

Collaborative Filtering Recommendation Algorithm Based on Rating Matrix Filling and Item Predictability
-
摘要: 针对传统矩阵填充算法忽略了预测评分与真实评分之间的可信度差异和传统Top-N方法推荐精度低等问题,提出了一种改进的协同过滤算法.该算法首先利用置信系数C区分评分值之间的可信度;然后提出物品可预测性的概念,综合物品的预测评分与物品的可预测性进行物品推荐并将其转化为0-1背包问题,从而筛选出最优化的推荐列表.实验结果表明:该算法能有效缓解稀疏性的影响,提高推荐性能,并且算法具有良好的可扩展性.Abstract: The traditional matrix filling algorithm ignores the difference between true rating and predictive rating, and there is only one standard on the traditional Top-N recommended method. In order to solve these two problems, an improved collaborative filtering algorithm is proposed. Firstly, the confidence coefficient is used to distinguish the credibility of the ratings. Then, a concept of item predictability is proposed. The program recommends items by comprehensively considering the item's predictive ratings and the predictability, and transforming the program into the 0-1 knapsack problem so as to select the optimized recommended list. Experimental results show that the algorithm can effectively alleviate the effect of sparsity and improve the performance of the recommendation, and that the optimization algorithm has good expansibility.
-
Key words:
- Collaborative filtering /
- recommendation system /
- predictive ratings /
- similarity /
- 0-1 knapsack problem
1) 本文责任编委 周涛 -
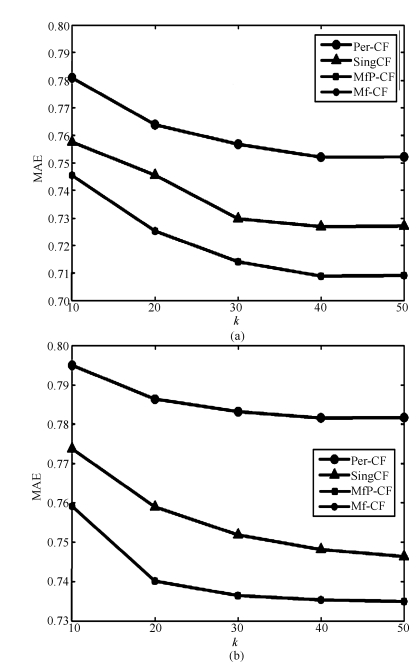
图 4 Movielens_100k中 $k$ 与MAE的关系
Fig. 4 The relationship between $k$ and MAE in Movielens_100k
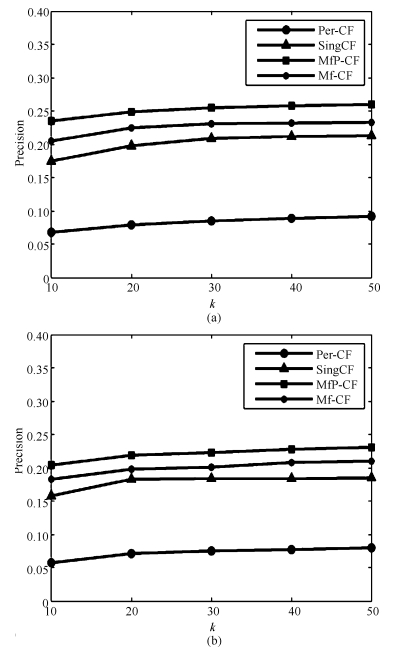
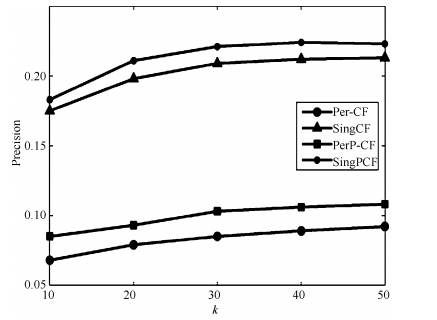
图 5 Movielens_100k中 $k$ 与precision的关系
Fig. 5 The relationship between $k$ and precision in Movielens_100k

