

-
摘要: 自适应动态规划(Adaptive dynamic programming,ADP)作为最优控制领域的近似优化方法,是求解复杂非线性系统最优控制问题的有力工具.近年来,已成为控制理论与计算智能领域的研究热点.本文着重介绍ADP算法的理论研究进展及其在航空航天领域的应用.分析了几种典型的制导律优化设计方法,以及ADP方法在导弹制导律设计中的应用现状和前景.Abstract: Adaptive dynamic programming (ADP) is a powerful tool for optimal control of complicated nonlinear system, which is a novel approximate optimal control method. Recently, it has become a hot topic in the field of control theory and computational intelligence. This paper focuses on giving a review of ADP on the development of ADP algorithms and its aerospace applications. The design methods of classic missile guidance law are introduced, as well as the present and potential applications of ADP in the guidance law design of missiles.
-
Key words:
- Adaptive dynamic programming (ADP) /
- optimal control /
- missile /
- guidance law
-
脊柱类疾病是比较常见的一种疾病, 手术是治疗脊柱类疾病的常见方式.图像引导的脊柱手术能够大大提高手术的成功率, 尤其是3D的图像能够给医生提供包括病人脊椎姿态的丰富信息.然而在术中获取病人的3D影像是十分困难的, 而获得2D的X-ray图像比较容易, 为了在术中给医生呈现病人的3D脊椎信息, 一个可行的方法便是对术前3D图像中的脊椎和术中2D图像中的脊椎进行配准, 从而间接地在术中为医生提供病人脊椎的3D姿态信息.
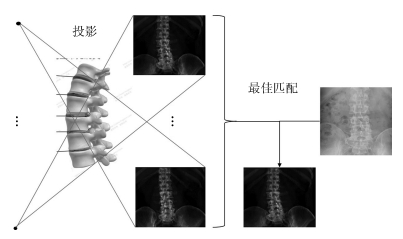
如图 1所示, 传统的2D/3D配准方法是基于搜索的策略, 是将3D图像模拟投影成一系列的2D图像, 将这些模拟投影图像与真实的2D图像进行相似性度量, 找到一个最佳匹配的模拟投影图像, 从而完成配准[1-4].在进行相似性度量时, 早期配准方法如[2, 4-7]是对整幅图像或感兴趣区域进行配准, 这样目标周围的组织也会对配准产生影响.为了避免邻近组织的影响, Pohl等在配准前先对目标进行分割, 使得配准更加的精确[8].在搜索的策略上, 由于投影空间复杂度较高为O(n6), 包括3个平移自由度和3个旋转自由度, 所以计算量巨大, 为了减小计算量, 有许多启发式搜索的方法被提出, 如Zollei等和Kim等使用梯度下降的方法来引导搜索[5-6], Chou等使用回归学习的方法建立灰度残差与投影参数改变量的关系来引导投影参数的搜索方向[9].这些基于启发式搜索的配准方法在一定程度上减小了计算量, 但是依然很难达到实时配准, 并且对初值敏感, 不易收敛.
由于基于搜索策略的配准方法计算量大, 越来越多的研究转向基于机器学习的方法[10-12].基于机器学习的配准方法主要是学习模拟投影图像与投影参数之间的关系, 从而避免搜索的过程, 大大提高了配准的效率.使用投影图像的哪些信息以及如何提取这些信息并建立与投影参数之间的关系是基于机器学习配准方法的一个重要的问题. Cyr等只使用了简单的轮廓信息, 而没有使用内部丰富的结构信息[10].文献[11]中建立了目标的纹理模型, 并学习纹理模型与投影参数之间的关系, 在精度和速度上都有较好的效果, 但是这个工作配准的对象是干扰较小的头部图像, 因此并没有分割的过程.文献[12]中使用标志点的统计分量来回归学习其与投影参数之间的关系, 但是其将分割、标志点定位和统计分量计算作为三个独立的问题进行处理, 且分割直接使用人工设定阈值的方法, 使得整个方法复杂且需要较多的人为干预, 稳定性和实用性欠佳.
为了更好地分割目标, 本文对脊椎建立了统计形状模型[13-14].统计形状模型最早应用于人脸分割上, 文献[15-16]将统计形状模型应用在医学影像的分割上, 得到了不错的效果.统计形状模型除了分割目标外, 还能提取形状分量、灰度分量、标志点位置等信息, 相比文献[12]中将这三个步骤作为三个独立的问题进行处理, 统计形状模型具有更高的稳定性和实用性.文献[11]中使用了灰度信息建立了纹理模型, 但是2D/3D配准是跨模态的, 灰度信息易受到模态的影响, 而形状信息并不会受到模态的影响, 因此本文采用形状信息建立与投影角度的关系, 即姿态模型.
另一方面, 可以证明6个投影参数, 在选择合理的投影方式下, 其中4个投影参数的效果可以等效为一个仿射变换, 有了标志点的位置, 可以通过几何的方法直接计算出这个仿射变换, 因此姿态模型只需要建立两个投影参数与形状分量的关系.
基于以上考虑, 本文提出了一个结合几何与学习的2D/3D脊椎配准方法, 该方法使用统计形状模型对目标脊椎进行分割并提取形状信息, 在一个本文构建的新的投影方式下, 两个参数通过学习求解, 其余4个投影参数通过几何求解.
本文的主要贡献如下:通过学习的方法建立投影图像与投影参数之间的关系, 构建了一个新的投影变换方式, 使用几何和学习相结合的方法计算投影参数.故而, 本文的方法实时性好, 准确性高, 鲁棒性好.
1. 方法
1.1 总体流程
如图 2所示, 本方法主要包括三个部分.第一部分为建立统计形状模型, 在术前使用训练集的CT图像投影生成2D的DRR (Digitally reconstructed radiograph)图像, 并和X-ray图像一起建立统计形状模型AAM (Active appearance model); 第二部分为建立姿态模型, 在术前对病人的CT图像进行DRR投影, 使用AAM模型分割DRR图像中目标脊椎, 并得到形状参数, 然后建立投影参数与形状参数之间的关系; 第三部分为配准, 在术中, 使用AAM模型对X-ray图像的目标脊椎进行分割, 并得到形状参数, 再使用姿态模型通过形状参数直接得到投影参数, 从而完成配准.
1.2 建立统计形状模型
统计形状模型广泛地应用在医学影像分割当中, 常用的统计形状模型包括ASM (Active shape model)[13]和AAM[14], 其中ASM只对形状信息进行建模, 而AAM不仅对形状信息进行建模同时也对灰度信息进行建模, 因此具有更好的分割性能, 因此本文采用AAM来建立统计形状模型.
本文将3D的CT图像投影成2D的DRR图像, 并对2D的DRR图像和X-ray图像进行AAM建模.为了可以使用同一个统计形状模型来对DRR图像和X-ray进行标志点的定位, 本文将DRR图像和X-ray图像放在一起建立一个统一的AAM模型.
为了提取建立AAM模型所需的标志点, 如图 3所示, 本文对每个样本使用人工提取的方法提取所需的标志点, 并使用普氏分析(Procrustes analysis)[17]将提取的标志点映射到一个共同的坐标系下, 使得每个样本标志点的重心为原点, 并消除平移、放缩、旋转对不同样本标志点的影响.
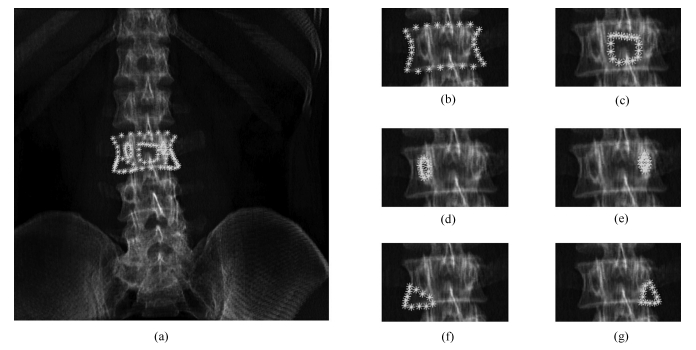 图 3 提取标志点(我们对每幅图像手动提取93个标志点, 所有标志点总体分为6个部分: (a)为所有的标志点, (b)、(c)、(d)、(e)、(f)、(g)为6个部分每个部分的标志点, 其中(b)为椎体轮廓, (c)为中央灰度凹陷, (d)和(e)接近于生理结构的椎弓根, (f)和(g)为椎体左右下切角)Fig. 3 Extract landmarks (We manually extract 93 landmarks for each image, all landmarks are divided into 6 parts, in which (a) contains all landmarks, while (b), (c), (d), (e), (f), (g) contain one of 6 parts, among them, (b) is vertebral body contour, (c) is the central gray depression, (d) and (e) are close to the pedicle of the physiological structure, and (f) and (g) are the left and right bottom of the vertebral body.)
图 3 提取标志点(我们对每幅图像手动提取93个标志点, 所有标志点总体分为6个部分: (a)为所有的标志点, (b)、(c)、(d)、(e)、(f)、(g)为6个部分每个部分的标志点, 其中(b)为椎体轮廓, (c)为中央灰度凹陷, (d)和(e)接近于生理结构的椎弓根, (f)和(g)为椎体左右下切角)Fig. 3 Extract landmarks (We manually extract 93 landmarks for each image, all landmarks are divided into 6 parts, in which (a) contains all landmarks, while (b), (c), (d), (e), (f), (g) contain one of 6 parts, among them, (b) is vertebral body contour, (c) is the central gray depression, (d) and (e) are close to the pedicle of the physiological structure, and (f) and (g) are the left and right bottom of the vertebral body.)1.2.1 形状模型
本文对映射到共同坐标系下的标志点使用PCA (Principal component analysis)得到形状模型(见文献[13]), 每个样本的特征点$x({x_1},{x_2}, \cdots ,{x_n})$可以表示为
$ x = \overline x + {P_s}{b_s} $
(1) 这里是$\overline x $平均形状, $P_s$是对标志点使用PCA得到的一组标准正交基, $b_s$是形状模型参数.
1.2.2 表观模型
我们把对所有的样本进行变形, 使得其特征点变形到平均形状上(使用三角算法)[18].我们把经过形状标准化的图像, 在其形状模型所覆盖的区域进行采样, 并对采样点进行归一化使其均值为0, 方差为1, 以消除亮度的影响, 从而得到$g$.对$g$我们使用PCA得到表观模型[14], 则$g$可以表示为
$ g = \bar g + {P_g}{b_g} $
(2) 这里$\bar{g}$是平均灰度, $P_g$是灰度模型的标准正交基, $b_g$是灰度模型参数.
1.2.3 联合模型
我们将形状模型参数和灰度模型参数串联起来建立一个联合模型.由于形状模型和灰度模型具有不同的量纲, 因此我们对形状模型加一个系数以统一量纲.
