

-
摘要: 社交网络与人们的生活息息相关,其上的用户行为可用于检测社交网络中的事件突发性,进而准确定位事件的发生区间.但用户行为易受主观及外部因素的影响,有时会出现隐式事件突发性,给事件突发性检测带来困难.本文针对社交网络中的隐式事件突发性问题,在以社交行为特征进行事件突发性检测的基础上,引入关键词特征,动态调整各个时间窗口的候选关键词,将不同事件与不同的关键词特征绑定,避免事件之间及噪音带来的干扰,实现对隐式事件突发性的准确识别.相关实验表明,本文提出的算法可有效改善现有社交网络中事件突发性检测任务的效果.Abstract: Social networks are closely bound up with our daily life, in which behaviors of users can be used for detection of event-related bursts and further for determination of the time period for each event. But latent event-related bursts, which result from internal or external impacts on users' behaviors, will be difficult to identify. In this paper, in order to solve the detection problem of latent event-related bursts in social networks, on the basis of event burst detection via social behavior features, we introduce the features of keywords and dynamically change the keyword candidates for each time window, so as to bind different events with different keywords, aiming to avoid interferences from inter-events or noise and discover latent event-related bursts more accurately. Experimental results show that our proposed method can improve the performance of event-related burst detection in social networks compared with existing algorithms.
-
Key words:
- Burst /
- event /
- detection /
- social network
1) 本文责任编委 张民 -
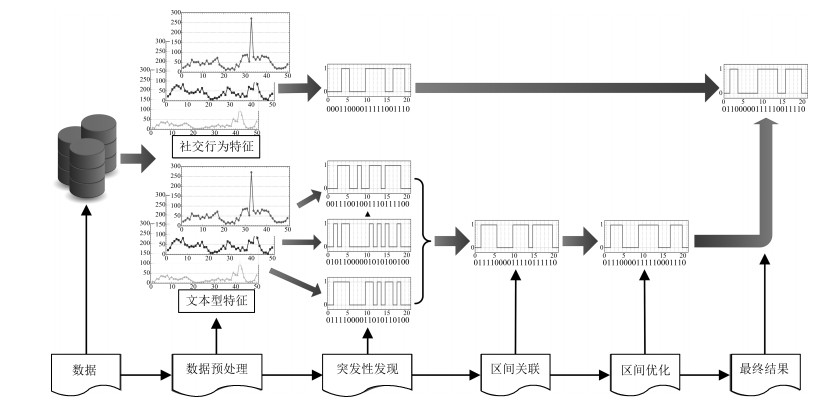
图 5 社交网络中事件突发性检测方案流程示意图
Fig. 5 The flow diagram of event-related burst detection in social networks
表 1 数据集HD上各算法实验结果
Table 1 The experimental results of different algorithms on dataset HD
实验项目 实验结果 Method Feature/Strategy $P$ $R$ $F$ all 0.9000 0.3846 0.5389 post 0.8352 0.3462 0.4894 Single repost $\textbf{0.9902}$ $\textbf{0.5385}$ $\textbf{0.6976}$ url 0.6803 0.3846 0.4914 user 0.6573 0.4615 0.5423 Multi post+repost+url $\textbf{0.9525}$ $\textbf{0.6923}$ $ \textbf{0.8018}$ conjunct 1.0000 0.5385 0.7000 Comb disjunct $\textbf{0.8256}$ $\textbf{0.9231}$ $\textbf{0.8716}$ hybrid 0.9949 0.6923 0.8165  下载: 导出CSV
下载: 导出CSV
表 2 数据集BA上各算法实验结果
Table 2 The experimental results of different algorithms on dataset BA
实验项目 实验结果 Method Feature/Strategy $P$ $R$ $F$ all $\textbf{0.9662}$ $ \textbf{0.4000}$ $\textbf{0.5658}$ post 0.9740 0.2000 0.3319 Single repost 0.8640 0.3000 0.4454 url 0.2574 0.1333 0.1757 user 0.7346 0.3333 0.4586 Multi post+repost+url $\textbf{0.8787}$ $\textbf{0.4667}$ $\textbf{0.6096}$ conjunct 0.9554 0.2667 0.4170 Comb disjunct $\textbf{0.9030} $ $ \textbf{0.5333}$ $\textbf{0.6706}$ hybrid 0.8051 0.5667 0.6652
下载: 导出CSV
表 3 单独使用关键词特征时实验结果
Table 3 The experimental results with only keyword features
数据集 实验结果 $P$ $R$ $F$ HD $\textbf{0.7709}$ $\textbf{0.7692}$ $\textbf{0.7701}$ BA $\textbf{0.6327}$ $\textbf{0.3667}$ $\textbf{0.4643} $
下载: 导出CSV
表 4 事件$A$, $B$的关键词提取结果
Table 4 Extracted keywords of event $A$ and $B$
时间窗口 关键词(Top 3) 2015-10-21 19时 恒大、决赛、亚冠、广州2015-10-21 20时 恒大、决赛、亚冠、广州2015-10-21 21时 恒大、决赛、亚冠、进2015-10-22 19时 恒大、英国、峰会、工商2015-10-22 20时 恒大、集团、英国、峰会2015-10-22 21时 恒大、英国、峰会、工商
下载: 导出CSV
-
