

-
摘要: 以移动设备、车辆、飞机、飓风等移动对象不确定性轨迹预测问题为背景,将大规模移动对象数据作为研究对象,以频繁轨迹模式挖掘、高斯混合回归技术为主要研究手段,提出多模式移动对象轨迹预测模型,关键技术包括:1)针对单一运动模式,提出一种基于频繁轨迹模式树FTP-tree的轨迹预测方法,利用基于密度的热点区域挖掘算法将轨迹点划分成不同的聚簇,构建轨迹频繁模式树,挖掘频繁轨迹模式预测移动对象连续运动位置.不同数据集上实验结果表明基于FTP-tree的轨迹预测算法在保证时间效率的前提下预测准确性明显优于已有预测算法.2)针对复杂多模式运动行为,利用高斯混合回归方法建模,计算不同运动模式的概率分布,将轨迹数据划分为不同分量,利用高斯过程回归预测移动对象最可能运动轨迹.实验证明,相比于基于隐马尔科夫模型和卡尔曼滤波的预测方法,所提方法具有较高的预测准确性和较低的时间代价.Abstract: This study aims to solve the problem of predicting uncertain trajectories of moving objects, including mobile devices, vehicles, airplanes, and hurricanes. In order to design a general schema of trajectory prediction on large-scale moving objects data, techniques of frequent trajectory patterns mining and Gaussian mixture regression model are employed, and a multiple-motion-pattern trajectory prediction model is proposed. The proposed key techniques include:1) as for simple motion patterns, a new trajectory prediction algorithm based on frequent trajectory pattern tree (FTP-tree) is proposed, which employs a density based region-of-interest discovery approach to partition a large number of trajectory points into distinct clusters. Then, it generates a frequent trajectory pattern tree to forecast continuous locations of moving objects. Experimental results show that the FTP-tree based trajectory prediction algorithm performs better than existing prediction approaches with the guarantee of time efficiency. 2) Gaussian mixture regression approach is used to model complex multiple motion patterns, which calculates the probability distribution of different types of motion patterns, as well as partitions trajectory data into distinct components, in order to predict the most possible trajectories of moving objects via Gaussian process regression. Experimental results show a high accuracy and low time consumption on trajectory prediction, as compared to the hidden Markov model approach and the Kalman filter one.1) 本文责任编委 黎铭
-
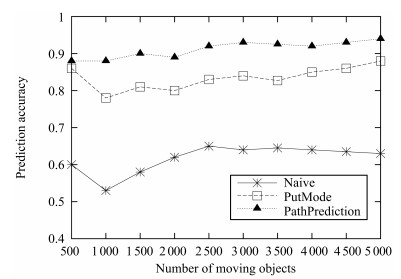
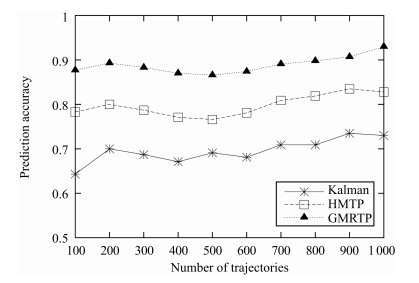
图 1 Chengdu数据集下不同算法预测准确率比较
Fig. 1 Prediction accuracy comparison of different algorithms under Chengdu datasets
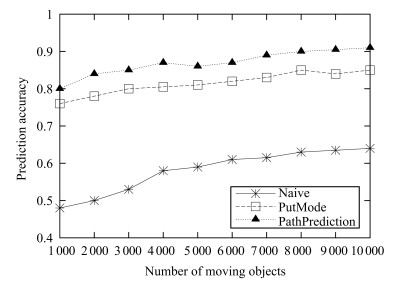
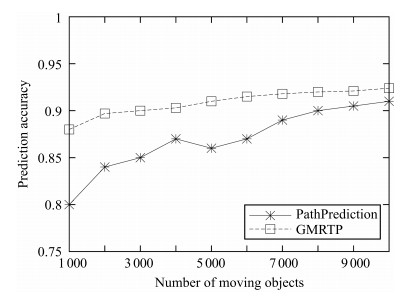
图 2 GeoLife数据集下不同算法预测准确率比较
Fig. 2 Prediction accuracy comparison of different algorithms under GeoLife datasets
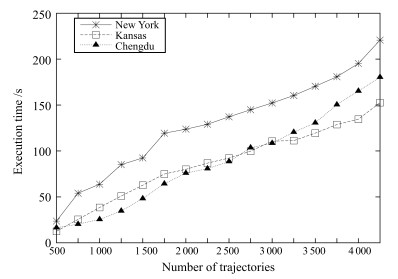
图 3 PathPrediction算法在不同数据集下预测时间比较
Fig. 3 Prediction tiof PathPrediction algorithm under different datasets

