

A Multivariate Decision Tree for Big Data Classification of Distributed Data Streams
-
摘要: 分布式数据流大数据中的类别边界不规则且易变,因此基于单变量决策树的集成分类器需要较大数量的基分类器才能准确地近似表达类别边界,这将降低集成分类器的学习与分类性能.因而,本文提出了基于几何轮廓相似度的多变量决策树.在最优基准向量的引导下将n维空间样本点投影到一维空间以建立有序投影点集合,然后通过类别投影边界将有序投影点集合划分为多个子集,接着分别对不同类别集合的交集递归投影分裂,最终生成决策树.实验表明,本文提出的多变量决策树GODT具有很高的分类精度和较低的训练时间,有效结合了单变量决策树学习效率高与多变量决策树表示能力强的优点.Abstract: Considering the irregularity and variability of the class boundaries of distributed big data streams, when the univariate decision tree is used as the base classifier in an ensemble classifier, large amounts of base classifiers are needed to accurately approximate class boundaries. This will reduce the learning and classification performance of ensemble classifiers. This article proposes a multivariate decision tree based on geometric outline similarity (GODT). Firstly, by using the optimal reference vector, the n-dimensional data points are projected onto the one-dimensional space, thus a set of ordered projection points are established. Secondly, the set of projection points are divided into several subsets, and the intersections of different subsets are projected and divided by recursive projecting and splitting. Finally, a decision tree is built. Experimental results show that GODT has a better classification accuracy and requires less training time. It combines the high learning efficiency of univariate decision tree algorithm with the strong representation power of multivariate decision tree.
-
Key words:
- Distributed data streams /
- big data /
- classification /
- outline similarity /
- multivariate decision tree
-
主成分分析(Principle component analysis,PCA) [1]是一种被广泛研究的数据处理和降维技术,在多元统计分析、 生物信息、图像识别等领域中有着广泛应用 [2-6]. 对于给定的数据,PCA寻找线性投影方向使得数据在投影后空间中方差极大化,从而使得这些投影方向构成的低维线性空间能够较好地体现原空间的数据结构信息.
当数据服从正态分布时,经典的PCA由于使用L2- 模,使得其在均方重构误差意义下是最优的.此外,PCA所求出的各主成分(Principle component,PC)之间互不相关,因此更有利于对各个主成分进行分析.尽管经典的PCA有诸多优点,但其各主成分是原变量的线性组合,且组合权重系数通常是非零的,这使得PCA在实际应用中往往可解释性较差. 为解决该问题,通常的做法是对权重系数加稀疏限制,如Zou等 [7]将PCA的原始问题构造为回归类型的优化问题,并通过Lasso和弹性网络得到稀疏的主成分; Shen等 [8]利用PCA和奇异值分解(Singular value decomposition,SVD) 之间的关系,通过求解低阶矩阵问题求解PCA,并通过极小化带正则项的优化问题得到稀疏的主成分; Johnstone等 [9] 则在高维情况下对单个主成分模型用阈值方法进行求解; Journée 等 [10]利用广义幂法通过添加L0- 模、L1- 模稀疏惩罚项构造非凸优化问题提取稀疏主成分.
同时,L2- 模本身性质会导致PCA对数据离群点敏感 [11].对此,许多学者对鲁棒性进行了研究 [12-18]. L1- 模常常被作为达到鲁棒降维的有效手段 [19-21]. Brooks等 [12]针对含不平衡离群点数据提出基于低维子空间的L1- 模PCA (L1-PCA*),并用基于最适应超平面的方法来求解. 相比于文献[12],Ke等 [13] 通过求解凸优化问题实现L1- 模问题.不同于利用L1- 模,Ding 等 [14] 使用旋转不变的R1- 模构造PCA,在一定程度上抑制了离群点的影响.但是 该方法依赖于投影空间的维数.不同于以上方法通过在输入空间中极小化重构误差而实现,Kwak [15]提出PCA-L1,在特征空间中极大化相应的L1- 模问题并通过贪婪算法进行求解.该算法直观、简单且易于实施,并且与R1-PCA相比速度更快; 文献[16]则讨论了带Lp- 模稀疏约束的PCA模型,其中0<p< 1,并采用逐次线性化算法求解.最近,Kwak [17]将PCA-L1推广到PCA-Lp,其中p是任意非负数,同时证明了当p=2和p=1时,PCA-Lp分别等价于经典PCA和文献[15]提出的PCA-L1.
为同时达到鲁棒性和稀疏性,Meng等 [18] 在PCA-L1的基础上提出具有稀疏性的L1- 模PCA (RSPCA). 实验表明,该算法不仅保持了PCA-L1的鲁棒性,而且具有稀疏性 [18]. 因此,本文拟提出稀疏的PCA-Lp (LpSPCA),将对任意p>0的LpSPCA进行研究;同时,通过添加额外L1- 模正则项,LpSPCA不仅有较好的降维性能,并具有一定的稀疏性.特别地,当0<p≦1时,LpSPCA同时具有良好的鲁棒性和稀疏性.
LpSPCA可以通过一个简单的迭代算法实现,并且该算法在p≧1时收敛于局部最优解.此外,当p=1时,LpSPCA等价于文献[18]中所提的RSPCA.在具有离群点的人工数据及带噪声的人脸数据上的实验表明,LpSPCA在鲁棒性和稀疏性上与经典PCA相比有诸多优势,并可针对不同数据选择适当的p 以达到更好的效果.
本文结构如下:第1节给出本文所提LpSPCA模型,第2节提出LpSPCA求解算法并进行相应的理论分析. 第3节将LpSPCA应用到人工数据及人脸数据上进行实验.第4节进行总结.
1. 鲁棒的稀疏Lp-模主成分分析 LpSPCA
考虑如下原始数据矩阵: $X = [{x_1},{x_2}, \cdots ,{x_N}] \in {R^{d \times N}}$ ,其中d代表样本点维数,N代表样本点个数. 不失一般性,假设数据已中心化.
