

-
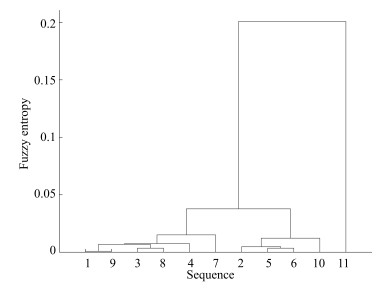
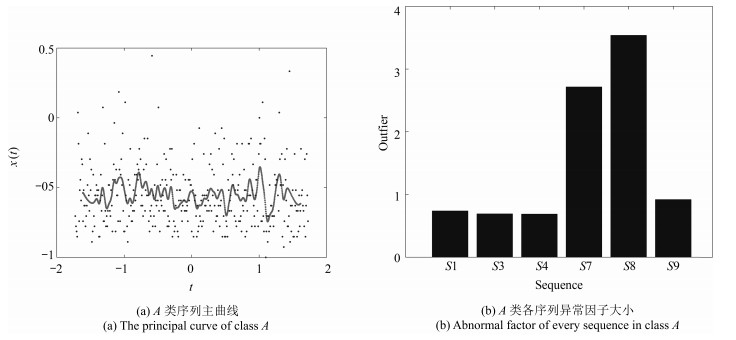
摘要: 针对传统多变量时间序列预测方法未考虑变量间依赖关系从而影响预测效果的问题,提出了一种基于异常序列剔除的多变量时间序列预测算法.该算法旨在利用多维支持向量回归机(Multi-dimensional support vector regression,M-SVR)内在的结构化输出特性,对选取到具有相似性的多个变量序列进行联合预测.首先,对已知序列进行基于模糊熵的层次聚类,实现对相似序列的初步划分;其次,求出类中所有序列的主曲线,根据序列到主曲线的距离计算各个序列的异常因子,从而进一步剔除聚类结果中的异常序列;最后,将选取到的相似变量序列作为输入,利用M-SVR进行预测.通过理论分析,证明本文算法在理论上存在信息损失上界与可靠度下界,从而说明本文算法的合理性与可行性.采用混沌时间序列数据与多个实际数据集进行对比实验,结果表明,与现有多个代表性方法相比,本文算法可有效挖掘多变量时间序列的内在结构信息,预测精度更高,数值稳定性更好.Abstract: To solve the problem that the traditional multivariate time series prediction generally ignores the dependency among all variables, a new multivariate time series structural prediction method through outlier elimination is proposed. This algorithm predicts on the selected multivariate time series by using the structural output characteristic. Firstly, to recognize the relatedness among the sequences, the variable sequences are initially divided by hierarchical clustering according to fuzzy entropy. Secondly, to further evaluate the similarity of the sequences in the obtained cluster, the principal curve is introduced to calculate the abnormality degree of each sequence, and then the outlier sequence can be eliminated in terms of the value of abnormality degree. As a result, similar sequences can be distinguished. Finally, for the similar series, multi-dimensional support vector regression (M-SVR) is used to construct the prediction model, and then the structural prediction for multivariate time series is conducted. Moreover, a theoretical proof is provided to show the proposed method has an upper bound of the loss of information and a lower bound of reliability and that the proposed method is reasonable and feasible from the perspective of information entropy. Experiments are conducted on three chaotic time series datasets and five real-life datasets. The results show that the proposed method can effectively recognize the inner group structure among multivariable sequences, so as to obtain a better forecasting accuracy and numerical stability than those widely used methods in terms of two different error measurements.1) 本文责任编委 张敏灵
-
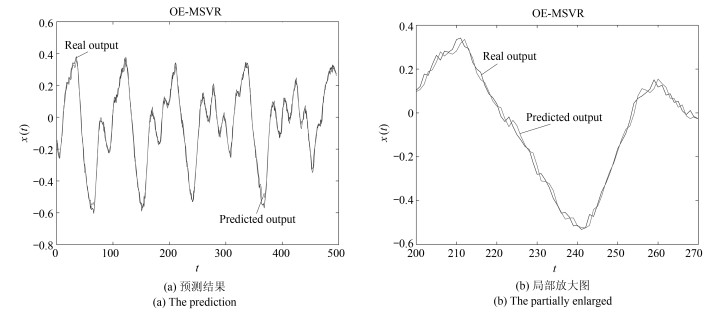
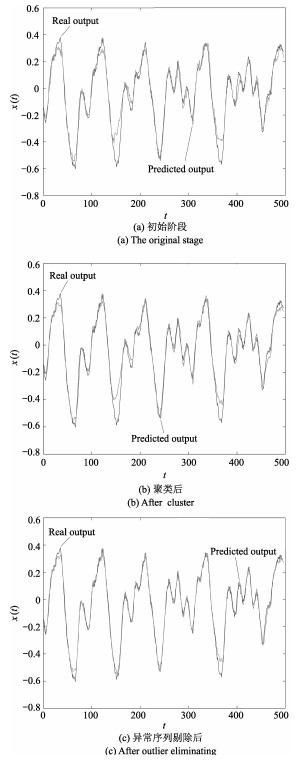
