

-
摘要: 专家系统是人工智能领域的重要分支,其中知识表示和知识推理是专家系统的重要组成部分.Rete算法是一种高效的模式匹配算法,能够解决专家系统中推理效率的问题,但是Rete算法在构建Rete网络和推理过程中存在空间和性能方面问题.本文采取有穷自动机理论的思想,阐述了Rete算法中的模式共享度和节点共享度模型,提出了一种Rete网络构建和推理算法来降低Rete网络的复杂度,提升Rete网络推理的速度.最后实验结果表明,本算法能够降低网络复杂度,提升推理速度.Abstract: Expert system is an important brunch of artificial intelligence. Knowledge representation and inference engine is an important part of the expert system. As an efficient pattern-matching algorithm, Rete algorithm can solve the ratiocination efficiency problem in expert system. However, there always exist the problems such as storage and efficiency in building and using Rete network. In this paper, we introduce the idea of finite automata, and the pattern sharing degree and node sharing degree model into Rete algorithm. We propose a Rete network construction and inference algorithm to reduce the complexity of Rete network and improve the speed of Rete network inference. Finally, experimental results show that it can reduce the complexity of the network greatly and raise the inference speed.
-
Key words:
- Expert system /
- Rete /
- finite automaton /
- ratiocination machine
1) 本文责任编委 周涛 -
表 1 网络构建对比实验结果(ms)
Table 1 The result of network construction (ms)
数据集 序号 Rete Rete Shuffled ReteSDM 构建时间 共享性 构建时间 共享性 构建时间 共享性 Adult 1 38 0.095 43 0.301 53 0.077 2 31 0.095 38 0.301 47 0.077 3 31 0.095 38 0.302 55 0.077 4 32 0.095 37 0.302 47 0.077 AVG 33 0.095 39 0.301 50.5 0.077 Bank marketing 1 61 0.077 64 0.296 72 0.059 2 61 0.077 66 0.296 75 0.059 3 61 0.077 66 0.296 74 0.059 4 60 0.077 62 0.295 72 0.059 AVG 60.75 0.077 64.5 0.295 73.25 0.059 Nursery 1 3 0.492 3 0.549 5 0.477 2 4 0.492 4 0.554 5 0.477 3 4 0.492 4 0.538 5 0.477 4 3 0.492 3 0.518 5 0.477 AVG 3.5 0.492 3.5 0.539 5 0.477  下载: 导出CSV
下载: 导出CSV
表 2 推理性能对比实验结果(s)
Table 2 The result of ratiocination effiency (s)
数据集 分组 Rete Rete Shuffled ReteSDM Hashed ReteSDM 偏差率 Adult 1 0.865 0.962 0.736 0.535 0 2 1.721 1.950 1.472 1.071 0 3 2.633 2.735 2.202 1.553 0 Bank marketing 1 0.996 1.115 0.823 0.625 0 2 2.102 2.327 1.650 1.256 0 3 3.001 3.423 2.436 1.903 0 Nursery 1 0.105 0.115 0.089 0.080 0 2 0.203 0.217 0.193 0.159 0 3 0.312 0.332 0.290 0.250 0
下载: 导出CSV
-
[1] Bemley J L. An introduction to expert systems. In: Proceedings of the 7th Annual National Convention and 10th Anniversary of Black Data Processing Associates "A Decade of Professional Growth". Washington, DC, USA, 1985. 27-34 [2] Giarratano J C, Riley G D. Expert Systems: Principles and Programming. New York: Thomson Learning, 2005. 78-122 [3] Munaiseche C P C, Liando O E S. Evaluation of expert system application based on usability aspects. In: Proceedings of the 2016 International Conference on Innovation in Engineering and Vocational Education. Bandung, Indonesia: IOP, 2016. 128-135 http://adsabs.harvard.edu/abs/2016MS%26E..128a2001M [4] Ochab M, Wajs W. Expert system supporting an early prediction of the bronchopulmonary dysplasia. Computers in Biology and Medicine, 2016, 69(1): 236-244 https://www.researchgate.net/publication/281467838_Expert_system_supporting_an_early_prediction_of_the_Bronchopulmonary_Dysplasia [5] Forgy C L. Rete: a fast algorithm for the many pattern/many object pattern match problem. Artificial Intelligence, 1982, 19(1): 17-37 doi: 10.1016/0004-3702(82)90020-0 [6] Sipser M. Introduction to the Theory of Computation (3rd edition). Boston: Cengage Learning, 2013. 44-80 [7] Kornoushenko E K. Operation of closure on the set of states of an incompletely defined deterministic automaton. Cybernetics, 1976, 12(1): 10-17 doi: 10.1007/BF01070337 [8] Topencharov V, Peeva K. Mathematical automata theory: a categorical approach. Problems of Control and Information Theory, 1980, 9(2): 141-161 http://www.ams.org/mathscinet-getitem?mr=561809 [9] Ilie L, Yu S. Reducing NFAs by invariant equivalences. Theoretical Computer Science, 2003, 306(1): 373-390 http://www.sciencedirect.com/science/article/pii/S0304397503003116 [10] Perlin M. Topologically traversing the RETE network. Applied Artificial Intelligence, 1990, 4(3): 155-177 doi: 10.1080/08839519008927948 [11] Shatueva T A. Method for classical Rete algorithm efficiency improvement for the system of production rules aimed at knowledge extraction from terminological dictionaries. Control Systems and Information Technologies, 2012, 4(3): 31-34 [12] Xiao D, Zhong X A. Improving Rete algorithm to enhance performance of rule engine systems. In: Proceedings of the 2010 International Conference on Computer Design and Applications. Qinhuangdao, China: IEEE, 2010. 572-575 http://ieeexplore.ieee.org/document/5541368/ [13] UCI Machine Learning Repository. Adult data set [Online], available: http://archive.ics.uci.edu/ml/datasets/Adult, February 3, 2017 [14] UCI Machine Learning Repository. Bank marketing data set [Online], available: http://archive.ics.uci.edu/ml/datasets/Bank+Marketing, February 3, 2017 [15] UCI Machine Learning Repository. Nursery data set [Online], available: http://archive.ics.uci.edu/ml/datasets/Nursery, February 3, 2017 [16] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃.深度学习在控制领域的研究现状与展望.自动化学报, 2016, 42(5): 643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtmlDuan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control: the state of the art and prospects. Acta Automatica Sinica, 2016, 42(5): 643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtml [17] 俞斌峰, 季海波.稀疏贝叶斯混合专家模型及其在光谱数据标定中的应用.自动化学报, 2016, 42(4): 566-579 http://www.aas.net.cn/CN/abstract/abstract18844.shtmlYu Bin-Feng, Ji Hai-Bo. Sparse bayesian mixture of experts and its application to spectral multivariate calibration. Acta Automatica Sinica, 2016, 42(4): 566-579 http://www.aas.net.cn/CN/abstract/abstract18844.shtml [18] 管皓, 薛向阳, 安志勇.深度学习在视频目标跟踪中的应用进展与展望.自动化学报, 2016, 42(6): 834-847 http://www.aas.net.cn/CN/abstract/abstract18874.shtmlGuan Hao, Xue Xiang-Yang, An Zhi-Yong. Advances on application of deep learning for video object tracking. Acta Automatica Sinica, 2016, 42(6): 834-847 http://www.aas.net.cn/CN/abstract/abstract18874.shtml -

