

Parallel Task Assignment Optimization Algorithm and Parallel Control for Cloud Control Systems
-
摘要: 利用Petri网模拟云控制系统的并行处理过程,引入并行处理系统的时钟周期、吞吐率和任务完成时间性能指标,运用极大-加代数方法分析和优化云控制系统并行处理性能.采用子过程细分的优化方式,通过求解一类最优控制问题,设计并行任务分配优化方案,以保证任务完成时间最短,并给出计算最短任务完成时间的有效算法.同时,采用重复设置多套瓶颈段并联的方式提高并行处理能力,并运用Petri网实现瓶颈子过程的并联控制,且给出并联控制在协同云控制系统中的一个应用.Abstract: We use Petri nets to simulate the parallel processing arising in cloud control systems. We introduce performance indexes called clock period, through-put rate and task completion time, and use the max-plus algebra to analyze and optimize the parallel processing performance of cloud control systems. By using the method of segmenting sub-processes and solving the optimal control problem, we design the optimization scheme for parallel task assignment to minimize the completion time, and develop an effective algorithm to compute such a minimum time. Computer performances can be improved through parallel connection of bottle-neck roads. We use the Petri nets to realize the parallel control of bottle-neck sub-processes and present an application of the parallel control in cooperative cloud control systems.
-
Key words:
- Cloud control system /
- parallel processing /
- task assignment /
- optimal control /
- parallel control /
- Petri nets
-
近年来,经济模型预测控制(Economic model predictive control,EMPC)在学术界和工业界受到了广泛关注 [1-15]. EMPC的一个显著优点是将过程实时控制与经济性能优化集成在一个最优控制的框架内设计 [1-2]. 不同于传统MPC (Model predictive control)需要预先设定目标值为前提(故也称为目标跟踪型MPC) [1],EMPC原则上并不需要这样一个前提 [2]. 由于这类MPC性能函数通常与过程的经济(环保)性能相关,故统称为经济MPC. 但该"经济"并不特指某个经济性能,而泛指一类非正定和(或)非凸的任意性能函数. 尽管如此,经济MPC和传统MPC的实施机理一样,即都采用滚动时域方式实现系统的闭环状态(或输出)反馈控制 [1-3],但直接优化经济性能计算控制量给EMPC带来更复杂的稳定性问题 [1, 16].
常规EMPC稳定性需引入强对偶性或耗散性假设,并附加罚函数将经济性能函数转换为正定性能函数,再结合终端等式或不等式约束,建立EMPC的递推可行性和闭环稳定性 [4-8, 16-17]. 由于系统与性能函数不一定满足正则性(Regulation)条件 [6],约束非线性系统通常不满足对偶性与耗散性假设 [4]. 进一步,由于附加项通常是平衡点偏差的函数,将改变原经济性能的最优路径,影响原始经济性能,特别是终端等式约束加重了EMPC在线优化的计算量,同时会减小EMPC的吸引域. 针对终端约束对经济性能的影响,文献[18]应用耗散性和能控性假设建立了无终端约束EMPC稳定性,但要求预测时域足够大,而这将增加EMPC在线优化的计算量. 基于 能控性假设和切换控制思想,文献[19]提出了基于 Lyapunov函数的稳定EMPC策略,但为保证闭环系统的稳定性和渐近平均性能,需要在线求解三个非线性最优控制问题 [20],增加了EMPC运行的复杂性. 现有研究结果表明,EMPC的经济性能与稳定性存在一定的矛盾 [7, 16]. 如何在优化经济性能的同时确保闭环系统的稳定性是EMPC研究的一个关键问题.
另一方面,在工业过程经济目标优化操作中,通常存在多个相互矛盾的性能指标 [21-22],且这些性能指标具有不同的物理含义. 因为加权函数法使用简单,在控制实践中,通常被用来近似处理多目标优化控制问题. 但各目标加权系数的选择与整定需要通过大量的离线实验完成,特别是在系统约束和目标函数非凸的情况下,权值选择与整定会异常困难 [22-23]. 近年来,提出了一些新的多目标优化MPC设计,如基于稳态目标规划计算的双层多目标MPC [23]、 参数规划多目标线性MPC [24]、 混合逻辑整数规划多目标MPC [25-27]、 考虑性能指标优先级要求的多目标MPC [28-30] 以及基于多目标理想点跟踪的多目标MPC [31-32]等. 由于理想点跟踪多目标MPC策略不需要人为选择各性能的加权系数,在不需要系统先验知识的条件下能自动处理各个性能指标的冲突性,成为目前广受关注的一种多目标MPC策略. 但在理想点跟踪多目标MPC中,由于性能指标相互冲突,折中性能函数在稳态平衡点不为零,即折中性能函数不是稳态平衡点的正定函数,对应的控制器通常不稳定,因此可看作是一类特殊的EMPC问题,可采用EMPC方法建立理想点跟踪多目标MPC的闭环稳定性.
本文考虑具有状态和控制约束的非线性系统,提出一种新的具有递推可行性和稳定性保证的EMPC策略. 通过离线计算经济性能指标的最优平衡点,引入关于该点偏差的正定辅助函数. 利用辅助函数的最优值函数定义原始EMPC优化问题的一个稳定性约束. 再应用终端约束集、终端代价函数和局部控制器等三要素 [3],建立闭环系统关于经济最优平衡点的渐近稳定性和渐近平均性能. 与现有稳定EMPC策略相比,本文的一个主要创新点是EMPC的递推可行性和渐近稳定性与非线性系统的强对偶性、耗散性条件无关,从而简化EMPC策略的设计. 进一步,结合多目标理想点法 [31],将上述结果推广至多个经济性能指标的优化控制问题,提出一种新的具有稳定性保证的理想点跟踪多目标EMPC策略. 最后以连续搅拌反应器多目标控制为例,对比仿真验证本文结果的有效性.
符号说明: 集合$R_{\geq 0}$和$ {I}_{\geq 0}$分别表示非负实数集和非负整数集. $ {I}_{a:b}=\{i\in {I}_{\geq 0}: a\leq i\leq b\}$,其中$a\in {I}_{\geq 0}$和$b\in {I}_{\geq 0}$. 符号${{u}_{k}}$表示$k\in {I} $时刻的一个信号序列,系统在$k\in {I}_{\geq 0}$时刻的状态${{x}_{k}}=\varphi (k;{{x}_{0}},u)$,其中,${ x}_0$为系统在零时刻的状态. 给定一个向量${ s}$,符号T表示${ s}$的转置,$\|{ s}\|_p$表示${ s}$的p范数,${ s}_{i|k}$表示在第k时刻对未来第$k+i$时刻的预测变量.
1. 问题描述
考虑离散时间非线性系统
${{x}_{k+1}}=f({{x}_{k}},{{u}_{k}}),k\in {{I}_{\ge 0}}$
(1) 其中,${{x}_{k}}\in {{R}^{n}}$和${{u}_{k}}\in {{R}^{m}}$分别为k时刻的状态变量和控制变量; $f:{{R}^{n}}\times {{R}^{m}}\to {{R}^{n}}$是关于$({ x},{ u})$的连续函数. 假设系统存在平衡点$({ x}_s,{ u}_s)$满足${ x}_s={ f}({ x}_s,{ u}_s)$. 进一步,系统存在状态和控制约束
$\begin{matrix} {{x}_{k}}\in X, & {{u}_{k}}\in U, & k\in {{I}_{\ge 0}} \\ \end{matrix}$
(2) 其中,约束集$X\subset {{R}^{n}}$和$U\subset {{R}^{m}}$为凸的紧集,且平衡点$({ x}_s,{ u}_s)$为其内点. 假设系统的状态是完全可测的,本文考虑状态反馈控制律设计.