图 6 Movielens_100k中 $k$ 与Coverage的关系
Fig. 6 The relationship between $k$ and Coverage in Movielens_100k

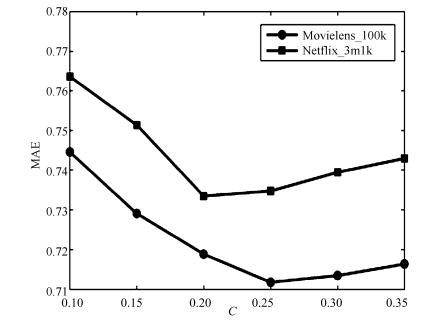
图 7 Movielens_100k中稀疏度与MAE的关系
Fig. 7 The relationship between sparsity and MAE in Movielens_100k
-
[1] Chen Y, Tsai W T. Service-Oriented Computing and Web Software Integration: From Principles to Development (Fourth edition). Dubuque, IA, USA: Kendall Hunt Publishing, 2014. http://dl.acm.org/citation.cfm?id=2559268 [2] Yu F, Zeng A, Gillard S, Medo M. Network-based recommendation algorithms: a review. Physica A: Statistical Mechanics and its Applications, 2016, 452: 192-208 doi: 10.1016/j.physa.2016.02.021 [3] 孙光福, 吴乐, 刘淇, 朱琛, 陈恩红.基于时序行为的协同过滤推荐算法.软件学报, 2013, 24(11): 2721-2733 http://cdmd.cnki.com.cn/Article/CDMD-10358-1014299735.htmSun Guang-Fu, Wu Le, Liu Qi, Zhu Chen, Chen En-Hong. Recommendations based on collaborative filtering by exploiting sequential behaviors. Journal of Software, 2013, 24(11): 2721-2733 http://cdmd.cnki.com.cn/Article/CDMD-10358-1014299735.htm [4] Hernando A, Bobadilla J, Ortega F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowledge-Based Systems, 2016, 97: 188-202 doi: 10.1016/j.knosys.2015.12.018 [5] Lv G, Hu C L, Chen S B. Research on recommender system based on ontology and genetic algorithm. Neurocomputing, 2016, 187: 92-97 doi: 10.1016/j.neucom.2015.09.113 [6] Mashal I, Alsaryrah O, Chung T Y. Performance evaluation of recommendation algorithms on internet of things services. Physica A: Statistical Mechanics and its Applications, 2016, 451: 646-656 doi: 10.1016/j.physa.2016.01.051 [7] Zhang J, Peng Q K, Sun S Q, Liu C. Collaborative filtering recommendation algorithm based on user preference derived from item domain features. Physica A: Statistical Mechanics and its Applications, 2014, 396: 66-76 doi: 10.1016/j.physa.2013.11.013 [8] Kim H N, Ji A T, Ha I, Jo G S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electronic Commerce Research and Applications, 2010, 9(1): 73-83 doi: 10.1016/j.elerap.2009.08.004 [9] 李聪, 骆志刚.基于数据非随机缺失机制的推荐系统托攻击探测.自动化学报, 2013, 39(10): 1681-1690 http://www.aas.net.cn/CN/abstract/abstract18205.shtmlLi Cong, Luo Zhi-Gang. Detecting shilling attacks in recommender systems based on non-random-missing mechanism. Acta Automatica Sinica, 2013, 39(10): 1681-1690 http://www.aas.net.cn/CN/abstract/abstract18205.shtml [10] 冷亚军, 梁昌勇, 丁勇, 陆青.协同过滤中一种有效的最近邻选择方法.模式识别与人工智能, 2013, 26(10): 968-974 doi: 10.3969/j.issn.1003-6059.2013.10.009Leng Ya-Jun, Liang Chang-Yong, Ding Yong, Lu Qing. Method of neighborhood formation in collaborative filtering. Pattern Recognition and Artificial Intelligence, 2013, 26(10): 968-974 doi: 10.3969/j.issn.1003-6059.2013.10.009 [11] 邓爱林, 朱扬勇, 施伯乐.基于项目评分预测的协同过滤推荐算法.