[1] Zhao W X, Shu B H, Jiang J, Song Y, Yan H F, Li X M. Identifying event-related bursts via social media activities. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA, USA: ACL, 2012. 1466-1477 http://www.researchgate.net/publication/262285003_Identifying_event-related_bursts_via_social_media_activities [2] Kleinberg J. Bursty and hierarchical structure in streams. Data Mining and Knowledge Discovery, 2003, 7(4):373-397 doi: 10.1023/A:1024940629314 [3] Swan R, Allan J. Extracting significant time varying features from text. In: Proceedings of the 8th International Conference on Information and Knowledge Management. New York, NY, USA: ACM, 1999. 38-45 http://www.researchgate.net/publication/2450599_Extracting_Significant_Time_Varying_Features_from_Text [4] Swan R, Allan J. Automatic generation of overview time-lines. In: Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY, USA: ACM, 2000. 49-56 http://www.researchgate.net/publication/221299242_Automatic_generation_of_overview_timelines [5] Mei Q Z, Zhai C X. Discovering evolutionary theme patterns from text: an exploration of temporal text mining. In: Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining. New York, NY, USA: ACM, 2005. 198-207 http://www.researchgate.net/publication/220272030_Discovering_evolutionary_theme_patterns_from_text_an_exploration_of_temporal_text_mining [6] Marcus A, Bernstein M S, Badar O, Karger D R, Madden S, Miller R C. Twitinfo: aggregating and visualizing microblogs for event exploration. In: Proceedings of the 2011 SIGCHI Conference on Human Factors in Computing Systems. New York, NY, USA: ACM, 2011. 227-236 http://www.researchgate.net/publication/228977615_TwitInfo_Aggregating_and_visualizing_microblogs_for_event_exploration [7] Takahashi T, Tomioka R, Yamanishi K. Discovering emerging topics in social streams via link-anomaly detection. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):120-130 doi: 10.1109/TKDE.2012.239 [8] 张鲁民, 贾焰, 周斌, 赵金辉, 洪锋.一种基于情感符号的在线突发事件检测方法.计算机学报, 2013, 36(8):1659-1667 http://edu.wanfangdata.com.cn/Periodical/Detail/jsjxb201308010Zhang Lu-Min, Jia Yan, Zhou Bin, Zhao Jin-Hui, Hong Feng. Online bursty events detection based on emoticons. Chinese Journal of Computers, 2013, 36(8):1659-1667 http://edu.wanfangdata.com.cn/Periodical/Detail/jsjxb201308010 [9] Chen F, Neill D B. Non-parametric scan statistics for event detection and forecasting in heterogeneous social media graphs. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM, 2014. 1166-1175 http://dl.acm.org/citation.cfm?id=2623619 [10] Zhang X M, Li Z J, Chao W H, Xia J L. Popularity prediction of burst event in microblogging. In: Proceedings of the 15th International Conference on Web-Age Information Management. Macau, China: Springer, 2014. 484-487 doi: 10.1007%2F978-3-319-08010-9_53 [11] Aiello L M, Petkos G, Martin C, Corney D, Papadopoulos S, Skraba R, Goker A, Kompatsiaris I, Jaimes A. Sensing trending topics in twitter. IEEE Transactions on Multimedia, 2013, 15(6):1268-1282 doi: 10.1109/TMM.2013.2265080 [12] 冯冲, 石戈, 郭宇航, 龚静, 黄河燕.