

-
摘要: 参数可辨识性研究在统计机器学习中具有重要的理论意义和应用价值.参数可辨识性是关于模型参数能否被惟一确定的性质.在包含物理参数的学习模型中,可辨识性不仅是物理参数获得正确估计的前提条件,更重要的是,它反映了学习机器中由参数决定的物理特征.为扩展到未来类人智能机器研究的考察视角,我们将学习模型纳入"知识与数据共同驱动模型"的框架中讨论.在此框架下,我们提出两个关键问题.第一是参数可辨识性准则问题.该问题考察与可辨识性密切相关的各种判断准则,其中知识驱动子模型与数据驱动子模型的耦合方式为参数可辨识性问题提供了新的研究空间.第二是参数可辨识性与机器学习理论和应用相关联的研究.该研究包括可辨识性对参数估计、模型选择、学习算法、学习动态过程、奇异学习理论、贝叶斯推断等内容的深刻影响.Abstract: The study of parameter identifiability has important theoretical meaning and practical value in statistical machine learning. Parameter identifiability is a property that concerns whether the model parameters can be uniquely determined. In learning models containing physical parameters, identifiability is a prerequisite for estimating those parameters; more importantly, it reflects the physical characteristic determined by those parameters. In order to extend our perspective to future human-like intelligent machines, we put the learning models into the framework of "knowledge-and data-driven models". Within this framework, we propose two key issues. The first is about identifiability criteria which aim to study various criteria closely related to identifiability; the coupling manner between knowledge-driven submodel and data-driven submodel provides novel topics for identifiability study. The second focuses on identifiability relevant to theory and application in machine learning; this involves the deep influence of identifiability on parameter estimation, model selection, learning algorithms, learning dynamics, Bayesian inference.1) 本文责任编委 朱军
-
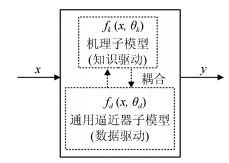
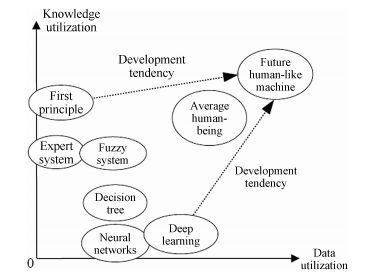
图 4 现有智能模型与未来类人机器在知识与数据利用中的相对关系示意图
Fig. 4 The relationship between current intelligent models and the future human-like machines which is based on the use of knowledge and data
-
[1] Matzkin R L. Nonparametric identification. Handbook of Econometrics. New York:Elsevier Science Ltd, 2007. [2] Dufour J M, Hsiao C. Identification. The New Palgrave Dictionary of Economics. London:Palgrave Macmillan Ltd., 2008. [3] Koopmans T C. Identification problems in economic model construction. Econometrica, 1949, 17(2):125-144 doi: 10.2307/1905689 [4] Aldrich J J. Haavelmo's identification theory. Econometric Theory, 1994, 10:198-219 doi: 10.1017/S026646660000829X [5] Zadeh L A. On the identification problem. IRE Transactions on Circuit Theory, 1956, 3(4):277-281 doi: 10.1109/TCT.1956.1086328 [6] Zadeh L A. From circuit theory to system theory. Proceedings of the Institute of Radio Engineers, 1962, 50(5):856-865 https://people.eecs.berkeley.edu/~zadeh/papers/From%20Circuit%20Theory%20to%20System%20Theory-May1962.pdf [7] Ljung L. System Identification:Theory for the User (Second Edition). Upper Saddle River, NJ:Prentice-Hall, 1999. [8] Chen H F, Guo L. Identification and Stochastic Adaptive Control. Boston, MA:Birkhauser, 1991. [9] Walter E, Pronzato L. Identification of Parameter Models from Experimental Data. London:Springer-Verlag, 1997. [10] 周彤.面向控制的系统辨识导论.北京:清华大学出版社, 2002.Zhou Tong. Introduction to Control-oriented System Identification. Beijing:Tinghua University Press, 2002. [11] Miao H Y, Xia X H, Perelson A S, Wu H L. On identifiability of nonlinear ODE models and applications in viral dynamics. SIAM Review, 2011, 53(1):3-39 doi: 10.1137/090757009 [12] 王乐一, 赵文虓.系统辨识:新的模式、挑战及机遇.