考虑经济性能函数${{L}_{e}}:X\times U\to R$. 该函数关于$({ x},{ u})$连续且有界,但可能是非凸的且对于任意$({ x}_s,{ u}_s)$不一定是正定的. 由文献[16]可知,极小化这类性能函数的控制律不一定保证闭环系统渐近稳定,甚至出现震荡和周期响应. 尽管周期响应适用一些间歇工业过程,但大部分连续工业过程要求闭环系统是渐近稳定的. 本文目标是设计一个经济最优状态反馈控制律${ u}({ x})$,使闭环系统能渐近稳定于最优经济平衡点$({ x}_s^*,{ u}_s^*)$,同时满足系统状态和控制约束(2),以及渐近平均性能条件
$\underset{T\to \infty }{\mathop{\lim }}\,\sup \frac{1}{T}\sum\limits_{k=0}^{T}{{{L}_{e}}}({{x}_{k}},{{u}_{k}})\le {{L}_{e}}(x_{s}^{*},u_{s}^{*})$
(3) 其中,时域$T\in {I}_{\geq 1}$,最优经济平衡点$({ x}_s^*,{ u}_s^*)$满足
$(x_{s}^{*},u_{s}^{*})=\arg {{\min }_{x\in X,u\in U}}\{{{L}_{e}}(x,u)|x=f(x,u)\}$
(4) 本文采用MPC策略设计经济最优状态反馈控制律${ u}({ x})$. 为书写简便,令$({ x}_s,{ u}_s)=({ x}_s^*,{ u}_s^*)$.
2. 稳定经济预测控制
2.1 预测控制器
令$N\in {I}_{\geq 1}$为预测时域,定义k时刻的N步预测控制序列${{u}_{k}}=\{{{u}_{0|k}},{{u}_{1|k}},\cdots ,{{u}_{N-1|k}}\}$和对应预测状态序列${{x}_{k}}=\{{{x}_{1|k}},{{x}_{2|k}},\cdots ,{{x}_{N|k}}\}$. 给定紧集$X_T\subset X$,如果${{u}_{k}}$满足${ x}_{i+1|k}\in X$和${ u}_{i|k}\in U$,$\forall i\in {I}_{0:N-1}$,以及${ x}_{N|k}\in X_T$,则该控制序列称为系统(1)的一个可行预测控制序列.
考虑系统(1)的一个可行预测控制序列${{u}_{k}}$及其对应的预测状态序列${{x}_{k}}$,定义如下目标函数:
${{V}_{a}}({{x}_{k}},{{u}_{k}})={{E}_{a}}({{x}_{N|k}})+\sum\limits_{i=0}^{N-1}{{{L}_{a}}}({{x}_{i|k}},{{u}_{i|k}})$
(5) 其中,${ x}_{0|k}\in X$是k时刻的状态; 辅助函数$L_a: X\times U\rightarrow R_{\geq 0}$和$E_a: X\in R_{\geq 0}$是连续有界函数. 进一步定义如下经济目标函数:
$J({{x}_{k}},{{u}_{k}})=\sum\limits_{i=0}^{N-1}{{{L}_{e}}}({{x}_{i|k}},{{u}_{i|k}})$
(6) 为计算EMPC控制律,在每个时刻求解如下有限时域最优控制问题
$u_{k}^{*}=\arg {{\min }_{{{u}_{k}}}}J({{x}_{k}},{{u}_{k}})$
(7a) $\text{s}.\text{t}.{{x}_{i+1|k}}=f({{x}_{i|k}},{{u}_{i|k}}),i\in {{I}_{0:N-1}}$
(7b) $\label{eq7c} ({ x}_{i|k},{ u}_{i|k})\in X\times U,\quad i\in {I}_{0:N-1} $
(7c) $\label{eq7d} { x}_{0|k}={ x}_k,\quad { x}_{N|k}\in X_T \quad\quad\quad $
(7d) $\label{eq7e} V_a({ x}_k,{u}_k)\leq \eta({ x}_k,\alpha) \quad\quad\quad\quad $
(7e) 其中,$u_{k}^{*}$表示优化问题(7)的最优解; ${ x}_{0|k}={ x}_k$是初始条件; ${ x}_{N|k}\in X_T$是终端约束条件; 终端约束集$X_T\subset X$且${ x}_s\in X_T$; 函数$\eta: X\times R_{\geq 0}\rightarrow R_{\geq 0}$.
为构造函数$\eta$,定义辅助优化问题
$u_{k}^{o}=\arg \underset{{{u}_{k}}}{\mathop{\min }}\,\{{{V}_{a}}({{x}_{k}},{{u}_{k}})|(7\text{b})-(7\text{d})\}$
(8) 其中,$u_{k}^{o}$为优化问题(8)的最优解. 分别将$u_{k}^{*}$和$u_{k}^{o}$代入式(5),得k时刻的值函数
$V_{a}^{*}({{x}_{k}}):={{V}_{a}}({{x}_{k}},u_{k}^{*})$
(9) $V_{a}^{o}({{x}_{k}}):={{V}_{a}}({{x}_{k}},u_{k}^{o})$
(10) 则函数$\eta$定义为
$\eta ({{x}_{k}},\alpha )=V_{a}^{o}({{x}_{k}})+\alpha [V_{a}^{*}({{x}_{k-1}})-V_{a}^{o}({{x}_{k}})]$
(11) 其中,系数$\alpha\geq 0$. 由定理1证明过程(见第2.2节)可知,不等式$\eta({ x},\alpha)\geq 0$对任意${ x}\in X$和$\alpha\geq 0$成立.
注 1. 序列$u_{k}^{*}$只是优化问题(8)在k时刻的一个可行解,从而
$0\le V_{a}^{o}({{x}_{k}})\le V_{a}^{*}({{x}_{k}}),\forall k\in {{I}_{\ge 0}}$
(12) 同理,当序列$u_{k}^{o}$满足式(7e)时,$u_{k}^{o}$是优化问题(7)在k时刻的可行解,但通常不是最优解,从而
$J({{x}_{k}},u_{k}^{*})\le J({{x}_{k}},u_{k}^{o}),\forall k\in {{I}_{\ge 0}}$
(13) 如果优化问题(7)在k时刻是可行的,则根据滚动时域控制原理,定义经济预测控制律如下:
${{u}_{k}}=u_{k}^{\text{empc}}:=u_{0|k}^{*},k\in {{I}_{\ge 0}}$
(14) 其中,${ u}_{0|k}^*$是$u_{k}^{*}$的第一个分量. 对应的闭环系统为
${{x}_{k+1}}=f({{x}_{k}},u_{k}^{\text{empc}}),k\in {{I}_{\ge 0}}$
(15) 本文将证明值函数(9)是系统(15)的Lyapunov函数,建立闭环系统关于$({ x}_s,{ u}_s)$的渐近稳定性结论.