$ b = \left[ {\begin{array}{*{20}{c}} {{W_s}{b_s}}\\ {{b_g}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{W_s}P_s^{\rm{T}}(x - \bar x)}\\ {P_g^{\rm{T}}(g - \bar g)} \end{array}} \right] $
(3) 其中, $W_s$是一个对角阵来平衡形状模型和灰度模型参数的量纲(见文献[14]).
为了进一步挖掘形状模型和灰度模型之间相关性, 我们对串联的形状模型和灰度模型参数使用PCA得到联合模型(见文献[14]), 由于形状模型参数和灰度模型参数的均值为0, 所以$b$均值为0, 则有:
$ \hat{b}=Qc $
(4) $Q$是表征模型正交基, $c$是表征模型参数:这样我们可以更直接地使用$c$来表达形状和灰度
$ \hat{x}=\bar{x}+P_s W_s Q_s c, \quad\hat{g}=\bar{g}+P_g Q_g c $
(5) 其中
$ Q= \begin{bmatrix} Q_s\\ Q_g \end{bmatrix} $
(6) 1.2.4 分割模型
建立了形状和灰度的联合统计模型之后, 使用该统计模型对目标进行分割, 分割使用迭代的策略.为了使得分割迭代修正的过程更加高效, 分割模型使用了学习的方法, 使用一个线性模型去学习灰度的偏差与联合统计模型参数的偏移量之间的关系:
$ \delta c=A\delta I $
(7) 为了得到A, 在模型的参数上人为增加一个偏移量$\delta{c}$, 计算增加了偏移量之后图像灰度的变化$\delta I$, 使用多元线性回归来拟合$A$.为了拟合平移$t_x$、$t_y$、旋转$\theta$和尺度$s$的变化带来的变化, 在模型参数上增加额外的4个参数($s_x, s_y, t_x, t_y$), 其中$s_x=s \cos (\theta)$, $s_y=s \sin (\theta)$.同时将原图像的灰度$I$标准化后进行采样得到纹理$g$, 则偏移关系变为
$ \delta c=A\delta g $
(8) 其中
$ \delta g=g_s -g_m $
(9) $g_s$为原图像纹理, ${g}_m$为模型的当前迭代联合统计模型的纹理.
1.3 建立姿态模型
由于病人的CT图像可以在术前得到, 所以可以在术前从病人的CT图像中尽可能地获取信息以辅助术中的配准, 提高术中的配准速度和精度.
本节通过对病人术前CT图像投影生成一系列DRR图像, 并使用AAM模型对目标脊椎进行分割得到其统计模型参数, 从这个参数中得到目标脊椎的形状分量和灰度分量.
为了避免配准搜索的过程, 本节建立了姿态模型, 即脊椎和投影参数之间的关系.由于DRR图像和X-ray图像属于不同的模态, 其灰度信息有一定的差异, 因此用DRR图像的灰度信息建立的姿态模型直接应用于X-ray图像并不合适.考虑到脊椎的形状信息不但受模态的影响小而且与投影参数也有较强的相关性, 所以本文使用形状信息来建立姿态模型.
在投影生成DRR图像时, 如果让CT以一些特定的方式变换, 4个投影参数的作用可以等效为一个仿射变换.这就意味着部分投影参数可被几何变换代替.本文构建了一种新的投影变换, 如图 4所示, ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示方向, $w$轴沿径向方法指向背离圆心的方向.
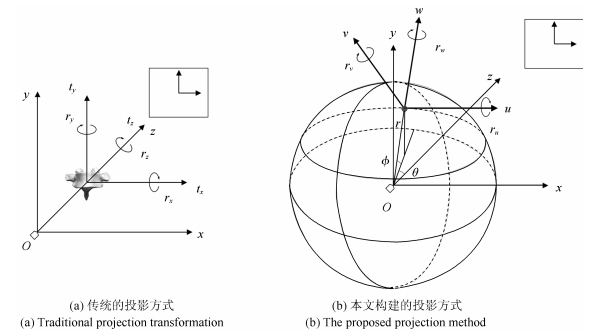 图 4 投影变换((a)图是传统的投影方式, ($x, y, z$)为世界坐标系, ($t_x, t_y, t_z$)是三个平移参数($r_x, r_y, r_z$)为三个旋转参数. (b)图是本文构建的投影方式, ($x, y, z$)为世界坐标系, ($x'O'y'$)为投影平面坐标系, 此坐标系沿世界坐标系$z$轴向投影与($xOy$)重合. ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示所示方向, $w$轴沿径向方法指向背离圆心的方向.)Fig. 4 Projection transformation ((a) is traditional projection transformation, and ($x, y, z$)is world coordinate system, and ($t_x, t_y, t_z$) are three translation parameters, while ($r_x, r_y, r_z$) are three rotation parameters. b) is the proposed projection method. ($x, y, z$) is the world coordinate system, and $x'O'y'$) is the coordinate system of projective plane. This coordinate system coincides with the axial projection of $z$ in the world coordinate system ($xOy$). ($r, \theta, \phi$) are parameters for the spherical coordinate system. ($u, v, w$) is pose projection coordinates of object, and it coact with spherical coordinates as the (b) shows.)
图 4 投影变换((a)图是传统的投影方式, ($x, y, z$)为世界坐标系, ($t_x, t_y, t_z$)是三个平移参数($r_x, r_y, r_z$)为三个旋转参数. (b)图是本文构建的投影方式, ($x, y, z$)为世界坐标系, ($x'O'y'$)为投影平面坐标系, 此坐标系沿世界坐标系$z$轴向投影与($xOy$)重合. ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示所示方向, $w$轴沿径向方法指向背离圆心的方向.)Fig. 4 Projection transformation ((a) is traditional projection transformation, and ($x, y, z$)is world coordinate system, and ($t_x, t_y, t_z$) are three translation parameters, while ($r_x, r_y, r_z$) are three rotation parameters. b) is the proposed projection method. ($x, y, z$) is the world coordinate system, and $x'O'y'$) is the coordinate system of projective plane. This coordinate system coincides with the axial projection of $z$ in the world coordinate system ($xOy$). ($r, \theta, \phi$) are parameters for the spherical coordinate system. ($u, v, w$) is pose projection coordinates of object, and it coact with spherical coordinates as the (b) shows.)为了使问题更加简化且清晰, 本文在对CT投影之前, 先将目标脊椎的中心移动到初始投影位置.对于新的投影方式, 投影过程可以表示为
$ I={ P}({T}(I_{3{\rm D}};r_u, r_v, r_w, r, \theta, \phi )) $
(10) 其中, $I_{3{\rm D}}$为3D图像, $T$为本文构建的三维空间变换, $P$为DRR投影, $I$为投影生成的2D的DRR图像.
由于我们获得X-ray图像生成时, 投影对象距离光源的大致距离$r_0$, 因此可以将$r_0$作为投影的基准值, 实际投影的距离可以表示为$r_0+\delta r$, 这样投影过程可以表示为
$ I={P}({T}(I_{3{\rm D}};r_u, r_v, r_w, r_0 +\delta r, \theta, \phi)) $
(11) 由于$\delta r\ll r_0$, 因此我们可以近似认为$\delta r$的改变所引起的投影图像的变化为一个放缩变换(证明详见附录A).
令
$ I_a={P}({T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0)) $
(12) $ I_c={P}({T}(I_{\rm CT};r_u, r_v, r_w, r_0 +\delta r, \theta, \phi )) $
(13) $x^a$为$I^a$某点的坐标, $x^c$为$I^c$中$x^a$的对应点的坐标, 我们把二维的投影坐标系下的坐标点增广表示在三维的世界坐标系中则有$x^A={bmatrix} x^a\\ {h} {bmatrix}$, $x^C={bmatrix} x^c\\ {h} {bmatrix}$. $h$是光源到投影平面原点的距离.则有(证明过程详见附录A)
$ x^C=kRSx^A $
(14) 其中, $k$为一个系数使得等式右边的第三维为$h$, 且
$ S= \begin{bmatrix} s & 0 & 0\\ 0 & s & 0\\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0\\ - \sin r_w & \cos r_w & 0\\ 0 & 0 & 1 \end{bmatrix} $
(15) $ s=\frac{r_0}{(r_0+\Delta r)} $
(16) 其中
$ R= \begin{bmatrix} \cos \theta & 0 & \sin \theta\\ - \sin \theta & \sin \phi & \cos \theta \cos \phi\\ \sin \theta \sin \phi & \cos \phi & - \cos \theta \sin \phi \end{bmatrix} $
(17) $r_u$和$r_v$是空间的旋转参数, 表示的是脊椎的空间姿态, 我们称之为姿态参数, $r_w, \delta r, \theta, \phi$可以使用一个几何变换代替, 我们称之为几何参数.具有相同姿态参数的DRR图像之间可以使用几何变换(齐次空间下)相互转换, 这就意味着对相同的姿态参数只需要投影生成一张DRR图像, 其他相同姿态参数的DRR图像可以通过几何变换的方法得到.这样需要进行DRR投影的参数空间就可以从O($n^6$)减少为O($n^2$).对于图像上的标志点, 同样可以使用线性变换得到, 需要定位标志点位置的图像空间也可以从O($n^6$)减少为O($n^2$), 这样显著的减少了定位标志点的工作量.
为了学习姿态参数与目标脊椎形状参数之间的关系, 对CT图像生成$n$幅DRR图像.对于$n$幅生成的投影图像, 使用AAM分割目标脊椎并获得$n$组形状参数${\pmb B}=(b_1, b_2, \cdots, b_n)$, 每个投影图像对应的姿态参数为
$ \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} = \begin{bmatrix} r_{u1} & r_{u2} & \cdots & r_{un} \\ r_{v1} & r_{v2} & \cdots & r_{vn} \end{bmatrix} $
本文使用一个线性模型$M$去学习形状参数与姿态参数之间的关系,
$ \begin{equation} \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} =M{\pmb B} \end{equation} $
(18) $ \begin{equation} M= \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} {\pmb B}^{\rm T}({\pmb B}{\pmb B}^{\rm T})^{-1} \end{equation} $
(19) 则$M$即是我们需要的姿态模型.通过该姿态模型, 我们可以使用形状参数直接求出对应的投影姿态参数.给定一幅图像目标脊椎的形状参数$b$, 则其对应的姿态参数为
$ \begin{equation} \begin{bmatrix} r_u \\ r_v \end{bmatrix} =Mb \end{equation} $
(20) 1.4 配准
如图 5所示, 在术前, 针对由CT投影生成的DRR图像, 首先用AAM模型分割目标脊椎得到其形状参数, 然后建立姿态模型, 即形状参数与投影角度之间的关系; 在术中, 先对X-ray图像使用AAM模型分割目标脊椎得到形状参数, 然后通过术前得到的姿态模型求取投影参数.具体如下:
对于术中待配准的X-ray图像$I_{ \mbox{X-ray}}$, 我们使用AAM模型分割目标脊椎(需手动指定初始位置)并获得其形状参数$b_{ \mbox{X-ray}}$, 则其对应的姿态参数为
$ \begin{equation} \begin{bmatrix} r_u \\ r_v \end{bmatrix} =Mb_{ \mbox{X-ray}} \end{equation} $
(21) 获得了姿态参数后, 使用此姿态参数生成对应的DRR图像.利用生成的DRR图像和X-ray图像上标志点的几何变换关系, 我们可以求出几何参数.具体如下:
我们根据得出的姿态参数对目标CT图像$I_{\rm CT}$进行DRR投影, 得到对应的DRR图像$I_{\rm DRR}$, 有:
$ \begin{equation} I_{\rm DRR}={P(T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0)) \end{equation} $
(22) $x_{ \mbox{X-ray}}$是$I_{\mbox{X-ray}}$中一点(齐次坐标下), $x_{\rm DRR}$是$I_{\rm DRR}$中的$x_{ \mbox{X-ray}}$的对应点(齐次坐标下).
