

-
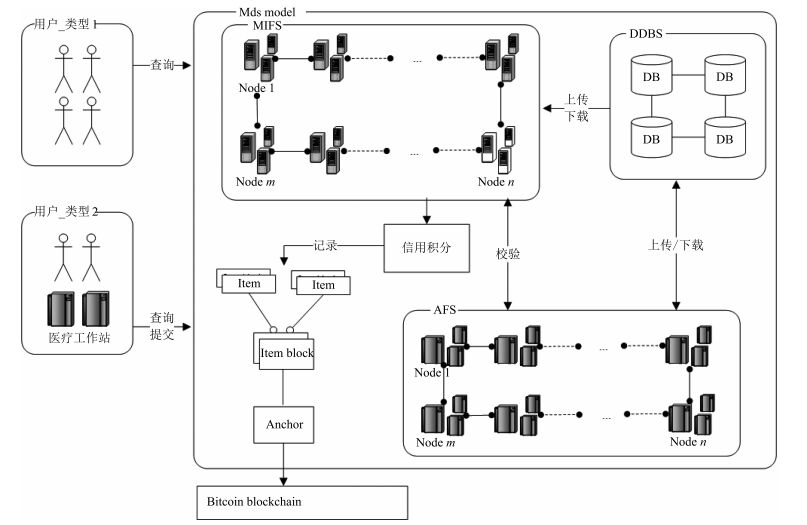
摘要: 根据医疗行业现状,不难发现各医疗机构间共享数据困难,因为医疗数据的校验、保存和同步一直是一个难点.病人、医生以及研究人员在访问和共享医疗数据时存在严格的限制,这一过程需要花费大量的资源和时间用于权限审查和数据校验.本文提出一个基于区块链的医疗数据共享模型,具有去中心化、安全可信、集体维护、不可篡改等特点,适用于解决各医疗机构数据共享的难题.本文详细介绍了模型的组件以及实现原理.将现有医疗机构进行分类,配合使用改进的共识机制实现了方便、安全、快捷的数据共享.此外,通过对比医疗数据共享存在的问题,分析了本模型的优势以及带来的影响.Abstract: According to the status quo of medical industry, verification, storage and synchronization of clinical data are difficult, therefore, clinic data sharing between institutions become a challenging task. There are many restrictions in data access and sharing for patients, doctors and even researchers, which results in a high cost of both resources and time for authority authentication and verification. To solve this problem, we propose a blockchain-based medical data sharing model, with advantages of decentralization, high security, collective maintenance and tamper resistance. We discuss the critical principles and components of this model in detail. Furthermore, we improve the consensus mechanism so as to better match different types of medical institutions for a more convenient, secure and faster data sharing. In addition, the merits and impacts of this model are presented and analyzed by comparisons in terms of existing issues in medical data.
-
Key words:
- Medical data /
- blockchain /
- consensus mechanism /
- sharing model
1) 本文责任编委 王飞跃 -
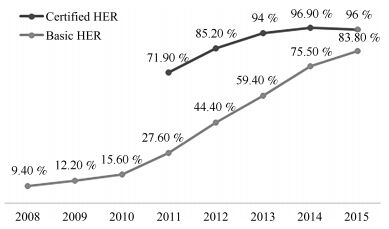