基于词向量语义分类的微博实体链接方法.自动化学报, 2016, 42(6):915-922 http://www.aas.net.cn/CN/abstract/abstract18882.shtmlFeng Chong, Shi Ge, Guo Yu-Hang, Gong Jing, Huang He-Yan. An entity linking method for microblog based on semantic categorization by word embeddings. Acta Automatica Sinica, 2016, 42(6):915-922 http://www.aas.net.cn/CN/abstract/abstract18882.shtml [13] Fung G P C, Yu J X, Yu P S, Lu H J. Parameter free bursty events detection in text streams. In: Proceedings of the 31st International Conference on Very Large Data Bases. New York, NY, USA: ACM, 2005. 181-192 http://www.researchgate.net/publication/221309682_Parameter_Free_Bursty_Events_Detection_in_Text_Streams [14] Urabe Y, Yamanishi K, Tomioka R, Iwai H. Real-time change-point detection using sequentially discounting normalized maximum likelihood coding. In: Proceedings of the 15th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining. Berlin, Heidelberg, Germany: Springer-Verlag, 2011. 185-197 [15] Mathioudakis M, Koudas N. TwitterMonitor: trend detection over the twitter stream. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data. New York, NY, USA: ACM, 2010. 1155-1158 http://www.researchgate.net/publication/221213158_TwitterMonitor_trend_detection_over_the_twitter_stream [16] Allan J, Carbonell J G, Doddington G, Yamron J, Yang Y M. Topic detection and tracking pilot study final report. In: Proceedings of the 1998 DARPA Broadcast News Transcription and Understanding Workshop. Lansdowne, Virginia, USA: DARPA, 1998. 194-218 [17] Atefeh F, Khreich W. A survey of techniques for event detection in twitter. Computational Intelligence, 2015, 31(1):132-164 doi: 10.1111/coin.v31.1 [18] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation. Journal of Machine Learning Research, 2003, 3:993-1022 http://ci.nii.ac.jp/naid/20001460587 [19] Zhao W X, Chen R S, Fan K, Yan H F, Li X M. A novel burst-based text representation model for scalable event detection. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: ACL, 2012, 2: 43-47 [20] Zhao W X, Jiang J, Weng J S, He J, Lim E P, Yan H F, Li X M. Comparing twitter and traditional media using topic models. In: Proceedings of the 33rd European Conference on Advances in Information Retrieval. Berlin, Heidelberg, Germany: Springer-Verlag, 2011. 338-349 [21] Diao Q M, Jiang J, Zhu F D, Lim E P. Finding bursty topics from microblogs. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: ACL, 2012, 1: 536-544 [22] Hong L J, Ahmed A, Gurumurthy S, Smola A J, Tsioutsiouliklis K. Discovering geographical topics in the twitter stream. In: Proceedings of the 21st International Conference on World Wide Web. New York, NY, USA: ACM, 2012. 769 -778 [23] Weng J S, Lee B S. Event detection in twitter. In: Proceedings of the 2011 International AAAI Conference on Web and Social Media. Palo Alto, CA, USA: AAAI, 2011. 401-408 [24] Wang Z H, Shou L D, Chen K, Chen G, Mehrotra S. On summarization and timeline generation for evolutionary tweet streams. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(5):1301-1315 doi: 10.1109/TKDE.2014.2345379 [25] Sakaki T, Okazaki M, Matsuo Y. Earthquake shakes twitter users: real-time event detection by social sensors. In: Proceedings of the 19th International Conference on World Wide Web. New York, NY, USA: ACM, 2010. 851-860 [26] Becker H, Naaman M, Gravano L. Beyond trending topics: real-world event identification on twitter. In: Proceedings of the 2011 International AAAI Conference on Web and Social Media. Palo Alto, CA, USA: AAAI, 2011. 438-441 [27] 付举磊, 刘文礼, 郑晓龙, 樊瑛, 汪寿阳.基于文本挖掘和网络分析的"东突"活动主要特征研究.自动化学报, 2014, 40(11):2456-2468 http://www.aas.net.cn/CN/abstract/abstract18522.shtmlFu Ju-Lei, Liu Wen-Li, Zheng Xiao-Long, Fan Ying, Wang Shou-Yang. Analyzing the characteristics of "east Turkistan" activities using text mining and network analysis. Acta Automatica Sinica, 2014, 40(11):2456-2468 http://www.aas.net.cn/CN/abstract/abstract18522.shtml [28] 胡艳丽, 白亮, 张维明.一种话题演化建模与分析方法.自动化学报, 2012, 38(10):1690-1697 http://www.aas.net.cn/CN/abstract/abstract17778.shtmlHu Yan-Li, Bai Liang, Zhang Wei-Ming. Modeling and analyzing topic evolution. Acta Automatica Sinica, 2012, 38(10):1690-1697 http://www.aas.net.cn/CN/abstract/abstract17778.shtml [29] Thelwall M, Buckley K, Paltoglou G. Sentiment in twitter events. Journal of the American Society for Information Science and Technology, 2011, 62(2):406-418 doi: 10.1002/asi.21462 [30] Bollen J, Mao H N, Zeng X J. Twitter mood predicts the stock market. Journal of Computational Science, 2011, 2(1):1-8 doi: 10.1016/j.jocs.2010.12.007 [31] 吴信东, 李毅, 李磊.在线社交网络影响力分析.计算机学报, 2014, 37(4):735-752Wu Xin-Dong, Li Yi, Li Lei. Influence analysis of online social networks. Chinese Journal of Computers, 2014, 37(4):735-752 [32] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: online learning of social representations. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM, 2014. 701-710 [33] 辛宇, 杨静, 谢志强.基于标签传播的语义重叠社区发现算法.自动化学报, 2014, 40(10):2262-2275 http://www.aas.net.cn/CN/abstract/abstract18501.shtmlXin Yu, Yang Jing, Xie Zhi-Qiang. An overlapping semantic community structure detecting algorithm by label propagation. Acta Automatica Sinica, 2014, 40(10):2262-2275 http://www.aas.net.cn/CN/abstract/abstract18501.shtml [34] 黄立威, 李彩萍, 张海粟, 刘玉超, 李德毅, 刘艳博.一种基于因子图模型的半监督社区发现方法.自动化学报, 2016, 42(10):1520-1531 http://www.aas.net.cn/CN/abstract/abstract18939.shtmlHuang Li-Wei, Li Cai-Ping, Zhang Hai-Su, Liu Yu-Chao, Li De-Yi, Liu Yan-Bo. A semi-supervised community detection method based on factor graph model. Acta Automatica Sinica, 2016, 42(10):1520-1531 http://www.aas.net.cn/CN/abstract/abstract18939.shtml [35] Tsur O, Rappoport A. What's in a hashtag?: content based prediction of the spread of ideas in microblogging communities. In: Proceedings of the 5th ACM International Conference on Web Search and Data Mining. Seattle, Washington, USA: ACM, 2012. 643-652 -

 下载:
下载:



计量
- 文章访问数: 2335
- HTML全文浏览量: 393
- PDF下载量: 667
- 被引次数: 0