自动化学报, 2013, 39(7):933-942 http://www.aas.net.cn/CN/abstract/abstract18122.shtmlWang Le-Yi, Zhao Wen-Xiao. System identification:new paradigms, challenges, and opportunities. Acta Automatica Sinica, 2013, 39(7):933-942 http://www.aas.net.cn/CN/abstract/abstract18122.shtml [13] Ljung L. Perspectives on system identification. Annual Reviews in Control, 2010, 34(1):1-12 doi: 10.1016/j.arcontrol.2009.12.001 [14] Ran Z Y, Hu B G. Determining structural identifiability of parameter learning machines. Neurocomputing, 2014, 127:88-97 doi: 10.1016/j.neucom.2013.08.039 [15] Hu B G, Qu H B, Wang Y, Yang S H. A generalizedconstraint neural network model:associating partially known relationships for nonlinear regressions. Information Sciences, 2009, 179(12):1929-1943 doi: 10.1016/j.ins.2009.02.006 [16] Koopmans T C, Reiersol O. The identification of structural characteristics. Annuals of Mathematical Statistics, 1950, 21(2):165-181 doi: 10.1214/aoms/1177729837 [17] Bellman R, Aström K J. On structural identifiability. In:Proceedings of the Mathematical Biosciences. Amsterdam:Elsevier, 1970, 7:329-339 http://www.sciencedirect.com/science/article/pii/002555647090132X [18] Amari S I, Nagaoka H. Methods of Information Geometry. New York:AMS and Oxford University Press, 2000. [19] Watanabe S. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. Journal of Machine Learning Research, 2010, 11:3571-3594 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.407.7976 [20] Watanabe S. Algebraic geometrical methods for hierarchical learning machines. Neural Networks, 2001, 14(8):1049-1060 doi: 10.1016/S0893-6080(01)00069-7 [21] Watanabe S. Algebraic geometry of singular learning machines and symmetry of generalization and training errors. Neurocomputing, 2005, 67:198-213 doi: 10.1016/j.neucom.2004.11.037 [22] Watanabe S. Almost all learning machines are singular. In:Proceedings of the 2007 IEEE Symposium on Foundations of Computational Intelligence. Piscataway, USA:IEEE, 2007. [23] Watanabe S. Algebraic Geometry and Statistical Learning Theory. Cambridge:Cambridge University Press, 2009. [24] Chen A M, Lu H, Hecht-Nielsen R. On the geometry of feedforward neural network error surfaces. Neural Computation, 1993, 5(6):910-927 doi: 10.1162/neco.1993.5.6.910 [25] Kurková V, Kainen P C. Functionally equivalent feedforward neural networks. Neural Computation, 1994, 6(3):543-558 doi: 10.1162/neco.1994.6.3.543 [26] Sussmann H J. Uniqueness of the weights for minimal feedforward nets with a given input-output map. Neural Networks, 1992, 5(4):589-593 doi: 10.1016/S0893-6080(05)80037-1 [27] Bishop C M. Pattern Recognition and Machine Learning. Berlin:Springer, 2006 [28] Henao R, Winther O. Sparse linear identifiable multivariate modeling. Journal of Machine Learning Research, 2011, 12:863-905 https://www.coursehero.com/file/17054240/Sparse-Linear-Identifiable-Multivariate-Modeling/ [29] Walter E, Lecourtier Y. Unidentifiable compartment models:what to do? Mathematical Biosciences, 1981, 56(1-2):1-25 doi: 10.1016/0025-5564(81)90025-0 [30] Wu H L, Zhu H H, Miao H Y, Perelson A S. Parameter identifiability and estimation of HIV/AIDS dynamic models. Bulletin of Mathematical Biology, 2008, 70(3):785-799 doi: 10.1007/s11538-007-9279-9 [31] Xia X, Moog C H. Identifiability of nonlinear systems with application to HIV/AIDS models. IEEE Transactions on Automatic Control, 2003, 48(2):330-336 doi: 10.1109/TAC.2002.808494 [32] Fortunati S, Gini F, Greco M S, Farina A, Graziano A, Giompapa S. On the identifiability problem in the presence of random nuisance parameters. Signal Processing, 2012, 92(10):2545-2551 doi: 10.1016/j.sigpro.2012.04.004 [33] Yang S H, Hu B G, Cournède P H. Structural identifiability