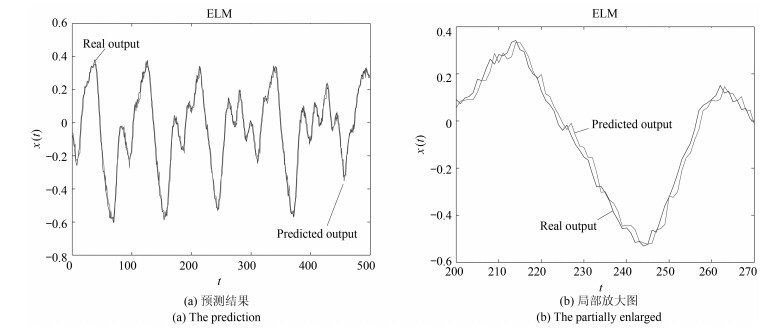
图 9 序列3的OE-MSVR预测效果图
Fig. 9 The prediction of the third sequence with OE-MSVR algorithm
表 1 各个阶段预测结果性能指标对比
Table 1 Prediction performance parameters of capillary of three stages
序列 RMSE MAE 初始序列 聚类后 异常序列剔除后 初始序列 聚类后 异常序列剔除后 序列3 0.0589 0.0511 0.0319 0.0405 0.0357 0.0248 序列4 0.0843 0.0814 0.0364 0.0638 0.0603 0.0270 序列5 0.0559 0.0508 0.0379 0.0435 0.0387 0.0292 序列6 0.0675 0.0585 0.0350 0.0494 0.0435 0.0269  下载: 导出CSV
下载: 导出CSV
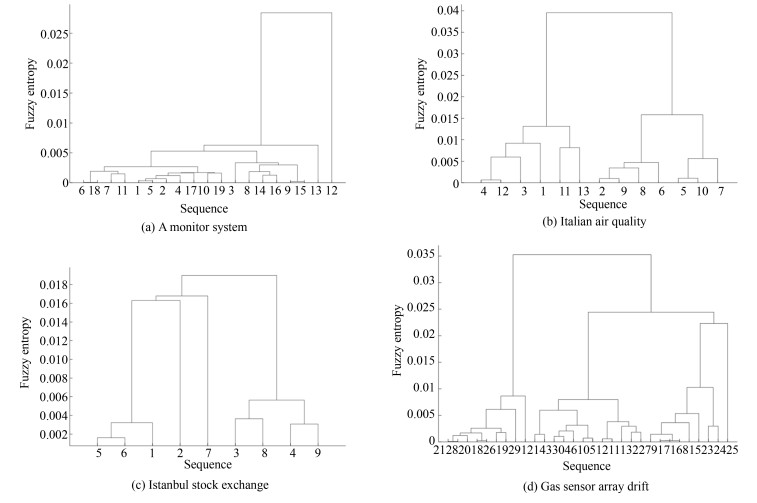
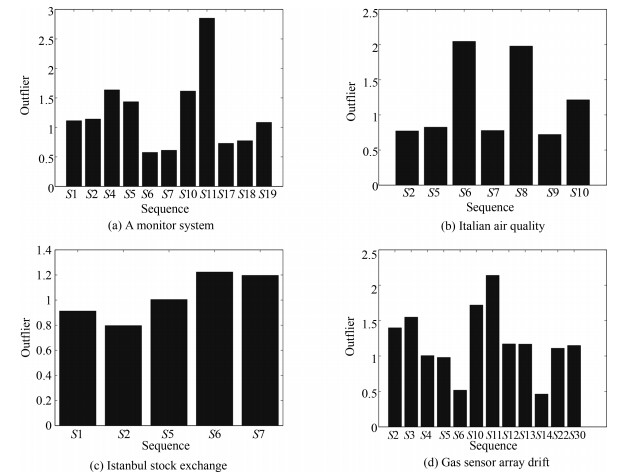
表 2 实际数据集信息
Table 2 Real datasets
数据集 样本数目 属性数目 训练样本 测试样本 澳门气象数据 1 276 547 11 Monitor system 1 260 540 19 Istanbul stock exchange 375 161 9 Air quality 1 680 720 13 Gas sensor array drift 310 133 30
下载: 导出CSV
表 3 A monitorsystem数据集预测结果性能指标对比
Table 3 Prediction performance parameters of capillary of A monitor system dataset
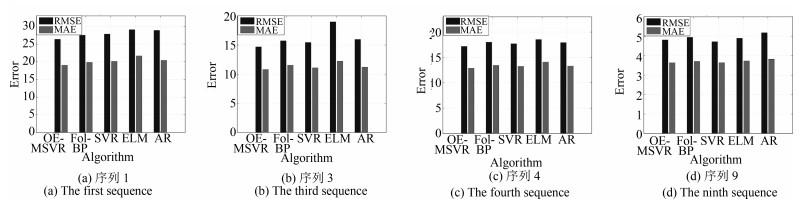
序列 RMSE MAE OE-MSVR Fol-BP SVR ELM AR OE-MSVR Fol-BP SVR ELM AR 序列1 0.1318 0.4561 0.8583 0.2388 0.1628 0.0949 0.3288 0.4115 0.1115 0.1628 序列2 0.1006 0.5843 0.4862 0.1926 0.1514 0.0835 0.4236 0.3271 0.1249 0.1514 序列5 4.7365 9.1443 14.5330 6.8052 4.0215 3.0607 6.4887 14.2472 2.4689 4.0215 序列6 0.5226 1.6900 0.7693 0.4723 0.4642 0.3459 1.1693 0.6508 0.3407 0.4642 序列7 0.3767 1.2893 0.5828 0.3817 0.2548 0.2730 0.9145 0.4679 0.2784 0.2548 序列17 0.2112 0.9896 1.6971 0.4789 0.2820 0.1642 0.7497 0.7099 0.2239 0.2820 序列18 0.7122 2.2701 0.9597 0.8947 0.6812 0.5146 1.7620 0.7590 0.6643 0.6812 序列19 0.1244 0.7442 0.2993 0.0434 0.0994 0.0613 0.4913 0.2992 0.0038 0.0994
下载: 导出CSV
表 4 Italian airquality数据集预测结果性能指标对比
Table 4 Prediction performance parameters of capillary of Italian air quality
序列 RMSE MAE OE-MSVR Fol-BP SVR ELM AR OE-MSVR Fol-BP SVR ELM AR 序列2 121.9587 122.2608 123.6130 122.9571 123.4309 75.7143 70.2002 75.4696 76.6154 69.6428 序列5 146.4420 148.3487 146.5258 146.3931 168.6011 89.7674 89.3968 88.6896 92.8062 100.1906 序列7 113.6631 113.6741 117.6938 122.5415 123.6603 76.7395 77.8434 81.9074 85.8995 85.7884 序列9 165.8359 167.1297 167.6215 174.2383 184.5600 100.3676 100.1063 101.4094 106.4807 108.7986 序列10 178.1549 180.5234 186.9799 190.4919 200.0233 120.5245 118.7809 125.6156 129.6792 131.0641
下载: 导出CSV
