

-
摘要: 针对Biohashing指纹模板保护算法存在用户令牌泄露时识别性能严重退化的问题,提出了两种改进的Biohashing指纹模板保护算法.该算法在指纹数据预处理的基础上,采用可变的步长参数和滑动窗口产生固定大小的二值特征矩阵,减少了指纹数据特征值之间的关联性,离散化的非线性处理过程能够获得更大的密钥空间,有效提高了算法的安全性.理论分析和实验结果表明,改进算法具有更好的安全和识别性能.
-
关键词:
- Biohashing /
- 指纹模板 /
- 步长参数 /
- 滑动窗口 /
- 特征矩阵
Abstract: Aimed at the problem that the Biohashing fingerprint template protection algorithm seriously degenerates when user's token is leaked, two improved Biohashing fingerprint template protection algorithms are proposed. On the basis of the preprocessing of fingerprint data, the variable step size parameter and sliding window are used to generate a fixed binary feature matrix, which can reduce the correlation between the eigenvalues of fingerprint data. The discretized nonlinear process can obtain a larger key space, which can effectively improve the security of the algorithm. Theoretical analysis and experimental results show that the improved algorithms have better security and identification performance.-
Key words:
- Biohashing /
- fingerprint template /
- step parameter /
- sliding window /
- feature matrix
1) 本文责任编委 田捷 -

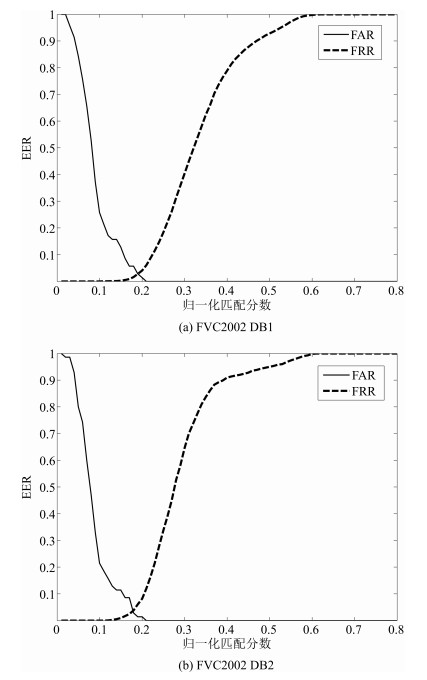
图 6 应用方法1的真假匹配汉明距离分布情况
Fig. 6 The distribution of Hamming distance about the match for true-false with the first method
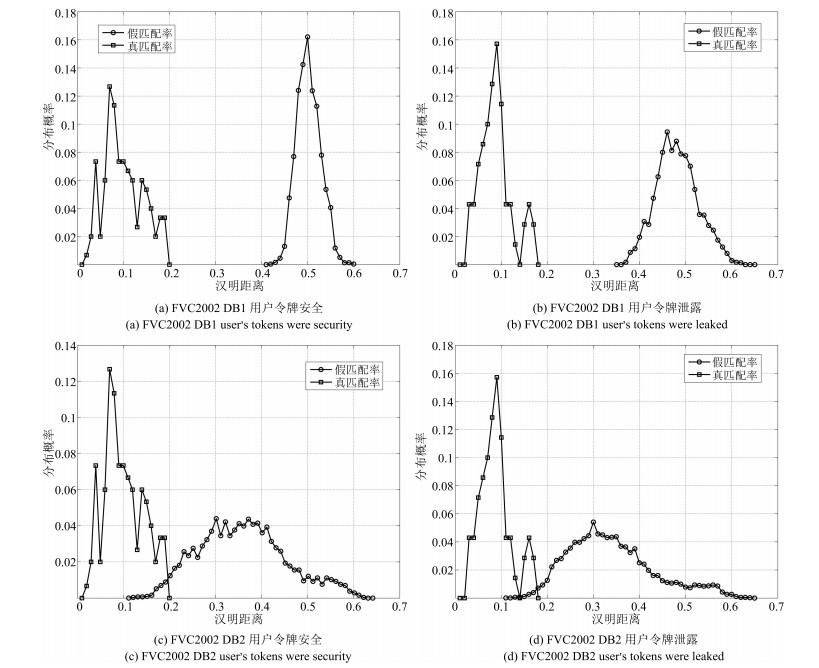
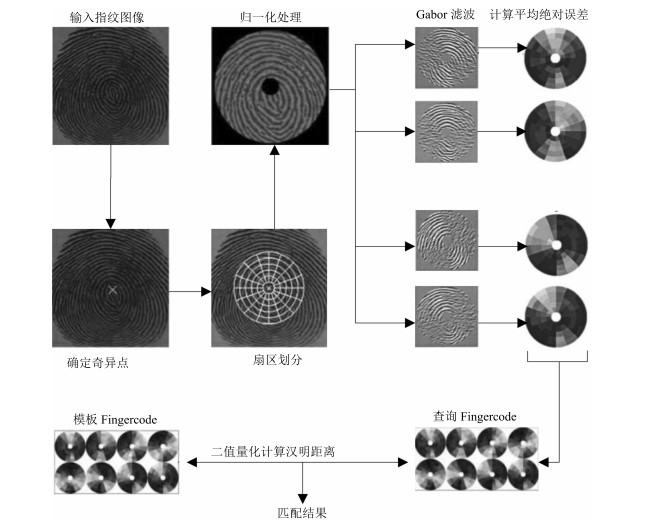
图 7 应用方法2的真假匹配汉明距离分布情况
Fig. 7 The distribution of Hamming distance about the match for true-false with the second method
表 1 应用方法1的BioCode码计算结果
Table 1 The results of BioCode calculations with the first method
指纹 BioCode码 指纹1 E1D2 BFED 5D33 C43B C57D 4C51 DC0E F29D 5B14 33B1 3872 68E7 03B5 0455 E91F F47C 5998 F273 4CE6 3C4C 4CD8 1E73 CF53 1127 631D 8E1E 162F 9C3F 1ECC 3BDA 88B9 2822 指纹2 E1C7 AFEB DC23 C439 C6A8 FF91 FE0C 70AD 19D4 23D1 B872 70EF 03B5 5C31 E915 E018 E1F8 62E3 5EE3 146E 4CB8 1E73 2D5D D054 66DF 8A32 1C6E 1C2F 3ECC BB9B 9CF0 62AE 指纹3 E1C7 AF0E 79DE F0AF 8B3A BE01 FC47 5FC0 3F2C 33BC 051C 827F 80A7 3502 F046 68CA B78C 79C2 E6E2 A5DD 6C46 7187 18C1 FD61 E352 A2A1 DB9D 5EA9 113A AD53 1C31 B1C6 指纹4 E1F6 3FCE 3F23 DC87 CC7F 8479 CE41 7F1D CB9E 23B8 0DF2 76E7 01F7 04C5 8F81 7D5E F999 E370 ACF3 9C46 1C9C 9A72 2F53 B563 F19D 8B3E 2E58 9C2B 6A8C BB99 A8F0 E3A6 指纹5 E1D2 8AA9 DC3B E039 C660 FE83 FC0C F0A9 53D5 3AF1 1523 E077 03BC 4611 F81C E118 C3D0 CEC7 5CE6 306C 4E38 1E30 AF11 D071 639F 8E37 1E3F 3C27 1EC4 BB83 8AF1 FA84  下载: 导出CSV
下载: 导出CSV
表 2 应用方法2的BioCode码计算结果
Table 2 The results of BioCode calculations with the second method
指纹 BioCode码 指纹1 FD67 AAF1 5F72 8CD7 C86F 84DC 9B82 580B B077 78A5 1F42 EEE9 5232 55DD BBBA 661D 8857 E4F9 09CA 2C45 D802 8912 EFB0 6736 6C0E CBEC 11D9 3657 08DB 9639 BD21 476E 指纹2 FFA6 66CE E1F4 0CEC 9933 08C5 1992 3754 FA82 6644 DCD5 2FE8 8993 3365 539A 22E4 DB9A D766 CC99 9AF2 1F13 1626 66EA 910C64E8 9927 54C5 92F2 351B 8650 6383 445E 指纹3 FBEF EAFC 1774 8CE3 993F 84DD 9910 7C08 FB06 748C 9FF0 6EE8 99B3 957D 03BA 46F4 FA17 622E 69CB 5E45 9933 BA26 6EE6 6342 4D1C 9BA4 45FC 734F 118B B031 BD23 4458 指纹4 FDE6 2BFC 5FDC 8337 E92F D026 AC45 DE02 2799 A790 7739 AB22 02F7 B57D 60CC 98DB F81F C515 638A E811 7D46 5BCA 48E4 9999 0B76 B1EE 013F 445D D2B8 263F B266 17B8 指纹5 FB6F 6EE8 1772 8C55 D933 8594 9913 780E FB26 24CC 9DE2 6EC8 99BB 157D 1BB2 66AC F817 C26C 48CB 1E05 9813 AB35 6EF2 6326 5DCB 8BA2 49EC 34C7 39CB 9670 AC23 6452
下载: 导出CSV
-
[1] 张宁, 臧亚丽, 田捷.生物特征与密码技术的融合——一种新的安全身份认证方案.密码学报, 2015, 2(2):159-176 http://www.cqvip.com/QK/72050X/201502/77778866504849534850484854.htmlZhang Ning, Zang Ya-Li, Tian Jie. The integration of biometrics and cryptography——a new solution for secure identity authentication. Journal of Cryptologic Research, 2015, 2(2):159-176 http://www.cqvip.com/QK/72050X/201502/77778866504849534850484854.html [2] 许秋旺, 张雪锋.基于细节点邻域信息的可撤销指纹模板生成算法.自动化学报, 2017, 43(4):645-652 http://www.aas.net.cn/CN/abstract/abstract19042.shtmlXu Qiu-Wang, Zhang Xue-Feng. Generating cancelable fingerprint templates using minutiae local information. Acta Automatica Sinica, 2017, 43(4):645-652 http://www.aas.net.cn/CN/abstract/abstract19042.shtml [3] Cao K, Jain A K. Learning fingerprint reconstruction:from minutiae to image. IEEE Transactions on Information Forensics and Security, 2015, 10(1):104-117 doi: 10.1109/TIFS.2014.2363951 [4] Davida G I, Frankel Y, Matt B J. On enabling secure applications through off-line biometric identification. In: Proceedings of the 1998 IEEE Symposium on Security and Privacy. Oakland, USA: IEEE, 1998. 148-157 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=674831 [5] Juels A, Wattenberg M. A fuzzy commitment scheme. In: Proceedings of the 6th ACM Conference on Computer and Communications Security. Kent Ridge Digital Labs, Singapore: ACM, 1999. 28-36 [6] Feng H, Anderson R, Daugman J. Combining crypto with biometrics effectively. IEEE Transactions on Computers, 2006, 55(9):1081-1088 doi: 10.1109/TC.2006.138 [7] Hartato B P, Adji T B, Bejo A. A review of chaff point generation methods for fuzzy vault scheme. In: Proceedings of the 2016 International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE). Yogyakarta, Indonesia: IEEE, 2016. 180-185 [8] You L, Yang L, Yu W K, Wu Z D. A cancelable fuzzy vault algorithm based on transformed fingerprint features. Chinese Journal of Electronics, 2017, 26(2):236-243 doi: 10.1049/cje.2017.01.009 [9] Ratha N K, Connell J H, Bolle R M. Enhancing security and privacy in biometrics-based authentication systems. IBM Systems Journal, 2001, 40(3):614-634 http://www.researchgate.net/publication/220353130_Enhancing_security_and_privacy_in_biometrics-based_authentication_systems?ev=pub_cit [10] Ratha N K, Chikkerur S, Connell J H, Bolle R M. Generating cancelable fingerprint templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(4):561-572 doi: 10.1109/TPAMI.2007.1004 [11] Lee C, Choi J Y, Toh K A, Lee S. Alignment-free cancelable fingerprint templates based on local minutiae information. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2007, 37(4):980-992 doi: 10.1109/TSMCB.2007.896999 [12] Ang R, Safavi-Naini R, McAven L. Cancelable key-based fingerprint templates. Information Security and Privacy. ACISP 2005. Lecture Notes in Computer Science. Berlin, Heidelberg, Germany: Springer, 2005. 242-252 [13] Jin A T B, Ling D N C, Goh A. Biohashing:two factor authentication featuring fingerprint data and tokenised random number. Pattern Recognition, 2004, 37(11):2245-2255 doi: 10.1016/j.patcog.2004.04.011 [14] Kong A, Cheung K H, Zhang D, Kamel M, You J. An analysis of Biohashing and its variants. Pattern Recognition, 2006, 39(7):1359-1368 doi: 10.1016/j.patcog.2005.10.025 [15] Jin A T B, Ling D N C, Song O T. An efficient fingerprint verification system using integrated wavelet and Fourier-Mellin invariant transform. Image and Vision Computing, 2004, 22(6):503-513 doi: 10.1016/j.imavis.2003.12.002 [16] Moon D, Yoo J H, Lee M K. Improved cancelable fingerprint templates using minutiae-based functional transform. Security and Communication Networks, 2014, 7(10):1543-1551 https://dl.acm.org/citation.cfm?id=2904939 [17] Liu Y X, Hatzinakos D. BioHashing for human acoustic signature based on random projection. Canadian Journal of Electrical and Computer Engineering, 2015, 38(3):266-273 doi: 10.1109/CJECE.2015.2416200 [18] Meetei T C, Begum S A. A variant of cancelable iris biometric based on BioHashing. In: Proceedings of the 2016 International Conference on Signal and Information Processing (IConSIP). Vishnupuri, India: IEEE, 2016. 1-5 [19] 郭静, 徐江峰.一种基于BioHashing和洗牌算法的可撤销密钥绑定方案.计算机应用研究, 2014, 31(5):1511-1515 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyyyj201405055Guo Jing, Xu Jiang-Feng. Cancellable key binding scheme based on BioHashing and shuffling algorithm. Application Research of Computers, 2014, 31(5):1511-1515 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyyyj201405055 [20] Liu E Y, Liang J M, Pang L J, Xie M, Tian J. Minutiae and modified Biocode fusion for fingerprint-based key generation. Journal of Network and Computer Applications, 2010, 33(3):221-235 doi: 10.1016/j.jnca.2009.12.002 [21] Maio D, Maltoni D, Cappelli R, Wayman J L, Jain A K. FVC2002: second fingerprint verification competition. In: Proceedings of the 16th International Conference on Pattern Recognition. Quebec City, Canada: IEEE, 2002, 3: 811-814 -

 下载:
下载:




计量
- 文章访问数: 2275
- HTML全文浏览量: 248
- PDF下载量: 672
- 被引次数: 0