经典PCA试图寻找一个m<d维线性子空间使得样本点X在该空间中的方差尽可能大.该空间可以通过求解以下优化问题得到:
$\eqalign{ & \mathop {\max }\limits_W \sum\limits_{i = 1}^N {\left\| {{W^{\rm{T}}}{x_i}} \right\|} _2^2 \cr & {\rm{s}}.{\rm{t}}.\quad {W^{\rm{T}}}W = I \cr} $
(1) 其中, $\|\cdot\|_2 $ 为L2- 模, $W = [{w_1},{w_2}, \cdots ,{w_m}] \in {R^{d \times m}},I \in {R^{m \times m}}$ 是单位阵.这里 ${{w}_j}$ 是数据X的第j主成分, $j=1,\cdots,m$ .优化问题(1)可以通过特征值问题进行求解.由约束条件 $W^{\rm T}W=I$ 知, $\{{{w}_j}\}_{j=1}^m $ 构成所求m 维线性子空间的标准正交基.
由于优化问题(1)对w不具有稀疏性,为了引入稀疏性,可考虑以下带稀疏约束的优化问题:
$\eqalign{ & \mathop {\max }\limits_W \mathop \sum \limits_{i = 1}^N \left\| {{W^{\rm{T}}}{x_i}} \right\|_2^2 \cr & {\rm{s}}.{\rm{t}}.\quad {W^{\rm{T}}}W = I,\left\| W \right\|0 \le k \cr} $
(2) 其中, $\| \cdot \| _0$ 为L0- 模,k是所求主成分稀疏度.显然,优化问题(2)是一个复杂的NP难组合问题,求解困难.为得到该问题的近似解,Jolliffe等 [22]将L0- 模问题(2)松弛为L1- 模问题:
$\eqalign{ & \mathop {\max }\limits_W \mathop \sum \limits_{i = 1}^N \left\| {{W^{\rm{T}}}{x_i}} \right\|_2^2 \cr & {\rm{s}}.{\rm{t}}.\quad {W^{\rm{T}}}W = I,{\left\| W \right\|_1} \le k \cr} $
(3) 其中, $\| \cdot \| _1$ 为L1- 模.优化问题(3)使得投射后的样本点在L2- 模意义下方差最大,并使解具有L1- 模意义下的稀疏度k. 但由于L2- 模的应用使得样本方差由范数较大的样本点决定,因此文献[18]进一步考虑如下优化问题:
$\eqalign{ & \mathop {\max }\limits_W \mathop \sum \limits_{i = 1}^N {\left\| {{W^{\rm{T}}}{x_i}} \right\|_1} \cr & {\rm{s}}.{\rm{t}}.\quad {W^{\rm{T}}}W = I,{\left\| W \right\|_1} \le k \cr} $
(4) 优化问题(3)和(4)的区别在于式(4)使用L1- 模定义投射空间样本方差,而式(3)则用L2- 模定义.进一步,我们可以将以上问题推广为要求投射后的样本点在Lp- 模意义下方差最大,其中p>0是任意实数.通过选择适当的p,适应更广泛类型的数据.因此,本文提出稀疏Lp- 模PCA的原始优化问题如下:
$\eqalign{ & \mathop {\max }\limits_W {F_p}(W) = \cr & {1 \over p}\sum\limits_{i = 1}^N {\left\| {{W^{\rm{T}}}{x_i}} \right\|_p^p} = {1 \over p}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^m | } w_j^{\rm{T}}{x_i}{|^p} \cr & {\rm{s}}.{\rm{t}}.\quad {W^{\rm{T}}}W = I,{\left\| W \right\|_1} \le k \cr} $
(5) 其中, $\| \cdot \|_p$ 为Lp- 模.我们称以上模型为LpSPCA.容易看到,当p=2时,式(5)是优化问题(3),而当p = 1时,式(5)等价于优化问题(4).此外,当0 < p ≦1时,LpSPCA可同时保持鲁棒性及稀疏性的优点.因此,可以通过选择不同的p,实现在保持稀疏性的同时满足不同的降维要求.
2. LpSPCA 算法
尽管优化问题(5)中的稀疏约束用凸的L1- 模代替了非凸的L0- 模,LpSPCA仍然难以给出通用的优化方法.为此,我们首先考虑求解m=1的情况;对于m>1的情形,可通过引入贪婪算法求解.因此,首先考虑求解如下问题:
$\eqalign{ & \mathop {\max }\limits_w {F_p}(w) = {1 \over p}\sum\limits_{i = 1}^N | {w^{\rm{T}}}{x_i}{|^p} \cr & {\rm{s}}.{\rm{t}}.\quad {w^{\rm{T}}}w = 1,{\left\| w \right\|_1} \le k \cr} $
(6) 2.1 一个主成分的 LpSPCA 算法
通过引入拉格朗日函数对优化问题(6)进行求解.记优化问题(6)的拉格朗日函数如下:
$L(w) = {F_p}(w) - \lambda ({w^{\rm{T}}}w - 1) - \gamma ({\left\| w \right\|_1} - k)$
(7) 其中,λ>0.令
$\nabla w = \sum\limits_{i = 1}^N {{\rm{sgn}}} ({w^{\rm{T}}}{x_i})|{w^{\rm{T}}}{x_i}{|^{p - 1}}{x_i}$
(8) 为Fp (w)对w的导数,其中 ${\rm sgn}(\cdot)$ 为符号函数.则L(w) 对w 的导数为0时有
$\nabla w - 2\lambda w - \gamma {\rm{sgn}}(w) = 0$
(9) 从而, $w = {1 \over {2\lambda }}(\nabla w - \gamma {\rm{sgn}}(w))$ ,λ>0. 当λ< 0 时,令 $\triangledown_{ w} =0$ . 则此时w=0,问题(6)无解. 当λ> 0时,从式(9)可得w满足 ${\rm{sgn}}(w) = {\rm{sgn}}({\nabla _w}),|{\nabla _w}| \ge \gamma $.由此,
$w = {{{\rm{sgn}}(w)} \over {2\lambda }}{(|{\nabla _w}| - \gamma )_ + } = {1 \over {2\lambda }}\beta $
(10) 其中,
$\eqalign{ & \beta = {\rm{sgn}}(w){(|\nabla w| - \gamma )_ + } \cr & {(a)_ + } = \left\{ \matrix{ a,{\rm{ }}a > 0 \hfill \cr 0,{\rm{ }}a \le 0 \hfill \cr} \right. \cr} $
由于 ${ w}^{\rm T}{ w}=1$ ,因此可得 $\lambda =\| {\beta} \| _2 /2$ ,且 ${ w}^\ast={\beta} /\| {\beta} \| _2$ . 令λ是 $| \triangledown_{ w} | $ 中第k+1大的元素,则由式(10)所表示的w恰好有k个非零元素.从而我们可以得到当m=1时,LpSPCA 模型的求解算法如下:
算法 1. 一个主成分的LpSPCA算法(m=1)
输入. 数据矩阵 $X=[{ x}_1 ,{ x}_2 ,\cdots ,{ x}_N]\in R^{d\times N}$ ,稀疏度k.
