

-
摘要: 在说话人识别中,有效的识别方法是核心.近年来,基于总变化因子分析(i-vector)方法成为了说话人识别领域的主流,其中总变化因子空间的估计是整个算法的关键.本文结合常规的因子分析方法提出一种新的总变化因子空间估计算法,即通用背景—联合估计(Universal background-joint estimation algorithm,UB-JE)算法.首先,根据高斯混合—通用背景模型(Gaussian mixture model-universal background model,GMM-UBM)思想提出总变化矩阵通用背景(UB)算法;其次,根据因子分析理论结合相关文献提出了一种总变化矩阵联合估计(JE)算法;最后,将两种算法相结合得到通用背景—联合估计(UB-JE)算法.采用TIMIT和MDSVC语音数据库,结合i-vector方法将所提的算法与传统算法进行对比实验.结果显示,等错误率(Equal error rate,EER)和最小检测代价函数(Minimum detection cost function,MinDCF)分别提升了8.3%与6.9%,所提方法能够提升i-vector方法的性能.
-
关键词:
- 总变化因子分析 /
- 总变化因子空间 /
- 通用背景—联合估计算法 /
- 说话人识别
Abstract: In the speaker recognition, the effective identification method is the core. In recent years, i-vector method has become the mainstream in the field of speaker recognition, and estimation of the total variation factor space is the key of whole algorithm. In this paper, we propose a new algorithm for total variation factor space estimation named UB-JE, which is combined with conventional factor analysis method. Firstly, the universal background algorithm of total variation matrix is proposed according to Gaussian mixture model-universal background model (GMM-UBM). Secondly, the joint estimation algorithm of total variation matrix is proposed according to the factor analysis theory and related works. Finally, the two algorithms are combined to get the universal background-joint estimation algorithm (UB-JE). TIMIT and MDSVC corpus are adopted in the experiment to compare the proposed algorithm with the traditional algorithm. Experimental results show that the equal error rate (EER) and the minimum detection cost function (MinDCF) are improved by 8.3% and 6.9%, respectively. The proposed method can improve the performance of i-vector method. -
语音是人们用来交流和沟通的最自然、最直接的方式之一, 因此, 语音是一种重要的生物特征.作为一种重要的身份鉴定技术, 目前说话人识别[1-2]已广泛运用于国家安全、司法鉴定、电话银行及门禁安全等领域.与此同时, 说话人识别仍有许多问题需要解决, 例如信道多样化的识别、噪声对识别性能的影响等, 这就涉及到对说话人识别算法的研究.
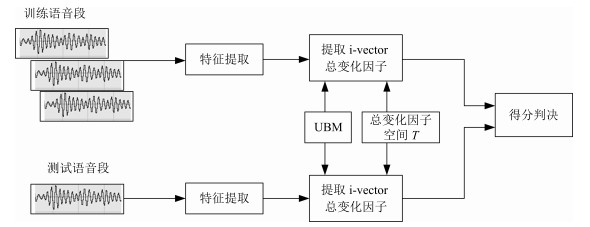
2000年左右, Reynolds等[3]提出的高斯混合模型-通用背景模型(Gaussian mixture model-universal background model, GMM-UBM), 以其特有的良好性能和灵活的模型结构, 降低了说话人模型对训练集的依赖, 迅速成为当时说话人识别领域的主流方法之一, 推动了整个领域的发展[4-5].由GMM-UBM的思想可知, 在高斯混合函数的均值超向量(Gaussian mixture model supervector, GSV)中包含有说话人语句的所有信息.根据该思想, Kenny等[6-7]提出了联合因子分析方法(Joint factor analysis, JFA), 认为说话人语句中包含说话人信息和信道信息两部分, 因此, GSV又可被分解为说话人和信道两部分. Dehak [8]研究发现, 在对JFA进行信道补偿时, 信道空间存在掩盖和重叠问题, 信道空间中不可避免地包含了一部分说话人的信息, 即不能准确地对说话人与信道分别建模.在此基础上, Dehak等[9-11]提出了i-vector方法, 该方法认为对GSV进行处理时不应该区分说话人和信道, 而应该把它们看成一个整体, 即总变化空间.但是, 在总变化空间中存在信道失配问题, Dehak等[9]又提出了一些信道补偿技术:线性鉴别分析(Linear discriminant analysis, LDA)和类内协方差规整(Within class covariance normalization, WCCN)等.近几年来, 基于i-vector方法的说话人识别模型(图 1)明显提升了说话人识别系统的性能, 是目前说话人识别领域中最热门的建模方法之一[12-13].在美国国家标准技术局组织的说话人评测(The National Institute of Standards and Technology speaker recognition evaluation, NIST SRE)中, 该方法的性能明显优于GMM-UBM [3]和GSV-SVM (Gaussian mixture model supervector-support vector machine) [14-15]等方法, 是处于国际研究前沿的一种说话人识别方法.
i-vector是一种有效的因子分析方法, 其中总变化因子空间的估计是基础和关键.为了得到性能更好的i-vector方法, 本文结合常规的因子分析方法提出了一种新的总变化因子空间估计算法, 即通用背景-联合估计(Universal background-joint estimation algorithm, UB-JE)算法.首先, 针对说话人识别任务中正负样本分布不平衡问题, 本文借鉴GMM-UBM的思想, 结合i-vector方法, 通过大量的非训练数据来训练形成一个包含大量说话人的通用背景初始总变化空间, 从而提出了总变化矩阵通用背景(Universal background, UB)算法; 其次, 在i-vector模型中由于均值不能很好地与更新后的总变化因子空间耦合, 我们根据因子分析理论结合文献[16-17]提出了一种总变化矩阵联合估计(Joint estimation, JE)算法; 最后, 将两种算法相结合得到通用背景-联合估计(UB-JE)算法.