算法 1. (EMPC 算法)
1) 设置预测时域N和参数$\alpha\geq 0$,经济函数$L_e({ x},{ u})$和辅助函数$L_a({ x},{ u})$及$E_a({ x})$.
2) 考虑初始状态${ x}_0$,令$\eta({ x}_0,\alpha)$充分大且$k=0$.
3) 求解优化问题(7),得最优控制序列$u_{k}^{*}$.
4) 将$u_{k}^{*}$的首个分量作用于系统(1); 令$k=k+1$.
5) 测量k时刻状态${ x}_k$,求解优化问题(8)得$u_{k}^{o}$.
6) 将$u_{k}^{o}$代入式(11)更新$\eta({ x}_k,\alpha)$,并返回第3)步.
2.2 稳定性与平均性能
假设 1. 函数$L_a({ x},{ u})$是$({ x}_s,{ u}_s)$的正定函数及$E_a({ x})$ 是${ x}_s$的正定函数.
假设 2. 在终端约束集XT内存在局部控制律${ u}={ \pi}({ x})$满足${ \pi}({ x})\in U$和$E_a({ f}({ x},{ \pi}({ x})))-E_a({ x})\leq -L_a({ x},{ \pi}({ x}))$,$\forall { x}\in X_T$.
注 2. 假设1和假设2是传统MPC稳定性研究中常采用的三要素$(E_a,X_T,{ \pi})$条件,可利用平衡点线性化、线性矩阵不等式和控制Lyapunov函数等方法求解 [33-35]. 假设1表明${{V}_{a}}(x,u)$是$({ x}_s,{ u}_s)$的正定函数,而XT定义为$E_a({ x})$的水平集,则假设2表明XT是闭环系统${ x}_{k+1}={ f}({ x}_k,{ \pi}({ x}_k))$的一个不变集.
定义 1. 考虑初始状态${ x}\in X$及边界条件${ x}_{0|k}={ x}$,如果系统(1)存在可行预测控制序列${{u}_{k}}$,则$\bf x$称为可行初始状态. 全体可行初始状态组成的集合XN称为系统(1)的可行初始集.
显然,XN满足$X_T\subseteq X_N\subseteq X$,且$X_N\subset X_{N+1}$.
定理 1. 如果假设1和2成立,则对于任意给定$\alpha\geq 0$,优化问题(7)在XN内具有递推可行性,进而XN是闭环系统(15)的一个不变集.
证明. 考虑$k-1$时刻的状态${ x}_{k-1}\in X_N$及优化问题(7)的最优解$u_{k-1}^{*}$.构造k时刻的一个控制序列
${{\hat{u}}_{k}}=\{u_{1|k-1}^{*},\cdots ,u_{N-1|k-1}^{*},\pi (x_{N|k-1}^{*})\}$
(16) 其中,状态${ x}_{N|k-1}^*$是对应于$u_{k-1}^{*}$的终端预测状态,满足${ x}_{N|k-1}^*\in X_T$. 将$\hat{{u}}_k$代入系统(1)得状态响应序列$\hat{{x}}_k=\{{ x}_{2|k-1}^*,{ x}_{3|k-1}^*,\cdots,{ x}_{N|k-1}^*,\hat{{ x}}_{N|k} \}$,其中$\hat{{ x}}_{N|k}={ f}({ x}_{N|k-1}^*,{ \pi}({ x}_{N|k-1}^*))$. 因为$(E_a$,XT,${ \pi})$满足假设1和2,且${ x}_{N| k-1}^*\in X_T$及XT是${ x}_{k+1}={ f}({ x}_k,{ \pi}({ x}_k))$的不变集,故 ${ \pi}({ x}_{N|k-1}^*)\in U$和$\hat{{ x}}_{N|k}\in X_T$. 则基于MPC三要素原理 [3, 36-37]可知,序列(16)满足约束条件(7b) $\sim$ (7d),从而优化问题(8)在k时刻存在可行解.
令优化问题(8)在k时刻的最优解为$u_{k}^{o}$,则
$\label{eq21} V_a^o({ x}_k)\leq V_a({ x}_k,\hat{{u}}_k). $
(17) 进一步考虑控制序列(16),可得:
$\begin{align} & V_{a}^{o}({{x}_{k}})-V_{a}^{*}({{x}_{k-1}})\le \\ & {{V}_{a}}({{x}_{k}},{{\widehat{\mathbf{u}}}_{k}})-V_{a}^{*}({{x}_{k-1}})= \\ & {{E}_{a}}({{x}_{N|k}})+{{L}_{a}}(x_{N|k-1}^{*},\pi (x_{N|k-1}^{*}))- \\ & {{E}_{a}}(x_{N|k-1}^{*})-{{L}_{a}}(x_{0|k-1}^{*},u_{0|k-1}^{*}) \\ \end{align}$
(18) 其中,${ x}_{N|k}={ f}({ x}_{N|k-1}^*,{ \pi}({ x}_{N|k-1}^*))$. 因为${ x}_{N|k-1}^*\in X_T$且XT为不变集,则对式(18)应用假设1和2可得:
$V_{a}^{*}({{x}_{k-1}})-V_{a}^{o}({{x}_{k}})\ge {{L}_{a}}(x_{0|k-1}^{*},u_{0|k-1}^{*})\ge 0$
(19) 将不等式(19)代入式(11),并考虑值函数$V_a^o({ x}_k)\geq 0$,得$\eta({ x}_k,\alpha)\geq 0$. 进一步,将$u_{k}^{o}$代入式(7e)中的左边项${{V}_{a}}({{x}_{k}},{{u}_{k}})$,并结合等式(10)和不等式(19),则对于任意给定$\alpha\geq 0$,不等式${{V}_{a}}({{x}_{k}},u_{k}^{o})\le V_{a}^{o}({{x}_{k}})+\alpha [V_{a}^{*}({{x}_{k-1}})-V_{a}^{o}({{x}_{k}})]=:\eta ({{x}_{k}},\alpha )$成立,即序列$u_{k}^{o}$是优化问题(7)的一个可行解. 此时,考虑优化问题(7)的初始条件,并根据定义1可得${ x}_k\in X_N$,即XN是闭环系统(15)的不变集.
定理 2. 如果假设1和2成立,且优化问题(7)在初始时刻存在可行解. 给定$\alpha\in [0,1)$,则${ x}_s$是闭环系统(15)在XN内的渐近稳定平衡点,且XN是闭环系统的一个吸引域.
证明. 任意给定$\alpha\in [0,1)$,由于优化问题(7)在初始时刻是可行的. 根据定理1可知,该优化问题在任意k时刻存在可行解.