$ \begin{equation} x_{ \mbox{X-ray}}=kRSx_{\rm DRR} \end{equation} $
(23) 对于$I_{\mbox{X-ray}}$中目标脊椎的标志点的点集为$X_{ \mbox{X-ray}}$, 和$I_{\rm DRR}$中目标脊椎的标志点的点集为$X_{\rm DRR}$. $X_{ \mbox{X-ray}}$的重心在二维投影平面的坐标为$(cx, cy)$; 由于CT中目标脊椎的中心在投影初始位置, 所以我们可以通过$X_{ \mbox{X-ray}}$重心的位置求出$\theta$和$\phi$,
$ \begin{equation} \theta ={\rm arctan}\left(-\frac{cx}{{h}}\right), \quad \phi={\rm arctan}\left(\frac{cy}{{h}}\right) \end{equation} $
(24) 通过$\theta$和$\phi$我们可以得到$R$, 于是我们可以消除球面旋转的影响:
$ \begin{equation} k^{-1}R^{-1}x_{ \mbox{X-ray}}=Sx_{\rm DRR} \end{equation} $
(25) 此时, 我们只需要求出相似矩阵$S$的旋转系数和放缩系数就可以求出X-ray图像与CT的配准关系.我们使用以下目标函数来求相似矩阵$S$的旋转系数$r_z$和放缩系数$s$.
$ \begin{equation} \begin{aligned} (r_z, s)= \arg \min\limits_{(r_z, s)}\left(\sum\limits_{i=1}^{n}\parallel {k_i}^{-1}R^{-1}x_i-Sy_i\parallel \right), \\ x_i\in X_{ \mbox{X-ray}}, \ y_i\in X_{\rm DRR} \end{aligned} \end{equation} $
(26) 得到$(r_z, s)$之后, 我们可以使用$s$和$r_0$求出$\delta r$
$ \begin{equation} \frac{r_0}{(r_0+\Delta r)}=s\Rightarrow \Delta r=\frac{r_0(1-s)}{s} \end{equation} $
(27) 这样我们就求出了和X-ray相对应的DRR图像的所有投影参数, 即完成了配准.
2. 实验
2.1 实验数据和实验环境
CT数据由北京医院提供. CT采集设备为GE公司的Discovery HD720, CT数据分辨率为0.24 mm × 0.24 mm × 0.7 mm.有6组CT数据和与其对应的冠状面X光图像, 构建统计形状模型时, 本文又同时使用没有对应图像的另外5个CT数据和20个X-ray冠状面图像.处理数据和运行算法是在一台个人电脑上进行的, 配置为Intel(R) Core(TM) i5-2400 CPU @ 3.10 GHz, 4 GB内存.运行算法平台为Matlab R2014b.
2.2 生成DRR投影图像
对于有6组有对应冠状面X-ray图像的CT图像, 本文使用式(7)所示的投影方式, 投影参数$r_u\in(-5^\circ , 5^\circ) $, $r_v\in(-10^\circ , 10^\circ )$, 且以$1°$为间隔, 其他参数$r_w\in(-45^\circ , 45^\circ )$, $\Delta r\in(-50 mm, 50 mm)$, $\theta \in(-10^\circ , 10^\circ )$, $\phi \in(-10^\circ , 10^\circ )$, 在区间内随机指定, 每个CT投影生成$11 \times 21=231$张图像.对于没有对应冠状面X-ray图像的CT, 本文投影参数的范围控制在$r_u\in(-5^\circ , 5^\circ )$, $r_v\in(-10^\circ , 10^\circ )$, $r_w\in(-45^\circ , 45^\circ )$, $\Delta r\in(-50 mm, 50 mm)$, $\theta \in(-10^\circ , 10^\circ )$, $\phi \in(-10^\circ , 10^\circ )$, 在这个投影参数空间中随机投影生成15张DRR图像.在进行DRR投影时, 投影源到投影平面的距离$h=1 000$ mm, 投影对象的初始距离$r_0=500$ mm.
2.3 实验过程
为了充分利用数据, 我们对6组有配套CT和X-ray图像的数据使用留一交叉验证.每次我们使用这6组数据中的5组作为训练集, 剩下的一组作为测试集.我们使用训练集的5组数据和没有对应图像的另外5个CT和20个X-ray数据来建立AAM模型, 使用测试集的CT数据来建立姿态模型, 使用测试集的X-ray数据来与测试集的CT数据进行配准来验证本文方法的性能.
在建立AAM模型时, 本文从每个CT投影生成的DRR图像中随机不重复的抽取15张图像, 并和其他的X-ray图像一起建立AAM模型, 这样用来建立AAM模型的图像共有$(5+5) \times 15+5+20=175$幅图像.我们对每幅图像手动提取93个标志点, 如图 2所示.
在建立姿态模型时, 本文使用测试集的CT投影生成的DRR图像来建立姿态模型.同时为了比较线性模型和更高阶模型如二次、三次、四次模型, 本文也做了对比实验.为了比较$r_u$和$rv$在不同采样间隔下建立的姿态模型的性能, 本文也对1°、2°、3°采样间隔下建立的姿态模型做了对比.
2.4 评价准则
对于最终的配准性能的评价, 本文使用平均目标误差(Mean target register error, mTRE).对X-ray图像和配准得到的其对应的DRR图像, 手动分割出目标脊椎的轮廓, 衡量两个轮廓之间的误差来衡量配准的性能.若$G$为X-ray图像的脊椎轮廓点集, $H$为配准得到的DRR图像的脊椎轮廓的点集, 则$G$和$H$的mTRE为
$ \begin{equation} \begin{aligned} m(G, H)=\frac{\sum\limits_{i=1}^{n}{\rm min}_{j=1}^{m}d(g_i, h_j)}{n}, \\ g_i\in G, h_j\in H \end{aligned} \end{equation} $
(28) 其中, $d(g_i, h_j)$为$g_i$和$h_j$的欧氏距离.
3. 结果
图 6(a)和(b)展示了在建立姿态模型时, 分别使用线性、二次、三次和四次的模型在采样间隔为1°和2°时对$r_u$和$r_v$进行拟合时的预测误差. 图 6(c)和(d)展示了使用线性模型时, 训练样本使用1°、2°、3°采样间隔的$r_u$和$r_v$来进行拟合时的$r_u$和$r_v$的预测误差.其表明相比之下在1°采样间隔和使用线性模型来建立姿态模型时, 具有较好的性能.
 图 6 线性和高阶拟合((a)和(b))与不同采样间隔下预测误差的变化((c)和(d))Fig. 6 The difference of prediction error between linear model and high order model (a), (b) and by difference sampling intervals (c), (d)
图 6 线性和高阶拟合((a)和(b))与不同采样间隔下预测误差的变化((c)和(d))Fig. 6 The difference of prediction error between linear model and high order model (a), (b) and by difference sampling intervals (c), (d)图 7是配准结果, 第一行是每个病人的X-ray图像, 黑线是目标脊椎的轮廓; 第二行是配准后对应的DRR图像, 白线是目标脊椎的轮廓; 第三行是配准结果, 底图是X-ray图像, 黑线是X-ray图像中目标脊椎的轮廓, 白线是DRR中目标脊椎轮廓对应到X-ray图像中的显示.
表 1是每组CT在采样间隔为1°和使用线性模型下的姿态预测误差, 配准的平均轮廓距离和配准(包含分割)所耗费时间, 其中可以看出本文的方法精度较高, 实时性好. 表 2为本文方法与其他方法在配准精度和时间上的对比, 可以看出本文方法具有一定的优越性.
表 1 配准结果Table 1 Results of registration对象 姿态误差ru(°) 姿态误差rv(°) mTRE (mm) 时间(s) PA1 0.92±0.69 0.88±0.71 0.88±0.73 0.96 PA2 0.62±0.51 0.70±0.62 1.13±0.75 0.88 PA3 0.52±0.44 0.70±0.58 1.01±0.62 0.88 PA4 1.43±1.05 1.13±0.92 0.77±0.58 0.89 PA5 0.78±0.61 0.62±0.48 0.73±0.45 0.88 PA6 0.76±0.63 0.81±0.64 0.68±0.46 0.88 平均 0.84 0.81 0.87 0.90 表 2 各种方法对比Table 2 Comparison with other methods作者 方法框架 相似度度量 mTRE (mm) 时间(s) Russakof 基于搜索 互信息 1.3 - Russakof 基于搜索 交叉相关 1.5 - Russakof 基于搜索 梯度相关 1.3 - Russakof 基于搜索 灰度模式 1.6 - Russakof 基于搜索 梯度差 1.3 - Russakof 基于搜索 Diff.图像熵 1.9 - Otake 基于搜索 NGI - 6.3 ~ 54 Philipp 基于学习 纹理 1.05 0.02 本文 基于学习 形状 0.87 0.90 4. 讨论
如图 6所示, 在建立姿态模型时, 本文同时实验了使用线性、二次、三次、四次的模型来拟合姿态模型, 但是其预测结果却并不如简单的线性模型好, 说明形状参数与姿态参数之间具有较好的线性关系, 使用高次的模型反而容易过拟合.同时我们测试了在线性模型下使用不同的采样间隔的预测性能, 在测试范围内的趋势为采样越密集模型的预测性能就越好, 在采样间隔为1°时既能有较好的预测性能又不用生成过多的投影图像.在1°采样间隔下, 使用线性模型的预测平均误差$r_u$仅为0.84°, $r_v$仅为0.81° (表 1), 这说明了用线性模型来回归学习形状参数和姿态参数的关系是有效的.因此本文配准采用的姿态模型为1°采样间隔和线性回归学习下的模型.