输出. ${ w}^\ast $ .
步骤 1. 初始化 ${ w}(0)$ ,并令 $w(0) = w(0)/w(0){_2}$ ,迭代次数t=0.
步骤 2. 奇异性检查:若 $p\le 1$ ,且存在i,使得 ${ w}^{\rm T}(t){ x}_i$ = 0,则令 $w(t) \leftarrow (w(t) + \delta )/w(t) + \delta {_2}$ ,其中△是一个小的随机生成的向量.
步骤 3. 计算
$\nabla w(t) = \sum\limits_{i = 1}^N {{\rm{sgn}}} (w{(t)^{\rm{T}}}{x_i})|w{(t)^{\rm{T}}}{x_i}{|^{p - 1}}{x_i}$
令 ${ w}(t+1)={\beta} (t)/\| {\beta} (t)\| _2$ ,其中${\beta} (t)={\rm sgn}({ w}(t))$×$(| \triangledown_{{ w}(t)} | -\gamma )_+ $,λ是 $| \triangledown_{{ w}(t)} | $ 中第k+1大的元素.
步骤 4. 收敛检查:如果优化问题(6)的目标函数继续增长,转到步骤2; 否则,得到最优解 ${w^ * } = w(t)$ ,并停止迭代.
在给出求解多个主成分的算法前,首先讨论算法1当p≧1时的收敛性.
定理 1. 当p≧1时,优化问题(6)的目标函数值通过每次迭代单调不降.
证明 . 首先考虑p>1的情况.令 w(t)为w在第t次迭代中的值.则 ${ w}(t+1)={\beta} (t)/\| {\beta} (t)\| _2 $ ,其中 ${\beta} (t)={\rm sgn}({ w}(t))(| \triangledown_{{ w}(t)} | -\gamma )_+ $ .由于p>1,因此 $F_p ({ w})$ 是凸函数.由凸函数的性质可知:
${F_p}(w(t + 1)) - {F_p}(w(t)) \ge \nabla _{w(t)}^{\rm{T}}(w(t + 1) - w(t))$
(11) 注意到sgn(w(t+1))=sgn(▽w(t)),且w(t+1) 满足 $w(t + 1){_2} = 1,w(t + 1){_1} \le k$ ,而w(t)满足 $\| { w}(t)\| _2 =1$,$\| { w}(t)\| _1 \le k$ ,因此有 $\nabla _{w(t)}^{\rm{T}}(w(t + 1) - w(t)) \ge 0$ .结合式(11)可知, ${F_p}(w(t + 1)) - {F_p}(w(t)) \ge 0$ ,因此可得p>1时的结论.
当p=1时,由文献[18]中的定理1知,算法1收敛.
综上所述,当p≧1时,优化问题(6)的目标函数是单调不降的.
由于优化问题(6)的目标函数有上界,且由定理1知,随着每次迭代目标函数值非降,因此算法1当p≧1时是收敛的.需要注意的是,尽管当0< p<1时,优化问题(6)的目标函数是非凸的,但在实验中发现,目标函数值在迭代过程中也很快趋于稳定.
2.2 多个主成分的 LpSPCA 算法
由于当m>1时,优化问题(5)很难用一般优化方法进行求解.为此,采用贪婪算法进行求解.算法的基本思路是首先对原始数据应用算法1得到第一主成分w1;然后将数据投影到与w1正交的空间中得到新的数据集,并在投影后的数据集上继续应用算法1 得到第二主成分;依次类推,直到得到m个主成分.算法具体步骤如下:
算法 2. 多个主成分的LpSPCA算法 (m>1)
输入. 数据矩阵 $X=[{ x}_1 ,{ x}_2 ,\cdots ,{ x}_N]\in R^{d\times N}$ ,稀疏度k,主成分个数m>1.
输出. m个稀疏主成分 $\{{ w}_i \}_{i=1}^m $ .
步骤 1. 记 ${ w}_0 =0\in R^d$ 且 $X^0=\{{ x}_i^0 ={ x}_i \}_{i=1}^n $ .
步骤 2. 对$j=1,2,\cdots ,m$,进行以下循环:
1) 令 $X^j=\{{ x}_i^j ={ x}_i^{j-1} -{ w}_{j-1} ({ w}_{j-1}^{\rm T} { x}_i^{j-1} )\}_{i=1}^N $ ;
2) 应用算法1到数据集Xj上并得到稀疏度为k的主成份wj.
算法2求得的各主成分不随m的变化而改变,并且第1主成分为原始式(6)的局部最优解,第2主成分为式(6)的局部次优解,依次类推.算法2是一个启发式算法,只能得到式(5)的近似解.主要包括两方面: 1)算法1本身只能得到式(6)的局部解; 2)由算法2产生的 $\{{ w}_i\}_{i=1}^m $ 的正交性不能在理论上给予保证.然而,由算法2中步骤2可知, $w_s^{\rm{T}}x_i^j = 0,i = 1,2, \cdots ,N,s = 1,2, \cdots ,j - 1$ ,因此投射后的样本集Xj属于 $\{{ w}_s \}_{s=1}^{j-1}$ 所张成的$(j-1)$维子空间,并且由Xj所得到的第j个主成分wj也近似正交于 $\{{ w}_s \}_{s=1}^{j-1} $ .
需要注意的是,算法2实际上是对算法1在不同数据集上的循环执行.因此,算法1的解对算法2有直接影响.在算法1中,初始值是随机选取,而算法1所得的局部解是依赖于该初始值的.因此,好的初始值比较重要.在实际运行中,除了随机赋初始值外,还可以采用经典PCA 的解作为算法1的初始值;或者选择不同的初始值多次运行算法1,并在这些初始值中选择使得目标函数最大的初始值;还可以选择初始值使得其与范数最大的样本同向.为减少运算复杂度,同时为了测试算法的稳定性,本文采取随机赋值的方法.