令$u_{k-1}^{*}$和$u_{k}^{*}$是优化问题(7)分别在$k-1$和k时刻的最优解. 考虑约束条件(7e)和式(11),对值函数(9)沿闭环系统(15)轨迹做差分运算,得:
$V_{a}^{*}({{x}_{k}})-V_{a}^{*}({{x}_{k-1}})\le (1-\alpha )[V_{a}^{o}({{x}_{k}})-V_{a}^{*}({{x}_{k-1}})]$
(20) 考虑假设1和2,将式(19)代入不等式(20)并整理得:
$\label{eq26} V_a^*({ x}_k)-V_a^*({ x}_{k-1}) =(\alpha-1)L_a({ x}_{k-1},{ u}_{k-1}^{\rm {empc}}) $
(21) 由于$\alpha\in [0,1)$且$L_a({ x},{ u})$为正定函数,所以值函数(9)沿着闭环系统(15)的轨迹是严格单调递减的. 又因为${{V}_{a}}(x,u)$是$({ x}_s,{ u}_s)$的正定函数,从而${ x}_s$是闭环系统的渐近稳定平衡点. 又因为XN是闭环系统的不变集,故XN是闭环系统的一个吸引域.
注 3. 由定理2证明过程可知,闭环系统(15)的稳定性是通过不等式(7e)建立的,即利用$(E_a,X_T,{ \pi})$满足假设1和2,使函数(9)成为闭环系统的Lyapunov函数,因此式(7e)是一类基于Lyapunov函数的稳定性约束. 在常规的基于Lyapunov函数MPC策略 [1, 38]中,性能函数$L_e({ x},{ u})$是关于平衡点偏差的正定函数,故Lyapunov稳定性约束是通过强制一个已知的正定函数的导数小于零构造的,而本文采用MPC的三要素原理建立闭环系统的Lyapunov函数,因此是两种不同的稳定性约束条件. 其次,经济优化问题(7)的最优解$u_{k}^{*}$并不能保证是优化问题(8)的最优解,而通常只是一个可行解; 同理,尽管$u_{k}^{o}$是优化问题(8)的最优解,但只是优化问题(7)的一个可行解. 尽管如此,结合定理1和MPC三要素原理可得,由最优解$u_{k}^{o}$定义的滚动时域控制器$\tilde{{ u}}_k= { u}_{0|k}^o$同样能保证${ x}_s$的渐近稳定性,且XN是对应闭环系统的一个吸引域. 最后,控制序列(16)只是优化问题(8)的一个可行序列,但不一定是优化问题(7)的可行序列,因为不等式(17)使得序列(16)不一定满足约束(7e).
定理 3. 如果假设1和2成立,且优化问题(7)在初始时刻存在可行解. 如果给定$\alpha\in [0,1)$,则闭环系统(15)在吸引域XN内满足渐近平均性能(3).
证明. 由注3可知,优化问题(7)存在次优控制器$\tilde{{ u}}_k={ u}_{0|k}^o$在XN内渐近镇定系统(1). 令次优闭环系统为$\tilde{{ x}}_{k+1}={ f}(\tilde{{ x}}_k,\tilde{{ u}}_k)$,则由最优性原理 [20]可得:
$\label{eq27} \frac{1}{T}\sum_{k=0}^{T} L_e({ x}_k,{ u}_k^{\rm{empc}})\leq \frac{1}{T}\sum_{k=0}^{T} L_e(\tilde{{ x}}_k,\tilde{{ u}}_k) $
(22) 其中,$T\in {I}_{\geq 1}$. 由于$L_e({ x},{ u})$是定义在紧集合$X\times U$上的连续函数,且各个时刻的状态量和控制量都是有界的,因此式(22)的两边是有界的.
由于次优闭环系统渐近稳定于$({ x}_s,{ u}_s)$,则对于任意给定的充分小$\varepsilon>0$,总存在一个有限时间$\check{T}\in {I}_{\geq 1}$,使$\|L_e(\tilde{{ x}}_k,\tilde{{ u}}_k)-L_e({ x}_s,{ u}_s)\|<\varepsilon/2$,$k\geq \check{T}$成立. 进一步考虑$T>\check{T}$,我们有:
$\begin{align} & \left\| \sum\limits_{k=0}^{T}{{{L}_{e}}}({{\widetilde{x}}_{k}},{{\widetilde{u}}_{k}})-T{{L}_{e}}({{x}_{s}},{{u}_{s}}) \right\|\le \\ & \sum\limits_{k=0}^{T}{\|{{L}_{e}}({{\widetilde{x}}_{k}},{{\widetilde{u}}_{k}})-{{L}_{e}}({{x}_{s}},{{u}_{s}})\|+} \\ & \sum\limits_{k=\overset{}{\mathop{T}}\,}^{T}{\|{{L}_{e}}(}{{\widetilde{x}}_{k}},{{\widetilde{u}}_{k}})-{{L}_{e}}({{x}_{s}},{{u}_{s}})\|\le \\ & \overset{}{\mathop{T}}\,{{L}_{e,\text{max}}}+(T-\overset{}{\mathop{T}}\,)\frac{\varepsilon }{2} \\ \end{align}$
(23) 其中,$L_{e,{\rm max}}=\sup_{k\in[0,\check{T}]}\|L_e(\tilde{{ x}}_k,\tilde{{ u}}_k)-L_e({ x}_s,{ u}_s)\|$. 由于各个时刻的状态量和控制量都是有界的,故$L_{e,{\rm max}}$是一个有限数. 令$\check{N}=2\check{T}(L_{e,{\rm max}}-\varepsilon/2)/\varepsilon$,并对$\check{N}$取最小整数操作得$T^*$. 则对任意$T\geq T^*+1$,由式(23)可得:
$\label{eq30} \begin{split} & \left\|\frac{1}{T}\sum_{k=0}^T L_e(\tilde{{ x}}_k,\tilde{{ u}}_k)-L_e({ x}_s,{ u}_s)\right\| \leq \ &\qquad \frac{\check{T}(L_{e,{\rm max}}-\frac{\varepsilon}{2})}{T}+\frac{\varepsilon}{2} \leq \varepsilon \end{split} $
(24) 即任意充分小$\varepsilon>0$,总存在一个有限时间$T^*$,当$T>T^*$时,式(24)成立. 从而由极限理论可知,
$\label{eq31} \lim_{T\rightarrow +\infty} \frac{1}{T}\sum_{k=0}^T L_e(\tilde{{ x}}_k,\tilde{{ u}}_k)=L_e({ x}_s,{ u}_s) $
(25) 结合式(25),对式(22)两边同时取极限,可得:
$\label{eq32} \lim_{T\rightarrow +\infty} \frac{1}{T}\sum_{k=0}^T L_e({ x}_k,{ u}_k^{ {\rm empc}})\leq L_e({ x}_s,{ u}_s) $
(26) 即闭环系统(15)在XN内具有渐近平均性能.
注 4. 闭环系统的渐近平均性能(26)是建立在无穷时间域上的结果,因此,在任意一个有限时间区间的平均性能值不一定小于稳态经济性能$L_e({ x}_s,{ u}_s)$.
3. 一类多目标经济预测控制
上述稳定EMPC策略可以推广应用到多经济目标优化控制问题. 本节结合多目标理想点概念 [39],给出一种稳定多目标EMPC策略.