表 1展示了拟合姿态模型的误差和配准误差, 可以看出本文使用学习的策略来预测投影姿态的角度误差在0.5°度到1.4°度之间, 平均预测误差$r_u$为0.84°, $r_v$为0.81°.其中第4组数据的误差比较大, 主要在于第4组数据的图像质量明显不如其他的几组数据, 因此其角度误差有明显增大.若除去第4组数据, 投影姿态角度预测误差在0.5°到0.9°之间, 平均为0.72°和0.74°.配准误差在0.6 mm ~ 1.2 mm之间, 平均0.87 mm, 配准速度平均为0.9 s, 可以看出本方法具有精度较高.传统的基于搜索策略的2D/3D配准, 搜索空间的复杂度为O($n^6$), 很难达到实时配准, 而本文的方法仅需要0.9 s, 能够满足实际应用的实时配准需求.
总体来说, 本文使用机器学习的方法, 通过建立姿态模型, 即形状参数与投影角度之间的关系, 来进行2D/3D配准, 避免了繁重的搜索.在计算投影参数时, 使用机器学习和几何变换相结合的方法, 使用几何变换的方法计算出6个投影参数中的4个, 使用机器学习的方法学习剩余的两个, 大大减小了要学习的参数空间.因此, 本方法具有实时性好, 准确性高, 鲁棒性强的优点.本文的配准方法在普通PC配置, 没有GPU加速, 以及使用计算效率并不高的MATLAB且并未对代码进行太多优化的情况下依然能够在1 s以内完成配准, 完全可以达到实时配准.
在建立DRR图像与投影参数的关系时, 本文并没有使用DRR图像的灰度信息作为学习的对象, 而是使用了形状信息, 由于形状信息与投影参数有非常好的线性相关性, 所以能够得到较好的配准结果.在学习投影参数时, 本文使用了新的投影方式, 使直接的投影图像空间和需要定位标志点的图像空间均从O($n^6$)减少到了O($n^2$), 大大减少了术前的工作量.在新的投影方式下, 几何参数和姿态参数相互独立, 因此可以用几何的方法求几何参数, 用学习的方法求姿态参数, 两者之间不会交叉影响, 也使得配准更加有效率, 结果也更准确.
本文的方法是基于分割与标志点的定位之上的, 标志点定位的效果对配准的影响较大, 本文的方法时间开销也主要耗费在分割和标志点定位上, 如果分割和标志点定位能够更加准确、快速, 本文的方法也能够更准确, 实时性更好.
附录. A
本文构建的投影方式可以表示为
$ \begin{equation} I={P(T}(I_{3{\rm D}};r_u, r_v, r_w, r, \theta, \phi )) \end{equation} $
(A1) 对象的姿态坐标系(图 3(b)所示)的基底$\beta$在世界坐标系下的表示为
$ \begin{align} \begin{aligned} \beta _E= & \begin{bmatrix} u & v & w \end{bmatrix} =\nonumber\\ &\begin{bmatrix} \cos \theta & - \sin \theta \cos \phi & \sin \theta \sin \phi \\ 0 & \sin \phi & \cos \phi \\ \sin \theta & \cos \theta \cos \phi & - \cos \theta \sin \phi \end{bmatrix} \end{aligned} \end{align} $
(A2) 在实际的操作中, 由于我们可以得到X-ray投影时投影对象与X-ray光源的大致距离$r_0$, 因此对$I_3D$进行DRR投影时可令$r$的初始值为$r_0$, 而$r$的实际影值可表示为为$r_0+\Delta r$, 投影过程可以表示为
$ \begin{equation} I={P(T}(I_{3{\rm D}};r_u, r_v, r_w, r_0+\Delta r, \theta, \phi )) \end{equation} $
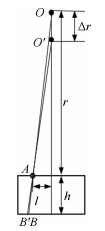
(A3) 由于$\Delta r\ll r_0$, 因此我们可以近似认为$\Delta r$的改变并不引起图像结构的变化.如图A1所示, 从$O$点发出的X-ray射线经过$A$点从$B$点穿出, 当$O$点移动$\Delta r$到$O'$时, X-ray射线经过$A$点从$B'$点穿出.则
$ \begin{equation} BB'=\frac{\Delta rlh}{(r-\Delta r)r} \end{equation} $
(A4) 脊椎的厚度和宽度均远远小于投影距离, 因此$l\ll r, h\ll r$, 有$BB'\approx 0$, 这样可以近似地认为放射源经过$Delta r$的移动经过$A$点在脊椎内部通过的路径并没有发生变化, 即经过$A$点成的像的灰度值没有变化.
由于我们近似地认为$\Delta r$的变化并不引起投影图像的灰度值的变化, 那么$\Delta r$的改变仅引起投影图像大小的变化(A2), 大小的变化可以使用一个放缩变换来代替.
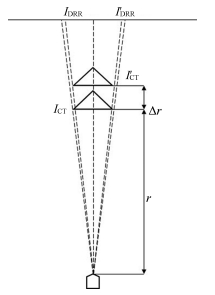 图 A2 $\Delta r$近似等效于相似变换Fig. A2 The effect of $\Delta r$ approximate to similar transformation
图 A2 $\Delta r$近似等效于相似变换Fig. A2 The effect of $\Delta r$ approximate to similar transformation为了方便证明$r_w, \Delta r, \theta, \phi$的改变引起的投影图像的变化可以使用几何变换来代替, 我们将投影变换拆解成3部分(如图A 3所示):
首先, 如图A3(a)所示, 初始化投影对象的位置为球形坐标系中$r=r_0, \theta =0, \phi =0$.然后对投影对象沿$u$轴旋转$r_u$, 沿$v$轴旋转$r_v$.投影过程可以表示为
$ \begin{equation} I^a={P(T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0 )) \end{equation} $
(A5) 如图A3所示, 在图A3(b)的基础上, 对投影对象沿$w$轴旋转$r_w$, 并沿径向方向向外移动$\Delta r$.投影过程可以表示为
$ \begin{equation} I^b={P(T}(I_{\rm CT};r_u, r_v, r_w, r_0+\Delta r, 0, 0 )) \end{equation} $
(A6) 如图A3(c)所示, 在图A3(b)的基础上, 对投影对象沿$x$轴旋转$\theta$, 然后沿$y$轴旋转$\phi$.投影过程可以表示为
$ \begin{equation} I^c={P(T}(I_{\rm CT};r_u, r_v, r_w, r_0+\Delta r, \theta, \phi )) \end{equation} $
(A7) 我们令$x^a$为$I^a$某点的坐标, $x^b$为$I^b$中$x^a$的对应点的坐标, $x^c$为$I^c$中$x^b$的对应点的坐标, 我们把二维的投影坐标系下的坐标点增广到齐次坐标系下则有$x^A={bmatrix} x^a \\ {h} {bmatrix}$, $x^B={bmatrix} x^b \\ {h} {bmatrix}$ $x^C={bmatrix} x^c \\ {h} {bmatrix}$. $h$是光源到投影平面原点的距离.
图A3(b)过程可以使用一个旋转变换和一个放缩变换来代替. $x^A$和$x^B$之间的关系可以表示为
$ \begin{equation} x^B=Sx^A \end{equation} $
(A8) 其中
$ \begin{align} \begin{aligned} &S= \begin{bmatrix} s & 0 & 0 \\ 0 & s & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0 \\ - \sin r_w & \cos r_w & 0 \\ 0 & 0 & 1 \end{bmatrix} , \\ &s=\frac{r_0}{(r_0+\Delta r)} \end{aligned} \end{align} $
(A9) 图A3(c)过程可以等价为成像平面以相同的坐标轴为轴沿相反的方向旋转, 这个过程可以等价为计算机视觉中的相机纯旋转. $x^B$和$x^C$之间的关系可以表示为
$ \begin{equation} x^C=kRx^B \end{equation} $
(A10) 其中
$ \begin{align} \begin{aligned} R= &[E]_{\beta }=([\beta]_E)^{\rm T}=\beta^{\rm T} =\\ &\begin{bmatrix} \cos \theta & 0 & \sin \theta \\ - \sin \theta \cos \phi & \sin \phi & \cos \theta \cos \phi \\ \sin \theta \sin \phi & \cos \theta & - \cos \theta \sin \phi \end{bmatrix} \end{aligned} \end{align} $
(A11) $E$为世界坐标系的基底, $k$为一个平衡系数使得$x^C$的第三维为$h$.