3. 实验结果与分析
为验证本文算法的鲁棒性和稀疏性,通过两个人工数据集和两组带离群点和噪声点的Yale人脸数据集,以重构误差(Reconstruction error)为指标,分别对LpSPCA算法与经典PCA [1]、PCA-Lp [17]及RSPCA [18]算法进行性能分析. 为方便起见,以下称PCA-Lp为LpPCA.所有实验均以Matlab 2014b为软件环境,以Intel i5 (2.3 GHz)处理器,8 GB内存的计算机为硬件平台.在实验中,使用Matlab中eig函数求解经典PCA的特征值问题,使用算法2求解LpSPCA.
3.1 人工数据集
3.1.1 LpSPCA 鲁棒性分析
通过设计一个三维带离群点的人工数据集,验证不同p值对LpSPCA算法抗离群点性能的影响.人工数据集构造如下: 1)选取31个数据点 $\{ ({x_i},{y_i},{z_i})\} _{i = 1}^{31}$ 构成空间中平行于x轴的近似直线,其中 ${x_i} \in [ - 3,3]$ ,且yi和zi分别随机取自[0,0.1]和[-1,-0.9]上的均匀分布. 2)在该数据中引入4个离群点,分别为 $(4+\alpha_i ,2+{\beta} _i ,4+\gamma _i )$ 和 $({\alpha _i}, - 3 + {\beta _i},4 + {\gamma _i})$ ,其中 ${\alpha _i},{\beta _i},{\gamma _i}$ 随机取自[0,0.1]上的均匀分布,i=1,2,如图 1 (a)所示.
 图 1 PCA和LpSPCA在人工数据集上所得到的第1个主成分及 将数据用LpSPCA、PCA、RSPCA、LpPCA投影到该主成分所张成空间上的重构误差Fig. 1 The -rst principal components of the arti-cial data set obtained by classical PCA and LpSPCA, and reconstruction errors in the spaces spanned by the -rst principal components obtained by LpSPCA, PCA, RSPCA and LpPCA, respectively
图 1 PCA和LpSPCA在人工数据集上所得到的第1个主成分及 将数据用LpSPCA、PCA、RSPCA、LpPCA投影到该主成分所张成空间上的重构误差Fig. 1 The -rst principal components of the arti-cial data set obtained by classical PCA and LpSPCA, and reconstruction errors in the spaces spanned by the -rst principal components obtained by LpSPCA, PCA, RSPCA and LpPCA, respectively由上述人工数据集的结构可知,该数据由1个平行于x的主方向和远离该主方向的4个离群点构成.因而,该人工数据本质上是1维向量嵌入在3 维空间中的数据.因此,在本组实验中,将检验LpSPCA和PCA、RSPCA、LpPCA将数据降到1维子空间后的重构性能.另外,设置LpSPCA 和RSPCA的稀疏度为k=2.
对于LpSPCA,由于该人工数据在三维空间中,因此稀疏度k可以取为1或2.然而,若取k=1时,则主成分将有两个分量为0.此时,根据该数据点的构造,可以得到的主成分将平行于x轴方向,因而意义不大.因此,选取稀疏度k=2.
图 1 (a)给出了LpSPCA和经典PCA的第1主成分(PC)投影方向(为使图像更清晰,没有画出LpPCA所提取的PC方向).结果表明:当p=0.5时,LpSPCA所得到的第一PC方向与数据的真实方向最为接近,并且随着p的增长,LpSPCA的PC方向受离群点影响越来越大.特别地,当p=2时,LpSPCA与经典PCA所得PC方向基本一致.
为进一步验证各算法性能,与文献[15]类似,引入重构误差指标,定义如下:
${e_i} = {\left\| {{\zeta _i} - {w_1}w_1^{\rm{T}}{\zeta _i}} \right\|_2}$
其中, ${\zeta} _i =\{(x_i ,y_i ,z_i )\}$ 为第i个样本点,w1是相应方法所得的第一PC.图 1 (b)描绘了各算法将原3维空间数据降到1维后每个样本点的重构误差.从图 1(b) 可以看出,当p=0.5时,LpSPCA在该数据上的重构误差最小,并且随着p增大,LpSPCA的重构误差依次增大; LpPCA也呈现同样的特点.然而,当取相同p时,可以看到LpSPCA的重构误差比LpPCA 略低,说明在此数据集上,主成分本身具有一定稀疏性,因此LpSPCA效果更好.同时,RSPCA的重构误差与p=1时的LpSPCA、LpPCA基本持平.此外,p=2时,LpSPCA、LpPCA与经典PCA在样本点上的重构误差相近.实验结果表明,LpSPCA可以通过调节p达到相当的鲁棒性.
3.1.2 LpSPCA 稀疏性分析
通过设计一个8维的人工数据集验证LpSPCA算法的稀疏性.该人工数据集的构造基于文献[7]中的人工数据.
在构造人工数据集前,定义三个潜在因子:
$\eqalign{ & {V_1} \sim {\rm{N}}(0,20) \cr & {V_2} \sim {\rm{N}}(0,30) \cr & {V_3} = - 0.2V + 0.8{V_2} + \varepsilon \cr} $
其中, $\varepsilon \sim {\rm N}(0,1)$ ,且V1、V2和ε互相独立.记xi为数据集的第i个特征, $i=1,2,{\cdots},8$ . 则定义 ${x_1},{x_2},{x_3} = {V_1},{x_4},{x_5},{x_6} = {V_2},{x_7},{x_8} = {V_3}$ .三个潜在因子的方差分别为20、30和20,因此V2最重要,V1和V3基本同等重要.这样,得到的第1主成分应只用 $({x_4},{x_5},{x_6})$ 就可恢复V3,而第2和第3主成分可只用 $({x_1},{x_2},{x_3})$ 或 $({x_7},{x_8})$ 恢复,即所构造数据本身具有稀疏性.将各算法应用于此数据,所得结果列于表 1 ~ 3中.