表 5 Istanbul stockexchange数据集预测结果性能指标对比
Table 5 Prediction performance parameters of capillary of Istanbul stock exchange
序列 RMSE MAE OE-MSVR Fol-BP SVR ELM AR OE-MSVR Fol-BP SVR ELM AR 序列1 0.0119 0.0192 0.0121 0.0133 0.0119 0.0090 0.0140 0.0092 0.0101 0.0092 序列2 0.0151 0.0217 0.0153 0.0167 0.0151 0.0116 0.0167 0.0117 0.0128 0.0117 序列5 0.0097 0.0170 0.0095 0.0110 0.0098 0.0072 0.0123 0.0073 0.0083 0.0073
下载: 导出CSV
表 6 Gas sensor arraydrift数据集预测结果性能指标对比
Table 6 Prediction performance parameters of capillary of Gas sensor array drift dataset
序列 RMSE MAE OE-MSVR Fol-BP SVR ELM AR OE-MSVR Fol-BP SVR ELM AR 序列2 9.08E + 04 2.58E + 05 9.17E + 04 1.17E + 05 9.27E + 04 5.20E + 04 1.58E + 05 5.73E + 04 7.48E + 04 5.30E + 04 序列4 22.7062 74.2977 27.8097 26.3881 25.4101 10.9343 39.8237 17.5229 17.1492 15.2092 序列5 31.5850 111.9757 34.3149 39.0925 34.9793 16.1337 73.2789 20.6630 25.5340 21.5229 序列6 45.5174 221.2905 52.0124 59.9806 52.5336 22.6310 118.2681 27.9837 36.8887 30.6452 序列12 18.0458 80.8880 24.1219 28.6046 20.4600 9.0439 45.7426 16.7021 16.8084 12.8685 序列13 26.9213 79.6147 26.4391 34.9546 30.0822 13.2553 49.2278 16.5452 24.2313 19.3481 序列14 36.5061 241.8456 38.7079 49.0467 43.4256 15.8653 138.9438 20.7230 27.4320 24.8211 序列22 3.2263 5.0164 3.4150 2.7369 2.3271 2.7023 2.9809 2.9791 1.8935 1.4541 序列30 3.1137 6.3610 3.4056 2.7941 2.2838 2.5935 4.2371 3.0138 1.8682 1.3841
下载: 导出CSV
-
[1] Schölkopf B B, Smola A J. Learning with Kernels. Cambridge, Britain:MIT Press, 2002, 3:2165-2176 https://www.cs.utah.edu/~piyush/teaching/learning-with-kernels.pdf [2] 张勇, 关伟.基于最大Lyapunov指数的多变量混沌时间序列预测.物理学报, 2009, 58(2):756-763 doi: 10.7498/aps.58.756Zhang Yong, Guan Wei. Predication of multivariable chaotic time series based on maximal Lyapunov exponent. Acta Physica Sinica, 2009, 58(2):756-763 doi: 10.7498/aps.58.756 [3] Sun B Q, Guo H F, Karimi H R, Ge Y J, Xiong S. Prediction of stock index futures prices based on fuzzy sets and multivariate fuzzy time series. Neurocomputing, 2015, 151:1528-1536 doi: 10.1016/j.neucom.2014.09.018 [4] 韩敏, 许美玲, 任伟杰.多元混沌时间序列的相关状态机预测模型研究.