软件学报, 2003, 14(9): 1621-1628 http://cdmd.cnki.com.cn/Article/CDMD-10663-1016757098.htmDeng Ai-Lin, Zhu Yang-Yong, Shi Bo-Le. A collaborative filtering recommendation algorithm based on item rating prediction. Journal of Software, 2013, 14(9): 1621-1628 http://cdmd.cnki.com.cn/Article/CDMD-10663-1016757098.htm [12] Xu R Z, Wang S Q, Zheng X W, Chen Y N. Distributed collaborative filtering with singular ratings for large scale recommendation. Journal of Systems and Software, 2014, 95: 231-241 doi: 10.1016/j.jss.2014.04.045 [13] 陈刚, 刘发升.基于BP神经网络的数据挖掘方法.计算机与现代化, 2006, (10): 20-22 doi: 10.3969/j.issn.1006-2475.2006.10.007Chen Gang, Liu Fa-Sheng. Method for data mining based on BP neural network. Computer and Modernization, 2006, (10): 20-22 doi: 10.3969/j.issn.1006-2475.2006.10.007 [14] Jang S, Yang J, Kim D K. Minimum MSE design for multiuser MIMO relay. IEEE Communications Letters, 2010, 14(9): 812-814 doi: 10.1109/LCOMM.2010.072610.100583 [15] Eldar Y C. Universal weighted MSE improvement of the least-squares estimator. IEEE Transactions on Signal Processing, 2008, 56(5): 1788-1800 doi: 10.1109/TSP.2007.913158 [16] Kaleli C. An entropy-based neighbor selection approach for collaborative filtering. Knowledge-Based Systems, 2014, 56: 273-280 doi: 10.1016/j.knosys.2013.11.020 [17] Zou D X, Gao L Q, Li S, Wu J H. Solving 0-1 knapsack problem by a novel global harmony search algorithm. Applied Soft Computing, 2011, 11(2): 1556-1564 doi: 10.1016/j.asoc.2010.07.019 [18] 高建煌, 陈恩红, 刘淇.基于用户兴趣传播的协同过滤方法.电子技术, 2010, 47(6): 1-4 http://www.cnki.com.cn/Article/CJFDTOTAL-DZJS201006003.htmGao Jian-Huang, Chen En-Hong, Liu Qi. User interests transmission based collaborative filtering approach. Electronic Technology, 2010, 47(6): 1-4 http://www.cnki.com.cn/Article/CJFDTOTAL-DZJS201006003.htm [19] Javari A, Gharibshah J, Jalili M. Recommender systems based on collaborative filtering and resource allocation. Social Network Analysis and Mining, 2014, 4: 234 doi: 10.1007/s13278-014-0234-0 [20] Hu Y C. Recommendation using neighborhood methods with preference-relation-based similarity. Information Sciences, 2014, 284: 18-30 doi: 10.1016/j.ins.2014.06.043 [21] Choi K, Suh Y. A new similarity function for selecting neighbors for each target item in collaborative filtering. Knowledge-Based Systems, 2013, 37: 146-153 doi: 10.1016/j.knosys.2012.07.019 [22] 朱郁筱, 吕琳媛.推荐系统评价指标综述.电子科技大学学报, 2012, 41(2): 163-175 http://www.cnki.com.cn/Article/CJFDTOTAL-DKDX201202003.htmZhu Yu-Xiao, Lv Lin-Yuan. Evaluation metrics for recommender systems. Journal of University of Electronic Science and Technology of China, 2012, 41(2): 163-175 http://www.cnki.com.cn/Article/CJFDTOTAL-DKDX201202003.htm -

 下载:
下载:


计量
- 文章访问数: 2320
- HTML全文浏览量: 449
- PDF下载量: 841
- 被引次数: 0