表 1 PCA和RSPCA在人工数据集2上提取的前两个主成分Table 1 The first two PCs extracted by PCA and RSPCA on artificial data set 2PCA RSPCA PC1 PC2 PC1 PC2 0.0608 -0.1238 0 0.0998 -0.0527 0.0422 0 0.4954 0.0389 0.1514 0 0.4048 -0.1343 -0.1754 -0.3608 0 0.167 -0.1062 0.3679 0 0.2074 0.1841 0 0 0.2135 0.0237 0 0 -0.1254 0.1933 0.2713 0 表 2 LpPCA 在人工数据集2 上所提取的前两个主成分Table 2 The first two PCs extracted by LpPCA on artificial data set 2LpPCA (L0.5) LpPCA (L1) LpPCA (L1.5) LpPCA (L2) PC1 PC2 PC1 PC2 PC1 PC2 PC1 PC2 0.161 0.1896 -0.1924 -0.1657 0.0588 -0.1483 -0.1807 -0.1945 -0.1433 0.0855 0.1783 0.0865 -0.1833 -0.036 0.0399 0.1858 -0.1472 -0.1807 0.1511 -0.0542 -0.1771 0.0428 0.1957 -0.1054 0.0773 0.0125 -0.1056 0.131 -0.035 0.1067 0.2457 -0.0457 -0.0942 0.0566 0.1713 0.1395 -0.2173 -0.1576 -0.0184 0.0696 0.1948 -0.1646 0.05 -0.1428 -0.238 0.2375 0.1488 -0.1129 0.0831 0.1925 -0.1428 0.1499 0.2135 0.0899 0.0831 0.1925 -0.0991 0.1179 0.0085 -0.1306 -0.1254 0.1812 -0.0991 0.1179 表 3 LpSPCA 在人工数据集2 上所提取的前两个主成分Table 3 The first two PCs extracted by LpSPCA on artificial data set 2LpPCA (L0.5) LpPCA (L1) LpPCA (L1.5) LpPCA (L2) PC1 PC2 PC1 PC2 PC1 PC2 PC1 PC2 0 0.2978 0 -0.4474 0 0.1285 0 0.1126 0 -0.674 0 -0.1696 0 0.4496 -0.0625 0 0 0.0282 0 -0.383 0 0.4220 0 0.4801 0.2726 0 0.2567 0 0.5954 0 0 0.4073 -0.4027 0 0.3741 0 -0.2469 0 -0.5845 0 0.3247 0 0.3693 0 0 0 -0.353 0 0 0 0 0 0 0 0 0 0 0 0 0 0.2713 0 0 0 从表 1 ~ 3可以看出,经典PCA和LpPCA (p = 0.5,1,1.5,2)均不具有稀疏性,而RSPCA和LpSPCA (p=0.5,1,1.5,2)有较好的稀疏性.同时p越小,LpSPCA所提取的稀疏主成分越接近于真实情况.特别地,当p=0.5,1和1.5时,LpSPCA所得结果优于RSPCA.
3.2 Yale 人脸数据集
特征脸提取是人脸识别的一个重要环节,近年来得到广泛研究与发展.然而,传统的特征脸提取方法大多基于无噪声污染的人脸图像数据 [23-26].但是,现实中人脸图像大多包含离群点或噪声,例如脸部被遮掩、弱光线下的图像等,这极大影响了传统基于L2- 模降维方法的性能.因此,本实验将LpSPCA算法应用到带离群点和噪声的Yale人脸数据上,并 将其和经典PCA、RSPCA及LpPCA比较,以验证其特征提取能力及鲁棒性.
Yale人脸数据集包含15类共165张灰色人脸数据图片,每类包含11张图片,并且每张图片都具有不同的布局及面部表情. Yale人脸数据图片的原始大小为320像素×243像素,本文采用裁剪后大小为64像素×64像素的归一化图片. 为测试LpSPCA的鲁棒性,本文采取文献[18]中的做法,对原始图片进行两种加离群点及噪声点处理: 1) 遮盖噪声(Occluded),首先在每类的11个图像中随机抽取两张图像,然后在抽取的图像上随机选择大小为40×30 的长方形区域,并用黑白噪声对其覆盖; 2)哑噪声(Dummy),在整个人脸数据集中额外加入与原人脸图像大小相同的50张黑白点噪声图片.
本文将分别在上述两类Yale人脸数据集上,以重构特征脸和平均重构误差(Average reconstruction error,ARCE)为指标,验证和分析LpSPCA的鲁棒性.类似文献[15],这里将使用前m个PC对图像进行重构,其ARCE定义如下:
$e(m) = {1 \over n}\sum\limits_{i = 1}^n {\xi _i^o - \sum\limits_{j = 1}^m {{w_j}} w_j^{\rm{T}}{\xi _i}{_2}} $
其中,n为图像样本点个数, ${\xi} _i^o $ 代表第i张原始人脸图片, ${\xi} _i$ 代表噪声化人脸数据集中相应的图片.
3.2.1 稀疏度 k 对算法性能的影响
在验证LpSPCA算法的鲁棒性之前,首先分析稀疏度k对ARCE的影响.每个人脸在实际计算中都相当于4 096 (64×64)维向量. 对每个不同的p,选取稀疏度k为维度的一定百分比: 95 %,90 %,85 %,80 %,75 %. 例如,当取百分比为95 %时,则此时稀疏度k 为4 096×95 %.
图 2 (a)和图 2 (b)分别给出了在两种噪声人脸数据集上,具有不同稀疏度的LpSPCA的平均重构误差.从图 2可以看出,无论是哪种数据,随着k 值的增加,LpSPCA的重构误差整体趋势逐渐增加,然而,当稀疏度选为维数的90% 时,其重构误差最小.因此,在后续鲁棒性实验中,始终设定算法稀疏度为维度的90%.
 图 2 稀疏度k对LpSPCA平均重构误差在带遮盖噪声和哑噪声的Yale 人脸数据上的影响Fig. 2 The influence of parsity k to the ARCE of LpSPCA on the occluded or dummy Yale face database
图 2 稀疏度k对LpSPCA平均重构误差在带遮盖噪声和哑噪声的Yale 人脸数据上的影响Fig. 2 The influence of parsity k to the ARCE of LpSPCA on the occluded or dummy Yale face database3.2.2 LpSPCA 与其他算法性能对比
对于遮盖噪声型数据,首先使用各算法将64×64维的图像高维空间降维到由前30个PC张成的子空间,然后再用该子空间对遮盖噪声图像进行重构. 图 3 (a)给出了各算法的重构效果.从图 3 (a)可以看出,当p=0.5时,LpSPCA重构效果最好,这是由于L0.5- 模极大程度抑制了噪声的影响; 随着p的增大,LpSPCA受噪声的影响增大;当p=2时,其性能与经典的L2-PCA相近.上述结果表明,传统基于L2- 模的降维算法,其重构性能易受噪声点影响.