本文结构如下:第1节介绍了因子分析方法的理论, 主要是高斯混合模型超向量、联合因子分析方法和总变化因子分析方法; 第2节提出通用背景-联合估计总变化矩阵估计算法, 包含两种总变化因子空间估计算法, 即通用背景算法和联合估计算法; 第3节是针对提出的三种总变化因子空间估计算法的实验与结果分析; 第4节是结论.
1. 因子分析方法理论
1.1 高斯混合模型超向量
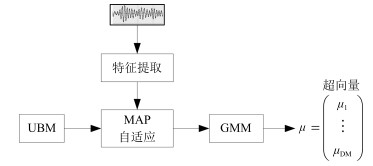
由于GMM-UBM [3]是先用一些无关数据训练一个通用背景模型(Universal background model, UBM), 然后利用训练数据对该UBM进行数据更新, 得到代表单个说话人的高斯混合模型(Gaussian mixture model, GMM).按照GMM-UBM模型的原理, 说话人所有的语音信息都包含在由说话人GSV [14-15]中(GSV形成过程见图 2).一般情况下, 在说话人识别领域里常用的超向量是均值超向量, 因此, 下文中的超向量如果没有特别指明, 均默认为均值超向量.
1.2 联合因子分析方法
随着科技的发展, 语音可以通过多种渠道获取, 在说话人识别任务中相应地产生了信道失配问题. Kenny等[6-7]认为一段语音信号中应包含说话人信息和信道信息两部分, 因此对说话人进行识别时, GSV应该被分解为说话人和信道两部分, 分别对它们建立模型, 然后去除无关信息(信道模型), 留下有用信息(说话人模型), 然后再进行估计, 这就是JFA的思想.
根据Kenny提出的JFA思路, 假设有一个混合度为$C$的GMM-UBM模型, 训练时的语音特征参数为$F$维, 则形成一个$FC$维的均值超向量, 则该超向量可表示为
$ m_{s, h} =m_{u} +Ux_{s, h} +Vy_{s} +Dz_{s} $
(1) 其中, $m_{s, h} $为特定说话人$s$的第$h$段语音所形成的$FC\times 1$维的GSV, $m_{u} $是$FC\times 1$维的UBM超矢量, $U$表示信道空间, 是一$FC\times R_{u} $维矩阵, 其中$R_{u} $为信道因子数, $V$表示说话人空间, 是一$FC$ $\times$ $R_{v} $维矩阵, $R_{v} $是说话人因子数, $D$是残差空间, 是一个$FC\times FC$维的对角矩阵, $x_{s, h} $表示信道因子, $y_{s} $表示说话人$s$的因子, $z_{s} $是残差因子.一般来说, $10 < R_{u} < 200$, $100 < R_{v} < 400$.
由式(1)可知, 在JFA中需要对$m_{u} $, $U$, $V$以及$D$进行预先估计, 由于$m_{u} $已预先得到, 因此只需要估计其他三个矩阵, 即$\lambda =\left({U, V, D} \right)$.关于这三个矩阵的估计参见文献[16].
1.3 总变化因子分析方法
由于JFA存在空间掩盖和空间重叠问题[8], 不能很好地区分说话人和信道. Dehak等提出了i-vector [9-10], i-vector把说话人和信道看成一个整体, 根据JFA可把i-vector表示为
$ s=m+Tw+\varepsilon $
(2) 其中, $s$为特定说话人GSV, $m$为UBM超矢量, $T$表示总变化因子空间, 迭代更新时, 先随机初始化, $w$为总变化因子, 即i-vector, $\varepsilon $为残差.
$ w\sim {\rm N}\left( {{\rm \boldsymbol{0}}, I} \right)\notag \\ \varepsilon \sim {\rm N}\left( {{\boldsymbol{0}}, \Sigma} \right) $
(3) 其中, $\Sigma$为对角协方差矩阵, 可用UBM协方差代替.