从以上可得:
$ \begin{equation} x^C=kRSx^A \end{equation} $
(A12) 其中
$ \begin{align} \begin{aligned} &S= \begin{bmatrix} s & 0 & 0 \\ 0 & s & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0 \\ - \sin r_w & \cos r_w & 0 \\ 0 & 0 & 1 \end{bmatrix} \\ &s=\frac{r_0}{(r_0+\Delta r)} \end{aligned} \end{align} $
(A13) $ \begin{equation} R= \begin{bmatrix} \cos \theta & 0 & \sin \theta \\ - \sin \theta \cos \phi & \sin \phi & \cos \theta \cos \phi \\ \sin \theta \sin \phi & \cos \theta & - \cos \theta \sin \phi \end{bmatrix} \end{equation} $
(A14)
-
[1] Zhang H G, Zhang X, Luo Y H, Yang J. An overview of research on adaptive dynamic programming. Acta Automatica Sinica, 2013, 39(4):303-311 doi: 10.1016/S1874-1029(13)60031-2 [2] Liu D R, Li H L, Wang D. Data-based self-learning optimal control:research progress and prospects. Acta Automatica Sinica, 2013, 39(11):1858-1870 doi: 10.3724/SP.J.1004.2013.01858 [3] Werbos P. Beyond Regression:New Tools for Prediction and Analysis in the Behavioral Sciences[Ph., D. dissertation], Harvard University, USA, 1974. [4] Prokhorov D V, Wunsch D C. Adaptive critic designs. IEEE Transactions on Neural Networks, 1997, 8(5):997-1007 doi: 10.1109/72.623201 [5] Padhi R, Unnikrishnan N, Wang X H, Balakrishnan S N. A single network adaptive critic (SNAC) architecture for optimal control synthesis for a class of nonlinear systems. Neural Networks, 2006, 19(10):1648-1660 doi: 10.1016/j.neunet.2006.08.010 [6] Wang Y, O'Donoghue B, Boyd S. Approximate dynamic programming via iterated Bellman inequalities. International Journal of Robust and Nonlinear Control, 2015, 25(10):1472-1496 doi: 10.1002/rnc.v25.10 [7] Bertsekas D P, Tsitsiklis J N. Neuro-dynamic programming:an overview. In:Proceedings of the 34th IEEE Conference on Decision and Control. New Orleans, LA, USA:IEEE, 1995. 560-564 [8] Zhu L M, Modares H, Peen G O, Lewis F L, Yue B Z. Adaptive suboptimal output-feedback control for linear systems using integral reinforcement learning. IEEE Transactions on Control Systems Technology, 2015, 23(1):264-273 doi: 10.1109/TCST.2014.2322778 [9] Bhasin S. Reinforcement Learning and Optimal Control Methods for Uncertain Nonlinear Systems[Ph., D. dissertation], University of Florida, USA, 2011. [10] Vrabie D, Vamvoudakis K G, Lewis F L. Optimal Adaptive Control and Differential Games by Reinforcement Learning Principles. London:IET, 2012. [11] Zhang H, Liu D, Luo Y, Wang D. Adaptive Dynamic Programming for Control:Algorithms and Stability. London:Springer-Verlag, 2013. [12] Lewis F L, Liu D R. Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. New Jersey:IEEE Press, 2013. [13] Jiang Z P, Jiang Y. Robust adaptive dynamic programming for linear and nonlinear systems:an overview. European Journal of Control, 2013, 19(5):417-425 doi: 10.1016/j.ejcon.2013.05.017 [14] Khan S G, Herrmann G, Lewis F L, Pipe T, Melhuish C. Reinforcement learning and optimal adaptive control:an overview and implementation examples. Annual Reviews in Control, 2012, 36(1):42-59 doi: 10.1016/j.arcontrol.2012.03.004 [15] Buşoniu L, Ernst D, De Schutter B, Babuška R. Approximate reinforcement learning:an overview. In:Proceedings of the 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning. Paris, France:IEEE, 2011. 1-8 [16] 刁兆师. 导弹精确高效末制导与控制若干关键技术研究[博士学位论文], 北京理工大学, 中国, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10007-1015801403.htmDiao Zhao-Shi. Research on High-precision and High-efficiency Terminal Guidance and Control Key Technologies for Missiles[Ph., D. dissertation], Beijing Institute of Technology, China, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10007-1015801403.htm [17] 李运迁. 大气层内拦截弹制导控制及一体化研究[博士学位论文], 哈尔滨工业大学, 中国, 2011. http://cdmd.cnki.com.cn/Article/CDMD-10213-1012000340.htmLi Yun-Qian. Integrated Guidance and Control for Endo-Atmospheric Interceptors[Ph., D. dissertation], Harbin Institute of Technology, China, 2011. http://cdmd.cnki.com.cn/Article/CDMD-10213-1012000340.htm [18] 孙传鹏. 基于博弈论的拦截制导问题研究[博士学位论文], 哈尔滨工业大学, 中国, 2014. http://cdmd.cnki.com.cn/Article/CDMD-10213-1014081874.htmSun Chuan-Peng. Research on Interception Guidance Based on Game Theory[Ph., D. dissertation], Harbin Institute of Technology, China, 2014. http://cdmd.cnki.com.cn/Article/CDMD-10213-1014081874.htm [19] Liu D R, Wei Q L. Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(3):621-634 doi: 10.1109/TNNLS.2013.2281663 [20] Wei Q L, Liu D R, Lin Q, Song R Z. Discrete-time optimal control via local policy iteration adaptive dynamic programming. IEEE Transactions on Cybernetics, 2016, DOI: 10.1109/TCYB.2016.2586082 [21] Zhang H G, Song R Z, Wei Q L, Zhang T Y. Optimal tracking control for a class of nonlinear discrete-time systems with time delays based on heuristic dynamic programming. IEEE Transactions on Neural Networks, 2011, 22(12):1851-1862 doi: 10.1109/TNN.2011.2172628 [22] Song R Z, Xiao W D, Zhang H G, Sun C Y. Adaptive dynamic programming for a class of complex-valued nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(9):1733-1739 doi: 10.1109/TNNLS.2014.2306201 [23] Wei Q L, Liu D R, Yang X. Infinite horizon self-learning optimal control of nonaffine discrete-time nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(4):866-879 doi: 10.1109/TNNLS.2015.2401334 [24] Wei Q L, Liu D R, Lewis F L, Liu Y, Zhang J. Mixed iterative adaptive dynamic programming for optimal battery energy control in smart residential microgrids. IEEE Transactions on Industrial Electronics, 2017, DOI:10. 1109/TIE.2017.265087 [25] Wei Q L, Liu D R, Lin Q, Song R Z. Adaptive dynamic programming for discrete-time zero-sum games. IEEE Transactions on Neural Networks and Learning Systems, 2017, DOI: 10.1109/TNNLS.2016.2638863 [26] Wei Q L, Liu D R. A novel policy iteration based deterministic Q-learning for discrete-time nonlinear systems. Science China Information Sciences, 2015, 58(12):1-15 doi: 10.1007%2F978-981-10-4080-1_4 [27] Kiumarsi B, Lewis F L, Modares H, Karimpour A, Naghibi-Sistani M B. Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics. Automatica, 2014, 50(4):1167-1175 doi: 10.1016/j.automatica.2014.02.015 [28] Vamvoudakis K G. Non-zero sum Nash Q-learning for unknown deterministic continuous-time linear systems. Automatica, 2015, 61:274-281 doi: 10.1016/j.automatica.2015.08.017 [29] Murray J J, Cox C J, Lendaris G G, Saeks R. Adaptive dynamic programming. IEEE Transactions on Systems, Man, and Cybernetics, Part C:Applications and Reviews, 2002, 32(2):140-153 doi: 10.1109/TSMCC.2002.801727 [30] Al-Tamimi A, Lewis F L, Abu-Khalaf M. Discrete-time nonlinear HJB solution using approximate dynamic programming:convergence proof. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2008, 38(4):943-949 doi: 10.1109/TSMCB.2008.926614 [31] Wang F Y, Jin N, Liu D R, Wei Q L. Adaptive dynamic programming for finite-horizon optimal control of discrete-time nonlinear systems with şvarepsilon-error bound. IEEE Transactions on Neural Networks, 2011, 22(1):24-36 doi: 10.1109/TNN.2010.2076370 [32] Heydari A, Balakrishnan S N. Finite-horizon control-constrained nonlinear optimal control using single network adaptive critics. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(1):145-157 doi: 10.1109/TNNLS.2012.2227339 [33] Wei Q L, Liu D R, Xu Y C. Neuro-optimal tracking control for a class of discrete-time nonlinear systems via generalized value iteration adaptive dynamic programming approach. Soft Computing, 2016, 20(2):697-706 doi: 10.1007/s00500-014-1533-0 [34] Wei Q L, Liu D R, Lin H Q. Value iteration adaptive dynamic programming for optimal control of discrete-time nonlinear systems. IEEE Transactions on Cybernetics, 2016, 46(3):840-853 doi: 10.1109/TCYB.2015.2492242 [35] Wei Q L, Lewis F L, Sun Q Y, Yan P F, Song R Z. Discrete-time deterministic Q-learning:a novel convergence analysis. IEEE Transactions on Cybernetics, 2017, 47(5):1024-0237 http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7450633& [36] Wei Q L, Song R Z, Sun Q Y. Nonlinear neuro-optimal tracking control via stable iterative Q-learning algorithm. Neurocomputing, 2015, 168:520-528 doi: 10.1016/j.neucom.2015.05.075 [37] Wei Q L, Liu D R. Stable iterative adaptive dynamic programming algorithm with approximation errors for discrete-time nonlinear systems. Neural Computing and Applications, 2014, 24(6):1355-1367 doi: 10.1007/s00521-013-1361-7 [38] Wei Q L, Liu D R. Adaptive dynamic programming for optimal tracking control of unknown nonlinear systems with application to coal gasification. IEEE Transactions on Automation Science and Engineering, 2014, 11(4):1020-1036 doi: 10.1109/TASE.2013.2284545 [39] Wei Q L, Liu D R. Numerical adaptive learning control scheme for discrete-time non-linear systems. IET Control Theory and Applications, 2013, 7(11):1472-1486 doi: 10.1049/iet-cta.2012.0486 [40] Wei Q L, Liu D R, Lin Q. Discrete-time local value iteration adaptive dynamic programming:admissibility and termination analysis. IEEE Transactions on Neural Networks and Learning Systems, 2017, DOI:10.1109/TNNLS. 