 图 3 带遮盖噪声的Yale人脸数据及LpSPCA、PCA、RSPCA和LpPCA在该数据上用前30个相应主成分的重构效果图及 将数据用各方法投影到该1 ~ 70个主成分上的重构误差Fig. 3 Occluded Yale face database and face reconstruction pictures of the data set constructed by the first thirty principal components obtained by LpSPCA,PCA,RSPCA and LpPCA and reconstruction errors in the spaces spanned by 1 ~ 70 principal components obtained by PCA,RSPCA,LpPCA and LpSPCA,respectively
图 3 带遮盖噪声的Yale人脸数据及LpSPCA、PCA、RSPCA和LpPCA在该数据上用前30个相应主成分的重构效果图及 将数据用各方法投影到该1 ~ 70个主成分上的重构误差Fig. 3 Occluded Yale face database and face reconstruction pictures of the data set constructed by the first thirty principal components obtained by LpSPCA,PCA,RSPCA and LpPCA and reconstruction errors in the spaces spanned by 1 ~ 70 principal components obtained by PCA,RSPCA,LpPCA and LpSPCA,respectively图 3 (b)给出了各算法提取的PC个数(即重构子空间维数)对ARCE的影响.结果表明:对于所有算法,随着PC个数的增大,ARCE逐级减少,说明重构子空间维数对重构效果存在较大影响.随PC个数增加,当p=0.5时,LpPCA和LpSPCA的ARCE 快速下降,且当特征个数大于35时,LpSPCA的ARCE略低于LpPCA. p=1时,LpPCA和LpSPCA的ARCE小于RSPCA,且当所提取特征个数小于50 时,LpSPCA的重构误差更小.随着p的增大(p=1.5,2),LpPCA和LpSPCA的性能开始变差,其ARCE高于RSPCA. 然而,LpPCA、 LpSPCA (p= 0.5,1,1.5,2)和RSPCA的性能都比经典PCA要好.从图中可以看出,当提取PC个数在12 ~ 30之间时,随着提取特征数的增加,经典PCA、RSPCA及p=1.5,2时,LpPCA和LpSPCA的重构误差也有所增加.表明对于经典PCA、RSPCA及p=1.5,2时的LpPCA和LpSPCA,所加遮盖噪声对第12 ~ 30个PC的提取有很大影响.相反,当p=0.5,1时,LpPCA和LpSPCA随提取特征数据的增长,ARCE下降较快,且没有接近常数的值.以上结果表明,当0<p< 1时,LpSPCA具有良好的鲁棒性.
对于哑噪声型数据,可以得到类似结论. 1)图 4 (a)描述了经典PCA、RSPCA 及p =0.5,1,1.5,2时LpPCA和LpSPCA在该数据集上的重构效果.从图 4 (a)可以看出,经典PCA及p=1.5,2时的LpPCA和LpSPCA对原始图片重构效果最差,以至于对半数以上人脸重构失真,并且p=1.5时的结果比p=2时更差.相对而言,RSPCA及对应p=0.5,1 的LpPCA和LpSPCA则成功提取人脸特征,并再现了原始人脸图片. 2)图 4 (b)给出的相应平均重构误差,进一步印证了以上结论.具体地,当提取特征数为5 ~ 55时,对于经典PCA、 p=1.5,2时的LpPCA 和p=2 时的LpSPCA,它们的重构误差接近于常数,表明所加虚拟噪声图像对第5 ~ 55个PC的提取有很大的影响.相反,当p=0.5,1时,LpSPCA和LpPCA的ARCE则下降较快,并且两者ARCE值基本相同.说明与LpPCA相比,LpSPCA并没有损失精度,却具有良好的稀疏性.
 图 4 原始Yale人脸数据及LpSPCA、PCA、RSPCA和LpPCA 在带哑噪声的Yale数据上用前30个相应主成分的\\重构效果图及将数据用 各方法投影到该1 ~ 70个主成分上的重构误差Fig. 4 Original Yale face database and face reconstruction pictures of its dummy data set constructed by the first thirty principal components obtained by LpSPCA,PCA,RSPCA and LpPCA and reconstruction errors in the spaces spanned by 1 ~ 70 principal components obtained by PCA,RSPCA,LpPCA and LpSPCA,respectively
图 4 原始Yale人脸数据及LpSPCA、PCA、RSPCA和LpPCA 在带哑噪声的Yale数据上用前30个相应主成分的\\重构效果图及将数据用 各方法投影到该1 ~ 70个主成分上的重构误差Fig. 4 Original Yale face database and face reconstruction pictures of its dummy data set constructed by the first thirty principal components obtained by LpSPCA,PCA,RSPCA and LpPCA and reconstruction errors in the spaces spanned by 1 ~ 70 principal components obtained by PCA,RSPCA,LpPCA and LpSPCA,respectively以上在Yale带离群点和噪声人脸数据上的实验结果表明,相比于经典PCA和LpPCA,本文所提LpSPCA在不损失精度的基础上具有较好的稀疏性; 相比于经典PCA和RSPCA,LpSPCA可通过选择p达到不同的处理离群点及噪声效果,具有鲁棒性.
4. 结论
本文提出一种新的鲁棒稀疏PCA模型及算法LpSPCA. LpSPCA对LpPCA赋予了稀疏性,使得算法在具有鲁棒性的同时具有较强的可解释性. LpSPCA可由一个简单的算法进行求解,并理论上验证了该算法p≧1时的收敛性. LpSPCA在人工数据及人脸数据上的结果表明了该算法的优势.然而,本文所提LpSPCA算法只能求得局部近似解而不保证精确解.因此,设计针对LpSPCA更有效的算法是值得进一步研究的.