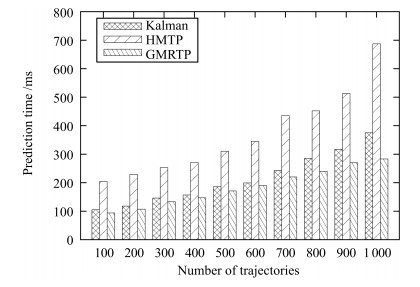
图 4 Chengdu数据集下不同算法预测时间比较
Fig. 4 Prediction time comparison of different algorithms under Chengdu datasets

图 5 GeoLife数据集下不同算法预测时间比较
Fig. 5 Prediction time comparison of different algorithms under GeoLife datasets

图 6 不同高斯过程分量下轨迹预测误差比较
Fig. 6 Prediction error comparison with distinct Gaussian regression components
-
[1] Meng X F, Ding Z M, Xu J J. Moving Objects Management:Models, Techniques and Applications. Berlin:Springer-Verlag, 2014. 117-131 [2] Hu W M, Xiao X J, Fu Z Y, Xie D, Tan T N, Maybank S. A system for learning statistical motion patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(9):1450-1464 doi: 10.1109/TPAMI.2006.176 [3] Parker A, Subrahmanian V S, Grant J. Fast and accurate prediction of the destination of moving objects. In: Proceedings of the 3rd International Conference on Scalable Uncertainty Management. Berlin, Germany: Springer, 2009. 180-192 [4] Song C M, Qu Z H, Blumm N, Barabási A L. Limits of predictability in human mobility. Science, 2010, 327(5968):1018-1021 doi: 10.1126/science.1177170 [5] Centola D. The spread of behavior in an online social network experiment. Science, 2010, 329(5996):1194-1197 doi: 10.1126/science.1185231 [6] Jeung H, Yiu M L, Zhou X F, Jensen C S. Path prediction and predictive range querying in road network databases. The VLDB Journal, 2010, 19(4):585-602 doi: 10.1007/s00778-010-0181-y [7] Zhou J B, Tung A K H, Wu W, Ng W S. A "semi-lazy" approach to probabilistic path prediction in dynamic environments. In: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2013. 748-756 [8] Pan T L, Sumalee A, Zhong R X, Indra-payoong N. Short-term traffic state prediction based on temporal-spatial correlation. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(3):1242-1254 doi: 10.1109/TITS.2013.2258916 [9] Qiao S J, Shen D Y, Wang X T, Han N, Zhu W. A self-adaptive parameter selection trajectory prediction approach via hidden Markov models. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(1):284-296 doi: 10.1109/TITS.2014.2331758 [10] 乔少杰, 李天瑞, 韩楠, 高云君, 元昌安, 王晓腾, 唐常杰.大数据环境下移动对象自适应轨迹预测模型.软件学报, 2015, 26(11):2869-2883 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=rjxb201511011&dbname=CJFD&dbcode=CJFQQiao Shao-Jie, Li Tian-Rui, Han Nan, Gao Yun-Jun, Yuan Chang-An, Wang Xiao-Teng, Tang Chang-Jie. Self-adaptive trajectory prediction model for moving objects in big data environment. Journal of Software, 2015, 26(11):2869-2883 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=rjxb201511011&dbname=CJFD&dbcode=CJFQ [11] Ding Z M, Yang B, Güting R H, Li Y G. Network-matched trajectory-based moving-object database:models and applications. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4):1918-1928 doi: 10.1109/TITS.2014.2383494 [12] Xu J J, Gao Y J, Liu C F, Zhao L, Ding Z M. Efficient route search on hierarchical dynamic road networks. Distributed and Parallel Databases, 2015, 33(2):227-252 doi: 10.1007/s10619-014-7146-x [13] Dai J, Yang B, Guo C J, Ding Z M. Personalized route recommendation using big trajectory data. In: Proceedings of the 31st IEEE International Conference on Data Engineering. Seoul, South Korea: IEEE Computer Society, 2015. 