zhou, Song Sha-Sha, Kong Ling-Fu. Research on semantic association and decision method of the internet of things. Acta Automatica Sinica, 2016, 42(11): 1691-1701 http://www.aas.net.cn/CN/abstract/abstract18958.shtml [23] 朱秀莉, 李龙, 李盼池.基于T-S推理网络的油田开发指标预测方法.计算机应用研究, 2011, 28(8): 2991-2993 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ201108054.htmZhu Xiu-Li, Li Long, Li Pan-Chi. Forecasting methods of oil field development indexes based on T-S reasoning networks. Application Research of Computers, 2011, 28(8): 2991-2993 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ201108054.htm -

 下载:
下载:


图(9)
计量
- 文章访问数: 2186
- HTML全文浏览量: 408
- PDF下载量: 624
- 被引次数: 0
