

-
摘要: 社交媒体数据中蕴含了丰富的交通状态信息,这些信息以人类语言为载体,包含了大量对交通状态的因果分析与多角度描述,可以为传统交通信息采集手段提供有力补充,近年来已成为交通状态感知的重要信息来源.本文以新浪微博为主要数据来源,分别利用支持向量机算法、条件随机场算法以及事件提取模型完成微博的分类、命名实体识别与交通事件提取,开发了基于社交媒体大数据的交通感知分析与可视化系统,可以为交通管理部门及时提供交通舆情及突发交通事件的态势、影响范围、起因等信息.在交通信息采集系统建设较为薄弱的地区,本文建立的系统可以为交通管理提供信息补充.Abstract: Social media data, which encapsulate abundant traffic status information, have gradually become an important data source for sensing traffic status. The information recorded by human language contains a large amount of causality analysis and multi-angle descriptions of the traffic condition, acting as a powerful supplement to traditional traffic information collecting methods. Employing Sina Weibo as a main data source, we apply SVM algorithm, CRF algorithm and event extracting model for classification, named entity recognition and events extraction of microblogs. We develop a traffic sensing and visualizing system, which can collect public opinion, situations, scales and even origins of traffic incidents for transportation agency. Furthermore, this system can provide traffic information for the transportation department in the area which lack traffic detectors.1) 本文责任编委 王飞跃
-
表 2 标准化微博数据
Table 2 Standardized Weibo data
微博发布时间 官方标记 微博正文 微博定位地点(缺省为*) 201604022042 0 竟然能在一个地方堵车堵快1个小时了!气得好多人中途下车了! 北京·北七家  下载: 导出CSV
下载: 导出CSV
表 3 不同分类算法的测试结果
Table 3 Test results of different algorithms
算法 Precision Recall F1-score SVM (kernel = 'linear') 0.880 0.850 0.859 SVM (kernel = 'rbf') 0.747 0.574 0.504 SVM (kernel = 'sigmoid') 0.799 0.524 0.419 SVM (kernel = 'poly') 0.234 0.500 0.318 1NN 0.693 0.685 0.683 3NN 0.725 0.699 0.692 5NN 0.727 0717 0.717 Gaussian NB 0.645 0.626 0.618 Multinomial NB 0.766 0.768 0.767 DT (criterion = 'entropy') 0.676 0.687 0.676 DT (criterion = 'gini') 0.674 0.677 0.672
下载: 导出CSV
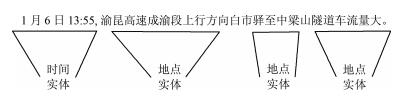
表 4 微博的词序列示例
Table 4 An example of a sequence of Weibo word
微博词序列示例 词性符号 词性 1月 nt nt temporal noun 6日 nt 13:55 m m number , wp 愈 j wp punctuation 昆 j 高速 d j abbreviation 成 v 渝段 n d adverb 上行 v 方向 n v verb 白市驿 ns 至 p n general noun 中梁山 ns 隧道 n ns geographical name 车流量 n 大 a p preposition
下载: 导出CSV
表 5 命名实体标注方案
Table 5 Method of NER labelling
类别 标注符号 说明 词序列示例 标注示例 B-Ns 地点词的起始 1月 nt B-Nm 6日 nt I-Nm 地 I-Ns 地点词的中部 13:55 m E-Nm 点 渝 wp B-Ns 实 E-Ns 地点词的结尾 昆 j I-Ns 体 高速 j I-Ns S-Ns 完整的地点词 成 d I-Ns 渝段 v E-Ns B-Nm 时间词的起始 上行 n O 方向 v O 时 I-Nm 时间词的中部 白市驿 n S-Ns 间 至 ns O 实 E-Nm 时间词的结尾 中梁山 nt B-Ns 体 隧道 n E-Ns S-Nm 完整的时间词 车流量 n O 大 wp O
下载: 导出CSV
表 6 CRF不同模板的设置方案与测试结果
Table 6 Settings of different CRF templates and test results
方案 窗口大小 考虑的列 考虑的相对关系 Precision Recall F1-score 一 3 a N/A 0.790 0.665 0.72 二 3 a, b N/A 0.798 0.743 0.769 三 3 a, b a, b 0.794 0.754 0.773 四 5 a N/A 0.787 0.639 0.703 五 5 a, b N/A 0.788 0.735 0.760 六 5 a, b a, b 0.791 0.741 0.764
下载: 导出CSV
-