2016.2593743 [41] Wei Q L, Wang F Y, Liu D R, Yang X. Finite-approximation-error-based discrete-time iterative adaptive dynamic programming. IEEE Transactions on Cybernetics, 2014, 44(12):2820-2833 doi: 10.1109/TCYB.2014.2354377 [42] Zhang H G, Luo Y H, Liu D R. Neural-network-based near-optimal control for a class of discrete-time affine nonlinear systems with control constraints. IEEE Transactions on Neural Networks, 2009, 20(9):1490-1503 doi: 10.1109/TNN.2009.2027233 [43] Wei Q L, Zhang H G, Liu D R, Zhao Y. An optimal control scheme for a class of discrete-time nonlinear systems with time delays using adaptive dynamic programming. Acta Automatica Sinica, 2010, 36(1):121-129 http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.669.1013&rep=rep1&type=pdf [44] Song R Z, Wei Q L, Sun Q Y. Nearly finite-horizon optimal control for a class of nonaffine time-delay nonlinear systems based on adaptive dynamic programming. Neurocomputing, 2015, 156:166-175 doi: 10.1016/j.neucom.2014.12.066 [45] Wang D, Liu D R, Wei Q L. Finite-horizon neuro-optimal tracking control for a class of discrete-time nonlinear systems using adaptive dynamic programming approach. Neurocomputing, 2012, 78(1):14-22 doi: 10.1016/j.neucom.2011.03.058 [46] Abu-Khalaf M, Lewis F L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica, 2005, 41(5):779-791 doi: 10.1016/j.automatica.2004.11.034 [47] Tassa Y, Erez T. Least squares solutions of the HJB equation with neural network value-function approximators. IEEE Transactions on Neural Networks, 2007, 18(4):1031-1041 doi: 10.1109/TNN.2007.899249 [48] Song R Z, Lewis F L, Wei Q L, Zhang H G. Off-policy actor-critic structure for optimal control of unknown systems with disturbances. IEEE Transactions on Cybernetics, 2016, 46(5):1041-1050 doi: 10.1109/TCYB.2015.2421338 [49] Song R Z, Lewis F L, Wei Q L. Off-policy integral reinforcement learning method to solve nonlinear continuous-time multiplayer nonzero-sum games. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3):704-713 doi: 10.1109/TNNLS.2016.2582849 [50] Vrabie D, Pastravanu O, Abu-Khalaf M, Lewis F L. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica, 2009, 45(2):477-484 doi: 10.1016/j.automatica.2008.08.017 [51] Vrabie D, Lewis F. Neural network approach to continuous-time direct adaptive optimal control for partially unknown nonlinear systems. Neural Networks, 2009, 22(3):237-246 doi: 10.1016/j.neunet.2009.03.008 [52] Vamvoudakis K G, Lewis F L. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica, 2010, 46(5):878-888 doi: 10.1016/j.automatica.2010.02.018 [53] Vamvoudakis K G, Vrabie D, Lewis F L. Online adaptive learning of optimal control solutions using integral reinforcement learning. In:Proceedings of the 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning. Paris, France:IEEE, 2011. 250-257 [54] Zhang H G, Cui L L, Zhang X, Luo Y H. Data-driven robust approximate optimal tracking control for unknown general nonlinear systems using adaptive dynamic programming method. IEEE Transactions on Neural Networks, 2011, 22(12):2226-2236 doi: 10.1109/TNN.2011.2168538 [55] Liu D R, Yang X, Wang D, Wei Q L. Reinforcement-learning-based robust controller design for continuous-time uncertain nonlinear systems subject to input constraints. IEEE Transactions on Cybernetics, 2015, 45(7):1372-1385 doi: 10.1109/TCYB.2015.2417170 [56] Yang X, Liu D R, Huang Y Z. Neural-network-based online optimal control for uncertain non-linear continuous-time systems with control constraints. IET Control Theory and Applications, 2013, 7(17):2037-2047 doi: 10.1049/iet-cta.2013.0472 [57] Wang D, Liu D R, Zhang Q C, Zhao D B. Data-based adaptive critic designs for nonlinear robust optimal control with uncertain dynamics. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2016, 46(11):1544-1555 doi: 10.1109/TSMC.2015.2492941 [58] Wang D, Liu D R, Li H L. Policy iteration algorithm for online design of robust control for a class of continuous-time nonlinear systems. IEEE Transactions on Automation Science and Engineering, 2014, 11(2):627-632 doi: 10.1109/TASE.2013.2296206 [59] Wang D, Liu D R, Li H L, Ma H W. Neural-network-based robust optimal control design for a class of uncertain nonlinear systems via adaptive dynamic programming. Information Sciences, 2014, 282:167-179 doi: 10.1016/j.ins.2014.05.050 [60] Vamvoudakis K, Vrabie D, Lewis F. Online policy iteration based algorithms to solve the continuous-time infinite horizon optimal control problem. In:Proceedings of the 2009 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning. Nashville, TN, USA:IEEE, 2009. [61] Yang X, Liu D R, Wei Q L. Online approximate optimal control for affine non-linear systems with unknown internal dynamics using adaptive dynamic programming. IET Control Theory and Applications, 2014, 8(16):1676-1688 doi: 10.1049/iet-cta.2014.0186 [62] Wang Z, Liu X P, Liu K F, Li S, Wang H Q. Backstepping-based Lyapunov function construction using approximate dynamic programming and sum of square techniques. IEEE Transactions on Cybernetics, 2016, DOI: 10.1109/TCYB.2016.2574747 [63] Vamvoudakis K G, Miranda M F, Hespanha J P. Asymptotically stable adaptive-optimal control algorithm with saturating actuators and relaxed persistence of excitation. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(11):2386-2398 doi: 10.1109/TNNLS.2015.2487972 [64] Yang X, Liu D R, Wei Q L, Wang D. Guaranteed cost neural tracking control for a class of uncertain nonlinear systems using adaptive dynamic programming. Neurocomputing, 2016, 198:80-90 doi: 10.1016/j.neucom.2015.08.119 [65] Zargarzadeh H, Dierks T, Jagannathan S. State and output feedback-based adaptive optimal control of nonlinear continuous-time systems in strict feedback form. In:Proceedings of the 2012 American Control Conference. Montréal, Canada:IEEE, 2012. 6412-6417 [66] Zargarzadeh H, Dierks T, Jagannathan S. Optimal control of nonlinear continuous-time systems in strict-feedback form. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(10):2535-2549 doi: 10.1109/TNNLS.2015.2441712 [67] Modares H, Lewis F L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica, 2014, 50(7):1780-1792 doi: 10.1016/j.automatica.2014.05.011 [68] Kamalapurkar R, Dinh H, Bhasin S, Dixon W E. Approximate optimal trajectory tracking for continuous-time nonlinear systems. Automatica, 2015, 51:40-48 doi: 10.1016/j.automatica.2014.10.103 [69] Zhou Q, Shi P, Tian Y, Wang M Y. Approximation-based adaptive tracking control for mimo nonlinear systems with input saturation. IEEE Transactions on Cybernetics, 2015, 45(10):2119-2128 doi: 10.1109/TCYB.2014.2365778 [70] Modares H, Lewis F L, Sistani M B N. Online solution of nonquadratic two-player zero-sum games arising in the H∞ control of constrained input systems. International Journal of Adaptive Control and Signal Processing, 2014, 28(3-5):232-254 doi: 10.1002/acs.v28.3-5 [71] Modares H, Sistani M B N, Lewis F L. A policy iteration approach to online optimal control of continuous-time constrained-input systems. ISA Transactions, 2013, 52(5):611-621 doi: 10.1016/j.isatra.2013.04.004 [72] Abu-Khalaf M, Lewis F L, Huang J. Neurodynamic programming and zero-sum games for constrained control systems. IEEE Transactions on Neural Networks, 2008, 19(7):1243-1252 doi: 10.1109/TNN.2008.2000204 [73] Yang X, Liu D R, Wang D. Reinforcement learning for adaptive optimal control of unknown continuous-time nonlinear systems with input constraints. International Journal of Control, 2014, 87(3):553-566 doi: 10.1080/00207179.2013.848292 [74] Jiang Y, Jiang Z P. Computational adaptive optimal control for continuous-time linear systems with completely unknown dynamics. Automatica, 2012, 48(10):2699-2704 doi: 10.1016/j.automatica.2012.06.096 [75] Jiang Y, Jiang Z P. Robust approximate dynamic programming and global stabilization with nonlinear dynamic uncertainties. In:Proceedings of the 50th IEEE Conference on Decision and Control and European Control Conference. Orlando, FL, USA:IEEE, 2011. 115-120 [76] Jiang Y, Jiang Z P. Robust adaptive dynamic programming and feedback stabilization of nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(5):882-893 doi: 10.1109/TNNLS.2013.2294968 [77] Jiang Y, Jiang Z P. Global adaptive dynamic programming for continuous-time nonlinear systems. IEEE Transactions on Automatic Control, 2015, 60(11):2917-2929 doi: 10.1109/TAC.2015.2414811 [78] Wang D, Liu D R, Li H L, Ma H W. Adaptive dynamic programming for infinite horizon optimal robust guaranteed cost control of a class of uncertain nonlinear systems. In:Proceedings of the 2015 American Control Conference. Chicago, IL, USA:IEEE, 2015. 2900-2905 [79] Luo Y H, Sun Q Y, Zhang H G, Cui L L. Adaptive critic design-based robust neural network control for nonlinear distributed parameter systems with unknown dynamics. Neurocomputing, 2015, 148:200-208 doi: 10.1016/j.neucom.2013.08.049 [80] Fan Q Y, Yang G H. Adaptive actor-critic design-based integral sliding-mode control for partially unknown nonlinear systems with input disturbances. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(1):165-177 doi: 10.1109/TNNLS.2015.2472974 [81] Liu D R, Huang Y Z, Wang D, Wei Q L. Neural-network-observer-based optimal control for unknown nonlinear systems using adaptive dynamic programming. International Journal of Control, 2013, 86(9):1554-1566 doi: 10.1080/00207179.2013.790562 [82] Lv Y F, Na J, Yang Q M, Wu X, Guo Y. Online adaptive optimal control for continuous-time nonlinear systems with completely unknown dynamics. International Journal of Control, 2016, 89(1):99-112 doi: 10.1080/00207179.2015.1060362 [83] Zhu Y H, Zhao D B, Li X J. Iterative adaptive dynamic programming for solving unknown nonlinear zero-sum game based on online data. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3):714-724 doi: 10.1109/TNNLS.2016.2561300 [84] Song R Z, Lewis F L, Wei Q L, Zhang H G, Jiang Z P, Levine D. Multiple actor-critic structures for continuous-time optimal control using input-output data. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(4):851-865 doi: 10.1109/TNNLS.2015.2399020 [85] Vamvoudakis K, Vrabie D, Lewis F L. Adaptive optimal control algorithm for zero-sum Nash games with integral reinforcement learning. In:Proceedings of the 2012 AIAA Guidance, Navigation, and Control Conference. Minneapolis, Minnesota, USA:AIAA, 2012. [86] Wei Q L, Song R Z, Yan P F. Data-driven zero-sum neuro-optimal control for a class of continuous-time unknown nonlinear systems with disturbance using ADP. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(2):444-458 doi: 10.1109/TNNLS.2015.2464080 [87] Vamvoudakis K G, Lewis F L. Multi-player non-zero-sum games:online adaptive learning solution of coupled Hamilton-Jacobi equations. Automatica, 2011, 47(8):1556-1569 doi: 10.1016/j.automatica.2011.03.005 [88] Vamvoudakis K G, Lewis F L, Hudas G R. Multi-agent differential graphical games:online adaptive learning solution for synchronization with optimality. Automatica, 2012, 48(8):1598-1611 doi: 10.1016/j.automatica.2012.05.074 [89] Wei Q L, Liu D R, Lewis F L. Optimal distributed synchronization control for continuous-time heterogeneous multi-agent differential graphical games. Information Sciences, 2015, 317:96-113 doi: 10.1016/j.ins.2015.04.044 [90] Zhang H G, Zhang J L, Yang G H, Luo Y H. Leader-based optimal coordination control for the consensus problem of multiagent differential games via fuzzy adaptive dynamic programming. IEEE Transactions on Fuzzy Systems, 2015, 23(1):152-163 doi: 10.1109/TFUZZ.2014.2310238 [91] Nguyen T L. Adaptive dynamic programming-based design of integrated neural network structure for cooperative control of multiple MIMO nonlinear systems. Neurocomputing, 2017, 237:12-24 doi: 10.1016/j.neucom.2016.05.044 [92] Jiao Q, Modares H, Xu S Y, Lewis F L, Vamvoudakis K G. Multi-agent zero-sum differential graphical games for disturbance rejection in distributed control. Automatica, 2016, 69:24-34 doi: 10.1016/j.automatica.2016.02.002 [93] Jiao Q, Modares H, Lewis F L, Xu S Y, Xie L H. Distributed L2-gain output-feedback control of homogeneous and heterogeneous systems. Automatica, 2016, 71:361-368 doi: 10.1016/j.automatica.2016.04.025 [94] Adib Yaghmaie F, Lewis F L, Su R. Output regulation of linear heterogeneous multi-agent systems via output and state feedback. Automatica, 2016, 67:157-164 doi: 10.1016/j.automatica.2016.01.040 [95] Zhang H G, Jiang H, Luo Y H, Xiao G Y. Data-driven optimal consensus control for discrete-time multi-agent systems with unknown dynamics using reinforcement learning method. IEEE Transactions on Industrial Electronics, 2017, 64(5):4091-4100 doi: 10.1109/TIE.2016.2542134 [96] Venayagamoorthy G K, Harley R G, Wunsch D C. Dual heuristic programming excitation neurocontrol for generators in a multimachine power system. IEEE Transactions on Industry Applications, 2003, 39(2):382-394 doi: 10.1109/TIA.2003.809438 [97] Park J W, Harley R G, Venayagamoorthy G K. Adaptive-critic-based optimal neurocontrol for synchronous generators in a power system using MLP/RBF neural networks. IEEE Transactions on Industry Applications, 2003, 39(5):1529-1540 doi: 10.1109/TIA.2003.816493 [98] Wei Q L, Liu D R, Shi G, Liu Y. Multibattery optimal coordination control for home energy management systems via distributed iterative adaptive dynamic programming. IEEE Transactions on Industrial Electronics, 2015, 62(7):4203-4214 doi: 10.1109/TIE.2014.2388198 [99] Wei Q L, Liu D R, Shi G. A novel dual iterative Q-learning method for optimal battery management in smart residential environments. IEEE Transactions on Industrial Electronics, 2015, 62(4):2509-2518 doi: 10.1109/TIE.2014.2361485 [100] Cai C, Wong C K, Heydecker B G. Adaptive traffic signal control using approximate dynamic programming. Transportation Research Part C:Emerging Technologies, 2009, 17(5):456-474 doi: 10.1016/j.trc.2009.04.005 [101] 赵冬斌, 刘德荣, 易建强.基于自适应动态规划的城市交通信号优化控制方法综述.自动化学报, 2009, 35(6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtmlZhao Dong-Bin, Liu De-Rong, Yi Jian-Qiang. An overview on the adaptive dynamic programming based urban city traffic signal optimal control. Acta Automatica Sinica, 2009, 35(6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtml [102] Wang F Y. Agent-based control for networked traffic management systems. IEEE Intelligent Systems, 2005, 20(5):92-96 doi: 10.1109/MIS.2005.80 [103] Lee J M, Lee J H. An approximate dynamic programming based approach to dual adaptive control. Journal of Process Control, 2009, 19(5):859-864 doi: 10.1016/j.jprocont.2008.11.009 [104] Wei Q L, Liu D R. Data-driven neuro-optimal temperature control of water-gas shift reaction using stable iterative adaptive dynamic programming. IEEE Transactions on Industrial Electronics, 2014, 61(11):6399-6408 doi: 10.1109/TIE.2014.2301770 [105] 林小峰, 黄元君, 宋春宁.带şvarepsilon误差限的近似最优控制.控制理论与应用, 2012, 29(1):104-108 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201201017.htmLin Xiao-Feng, Huang Yuan-Jun, Song Chun-Ning. Approximate optimal control with şvarepsilon-error bound. Control Theory and Applications, 2012, 29(1):104-108 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201201017.htm [106] Nodland D, Zargarzadeh H, Jagannathan S. Neural network-based optimal adaptive output feedback control of a helicopter UAV. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(7):1061-1073 doi: 10.1109/TNNLS.2013.2251747 [107] Stingu E, Lewis F L. An approximate dynamic programming based controller for an underactuated 6DOF quadrotor. In:Proceedings of the 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning. Paris, France:IEEE, 2011. [108] Xie Q Q, Luo B, Tan F X, Guan X P. Optimal control for vertical take-off and landing aircraft non-linear system by online kernel-based dual heuristic programming learning. IET Control Theory and Applications, 2015, 9(6):981-987 doi: 10.1049/iet-cta.2013.0889 [109] Mu C X, Ni Z, Sun C Y, He H B. Air-breathing hypersonic vehicle tracking control based on adaptive dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3):584-598 doi: 10.1109/TNNLS.2016.2516948 [110] Balakrishnan S N, Biega V. Adaptive-critic-based neural networks for aircraft optimal control. Journal of Guidance, Control, and Dynamics, 1996, 19(4):893-898 doi: 10.2514/3.21715 [111] Enns R, Si J. Apache helicopter stabilization using neural dynamic programming. Journal of Guidance, Control, and Dynamics, 2002, 25(1):19-25 doi: 10.2514/2.4870 [112] Enns R, Si J. Helicopter trimming and tracking control using direct neural dynamic programming. IEEE Transactions on Neural Networks, 2003, 14(4):929-939 doi: 10.1109/TNN.2003.813839 [113] Ferrari S, Stengel R F. Online adaptive critic flight control. Journal of Guidance, Control, and Dynamics, 2004, 27(5):777-786 doi: 10.2514/1.12597 [114] Valasek J, Doebbler J, Tandale M D, Meade A J. Improved adaptive-reinforcement learning control for morphing unmanned air vehicles. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2008, 38(4):1014-1020 doi: 10.1109/TSMCB.2008.922018 [115] Guo C, Wu H N, Luo B, Guo L. H∞ control for air-breathing hypersonic vehicle based on online simultaneous policy update algorithm. International Journal of Intelligent Computing and Cybernetics, 2013, 6(2):126-143 doi: 10.1108/IJICC-Jun-2012-0031 [116] Luo X, Chen Y, Si J, Feng L. Longitudinal control of hypersonic vehicles based on direct heuristic dynamic programming using ANFIS. In:Proceedings of the 2014 International Joint Conference on Neural Networks. Beijing, China:IEEE, 2014. 3685-3692 [117] Furfaro R, Wibben D R, Gaudet B, Simo J. Terminal multiple surface sliding guidance for planetary landing:development, tuning and optimization via reinforcement learning. The Journal of the Astronautical Sciences, 2015, 62(1):73-99 doi: 10.1007/s40295-015-0045-1 [118] Zhou Y, Van Kampen E J, Chu Q P. Nonlinear adaptive flight control using incremental approximate dynamic programming and output feedback. Journal of Guidance, Control, and Dynamics, 2017, 40(S):493-500 https://www.researchgate.net/publication/310781464_Nonlinear_Adaptive_Flight_Control_Using_Incremental_Approximate_Dynamic_Programming_and_Output_Feedback [119] Zhou Y, Van Kampen E J, Chu Q P. An incremental approximate dynamic programming flight controller based on output feedback. In:Proceedings of the 2016 AIAA Guidance, Navigation, and Control Conference. San Diego, California, USA:AIAA, 2016. [120] Ghosh S, Ghose D, Raha S. Capturability of augmented pure proportional navigation guidance against time-varying target maneuvers. Journal of Guidance, Control, and Dynamics, 2014, 37(5):1446-1461 doi: 10.2514/1.G000561 [121] Shaferman V, Shima T. Linear quadratic guidance laws for imposing a terminal intercept angle. Journal of Guidance, Control, and Dynamics, 2008, 31(5):1400-1412 doi: 10.2514/1.32836 [122] Lee Y, Kim Y, Moon G, Jun B E. Sliding-mode-based missile-integrated attitude control schemes considering velocity change. Journal of Guidance, Control, and Dynamics, 2016, 39(3):423-436 doi: 10.2514/1.G001416 [123] Kumar S R, Rao S, Ghose D. Nonsingular terminal sliding mode guidance with impact angle constraints. Journal of Guidance, Control, and Dynamics, 2014, 37(4):1114-1130 doi: 10.2514/1.62737 [124] 周慧波. 