3.1 多目标理想点
考虑$l\in {I}_{\geq 2}$个连续且有界的性能函数$L_j: X\times U\rightarrow R$,$j\in {I}_{1:l}$. 令$L({ x},{ u})=[L_1({ x},{ u})$,$L_2({ x},{ u})$,$\cdots$,$L_l({ x},{ u})]^{\rm T}$为函数向量. 在多目标优化问题中,这些性能函数可能相互冲突,此时不存在唯一的最优解同时极小化各个性能函数$L_j({ x},{ u})$,$j\in {I}_{1:l}$. 通常采用Pareto最优解定义多目标优化问题的有效解,但Pareto最优解通常不唯一(甚至无穷多个),并在目标空间$R^l$形成一个Pareto面(Pareto front) [39]. 因此,文献[28-30]等对具有优先级排序的多目标优化控制问题,采用字典序多目标优化方法设计多目标MPC控制器; 而文献[31-32]等对一类冲突但无排序要求的多目标优化控制问题,提出了理想点跟踪多目标MPC控制器设计等.
多目标理想点法的基本原理是在目标空间${{R}^{l}}$中定义某种范数距离,然后计算与理想点距离最近的折中点对应的Pareto解定义为多目标优化问题的一个最优解[39]. 由于多目标理想点法不需要人为选择各性能的加权系数,在不需要先验知识的条件下能自动处理各个目标的冲突性,是目前广受关注的一种多目标MPC控制器设计方法. 本节考虑一组冲突但无排序要求的多经济性能函数$L({ x},{ u})$,采用多目标理想点法设计一类多目标EMPC控制器.
考虑约束系统(1)和(2),定义$L({ x},{ u})$的稳态理想性能,即理想点$L^*=[L_1^*,L_2^*,\cdots,L_l^*]^{\rm T}$,其中
$\label{eq33} L_j^*=\min_{{ x}\in X,{ u}\in U} \{L_j({ x},{ u})|{ x}={ f}({ x},{ u})\},j\in {I}_{1:l} $
(27) 由于$L({ x},{ u})$的冲突性,$L^*$是不可实现的,根据理想点法基本原理 [39],在Pareto面中寻找一个距离$L^*$最近的折中点,求得该折中点对应的一个Pareto解:
$\label{eq34} ({ x}_s^*,{ u}_s^*)=\arg\min_{{ x}\in X,{ u}\in U} \{\|L({ x},{ u})-L^*\|_p | { x}={ f}({ x},{ u})\} $
(28) 其中,向量p范数$\|\cdot\|_p$定义了目标空间${{R}^{l}}$中性能值$L({ x},{ u})$到理想点$L^*$的距离. 则本节的目的是设计一个多目标状态反馈控制器${ u}(x)$,使闭环系统在约束(2)作用下能渐近稳定于Pareto解$({ x}_s^*,{ u}_s^*)$,同时极小化一组性能函数$L({ x},{ u})$. 为此,结合算法1和多目标理想点法,设计一种理想点跟踪多目标优化经济模型预测控制器.
3.2 多目标EMPC
记Pareto最优解$({ x}_s^*,{ u}_s^*)$为$({ x}_s,{ u}_s)$,应用上节提出的稳定EMPC策略,令经济性能函数
${{L}_{e}}(x,u)=\|L(x,u)-{{L}^{*}}\|$
(29) 将式(29)代入目标函数(6). 由于该$L_e({ x},{ u})$不是$({ x}_s^*,{ u}_s^*)$的正定函数,即$({ x}_s^*,{ u}_s^*)\neq 0$,故选择函数$L_a({ x},{ u})$和$E_a({ x})$使其满足假设1和2. 则在每个时刻k在线求解优化控制问题(7),可得一个多目标经济预测控制律
${{u}_{k}}=u_{k}^{\text{mo}}:=u_{0|k}^{*},k\in {{I}_{\ge 0}}$
(30) 及其闭环系统
${{x}_{k+1}}=f({{x}_{k}},u_{k}^{\text{mo}}),k\in {{I}_{\ge 0}}$
(31) 下面给出多目标EMPC控制律(30)的实施步骤.
算法 2.(多目标EMPC算法)
1) 设置N,$\alpha\geq 0$和性能函数$L_j({ x},{ u})$,$j\in {I}_{1:l}$; 根据式(27)和式(28)分别离线计算$L^*$和$({ x}_s^*,{ u}_s^*)$.
2) 根据式(29)定义经济性能函数$L_e({ x},{ u})$,并设置辅助函数$L_a({ x},{ u})$及$E_a({ x})$.
3) 考虑初始状态${ x}_0$,令$\eta({ x}_0,\alpha)$充分大且$k=0$.
4) 求解优化问题(7),得最优控制序列$u_{k}^{*}$.
5) 将$u_{k}^{*}$的第1个控制量输入系统(1); 令$k=k+1$.
6) 测量k时刻的状态${ x}_k$,求解优化问题(8)得最优解$u_{k}^{o}$.
7) 将$u_{k}^{o}$代入式(11)更新$\eta({ x}_k,\alpha)$,并返回第4)步.
定理 4. 若函数$L_a({ x},{ u})$和$E_a({ x})$满足假设1和2,且优化问题(7)在初始时刻存在可行解,则当$\alpha\in [0,1)$时,闭环系统(31)具有如下性质: 1) 系统在吸引域XN内渐近稳定于${ x}_s^*$.
2) 系统在XN内满足如下性能:
$\underset{T\to +\infty }{\mathop{\lim }}\,\frac{1}{T}\sum\limits_{k=0}^{T}{\|L(}{{x}_{k}},u_{k}^{\text{mo}})-{{L}^{*}}{{\|}_{p}}\le \|L(x_{s}^{*},u_{s}^{*})-{{L}^{*}}{{\|}_{p}}$
(32) 3) 性能函数$L_j({ x},{ u})$在XN内具有如下收敛性:
$\label{eq39} \lim_{T\rightarrow +\infty}\frac{1}{T}\sum_{k=0}^{T}L_j({ x}_k,{ u}_k^{\rm{mo}})= L_j({ x}_s^*,{ u}_s^*),j\in {I}_{1:l} $
(33) 证明. 考虑性能函数(29),并利用定理1 $\sim$ 3的结果直接得到定理4.
4. 实例仿真
考虑二元物系聚合过程连续搅拌釜反应器 [38],其动态聚合过程可描述为
$\begin{align} & {{{\dot{C}}}_{A}}=\frac{q}{V}({{C}_{Af}}-{{C}_{A}})-{{k}_{0}}{{C}_{A}}\exp (-\frac{E}{RT}) \\ & \dot{T}=\frac{q}{V}({{T}_{f}}-T)-\frac{\Delta H}{\rho {{C}_{p}}}{{k}_{0}}{{C}_{A}}\exp (-\frac{E}{RT})+ \\ & \frac{UA}{V\rho {{C}_{p}}}({{T}_{c}}-T) \\ \end{align}$
(34) 其中,CA、T和Tc分别为反应物浓度(mol/L)、反应器温度(K)和冷却剂温度(K),模型参数为$q=100$ L/min,$C_{Af}=1$ mol/L,$UA=5\times 10^4$ J/min$\cdot$K,$\rho=1 000$ g/L,$C_p=0.239$ J/g$\cdot$K,$E/R=8 750$ K,$k_0=7.2\times 10^{10}$ min$^{-1}$,$V=100$ L,$T_f=350$ K,$\triangle H=-5\times 10^4$ J/mol. 定义状态变量${ x}=[C_A,T]^ {\rm T}$和控制变量$u=T_c$,及状态和控制约束
$X=\left[ 0,1 \right]\times \left[ 300,370 \right],U=\left[ 280,350 \right]$
(35) 我们用多目标优化控制结果验证本文结果的有效性.