[1] 翁剑成, 荣建, 于泉, 任福田.基于浮动车数据的行程速度估计算法及优化.北京工业大学学报, 2007, 33(5):459-464 http://www.cqvip.com/QK/95054X/200705/24620217.htmlWeng Jian-Cheng, Rong Jian, Yu Quan, Ren Fu-Tian. Optimization on estimation algorithms of travel speed based on the real-time floating car data. Journal of Beijing University of Technology, 2007, 33(5):459-464 http://www.cqvip.com/QK/95054X/200705/24620217.html [2] 董均宇. 基于GPS浮动车的城市路段平均速度估计技术研究[硕士学位论文], 重庆大学, 中国, 2006.Dong Jun-Yu. Study on Link Speed Estimation in Urban Arteries Based on GPS Equipped Floating Vehicle[Master thesis], Chongqing University, China, 2006. [3] 陶汉卿, 李文勇.基于感应线圈车辆检测器的车辆转弯信息获取.桂林电子科技大学学报, 2008, 28(5):387-391 http://www.doc88.com/p-912614749885.htmlTao Han-Qing, Li Wen-Yong. Acquisition of turning vehicles information based on induction loop detector. Journal of Guilin University of Electronic Technology, 2008, 28(5):387-391 http://www.doc88.com/p-912614749885.html [4] Zhang Z, Yao D Y, Zhang Y, Hu J M. Mixed urban traffic data collection and processing with advanced information technologies. In: Proceedings of the 3rd China Annual Conference on ITS. Nanjing, China: Southeast University Press, 2007. 474-479 [5] 王川童. 基于视频处理的城市道路交通拥堵判别技术研究[硕士学位论文], 重庆大学, 中国, 2010.Wang Chuan-Tong. Study on Video-based Traffic Congestion Identification Technology of City Road[Master thesis], Chongqing University, China, 2010. [6] Li R M, Jiang C Y, Zhu F H, Chen X L. Traffic flow data forecasting based on interval type-2 fuzzy sets theory. IEEE/CAA Journal of Automatica Sinica, 2016, 3(2):141-148 doi: 10.1109/JAS.2016.7451101 [7] Shang J B, Zheng Y, Tong W Z, Chang E, Yu Y. Inferring gas consumption and pollution emission of vehicles throughout a city. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2014. 1027-1036 [8] 陆锋, 郑年波, 段滢滢, 张健钦.出行信息服务关键技术研究进展与问题探讨.中国图像图形学报, 2009, 14(7):1219-1229 http://www.oalib.com/paper/4487339Lu Feng, Zheng Nian-Bo, Duan Ying-Ying, Zhang Jian-Qin. Travel information services:state of the art and discussion on crucial technologies. Journal of Image and Graphics, 2009, 14(7):1219-1229 http://www.oalib.com/paper/4487339 [9] Zhang J P, Wang F Y, Wang K F, Lin W H, Xu X, Chen C. Data-driven intelligent transportation systems:a survey. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(4):1624-1639 doi: 10.1109/TITS.2011.2158001 [10] Wang F Y, Zhang J J, Zheng X H, Wang X, Yuan Y, Dai X X, Zhang J, Yang L Q. Where does AlphaGo go:from church-turing thesis to AlphaGo thesis and beyond. IEEE/CAA Journal of Automatica Sinica, 2016, 3(2):113-120 doi: 10.1109/JAS.2016.7471613 [11] Wang F Y. Scanning the issue and beyond:crowdsourcing for field transportation studies and services. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(1):1-8 [12] Qiao F X, Zhu Q, Yu L. Social media applications to publish dynamic transportation information on campus. In: Proceedings of the 11th International Conference of Chinese Transportation Professionals. Nanjing, China: Southeast University Press, 2011. 4318-4329 [13] Zeng K, Liu W L, Wang X, Chen S H. Traffic congestion and social media in China. IEEE Intelligent Systems, 2013, 28(1):72-77 [14] Wanichayapong N, Pruthipunyaskul W, Pattara-Atikom W, Chaovalit P. Social-based traffic information extraction and classification. In: Proceedings of the 11th International Conference on ITS Telecommunications. St. Petersburg, Russia: IEEE, 2011. 