由式(2)可知, i-vector的建模可简化为对模型参数$\lambda =({s, m, T, \Sigma })$的估计, 由上述理论可知, 训练数据的$s$, $m$很容易得到, 因此, 可简化为对$\lambda=$ $(T, \Sigma)$的估计.其中最关键的是对总变化因子空间$T$的估计, $T$的估计类似于JFA中说话人空间估计, 可以采用最大期望(EM)算法得到, 参见文献[9].步骤如下:
步骤1.估计统计量.一段语音特征参数为$x_{s, t} $, UBM超矢量为$m$, 则
$ N_{c, s} =\sum\limits_t {\gamma_{c, s, t} } $
(4) $ F_{c, s} =\sum\limits_t {\gamma_{c, s, t} \left( {x_{s, t} -m_{c} } \right)} $
(5) $ S_{c, s} = {\rm diag}\left\{ {\sum\limits_t {\gamma_{c, s, t} } \left( {x_{s, t} -m_{c} } \right)\left( {x_{s, t} -m_{c} } \right)^{{\rm T}}} \right\} $
(6) 其中, $N_{c, s} $为零阶统计量, $F_{c, s} $为一阶统计量, $S_{c, s} $为二阶统计量, $m_{c} $为$m$中的第$c$个分量, $\gamma_{c, s, t} $为第$c$个高斯密度函数后验概率.
步骤2. (E步)计算总变化因子$w$的一阶统计量和二阶统计量.
$ L_{s} =I+T^{{\rm T}}\Sigma^{-1}N_{s} T $
(7) $ {\rm E}\left[{w_{s} } \right]=L_{s}^{-1}T^{{\rm T}}\Sigma^{-1}F_{s} $
(8) $ {\rm E}\left[{w_{s} w_{s}^{{\rm T}}} \right]={\rm E}\left[{w_{s} } \right]{\rm E}\left[{w_{s}^{{\rm T}}} \right]+L_{s}^{-1} $
(9) 其中, $L_{s} $为临时中间变量, ${\rm E}[{w_{s} }]$, ${\rm E}[{w_{s} w_{s}^{{\rm T}}}]$为$w$的一阶统计量(需要的结果)和二阶统计量, $N_{s} $为$N_{c, s} $的对角拼接$FC\times FC$维矩阵, $F_{s} $为$F_{c, s} $拼接的$FC$维矢量, $\Sigma$为UBM协方差.
步骤3. (M步)更新$T$和$\Sigma$.
$T$更新:
$ \sum\limits_s {N_{s} T} {\rm E}\left[{w_{s} w_{s}^{{\rm T}}} \right]=\sum\limits_s {F_{s} } {\rm E}\left[{w_{s} } \right] $
(10) $\Sigma$更新:
$ \begin{align} \Sigma=&\ N^{-1}\sum\limits_s S_{s} -\\&\ N^{-1}{\rm diag}\left\{ {\sum\limits_s {F_{s} } {\rm E}\left[{w_{s}^{{\rm T}}} \right]T^{{\rm T}}} \right\} \end{align} $
(11) 其中, $S_{s} $为$S_{c, s} $拼接的$FC\times FC$维矩阵, $N=\sum\nolimits_c {N_{s} } $为所有说话人零阶统计量之和. (当反复迭代几次后, 就可得到收敛的$T$和$\Sigma$).
2. 总变化因子空间通用背景-联合估计算法
在i-vector中$T$的估计是关键和基础, 由上一节可知, $T$是通过随机初始化然后通过迭代产生的, 但并没有考虑到通用背景的情况.本文根据GMM-UBM的思想, 先通过背景无关数据产生一个初始化的$T_{\rm ubm} $, 然后再进行迭代更新, 提出了一种总变化因子空间通用背景算法.在常规的i-vector算法中, 用均值最大化算法(Expectation maximum, EM)对数据更新时, 仅仅考虑到$T$和$\Sigma $, 而没有对$m$进行更新.为了使得i-vector能够有更好的结合性, 本文又提出了一种同时更新$m$和$T$的联合估计算法.在本节最后, 我们把上述两种算法相结合, 提出通用背景-联合估计算法.
2.1 通用背景算法(UB)
首先, 利用大量的无关数据训练一个UBM超向量, 并根据i-vector中$T$估计方法估计一通用背景变化空间$T_{\rm ubm} $.然后, 将$T_{\rm ubm} $作为EM算法中对$T$估计的初始矩阵, 进行自适应计算(如图 3所示).具体如下:
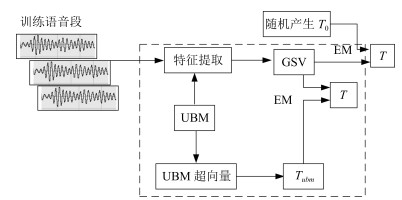 图 3 总变化因子的常规估计算法和UB算法(虚线框)比较Fig. 3 Comparison of conventional estimation algorithm of total variation factor with UB (dashed frame)
图 3 总变化因子的常规估计算法和UB算法(虚线框)比较Fig. 3 Comparison of conventional estimation algorithm of total variation factor with UB (dashed frame)步骤1.通过前端处理将大量的无关数据训练成一个UBM超向量, 并结合第1.3节中$T$的估计算法, 生成一个通用背景下的总变化空间, 记为$T_{\rm ubm} $.
步骤2.将$T_{\rm ubm} $代入式(7), 生成$L_{s} $.
步骤3.将$L_{s} $代入式(8)和式(9)生成${\rm E}[{w_{s} }]$和${\rm E}[{w_{s} w_{s}^{{\rm T}}}]$.