在聚合反应过程中,通常希望增强聚合反应速率以提高生产效率,即极小化性能函数
$\label{eq42} L_1({ x},u)=-k_0x_1\exp\left( -\frac{E}{Rx_2}\right) $
(36) 同时希望降低能源消耗,采用极小化性能函数
$\label{eq43} L_2({ x},u)=u+(x_2-350)^2 $
(37) 表示降低能源消耗. 因此,一个理想的聚合反应过程控制器应该同时满足上述两个性能要求.
记$L({ x},u)=[L_1({ x},u),L_2({ x},u)]^{\rm T}$. 离线计算理想点$L^*=[-0.7943$,$299.9547]^{\rm T}$,其中,$L_1^*$对应的$({ x}_{s,1}^*,u_{s,1}^*)=(0.2057$,$370$,$300.1261)$,$L_2^*$对应的$({ x}_{s,2}^*,u_{s,2}^*)=(0.4973$,$350.1530$,$299.9547)$. 两组稳态最优解不一致表明$L_1({ x},u)$和$L_2({ x},u)$具有冲突性,从而上述聚合反应过程控制是一个双目标冲突的多目标优化控制问题.
选择向量2 - 范数,定义折中经济性能函数
$\label{eq44} L_e({ x},u)=\|L({ x},u)-L^*\|_2 $
(38) 计算距离$L^*$最近的折中点对应的最优解$({ x}_s^*,u_s^*)=(0.4948$,$350.2900$,$299.9129)$. 设置关于$({ x}_s^*,u_s^*)$的正定函数
$\label{eq45} L_a({ x},u)=({ x}-{ x}_s^*)^{{\rm T}}W_x({ x}-{ x}_s^*)+W_u(u-u_s^*)^2 $
(39) 其中,$W_x={\rm diag}\{1,1\}$和$W_u=0.1$. 对系统(34)在平衡点$({ x}_s^*,u_s^*)$的线性化模型求解LQR问题,得:
${{E}_{a}}(x)={{(x-x_{s}^{*})}^{\text{T}}}\left[ \begin{matrix} 257.1949 & \text{ }5.1672 \\ 5.1672 & 0.2585 \\ \end{matrix} \right](x-x_{s}^{*})$
(40a) ${{X}_{T}}=\{x\in {{R}^{2}}:{{E}_{a}}(x)\le 62.9680\}$
(40b) $\label{eq46c} \pi({ x})=[108.1010 5.4086]({ x}-{ x}_s^*)+u_s^* $
(40c) 可以验证,三要素(40)满足假设1和2.
在仿真中,采用欧拉差分法离散系统(34),取采样周期为0.1 min,预测步长N为7,仿真总步长为30. 采用MatLab 2007的fmincon函数优化计算最优控制问题(7)和(8). 下面,先验证本文结果的正确性,再与文献[6]等提出的EMPC策略、常规目标跟踪型MPC策略做比较以验证本文结果的优越性.
4.1 仿真实验一
选取系统初始状态(0.7 mol/L,320 K),运行算法2,仿真结果如图 1所示. 其中,实线为$\alpha=0$的仿真结果;虚线为$\alpha =0.3$的仿真结果; 点划线为$\alpha=0.7$的仿真结果;点线为$\alpha =0.99$的仿真结果. 需要指出的是: 为了更清楚地显示值函数$V_a^*(x)$在不同$\alpha$ 取值时的差异,图 1右下子图的时间坐标截取为前20步. 由图 1可知,对于系数$\alpha\in [0,1)$,值函数$V_a^*$都是单调递减的. 因此,由算法2产生的多目标EMPC及其闭环系统渐近稳定于Pareto最优稳态解$({ x}_s^*,u_s^*)$,且在所有时刻满足状态和控制约束(35).