自动化学报, 2014, 40(5):822-829 http://www.aas.net.cn/CN/abstract/abstract18350.shtmlHan Min, Xu Mei-Ling, Ren Wei-Jie. Research on multivariate chaotic time series prediction using mRSM model. Acta Automatica Sinica, 2014, 40(5):822-829 http://www.aas.net.cn/CN/abstract/abstract18350.shtml [5] Wang X Y, Han M. Improved extreme learning machine for multivariate time series online sequential prediction. Engineering Applications of Artificial Intelligence, 2015, 40:28-36 doi: 10.1016/j.engappai.2014.12.013 [6] Han M, Xu M L, Liu X X, Wang X Y. Online multivariate time series prediction using SCKF-γ ESN model. Neurocomputing, 2015, 147:315-323 doi: 10.1016/j.neucom.2014.06.057 [7] Chen T T, Lee S J. A weighted LS-SVM based learning system for time series forecasting. Information Sciences, 2015, 299:99-116 doi: 10.1016/j.ins.2014.12.031 [8] Sanchez-Fernandez M, de-Prado-Cumplido M, Arenas-Garcia J, Perez-Cruz F. SVM multiregression for nonlinear channel estimation in multiple-input multiple-output systems. IEEE Transactions on Signal Processing, 2005, 52(8):2298-2307 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=1315948 [9] Bao Y K, Xiong T, Hu Z Y. Multi-step-ahead time series prediction using multiple-output support vector regression. Neurocomputing, 2014, 129:482-493 doi: 10.1016/j.neucom.2013.09.010 [10] Han J W, Kamber M, Pei J[著], 范明, 孟小峰[译]. 数据挖掘概念与技术(第3版) (计算机科学丛书). 北京: 机械工业出版社, 2012. 297-301Han J W, Kamber M, Pei J[Author], Fan Ming, Meng Xiao-Feng[Translator]. Data Mining Concepts and Techniques (3rd edition) (Computer Science Series). Beijing: China Machine Press, 2012. 297-301 [11] 韩忠明, 陈妮, 乐嘉锦, 段大高, 孙践知.面向热点话题时间序列的有效聚类算法研究.计算机学报, 2012, 35(11):2337-2347 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx201211012&dbname=CJFD&dbcode=CJFQHan Zhong-Ming, Chen Ni, Le Jia-Jin, Duan Da-Gao, Sun Jian-Zhi. An efficient and effective clustering algorithm for time series of hot topics. Chinese Journal of Computers, 2012, 35(11):2337-2347 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx201211012&dbname=CJFD&dbcode=CJFQ [12] Lee H. The Euclidean distance degree of Fermat hypersurfaces. Journal of Symbolic Computation, 2017, 80:502-510 doi: 10.1016/j.jsc.2016.07.006 [13] Hautamaki V, Nykanen P, Franti P. Time-series clustering by approximate prototypes. In: Proceedings of the 19th International Conference on Pattern Recognition. Tampa, FL, USA: IEEE, 2008. 