107-112 [15] Endarnoto S K, Pradipta S, Nugroho A S, Purnama J. Traffic condition information extraction & visualization from social media Twitter for Android mobile application. In: Proceedings of the 2011 International Conference on Electrical Engineering and Informatics. Bandung, Indonesia: IEEE, 2011. 1-4 [16] Balagapo J, Sabidong J, Caro J. Data crowdsourcing and traffic sensitive routing for a mixed mode public transit system. In: Proceedings of the 5th International Conference on Information, Intelligence, Systems and Applications. Chania, Crete, Greece: IEEE, 2014. 1-6 [17] D'Andrea E, Ducange P, Lazzerini B, Marcelloni F. Real-time detection of traffic from twitter stream analysis. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4):2269-2283 doi: 10.1109/TITS.2015.2404431 [18] 张恒才, 陆锋, 陈洁.微博客蕴含交通信息的提取.中国图象图形学报, 2013, 18(1):123-129 doi: 10.11834/jig.20130116Zhang Heng-Cai, Lu Feng, Chen Jie. Extracting traffic information from massive micro-blog messages. Journal of Image and Graphics, 2013, 18(1):123-129 doi: 10.11834/jig.20130116 [19] 张恒才, 陆锋, 仇培元.基于D-S证据理论的微博客蕴含交通信息提取方法.中文信息学报, 2015, 29(2):170-178 http://or.nsfc.gov.cn/bitstream/00001903-5/249242/1/1000013869785.pdfZhang Heng-Cai, Lu Feng, Qiu Pei-Yuan. Extracting traffic information from micro-blog based on D-S evidence theory. Journal of Chinese Information Processing, 2015, 29(2):170-178 http://or.nsfc.gov.cn/bitstream/00001903-5/249242/1/1000013869785.pdf [20] 崔健, 冯璇, 张佐.基于微博的交通事件提取与文本分析系统.交通信息与安全, 2013, 31(6):132-135 http://www.cqvip.com/QK/91770A/201306/1002148556.htmlCui Jian, Feng Xuan, Zhang Zuo. Extraction and analysis system of traffic incident based on microblog. Journal of Transport Information and Safety, 2013, 31(6):132-135 http://www.cqvip.com/QK/91770A/201306/1002148556.html [21] 熊佳茜. 基于CRF的中文微博交通信息事件抽取[硕士学位论文], 上海交通大学, 中国, 2014.Xiong Jia-Xi. Civil Transportation Event Extraction from Chinese Microblogs Based on CRF[Master thesis], Shanghai Jiao Tong University, China, 2014. [22] Hasan S, Ukkusuri S V. Urban activity pattern classification using topic models from online geo-location data. Transportation Research Part C:Emerging Technologies, 2014, 44:363-381 doi: 10.1016/j.trc.2014.04.003 [23] Gkiotsalitis K, Stathopoulos A. A utility-maximization model for retrieving users' willingness to travel for participating in activities from big-data. Transportation Research Part C:Emerging Technologies, 2015, 58:265-277 doi: 10.1016/j.trc.2014.12.006 [24] Gkiotsalitis K, Stathopoulos A. Joint leisure travel optimization with user-generated data via perceived utility maximization. Transportation Research Part C:Emerging Technologies, 2016, 68:532-548 doi: 10.1016/j.trc.2016.05.009 [25] Gu Y M, Qian Z, Chen F. From Twitter to detector:real-time traffic incident detection using social media data. Transportation Research Part C:Emerging Technologies, 2016, 67:321-342 doi: 10.1016/j.trc.2016.02.011 [26] Kuflik T, Minkov E, Nocera S, Grant-Muller S, Gal-Tzur A, Shoor I. Automating a framework to extract and analyse transport related social media content:the potential and the challenges. Transportation Research Part C:Emerging Technologies, 2017, 77:275-291 doi: 10.1016/j.trc.2017.02.003 [27] Rashidi T H, Abbasi A, Maghrebi