尽管对系数$\alpha\in [0,1)$,闭环系统渐近稳定,但不同 值对应的闭环系统的动态响应和经济性能是不一样的,图 2给出了上述 取值时的性能实时曲线. 分析图 1和2可知,$\alpha$取值越小,值函数$V_a^*$下降越快,闭环系统趋于最优平衡点的时间越短,但经济性能可能会下降,如图 2左子图实线所示. 反之亦然,如对应$\alpha=0.99$的点线所示,尽管在30步仿真时间内,闭环系统还没有收敛至平衡点,但它的性能指标$L_1$可以达到更小的值. 因此,设计者可以通过调整$\alpha$取值对闭环系统的收敛速度和经济性能进行权衡,从而提高经济预测控制器应用的灵活性.
4.2 仿真实验二
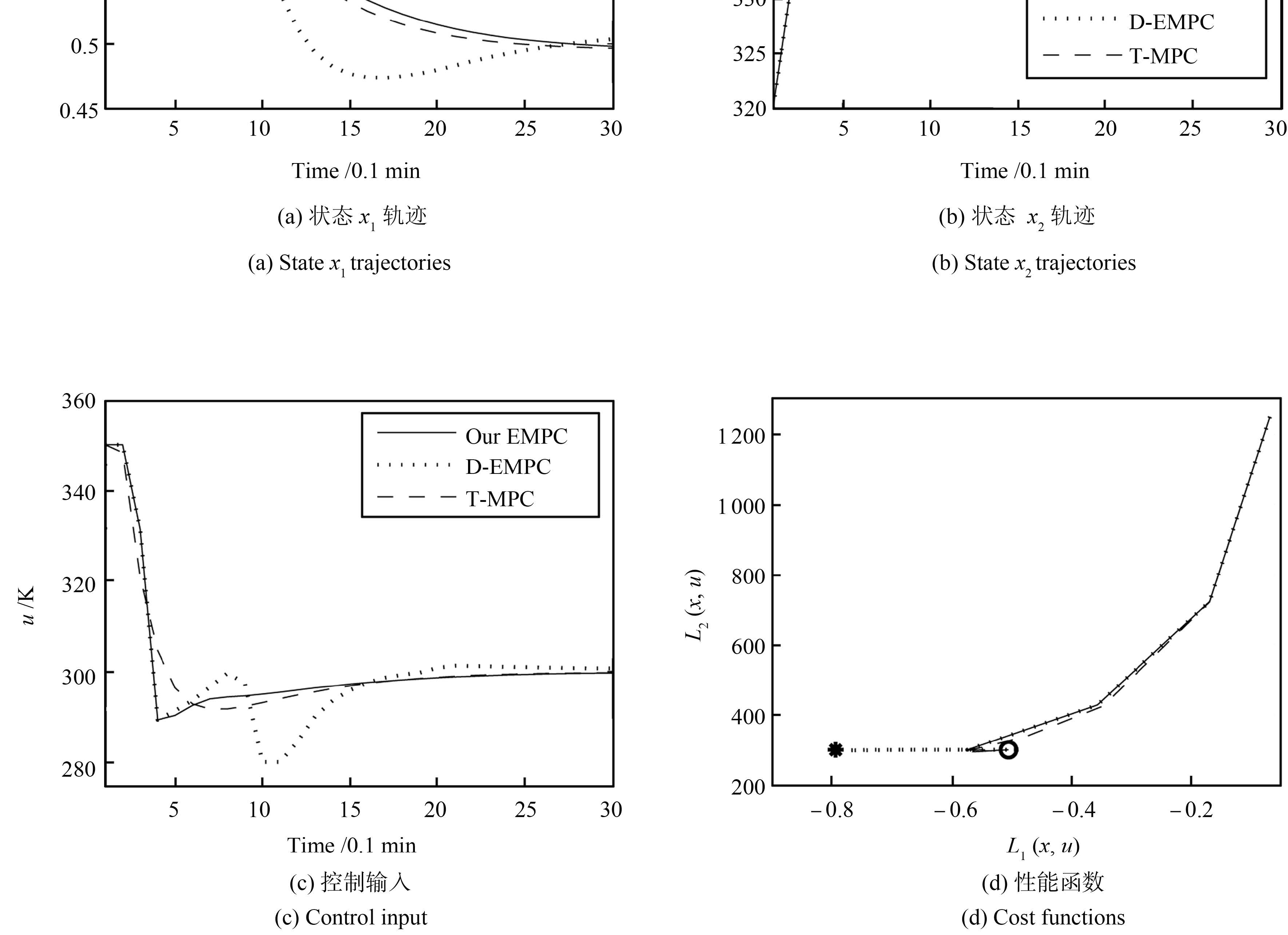
为验证本文控制策略的优越性,对比文献[6]等提出耗散EMPC策略(简记为D-EMPC)和目标跟踪MPC策略(简记为T-MPC). 由于T-MPC策略的性能函数总是设定值偏差的正定函数 [1-2],因此在该次实验中,令正定函数(39)为T-MPC策略的性能函数. 考虑初始状态(0.7 mol/L,320 K),图 3给出了本文策略和其余两种策略在相同仿真环境下的控制结果. 其中,实线表示本文策略($\alpha=0.2$)对应结果; 点线表示D-MPC策略对应结果; 虚线表示T-MPC策略对应结果; 右下子图符号"*"表示性能理想点,"o"表示最优平衡点对应的经济性能.
由图 3分析可知,本文策略和T-MPC策略对应的闭环系统渐近收敛至$({ x}_s^*,u_s^*)$,而D-MPC策略对应的闭环系统在暂态响应过程中出现震荡现象(如控制输入u),同时存在稳态误差(如反应器温度$x_2$),这主要是因为D-EMPC策略要求被控系统和经济性能函数满足严格耗散性条件. 但对于非线性系统,严格耗散性条件很难成立 [5],如本例中的聚合过程(34)和经济性能(38)不满足严格耗散性条件,从而D-EMPC策略不能保证闭环系统收敛至$({ x}_s^*,u_s^*)$,对应的性能相位曲线也不能收敛至最优平衡点对应的经济性能"o",如图 3右下子图点线所示. 另一方面,尽管本文策略和T-MPC策略的闭环系统都收敛至$({ x}_s^*,u_s^*)$,但收敛路径不一样.如果以进入稳态解$\pm 5 %$为界,那么本文策略对应闭环系统的收敛过渡时间小于T-MPC策略闭环系统的收敛过渡时间,从而加快闭环系统的过渡响应过程.
令$Av\{L_1\}$和$Av\{L_2\}$分别表示性能函数(36)和(37)的渐近平均性能,则进一步比较三种策略取得的渐近平均性能. 取足够大的仿真时间步长100,图 4和表 1分别给出了三种策略关于性能函数(36)和(37)的瞬时性能和渐近平均性能. 图 4中实线为本文策略对应的结果; 点线为D-MPC策略对应的结果; 虚线表示T-MPC策略对应结果. 由图 4分析可知,对于$L_1({ x},u)$,本文策略和T-MPC策略取得的平均性能较优于D-MPC策略; 对于$L_2({ x},u)$,三种策略取得的平均性能较为接近. 进一步,以D-MPC策略取得的渐近平均性能值作为参考基准,对于$L_1({ x},u)$,本文策略和T-MPC策略分别增效$1.52 %$和$1.69 %$; 对于$L_2({ x},u)$,本文策略和T-MPC策略分别增效$0.34 %$和$0.27 %$. 综合图 3和4和表 1结果,验证了本文策略在性能优化方面的优越性.
表 1 渐近平均性能Table 1 Asymptotic average performanceOur EMPC D-EMPC T-MPC Av{L1} -0.502 2 -0.494 7 -0.503 1 Av{L2} 314.579 7 315.660 2 314.801 2 5. 结语
本文针对约束非线性系统,提出了一种新的稳定经济MPC策略. 通过引入关于经济最优平衡点的辅助正定函数,并利用辅助函数的最优值函数定义原始EMPC优化问题的一类稳定性约束. 应用常规MPC的终端约束集、终端代价函数和局部控制器三要素方法,建立了闭环系统关于经济最优平衡点渐近稳定性和渐近平均性能的充分条件. 结合多目标理想点法,将提出EMPC策略推广至多经济目标函数优化控制问题. 建立了多目标EMPC策略的渐近稳定性充分条件. 通过对连续搅拌反应器多目标优化控制的对比研究,验证了本文结果的有效性.
