

-
摘要: 聚焦模型(Attention model,AM)将计算资源集中于输入数据特定区域,相比卷积神经网络,AM具有参数少、计算量独立输入和高噪声下正确率较高等优点.相对于输入图像和识别目标,聚焦区域通常较小;如果聚焦区域过小,就会导致过多的迭代次数,降低了效率,也难以在同一输入中寻找多个目标.因此本文提出多焦点聚焦模型,同时对多处并行聚焦.使用增强学习(Reinforce learning,RL)进行训练,将所有焦点的行为统一评分训练.与单焦点聚焦模型相比,训练速度和识别速度提高了25%.同时本模型具有较高的通用性.Abstract: Attention model (AM) concentrates computing resources on specific areas of the input data. Compared with the convolutional neural network, AM has many advantages: fewer parameters, the amount of computation being independent of the input, higher tolerance for noise input, etc. Generally, the focused area is smaller than the input image and target. However, if the focused area is too small, it will lead to more iterations and a low efficiency; besides, it is difficult to recognize multiple targets in the same input. Therefore, this paper proposes a multi-focus model. However, if on multiple focuses in parallel. This model uses reinforce learning (RL) to train, and scores the behaviors of all focuses uniformly during training. Compared with the single focus model, both the training and recognition speeds are improved by 25%. At the same time, the model has good generality.
-
Key words:
- Deep learning /
- attention model (AM) /
- reinforce learning (RL) /
- multi-attention
-
-