1-4 [14] 杨一鸣, 潘嵘, 潘嘉林, 杨强, 李磊.时间序列分类问题的算法比较.计算机学报, 2007, 30(8):1259-1266 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200708010&dbname=CJFD&dbcode=CJFQYang Yi-Ming, Pan Rong, Pan Jia-Lin, Yang Qiang, Li Lei. A comparative study on time series classification. Chinese Journal of Computers, 2007, 30(8):1259-1266 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200708010&dbname=CJFD&dbcode=CJFQ [15] 张军平, 王珏.主曲线研究综述.计算机学报, 2003, 26(2):129-146 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200302000&dbname=CJFD&dbcode=CJFQZhang Jun-Ping, Wang Yu. An overview of principal curves. Chinese Journal of Computers, 2003, 26(2):129-146 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjx200302000&dbname=CJFD&dbcode=CJFQ [16] 毛文涛, 王金婉, 何玲, 袁培燕.面向贯序不均衡数据的混合采样极限学习机.计算机应用, 2015, 35(8):2221-2226 doi: 10.11772/j.issn.1001-9081.2015.08.2221Mao Wen-Tao, Wang Jin-Wan, He Ling, Yuan Pei-Yan. Hybrid sampling extreme learning machine for sequential imbalanced data. Journal of Computer Application, 2015, 35(8):2221-2226 doi: 10.11772/j.issn.1001-9081.2015.08.2221 [17] 孙克辉, 贺少波, 尹林子, 阿地力·多力坤.模糊熵算法在混沌序列复杂度分析中的应用.物理学报, 2012, 61(13):130507 doi: 10.7498/aps.61.130507Sun Ke-Hui, He Shao-Bo, Yin Lin-Zi, A Di-Li·Duo Li-Kun. Application of fuzzyen algorithm to the analysis of complexity of chaotic sequence. Acta Physica Sinica, 2012, 61(13):130507 doi: 10.7498/aps.61.130507 [18] 毛文涛, 赵胜杰, 张俊娜.基于主曲线的多输入多输出支持向量机算法.计算机应用, 2013, 33(5):1281-1284, 1293 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjy201305022&dbname=CJFD&dbcode=CJFQMao Wen-Tao, Zhao Sheng-Jie, Zhang Jun-Na. Multi-input-multi-output support vector machine based on principal curve. Journal of Computer Application, 2013, 33(5):1281 -1284, 1293 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjy201305022&dbname=CJFD&dbcode=CJFQ [19] Yuan P Y, Ma H D, Fu H Y. Hotspot-entropy based data forwarding in opportunistic social networks. Pervasive and Mobile Computing, 2015, 16:136-154 doi: 10.1016/j.pmcj.2014.06.003 [20] 汤礼东, 宋保维, 李正, 郑珂.基于信息熵理论的小子样模糊可靠性评定方法.