-
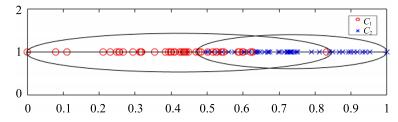
图 1 投影点集合$P_1 $与$P_2 $的位置关系
Fig. 1 The position relationship of projection point sets $P_1 $ and $P_2 $
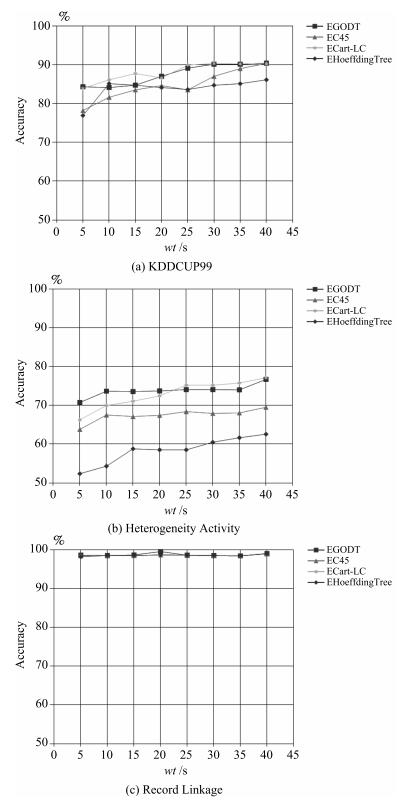
图 3 分类精度随滑动窗口大小的变化情况
Fig. 3 The variation of classification accuracy with the sliding window size

图 4 $wt=5$时, 分类精度在整个挖掘序列的变化情况
Fig. 4 The variation of classification accuracy in the mining sequence when $wt=5$
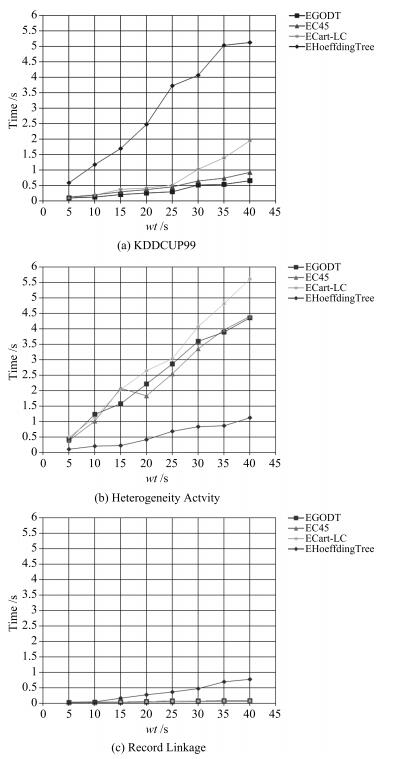
图 5 训练时间随滑动窗口大小的变化情况
Fig. 5 The variation of training time with the sliding window size
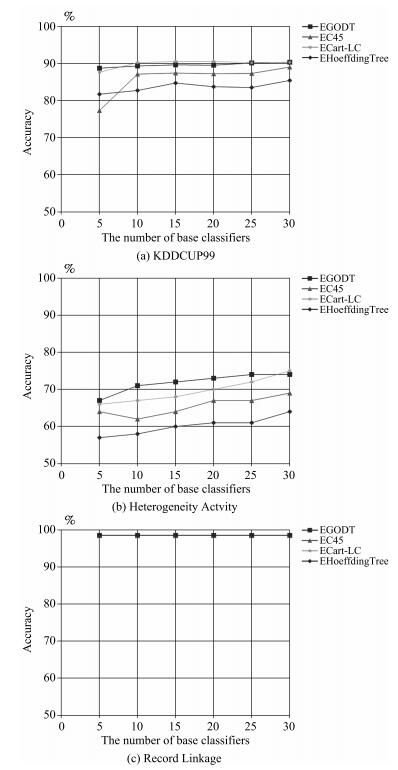
图 6 分类精度随基分类器数量的变化情况
Fig. 6 The variation of classification accuracy with the number of base classifiers
表 1 数据集
Table 1 Dataset
Dataset Number of attributes Type of attributes Size Number of class KDDCUP99 42 Nominal, Numeric 5 209 460 23 Record Linkage 12 Numeric 4 587 620 2 Heterogeneity Activity 7 Numeric 13 062 475 7  下载: 导出CSV
下载: 导出CSV
表 2 EGODT的基分类器间的不合度量
Table 2 The disagreement measure between base classifiers of EGODT
GODT $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.43 0.52 0.55 0.51 0.41 0.43 0.43 0.41 0.48 $c$2 0 0.51 0.46 0.6 0.32 0.29 0.39 0.29 0.6 $c$3 0 0.24 0.24 0.56 0.6 0.56 0.6 0.52 $c$4 0 0.35 0.66 0.56 0.67 0.55 0.73 $c$5 0 0.53 0.64 0.52 0.57 0.58 $c$6 0 0.41 0.19 0.13 0.37 $c$7 0 0.12 0.19 0.68 $c$8 0 0.2 0.64 $c$9 0 0.6 $c$10 0
下载: 导出CSV
表 3 EC45的基分类器间的不合度量
Table 3 The disagreement measure between base classifiers of EC45
C4.5 $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.31 0.44 0.44 0.35 0.3 0.31 0.31 0.29 0.35 $c$2 0 0.48 0.48 0.53 0.11 0.09 0.09 0.09 0.53 $c$3 0 0.02 0.53 0.55 0.53 0.52 0.51 0.55 $c$4 0 0.52 0.55 0.53 0.53 0.53 0.54 $c$5 0 0.48 0.51 0.53 0.49 0.04 $c$6 0 0.08 0.09 0.07 0.47 $c$7 0 0.02 0.07 0.53 $c$8 0 0.08 0.54 $c$9 0 0.49 $c$10 0
下载: 导出CSV
表 4 ECart-LC的基分类器间的不合度量
Table 4 The disagreement measure between base classifiers of ECart-LC
Cart-LC $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.39 0.31 0.31 0.3 0.37 0.46 0.46 0.32 0.32 $c$2 0 0.22 0.22 0.36 0.57 0.48 0.47 0.48 0.6 $c$3 0 0 0.15 0.61 0.5 0.5 0.5 0.5 $c$4 0 0.15 0.61 0.5 0.5 0.5 0.5 $c$5 0 0.46 0.52 0.52 0.39 0.39 $c$6 0 0.57 0.57 0.2 0.16 $c$7 0 0 0.38 0.5 $c$8 0 0.38 0.5 $c$9 0 0.12 $c$10 0
下载: 导出CSV
表 5 EHoeffdingTree的基分类器间的不合度量
Table 5 The disagreement measure between base classifiers of EHoeffdingTree
HoeffdingTree $c$1 $c$2 $c$3 $c$4 $c$5 $c$6 $c$7 $c$8 $c$9 $c$10 $c$1 0 0.26 0.53 0.54 0.38 0.3 0.36 0.31 0.24 0.47 $c$2 0 0.42 0.47 0.2 0.18 0.12 0.16 0.1 0.32 $c$3 0 0.45 0.45 0.43 0.58 0.58 0.46 0.45 $c$4 0 0.52 0.44 0.45 0.5 0.47 0.51 $c$5 0 0.54 0.57 0.56 0.58 0.07 $c$6 0 0.08 0.15 0.14 0.51 $c$7 0 0.19 0.12 0.58 $c$8 0 0.25 0.57 $c$9 0 0.56 $c$10 0
下载: 导出CSV
-
[1] 朱群, 张玉红, 胡学钢, 李培培.一种基于双层窗口的概念漂移数据流分类算法.自动化学报, 2011, 37(9):1077-1084 doi: 10.3724/SP.J.1004.2011.01077Zhu Qun, Zhang Yu-Hong, Hu Xue-Gang, Li Pei-Pei. A double-window-based classification algorithm for concept drifting data streams. Acta Automatica Sinica, 2011, 37(9):1077-1084 doi: 10.3724/SP.J.1004.2011.01077 [2] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):97-107 doi: 10.1109/TKDE.2013.109 [3] 孙大为, 张广艳, 郑纬民.大数据流式计算:关键技术及系统实例.软件学报, 2014, 25(4):839-862 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201404011.htmSun Da-Wei, Zhang Guang-Yan, Zheng Wei-Min. Big data stream computing:technologies and instances. Journal of Software, 2014, 25(4):839-862 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201404011.htm [4] Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 1997, 55(1):119-139 doi: 10.1006/jcss.1997.1504 [5] Breiman L. Bagging predictors. Machine Learning, 1996, 24(2):123-140 [6] Zhang P, Zhou C, Wang P, Gao B J, Zhu X Q, Guo L. E-tree:an efficient indexing structure for ensemble models on data streams. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(2):461-474 doi: 10.1109/TKDE.2014.2298018 [7] Blaser R, Fryzlewicz P. Random rotation ensembles. Journal of Machine Learning Research, 2016, 17(4):1-26 [8] Street W N, Kim Y. A streaming ensemble algorithm (SEA) for large-scale classification. In: Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: ACM, 2001. 