of generalized-constraint neural network models for nonlinear regression. Neurocomputing, 2008, 72(1-3):392-400 doi: 10.1016/j.neucom.2007.12.013 [34] Rothenberg T J. Identification in parametric models. Econometrica, 1971, 39(3):577-591 doi: 10.2307/1913267 [35] Cover T M, Thomas J A. Elements of Information Theory (Second Edition). Chichester:Wiley-Blackwell, 1991. [36] Bowden R J. The theory of parametric identification. Econometrica, 1973, 41:1069-1074 doi: 10.2307/1914036 [37] Ran Z Y, Hu B G. Determining parameter identifiability from the optimization theory framework:a Kullback-Leibler divergence approach. Neurocomputing, 2014, 142:307-317 doi: 10.1016/j.neucom.2014.03.055 [38] Luenberger D G, Ye Y Y. Linear and nonlinear programming. International Series in Operations Research & Management Science (Second Edition). New Jersey:AddisonWesley, 1984 [39] Ran Z Y, Hu B G. An identifying function approach for determining parameter structure of statistical learning machines. Neurocomputing, 2015, 162:209-217 doi: 10.1016/j.neucom.2015.03.050 [40] Hochwald B, Nehorai A. On identifiability and informationregularity in parameterized normal distributions. Circuits Systems Signal Processing, 1997, 16(1):83-89 doi: 10.1007/BF01183177 [41] Stoica P, Ng B C. On the Cramér-Rao bound under parametric constraint. IEEE Signal Processing Letters, 1998, 5(7):177-179 doi: 10.1109/97.700921 [42] Yao Y W, Giannakis G. On regularity and identifiability of blind source separation under constant modulus constraints. IEEE Transactions on Signal Processing, 2005, 53(4):1272-1281 doi: 10.1109/TSP.2005.843718 [43] Murphy K P. Machine Learning:A Probabilistic Perspective. Cambridge:MIT Press, 2012. [44] Bishop C M. Pattern Recognition and Machine Learning. Berlin:Springer, 2006. [45] Paulino C D M, de Bragança Pereira C A. On identifiability of parametric statistical models. Journal of the Italian Statistical Society, 1994, 3(1):125-151 doi: 10.1007/BF02589044 [46] Ernesto S M, Fernando Q. Consistency and identifiability, revisited. Brazilian Journal of Probability and Statistics, 2002, 16(1):99-106 http://www.redeabe.org.br/bjpspublishedpapers_volume16_1_pp099-106.pdf [47] Boyd S, Vandenberghe L. Convex Optimization. Cambridge:Cambridge University Press, 2004. [48] Catchpole E A, Morgan B J T, Freeman S N. Estimation in parameter redundant models. Biometrika, 1998, 85(2):462-468 doi: 10.1093/biomet/85.2.462 [49] Catchpole E A, Morgan B J T. Deficiency of parameterredundant models. Biometrika, 2001, 88(2):593-598 doi: 10.1093/biomet/88.2.593 [50] Catchpole E A, Morgan B J T. Detecting parameter redundancy. Biometrika, 1997, 84(1):187-196 doi: 10.1093/biomet/84.1.187 [51] Amari S I, Park H, Ozeki T. Singularities affect dynamics of learning in neuromanifolds. Neural Computation, 2006, 18(5):1007-1065 doi: 10.1162/neco.2006.18.5.1007 [52] Hu B G. What are the differences between Bayesian classifiers and mutual information classifiers. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(2):249-264 doi: 10.1109/TNNLS.2013.2274799 [53] Ran Z Y, Hu B G. An identifying function approach for determining structural identifiability of parameter learning machines. In:Proceedings of International Joint Conference on Neural Networks. Beijing:IEEE, 2014. [54] Jiang H H, Pollack K H, Brownie C, Hightower J E, Hoeing J E, Hearn W S. Age-dependent tag return models for estimating fishing mortality, natural mortality and selectivity. Journal of Agricultural, Biological, and Environmental