543-554 [14] Tripathy S, Howard C J. Multiple trajectory tracking. Scholarpedia, 2012, 7(4):Article No. 11287 doi: 10.4249/scholarpedia.11287 [15] Xu J Q, Güting R H. A generic data model for moving objects. Geoinformatica, 2013, 17(1):125-172 doi: 10.1007/s10707-012-0158-7 [16] 黄玉龙, 张勇刚, 李宁, 赵琳.一种改进的高斯近似滤波方法.自动化学报, 2016, 42(3):385-401 http://www.aas.net.cn/CN/abstract/abstract18828.shtmlHuang Yu-Long, Zhang Yong-Gang, Li Ning, Zhao Lin. An improved Gaussian approximate filtering method. Acta Automatica Sinica, 2016, 42(3):385-401 http://www.aas.net.cn/CN/abstract/abstract18828.shtml [17] 陈成, 何玉庆, 卜春光, 韩建达.基于四阶贝塞尔曲线的无人车可行轨迹规划.自动化学报, 2015, 41(3):486-496 http://www.aas.net.cn/CN/abstract/abstract18627.shtmlChen Cheng, He Yu-Qing, Bu Chun-Guang, Han Jian-Da. Feasible trajectory generation for autonomous vehicles based on quartic Bézier curve. Acta Automatica Sinica, 2015, 41(3):486-496 http://www.aas.net.cn/CN/abstract/abstract18627.shtml [18] Monfort M, Liu A Q, Ziebart B D. Intent prediction and trajectory forecasting via predictive inverse linear-quadratic regulation. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AAAI, 2015. 3672-3678 [19] Qiao S J, Han N, Zhu W, Gutierrez L A. TraPlan:an effective three-in-one trajectory-prediction model in transportation networks. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(3):1188-1198 doi: 10.1109/TITS.2014.2353302 [20] Han J W, Pei J, Yin Y W, Mao R Y. Mining frequent patterns without candidate generation:a frequent-pattern tree approach. Data Mining and Knowledge Discovery, 2004, 8(1):53-87 doi: 10.1023/B:DAMI.0000005258.31418.83 [21] Rasmussen C E, Williams C K I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning). Cambridge, USA:The MIT Press, 2005. 12-22 [22] 余建波, 卢笑蕾, 宗卫周.基于局部与非局部线性判别分析和高斯混合模型动态集成的晶圆表面缺陷探测与识别.自动化学报, 2016, 42(1):47-59 http://www.aas.net.cn/CN/abstract/abstract18795.shtmlYu Jian-Bo, Lu Xiao-Lei, Zong Wei-Zhou. Wafer defect detection and recognition based on local and nonlocal linear discriminant analysis and dynamic ensemble of Gaussian mixture models. Acta Automatica Sinica, 2016, 42(1):47-59 http://www.aas.net.cn/CN/abstract/abstract18795.shtml [23] Dellaert F. The Expectation Maximization Algorithm, Technical Report GIT-GVU-02-20, Colleage of Computing, Georgia Institute of Technology, USA, 2002. [24] Qiao S J, Tang C J, Jin H D, Long T, Dai S C, Ku Y C, Chau M. PutMode:prediction of uncertain trajectories in moving objects databases. Applied Intelligence, 2010, 33(3):370-386 doi: 10.1007/s10489-009-0173-z [25] Brinkhoff T. A framework for generating network-based moving objects. GeoInformatica, 2002, 6(2):153-180 doi: 10.1023/A:1015231126594 [26] Zheng Y, Xie X, Ma W Y. Geolife:a collaborative social networking service among user, location and trajectory. IEEE Data(base) Engineering Bulletin, 2010, 33(2):32-40 http://www.mendeley.com/catalog/geolife-collaborative-social-networking-service-among-user-location-trajectory/ [27] 邓胡滨, 张磊, 吴颖, 周洁, 刘枫.基于卡尔曼滤波算法的轨迹估计研究.传感器与微系统, 2012, 31(5):4-7 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=cgqj201205003&dbname=CJFD&dbcode=CJFQDeng Hu-Bin, Zhang Lei, Wu Ying, Zhou Jie, Liu Feng. Research on track estimation based on Kalman filtering algorithm. Transducer and Microsystem Technologies, 2012, 31(5):4-7 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=cgqj201205003&dbname=CJFD&dbcode=CJFQ -

 下载:
下载:

计量
- 文章访问数: 2849
- HTML全文浏览量: 951
- PDF下载量: 1322
- 被引次数: 0