表 1 模型与现有解决方案对比
Table 1 The model is compared to existing solutions
 下载: 导出CSV
下载: 导出CSV
表 2 当前面临的问题以及模型应对的方法
Table 2 The problems faced and the coping methods of the model
类型 面临问题 模型应对方法及分析 隐私和安全 信任和访问控制 提倡医疗数据电子化, 医疗数据由可信的代理负责记录 黑客攻击和医疗数据保护 采用非对称加密技术加密数据 不可抵赖性 周期性将信息锚定到比特币公链, 借助公链实现不可篡改 医疗数据滥用和诈骗 被滥用, 追责困难 模型是轮流责任制, 采用区块链技术方便追责 记录难以辨识 数字化电子病历即时存储, 机器可识别易辨认 不正当收费, 虚假声明等 每种类型客户端均可快捷查询, 获得统一且可信的结果 用户参与度 用户无法管理自身的健康数据 完全由用户管理自己的医疗数据, 代理重加密实现权利委托 公共卫生相关研究与用户无直接关联 开放自己的医疗数据, 做为研究素材推动相关研究 数据分别存储在不同的数据中心, 形成数据孤岛共享困难 模型打通各医疗机构之间的数据孤岛, 实现方便的数据互操作 互操作性, 可访问性, 数据完整性 各机构权限不明确, 数据所属权不明确 医疗联合服务器负责代理记账, 审计服务器负责校验记账.客户端分不同类型, 支持不同的访问限制.另外, 明确各个医疗机构的职责, 方便外部审计. 数据容易丢失, 造成数据不完整 分布式的存储节点, 保证数据的多重备份 规则 不同的数据标准和共享规则 统一的数据查询接口, 统一的数据标准, 可以实时数据共享
下载: 导出CSV
-
[1] Charles D, Gabriel M, Furukawa M F. Adoption of electronic health record systems among U.S. non-federal acute care hospitals: 2008-2012. ONC data brief, 2013, 9: 1-9 [2] Nakamoto S. Bitcoin: a peer-to-peer electronic cash system [Online], available: http://bitcoin.org/bitcoin.pdf, June 12, 2016 [3] Healthbank [Online], available: http://www.healthbank.coop, August 18, 2016 [4] Health [Online], available: https://gem.co/health, January 22, 2016 [5] China Blockchain Development Forum. China Blockchain Technology and Application Development White Paper (2016) [Online], available: http://chainb.com/download/工信部—中国区块链技术和应用发展白皮书1014. pdf, October 18, 2016
中国区块链技术和产业发展论坛. 中国区块链技术和应用发展白皮书(2016) [Online], available: http://chainb.com/download/工信部—中国区块链技术和应用发展白皮书1014. pdf, October 18, 2016[6] Lvan D. Moving toward a blockchain-based method for the secure storage of patient records [Online], available: http://www.healthit.gov/sites/default/files/9-16-drew_ivan_20160804_blockchain_for_healthcare_final.pdf, August 4, 2016 [7] Shrier A A, Chang A, Diakun-thibault N, Forni L, Landa F, Mayo J, van Riezen R. Blockchain and Health IT: Algorithms, Privacy, and Data. [Online], available: http://www.truevaluemetrics.org/DBpdfs/Technology/Blockchain/1-78-blockchainandhealthitalgorithmsprivacydata_whitepaper.pdf, September 18, 2016 [8] Kuo T T, Hsu C N, Ohno-Machado L. ModelChain: decentralized privacy-preserving healthcare predictive modeling framework on private blockchain networks [Online], available: https://www.healthit.gov/sites/default/files/10-30-ucsd-dbmi-onc-blockchain-challenge.pdf, January 22, 2016. [9] Ekblaw A, Azaria A, Halamka J D, Lippman A. A Case Study for Blockchain in Healthcare: "MedRec"prototype for electronic health records and medical research data. In: Proceedings of the 2016 IEEE of International Conference on Open and Big Data, 2016. 25-30 [10] Yuan B, Lin W, McDonnell C. Blockchains and electronic health records [Online], available: http://mcdonnell.mit.edu/blockchain_ehr.pdf, May 4, 2016 [11] Witchey N J. Healthcare Transaction Validation Via Blockchain Proof-of-Work, Systems and Methods: U.S. Patent 2015/0332283, November 2015. [12] 袁勇, 王飞跃.区块链技术发展现状与展望.自动化学报, 2016, 42(4): 481-494 http://www.aas.net.cn/CN/abstract/abstract18837.shtmlYuan Yong, Wang Fei-Yue. Blockchain: the state of the art and future trends. Acta Automatica Sinica, 2016, 42(4): 481-494 http://www.aas.net.cn/CN/abstract/abstract18837.shtml [13] Merkle R C. A digital signature based on a conventional encryption function. In: Proceedings of the 1987 Conference on the Theory and Applications of Cryptographic Techniques. Berlin Heidelberg, Germany: Springer, 1987. 369-378 [14] Blaze M, Bleumer G, Strauss M. Divertible protocols and atomic proxy cryptography. In: Proceedings of the 1998 International Conference on the Theory and Applications of Cryptographic Techniques. Berlin Heidelberg, Germany: Springer, 1998. 127-144 [15] Aono Y, Boyen X, Phong L T, Wang L. Key-private proxy re-encryption under LWE. In: Proceedings of the 2013 International Conference on Cryptology in India. Cham, Germany: Springer International Publishing, 2013. 1-18 [16] Blockchain: the chain of trust and its potential to transform healthcare-our point of view [Online], available: http://www.healthit.gov/sites/default/files/8-31-blockchain-ibm_ideation-challenge_aug8.pdf, August 8, 2016. [17] Snow P, Deery B, Lu J, Johnston D, Kirby P. Factom: business processes secured by immutable audit trails on the blockchain [Online], available: http://bravenewcoin.com/assets/Whitepapers/Factom-Whitepaper.pdf, November 17, 2014. -

 下载:
下载:



图(5) / 表(2)
计量
- 文章访问数: 5743
- HTML全文浏览量: 3980
- PDF下载量: 4050
- 被引次数: 0