M, Hasan S, Waller T S. Exploring the capacity of social media data for modelling travel behaviour:opportunities and challenges. Transportation Research Part C:Emerging Technologies, 2017, 75:197-211 doi: 10.1016/j.trc.2016.12.008 [28] Cottrill C, Gault P, Yeboah G, Nelson J D, Anable J, Budd T. Tweeting Transit:an examination of social media strategies for transport information management during a large event. Transportation Research Part C:Emerging Technologies, 2017, 77:421-432 doi: 10.1016/j.trc.2017.02.008 [29] Xiong G, Zhu F H, Liu X W, Dong X S, Huang W L, Chen S H, Zhao K. Cyber-physical-social system in intelligent transportation. IEEE/CAA Journal of Automatica Sinica, 2015, 2(3):320-333 doi: 10.1109/JAS.2015.7152667 [30] Wang F Y. Scanning the issue and beyond:real-time social transportation with online social signals. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(3):909-914 doi: 10.1109/TITS.2014.2323531 [31] Wang X, Zheng X H, Zhang Q P, Wang T, Shen D Y. Crowdsourcing in ITS:the state of the work and the networking. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(6):1596-1605 doi: 10.1109/TITS.2015.2513086 [32] HIT-SCIR. LTP[Online], available: http://ltp.readthedocs.io/zh_CN/latest/, July 12, 2016. [33] Řehuřek R, Sojka P. Software framework for topic modelling with large corpora. In: Proceedings of LREC 2010 Workshop New Challenges for NLP Frameworks. Valletta, Malta: University of Malta, 2010. 45-50 [34] Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E. Scikit-learn:machine learning in Python. The Journal of Machine Learning Research, 2011, 12:2825-2830 [35] Pan S J, Toh Z Q, Su J. Transfer joint embedding for cross-domain named entity recognition. ACM Transactions on Information Systems, 2013, 31(2):Article No.7 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.422.888 [36] Zhou G D, Su J. Named entity recognition using an HMM-based chunk tagger. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics, 2002. 473-480 [37] Morwal S, Jahan N, Chopra D. Named entity recognition using hidden Markov model (HMM). International Journal on Natural Language Computing, 2012, 1(4):15-23 doi: 10.5121/ijnlc [38] 王丹, 樊兴华.面向短文本的命名实体识别.计算机应用, 2009, 29(1):143-145 https://www.wenkuxiazai.com/doc/918cd3c189eb172ded63b7a9.htmlWang Dan, Fan Xing-Hua. Named entity recognition for short text. Journal of Computer Applications, 2009, 29(1):143-145 https://www.wenkuxiazai.com/doc/918cd3c189eb172ded63b7a9.html [39] Peng F C, McCallum A. Information extraction from research papers using conditional random fields. Information Processing & Management, 2006, 42(4):963-79 https://www.sciencedirect.com/science/article/pii/S0306457305001172 [40] Taku-ku. CRF++[Online], available: http://sourceforge.net/projects/crfpp/files/, July 12, 2016. [41] Lafferty J D, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of the Eighteenth International Conference on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc, 2001. 282-289 [42] Baidu. Baidu map API[Online], available: http://lbsyun.baidu.com, October 12, 2016. -

 下载:
下载:






计量
- 文章访问数: 2549
- HTML全文浏览量: 979
- PDF下载量: 1094
- 被引次数: 0