-
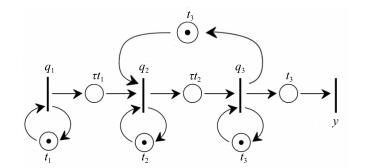
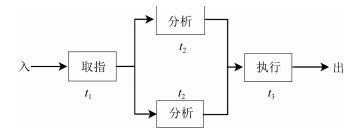
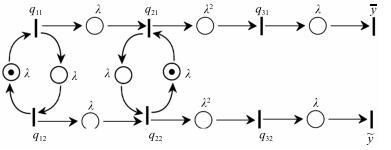
图 6 发生指令相关的并行处理系统的Petri网模型
Fig. 6 Petri net of the parallel processing with instruction dependency

图 11 不同时刻并联系统的状态描述
Fig. 11 State descriptions of the parallel system at various moments

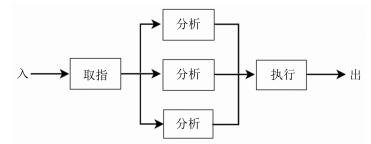
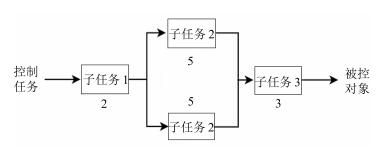
图 13 三套瓶颈段并联的Petri网模型
Fig. 13 Petri net of parallel connection with three bottleneck sub-processes
-
[1] Xia Y Q. From networked control systems to cloud control systems. In:Proceedings of the 31st Chinese Control Conference. Las Vegas, Nevada, USA:IEEE, 2012. 5878-5883 [2] Xia Y Q. Cloud control systems. IEEE/CAA Journal of Automatica Sinica, 2015, 2(2):134-142 doi: 10.1109/JAS.2015.7081652 [3] Xia Y Q, Fu M Y, Liu G P. Analysis and Synthesis of Networked Control Systems. Berlin:Springer-Verlag, 2011. [4] Antonopoulos N, Gillam L. Cloud Computing. Berlin:Springer-Verlag, 2010. [5] Floerkemeier C, Langheinrich M, Fleisch E, Mattern F, Sarma S E. The Internet of Things. Berlin:Springer-Verlag, 2008. [6] Braubach L, Briot J P, Thangarajah J. Programming Multi-Agent Systems. Berlin:Springer-Verlag, 2010. [7] Kaneko K, Tsuda I. Complex Systems:Chaos and Beyond. Berlin:Springer-Verlag, 2001. [8] 夏元清.云控制系统及其面临的挑战.自动化学报, 2016, 42(1):1-12 http://www.aas.net.cn/CN/abstract/abstract18791.shtmlXia Yuan-Qing. Cloud control systems and their challenges. Acta Automatica Sinica, 2016, 42(1):1-12 http://www.aas.net.cn/CN/abstract/abstract18791.shtml [9] Peterson J L. Petri Net Theory and the Modeling of Systems. Englewood Cliffs:Prentice-Hall, 1981. [10] Reisig W. Petri Nets:An Introduction. Berlin:Springer-Verlag, 1985. [11] Murata T. Petri nets:properties, analysis and applications. Proceedings of the IEEE, 1989, 77(4):541-580 doi: 10.1109/5.24143 [12] Fan L J, Wang Y Z, Li J Y, Cheng X Q, Lin C. Privacy Petri net and privacy leak software. Journal of Computer Science and Technology, 2015, 30(6):1318-1343 doi: 10.1007/s11390-015-1601-7 [13] Tavares J J P Z D S, Saraiva T A. Elementary Petri net inside RFID distributed database (PNRD). International Journal of Production Research, 2010, 48(9):2563-2582 doi: 10.1080/00207540903564934 [14] Gradišar D, Mušič G. Production-process modelling based on production-management data:a Petri-net approach. International Journal of Computer Integrated Manufacturing, 2007, 20(8):794-810 doi: 10.1080/09511920601103064 [15] Khan N A, Ahmad F. Modeling and simulation of an improved random direction mobility model for wireless networks using colored Petri nets. Simulation, 2016, 92(4):323-336 doi: 10.1177/0037549716634435 [16] Baruwa O T, Piera M A, Guasch A. Deadlock-free scheduling method for flexible manufacturing systems based on timed colored Petri nets and anytime heuristic search. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2015, 45(5):831-846 doi: 10.1109/TSMC.2014.2376471 [17] Cuninghame-Green R A. Minimax Algebra. Berlin:Springer-Verlag, 1979. [18] Baccelli F, Cohen G, Olsder G J, Quadrat J P. Synchronization and Linearity:An Algebra for Discrete Event Systems. New York:John Wiley and Sons, 1992. [19] Heidergott B, Olsder G J, van der Woude J. Max Plus at Work:Modeling and Analysis of Synchronized Systems:A Course on Max-Plus Algebra and Its Applications. New Jersey:Princeton University Press, 2006. [20] Gaubert S. Théorie des Systémes Linéaires dans les Dioides[Ph.D. dissertation], Ecole Nationale Supérieure des Mines de Paris, French, 1992. [21] 陈文德, 齐向东.离散事件动态系统的周期配置.中国科学(A辑), 1993, 23(1):1-7 http://d.wanfangdata.com.cn/Conference/191447Chen Wen-De, Qi Xiang-Dong. Period assignment of discrete event dynamic systems. Science in China (Series A), 1993, 23(1):1-7 http://d.wanfangdata.com.cn/Conference/191447 [22] Gaubert S, Gunawardena J. The duality theorem for min-max functions. Comptes Rendus de l'Académie des Sciences, Series Ⅰ:Mathematics, 1998, 326(1):43-48 doi: 10.1016/S0764-4442(97)82710-3 [23] Zhao Q C. A remark on inseparability of min-max systems. IEEE Transactions on Automatic Control, 2004, 49(6):967-970 doi: 10.1109/TAC.2004.829611 [24] Cohen G, Dubois D, Quadrat J P, Viot M. Linear system theory for discrete event systems. In:Proceedings of the 23rd IEEE Conference on Decision and Control. Las Vegas, Nevada, USA:IEEE, 1984. 539-544 [25] Necoara I, De Schutter B, van den Boom T, Hellendoorn H. Robust control of constrained max-plus-linear systems. International Journal of Robust and Nonlinear Control, 2009, 19(2):218-242 doi: 10.1002/rnc.v19:2 [26] 王龙, 郑大钟.线性离散事件动态系统的可达性.高校应用数学学报, 1990, 5(2):292-301Wang Long, Zheng Da-Zhong. On the reachability of linear discrete event dynamic systems. Applied Mathematics:A Journal of Chinese Universities, 1990, 5(2):292-301 [27] Tao Y G, Liu G P, Mu X W. Max-plus matrix method and cycle time assignability and feedback stabilizability for min-max-plus systems. Mathematics of Control, Signals, and Systems, 2013, 25(2):197-229 doi: 10.1007/s00498-012-0098-7 [28] Adzkiya D, De Schutter B, Abate A. Computational techniques for reachability analysis of max-plus-linear systems. Automatica, 2015, 53:293-302 doi: 10.1016/j.automatica.2015.01.002 [29] De Schutter B, van den Boom T. Model predictive control for max-plus-linear discrete event systems. Automatica, 2001, 37(7):1049-1056 doi: 10.1016/S0005-1098(01)00054-1 [30] van den Boom T, De Schutter B. Properties of MPC for max-plus-linear systems. European Journal of Control, 2002, 8(5):453-462 doi: 10.3166/ejc.8.453-462 [31] Trobec R, Vajteršic M, Zinterhof P. Parallel Computing. Berlin:Springer-Verlag, 2009. [32] Olsder G J, Roos C. Cramer and Cayley-Hamilton in the max algebra. Linear Algebra and Its Applications, 1988, 101:87-108 doi: 10.1016/0024-3795(88)90145-0 [33] De Schutter B, De Moor B. A note on the characteristic equation in the max-plus algebra. Linear Algebra and Its Applications, 1997, 261(1-3):237-250 doi: 10.1016/S0024-3795(96)00407-7 [34] Cohen G, Dunois D, Quadrat J, Viot M. A linear-system-theoretic view of discrete-event processes and its use for performance evaluation in manufacturing. IEEE Transactions on Automatic Control, 1985, 30(3):210-220 doi: 10.1109/TAC.1985.1103925 [35] Chen W D, Qi X D, Deng S H. The eigen-problem and period analysis of the discrete-event system. Systems Science and Mathematical Sciences, 1990, 3(3):243-260 [36] Karp R M. A characterization of the minimum cycle mean in a digraph. Discrete Mathematics, 1978, 23(3):309-311 doi: 10.1016/0012-365X(78)90011-0 [37] Hassanien A E, Azar A T, Snasael V, Kacprzyk J, Abawajy J H. Big Data in Complex Systems. Berlin:Springer-Verlag, 2015. -


 下载:
下载:


 下载:
下载:





计量
- 文章访问数: 2582
- HTML全文浏览量: 317
- PDF下载量: 589
- 被引次数: 0