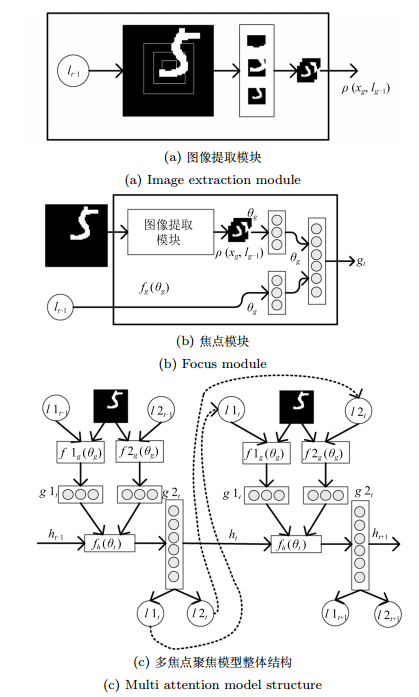
图 4 多焦点模型在60像素× 60像素图像中识别的效果
Fig. 4 Recognition process of multi attention model in 60 × 60 image dataset
表 1 多焦点模型错误率
Table 1 Multi-attention model error rate
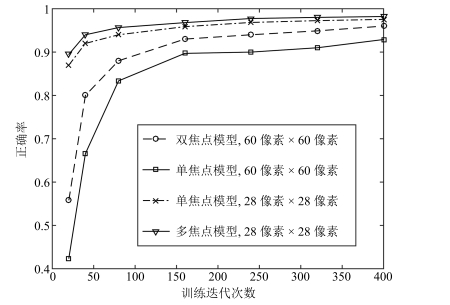
模型 错误率(%) RAM, 2次 8.11 RAM, 4次 3.28 RAM, 6次 2.11 RAM, 8次 1.55 RAM, 10次 1.26 多焦点模型, 2次 4.17 多焦点模型, 4次 2.59 多焦点模型, 6次 1.58 多焦点模型, 8次 1.19 多焦点模型, 10次 1.19  下载: 导出CSV
下载: 导出CSV
表 2 随机坐标错误率
Table 2 Random position error rate
模型 错误率(%) RAM, 2次 1.51 RAM, 4次 1.29 RAM, 6次 1.22 多焦点模型, 2次 2.81 多焦点模型, 4次 1.55 多焦点模型, 6次 1.01
下载: 导出CSV
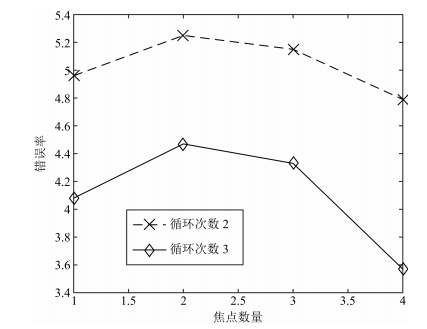
表 3 噪声环境对比
Table 3 Noisy dataset error rate between RAM and multi attention model
模型 错误率(%) RAM, 2次 4.96 RAM, 4次 4.08 RAM, 6次 4.04 多焦点模型, 2次 5.25 多焦点模型, 4次 4.47 多焦点模型, 6次 3.43
下载: 导出CSV
-
[1] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [2] Mordvintsev A, Olah C, Tyka M. Inceptionism: going deeper into neural networks [Online], available: http://research.googleblog.com/2015/06/inceptionism-goi-ng-deeper-into-neural.html, August 22, 2016 [3] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012. 1097-1105 http://dl.acm.org/citation.cfm?id=2999257 [4] Girshick R, Donahue J, Darrell T, Malik J. Rich feature Hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 580-587 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6909475 [5] Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y. OverFeat: integrated recognition, localization and detection using convolutional networks [Online], available: http://arxiv.org/abs/1312.6229, August 22, 2016 http://www.oalib.com/paper/4042258 [6] Felzenszwalb P F, Girshick R B, McAllester D. Cascade object detection with deformable part models. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 2241-2248 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5539906 [7] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA: IEEE, 2001. 511-518 [8] Mnih V, Heess N, Graves A, Kavukcuoglu K. Recurrent models of visual attention. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2014. 2204-2212 http://dl.acm.org/citation.cfm?id=2969073 [9] Rensink R A. The dynamic representation of scenes. Visual Cognition, 2000, 7(1-3): 17-42 doi: 10.1080/135062800394667 [10] Yoo D, Park S, Lee J Y, Paek A S, Kweon I S. AttentionNet: aggregating weak directions for accurate object detection [Online], available: http://arxiv.org/abs/1506.07704, August 22, 2016 [11] Stollenga M F, Masci J, Gomez F, Schmidhuber J. Deep networks with internal selective attention through feedback connections. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2014. 4(2): 107-122 http://www.ams.org/mathscinet-getitem?mr=1312581 [12] Legrand J, Collobert R. Jiont RNN-based greedy parsing and word composition [Online], avaliable: https://arxiv.org/abs/1412.7028?context=cs, August 22, 2016 http://arxiv.org/abs/1412.7028 [13] Alexe B, Heess N, Teh Y W, Ferrari V. Searching for objects driven by context. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012. 881-889 http://dl.acm.org/citation.cfm?id=2999233 [14] 冯欣, 杨丹, 张凌.基于视觉注意力变化的网络丢包视频质量评估.自动化学报, 2011, 37(11): 1322-1331 http://www.aas.net.cn/CN/abstract/abstract17526.shtmlFeng Xin, Yang Dan, Zhang Ling. Saliency variation based quality assessment for packet-loss-impaired videos. Acta Automatica Sinica, 2011, 37(11): 1322-1331 http://www.aas.net.cn/CN/abstract/abstract17526.shtml [15] 刘龙, 樊波阳, 刘金星, 杨乐超.面向运动目标检测的粒子滤波视觉注意力模型.电子学报, 2016, 44(9): 2235-2241 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201609031.htmLiu Long, Fan Bo-Yang, Liu Jin-Xing, Yang Le-Chao. Particle filtering based visual attention model for moving target detection. Acta Electronica Sinica, 2016, 44(9): 2235-2241 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201609031.htm [16] 张冲. 基于Attention-Based LSTM模型的文本分类技术的研究[硕士学位论文], 南京大学, 中国, 2016. http://cdmd.cnki.com.cn/Article/CDMD-10284-1016136802.htmZhang Chong. Text Classification Based on Attention-Based LSTM Model [Master dissertation], Nanjing University, China, 2016. http://cdmd.cnki.com.cn/Article/CDMD-10284-1016136802.htm [17] Denil M, Bazzani L, Larochelle H, de Freitas N. Learning where to attend with deep architectures for image tracking. Neural Computation, 2012, 24(8): 2151-2184 doi: 10.1162/NECO_a_00312 [18] Paletta L, Fritz G, Seifert C. Q-learning of sequential attention for visual object recognition from informative local descriptors. In: Proceedings of the 22nd International Conference on Machine Learning. New York, NY, USA: ACM, 2005. 649-656 http://dl.acm.org/citation.cfm?id=1102433 [19] Ranzato M. On learning where to look [Online], available: http://arxiv.org/abs/1405.5488, August 22, 2016. [20] Stanley K O, Miikkulainen R. Evolving a roving eye for go. In: Proceedings of the 2004 Genetic and Evolutionary Computation Conference. Berlin, Heidelberg, Germany: Springer, 2004. 1226-1238 http://www.springerlink.com/index/96y7lyycbj8k67ey.pdf [21] Larochelle H, Hinton G. Learning to combine foveal glimpses with a third-order Boltzmann machine. In: Proceedings of the 23rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2010. 1243-1251 http://dl.acm.org/citation.cfm?id=2997328 -





图(8) / 表(3)
计量
- 文章访问数: 1536
- HTML全文浏览量: 575
- PDF下载量: 999
- 被引次数: 0