Statistics, 2007, 12(2):177-194 doi: 10.1198/108571107X197382 [55] Saccomani M P, Audoly S, Bellu G, D' Angiò L. Examples of testing global identifiability of biological and biomedical models with the DAISY software. Computers in Biology and Medicine, 2010, 40(4):402-407 doi: 10.1016/j.compbiomed.2010.02.004 [56] Dasgupta A, Self S G, Gupta S D. Unidentifiable parametric probability models and reparameterization. Journal of Statistical Planning and Inference, 2007, 137(11):3380-3393 doi: 10.1016/j.jspi.2007.03.018 [57] Evans N D, Chappell M J. Extensions to a procedure for generating locally identifiable reparameterisations of unidentifiable systems. Mathematical Biosciences, 2000, 168(2):137-159 doi: 10.1016/S0025-5564(00)00047-X [58] Little M P, Heidenreich W F, Li G Q. Parameter identifiability and redundancy in a general class of stochastic carcinogenesis models. PLoS ONE, 2009, 4:e8520 doi: 10.1371/journal.pone.0008520 [59] Little M P, Heidenreich M F, Li G. Parameter identifiability and redundancy:theoretical considerations. PLoS ONE, 2010, 5:e8915 doi: 10.1371/journal.pone.0008915 [60] Nakajima S, Sugiyama M. Implicit regularization in variational Bayesian matrix factorization. In:Proceedings of the International Conference on Machine Learning. Piscataway, USA:IEEE, 2010. [61] Kiraly F, Tomioka R. A combinatorial algebraic approach for the identifiability of low-rank matrix completion. In:Proceedings of the 29th International Conference on Machine Learning. Edinburgh, Scotland:ACM, 2012. 755-762 [62] Dacunha-Castelle D, Gassiat É. Testing in locally conic models, and application to mixture models. Probability and Statistics, 1997, 1:285-317 doi: 10.1051/ps:1997111 [63] Brockett R W. Some geometric questions in the theory of linear systems. In:Proceedings of the IEEE Conference on Decision and Control including the 14th Symposium on Adaptive Processes. New York:IEEE, 1975. 71-76 doi: 10.1007%2F978-1-4615-5223-9_1.pdf [64] Vapnik V N. The Natural of Statistical Learning Theory. New York:Springer, 1995. [65] Vapnik V N. Statistical Learning Theory. New York:John Wiley and Sons, 1998. [66] White H. Learning in artificial neural networks:a statistical perspective. Neural Computation, 1989, 1(4):425-464 doi: 10.1162/neco.1989.1.4.425 [67] Hagiwara K. On the problem in model selection of neural network regression in overrealizable scenario. Neural Computation, 2002, 14(8):1979-2002 doi: 10.1162/089976602760128090 [68] Murata N, Yoshizawa S, Amari S I. Network information criterion-determining the number of hidden units for an artificial network model. IEEE Transactions on Neural Networks, 1994, 5(6):865-872 doi: 10.1109/72.329683 [69] Akaike H. A new look at the statistical model identification. IEEE Transactions on Automatic Control, 1974, 19(6):716-723 doi: 10.1109/TAC.1974.1100705 [70] Duda R O, Hart P E, Stork D G. Pattern Classification. New York:Wiley, 2001. [71] Amari S I. Natural gradient works efficiently in learning. Neural Computation, 1998, 10(2):251-276 doi: 10.1162/089976698300017746 [72] Yang H H, Amari S I. Complexity issues in natural gradient descent method for training multi-layer perceptrons. Neural Computation, 1998, 10(8):2137-2157 doi: 10.1162/089976698300017007 [73] Rattray M, Saad D. Analysis of natural gradient descent for multilayer neural networks. Physical Review E, 1999, 59(4):4523-4532 doi: 10.1103/PhysRevE.59.4523 [74] Rattray M, Saad D, Amari S I. Natural gradient descent for online learning. Physical Review