步骤4.结合$T_{\rm ubm} $, ${\rm E}[{w_{s} }]$以及${\rm E}[{w_{s} w_{s} ^{{\rm T}}}]$, 根据第1.3节中的EM算法, 依次对$T$和$\Sigma$进行更新.
步骤5.观察$T$和$\Sigma$是否收敛或者达到迭代次数.如果没有, 则返回步骤2继续; 否则退出.
2.2 联合估计算法(JE)
由第1.3节可知, i-vector的建模可转化为对$\lambda$ $=$ $({s, m, T, \Sigma})$的估计.其中, $s$与$m$已预先估计好了, 即GSV和UBM超矢量, 因此, 只更新$\lambda=$ $(T$, $\Sigma)$.事实上, 在更新$T$和的$\Sigma $的同时, 也应该更新$m$, 即$\lambda =({m, T, \Sigma})$, 只有这样, 不断更新的参数模型才会更加耦合.
本文提出一种$m$, $T$联合估计算法, 即
$ T_{1} =\left[{T \;\;m} \right] $
(12) 把$T$和$m$看成一个整体, 在更新$T$的同时, 也更新$m$.此时, i-vector模型表示为$\lambda_{1} =({T_{1}, \Sigma})$, 根据式(2)可写为
$ s=T_{1} w_{1} +\varepsilon $
(13) 其中, $s$为GSV, $w_{1} =\left[{w^{{\rm T}}{\kern 1pt}{\kern 1pt}{\kern 1pt}{\kern 1pt}{\kern 1pt}{\kern 1pt}{\kern 1pt}1} \right]^{{\rm T}}$, 称为联合变化因子, $T$称为联合变化空间, $\varepsilon $为残差.
$ w_{1} \sim {\rm N}\left( {{\rm \boldsymbol{0}}, I} \right)\notag \\ \varepsilon \sim {\rm N}\left( {{\rm \boldsymbol{0}}, \Sigma} \right) $
(14) 根据第1.3节中i-vector中的EM更新算法可得:
步骤1. (E步)
$ J_{s} =I+T_{1}^{{\rm T}}\Sigma^{-1}N_{s} T $
(15) $ {\rm E}\left[{w_{1s} } \right]=J_{s}^{-1}T_{1}^{{\rm T}}\Sigma^{-1}F_{s} $
(16) $ {\rm E}\left[{w_{1s} w_{1s}^{{\rm T}}} \right]={\rm E}\left[ {w_{1s} } \right]{\rm E}\left[{w_{1s}^{{\rm T}}} \right]+J_{s}^{-1} $
(17) 步骤2. (M步)
对$T_{1} $更新:
$ \sum\limits_s {N_{s} T_{1} } {\rm E}\left[{w_{1s} w_{1s}^{{\rm T}}} \right]=\sum\limits_s {F_{s} } {\rm E}\left[{w_{1s} } \right] $
(18) 对$\Sigma$更新:
$ \begin{align} \Sigma=&\ N^{-1}\sum\limits_s S_{s} -\\ &\ N^{-1}{\rm diag}\left\{ {\sum\limits_s {F_{s} } {\rm E}\left[ {w_{1s}^{{\rm T}}} \right]T_{1}^{{\rm T}}} \right\} \end{align} $
(19) 对$T_{1} $的更新就是对$T$和$m$同时更新.
2.3 通用背景-联合估计算法(UB-JE)
基于上述两种算法, 本文将它们相结合形成互补, 提出了一种新的算法, 即UB-JE (如图 4所示).具体如下:
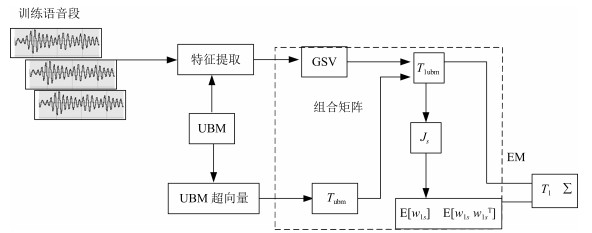 图 4 通用背景-联合估计算法(虚线框)Fig. 4 Diagram of universal background-joint estimation algorithm (dashed frame)
图 4 通用背景-联合估计算法(虚线框)Fig. 4 Diagram of universal background-joint estimation algorithm (dashed frame)步骤1.通过大量无关数据得到UBM超向量, 集合JE算法中$T_{1} $的估计算法, 得到通用背景-联合总变化空间$T_{\rm 1ubm} $.
步骤2.将$T_{\rm 1ubm} $代入式(15), 生成$J_{s} $.
步骤3.将$J_{s} $代入式(16)和式(17), 生成${\rm E}\left[{w_{1s} } \right]$和${\rm E}\left[{w_{1s} w_{1s}^{{\rm T}}} \right]$.
步骤4.结合$T_{\rm 1ubm} $, ${\rm E}\left[{w_{1s} } \right]$以及${\rm E}\left[{w_{1s} w_{1s} ^{{\rm T}}} \right]$, 根据JE算法中的EM算法, 依次对$T_{1} $和$\Sigma$进行更新.
步骤5.观察$T_{1} $和$\Sigma$是否收敛或者达到迭代次数.如果没有, 则返回步骤2继续; 否则退出.
3. 实验与分析
3.1 实验设置
实验的测试数据采用TIMIT语音库[18]、MDS- VC语音库[19]以及一组由MDSVC语音库组成的长时语音数据.实验在预处理阶段包括:有效语音端点检测(短时能量与平均过零率相结合的方法)、预加重(因子为0.95)、分帧(帧长25 ms, 帧移12.5 ms)和加窗.实验采用39维美尔倒谱系数(Mel frequency cepstral coefficients, MFCC)特征参数(基本特征包括1维能量和12维倒谱、13维一阶差分特征以及13维二阶差分特征).实验中, UBM混合数为512, 密度函数方差采用对角矩阵.在i-vector训练中, 总变化因子空间维数设置为400, 训练时迭代次数取6次.
运用5 300句TIMIT语音(女性1 620句语音, 男性3 680句语音)、MDSVC中Enroll_Session1 + Enroll_Session2以及用HTK工具[20]对MDSVC语音数据组合长句(48Enroll_Session1 + 48Enroll_Session2 + 40Imposter共136长句)分别训练UBM模型和T.实验训练数据为100人(30个女性, 70个男性, 每人9句语音) TIMIT语音、MDSVC中Imposter (23个文件的男性和17个文件的女性中各50句)以及MDSVC中部分数据(30个文件的男性和30个文件的女性中各50句); 测试数据为TIMIT中100人(30个女性, 70个男性, 每人1句语音)、MDSVC Imposter (23个文件的男性和17个文件的女性中的剩余4句)以及MDSVC中部分数据(30个文件的男性和30个文件的女性中各4句) (详见表 1).本文设置了一个基线实验(GMM-UBM) [3]来验证因子分析方法(i-vector)的有效性.
表 1 实验所用语音库Table 1 The corpus used in the experiment类型 TIMIT MDSVC MDSVC长句 male female male female UBM 3 860 1 620 2 808 2376 136 T 3 860 1 620 2 808 2 376 136 训练GSV 630 270 1 150 850 1 500 1 500 测试 70 30 92 68 120 120 3.2 评价指标
本文采用等错误率(Equal error rate, EER)和2010年的NIST SRE中的最小检测代价函数(Minimum detection cost function 2010, Min- DCF10) [21]作为性能评测指标. MinDCF10与EER越小说明系统的性能越好.
检测代价函数计算公式为
$ \begin{align} C_{\det } =&\ C_{\rm Miss} \times P_{\rm Miss|Target} \times P_{\rm Target} + \notag\\ &\ C_{\rm FalseAlarm} \times P_{\rm FalseAlarm|NonTarget} \times\notag\\ &\ \left( {1-P_{\rm Target} } \right) \end{align} $
(20) 其中, $C_{\rm Miss} $和$C_{\rm FalseAlarm} $分别为漏警和虚警的代价; $P_{\rm Miss|Target} $和$P_{\rm FalseAlarm|NonTarget} $分别为给定门限$\theta $情况下的漏警率和虚警率. $P_{\rm Target} $为目标实验的先验概率, 参数设定见表 2.当$P_{\rm Miss|Target} = P_{\rm FalseAlarm |NonTarget} $时, $EER=C_{\det } $.
表 2 MinDCF10参数设定Table 2 MinDCF10 parameter setting$C_{\rm Miss} $ $C_{\rm FalseAlarm} $ $P_{\rm Target} $ 1 1 0.001 3.3 实验设计与结果分析
为了验证所提算法的有效性, 本文基于两种不同的语音库设置了四个实验:实验1基于TIMIT语音库; 实验2基于MDSVC语音库; 实验3是在两者综合的语音库中完成的; 实验4基于MDSVC语音库组成的长时语音数据.每一个实验做6次比较试验, 即基线实验(GMM-UBM) [3]、本文提出的三个新算法、总变化矩阵传统算法以及文献[22]中i-vector矢量规整PLDA技术.由于不同语音库的录音条件、方式等不同, 四个实验分别代表了四种不同的实验环境. 表 3~6分别给出在不同语音库上各算法训练$T$后的系统性能比较.表中括号里的是性能提升值.
表 3 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在TIMIT语音库上的性能对比Table 3 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on TIMIT corpora算法 EER (%) MinDCF10 GMM-UBM 6.26 0.076 传统算法估计$T$ 4.76 0.025 通用背景估计$T$ 4.28 0.021 联合估计$T$ 4.01 0.020 通用背景-联合估计$T$ 3.76 (21 %) 0.019 (24 %) PLDA 3.94 0.022 表 4 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在MDSVC语音库上的性能对比Table 4 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on MDSVC corpora算法 EER (%) MinDCF10 GMM-UBM 7.57 0.072 传统算法估计$T$ 4.96 0.027 通用背景估计$T$ 4.92 0.026 联合估计$T$ 4.71 0.024 通用背景-联合估计$T$ 4.67 (5.8 %) 0.023 (14.8 %) PLDA 4.67 0.024 表 5 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在TIMIT + MDSVC语音库上的性能对比Table 5 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on TIMIT mixed MDSVC corpora算法 EER (%) MinDCF10 GMM-UBM 8.33 0.071 传统算法估计$T$ 5.41 0.029 通用背景估计$T$ 5.19 0.028 联合估计$T$ 5.11 0.028 通用背景-联合估计$T$ 4.96 (8.3 %) 0.027 (6.9 %) PLDA 5.01 0.025 表 6 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在MDSVC长句语音库上的性能对比Table 6 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on MDSVC long sentence corpora算法 EER (%) MinDCF10 GMM-UBM 6.58 0.067 传统算法估计$T$ 4.45 0.022 通用背景估计$T$ 3.96 0.021 联合估计$T$ 3.73 0.021 通用背景-联合估计$T$ 3.72 (16.40 %) 0.020 (9.09 %) PLDA 3.88 0.021 为了更加直观地观察实验结果, 本文分别作了图 5和图 6. 图 5是在不同语音库中各个算法的性能比较(表 3~6的内容), 图 6是不同算法在四种语音库中的性能比较(包含表 7).
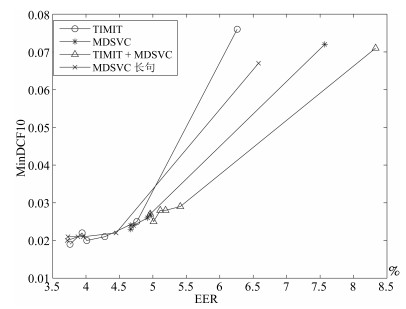 图 5 不同语音库中各算法性能对比Fig. 5 Performance comparison of algorithms on different speech corpus
图 5 不同语音库中各算法性能对比Fig. 5 Performance comparison of algorithms on different speech corpus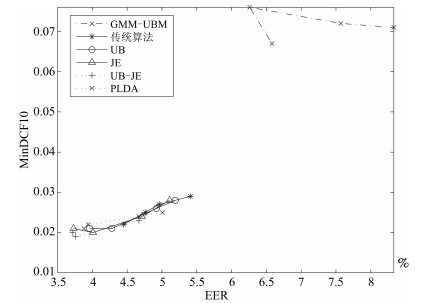 图 6 不同算法在四种语音库中的性能对比Fig. 6 Performance comparison of different algorithms on four speech corpus表 7 通用背景-联合估计算法在不同语音库中的性能对比Table 7 Performance comparison of universal background-joint estimation algorithm on different speech corpus
图 6 不同算法在四种语音库中的性能对比Fig. 6 Performance comparison of different algorithms on four speech corpus表 7 通用背景-联合估计算法在不同语音库中的性能对比Table 7 Performance comparison of universal background-joint estimation algorithm on different speech corpus语音库 EER (%) MinDCF10 TIMIT 3.76 0.019 MDSVC 4.67 0.023 TIMIT + MDSVC 4.96 0.027 MDSVC长句 3.72 0.020 从以上图表可以看出, 在TIMIT数据集、MDSVC数据集、TIMIT + MDSVC综合集或MDSVC长句集上, 1)因子分析方法相较于基线系统(GMM-UBM)性能都有显著提升. 2)新提出算法的性能都有一定提升, 特别是通用背景-联合估计算法的性能在TIMIT中提升了较为明显, EER和MinDCF10分别提升21 %和24 %.同时, 在实验环境更加复杂的综合集TIMIT + MDSVC上性能也有一定提升, EER和MinDCF10分别提升了8.3 %和6.9 %.通过每单个实验的对比发现, 联合估计算法的性能要一致性的优于通用背景算法, 两者结合的算法(通用背景-联合估计)可以得到更优的系统. 3)相比于文献[22]中i-vector矢量规整PLDA技术, 本文提出的算法(UB-JE)在不同语音数据库中, 性能有一定的提升.
但是对比表 3~6的数据可知, 表 6中算法的性能最好, 其次是表 3, 然后是表 4, 最后才到表 5 (从表 7和图 6可以看出), 这是由于长时语音相对短时语音更能准确地代表说话人信息以及随着语音数据复杂程度的提高, 系统的性能受到一定的影响.现阶段说话人识别领域一个热门方向就是针对语音数据复杂程度展开的, 即多信道下的说话人识别, 这是说话人识别发展的一个趋势.
4. 结论
本文主要研究了说话人识别算法i-vector中总变化因子空间$T$的估计, 提出了四种$T$估计算法.实验结果显示, 在三种语音库中, 新提出的三种算法对系统的性能都有一定的提升(如图 5), 且不同语音库对每一种算法的性能都有一定的影响(如图 6).实验结果证明有效估计$T$对整个i-vector模型起着至关重要的作用, 验证了前面i-vector理论分析, $T$的估计引领着整个模型.语音库的选择对整个系统的性能有一定影响, 下一步将在更加复杂的语音库(如NIST SRE语音库)上进行评测实验.
-
图 3 总变化因子的常规估计算法和UB算法(虚线框)比较
Fig. 3 Comparison of conventional estimation algorithm of total variation factor with UB (dashed frame)
图 4 通用背景-联合估计算法(虚线框)
Fig. 4 Diagram of universal background-joint estimation algorithm (dashed frame)
图 5 不同语音库中各算法性能对比
Fig. 5 Performance comparison of algorithms on different speech corpus
图 6 不同算法在四种语音库中的性能对比
Fig. 6 Performance comparison of different algorithms on four speech corpus
表 1 实验所用语音库
Table 1 The corpus used in the experiment
类型 TIMIT MDSVC MDSVC长句 male female male female UBM 3 860 1 620 2 808 2376 136 T 3 860 1 620 2 808 2 376 136 训练GSV 630 270 1 150 850 1 500 1 500 测试 70 30 92 68 120 120  下载: 导出CSV
下载: 导出CSV
表 2 MinDCF10参数设定
Table 2 MinDCF10 parameter setting
$C_{\rm Miss} $ $C_{\rm FalseAlarm} $ $P_{\rm Target} $ 1 1 0.001
下载: 导出CSV
表 3 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在TIMIT语音库上的性能对比
Table 3 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on TIMIT corpora
算法 EER (%) MinDCF10 GMM-UBM 6.26 0.076 传统算法估计$T$ 4.76 0.025 通用背景估计$T$ 4.28 0.021 联合估计$T$ 4.01 0.020 通用背景-联合估计$T$ 3.76 (21 %) 0.019 (24 %) PLDA 3.94 0.022
下载: 导出CSV
表 4 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在MDSVC语音库上的性能对比
Table 4 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on MDSVC corpora
算法 EER (%) MinDCF10 GMM-UBM 7.57 0.072 传统算法估计$T$ 4.96 0.027 通用背景估计$T$ 4.92 0.026 联合估计$T$ 4.71 0.024 通用背景-联合估计$T$ 4.67 (5.8 %) 0.023 (14.8 %) PLDA 4.67 0.024
下载: 导出CSV
表 5 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在TIMIT + MDSVC语音库上的性能对比
Table 5 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on TIMIT mixed MDSVC corpora
算法 EER (%) MinDCF10 GMM-UBM 8.33 0.071 传统算法估计$T$ 5.41 0.029 通用背景估计$T$ 5.19 0.028 联合估计$T$ 5.11 0.028 通用背景-联合估计$T$ 4.96 (8.3 %) 0.027 (6.9 %) PLDA 5.01 0.025
下载: 导出CSV
表 6 GMM-UBM、传统算法估计$T$、本文所提出算法估计$T$以及PLDA在MDSVC长句语音库上的性能对比
Table 6 Performance comparison of GMM-UBM, the traditional algorithm to estimate $T$, the proposed algorithms to estimate $T$, and the PLDA on MDSVC long sentence corpora
算法 EER (%) MinDCF10 GMM-UBM 6.58 0.067 传统算法估计$T$ 4.45 0.022 通用背景估计$T$ 3.96 0.021 联合估计$T$ 3.73 0.021 通用背景-联合估计$T$ 3.72 (16.40 %) 0.020 (9.09 %) PLDA 3.88 0.021
下载: 导出CSV
表 7 通用背景-联合估计算法在不同语音库中的性能对比
Table 7 Performance comparison of universal background-joint estimation algorithm on different speech corpus
语音库 EER (%) MinDCF10 TIMIT 3.76 0.019 MDSVC 4.67 0.023 TIMIT + MDSVC 4.96 0.027 MDSVC长句 3.72 0.020
下载: 导出CSV
-
[1] Reynolds D A. An overview of automatic speaker recognition technology. In: Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Orlando, FL, USA: IEEE, 2002. IV-4072-IV-4075 [2] Kinnunen T, Li H Z. An overview of text-independent speaker recognition:from features to supervectors. Speech Communication, 2010, 52(1):12-40 doi: 10.1016/j.specom.2009.08.009 [3] Reynolds D A, Quatieri T F, Dunn R B. Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 2000, 10(1-3):19-41 doi: 10.1006/dspr.1999.0361 [4] Cumani S, Laface P. Large-scale training of pairwise support vector machines for speaker recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(11):1590-1600 doi: 10.1109/TASLP.2014.2341914 [5] Yessad D, Amrouche A. SVM based GMM supervector speaker recognition using LP residual signal. In: Proceedings of the 2012 International Conference on Image and Signal Processing. Agadir, Morocco: Springer, 2012. 579-586 [6] Kenny P, Boulianne G, Ouellet P, Dumouchel P. Speaker and session variability in gmm-based speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(4):1448-1460 doi: 10.1109/TASL.2007.894527 [7] Kenny P, Boulianne G, Ouellet P, Dumouchel P. Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(4):1435-1447 doi: 10.1109/TASL.2006.881693 [8] Dehak N. Discriminative and Generative Approaches for Long-and Short-Term Speaker Characteristics Modeling: Application to Speaker Verification[Ph. D. dissertation], École de Technologie Supérieure, Montreal, QC, Canada, 2009. [9] Dehak N, Kenny P J, Dehak R, Dumouchel P, Ouellet P. Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):788-798 doi: 10.1109/TASL.2010.2064307 [10] Dehak N, Dehak R, Kenny P, Brummer N, Ouellet P, Dumouchel P. Support vector machines versus fast scoring in the low-dimensional total variability space for speaker verification. In: Proceedings of the 10th Annual Conference of the International Speech Communication Association. Brighton, UK: DBLP, 2009. 1559-1562 [11] Cumani S, Laface P. I-vector transformation and scaling for PLDA based speaker recognition. In: Proceedings of the 2016 Odyssey Speaker and Language Recognition Workshop. Bilbao, Spain: IEEE, 2016. 39-46 [12] Rouvier M, Bousquet P M, Ajili M, Kheder W B, Matrouf D, Bonastre J F. LIA system description for NIST SRE 2016. In: Proceedings of the 2016 International Speech Communication Association. San Francisco, USA: Elsevier, 2016. [13] Xu Y, McLoughlin I, Song Y, Wu K. Improved i-vector representation for speaker diarization. Circuits, Systems, and Signal Processing, 2016, 35(9):3393-3404 doi: 10.1007/s00034-015-0206-2 [14] Fine S, Navratil J, Gopinath R A. Enhancing GMM scores using SVM "hints". In: Proceedings of the 7th European Conference on Speech Communication and Technology. Aalborg, Denmark: DBLP, 2001. 1757-1760 [15] Campbell W M, Sturim D E, Reynolds D A. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Processing Letters, 2006, 13(5):308-311 doi: 10.1109/LSP.2006.870086 [16] 何亮, 史永哲, 刘加.联合因子分析中的本征信道空间拼接方法.自动化学报, 2011, 37(7):849-856 http://www.aas.net.cn/CN/abstract/abstract17496.shtmlHe Liang, Shi Yong-Zhe, Liu Jia. Eigenchannel space combination method of joint factor analysis. Acta Automatica Sinica, 2011, 37(7):849-856 http://www.aas.net.cn/CN/abstract/abstract17496.shtml [17] 郭武, 李轶杰, 戴礼荣, 王仁华.说话人识别中的因子分析以及空间拼接.自动化学报, 2009, 35(9):1193-1198 http://www.aas.net.cn/CN/abstract/abstract13565.shtmlGuo Wu, Li Yi-Jie, Dai Li-Rong, Wang Ren-Hua. Factor analysis and space assembling in speaker recognition. Acta Automatica Sinica, 2009, 35(9):1193-1198 http://www.aas.net.cn/CN/abstract/abstract13565.shtml [18] Jankowski C, Kalyanswamy A, Basson S, Spitz J. NTIMIT: a phonetically balanced, continuous speech, telephone bandwidth speech database. In: Proceedings of the 1990 International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Albuquerque, NM, USA: IEEE, 1990, 1: 109-122 [19] Woo R H, Park A, Hazen T J. The MIT mobile device speaker verification corpus: data collection and preliminary experiments. In: Proceedings of the 2016 IEEE Odyssey: the Speaker and Language Recognition Workshop. San Juan, Puerto Rico: IEEE, 2006. 1-6 [20] Young S, Evermann G, Gales M, Hain T, Liu X Y, Moore G, Odell J, Ollason D, Povey D, Valtchev V, Woodland P. The HTK Book (for HTK Version 3. 4). Cambridge: Cambridge University Engineering Department, 2006. [21] NIST Speaker Recognition Evaluation[Online], available: http://www.itl.nist.gov/iad/mig/tests/sre/2010/index.html, April 21, 2010 [22] Chen L P, Lee K A, Ma B, Li H Z, Dai L R. Adaptation of PLDA for multi-source text-independent speaker verification. In: Proceedings of the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). New Orleans, USA: IEEE, 2017. 5380-5384 期刊类型引用(5)
1. 邓飞,邓力洪,胡文艺,张葛祥,杨强. 说话人身份识别深度网络中的聚合模型研究. 计算机应用研究. 2022(03): 721-725 .  百度学术
百度学术2. 李燕萍,曹盼,左宇涛,张燕,钱博. 基于i向量和变分自编码相对生成对抗网络的语音转换. 自动化学报. 2022(07): 1824-1833 . 本站查看3. 杨明亮,龙华,邵玉斌,杜庆治. 基于i-vector全局参数联合的说话人识别. 重庆邮电大学学报(自然科学版). 2021(01): 144-151 . 百度学术4. 陈晨,肜娅峰,季超群,陈德运,何勇军. 基于深层信息散度最大化的说话人确认方法. 通信学报. 2021(07): 231-237 . 百度学术5. 罗春梅. 基于改进MFCC与RCNN的说话人识别算法. 数学的实践与认识. 2021(17): 102-110 . 百度学术其他类型引用(3)
-

 下载:
下载:
计量
- 文章访问数: 1831
- HTML全文浏览量: 283
- PDF下载量: 647
- 被引次数: 8