 下载:
下载:
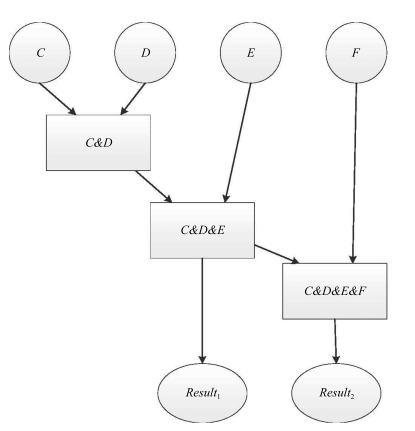
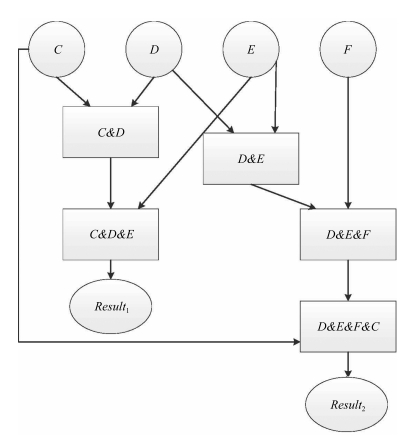


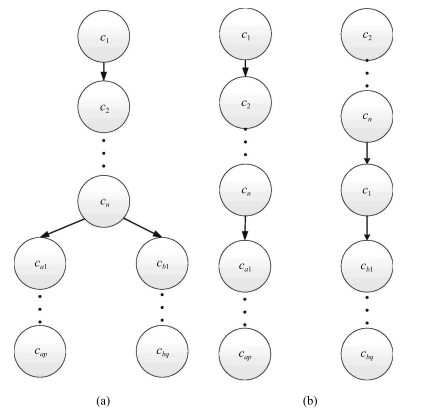
图(4) / 表(2)
计量
- 文章访问数: 2112
- HTML全文浏览量: 727
- PDF下载量: 717
- 被引次数: 0