377-382 [9] Bifet A, Holmes G, Pfahringer B, Kirkby R, Gavaldá R. New ensemble methods for evolving data streams. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France: ACM, 2009. 139-148 [10] Polat K, Güneş. A novel hybrid intelligent method based on C4.5 decision tree classifier and one-against-all approach for multi-class classification problems. Expert Systems with Applications, 2009, 36(2):1587-1592 doi: 10.1016/j.eswa.2007.11.051 [11] Wozniak M. A hybrid decision tree training method using data streams. Knowledge and Information Systems, 2011, 29(2):335-347 doi: 10.1007/s10115-010-0345-5 [12] Abdulsalam H, Skillicorn D B, Martin P. Classification using streaming random forests. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(1):22-36 [13] Bifet A, Frank E, Holmes G, Pfahringer B. Ensembles of restricted hoeffding trees. ACM Transactions on Intelligent Systems and Technology (TIST), 2012, 3(2):Article No. 30 [14] Ahmad A, Brown G. Random projection random discretization ensembles-ensembles of linear multivariate decision trees. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5):1225-1239 doi: 10.1109/TKDE.2013.134 [15] 毛国君, 胡殿军, 谢松燕.基于分布式数据流的大数据分类模型和算法.计算机学报, 2017, 40(1):161-175 doi: 10.11897/SP.J.1016.2017.00161Mao Guo-Jun, Hu Dian-Jun, Xie Song-Yan. Models and algorithms for classifying big data based on distributed data streams. Chinese Journal of Computers, 2017, 40(1):161-175 doi: 10.11897/SP.J.1016.2017.00161 [16] Quinlan J R. Induction of decision trees. Machine Learning, 1986, 1(1):81-106 [17] Quinlan J R. C4. 5: Programs for Machine Learning. San Mateo, CA, USA: Morgan Kaufmann, 1993. [18] Breiman L, Friedman J H, Olshen R A, Stone C J. Classification and Regression Trees. Belmont, CA, USA:CRC Press, 1984. [19] Brodley C E, Utgoff P E. Multivariate decision trees. Machine Learning, 1995, 19(1):45-77 [20] Ferri C, Flach P A, Hernández-Orallo J. Improving the AUC of probabilistic estimation trees. In: Proceedings of the 2003 European Conference on Machine Learning. Berlin, Heidelberg, Germany: Springer, 2003. 121-132 [21] Mingers J. An empirical comparison of pruning methods for decision tree induction. Machine Learning, 1989, 4(2):227-243 doi: 10.1023/A:1022604100933 [22] Esposito F, Malerba D, Semeraro G, Kay J. A comparative analysis of methods for pruning decision trees. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(5):476-491 [23] Fournier D, Crémilleux B. A quality index for decision tree pruning. Knowledge-Based Systems, 2002, 15(1-2):37-43 doi: 10.1016/S0950-7051(01)00119-8 [24] Osei-Bryson K M. Post-pruning in decision tree induction using multiple performance measures. Computers and Operations Research, 2007, 34(11):3331-3345 [25] Elomaa T, Kääriäinen M. An analysis of reduced error pruning. Journal of Artificial Intelligence Research, 2001, 15(1):163-187 [26] Quinlan J R. Simplifying decision trees. International Journal of Man-Machine Studies, 1987, 27(3):221-234 doi: 10.1016/S0020-7373(87)80053-6 [27] 包研科, 赵凤华.多标度数据轮廓相似性的度量公理与计算.辽宁工程技术大学学报(自然科学版), 2012, 31(5):797-800 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=lngcjsdxxb201205053Bao Yan-Ke, Zhao Feng-Hua. Measure axiom of outline similarity of multi-scale data and its calculation. Journal of Liaoning Technical University (Natural Science), 2012, 31(5):797-800 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=lngcjsdxxb201205053 [28] Bache K, Lichman M. UCI machine learning repository[Online], available: http://archive.ics.uci.edu/ml, January 1, 2016 [29] Stisen A, Blunck H, Bhattacharya S, Prentow T S, Kjaergaard M B, Dey A, Sonne T, Jensen M M. Smart devices are different: assessing and mitigating mobile sensing heterogeneities for activity recognition. In: Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems. Seoul, South Korea: ACM, 2015. 127-140 [30] Zhou Z H. Ensemble Methods: Foundations and Algorithms. Boca Raton, FL, USA: Chapman and Hall/CRC, 2012. -

 下载:
下载:

计量
- 文章访问数: 2462
- HTML全文浏览量: 438
- PDF下载量: 843
- 被引次数: 0