Letters, 2000, 81(24):5461-5464 doi: 10.1103/PhysRevLett.81.5461 [75] Cousseau F, Ozeki T, Amari S I. Dynamics of learning in multilayer perceptrons near singularities. IEEE Transactions on Neural Networks, 2008, 19(8):1313-1328 doi: 10.1109/TNN.2008.2000391 [76] Wei H K, Zhang J, Cousseau F, Ozeki T, Amari S I. Dynamics of learning near singularities in layered networks. Neural Computation, 1989, 20(3):813-843 http://www.docin.com/p-513451782.html [77] Weyl H. On the volume of tubes. American Journal of Mathematics, 1939, 61(2):461-472 doi: 10.2307/2371513 [78] Fukumizu K. Generalization error of linear neural networks in unidentifiable cases. In:Proceedings of the 10th International Conference on Algorithmic Learning Theory. Berlin:Springer-Verlag, 1999. 51-62 [79] Liu X, Shao Y Z. Asymptotics for likelihood ratio tests under loss of identifiability. Annals of Statics, 2003, 31(3):807-832 doi: 10.1214/aos/1056562463 [80] Ran Z Y, Hu B G. Parameter identifiability in statistical machine learning:a review. Neural Computation, 2017, 29(5):1151-1203 doi: 10.1162/NECO_a_00947 [81] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers:surpassing human-level performance on imageNet classification. In:Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015. 1026-1034 [82] 胡包钢, 王泳, 杨双红, 曲寒冰.如何增加人工神经元网络的透明度.模式识别与人工智能, 2007, 20(1):72-84 http://www.cnki.com.cn/Article/CJFDTOTAL-MSSB200701011.htmHu Bao-Gang, Wang Yong, Yang Shuang-Hong, Qu HanBing. How to add transparency to artificial neural networks. Pattern Recognition and Artificial Intelligence, 2007, 20(1):72-84 http://www.cnki.com.cn/Article/CJFDTOTAL-MSSB200701011.htm [83] 王飞跃, 刘德荣, 熊刚, 程长建, 赵冬斌.复杂系统的平行控制理论及应用.复杂系统与复杂性科学, 2012, 9(3):1-12 http://youxian.cnki.com.cn/yxdetail.aspx?filename=MOTO20171010009&dbname=CAPJ2015Wang Fei-Yue, Liu De-Rong, Xiong Gang, Cheng ChangJian, Zhao Dong-Bin. Parallel control theory of complex systems and applications. Complex Systems and Complexity Science, 2012, 9(3):1-12 http://youxian.cnki.com.cn/yxdetail.aspx?filename=MOTO20171010009&dbname=CAPJ2015 [84] 马世骏, 王如松.社会-经济-自然复合生态系统.生态学报, 1984, 4(1):1-9 http://www.cnki.com.cn/Article/CJFDTOTAL-STXB200112025.htmMa Shi-Jun, Wang Ru-Song. The Social-economic-natural Complex Ecosystem. Acta Ecologica Sinica, 1984, 4(1):1-9 http://www.cnki.com.cn/Article/CJFDTOTAL-STXB200112025.htm [85] 钱学森, 于景元, 戴汝为.一个科学新领域-开放的复杂巨系统及其方法论.自然杂志, 1990, 13(1):3-10 http://www.cnki.com.cn/Article/CJFDTOTAL-ZRZZ199001000.htmQian Xue-Sen, Yu Jing-Yuan, Dai Ru-Wei. A new discipline of science-the study of open complex giant system and its methodology. Chinese Journal of Nature, 1990, 13(1):3-10 http://www.cnki.com.cn/Article/CJFDTOTAL-ZRZZ199001000.htm [86] 戴汝为, 操龙兵. Internet-一个开放的复杂巨系统.中国科学, 2003, 33(4):289-296 http://www.cnki.com.cn/Article/CJFDTOTAL-JEXK200304000.htmDai Ru-Wei, Cao Long-Bing. Internet-a open complex giant system. Scientia Sinica, 2003, 33(4):289-296 http://www.cnki.com.cn/Article/CJFDTOTAL-JEXK200304000.htm [87] 万百五.控制论视角下对宏观经济建模的再思考:为能预测经济危机, 对建模的审视及趋势评述.控制理论与应用, 2015, 32(9):1132-1142 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201509002.htmWan Bai-Wu. Rethinking macroeconomic modeling in the viewpoint of Cybernetics:review and trend of modeling for predicting the next economic crisis. Control Theory and Applications, 2015, 32(9):1132-1142 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201509002.htm -

 下载:
下载:


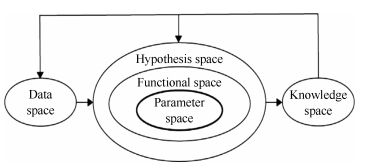
图(5)
计量
- 文章访问数: 3739
- HTML全文浏览量: 682
- PDF下载量: 1332
- 被引次数: 0
