

Algorithm for Resource-constrained Project Scheduling Problem With Resource Transfer Time
-
摘要: 现有项目调度问题的研究一般假设资源在任务间转移不需要时间,但这一假设与很多实际情况不相符,本文在资源受限项目调度问题(Resource-constrained project scheduling problem,RCPSP)中引入资源转移时间,以最小化项目工期为目标,建立了考虑资源转移时间的资源受限项目调度问题的数学模型.为改善遗传算法在局部搜索能力方面的不足,提出将分支定界法与遗传算法相结合,构造了一种内嵌分支定界寻优搜索的遗传算法,在保证算法全局搜索能力的前提下提升局部精确搜索能力.同时,对于遗传算法,为了适应算法结构提出了一种基于任务绝对顺序的编码策略.数据实验表明,对于小规模问题可获得近似精确解,对于大规模问题相较现有文献所提算法,在算法求解精度上可提升10%.
-
关键词:
- 项目调度 /
- 资源受限 /
- 资源转移时间 /
- 内嵌分支定界的遗传算法
Abstract: Most studies in the literature so far assume that resources can be transferred from one job to the other without any expense of time. However, in many practical cases, it takes time for resources to transfer from one job to another. In this paper, we introduce the resource-constrained project scheduling problem (RCPSP) considering resource transfer time, which aims at minimizing the makespan of the project. A linear model is established and a branch-and-bound embedded genetic algorithm is proposed. A new precedence-based coding method which adapts to the structure of the problem is also proposed. Comparative computational results reveal that the branch-and-bound embedded genetic algorithm improves about 10% in terms of solution accuracy compared with the algorithm proposed in the literature.1) 本文责任编委 王红卫 -
表 1 不同参数设置下的实验结果对比
Table 1 Comparison of experimental results under different parameter settings
算例规模 平均值偏差(%) $pc=0.8$ $pc=0.6$ $pc=0.6$ $pc=0.8$ $pm=0.2$ $pm=0.2$ $pm=0.1$ $pm=0.1$ J30 0.89 0.99 1.44 0.00 J60 1.11 0.00 0.08 0.13 J90 0.66 0.00 0.13 0.24 平均 0.87 0.33 0.55 0.12  下载: 导出CSV
下载: 导出CSV
表 2 不同算法求解小规模算例的实验结果对比
Table 2 Comparison of different algorithms in small-to-medium size problems
算例规模 组别 CPLEX 无分支定界的遗传算法 内嵌分支定界的遗传算法 上界均值 下界均值 时间均值(s) 均值 时间均值(s) GAP (%) 均值 时间均值(s) GAP (%) J10 1 34.9 34.9 86.00 35.8 1.44 2.52 35.2 17.85 0.74 2 23.4 23.4 19.01 24.8 1.30 5.98 23.6 25.97 0.85 3 37.9 37.9 102.35 38.4 1.31 1.32 38.1 16.14 0.53 平均 69.12 1.35 3.27 19.99 0.71 J12 1 62.1 60.6 4 035.60 64.1 1.72 3.22 62.7 20.46 0.97 2 41.3 39.3 3 233.42 42.3 1.74 2.42 41.7 19.10 0.97 3 27.1 27.1 30.69 28.1 1.68 3.69 27.3 24.25 0.74 平均 2 429.90 1.71 3.11 21.27 0.89 J14 1 62.8 49.0 5 898.80 64.2 2.17 2.23 61.7 35.70 -1.75 2 32.1 30.2 2 335.54 33.4 2.21 4.05 32.5 39.12 1.25 3 47.1 46.2 950.73 48.6 2.67 3.18 47.7 39.73 1.27 平均 3 061.69 2.35 3.15 38.18 0.26 J16 1 78.7 53.6 7 200.00 77.7 2.33 -1.27 75.7 44.38 -3.81 2 39.8 30.1 6 484.84 43.6 3.08 9.55 42.4 41.76 6.53 3 59.9 46.1 6 509.60 61.5 2.70 2.67 59.8 56.31 -0.17 平均 6 731.48 2.70 3.65 47.48 0.85 J20 1 49.4 28.8 7 200.00 48.3 3.12 -2.23 46.9 59.68 -5.06 2 64.4 41.0 7 200.00 63.0 3.23 -2.17 61.1 59.80 -5.12 3 68.1 46.0 7 200.00 67.8 3.09 -0.44 65.6 72.30 -3.67 平均 7 200.00 3.15 -1.61 63.93 -4.62
下载: 导出CSV
表 3 不同算法求解大规模算例的实验结果对比
Table 3 Comparison of different algorithms in large size problems
算例规模 组别 启发式算法 无分支定界的遗传算法 内嵌分支定界的遗传算法 LFT均值 GAP (%) SLACK均值 GAP (%) 均值 时间均值(s) GAP (%) 均值 时间均值(s) GAP (%) J30 1 159.0 14.80 156.9 13.29 140.7 5.69 1.59 138.5 63.65 0.00 2 157.6 16.65 161.9 19.84 136.7 6.27 1.18 135.1 77.20 0.00 3 120.1 12.77 119.3 12.02 109.1 6.22 2.44 106.5 117.81 0.00 平均 14.74 15.05 6.06 1.74 86.22 0.00 J60 1 217.0 12.55 216.0 12.03 196.7 24.14 2.02 192.8 744.97 0.00 2 152.4 11.00 151.0 9.98 140.4 26.58 2.26 137.3 777.18 0.00 3 115.8 8.22 114.9 7.38 109.2 25.77 2.06 107.0 798.22 0.00 平均 10.59 9.80 25.50 2.11 773.46 0.00 J90 1 383.8 11.05 386.3 11.78 351.4 68.89 1.68 345.6 1 191.98 0.00 2 199.2 9.15 198.8 8.93 186.8 68.18 2.36 182.5 1 952.75 0.00 3 520.9 14.38 515.9 13.29 462.6 71.57 1.58 455.4 1 755.12 0.00 平均 11.53 11.33 69.55 1.87 1 633.28 0.00
下载: 导出CSV
-
[1] Brucker P, Knust S, Schoo A, Thiele O. A branch and bound algorithm for the resource-constrained project scheduling problem. European Journal of Operational Research, 1998, 107(2):272-288 doi: 10.1016/S0377-2217(97)00335-4 [2] Dorndorf U, Pesch E, Phan-Huy T. A branch-and-bound algorithm for the resource-constrained project scheduling problem. Mathematical Methods of Operations Research, 2000, 52(3):413-439 doi: 10.1007/s001860000091 [3] Klein R. Bidirectional planning:improving priority rule-based heuristics for scheduling resource-constrained projects. European Journal of Operational Research, 2000, 127(3):619-638 doi: 10.1016/S0377-2217(99)00347-1 [4] Buddhakulsomsiri J, Kim D S. Priority rule-based heuristic for multi-mode resource-constrained project scheduling problems with resource vacations and activity splitting. European Journal of Operational Research, 2007, 178(2):374-390 doi: 10.1016/j.ejor.2006.02.010 [5] Valls V, Ballestín F, Quintanilla S. A hybrid genetic algorithm for the resource-constrained project scheduling problem. European Journal of Operational Research, 2008, 185(2):495-508 doi: 10.1016/j.ejor.2006.12.033 [6] Peteghem V, Vanhoucke M. A genetic algorithm for the preemptive and non-preemptive multi-mode resource-constrained project scheduling problem. European Journal of Operational Research, 2010, 201(2):409-418 doi: 10.1016/j.ejor.2009.03.034 [7] Cho J, Kim Y. A simulated annealing algorithm for resource constrained project scheduling problems. Journal of the Operational Research Society, 1997, 48(7):736-744 doi: 10.1057/palgrave.jors.2600416 [8] Krüger D, Scholl A. A heuristic solution framework for the resource constrained (multi-)project scheduling problem with sequence-dependent transfer times. European Journal of Operational Research, 2009, 197(2):492-508 doi: 10.1016/j.ejor.2008.07.036 [9] Krüger D, Scholl A. Managing and modelling general resource transfers in (multi-)project scheduling. OR Spectrum, 2010, 32(2):369-394 doi: 10.1007/s00291-008-0144-5 [10] 宗砚, 刘琼, 张超勇, 朱海平.考虑资源传递时间的多项目调度问题.计算机集成制造系统, 2011, 17(9):1921-1928 http://www.cnki.com.cn/Article/CJFDTotal-HNCG201503032.htmZong Yan, Liu Qiong, Zhang Chao-Yong, Zhu Hai-Ping. Multi-project scheduling problem with resource transfer time. Computer Integrated Manufacturing Systems, 2011, 17(9):1921-1928 http://www.cnki.com.cn/Article/CJFDTotal-HNCG201503032.htm [11] Kolisch R, Sprecher A. PSPLIB——A project scheduling problem library:OR Software-ORSEP Operations Research Software Exchange Program. European Journal of Operational Research, 1996, 96(1):205-216 http://cn.bing.com/academic/profile?id=bed96a8f24c0e94f44eb2d09f21eb077&encoded=0&v=paper_preview&mkt=zh-cn -

 下载:
下载:
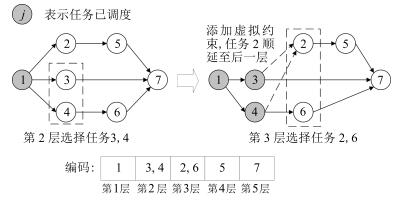




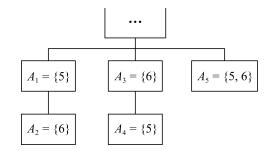


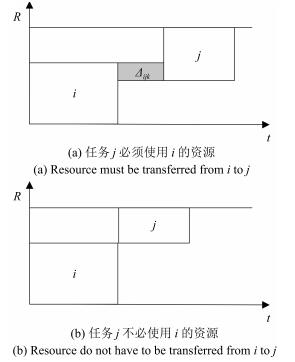

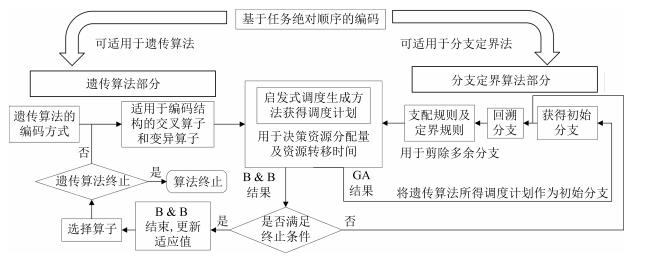
图(10) / 表(3)
计量
- 文章访问数: 2932
- HTML全文浏览量: 297
- PDF下载量: 521
- 被引次数: 0