弹箭与制导学报, 2005, 25(S1):214-216 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=djzd2005s1040&dbname=CJFD&dbcode=CJFQTang Li-Dong, Song Bao-Wei, Li Zheng, Zheng Ke. A fuzzy reliability evaluation method for sub-sample products based on information entropy theory. Journal of Projectiles, Rockets, Missiles and Guidance, 2005, 25(S1):214-216 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=djzd2005s1040&dbname=CJFD&dbcode=CJFQ [21] Mao W T, Zhao S J, Mu X X, Wang H C. Multi-dimensional extreme learning machine. Neurocomputing, 2015, 149:160 -170 doi: 10.1016/j.neucom.2014.02.073 [22] Chang C C, Lin C J. LIBSVM: a library for support vector machines[Online], available: http://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html. February 1, 2016 [23] 许美玲, 韩敏.多元混沌时间序列的因子回声状态网络预测模型.自动化学报, 2015, 41(5):1042-1046 http://www.aas.net.cn/CN/abstract/abstract18678.shtmlXu Mei-Ling, Han Min. Factor echo state network for multivariate chaotic time series prediction. Acta Automatica Sinica, 2015, 41(5):1042-1046 http://www.aas.net.cn/CN/abstract/abstract18678.shtml [24] 李军, 李大超.基于优化核极限学习机的风电功率时间序列预测.物理学报, 2016, 65(13):33-42 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=wlxb201613005&dbname=CJFD&dbcode=CJFQLi Jun, Li Da-Chao. Wind power time series prediction using optimized kernel extreme learning machine method. Acta Physica Sinica, 2016, 65(13):33-42 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=wlxb201613005&dbname=CJFD&dbcode=CJFQ [25] 马千里, 郑启伦, 彭宏, 覃姜维.基于模糊边界模块化神经网络的混沌时间序列预测.物理学报, 2009, 58(3):1410-1419 doi: 10.7498/aps.58.1410Ma Qian-Li, Zheng Qi-Lun, Peng Hong, Qin Jiang-Wei. Chaotic time series prediction based on fuzzy boundary modular neural networks. Acta Physica Sinica, 2009, 58(3):1410-1419 doi: 10.7498/aps.58.1410 [26] 侯公羽, 梁荣, 孙磊, 刘琳, 龚砚芬.基于多变量混沌时间序列的煤矿斜井TBM施工动态风险预测.物理学报, 2014, 63(9):90505 doi: 10.7498/aps.63.090505Hou Gong-Yu, Liang Rong, Sun Lei, Liu Lin, Gong Yan-Fen. Risk analysis on long inclined-shaft construction in coalmine by TBM techniques based on multiple variables chaotic time series. Acta Physica Sinica, 2014, 63(9):90505 doi: 10.7498/aps.63.090505 [27] Liu C H, Shang Y L, Duan L, Chen S P, Liu C C, Chen J. Optimizing workload category for adaptive workload prediction in service clouds. Service-Oriented Computing. Lecture Notes in Computer Science. Berlin, Heidelberg, Germany: Springer, 2015. 87-104 -

 下载:
下载:




计量
- 文章访问数: 3674
- HTML全文浏览量: 688
- PDF下载量: 990
- 被引次数: 0