基于有限时间和滑模理论的导引律及多导弹协同制导研究[博士学位论文], 哈尔滨工业大学, 中国, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10213-1015957301.htmZhou Hui-Bo. Study on Guidance Law and Cooperative Guidance for Multi-missiles Based on Finite-time and Sliding Mode Theory[Ph., D. dissertation], Harbin Institute of Technology, China, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10213-1015957301.htm [125] 张友安, 黄诘, 王丽英.约束条件下的末制导律研究进展.海军航空工程学院学报, 2013, 28(6):581-586 http://www.cnki.com.cn/Article/CJFDTOTAL-HJHK201306001.htmZhang You-An, Huang Jie, Wang Li-Ying. Research progress of terminal guidance law with constraint. Journal of Naval Aeronautical and Astronautical, 2013, 28(6):581-586 http://www.cnki.com.cn/Article/CJFDTOTAL-HJHK201306001.htm [126] Imado F, Kuroda T, Miwa S. Optimal midcourse guidance for medium-range air-to-air missiles. Journal of Guidance, Control, and Dynamics, 1990, 13(4):603-608 doi: 10.2514/3.25376 [127] Balakrishnan S N, Xin M. Robust state dependent Riccati equation based guidance laws. In:Proceedings of the 2001 American Control Conference. Arlington, VA, USA:IEEE, 2001. 3352-3357 [128] Indig N, Ben-Asher J Z, Sigal E. Near-optimal minimum-time guidance under spatial angular constraint in atmospheric flight. Journal of Guidance, Control, and Dynamics, 2016, 39(7):1563-1577 doi: 10.2514/1.G001485 [129] Taub I, Shima T. Intercept angle missile guidance under time varying acceleration bounds. Journal of Guidance, Control, and Dynamics, 2013, 36(3):686-699 doi: 10.2514/1.59139 [130] 陈克俊, 赵汉元.一种适用于攻击地面固定目标的最优再入机动制导律.宇航学报, 1994, 15(1):1-7, 94 http://www.cnki.com.cn/Article/CJFDTOTAL-YHXB401.000.htmChen Ke-Jun, Zhao Han-Yuan. An optimal reentry maneuver guidance law applying to attack the ground fixed target. Journal of Astronautics, 1994, 15(1):1-7, 94 http://www.cnki.com.cn/Article/CJFDTOTAL-YHXB401.000.htm [131] 赵汉元.飞行器再入动力学和制导.北京:国防科技大学出版社, 1997.Zhao Han-Yuan. Reentry Vehicle Dynamics and Guidance. Beijing:National University of Defense Technology, 1997. [132] Lee Y I, Ryoo C K, Kim E. Optimal guidance with constraints on impact angle and terminal acceleration. In:Proceedings of the 2003 AIAA Guidance, Navigation, and Control Conference and Exhibit. Austin, Texas, USA:AIAA, 2003. [133] Lee J I, Jeon I S, Tahk M J. Guidance law to control impact time and angle. IEEE Transactions on Aerospace and Electronic Systems, 2007, 43(1):301-310 doi: 10.1109/TAES.2007.357135 [134] 胡正东, 郭才发, 蔡洪.带落角约束的再入机动弹头的复合导引律.国防科技大学学报, 2008, 30(3):21-26 http://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ200803004.htmHu Zheng-Dong, Guo Cai-Fa, Cai Hong. Integrated guidance law of reentry maneuvering warhead with terminal angular constraint. Journal of National University of Defense Technology, 2008, 30(3):21-26 http://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ200803004.htm [135] Bardhan R, Ghose D. Nonlinear differential games-based impact-angle-constrained guidance law. Journal of Guidance, Control, and Dynamics, 2015, 38(3):384-402 doi: 10.2514/1.G000940 [136] 方绍琨, 李登峰.微分对策及其在军事领域的研究进展.指挥控制与仿真, 2008, 30(1):114-117 http://www.cnki.com.cn/Article/CJFDTOTAL-QBZH200801032.htmFang Shao-Kun, Li Deng-Feng. Research advances on differential games and applications to military field. Command Control and Simulation, 2008, 30(1):114-117 http://www.cnki.com.cn/Article/CJFDTOTAL-QBZH200801032.htm [137] Yang C D, Chen H Y. Nonlinear H∞ robust guidance law for homing missiles. Journal of Guidance, Control, and Dynamics, 1998, 21(6):882-890 doi: 10.2514/2.4321 [138] Dalton J, Balakrishnan S N. A neighboring optimal adaptive critic for missile guidance. Mathematical and Computer Modelling, 1996, 23(1-2):175-188 doi: 10.1016/0895-7177(95)00226-X [139] Han D C, Balakrishnan S N. Adaptive critic based neural networks for control-constrained agile missile control. In:Proceedings of the 1999 American Control Conference. San Diego, California, USA:IEEE, 1999. 2600-2604 [140] Si J, Barto A, Powell W, Wunsch D. Adaptive Critic Based Neural Network for Control-Constrained Agile Missile. New Jersey:John Wiley and Sons, Inc., 2012. [141] Han D C, Balakrishnan S. Midcourse guidance law with neural networks. In:Proceedings of the 2000 AIAA Guidance, Navigation, and Control Conference and Exhibit. Denver, CO, USA:AIAA, 2000. [142] Han D C, Balakrishnan S N. State-constrained agile missile control with adaptive-critic-based neural networks. IEEE Transactions on Control Systems Technology, 2002, 10(4):481-489 doi: 10.1109/TCST.2002.1014669 [143] Bertsekas D P, Homer M L, Logan D A, Patek S D, Sandell N R. Missile defense and interceptor allocation by neuro-dynamic programming. IEEE Transactions on Systems, Man, and Cybernetics, Part A:Systems and Humans, 2000, 30(1):42-51 doi: 10.1109/3468.823480 [144] Davis M T, Robbins M J, Lunday B J. Approximate dynamic programming for missile defense interceptor fire control. European Journal of Operational Research, 2017, 259(3):873-886 doi: 10.1016/j.ejor.2016.11.023 [145] Lin C K. Adaptive critic autopilot design of bank-to-turn missiles using fuzzy basis function networks. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2005, 35(2):197-207 doi: 10.1109/TSMCB.2004.842246 [146] 卢超群, 江加和, 任章.基于增强学习的空空导弹智能精确制导律研究.战术导弹控制技术, 2006, (4):19-22, 76 http://d.wanfangdata.com.cn/Periodical/zsddkzjs200604007Lu Chao-Qun, Jiang Jia-He, Ren Zhang. Research of precision guidance law based on Q-learning for air-to-air missile. Control Technology of Tactical Missile, 2006, (4):19-22, 76 http://d.wanfangdata.com.cn/Periodical/zsddkzjs200604007 [147] McGrew J S, How J P, Bush L, Williams B, Roy N. Air combat strategy using approximate dynamic programming. In:Proceedings of the 2008 AIAA Guidance, Navigation and Control Conference and Exhibit. Honolulu, Hawaii, USA:AIAA, 2008. [148] Gaudet B, Furfaro R. Missile homing-phase guidance law design using reinforcement learning. In:Proceedings of the 2012 AIAA Guidance, Navigation, and Control Conference. Minneapolis, Minnesota, USA:AIAA, 2012. [149] Lee D, Bang H. Planar evasive aircrafts maneuvers using reinforcement learning. Intelligent Autonomous Systems 12:Advances in Intelligent Systems and Computing. Berlin Heidelberg:Springer, 2013. 533-542 [150] Sun J L, Liu C S, Ye Q. Robust differential game guidance laws design for uncertain interceptor-target engagement via adaptive dynamic programming. International Journal of Control, 2017, 64(5):4091-4100 https://www.researchgate.net/publication/283513965_Robust_Adaptive_Dynamic_Programming_of_Two-Player_Zero-Sum_Games_for_Continuous-Time_Linear_Systems [151] 姚郁, 郑天宇, 贺风华, 王龙, 汪洋, 张曦, 朱柏羊, 杨宝庆.飞行器末制导中的几个热点问题与挑战.航空学报, 2015, 36(8):2696 http://www.cnki.com.cn/Article/CJFDTOTAL-HKXB201508020.htmYao Yu, Zheng Tian-Yu, He Feng-Hua, Wang Long, Wang Yang, Zhang Xi, Zhu Bai-Yang, Yang Bao-Qing. Several hot issues and challenges in terminal guidance of flight vehicles. Acta Aeronautica et Astronautica Sinica, 2015, 36(8):2696-2716 http://www.cnki.com.cn/Article/CJFDTOTAL-HKXB201508020.htm 期刊类型引用(28)
1. 陈文雪,胡玉东,高长生,荆武兴,安若铭. 拦截高超声速滑翔飞行器:制导进展与展望. 宇航学报. 2024(06): 799-814 .  百度学术
百度学术2. 吕振瑞,沈欣,李少博,田鹏,司迎利. 基于深度强化学习的来袭导弹智能拦截与平台机动策略优化技术. 航空兵器. 2024(05): 56-66 . 百度学术3. 朱建全,朱文凯,刘海欣,陈嘉俊,曾恺,刘明波. 近似动态规划在电力系统优化运行中的应用综述. 电力系统自动化. 2024(22): 1-21 . 百度学术4. 杨秀霞,姜子劼,张毅,王聪. 针对机动目标的三维实时滚动优化制导策略. 系统工程与电子技术. 2023(02): 546-558 . 百度学术5. 杨豪,余渝生,王志城,孙永岩,刘艳阳,林欣,黄鹏辉,邹子豪. 复杂运动下弹载雷达杂波建模方法. 上海航天(中英文). 2023(01): 94-103+116 . 百度学术6. 刘双喜,闫斌斌,黄伟,张旭,闫杰. 拦截临近空间高超声速飞行器末制导律研究进展与展望(英文). Journal of Zhejiang University-Science A(Applied Physics & Engineering). 2023(05): 387-404 . 百度学术7. 王子瑶,唐胜景,郭杰,阎宏磊,葛健豪. 高超声速攻防博弈自适应微分对策三维制导. 兵工学报. 2023(08): 2342-2353 . 百度学术8. 袁斐然,刘春生,陈必露. 基于自适应动态规划的多对一追逃博弈策略. 电光与控制. 2022(01): 1-6 . 百度学术9. 陈必露,刘春生,袁斐然. 基于微分对策的鲁棒导弹自动驾驶仪设计. 电光与控制. 2022(01): 70-74+104 . 百度学术10. 陈必露,刘春生,高煜欣. 输入受限下的鲁棒微分博弈拦截制导律设计. 飞行力学. 2022(03): 57-64 . 百度学术11. 郭建国,胡冠杰,郭宗易,王国庆. 天线罩误差下基于ADP的机动目标拦截制导策略. 宇航学报. 2022(07): 911-920 . 百度学术12. 郭宗易,杨晓宏,胡冠杰,郭建国,王国庆. 落角与视场约束制导控制一体化策略. 宇航学报. 2022(12): 1676-1685 . 百度学术13. 梁小辉,胡昌华,周志杰,王青. 基于自适应动态规划的运载火箭智能姿态容错控制. 航空学报. 2021(04): 511-524 . 百度学术14. 雷虎民,骆长鑫,周池军,王华吉,邵雷. 临近空间防御作战拦截弹制导与控制关键技术综述. 航空兵器. 2021(02): 1-10 . 百度学术15. 袁斐然,刘春生,吴翔. 基于ADP的预定性能导引控制一体化设计. 飞行力学. 2021(04): 61-67+74 . 百度学术16. 唐志国,张富尧,马彦. 基于自适应动态规划的移动装弹机械臂轨迹控制. 控制理论与应用. 2021(09): 1442-1451 . 百度学术17. 刘富,安毅,董博,李元春. 基于ADP的可重构机械臂能耗保代价分散最优控制. 吉林大学学报(工学版). 2020(01): 342-350 . 百度学术18. 南英,蒋亮. 基于深度强化学习的弹道导弹中段突防控制. 指挥信息系统与技术. 2020(04): 1-9+27 . 百度学术19. 夏宏兵,黄迎辉. 基于ADP的可重构机器人在线故障补偿控制. 武汉轻工大学学报. 2020(05): 96-103 . 百度学术20. 金辉,张子豪. 基于自适应动态规划的HEV能量管理研究综述. 汽车工程. 2020(11): 1490-1496 . 百度学术21. 方洋旺,邓天博,符文星. 智能制导律研究综述. 无人系统技术. 2020(06): 36-42 . 百度学术22. 王琼,郭戈. 车队速度滚动时域动态规划及非线性控制. 自动化学报. 2019(05): 888-896 . 本站查看23. 陈燕妮,刘春生,孙景亮. 基于自适应最优控制的有限时间微分对策制导律. 控制理论与应用. 2019(06): 877-884 . 百度学术24. 吴翔,刘春生,孙景亮. 基于ADP的导引控制一体化全状态受限反演控制. 信息与控制. 2019(03): 293-301+309 . 百度学术25. 穆朝絮,张勇,余瑶,孙长银. 基于自适应动态规划的航空航天飞行器鲁棒控制研究综述. 空间控制技术与应用. 2019(04): 71-79 . 百度学术26. 蒲俊,马清亮,顾凡. 基于自适应动态规划的未知模型非线性系统H_2/H_∞控制. 电光与控制. 2018(09): 17-21 . 百度学术27. 魏阿龙,刘春生,孙景亮. 不确定非线性多智能体系统的最优协同控制. 电光与控制. 2018(09): 12-16+48 . 百度学术28. 戴姣,刘春生,孙景亮. 基于自适应动态规划的一类非线性系统的容错控制器设计. 电光与控制. 2018(10): 84-88 . 百度学术其他类型引用(40)
-

 下载:
下载:




计量
- 文章访问数: 2613
- HTML全文浏览量: 329
- PDF下载量: 2116
- 被引次数: 68
 下载:
下载:
