

A Multivariate Decision Tree for Big Data Classification of Distributed Data Streams
-
摘要: 分布式数据流大数据中的类别边界不规则且易变,因此基于单变量决策树的集成分类器需要较大数量的基分类器才能准确地近似表达类别边界,这将降低集成分类器的学习与分类性能.因而,本文提出了基于几何轮廓相似度的多变量决策树.在最优基准向量的引导下将n维空间样本点投影到一维空间以建立有序投影点集合,然后通过类别投影边界将有序投影点集合划分为多个子集,接着分别对不同类别集合的交集递归投影分裂,最终生成决策树.实验表明,本文提出的多变量决策树GODT具有很高的分类精度和较低的训练时间,有效结合了单变量决策树学习效率高与多变量决策树表示能力强的优点.Abstract: Considering the irregularity and variability of the class boundaries of distributed big data streams, when the univariate decision tree is used as the base classifier in an ensemble classifier, large amounts of base classifiers are needed to accurately approximate class boundaries. This will reduce the learning and classification performance of ensemble classifiers. This article proposes a multivariate decision tree based on geometric outline similarity (GODT). Firstly, by using the optimal reference vector, the n-dimensional data points are projected onto the one-dimensional space, thus a set of ordered projection points are established. Secondly, the set of projection points are divided into several subsets, and the intersections of different subsets are projected and divided by recursive projecting and splitting. Finally, a decision tree is built. Experimental results show that GODT has a better classification accuracy and requires less training time. It combines the high learning efficiency of univariate decision tree algorithm with the strong representation power of multivariate decision tree.
-
Key words:
- Distributed data streams /
- big data /
- classification /
- outline similarity /
- multivariate decision tree
1) 本文责任编委 张敏灵 -
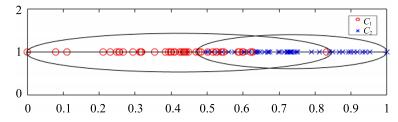
图 1 投影点集合$P_1 $与$P_2 $的位置关系
Fig. 1 The position relationship of projection point sets $P_1 $ and $P_2 $
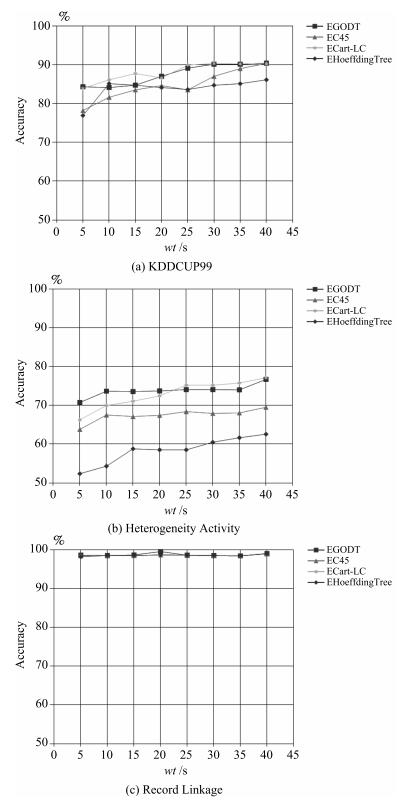
图 3 分类精度随滑动窗口大小的变化情况
Fig. 3 The variation of classification accuracy with the sliding window size

图 4 $wt=5$时, 分类精度在整个挖掘序列的变化情况
Fig. 4 The variation of classification accuracy in the mining sequence when $wt=5$
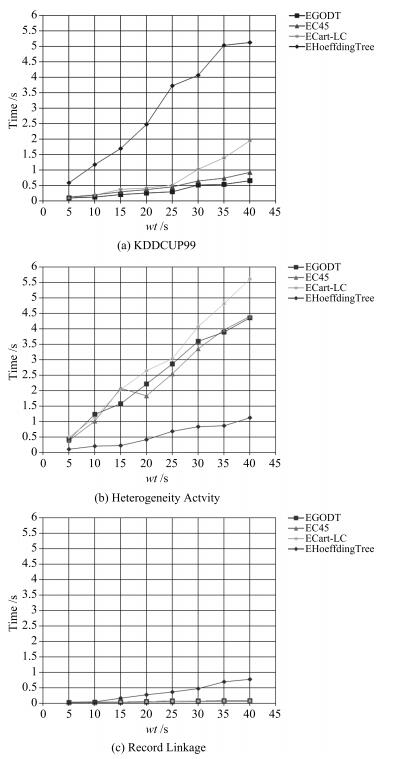
图 5 训练时间随滑动窗口大小的变化情况
Fig. 5 The variation of training time with the sliding window size
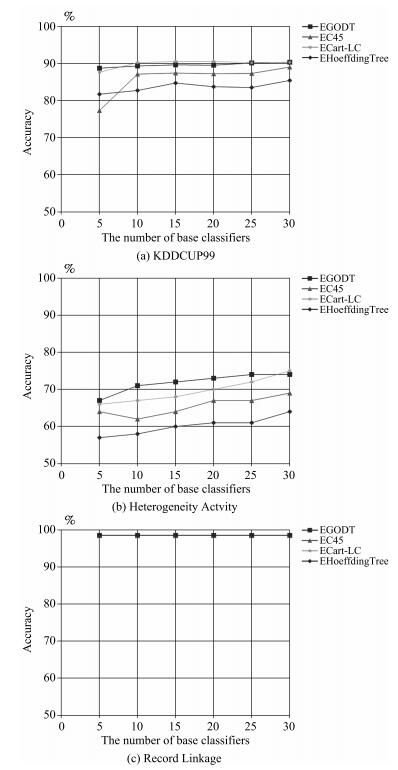
图 6 分类精度随基分类器数量的变化情况
Fig. 6 The variation of classification accuracy with the number of base classifiers
表 1 数据集
Table 1 Dataset
Dataset Number of attributes Type of attributes Size Number of class KDDCUP99 42 Nominal, Numeric 5 209 460 23 Record Linkage 12 Numeric 4 587 620 2 Heterogeneity Activity 7 Numeric 13 062 475 7  下载: 导出CSV
下载: 导出CSV
表 2 EGODT的基分类器间的不合度量
Table 2 The disagreement measure between base classifiers of EGODT
GODT $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.43 0.52 0.55 0.51 0.41 0.43 0.43 0.41 0.48 $c$2 0 0.51 0.46 0.6 0.32 0.29 0.39 0.29 0.6 $c$3 0 0.24 0.24 0.56 0.6 0.56 0.6 0.52 $c$4 0 0.35 0.66 0.56 0.67 0.55 0.73 $c$5 0 0.53 0.64 0.52 0.57 0.58 $c$6 0 0.41 0.19 0.13 0.37 $c$7 0 0.12 0.19 0.68 $c$8 0 0.2 0.64 $c$9 0 0.6 $c$10 0
下载: 导出CSV
表 3 EC45的基分类器间的不合度量
Table 3 The disagreement measure between base classifiers of EC45
C4.5 $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.31 0.44 0.44 0.35 0.3 0.31 0.31 0.29 0.35 $c$2 0 0.48 0.48 0.53 0.11 0.09 0.09 0.09 0.53 $c$3 0 0.02 0.53 0.55 0.53 0.52 0.51 0.55 $c$4 0 0.52 0.55 0.53 0.53 0.53 0.54 $c$5 0 0.48 0.51 0.53 0.49 0.04 $c$6 0 0.08 0.09 0.07 0.47 $c$7 0 0.02 0.07 0.53 $c$8 0 0.08 0.54 $c$9 0 0.49 $c$10 0
下载: 导出CSV
表 4 ECart-LC的基分类器间的不合度量
Table 4 The disagreement measure between base classifiers of ECart-LC
Cart-LC $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.39 0.31 0.31 0.3 0.37 0.46 0.46 0.32 0.32 $c$2 0 0.22 0.22 0.36 0.57 0.48 0.47 0.48 0.6 $c$3 0 0 0.15 0.61 0.5 0.5 0.5 0.5 $c$4 0 0.15 0.61 0.5 0.5 0.5 0.5 $c$5 0 0.46 0.52 0.52 0.39 0.39 $c$6 0 0.57 0.57 0.2 0.16 $c$7 0 0 0.38 0.5 $c$8 0 0.38 0.5 $c$9 0 0.12 $c$10 0
下载: 导出CSV
表 5 EHoeffdingTree的基分类器间的不合度量
Table 5 The disagreement measure between base classifiers of EHoeffdingTree
HoeffdingTree $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.26 0.53 0.54 0.38 0.3 0.36 0.31 0.24 0.47 $c$2 0 0.42 0.47 0.2 0.18 0.12 0.16 0.1 0.32 $c$3 0 0.45 0.45 0.43 0.58 0.58 0.46 0.45 $c$4 0 0.52 0.44 0.45 0.5 0.47 0.51 $c$5 0 0.54 0.57 0.56 0.58 0.07 $c$6 0 0.08 0.15 0.14 0.51 $c$7 0 0.19 0.12 0.58 $c$8 0 0.25 0.57 $c$9 0 0.56 $c$10 0
下载: 导出CSV
-
[1] 朱群, 张玉红, 胡学钢, 李培培.一种基于双层窗口的概念漂移数据流分类算法.自动化学报, 2011, 37(9):1077-1084 doi: 10.3724/SP.J.1004.2011.01077Zhu Qun, Zhang Yu-Hong, Hu Xue-Gang, Li Pei-Pei. A double-window-based classification algorithm for concept drifting data streams. Acta Automatica Sinica, 2011, 37(9):1077-1084 doi: 10.3724/SP.J.1004.2011.01077 [2] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):97-107 doi: 10.1109/TKDE.2013.109 [3] 孙大为, 张广艳, 郑纬民.大数据流式计算:关键技术及系统实例.软件学报, 2014, 25(4):839-862 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201404011.htmSun Da-Wei, Zhang Guang-Yan, Zheng Wei-Min. Big data stream computing:technologies and instances. Journal of Software, 2014, 25(4):839-862 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201404011.htm [4] Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 1997, 55(1):119-139 doi: 10.1006/jcss.1997.1504 [5] Breiman L. Bagging predictors. Machine Learning, 1996, 24(2):123-140 [6] Zhang P, Zhou C, Wang P, Gao B J, Zhu X Q, Guo L. E-tree:an efficient indexing structure for ensemble models on data streams. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(2):461-474 doi: 10.1109/TKDE.2014.2298018 [7] Blaser R, Fryzlewicz P. Random rotation ensembles. Journal of Machine Learning Research, 2016, 17(4):1-26 [8] Street W N, Kim Y. A streaming ensemble algorithm (SEA) for large-scale classification. In: Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: ACM, 2001. 377-382 [9] Bifet A, Holmes G, Pfahringer B, Kirkby R, Gavaldá R. New ensemble methods for evolving data streams. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France: ACM, 2009. 139-148 [10] Polat K, Güneş. A novel hybrid intelligent method based on C4.5 decision tree classifier and one-against-all approach for multi-class classification problems. Expert Systems with Applications, 2009, 36(2):1587-1592 doi: 10.1016/j.eswa.2007.11.051 [11] Wozniak M. A hybrid decision tree training method using data streams. Knowledge and Information Systems, 2011, 29(2):335-347 doi: 10.1007/s10115-010-0345-5 [12] Abdulsalam H, Skillicorn D B, Martin P. Classification using streaming random forests. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(1):22-36 [13] Bifet A, Frank E, Holmes G, Pfahringer B. Ensembles of restricted hoeffding trees. ACM Transactions on Intelligent Systems and Technology (TIST), 2012, 3(2):Article No. 30 [14] Ahmad A, Brown G. Random projection random discretization ensembles-ensembles of linear multivariate decision trees. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5):1225-1239 doi: 10.1109/TKDE.2013.134 [15] 毛国君, 胡殿军, 谢松燕.基于分布式数据流的大数据分类模型和算法.计算机学报, 2017, 40(1):161-175 doi: 10.11897/SP.J.1016.2017.00161Mao Guo-Jun, Hu Dian-Jun, Xie Song-Yan. Models and algorithms for classifying big data based on distributed data streams. Chinese Journal of Computers, 2017, 40(1):161-175 doi: 10.11897/SP.J.1016.2017.00161 [16] Quinlan J R. Induction of decision trees. Machine Learning, 1986, 1(1):81-106 [17] Quinlan J R. C4. 5: Programs for Machine Learning. San Mateo, CA, USA: Morgan Kaufmann, 1993. [18] Breiman L, Friedman J H, Olshen R A, Stone C J. Classification and Regression Trees. Belmont, CA, USA:CRC Press, 1984. [19] Brodley C E, Utgoff P E. Multivariate decision trees. Machine Learning, 1995, 19(1):45-77 [20] Ferri C, Flach P A, Hernández-Orallo J. Improving the AUC of probabilistic estimation trees. In: Proceedings of the 2003 European Conference on Machine Learning. Berlin, Heidelberg, Germany: Springer, 2003. 121-132 [21] Mingers J. An empirical comparison of pruning methods for decision tree induction. Machine Learning, 1989, 4(2):227-243 doi: 10.1023/A:1022604100933 [22] Esposito F, Malerba D, Semeraro G, Kay J. A comparative analysis of methods for pruning decision trees. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(5):476-491 [23] Fournier D, Crémilleux B. A quality index for decision tree pruning. Knowledge-Based Systems, 2002, 15(1-2):37-43 doi: 10.1016/S0950-7051(01)00119-8 [24] Osei-Bryson K M. Post-pruning in decision tree induction using multiple performance measures. Computers and Operations Research, 2007, 34(11):3331-3345 [25] Elomaa T, Kääriäinen M. An analysis of reduced error pruning. Journal of Artificial Intelligence Research, 2001, 15(1):163-187 [26] Quinlan J R. Simplifying decision trees. International Journal of Man-Machine Studies, 1987, 27(3):221-234 doi: 10.1016/S0020-7373(87)80053-6 [27] 包研科, 赵凤华.多标度数据轮廓相似性的度量公理与计算.辽宁工程技术大学学报(自然科学版), 2012, 31(5):797-800 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=lngcjsdxxb201205053Bao Yan-Ke, Zhao Feng-Hua. Measure axiom of outline similarity of multi-scale data and its calculation. Journal of Liaoning Technical University (Natural Science), 2012, 31(5):797-800 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=lngcjsdxxb201205053 [28] Bache K, Lichman M. UCI machine learning repository[Online], available: http://archive.ics.uci.edu/ml, January 1, 2016 [29] Stisen A, Blunck H, Bhattacharya S, Prentow T S, Kjaergaard M B, Dey A, Sonne T, Jensen M M. Smart devices are different: assessing and mitigating mobile sensing heterogeneities for activity recognition. In: Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems. Seoul, South Korea: ACM, 2015. 127-140 [30] Zhou Z H. Ensemble Methods: Foundations and Algorithms. Boca Raton, FL, USA: Chapman and Hall/CRC, 2012. -

 下载:
下载:


计量
- 文章访问数: 2634
- HTML全文浏览量: 499
- PDF下载量: 844
- 被引次数: 0
